
- Какие существуют подходы к обеспечению совместного редактирования?
- Насколько они сложны в реализации?
- Можно ли взять готовую библиотеку и использовать ее в своем проекте?
- Можно ли вести разработку без оглядки на совместное редактирование?
Для того чтобы подробно и аргументированно ответить на них, необходимо написать довольно много материала, поэтому статей будет несколько, присаживайтесь поудобнее, мы начинаем.
Как только мы начинаем хранить файлы на сервере (в облаке), возникает естественное желание обеспечить их редактирование несколькими людьми. Особенно это актуально для офисных документов, над которыми работают сразу несколько человек и каждый из них вносит правки.
Но «нельзя просто так взять и…» предоставить всем доступ для правки одного документа. Необходим механизм, который обеспечит удобное и корректное изменение одного файла несколькими пользователями. Давайте рассмотрим варианты, как это можно сделать.
Возможные подходы
Блокировка всего документа при редактировании
Это самый тривиальный метод. Преимуществами такого решения являются простота реализации и возможность работы со всеми типами данных. На этом преимущества заканчиваются и начинаются сплошные неудобства для пользователя:
- В один момент времени только один пользователь может вносить правки. Чем больше будет такой документ и чем чаще его будут редактировать, тем более явным становится это неудобство. Представьте себе ТЗ на сотню с лишним страниц, при этом один пользователь вынужден ждать, пока его коллега закончит править раздел в другой части документа.
- Каждое изменение в документе приводит к необходимости полностью передать его на сервер, а затем скачать всем участникам, что сильно ухудшает скорость работы и увеличивает объем пересылаемых данных.
- Данное решение не может обеспечить офлайн-работу, ведь чтобы приступить к редактированию документа, требуется заблокировать его на сервере от изменения другими пользователями. А без соединения с сервером сделать это нельзя.
- Неснятая блокировка. Представим, что один пользователь забыл снять блокировку, да еще и ушел домой или вовсе уехал в отпуск. Всем остальным приходится ждать или искать нерадивого пользователя. Частично от этого можно уйти, контролируя время активности или предоставив администратору возможность принудительно снять блокировку. Впрочем, ни то ни другое не является идеальным решением, так как в первом случае нельзя понять, на основе чего можно отличить пропавший интернет от недисциплинированности пользователя, а во втором нельзя обойтись без вмешательства человека и чьи-то изменения могут быть потеряны.
Такой вариант можно часто встретить в решениях для корпоративных порталов, ERP, СЭД.
Блокировка части документа
Для текстового документа такой единицей деления может стать абзац или таблица. Это улучшает весь процесс работы, а именно:
- Теперь можно одновременно редактировать один документ, при условии, что правки вносятся в разные его части.
- Заблокировать документ полностью нельзя. Несмотря на неснятую блокировку, с остальным документом можно продолжать работать.
Но и этот подход нельзя назвать идеальным:
- По-прежнему нельзя обеспечить офлайн-работу. Для блокировки любой из частей документа необходимо связаться с сервером.
- Часть документа, заблокированная при редактировании, может быть значительной. Действительно, абзац может быть довольно большим и содержать несколько сотен или тысяч знаков текста. Еще больше сложностей возникает при работе с таблицами. Без дополнительных ухищрений нельзя одновременно разрешить менять содержимое ячеек и структуру таблицы — вставлять и удалять строки или столбцы. Это означает, что при любом изменении одной из ячеек требуется блокировать всю таблицу. В офисных документах таблицы могут быть разного уровня вложенности или же очень большого размера. Особенно неприятным этот момент становится при работе с табличными документами, где рабочий лист и вовсе состоит из одной таблицы, а значит при любых изменениях надо его блокировать полностью.
- С точки зрения структуры, документ можно упрощенно представить как последовательность абзацев и таблиц. И когда мы вставляем или удаляем таблицы и абзацы, то мы редактируем эту последовательность. А это значит, что корректность совместного редактирования такой последовательности также необходимо обеспечить (кстати, принципиальной разницы между редактированием списка абзацев или списка букв нет, разве что первое происходит реже). Без введения принципиально другого метода синхронизации это должна быть опять же блокировка, только на этот раз объект блокировки будет один на весь документ.
Некоторые читатели могут заметить, что задача совместного редактирования успешно решается в системах контроля версий, с последовательной историей (SVN или CVS) или с возможностью ветвлений (GIT, Mercurial). Да, вы правы, но и здесь есть свои нюансы, которые делают невозможным применить в нашем случае тот же принцип:
- Merge. Во-первых, для пользователей офисных пакетов это понятие как правило незнакомо. Во-вторых, объединение разных версий документа становится принципиально более трудным при переходе от простого текста к документу со сложной (как правило иерархической) структурой, где есть текст, вложенные таблицы, изображения и различные настройки форматирования. Просто представьте себе подобный 3-way merge.
- Даже при использовании kdiff3 или winmerge случаются ошибки, а ведь они работают с простым текстом.
- Обычному пользователю офисных приложений будет непросто вникнуть в мир ветвлений и слияний. А вникнув, использовать будет не очень быстро и удобно.
Взгляд с другой стороны
Будем исходить из того, что с точки зрения пользователя вся работа с документом должна сводиться лишь к тому, чтобы исправить текст, вставить график, обещанный коллегам, и на этом закончить. Так же, как он это делал раньше с локальными документами. Все сложные процессы по поддержке корректного состояния документа должны быть скрыты от пользователя. При этом важно сохранить отзывчивость и функциональность, сравнимую с редактированием локальных файлов.
Для нас это диктует дополнительные требования:
1. Использование оптимистичной стратегии внесения изменений. К локальной копии документа правки должны применяться сразу. И независимо от этого они отправляются на сервер, а от него к другим клиентам, при этом то, как быстро они будут получены и применены, никак не влияет на скорость работы с локальной версией.
Отсюда следует, что состояния документа у клиентов и на сервере могут отличаться. Это формирует следующее требование:
2. Сходимость (convergence). Когда все пользователи закончат свою работу и все уведомления о правках будут доставлены, как на сервере, так и у клиентов должно быть одно и то же состояние документа.
Но это еще не все. Первые два требования можно выполнить с помощью простого, но явно не устраивающего пользователей алгоритма. Если на сервер приходят два конкурирующих изменения, то можно просто игнорировать то, что пришло позже, уведомив соответствующим образом клиентов. Этого будет достаточно, чтобы удовлетворить первые два требования, но явно недостаточно, чтобы сделать счастливым того, чьи изменения были выкинуты. А это значит, что нужно задекларировать еще одно требование:
3. Принцип сохранения намерений (intention preservation). Мы должны обеспечить максимальное сохранение намерений всех пользователей, даже если правки вносятся одновременно и они конкурируют друг с другом.
Мы декларируем, что каждая правка от каждого из пользователей важна для нас и мы не будем отменять ее без необходимости. Необходимость отменить все же может возникнуть. Например, в таких ситуациях, когда один пользователь отредактировал абзац, который параллельно был удален кем-то другим. В этом случае изменения уже просто нельзя применить, так как абзац более не существует.
Второй момент, который стоит упомянуть в контексте этого принципа, — формализация. Понятие «намерение» достаточно абстрактно. Представим, что в тексте есть слово «оптека», которое параллельно исправляют два пользователя, причем по-разному: «аптека» и «оптика». Большинство известных алгоритмов (и наш тоже) работают на уровне букв, и в результате получится «аптика», что не соответствует «высокоуровневым» намерениям обоих авторов. Существуют формализации намерений пользователей на уровне слабых порядков букв («хочу вставить букву “и” после буквы “т”, но перед “к”»). Для некоторых алгоритмов сохранение выраженных таким образом намерений является неотъемлемой их частью (об этом можно почитать здесь).
В нашем случае мы не формализуем намерения пользователей и тем более не даем строгих гарантий их соблюдения, но декларируем, что будем максимально придерживаться этого принципа.
Выбор неблокирующего алгоритма
Существуют два алгоритма, которые удовлетворяют всем нашим требованиям: оптимистичное внесение изменений, сходимость и сохранение намерений.
Первый. Differential synchronization. Который в итоге нам не подошел
Алгоритм предполагает постоянный 3-way merge на стороне клиента и сервера, который сопровождается пересылкой патчей в обе стороны. На схеме представлена общая идея.
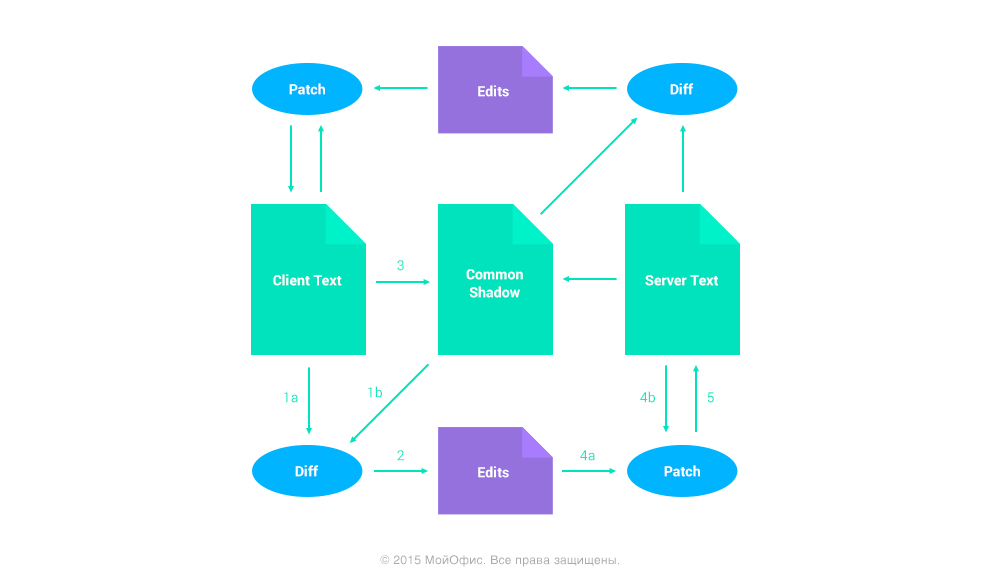
Более подробное описание можно увидеть на сайте автора.
Вероятно, вы уже догадались, по какой причине этот алгоритм нам не подходит. Правильно, как уже упоминалось, 3-way merge для документа со сложной структурой нетривиален. При этом необходимо иметь формальную гарантию того, что он даст одинаковые результаты при слияниях в разных порядках и направлениях… Это ставит крест на перспективе применения у нас данного подхода.
Второй. Operation Transformation (OT)
Это скорее общий подход, на основе которого разработаны различные алгоритмы.
В основе OT лежит довольно простая идея. Все изменения данных мы описываем как операции, которые пересылаем и преобразуем относительно других без самого документа. Когда операция приходит от одного пользователя к другому, мы ее трансформируем таким образом, чтобы она стала валидной относительно разницы между документами этих двух пользователей, выраженной в операциях. Звучит заумно, но на самом деле принцип довольно простой.
Что такое Operation Transformation
Давайте посмотрим на еще одну схему, которая популярна в статьях об OT.
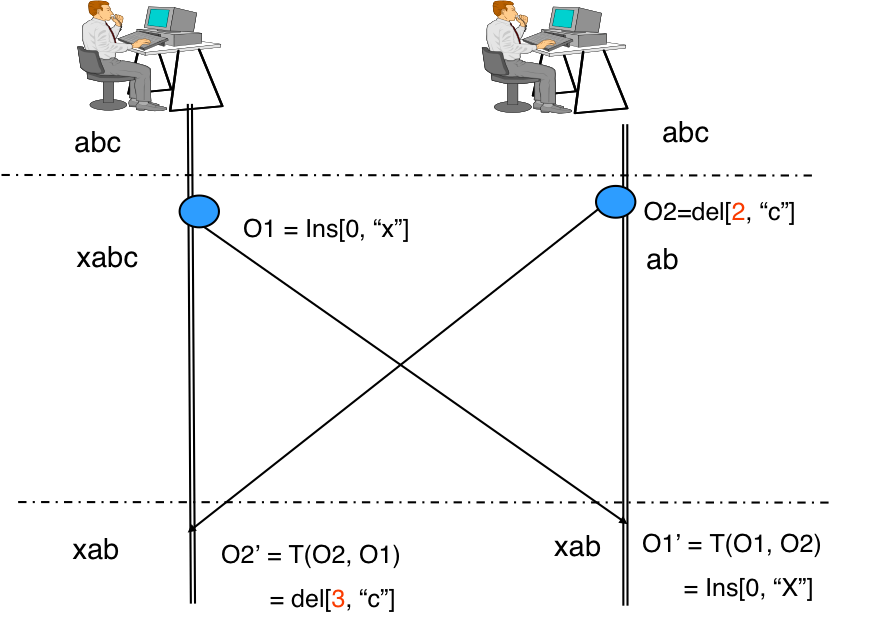
Операция О2:
- Пользователю 1 приходит операция О2 del[2, “c”] от пользователя 2.
- Операция О2 трансформируется относительно операции О1, которой не было у пользователя 2 на момент создания О2.
- В результате получается del[3, “c”], так как перед позицией 2 уже успели вставить один символ и у “с” позиция стала 3.
Операция О1:
- Пользователю 2 от пользователя 1 приходит операция О1 ins[0, “x”].
- O1 трансформируется относительно О2, но на этот раз при трансформации операция не меняется и применяется в таком же виде, как и у автора операции — пользователя 1.
Здесь используется трансформация включения (в некоторых алгоритмах используется и трансформация исключения). В дальнейшем я буду использовать обозначение Inc(O1, O2) для операции О1 с учетом эффектов операции О2, то есть, если кратко, мы включили О2 в О1.
Основное требование, которому должны удовлетворять трансформации включения (известное как Transition Property 1), — это:
Inc(O2, O1) * O1 = Inc(O1, O2) * O2,
где * — последовательное применение, справа налево. Для простоты понимания посмотрите на изображение:
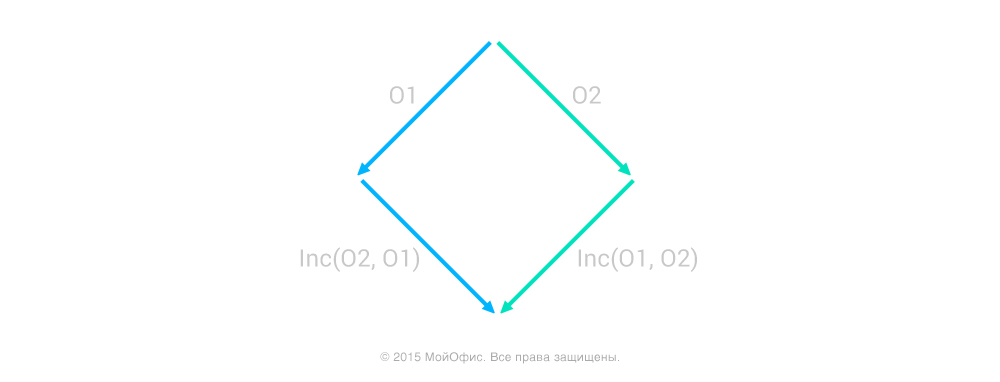
Приведенное выше равенство в применении к этой картинке означает, что, начав с одного состояния документа и двигаясь по правой или левой ветке, мы получим одно и то же итоговое состояние. Принципиальным моментом является то, что начинать «движение» мы должны из одного и того же состояния. Если это условие не соблюдать, то результатом будет рассогласованное состояние документов либо трансформированная операция может просто не иметь смысла. Например, вставка символа в неверную или несуществующую позицию документа.
Как я указал выше, существует несколько различных алгоритмов на основе ОТ. Их главным отличием является решение ключевого вопроса: как производить трансформации таким образом, чтобы любые операции, участвующие в трансформации, были над одним и тем же состоянием документа, и, если такой возможности нет, то с помощью каких еще преобразований можно изменить порядок применения операций.
Дело в том, что первые алгоритмы на основе ОТ не предусматривали использования центрального сервера. Все клиенты связывались между собой peer-to-peer. Соответственно, текущее состояние документа у пользователей выражалось последовательностью операций (О1, О2… ОN), при этом в каждый момент времени количество, состав и порядок этих операций у каждого клиента может быть свой. В этом случае нельзя определить единый строгий порядок среди всех генерируемых операций, можно ввести только слабый порядок по happens before критерию. Операции, между которыми нет такого отношения, считаются конкурирующими или параллельными (concurrent).
Подобный подход также несет с собой определенные сложности:
- Производительность. Количество трансформаций может быть очень большим, клиентам приходится хранить всю историю, так как в любой момент может прийти сколь угодно «древняя» операция от другого пользователя.
- Для корректной реализации требования TP-1 уже недостаточно. Приходится требовать еще и как минимум TP-2: Inc(O3, Inc(O1, O2) * O2) = Inc(O3, Inc(O2, O1) * O1). В зависимости от конкретного алгоритма может понадобиться выполнение других требований к трансформациям и обратным операциям (полный список здесь). Если у вас есть набор операций, то эти требования должны быть выполнены для любой пары или тройки, а это далеко не всегда так. При этом, чтобы иметь уверенность в сходимости алгоритма, эти требования необходимо формально верифицировать, то есть доказать, как теорему.
- Сложность. Подобные алгоритмы действительно непростые, и порой в них находят ошибки. Например, один из случаев, потенциально приводящий к ошибке, выглядит вот так:
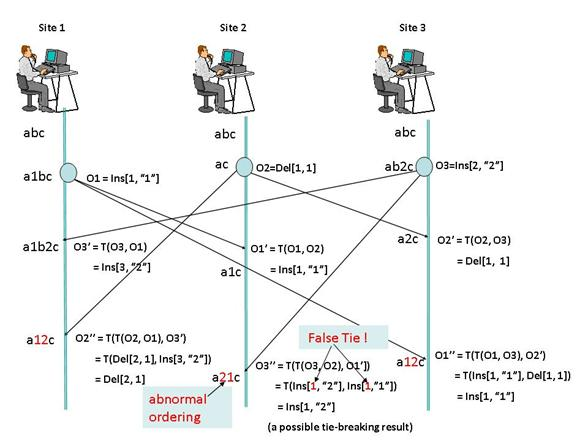
Интересующиеся классическими peer-to-peer алгоритмами могут найти подробный их обзор и сравнение тут.
Перечисленные выше трудности можно разрешить, если отказаться от равноправности всех клиентов и peer-to-peer соединений. При добавлении центрального сервера состояние документов можно описывать простой ревизией и требовать выполнения не более чем TP-1… Но этой теме будет посвящена уже следующая статья. Обещаю, что для любителей алгоритмов там будет больше интересного.
Первая статья из цикла тем временем подошла к финалу. Буду рад увидеть в комментариях ваши вопросы и пожелания по поводу содержания следующих статей.
Вторую часть можно найти тут.
Пока!
Комментарии (29)

flint
17.08.2015 19:28Если я правильно понимаю, то в основе OT лежит идея, близкая к Treedoc и Logoot. Вы не смотрели на подобные CRDT?

GraD_Kh
17.08.2015 20:34Я бегло посмотрел материал по ссылкам. Насколько я понял, там немного другая идея: документ представляется некоторой моделью, которая редактируется таким образом, чтобы не возникало коллизий. В частности элементам модели присваиваются уникальные идентификаторы, а удаление несуществующего элемента не считается ошибкой.
У ОТ подход другой — коллизии допускаются. К примеру, одновременная вставка в одну и ту же позицию в документе, или когда два пользователя меняют одно и то же свойство. Но при этом трансформация операций обеспечивает одинаковое итоговое состояние документа у всех.
gritzko
26.08.2015 14:52Основная идея семейства CRDT (WOOT, Logoot, Causal Trees и TreeDoc) — избежать трансформации операций, тем самым уменьшив сложность и повысив надёжность алгоритмов.
Это достигается за счёт уникальных идентификаторов, хранение которых и представляет интересную задачу.
При правильном подходе, идентификаторы занимают примерно столько же места, сколько и текст, а текст практически нисколько не занимает, по сравнению с различными медиа (картинки/видео).
CRDT также позволяет сложные сценарии (P2P, кэши, долгий оффлайн) и предлагает больший набор типов данных.
Кажется, мы общались с кем-то из вашей команды, примерно год назад. Вижу, за год вы многое успели. Впереди ещё много интересного.

Mendel
17.08.2015 19:42Неблокирующее одновременное редактирование — зло.
Одно дело когда у нас есть мерже-коммит, у которого есть автор. Другое дело когда у нас этот этап скрывается.
Ваш пример с «аптика» может быть фатальным.
Один человек удалил часть текста из одного места, и перенес его в другое место, параллельно другой человек удалили тот абзац куда фразу перенесли, и всё. На выходе уже текст который никто не читал, а если это договор, и пункт был важный…
Даже если мы целые фразы не теряем, а только буквы искажаем, ну или цифры… всё это может, и будет фатальным.
Либо у нас реально одновременная правка, как у гугла, где ты видишь чужой курсор, либо блокирующая работа.
Строго говоря здесь она тоже блокирующая, но строго на момент правки измеряющийся мс.AlDev
17.08.2015 19:50OT как раз дает реально одновременную правка как у гугла. Собственно у гугла и есть одна из реализаций OT, которую можно подсмотреть в apache wave например
GraD_Kh
17.08.2015 20:421) Имея техническую возможность сделать одновременное неблокирующее редактирование всегда можно сделать режим с блокировкой любой части документа. В обратную сторону — очень сложно.
2)Либо у нас реально одновременная правка, как у гугла, где ты видишь чужой курсор
Посмотрите на верхнюю картинку в посте :)
3) Выше совершенно верно заметили, что в основе гугловского алгоритма тоже OT. Причем сам механизм ОТ позволяет поддерживать валидные позиции курсоров.Mendel
17.08.2015 21:21И как это сочетается с оффлайном?
Потерял коннект, имеешь блокировку. Иначе получаем мердж. Со всеми радостями…GraD_Kh
17.08.2015 21:44Блокировка с офлайном, естественно, не сочетается никак. Я хотел отметить, что имея возможность совместного редактирования без блокировок, всегда можно дать возможность редактировать важные документы с блокировками его полностью или частично. А вот если сделать систему без оглядки на «фичу» одновременного редактирования, то впоследствии добавить ее будет очень сложно или даже практически невозможно.

RusSuckOFF
17.08.2015 19:45Как же все знакомо) А в вашей реализации есть какие-то интересные отличия от sharejs.org (как самый простой пример) или от OT алгоритма, лежащего в основе Google Docs? Было интересно послушать. Кроме undo, животрепещущий вопрос работы в офлайне.
GraD_Kh
17.08.2015 21:10Отличия от гугловского алгоритма есть: tombstones, иерархическая модель документа, возможность изменения операции во время выполнения для поддержания ограничений бизнес-логики. Офлайн, в принципе, эквивалентен долгому обрыву связи.
gritzko
26.08.2015 14:22OT с tombstones? Необычно…
У OT в оффлайне нарастает сложность задачи merge нетривиальным образом. Вы тестировали такие сценарии?GraD_Kh
26.08.2015 16:13OT с tombstones? Необычно…
Самое простое и эффективное решение FalseTie на мой взгляд.
У OT в оффлайне нарастает сложность задачи merge нетривиальным образом. Вы тестировали такие сценарии?
Из того, что проверяли в ручном режиме задержки именно OT-движка были незаметны. Специализированных тестов пока нет, у нас еще есть много моментов для оптимизаций и сжатия операций.

apple01
17.08.2015 20:29Разве совместное редактирование документа = collaboration? Последнее понятие намного шире.

vintage
20.08.2015 12:13А в чём проблема смёржить иерархические документы?
На одном из проектов имел дело с OT и вот какие ощущения:
1. Для каждого документа хранится вся история трансформаций (много весят, выборки тормозят и тп). Для решения этой проблемы пришлось писать таск на периодическое смёрживание трансформаций из одной сессии.
2. Малейший баг в алгоритме (а алгоритмы тут довольно нетривиальные) легко может запороть документ (у нас чудесно падал редактор), а исправлять битые трансформации — то ещё удовольствие.
3. Для получения актуальной версии нужно плясать с бубном — либо применяем все трансформации от начала времён, либо периодически расставляем «чекпоинты» и применяем трансформации от последнего чекпоинта.
В то же время, если использовать автомёрж, то:
1. Хранить нужно лишь последнюю актуальную версию и применять к ней патчи от клиентов.
2. Можно использовать любой редактор.
3. Неправильный автомёрж легко исправляется вручную.GraD_Kh
20.08.2015 14:08в чём проблема смёржить иерархические документы?
Проблема в том, что алгоритм автоматического мержа вынужден выбирать между надежностью и удобством для пользователя. То есть либо мы выбираем надежный алгоритм, который будет чаще просить пользователя смержить вручную. Либо более интеллектуальный, но который может дать неверный результат. По сравнению с простым текстом сложность мержа полноценного документа больше: представьте, что один пользователь добавил несколько строк в таблицу, а другой несколько столбцов. И при этом они отредактировали содержимое нескольких ячеек.
Кроме того, интерфейс ручного мержа офисных документов не может быть проще чем существующие утилиты для 3-way мержа. Вероятнее всего он будет значительно сложнее, а это значит, что пользователей нужно научить с ним работать.
1. Для каждого документа хранится вся история трансформаций (много весят, выборки тормозят и тп)
Скорее всего имелись ввиду операции, поскольку трансформации — это методы.
Правильно замечено, что наборы операций можно мержить. Плюс историю старше определенного времени можно удалять, если предположить, что клиенты достаточно регулярно синхронизируются с сервером. К тому же вся история нужна только на сервере, и при правильном выборе алгоритма большая ее часть практически не используется и может быть заархивирована. То есть проблемы с размером истории чисто технические и легко решаются с помощью стандартных подходов.
Малейший баг в алгоритме (а алгоритмы тут довольно нетривиальные) легко может запороть документ
Да, алгоритм должен быть качественно оттестирован. Кроме того, счет наличия истории всегда можно откатиться к последнему валидному состоянию.
Для получения актуальной версии нужно плясать с бубном
Обычно актуальная версия как раз и хранится, поэтому доступна без дополнительных издержек. Если нужно быстро получать старые версии, то можно использовать чекпоинты.
Хранить нужно лишь последнюю актуальную версию и применять к ней патчи от клиентов.
В этом как раз основная разница между ОТ и мержем. OT работает с операциями и имеет информацию о том, как менялся документ. Мерж имеет дело только с конечными состояниями и уже постфактум находит одинаковые и отличающиеся части, что дает намного меньше возможности «свести» различные изменения пользователей.vintage
20.08.2015 16:01Элементарно — каждой ячейке назначаем гуид и по ним видно какие ячейки добавились, какие удалились и какие изменились. Со столбцами, строками, параграфами — та же песня.
И ручной мёрж можно сделать проще, так как у нас есть информация о структуре. В отличие от плоского текста, где единственная структура — это список строк текста.
Вот вам задачка: два пользователя находясь в оффлайне исправили опечатку поменяв «оптека» на «аптека» путём стирания буквы «о» (первая операция) и добавления буквы «а» (вторая операция), потом оба выходят в онлайн и что они получают в результате?
GraD_Kh
20.08.2015 16:27Подход с гуидами близок к упоминавшемуся выше в комментариях CRDT. Если гуиды присваивать всему вплоть до букв, то это сильно просаживает производительность и увеличивает размер документа. Если внутри абзаца гуидов нет, то сама структура документа мержится однозначно, а вот текст внутри параграфов с теми же проблемами, что и плоский текст. Хотя в целом, если выбрать в качестве метода синхронизации мерж, то это решение выглядело бы оптимальным.
По поводу «аптеки» и «оптики» — для классического OT будет, естественно гибрид, хотя отслеживать такие конфликты возможность есть. Но и в зависимости от правил мержа это тоже может быть автоматически смержено, либо помечено как конфликт.

This_man
23.08.2015 17:50Спасибо за статью, познавательно. Действительно, задача не тривиальна и интересна.
GraD_Kh
09.09.2015 12:40Вышла вторая часть статьи. Там есть ответы на многие вопросы из комментариев :)
AlDev
Самое веселье в OT начинается с поддержкой операций отмены
GraD_Kh
Имеете ввиду false-tie? Про undo обязательно будет в продолжении.
AlDev
Да, и FT тоже, ну и саму задачу отмены не последней операции + поддержку IP2-3 на уровне алгоритма.
Хотелось бы услышать в чем, с Вашей точки зрения, недостаток контекстной теории (context-based OT)?
GraD_Kh
1) Если не вводить дополнительные оптимизации, то с каждой операцией надо передавать ее контекст, то есть набор предыдущих операций от некоторого базового состояния. Чем дольше мы редактируем — тем больше «хвост». Оптимизации существуют, но они ведут к значительному усложнению алгоритма со всеми вытекающими.
2) Как я упоминал в статье, каждому пользователю необходима полная история операций, даже если он пришел позже.
3) Если есть возможность использовать центральный сервер, то лучше отказаться от peer-to-peer алгоритмов. Наличие одного «стандартного» порядка операций (естественно, это порядок операций на сервере) очень сильно упрощает алгоритм и положительно влияет на быстродействие, так как «нагрузка» к операции — это просто одно число (ревизия). В следующей статье это будет подробно разобрано и для тех, кто знаком с классическими «peer-to-peer» алгоритмами, разница будет видна невооруженным глазом.
4) Есть некоторые моменты, которые можно реализовать только если есть центральный сервер. А если нет общего «правильного» порядка, то невозможно. К сожалению, двумя словами их не объяснишь. Если получится, то это будет частью одной из следующих статей.
Vanger13
По описанию сильно похоже на стандартный game server с возможностью reconnect'a :)
AlDev
1 — передается вектор контекста, описывающий ее состояние. То есть если отказаться от отмены и упростить — данный вектор содержит количество операций на каждом сайте
2 — нет, зачем? у него есть состояние документа (вектор контекста) при его подключении, его интересует только то, что происходит после его подключения, а данные операции в любом случае рассылаются всем сайтам
3 — сontext-based может быть и не p2p, что сильно его упрощает. Не совсем понял, как поддерживается соответствие порядка операций на сервере и на клиенте. Получается операция выполняется и преобразуется только на сервере, а на клиенте затем виден результат? Но тогда как быть с оффлайном и низкой скоростью подключения?
4 — было бы интересно почитать
GraD_Kh
1 — У нас вариант отказа от возможности отмены не рассматривался. Мало кто захочет пользоваться редактором, в котором нет undo-redo.
2 — А если вдруг придет операция, сгенерированная на состоянии более раннем, чем то, которое было при подключении?
3 — Мне сложно в одном комментарии рассказать весь алгоритм, потерпите немного, это обязательно будет в следующей статье. Могу намекнуть, что если взять алгоритм от google docs или wave, то с некоторыми изменениями этого можно добиться)
4 — Постараемся, это то, чего я в существующих статьях не встречал.
AlDev
По первому пункту я имел ввиду отмену любой операции в истории, там вектор контекста становится чуть сложнее, но все равно достаточно простой. Про операцию из прошлого да, такие случаи надо обрабатывать отдельно.