
We've already discussed some object-level locks (specifically, relation-level locks), as well as row-level locks with their connection to object-level locks and also explored wait queues, which are not always fair.
We have a hodgepodge this time. We'll start with deadlocks (actually, I planned to discuss them last time, but that article was excessively long in itself), then briefly review object-level locks left and finally discuss predicate locks.
When using locks, we can confront a deadlock. It occurs when one transaction tries to acquire a resource that is already in use by another transaction, while the second transaction tries to acquire a resource that is in use by the first. The figure on the left below illustrates this: solid-line arrows indicate acquired resources, while dashed-line arrows show attempts to acquire a resource that is already in use.
To visualize a deadlock, it is convenient to build the wait-for graph. To do this, we remove specific resources, leave only transactions and indicate which transaction waits for which other. If a graph contains a cycle (from a vertex, we can get to itself in a walk along arrows), this is a deadlock.
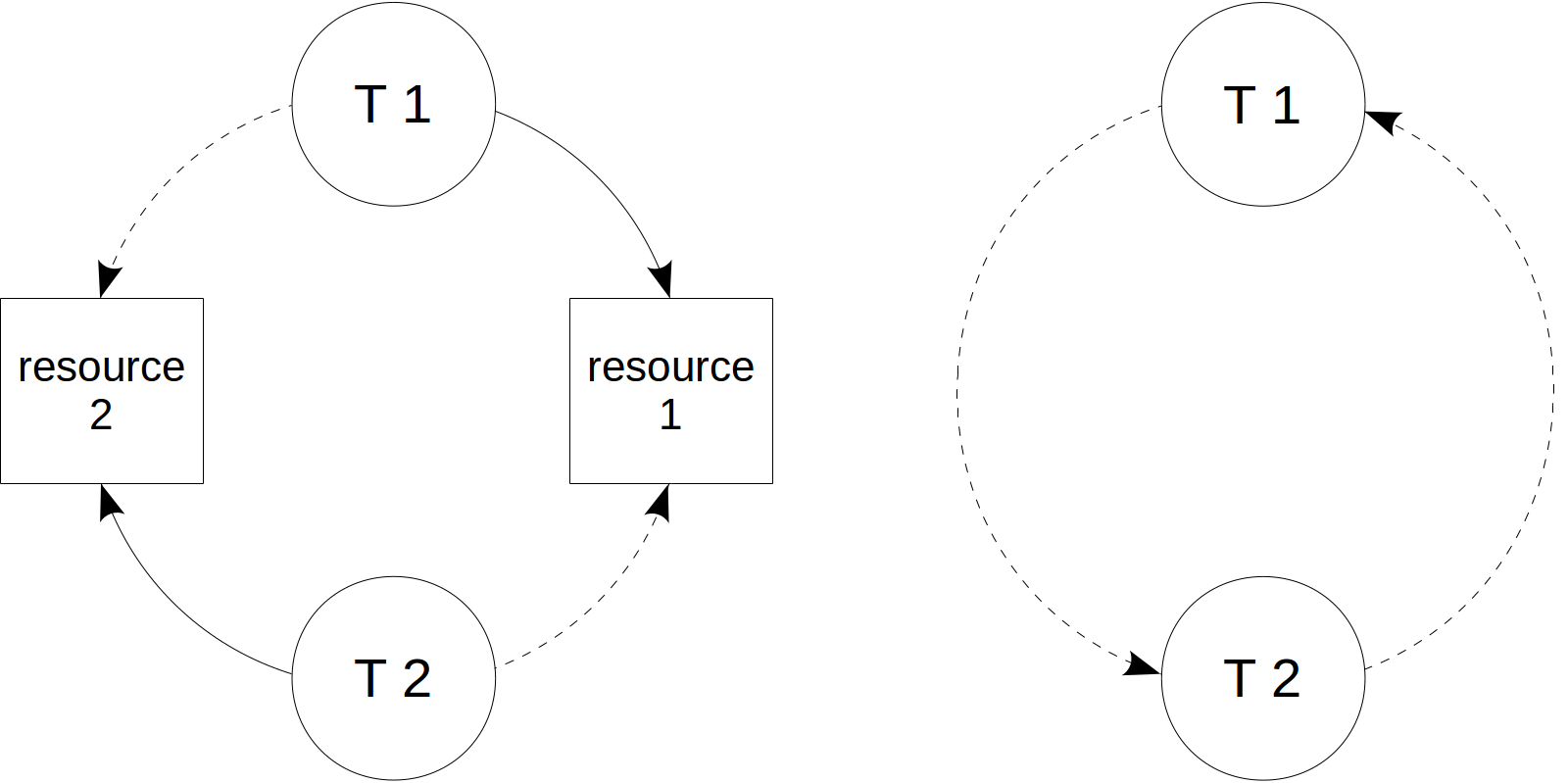
A deadlock can certainly occur not only for two transactions, but for any larger number of them.
If a deadlock occured, the involved transactions can do nothing but wait infinitely. Therefore, all DBMS, including PostgreSQL, track locks automatically.
The check, however, requires a certain effort, and it's undesirable to make it each time a new lock is requested (deadlocks are pretty infrequent after all). So, when a process tries to acquire a lock, but cannot, it queues and «falls asleep», but sets the timer to the value specified in the deadlock_timeout parameter (1 second by default). If the resource gets free earlier, this is fine and we skimp on the check. But if on expiration of deadlock_timeout, the wait continues, the waiting process will wake up and initiate the check.
If the check (which consists in building the wait-for graph and searching it for cycles) does not detect deadlocks, it continues sleeping, this time «until final victory».
But if a deadlock is detected, one of the transactions (in most cases, the one that initiated the check) is forced to abort. This releases the locks it acquired and enables other transactions to continue.
Deadlocks usually mean that the application is designed incorrectly. There are two ways to detect such situations: first, messages will occur in the server log and second, the value of
Usually deadlocks are caused by an inconsistent order of locking table rows.
Let's consider a simple example. The first transaction is going to transfer 100 rubles from the first account to the second one. To this end, the transaction reduces the first account:
At the same time, the second transaction is going to transfer 10 rubles from the second account to the first one. And it starts with reducing the second account:
Now the first transaction tries to increase the second account, but detects a lock on the row.
Then the second transaction tries to increase the first account, but also gets blocked.
So a circular wait arises, which won't end on its own. In a second, the first transaction, which cannot access the resource yet, initiates a check for a deadlock and is forced to abort by the server.
Now the second transaction can continue.
The correct way to perform such operations is to lock resources in the same order. For example: in this case, accounts can be locked in ascending order of their numbers.
Sometimes we can get a deadlock in situations where, seemingly, it could never occur. For example: it is convenient and usual to treat SQL commands as atomic, but the UPDATE command locks rows as they are updated. This does not happen instantaneously. Therefore, if the order in which a command updates rows is inconsistent with the order in which another command does this, a deadlock can occur.
Although such a situation is unlikely, it can still occur. To reproduce it, we will create an index on the
To be able to watch what happens, let's create a function that increases the passed value, but very-very slowly, for as long as an entire second:
We will also need the
The first UPDATE command will update the entire table. The execution plan is evident — it is sequential scan:
Since tuples on the table page are located in ascending order of the amount (exactly how we added them), they will also be updated in the same order. Let the update start.
At the same time, in another session we'll forbid sequential scans:
In this case, for the next UPDATE operator, the planner decides to use index scan:
The second and third rows meet the condition, and since the index is built in descending order of the amount, the rows will be updated in a reverse order.
Let's run the next update.
A quick look into the table page shows that the first operator already managed to update the first row (0,1) and the second operator updated the last row (0,3):
One more second elapses. The first operator updated the second row, and the second one would like to do the same, but cannot.
Now the first operator would like to update the last table row, but it is already locked by the second operator. Hence a deadlock.
One of the transactions aborts:
And the second one continues:
This completes a talk on deadlocks, and we proceed to the remaining object-level locks.

When we need to lock a resource that is not a relation in the meaning of PostgreSQL, locks of the
Illustrating this by a simple example. Let's start a transaction and create a table in it:
Now let's see what locks of the
To figure out what in particular is locked here, we need to look at three fields:
We work as
Now let's clarify the second line. The database is specified, and it is
This shows that the
So, we've seen that when an object is created, the owner role and schema in which the object is created get locked (in a shared mode). And this is reasonable: otherwise, someone could drop the role or schema while the transaction is not completed yet.
When the number of rows in a relation (table, index or materialized view) increases, PostgreSQL can use free space in available pages for inserts, but evidently, once new pages also have to be added. Physically they are added at the end of the appropriate file. And this is meant by a relation extension.
To ensure that two processes do not rush to add pages simultaneously, the extension process is protected by a specialized lock of the
This lock is certainly released without waiting for completion of the transaction.
Page-level locks of the
GIN indexes enable us to accelerate search in compound values, for instance: words in text documents (or array elements). To a first approximation, these indexes can be represented as a regular B-tree that stores separate words from the documents rather than the documents themselves. Therefore, when a new document is added, the index has to be rebuilt pretty much in order to add there each new word from the document.
For better performance, GIN index has a postponed insert feature, which is turned on by the
To prevent moving from the pending list to the main index by several processes simultaneously, for the duration of moving, the index metapage gets locked in an exclusive mode. This does not hinder regular use of the index.
Unlike other locks (such as relation-level locks), advisory locks are never acquired automatically — the application developer controls them. They are useful when, for instance, an application for some reason needs a locking logic that is not in line with the standard logic of regular locks.
Assume we have a hypothetical resource that does not match any database object (which we could lock using commands such as SELECT FOR or LOCK TABLE). We need to devise a numeric identifier for it. If a resource has a unique name, a simple option is to use its hash code:
This is how we have the lock acquired:
As usual, information on locks is available in
For locking to be really effective, other processes must also acquire a lock on the resource prior to accessing it. Evidently the application must ensure that this rule is observed.
In the above example, the lock will be held through the end of the session rather than the transaction, as usual.
And we need to explicitly release it:
A rich collection of functions to work with advisory locks is available for all intents and purposes:
A collection of
The predicate lock term occurred long ago, when early DBMS made first attempts to implement complete isolation based on locks (the Serializable level, although there was no SQL standard at that time). The issue they confronted then was that even locking of all read and updated rows did not ensure complete isolation: new rows that meet the same selection conditions can occur in the table, which causes phantoms to arise (see the article on isolation).
The idea of predicate locks was to lock predicates rather than rows. If during execution of a query with the condition a > 10 we lock the a > 10 predicate, this won't allow us to add new rows that meet the condition to the table and will enable us to avoid phantoms. The issue is that this problem is computationally complicated; in practice, it can be solved only for very simple predicates.
In PostgreSQL, the Serializable level is implemented differently, on top of the available isolation based on data snapshots. Although the predicate lock term is still used, its meaning drastically changed. Actually these «locks» block nothing; they are used to track data dependencies between transactions.
It is proved that snapshot isolation permits an inconsistent write (write skew) anomaly and a read-only transaction anomaly, but any other anomalies are impossible. To figure out that we deal with one of the two above anomalies, we can analyze dependencies between transactions and discover certain patterns there.
Dependencies of two kinds are of interest to us:
We can track WR dependencies using already available regular locks, but RW dependencies have to be tracked specially.
To reiterate, despite the name, predicate locks bock nothing. A check is performed at the transaction commit instead, and if a suspicious sequence of dependencies that may indicate an anomaly is discovered, the transaction aborts.
Let's look at how predicate locks are handled. To do this, we'll create a table with a pretty large number of locks and an index on it.
If a query is executed using sequential scan of the entire table, a predicate lock on the entire table gets acquired (even if not all rows meet the filtering condition).
All predicate locks are acquired in one special mode — SIReadLock (Serializable Isolation Read):
But if a query is executed using index scan, the situation changes for the better. If we deal with a B-tree, it is sufficient to have a lock acquired on the rows read and on the leaf index pages walked through — this allows us to track not only specific values, but all the range read.
Note a few complexities.
First, a separate lock is created for each read tuple, and the number of such tuples can potentially be very large. The total number of predicate locks in the system is limited by the product of parameter values: max_pred_locks_per_transaction ? max_connections (the default values are 64 and 100, respectively). The memory for these locks is allocated at the server start; an attempt to exceed this limit will result in errors.
Therefore, escalation is used for predicate locks (and only for them!). Prior to PostgreSQL 10, the limitations were hard coded, but starting this version, we can control the escalation through parameters. If the number of tuple locks related to one page exceeds max_pred_locks_per_page, these locks are replaced with one page-level lock. Consider an example:
We see one lock of the
Likewise, if the number of locks on pages related to one relation exceeds max_pred_locks_per_relation, these locks are replaced with one relation-level lock.
There are no other levels: predicate locks are acquired only for relations, pages and tuples and always in the SIReadLock mode.
Certainly, escalation of locks inevitably results in an increase of the number of transactions that falsely terminate with a serialization error, and eventually, the system throuthput will decrease. Here you need to balance RAM consumption and performance.
The second complexity is that different operations with an index (for instance, due to splits of index pages when new rows are inserted) change the number of leaf pages that cover the range read. But the implementation takes this into account:
By the way, predicate locks are not always released immediately on completion of the transaction since they are needed to track dependencies between several transactions. But anyway, they are controlled automatically.
By no means all types of indexes in PostgreSQL support predicate locks. Before PostgreSQL 11, only B-trees could boast of this, but that version improved the situation: hash, GiST and GIN indexes were added to the list. If index access is used, but the index does not support predicate locks, a lock on the entire index is acquired. This, certainly, also increases the number of false aborts of transactions.
Finally, note that it's the use of predicate locks that limits all transactions to working at the Serializable level in order to ensure complete isolation. If a certain transaction uses a different level, it just won't acquire (and check) predicate locks.
To be continued.
We have a hodgepodge this time. We'll start with deadlocks (actually, I planned to discuss them last time, but that article was excessively long in itself), then briefly review object-level locks left and finally discuss predicate locks.
Deadlocks
When using locks, we can confront a deadlock. It occurs when one transaction tries to acquire a resource that is already in use by another transaction, while the second transaction tries to acquire a resource that is in use by the first. The figure on the left below illustrates this: solid-line arrows indicate acquired resources, while dashed-line arrows show attempts to acquire a resource that is already in use.
To visualize a deadlock, it is convenient to build the wait-for graph. To do this, we remove specific resources, leave only transactions and indicate which transaction waits for which other. If a graph contains a cycle (from a vertex, we can get to itself in a walk along arrows), this is a deadlock.
A deadlock can certainly occur not only for two transactions, but for any larger number of them.
If a deadlock occured, the involved transactions can do nothing but wait infinitely. Therefore, all DBMS, including PostgreSQL, track locks automatically.
The check, however, requires a certain effort, and it's undesirable to make it each time a new lock is requested (deadlocks are pretty infrequent after all). So, when a process tries to acquire a lock, but cannot, it queues and «falls asleep», but sets the timer to the value specified in the deadlock_timeout parameter (1 second by default). If the resource gets free earlier, this is fine and we skimp on the check. But if on expiration of deadlock_timeout, the wait continues, the waiting process will wake up and initiate the check.
If the check (which consists in building the wait-for graph and searching it for cycles) does not detect deadlocks, it continues sleeping, this time «until final victory».
Earlier, I was fairly reproached in the comments for not mentioning the lock_timeout parameter, which affects any operator and allows avoiding an infinitely long wait: if a lock cannot be acquired during the time specified, the operator terminates with alock_not_availableerror. Do not confuse this parameter with statement_timeout, which limits the total time to execute the operator, no matter whether the latter waits for a lock or does a regular work.
But if a deadlock is detected, one of the transactions (in most cases, the one that initiated the check) is forced to abort. This releases the locks it acquired and enables other transactions to continue.
Deadlocks usually mean that the application is designed incorrectly. There are two ways to detect such situations: first, messages will occur in the server log and second, the value of
pg_stat_database.deadlocks will increase.Example of deadlocking
Usually deadlocks are caused by an inconsistent order of locking table rows.
Let's consider a simple example. The first transaction is going to transfer 100 rubles from the first account to the second one. To this end, the transaction reduces the first account:
=> BEGIN;
=> UPDATE accounts SET amount = amount - 100.00 WHERE acc_no = 1;
UPDATE 1
At the same time, the second transaction is going to transfer 10 rubles from the second account to the first one. And it starts with reducing the second account:
| => BEGIN;
| => UPDATE accounts SET amount = amount - 10.00 WHERE acc_no = 2;
| UPDATE 1
Now the first transaction tries to increase the second account, but detects a lock on the row.
=> UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 2;
Then the second transaction tries to increase the first account, but also gets blocked.
| => UPDATE accounts SET amount = amount + 10.00 WHERE acc_no = 1;
So a circular wait arises, which won't end on its own. In a second, the first transaction, which cannot access the resource yet, initiates a check for a deadlock and is forced to abort by the server.
ERROR: deadlock detected
DETAIL: Process 16477 waits for ShareLock on transaction 530695; blocked by process 16513.
Process 16513 waits for ShareLock on transaction 530694; blocked by process 16477.
HINT: See server log for query details.
CONTEXT: while updating tuple (0,2) in relation "accounts"
Now the second transaction can continue.
| UPDATE 1
| => ROLLBACK;
=> ROLLBACK;
The correct way to perform such operations is to lock resources in the same order. For example: in this case, accounts can be locked in ascending order of their numbers.
Deadlock of two UPDATE commands
Sometimes we can get a deadlock in situations where, seemingly, it could never occur. For example: it is convenient and usual to treat SQL commands as atomic, but the UPDATE command locks rows as they are updated. This does not happen instantaneously. Therefore, if the order in which a command updates rows is inconsistent with the order in which another command does this, a deadlock can occur.
Although such a situation is unlikely, it can still occur. To reproduce it, we will create an index on the
amount column in descending order of amount:=> CREATE INDEX ON accounts(amount DESC);
To be able to watch what happens, let's create a function that increases the passed value, but very-very slowly, for as long as an entire second:
=> CREATE FUNCTION inc_slow(n numeric) RETURNS numeric AS $$
SELECT pg_sleep(1);
SELECT n + 100.00;
$$ LANGUAGE SQL;
We will also need the
pgrowlocks extension.=> CREATE EXTENSION pgrowlocks;
The first UPDATE command will update the entire table. The execution plan is evident — it is sequential scan:
| => EXPLAIN (costs off)
| UPDATE accounts SET amount = inc_slow(amount);
| QUERY PLAN
| ----------------------------
| Update on accounts
| -> Seq Scan on accounts
| (2 rows)
Since tuples on the table page are located in ascending order of the amount (exactly how we added them), they will also be updated in the same order. Let the update start.
| => UPDATE accounts SET amount = inc_slow(amount);
At the same time, in another session we'll forbid sequential scans:
|| => SET enable_seqscan = off;
In this case, for the next UPDATE operator, the planner decides to use index scan:
|| => EXPLAIN (costs off)
|| UPDATE accounts SET amount = inc_slow(amount) WHERE amount > 100.00;
|| QUERY PLAN
|| --------------------------------------------------------
|| Update on accounts
|| -> Index Scan using accounts_amount_idx on accounts
|| Index Cond: (amount > 100.00)
|| (3 rows)
The second and third rows meet the condition, and since the index is built in descending order of the amount, the rows will be updated in a reverse order.
Let's run the next update.
|| => UPDATE accounts SET amount = inc_slow(amount) WHERE amount > 100.00;
A quick look into the table page shows that the first operator already managed to update the first row (0,1) and the second operator updated the last row (0,3):
=> SELECT * FROM pgrowlocks('accounts') \gx
-[ RECORD 1 ]-----------------
locked_row | (0,1)
locker | 530699 <- the first
multi | f
xids | {530699}
modes | {"No Key Update"}
pids | {16513}
-[ RECORD 2 ]-----------------
locked_row | (0,3)
locker | 530700 <- the second
multi | f
xids | {530700}
modes | {"No Key Update"}
pids | {16549}
One more second elapses. The first operator updated the second row, and the second one would like to do the same, but cannot.
=> SELECT * FROM pgrowlocks('accounts') \gx
-[ RECORD 1 ]-----------------
locked_row | (0,1)
locker | 530699 <- the first
multi | f
xids | {530699}
modes | {"No Key Update"}
pids | {16513}
-[ RECORD 2 ]-----------------
locked_row | (0,2)
locker | 530699 <- the first was quicker
multi | f
xids | {530699}
modes | {"No Key Update"}
pids | {16513}
-[ RECORD 3 ]-----------------
locked_row | (0,3)
locker | 530700 <- the second
multi | f
xids | {530700}
modes | {"No Key Update"}
pids | {16549}
Now the first operator would like to update the last table row, but it is already locked by the second operator. Hence a deadlock.
One of the transactions aborts:
|| ERROR: deadlock detected
|| DETAIL: Process 16549 waits for ShareLock on transaction 530699; blocked by process 16513.
|| Process 16513 waits for ShareLock on transaction 530700; blocked by process 16549.
|| HINT: See server log for query details.
|| CONTEXT: while updating tuple (0,2) in relation "accounts"
And the second one continues:
| UPDATE 3
Engaging details of detecting and preventing deadlocks can be found in the lock manager README.
This completes a talk on deadlocks, and we proceed to the remaining object-level locks.
Locks on non-relations
When we need to lock a resource that is not a relation in the meaning of PostgreSQL, locks of the
object type are used. Almost whatever we can think of can refer to such resources: tablespaces, subscriptions, schemas, enumerated data types and so on. Roughly, this is everything that can be found in the system catalog.Illustrating this by a simple example. Let's start a transaction and create a table in it:
=> BEGIN;
=> CREATE TABLE example(n integer);
Now let's see what locks of the
object type appeared in pg_locks:=> SELECT
database,
(SELECT datname FROM pg_database WHERE oid = l.database) AS dbname,
classid,
(SELECT relname FROM pg_class WHERE oid = l.classid) AS classname,
objid,
mode,
granted
FROM pg_locks l
WHERE l.locktype = 'object' AND l.pid = pg_backend_pid();
database | dbname | classid | classname | objid | mode | granted
----------+--------+---------+--------------+-------+-----------------+---------
0 | | 1260 | pg_authid | 16384 | AccessShareLock | t
16386 | test | 2615 | pg_namespace | 2200 | AccessShareLock | t
(2 rows)
To figure out what in particular is locked here, we need to look at three fields:
database, classid and objid. We start with the first line.database is the OID of the database that the resource being locked relates to. In this case, this column contains zero. It means that we deal with a global object, which is not specific to any database.classid contains the OID from pg_class that matches the name of the system catalog table that actually determines the resource type. In this case, it is pg_authid, that is, a role (user) is the resource.objid contains the OID from the system catalog table indicated by classid.=> SELECT rolname FROM pg_authid WHERE oid = 16384;
rolname
---------
student
(1 row)
We work as
student, and this is exactly the role locked.Now let's clarify the second line. The database is specified, and it is
test, to which we are connected.classid indicates the pg_namespace table, which contains schemas.=> SELECT nspname FROM pg_namespace WHERE oid = 2200;
nspname
---------
public
(1 row)
This shows that the
public schema is locked.So, we've seen that when an object is created, the owner role and schema in which the object is created get locked (in a shared mode). And this is reasonable: otherwise, someone could drop the role or schema while the transaction is not completed yet.
=> ROLLBACK;
Lock on relation extension
When the number of rows in a relation (table, index or materialized view) increases, PostgreSQL can use free space in available pages for inserts, but evidently, once new pages also have to be added. Physically they are added at the end of the appropriate file. And this is meant by a relation extension.
To ensure that two processes do not rush to add pages simultaneously, the extension process is protected by a specialized lock of the
extend type. The same lock is used when vacuuming indexes for other processes to be unable to add pages during the scan.This lock is certainly released without waiting for completion of the transaction.
Earlier, tables could extend only by one page at a time. This caused issues during simultaneous row inserts by several processes; therefore, starting with PostgreSQL 9.6, several pages are added to tables at once (in proportion to the number of waiting processes, but not greater than 512).
Page lock
Page-level locks of the
page type are used in the only case (aside from predicate locks, to be discussed later).GIN indexes enable us to accelerate search in compound values, for instance: words in text documents (or array elements). To a first approximation, these indexes can be represented as a regular B-tree that stores separate words from the documents rather than the documents themselves. Therefore, when a new document is added, the index has to be rebuilt pretty much in order to add there each new word from the document.
For better performance, GIN index has a postponed insert feature, which is turned on by the
fastupdate storage parameter. New words are quickly added to an unordered pending list first, and after a while, everything accumulated is moved to the main index structure. The gains are due to a high probability of occurrence of the same words in different documents.To prevent moving from the pending list to the main index by several processes simultaneously, for the duration of moving, the index metapage gets locked in an exclusive mode. This does not hinder regular use of the index.
Advisory locks
Unlike other locks (such as relation-level locks), advisory locks are never acquired automatically — the application developer controls them. They are useful when, for instance, an application for some reason needs a locking logic that is not in line with the standard logic of regular locks.
Assume we have a hypothetical resource that does not match any database object (which we could lock using commands such as SELECT FOR or LOCK TABLE). We need to devise a numeric identifier for it. If a resource has a unique name, a simple option is to use its hash code:
=> SELECT hashtext('resource1');
hashtext
-----------
991601810
(1 row)
This is how we have the lock acquired:
=> BEGIN;
=> SELECT pg_advisory_lock(hashtext('resource1'));
As usual, information on locks is available in
pg_locks:=> SELECT locktype, objid, mode, granted
FROM pg_locks WHERE locktype = 'advisory' AND pid = pg_backend_pid();
locktype | objid | mode | granted
----------+-----------+---------------+---------
advisory | 991601810 | ExclusiveLock | t
(1 row)
For locking to be really effective, other processes must also acquire a lock on the resource prior to accessing it. Evidently the application must ensure that this rule is observed.
In the above example, the lock will be held through the end of the session rather than the transaction, as usual.
=> COMMIT;
=> SELECT locktype, objid, mode, granted
FROM pg_locks WHERE locktype = 'advisory' AND pid = pg_backend_pid();
locktype | objid | mode | granted
----------+-----------+---------------+---------
advisory | 991601810 | ExclusiveLock | t
(1 row)
And we need to explicitly release it:
=> SELECT pg_advisory_unlock(hashtext('resource1'));
A rich collection of functions to work with advisory locks is available for all intents and purposes:
pg_advisory_lock_sharedhas a shared lock acquired.pg_advisory_xact_lock(andpg_advisory_xact_lock_shared) has a shared lock acquired up to the end of the transaction.pg_try_advisory_lock(as well aspg_try_advisory_xact_lockandpg_try_advisory_xact_lock_shared) does not wait for a lock, but returnsfalseif a lock could not be acquired immediately.
A collection of
try_ functions is one more technique to avoid waiting for a lock, in addition to those listed in the last article.Predicate locks
The predicate lock term occurred long ago, when early DBMS made first attempts to implement complete isolation based on locks (the Serializable level, although there was no SQL standard at that time). The issue they confronted then was that even locking of all read and updated rows did not ensure complete isolation: new rows that meet the same selection conditions can occur in the table, which causes phantoms to arise (see the article on isolation).
The idea of predicate locks was to lock predicates rather than rows. If during execution of a query with the condition a > 10 we lock the a > 10 predicate, this won't allow us to add new rows that meet the condition to the table and will enable us to avoid phantoms. The issue is that this problem is computationally complicated; in practice, it can be solved only for very simple predicates.
In PostgreSQL, the Serializable level is implemented differently, on top of the available isolation based on data snapshots. Although the predicate lock term is still used, its meaning drastically changed. Actually these «locks» block nothing; they are used to track data dependencies between transactions.
It is proved that snapshot isolation permits an inconsistent write (write skew) anomaly and a read-only transaction anomaly, but any other anomalies are impossible. To figure out that we deal with one of the two above anomalies, we can analyze dependencies between transactions and discover certain patterns there.
Dependencies of two kinds are of interest to us:
- One transaction reads a row that is then updated by the second transaction (RW dependency).
- One transaction updates a row that is then read by the second transaction (WR dependency).
We can track WR dependencies using already available regular locks, but RW dependencies have to be tracked specially.
To reiterate, despite the name, predicate locks bock nothing. A check is performed at the transaction commit instead, and if a suspicious sequence of dependencies that may indicate an anomaly is discovered, the transaction aborts.
Let's look at how predicate locks are handled. To do this, we'll create a table with a pretty large number of locks and an index on it.
=> CREATE TABLE pred(n integer);
=> INSERT INTO pred(n) SELECT g.n FROM generate_series(1,10000) g(n);
=> CREATE INDEX ON pred(n) WITH (fillfactor = 10);
=> ANALYZE pred;
If a query is executed using sequential scan of the entire table, a predicate lock on the entire table gets acquired (even if not all rows meet the filtering condition).
| => SELECT pg_backend_pid();
| pg_backend_pid
| ----------------
| 12763
| (1 row)
| => BEGIN ISOLATION LEVEL SERIALIZABLE;
| => EXPLAIN (analyze, costs off)
| SELECT * FROM pred WHERE n > 100;
| QUERY PLAN
| ----------------------------------------------------------------
| Seq Scan on pred (actual time=0.047..12.709 rows=9900 loops=1)
| Filter: (n > 100)
| Rows Removed by Filter: 100
| Planning Time: 0.190 ms
| Execution Time: 15.244 ms
| (5 rows)
All predicate locks are acquired in one special mode — SIReadLock (Serializable Isolation Read):
=> SELECT locktype, relation::regclass, page, tuple
FROM pg_locks WHERE mode = 'SIReadLock' AND pid = 12763;
locktype | relation | page | tuple
----------+----------+------+-------
relation | pred | |
(1 row)
| => ROLLBACK;
But if a query is executed using index scan, the situation changes for the better. If we deal with a B-tree, it is sufficient to have a lock acquired on the rows read and on the leaf index pages walked through — this allows us to track not only specific values, but all the range read.
| => BEGIN ISOLATION LEVEL SERIALIZABLE;
| => EXPLAIN (analyze, costs off)
| SELECT * FROM pred WHERE n BETWEEN 1000 AND 1001;
| QUERY PLAN
| ------------------------------------------------------------------------------------
| Index Only Scan using pred_n_idx on pred (actual time=0.122..0.131 rows=2 loops=1)
| Index Cond: ((n >= 1000) AND (n <= 1001))
| Heap Fetches: 2
| Planning Time: 0.096 ms
| Execution Time: 0.153 ms
| (5 rows)
=> SELECT locktype, relation::regclass, page, tuple
FROM pg_locks WHERE mode = 'SIReadLock' AND pid = 12763;
locktype | relation | page | tuple
----------+------------+------+-------
tuple | pred | 3 | 236
tuple | pred | 3 | 235
page | pred_n_idx | 22 |
(3 rows)
Note a few complexities.
First, a separate lock is created for each read tuple, and the number of such tuples can potentially be very large. The total number of predicate locks in the system is limited by the product of parameter values: max_pred_locks_per_transaction ? max_connections (the default values are 64 and 100, respectively). The memory for these locks is allocated at the server start; an attempt to exceed this limit will result in errors.
Therefore, escalation is used for predicate locks (and only for them!). Prior to PostgreSQL 10, the limitations were hard coded, but starting this version, we can control the escalation through parameters. If the number of tuple locks related to one page exceeds max_pred_locks_per_page, these locks are replaced with one page-level lock. Consider an example:
=> SHOW max_pred_locks_per_page;
max_pred_locks_per_page
-------------------------
2
(1 row)
| => EXPLAIN (analyze, costs off)
| SELECT * FROM pred WHERE n BETWEEN 1000 AND 1002;
| QUERY PLAN
| ------------------------------------------------------------------------------------
| Index Only Scan using pred_n_idx on pred (actual time=0.019..0.039 rows=3 loops=1)
| Index Cond: ((n >= 1000) AND (n <= 1002))
| Heap Fetches: 3
| Planning Time: 0.069 ms
| Execution Time: 0.057 ms
| (5 rows)
We see one lock of the
page type instead of three locks of the tuple type:=> SELECT locktype, relation::regclass, page, tuple
FROM pg_locks WHERE mode = 'SIReadLock' AND pid = 12763;
locktype | relation | page | tuple
----------+------------+------+-------
page | pred | 3 |
page | pred_n_idx | 22 |
(2 rows)
Likewise, if the number of locks on pages related to one relation exceeds max_pred_locks_per_relation, these locks are replaced with one relation-level lock.
There are no other levels: predicate locks are acquired only for relations, pages and tuples and always in the SIReadLock mode.
Certainly, escalation of locks inevitably results in an increase of the number of transactions that falsely terminate with a serialization error, and eventually, the system throuthput will decrease. Here you need to balance RAM consumption and performance.
The second complexity is that different operations with an index (for instance, due to splits of index pages when new rows are inserted) change the number of leaf pages that cover the range read. But the implementation takes this into account:
=> INSERT INTO pred SELECT 1001 FROM generate_series(1,1000);
=> SELECT locktype, relation::regclass, page, tuple
FROM pg_locks WHERE mode = 'SIReadLock' AND pid = 12763;
locktype | relation | page | tuple
----------+------------+------+-------
page | pred | 3 |
page | pred_n_idx | 211 |
page | pred_n_idx | 212 |
page | pred_n_idx | 22 |
(4 rows)
| => ROLLBACK;
By the way, predicate locks are not always released immediately on completion of the transaction since they are needed to track dependencies between several transactions. But anyway, they are controlled automatically.
By no means all types of indexes in PostgreSQL support predicate locks. Before PostgreSQL 11, only B-trees could boast of this, but that version improved the situation: hash, GiST and GIN indexes were added to the list. If index access is used, but the index does not support predicate locks, a lock on the entire index is acquired. This, certainly, also increases the number of false aborts of transactions.
Finally, note that it's the use of predicate locks that limits all transactions to working at the Serializable level in order to ensure complete isolation. If a certain transaction uses a different level, it just won't acquire (and check) predicate locks.
Traditionally, providing you with a link to the predicate locking README, to start exploring the source code with.
To be continued.