
The previous series addressed isolation and multiversion concurrency control, and now we start a new series: on write-ahead logging. To remind you, the material is based on training courses on administration that Pavel pluzanov and I are creating (mostly in Russian, although one course is available in English), but does not repeat them verbatim and is intended for careful reading and self-experimenting.
This series will consist of four parts:
Part of the data that a DBMS works with is stored in RAM and gets written to disk (or other nonvolatile storage) asynchronously, i. e., writes are postponed for some time. The more infrequently this happens the less is the input/output and the faster the system operates.
But what will happen in case of failure, for example, power outage or an error in the code of the DBMS or operating system? All the contents of RAM will be lost, and only data written to disk will survive (disks are not immune to certain failures either, and only a backup copy can help if data on disk are affected). In general, it is possible to organize input/output in such a way that data on disk are always consistent, but this is complicated and not that much efficient (to my knowledge, only Firebird chose this option).
Usually, and specifically in PostgreSQL, data written to disk appear to be inconsistent, and when recovering after failure, special actions are required to restore data consistency. Write-ahead logging (WAL) is just a feature that makes it possible.
Oddly enough, we will start a talk on WAL with discussing the buffer cache. The buffer cache is not the only structure that is stored in RAM, but one of the most critical and complicated of them. Understanding how it works is important in itself; besides we will use it as an example in order to get acquainted with how RAM and disk exchange data.
Caching is used in modern computer systems everywhere; a processor alone has three or four levels of cache. In general cache is needed to alleviate the difference in the performances between two kinds of memory, of which one is relatively fast, but there is not enough of it to go round, and the other one is relatively slow, but there is quite enough of it. And the buffer cache alleviates the difference between the time of access to RAM (nanoseconds) and disk storage (milliseconds).
Note that the operating system also has the disk cache that solves the same problem. Therefore, database management systems usually try to avoid double caching by accessing disks directly rather than through the OS cache. But this is not the case with PostgreSQL: all data are read and written using normal file operations.
Besides, controllers of disk arrays and even disks themselves also have their own cache. This will come in useful when we reach a discussion of reliability.
But let's return to the DBMS buffer cache.
It is called like this because it is represented as an array of buffers. Each buffer consists of space for one data page (block) plus the header. The header, among the rest, contains:
The buffer cache is located in the shared memory of the server and is accessible to all processes. To work with data, that is, read or update them, the processes read pages into the cache. While the page is in the cache, we work with it in RAM and save on disk accesses.
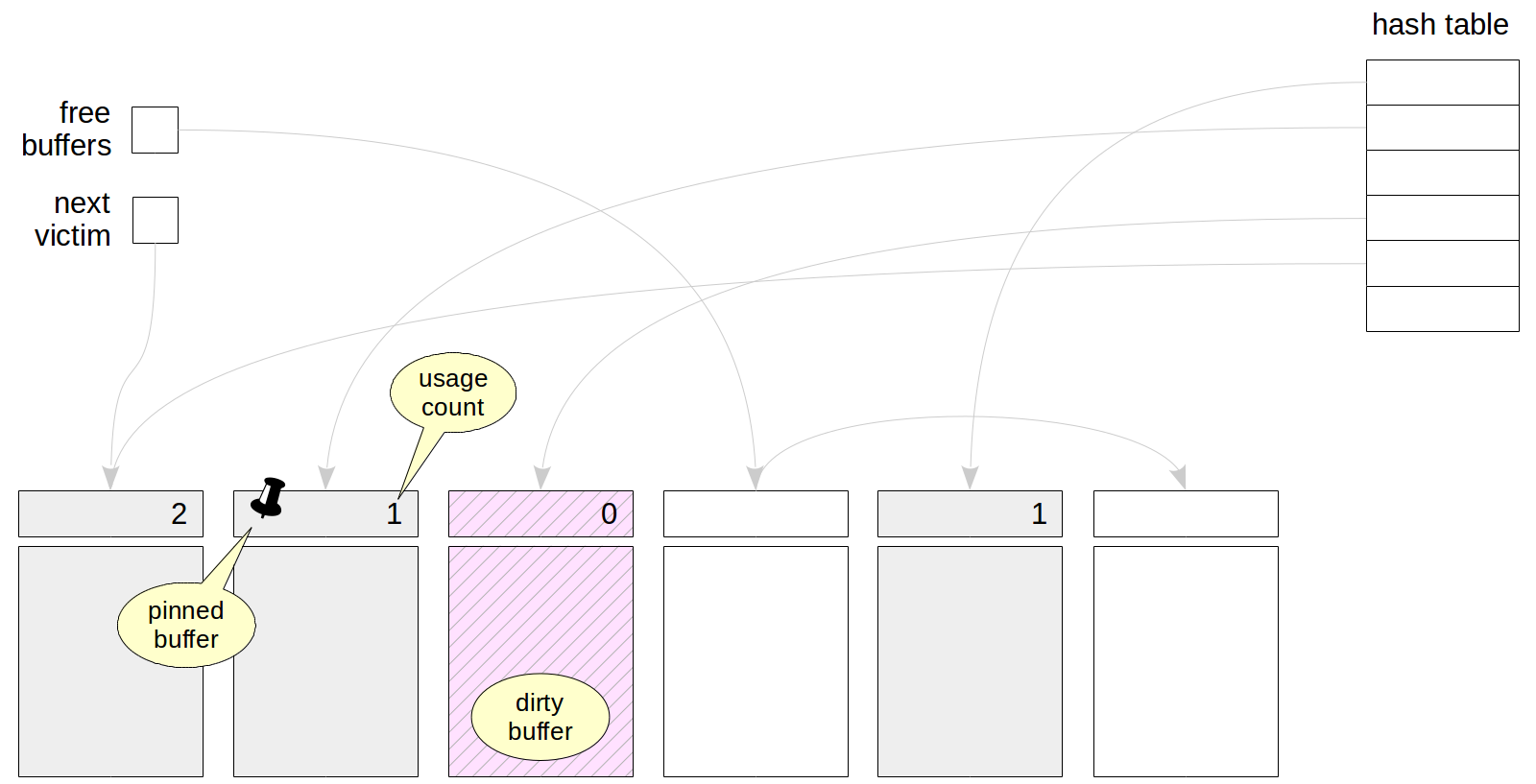
The cache initially contains empty buffers, and all of them are chained into the list of free buffers. The meaning of the pointer to the «next victim» will be clear a bit later. A hash table in the cache is used to quickly find there a page you need.
When a process needs to read a page, it first attempts to find it in the buffer cache by means of the hash table. The file number and the number of the page in the file are used as the hash key. The process finds the buffer number in the appropriate hash bucket and checks whether it really contains the page needed. Like with any hash table, collisions may arise here, in which case the process will have to check several pages.
If the page needed is found in the cache, the process must «pin» the buffer by incrementing the pin count (several processes can concurrently do this). While a buffer is pinned (the count value is greater than zero), it is considered to be used and to have contents that cannot «drastically» change. For example: a new tuple can appear on the page — this does no harm to anybody because of multiversion concurrency and visibility rules. But a different page cannot be read into the pinned buffer.
It may so happen that the page needed will not be found in the cache. In this case, the page will need to be read from disk into some buffer.
If empty buffers are still available in the cache, the first empty one is chosen. But they will be over sooner or later (the size of a database is usually larger than the memory allocated for the cache), and then we will have to choose one of the occupied buffers, evict the page located there and read the new one into the freed space.
The eviction technique is based on the fact that for each access to a buffer, processes increment the usage count in the buffer header. So the buffers that are used less often than the others have a smaller value of the count and are therefore good candidates for eviction.
The clock-sweep algorithm circularly goes through all buffers (using the pointer to the «next victim») and decreases their usage counts by one. The buffer that is selected for eviction is the first one that:
Note that if all buffers have a non-zero usage count, the algorithm will have to do more than one circle through the buffers, decreasing the values of counts until some of them is reduced to zero. For the algorithm to avoid «doing laps», the maximum value of the usage count is limited by 5. However, for a large-size buffer cache, this algorithm can cause considerable overhead costs.
Once the buffer is found, the following happens to it.
The buffer is pinned to show other processes that it is used. Other locking techniques are used, in addition to pinning, but we will discuss this in more detail later.
If the buffer appears to be dirty, that is, to contain changed data, the page cannot be just dropped — it needs to be saved to disk first. This is hardly a good situation since the process that is going to read the page has to wait until other processes' data are written, but this effect is alleviated by checkpoint and background writer processes, which will be discussed later.
Then the new page is read from disk into the selected buffer. The usage count is set equal to one. Besides, a reference to the loaded page must be written to the hash table in order to enable finding the page in future.
The reference to the «next victim» now points to the next buffer, and the just loaded buffer has time to increase the usage count until the pointer goes circularly through the entire buffer cache and is back again.
As usual, PostgreSQL has an extension that enables us to look inside the buffer cache.
Let's create a table and insert one row there.
What will the buffer cache contain? At a minimum, there must appear the page where the only row is added. Let's check this using the following query, which selects only buffers related to our table (by the
Just as we thought: the buffer contains one page. It is dirty (
Now let's add one more row and rerun the query. To save keystrokes, we insert the row in another session and rerun the long query using the
No new buffers were added: the second row fit on the same page. Pay attention to the increased usage count.
The count also increases after reading the page.
But what if we do vacuuming?
VACUUM created the visibility map (one-page) and the free space map (having three pages, which is the minimum size of such a map).
And so on.
We can set the cache size using the shared_buffers parameter. The default value is ridiculous 128 MB. This is one of the parameters that it makes sense to increase right after installing PostgreSQL.
Note that a change of this parameter requires server restart since all the memory for the cache is allocated when the server starts.
What do we need to consider to choose the appropriate value?
Even the largest database has a limited set of «hot» data, which are intensively processed all the time. Ideally, it's this data set that must fit in the buffer cache (plus some space for one-time data). If the cache size if less, then intensively used pages will be constantly evicting one another, which will cause excessive input/output. But blindly increasing the cache is no good either. When the cache is large, the overhead costs of its maintenance will grow, and besides, RAM is also required for other use.
So, you need to choose the optimal size of the buffer cache for your particular system: it depends on the data, application, and load. Unfortunately, there is no magic, one-size-fits-all value.
It is usually recommended to take 1/4 of RAM for the first approximation (PostgreSQL versions lower than 10 recommended a smaller size for Windows).
And then we should adapt to the situation. It's best to experiment: increase or reduce the cache size and compare the system characteristics. To this end, you, certainly, need a test rig and you should be able to reproduce the workload. — Experiments like these in a production environment are a dubious pleasure.
But you can get some information on what's happening directly on your live system by means of the same
For example: you can explore the distribution of buffers by their usage:
In this case, multiple empty values of the count correspond to empty buffers. This is hardly a surprise for a system where nothing is happening.
We can see what share of which tables in our database is cached and how intensively these data are used (by «intensively used», buffers with the usage count greater than 3 are meant in this query):
For example: we can see here that the
You can consider other viewpoints, which will provide you with food for thought. You only need to take into account that:
And there is one more point to note. Do not forget either that PostgreSQL works with files through usual OS calls and therefore, double caching takes place: pages get both into the buffer cache of the DBMS and the OS cache. So, not hitting the buffer cache does not always cause a need for actual input/output. But the eviction strategy of OS differs from that of the DBMS: the OS knows nothing about the meaning of the read data.
Bulk read and write operations are prone to the risk that useful pages can be fast evicted from the buffer cache by «one-time» data.
To avoid this, so called buffer rings are used: only a small part of the buffer cache is allocated for each operation. The eviction is carried out only within the ring, so the rest of the data in the buffer cache are not affected.
For sequential scans of large tables (whose size is greater than a quarter of the buffer cache), 32 pages are allocated. If during a scan of a table, another process also needs these data, it does not start reading the table from the beginning, but connects to the buffer ring already available. After finishing the scan, the process proceeds to reading the «missed» beginning of the table.
Let's check it. To do this, let's create a table so that one row occupies a whole page — this way it is more convenient to count. The default size of the buffer cache is 128 MB = 16384 pages of 8 KB. It means that we need to insert more than 4096 rows, that is, pages, into the table.
Let's analyze the table.
Now we will have to restart the server to clear the cache of the table data that the analysis has read.
Let's read the whole table after the restart:
And let's make sure that table pages occupy only 32 buffers in the buffer cache:
But if we forbid sequential scans, the table will be read using index scan:
In this case, no buffer ring is used and the entire table will get into the buffer cache (along with almost the entire index):
Buffer rings are used in a similar way for a vacuum process (also 32 pages) and for bulk write operations COPY IN and CREATE TABLE AS SELECT (usually 2048 pages, but not more than 1/8 of the buffer cache).
Temporary tables are an exception from the common rule. Since temporary data are visible to only one process, there's no need for them in the shared buffer cache. Moreover, temporary data exist only within one session and therefore do not need protection against failures.
Temporary data use the cache in the local memory of the process that owns the table. Since such data are available to only one process, they do not need to be protected with locks. The local cache uses the normal eviction algorithm.
Unlike for the shared buffer cache, memory for the local cache is allocated as the need arises since temporary tables are far from being used in many sessions. The maximum memory size for temporary tables in a single session is limited by the temp_buffers parameter.
After server restart, some time must elapse for the cache to «warm up», that is, get filled with live actively used data. It may sometimes appear useful to immediately read the contents of certain tables into the cache, and a specialized extension is available for this:
Earlier, the extension could only read certain tables into the buffer cache (or only into the OS cache). But PostgreSQL 11 enabled it to save the up-to-date state of the cache to disk and restore it after a server restart. To make use of it, you need to add the library to shared_preload_libraries and restart the server.
After the restart, if the value of the pg_prewarm.autoprewarm parameter did not change, the autoprewarm master background process will be launched, which will flush the list of pages stored in the cache once every pg_prewarm.autoprewarm_interval seconds (do not forget to count the new process in when setting the value of max_parallel_processes).
Now the cache does not contain the table
If we consider all its contents to be critical, we can read it into the buffer cache by calling the following function:
The list of blocks is flushed into the
The number of flushed pages already exceeds 4097; the pages of the system catalog that are already read by the server are counted in. And this is the file:
Now let's restart the server again.
Our table will again be in the cache after the server start.
That same autoprewarm master process provides for this: it reads the file, divides the pages by databases, sorts them (to make reading from disk sequential whenever possible) and passes them to a separate autoprewarm worker process for handling.
To be continued.
This series will consist of four parts:
- Buffer cache (this article).
- Write-ahead log — how it is structured and used to recover the data.
- Checkpoint and background writer — why we need them and how we set them up.
- WAL setup — levels and problems solved, reliability, and performance.
Many thanks to Elena Indrupskaya for the translation of these articles into English.
Why do we need write-ahead logging?
Part of the data that a DBMS works with is stored in RAM and gets written to disk (or other nonvolatile storage) asynchronously, i. e., writes are postponed for some time. The more infrequently this happens the less is the input/output and the faster the system operates.
But what will happen in case of failure, for example, power outage or an error in the code of the DBMS or operating system? All the contents of RAM will be lost, and only data written to disk will survive (disks are not immune to certain failures either, and only a backup copy can help if data on disk are affected). In general, it is possible to organize input/output in such a way that data on disk are always consistent, but this is complicated and not that much efficient (to my knowledge, only Firebird chose this option).
Usually, and specifically in PostgreSQL, data written to disk appear to be inconsistent, and when recovering after failure, special actions are required to restore data consistency. Write-ahead logging (WAL) is just a feature that makes it possible.
Buffer cache
Oddly enough, we will start a talk on WAL with discussing the buffer cache. The buffer cache is not the only structure that is stored in RAM, but one of the most critical and complicated of them. Understanding how it works is important in itself; besides we will use it as an example in order to get acquainted with how RAM and disk exchange data.
Caching is used in modern computer systems everywhere; a processor alone has three or four levels of cache. In general cache is needed to alleviate the difference in the performances between two kinds of memory, of which one is relatively fast, but there is not enough of it to go round, and the other one is relatively slow, but there is quite enough of it. And the buffer cache alleviates the difference between the time of access to RAM (nanoseconds) and disk storage (milliseconds).
Note that the operating system also has the disk cache that solves the same problem. Therefore, database management systems usually try to avoid double caching by accessing disks directly rather than through the OS cache. But this is not the case with PostgreSQL: all data are read and written using normal file operations.
Besides, controllers of disk arrays and even disks themselves also have their own cache. This will come in useful when we reach a discussion of reliability.
But let's return to the DBMS buffer cache.
It is called like this because it is represented as an array of buffers. Each buffer consists of space for one data page (block) plus the header. The header, among the rest, contains:
- The location of the page in the buffer (the file and block number there).
- The indicator of a change to the data on the page, which will sooner or later need to be written to disk (such a buffer is called dirty).
- The usage count of the buffer.
- The pin count of the buffer.
The buffer cache is located in the shared memory of the server and is accessible to all processes. To work with data, that is, read or update them, the processes read pages into the cache. While the page is in the cache, we work with it in RAM and save on disk accesses.
The cache initially contains empty buffers, and all of them are chained into the list of free buffers. The meaning of the pointer to the «next victim» will be clear a bit later. A hash table in the cache is used to quickly find there a page you need.
Search for a page in the cache
When a process needs to read a page, it first attempts to find it in the buffer cache by means of the hash table. The file number and the number of the page in the file are used as the hash key. The process finds the buffer number in the appropriate hash bucket and checks whether it really contains the page needed. Like with any hash table, collisions may arise here, in which case the process will have to check several pages.
Usage of hash tables has long been a source of complaint. A structure like this enables to quickly find a buffer by a page, but a hash table is absolutely useless if, for instance, you need to find all buffers occupied by a certain table. But nobody has suggested a good replacement yet.
If the page needed is found in the cache, the process must «pin» the buffer by incrementing the pin count (several processes can concurrently do this). While a buffer is pinned (the count value is greater than zero), it is considered to be used and to have contents that cannot «drastically» change. For example: a new tuple can appear on the page — this does no harm to anybody because of multiversion concurrency and visibility rules. But a different page cannot be read into the pinned buffer.
Eviction
It may so happen that the page needed will not be found in the cache. In this case, the page will need to be read from disk into some buffer.
If empty buffers are still available in the cache, the first empty one is chosen. But they will be over sooner or later (the size of a database is usually larger than the memory allocated for the cache), and then we will have to choose one of the occupied buffers, evict the page located there and read the new one into the freed space.
The eviction technique is based on the fact that for each access to a buffer, processes increment the usage count in the buffer header. So the buffers that are used less often than the others have a smaller value of the count and are therefore good candidates for eviction.
The clock-sweep algorithm circularly goes through all buffers (using the pointer to the «next victim») and decreases their usage counts by one. The buffer that is selected for eviction is the first one that:
- has a zero usage count
- has a zero pin count (i. e. is not pinned)
Note that if all buffers have a non-zero usage count, the algorithm will have to do more than one circle through the buffers, decreasing the values of counts until some of them is reduced to zero. For the algorithm to avoid «doing laps», the maximum value of the usage count is limited by 5. However, for a large-size buffer cache, this algorithm can cause considerable overhead costs.
Once the buffer is found, the following happens to it.
The buffer is pinned to show other processes that it is used. Other locking techniques are used, in addition to pinning, but we will discuss this in more detail later.
If the buffer appears to be dirty, that is, to contain changed data, the page cannot be just dropped — it needs to be saved to disk first. This is hardly a good situation since the process that is going to read the page has to wait until other processes' data are written, but this effect is alleviated by checkpoint and background writer processes, which will be discussed later.
Then the new page is read from disk into the selected buffer. The usage count is set equal to one. Besides, a reference to the loaded page must be written to the hash table in order to enable finding the page in future.
The reference to the «next victim» now points to the next buffer, and the just loaded buffer has time to increase the usage count until the pointer goes circularly through the entire buffer cache and is back again.
See it for yourself
As usual, PostgreSQL has an extension that enables us to look inside the buffer cache.
=> CREATE EXTENSION pg_buffercache;
Let's create a table and insert one row there.
=> CREATE TABLE cacheme(
id integer
) WITH (autovacuum_enabled = off);
=> INSERT INTO cacheme VALUES (1);
What will the buffer cache contain? At a minimum, there must appear the page where the only row is added. Let's check this using the following query, which selects only buffers related to our table (by the
relfilenode number) and interprets relforknumber:=> SELECT bufferid,
CASE relforknumber
WHEN 0 THEN 'main'
WHEN 1 THEN 'fsm'
WHEN 2 THEN 'vm'
END relfork,
relblocknumber,
isdirty,
usagecount,
pinning_backends
FROM pg_buffercache
WHERE relfilenode = pg_relation_filenode('cacheme'::regclass);
bufferid | relfork | relblocknumber | isdirty | usagecount | pinning_backends
----------+---------+----------------+---------+------------+------------------
15735 | main | 0 | t | 1 | 0
(1 row)
Just as we thought: the buffer contains one page. It is dirty (
isdirty), the usage count (usagecount) equals one, and the page is not pinned by any process (pinning_backends).Now let's add one more row and rerun the query. To save keystrokes, we insert the row in another session and rerun the long query using the
\g command.| => INSERT INTO cacheme VALUES (2);
=> \g
bufferid | relfork | relblocknumber | isdirty | usagecount | pinning_backends
----------+---------+----------------+---------+------------+------------------
15735 | main | 0 | t | 2 | 0
(1 row)
No new buffers were added: the second row fit on the same page. Pay attention to the increased usage count.
| => SELECT * FROM cacheme;
| id
| ----
| 1
| 2
| (2 rows)
=> \g
bufferid | relfork | relblocknumber | isdirty | usagecount | pinning_backends
----------+---------+----------------+---------+------------+------------------
15735 | main | 0 | t | 3 | 0
(1 row)
The count also increases after reading the page.
But what if we do vacuuming?
| => VACUUM cacheme;
=> \g
bufferid | relfork | relblocknumber | isdirty | usagecount | pinning_backends
----------+---------+----------------+---------+------------+------------------
15731 | fsm | 1 | t | 1 | 0
15732 | fsm | 0 | t | 1 | 0
15733 | fsm | 2 | t | 2 | 0
15734 | vm | 0 | t | 2 | 0
15735 | main | 0 | t | 3 | 0
(5 rows)
VACUUM created the visibility map (one-page) and the free space map (having three pages, which is the minimum size of such a map).
And so on.
Tuning the size
We can set the cache size using the shared_buffers parameter. The default value is ridiculous 128 MB. This is one of the parameters that it makes sense to increase right after installing PostgreSQL.
=> SELECT setting, unit FROM pg_settings WHERE name = 'shared_buffers';
setting | unit
---------+------
16384 | 8kB
(1 row)
Note that a change of this parameter requires server restart since all the memory for the cache is allocated when the server starts.
What do we need to consider to choose the appropriate value?
Even the largest database has a limited set of «hot» data, which are intensively processed all the time. Ideally, it's this data set that must fit in the buffer cache (plus some space for one-time data). If the cache size if less, then intensively used pages will be constantly evicting one another, which will cause excessive input/output. But blindly increasing the cache is no good either. When the cache is large, the overhead costs of its maintenance will grow, and besides, RAM is also required for other use.
So, you need to choose the optimal size of the buffer cache for your particular system: it depends on the data, application, and load. Unfortunately, there is no magic, one-size-fits-all value.
It is usually recommended to take 1/4 of RAM for the first approximation (PostgreSQL versions lower than 10 recommended a smaller size for Windows).
And then we should adapt to the situation. It's best to experiment: increase or reduce the cache size and compare the system characteristics. To this end, you, certainly, need a test rig and you should be able to reproduce the workload. — Experiments like these in a production environment are a dubious pleasure.
Be sure to look into Nikolay Samokhvalov's presentation at PostgresConf Silicon Valley 2018: The Art of Database Experiments.
But you can get some information on what's happening directly on your live system by means of the same
pg_buffercache extension. The main thing is to look from the right perspective.For example: you can explore the distribution of buffers by their usage:
=> SELECT usagecount, count(*)
FROM pg_buffercache
GROUP BY usagecount
ORDER BY usagecount;
usagecount | count
------------+-------
1 | 221
2 | 869
3 | 29
4 | 12
5 | 564
| 14689
(6 rows)
In this case, multiple empty values of the count correspond to empty buffers. This is hardly a surprise for a system where nothing is happening.
We can see what share of which tables in our database is cached and how intensively these data are used (by «intensively used», buffers with the usage count greater than 3 are meant in this query):
=> SELECT c.relname,
count(*) blocks,
round( 100.0 * 8192 * count(*) / pg_table_size(c.oid) ) "% of rel",
round( 100.0 * 8192 * count(*) FILTER (WHERE b.usagecount > 3) / pg_table_size(c.oid) ) "% hot"
FROM pg_buffercache b
JOIN pg_class c ON pg_relation_filenode(c.oid) = b.relfilenode
WHERE b.reldatabase IN (
0, (SELECT oid FROM pg_database WHERE datname = current_database())
)
AND b.usagecount is not null
GROUP BY c.relname, c.oid
ORDER BY 2 DESC
LIMIT 10;
relname | blocks | % of rel | % hot
---------------------------+--------+----------+-------
vac | 833 | 100 | 0
pg_proc | 71 | 85 | 37
pg_depend | 57 | 98 | 19
pg_attribute | 55 | 100 | 64
vac_s | 32 | 4 | 0
pg_statistic | 27 | 71 | 63
autovac | 22 | 100 | 95
pg_depend_reference_index | 19 | 48 | 35
pg_rewrite | 17 | 23 | 8
pg_class | 16 | 100 | 100
(10 rows)
For example: we can see here that the
vac table occupies most space (we used this table in one of the previous topics), but it has not been accessed long and it is not evicted yet only because empty buffers are still available.You can consider other viewpoints, which will provide you with food for thought. You only need to take into account that:
- You need to rerun such queries several times: the numbers will vary in a certain range.
- You should not continuously run such queries (as part of monitoring) since the extension momentarily blocks accesses to the buffer cache.
And there is one more point to note. Do not forget either that PostgreSQL works with files through usual OS calls and therefore, double caching takes place: pages get both into the buffer cache of the DBMS and the OS cache. So, not hitting the buffer cache does not always cause a need for actual input/output. But the eviction strategy of OS differs from that of the DBMS: the OS knows nothing about the meaning of the read data.
Massive eviction
Bulk read and write operations are prone to the risk that useful pages can be fast evicted from the buffer cache by «one-time» data.
To avoid this, so called buffer rings are used: only a small part of the buffer cache is allocated for each operation. The eviction is carried out only within the ring, so the rest of the data in the buffer cache are not affected.
For sequential scans of large tables (whose size is greater than a quarter of the buffer cache), 32 pages are allocated. If during a scan of a table, another process also needs these data, it does not start reading the table from the beginning, but connects to the buffer ring already available. After finishing the scan, the process proceeds to reading the «missed» beginning of the table.
Let's check it. To do this, let's create a table so that one row occupies a whole page — this way it is more convenient to count. The default size of the buffer cache is 128 MB = 16384 pages of 8 KB. It means that we need to insert more than 4096 rows, that is, pages, into the table.
=> CREATE TABLE big(
id integer PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
s char(1000)
) WITH (fillfactor=10);
=> INSERT INTO big(s) SELECT 'FOO' FROM generate_series(1,4096+1);
Let's analyze the table.
=> ANALYZE big;
=> SELECT relpages FROM pg_class WHERE oid = 'big'::regclass;
relpages
----------
4097
(1 row)
Now we will have to restart the server to clear the cache of the table data that the analysis has read.
student$ sudo pg_ctlcluster 11 main restart
Let's read the whole table after the restart:
=> EXPLAIN (ANALYZE, COSTS OFF) SELECT count(*) FROM big;
QUERY PLAN
---------------------------------------------------------------------
Aggregate (actual time=14.472..14.473 rows=1 loops=1)
-> Seq Scan on big (actual time=0.031..13.022 rows=4097 loops=1)
Planning Time: 0.528 ms
Execution Time: 14.590 ms
(4 rows)
And let's make sure that table pages occupy only 32 buffers in the buffer cache:
=> SELECT count(*)
FROM pg_buffercache
WHERE relfilenode = pg_relation_filenode('big'::regclass);
count
-------
32
(1 row)
But if we forbid sequential scans, the table will be read using index scan:
=> SET enable_seqscan = off;
=> EXPLAIN (ANALYZE, COSTS OFF) SELECT count(*) FROM big;
QUERY PLAN
-------------------------------------------------------------------------------------------
Aggregate (actual time=50.300..50.301 rows=1 loops=1)
-> Index Only Scan using big_pkey on big (actual time=0.098..48.547 rows=4097 loops=1)
Heap Fetches: 4097
Planning Time: 0.067 ms
Execution Time: 50.340 ms
(5 rows)
In this case, no buffer ring is used and the entire table will get into the buffer cache (along with almost the entire index):
=> SELECT count(*)
FROM pg_buffercache
WHERE relfilenode = pg_relation_filenode('big'::regclass);
count
-------
4097
(1 row)
Buffer rings are used in a similar way for a vacuum process (also 32 pages) and for bulk write operations COPY IN and CREATE TABLE AS SELECT (usually 2048 pages, but not more than 1/8 of the buffer cache).
Temporary tables
Temporary tables are an exception from the common rule. Since temporary data are visible to only one process, there's no need for them in the shared buffer cache. Moreover, temporary data exist only within one session and therefore do not need protection against failures.
Temporary data use the cache in the local memory of the process that owns the table. Since such data are available to only one process, they do not need to be protected with locks. The local cache uses the normal eviction algorithm.
Unlike for the shared buffer cache, memory for the local cache is allocated as the need arises since temporary tables are far from being used in many sessions. The maximum memory size for temporary tables in a single session is limited by the temp_buffers parameter.
Warming up the cache
After server restart, some time must elapse for the cache to «warm up», that is, get filled with live actively used data. It may sometimes appear useful to immediately read the contents of certain tables into the cache, and a specialized extension is available for this:
=> CREATE EXTENSION pg_prewarm;
Earlier, the extension could only read certain tables into the buffer cache (or only into the OS cache). But PostgreSQL 11 enabled it to save the up-to-date state of the cache to disk and restore it after a server restart. To make use of it, you need to add the library to shared_preload_libraries and restart the server.
=> ALTER SYSTEM SET shared_preload_libraries = 'pg_prewarm';
student$ sudo pg_ctlcluster 11 main restart
After the restart, if the value of the pg_prewarm.autoprewarm parameter did not change, the autoprewarm master background process will be launched, which will flush the list of pages stored in the cache once every pg_prewarm.autoprewarm_interval seconds (do not forget to count the new process in when setting the value of max_parallel_processes).
=> SELECT name, setting, unit FROM pg_settings WHERE name LIKE 'pg_prewarm%';
name | setting | unit
---------------------------------+---------+------
pg_prewarm.autoprewarm | on |
pg_prewarm.autoprewarm_interval | 300 | s
(2 rows)
postgres$ ps -o pid,command --ppid `head -n 1 /var/lib/postgresql/11/main/postmaster.pid` | grep prewarm
10436 postgres: 11/main: autoprewarm master
Now the cache does not contain the table
big:=> SELECT count(*)
FROM pg_buffercache
WHERE relfilenode = pg_relation_filenode('big'::regclass);
count
-------
0
(1 row)
If we consider all its contents to be critical, we can read it into the buffer cache by calling the following function:
=> SELECT pg_prewarm('big');
pg_prewarm
------------
4097
(1 row)
=> SELECT count(*)
FROM pg_buffercache
WHERE relfilenode = pg_relation_filenode('big'::regclass);
count
-------
4097
(1 row)
The list of blocks is flushed into the
autoprewarm.blocks file. To see the list, we can just wait until the autoprewarm master process completes for the first time, or we can initiate the flush manually like this:=> SELECT autoprewarm_dump_now();
autoprewarm_dump_now
----------------------
4340
(1 row)
The number of flushed pages already exceeds 4097; the pages of the system catalog that are already read by the server are counted in. And this is the file:
postgres$ ls -l /var/lib/postgresql/11/main/autoprewarm.blocks
-rw------- 1 postgres postgres 102078 jun 29 15:51 /var/lib/postgresql/11/main/autoprewarm.blocks
Now let's restart the server again.
student$ sudo pg_ctlcluster 11 main restart
Our table will again be in the cache after the server start.
=> SELECT count(*)
FROM pg_buffercache
WHERE relfilenode = pg_relation_filenode('big'::regclass);
count
-------
4097
(1 row)
That same autoprewarm master process provides for this: it reads the file, divides the pages by databases, sorts them (to make reading from disk sequential whenever possible) and passes them to a separate autoprewarm worker process for handling.
To be continued.