
We started with problems related to isolation, made a digression about low-level data structure, discussed row versions in detail and observed how data snapshots are obtained from row versions.
Then we covered different vacuuming techniques: in-page vacuum (along with HOT updates), vacuum and autovacuum.
Now we've reached the last topic of this series. We will talk on the transaction id wraparound and freezing.
PostgreSQL uses 32-bit transaction IDs. This is a pretty large number (about 4 billion), but with intensive work of the server, this number is not unlikely to get exhausted. For example: with the workload of 1000 transactions a second, this will happen as early as in one month and a half of continuous work.
But we've mentioned that multiversion concurrency control relies on the sequential numbering, which means that of two transactions the one with a smaller number can be considered to have started earlier. Therefore, it is clear that it is not an option to just reset the counter and start the numbering from scratch.
But why not use 64-bit transaction IDs — wouldn't it completely eliminate the issue? The thing is that the header of each tuple (as discussed earlier) stores two transaction IDs:
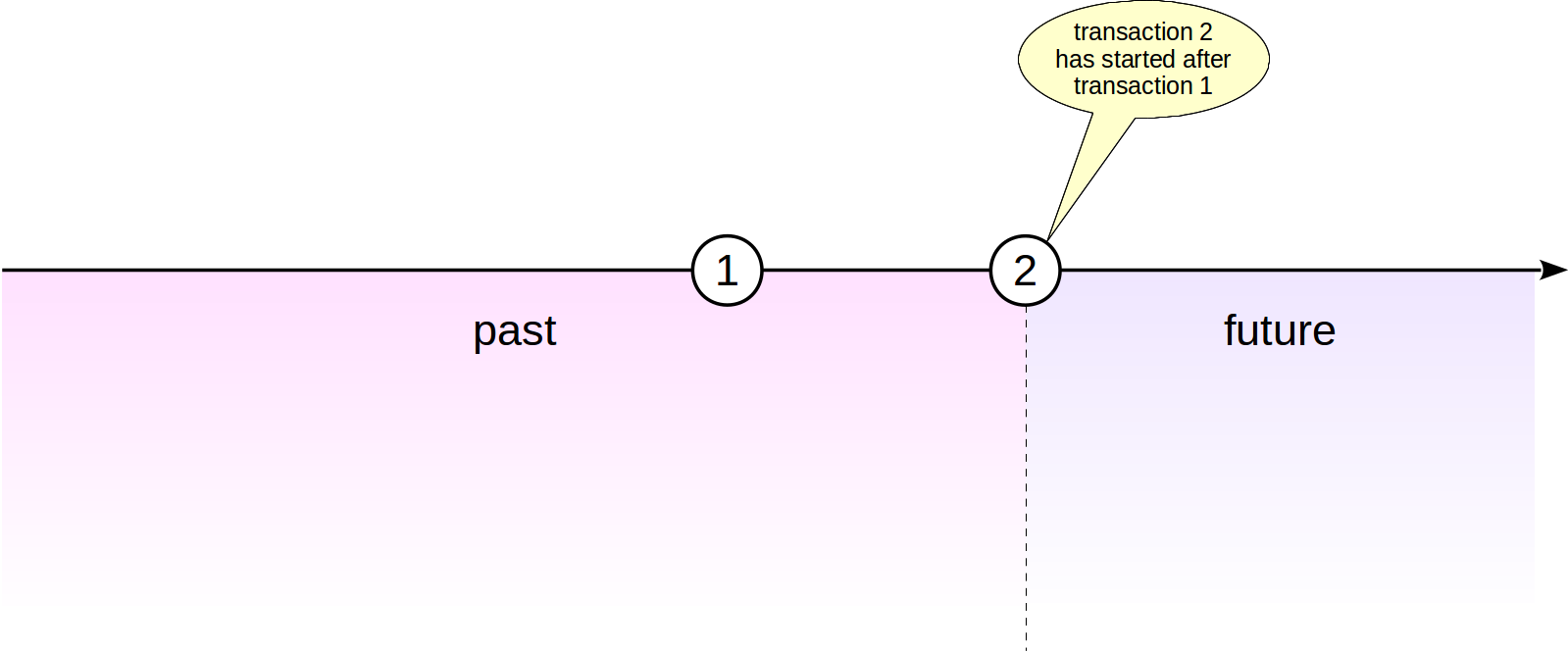
So what's to be done? Instead of ordering transaction IDs sequentially (as numbers), imagine a circle or a clock dial. Transaction IDs are compared in the same sense as clock readings are compared. That is, for each transaction, the «counterclockwise» half of transaction IDs is regarded to pertain to the past, while the «clockwise» part is regarded to pertain to the future.
The age of the transaction is defined as the number of transactions that ran since the time when the transaction occurred in the system (regardless of the transaction ID wraparound). To figure out whether one transaction is older than the other, we compare their ages rather than IDs. (By the way, it's for this reason that the operations «greater» and «less» are not defined for the

But this looped arrangement is troublesome. A transaction that was in the distant past (transaction 1 in the figure), some time later will get into the half of the circle pertinent to the future. This, certainly, breaks visibility rules and would cause issues: changes done by the transaction 1 would just fall out of sight.

To prevent such «travels» from the past to future, vacuuming does one more task (in addition to freeing page space). It finds pretty old and «cold» tuples (which are visible in all snapshots and are unlikely to change) and marks them in a special way, that is, «freezes» them. A frozen tuple is considered older than any normal data and is always visible in all snapshots. And it is no longer needed to look at the

To track the
Note that the
Let's create a table for experiments. And let's specify the minimum fillfactor for it such that only two rows fit on each page — this makes it more convenient for us to watch what is happening. Let's also turn autovacuum off to control the vacuuming time on our own.
We've already created a few variants of the function that uses the «pageinspect» extension to show the tuples located on a page. We will now create one more variant of this function: it will show several pages at once and output the age of the
Note that both
We will also need the «pg_visibility» extension, which enables us to look into the visibility map:
In PostgreSQL versions earlier than 9.6, the visibility map contained one bit per page; the map tracked only pages with «pretty old» row versions, which are visible in all data snapshots for sure. The idea behind this is that if a page is tracked in the visibility map, the visibility rules for its tuples do not need to be checked.
Starting with version 9.6, the all-frozen bit for each page was added to the visibility map. The all-frozen bit tracks pages where all tuples are frozen.
Let's insert a few rows into the table and immediately do vacuuming for the visibility map to be created:
And we can see that both pages are known to be all-visible, but not to be all-frozen:
The age of the transaction that created the rows (
Three main parameters control freezing, and we will discuss them one after another.
Let's start with vacuum_freeze_min_age, which defines the minimum age of the
The default value of this parameter specifies that a transaction starts getting frozen when 50 million of other transactions ran since the time it occurred:
To watch freezing, let's reduce the value of this parameter to one.
And let's update one row on the zero page. The new version will get onto the same page because of the small fillfactor.
This is what we now see on the data pages:
Now the rows older than vacuum_freeze_min_age = 1 are to be frozen. But note that the zero row is not tracked in the visibility map (the UPDATE command that changed the page reset the bit), while the first one is still tracked:
We've already discussed that vacuuming looks only through pages not tracked in the visibility map. And this is the case:
On the zero page, one version is frozen, but vacuuming did not look into the first page at all. So, if only live tuples are left on a page, vacuuming will not access this page and will not freeze them.
To freeze the tuples left on pages where vacuuming does not normally look, the second parameter is provided: vacuum_freeze_table_age. It defines the age of the transaction for which vacuuming ignores the visibility map and looks through all the table pages in order to do freezing.
Each page stores the transaction ID for which all the older transactions are known to be frozen for sure (
Before PostgreSQL 9.6, each time vacuuming did full scan of a table in order to visit all the pages for sure. For large-size tables this operation was long and sad. The matter was even worse because if vacuuming did not complete (for example, an impatient admin interrupted the command), the process had to be started from the very beginning.
Since version 9.6, thanks to the all-frozen bit (which we can see in the
Anyway, all table pages get frozen once every (vacuum_freeze_table_age ? vacuum_freeze_min_age) transactions. With the default values, this happens once a million transactions:
So it is clear that a too large value of vacuum_freeze_min_age is not an option either since this will start increasing the overhead rather than reduce it.
Let's see how freezing of an entire table is done, and to this end, we'll reduce vacuum_freeze_table_age to 5, so that the freezing condition is met.
Let's do freezing:
Now, since the entire table was checked for sure, the ID of the frozen transaction can be increased because we are certain that no older unfrozen transaction is left on the pages.
Now all the tuples on the first page are frozen:
Besides, the first page is known to be all-frozen:
Timely freezing of tuples is essential. If a transaction that is not frozen yet faces a risk to get to the future, PostgreSQL will shutdown in order to prevent possible issues.
Why can this happen? There are various reasons.
To respond to these, «aggressive» freezing is provided, which is controlled by the autovacuum_freeze_max_age parameter. If a table in some database may have an unfrozen transaction that is older that the age specified in the age parameter, forced autovacuuming is launched (even if it is turned off) and the processes will sooner or later reach the problematic table (regardless of usual criteria).
The default value is pretty conservative:
The limitation for autovacuum_freeze_max_age is 2 billion transactions, and the value used is 10 times smaller. And this makes sense: by increasing the value we also increase the risk for autovacuuming to be unable to freeze all the necessary rows during the time interval left.
Besides, the value of this parameter determines the size of the XACT structure: since the system must not retain older transactions that may require the status to be found out, autovacuuming frees space by deleting unneeded segment files of XACT.
Let's look at how vacuuming handles append-only tables by example of «tfreeze». Autovacuum is turned off for this table, but even this won't hinder.
The change of the autovacuum_freeze_max_age parameter requires the server to restart. But you can also set all the above parameters at the level of separate tables by means of storage parameters. This usually makes sense to do only in special situations when the table does require special handling.
So, we'll set autovacuum_freeze_max_age at the table level (and revert to the normal fillfactor at the same time). Unfortunately the minimum possible value is 100 000:
Unfortunately — because we will have to perform 100 000 transactions to reproduce the situation of interest. But for practical use this is, certainly, an extremely low value.
Since we are going to add data, let's insert 100 000 rows into the table, each in its own transaction. And again, note that you should avoid doing so in a real-case scenario. But we are only researching, so we are permitted.
As we can see, the age of the last frozen transaction in the table exceeded the threshold:
But now if we wait for a while, a record will appear in the message log on
Sometimes it appears convenient to control freezing manually rather than rely on autovacuuming.
You can manually launch freezing by means the VACUUM FREEZE command. It will freeze all the tuples regardless of the age of transactions (as if the autovacuum_freeze_min_age parameter were equal to zero). When a table is rewritten using the VACUUM FULL or CLUSTER command, all the rows also get frozen.
To freeze all the databases, you can use the utility:
The data can also be frozen when it is initially loaded by the COPY command if the FREEZE parameter is specified. To this end, the table must be created (or emptied with the TRUNCATE command) in the same transaction as COPY.
Since there is an exception for frozen rows in visibility rules, such rows will be visible in the snapshots of other transactions, which violates normal isolation rules (this relates to transactions with the Repeatable Read or Serializable level).
To make sure of this, in another session, let's start a transaction with the Repeatable Read isolation level:
Note that this transaction created a data snapshot, but did not access the «tfreeze» table. We will now truncate the «tfreeze» table and load new rows there in one transaction. If a parallel transaction read the contents of «tfreeze», the TRUNCATE command would be locked to the end of this transaction.
Now the concurrent transaction sees the new data, although this violates isolation:
But since such data loading is unlikely to regularly happen, this is hardly an issue.
What is much worse is that COPY WITH FREEZE does not work with the visibility map — loaded pages are not tracked as containing only tuples visible to all. Therefore, when a vacuum operation accesses the table first, it has to process all the table again and create the visibility map. What is even worse is that data pages have the all-visible indicator in their own headers, and therefore, vacuuming not only reads the entire table, but also entirely rewrites it to set the needed bit. Unfortunately, the solution to this problem can be expected not earlier than in version 13 (discussion).
This completes the series of articles on isolation and multiversion concurrency control in PostgreSQL. Thank you for your attention and especially for comments. They help improve the contents and often detect the areas that require more intense attention on my part.
Stay with us, there is more to come!
Then we covered different vacuuming techniques: in-page vacuum (along with HOT updates), vacuum and autovacuum.
Now we've reached the last topic of this series. We will talk on the transaction id wraparound and freezing.
Transaction ID wraparound
PostgreSQL uses 32-bit transaction IDs. This is a pretty large number (about 4 billion), but with intensive work of the server, this number is not unlikely to get exhausted. For example: with the workload of 1000 transactions a second, this will happen as early as in one month and a half of continuous work.
But we've mentioned that multiversion concurrency control relies on the sequential numbering, which means that of two transactions the one with a smaller number can be considered to have started earlier. Therefore, it is clear that it is not an option to just reset the counter and start the numbering from scratch.
But why not use 64-bit transaction IDs — wouldn't it completely eliminate the issue? The thing is that the header of each tuple (as discussed earlier) stores two transaction IDs:
xmin and xmax. The header is pretty large as it is — 23 bytes at a minimum, and the increase of the bit size would entail the increase of the header by extra 8 bytes. And this is out of all reason.64-bit transaction IDs are implemented in our company's Postgres Pro Enterprise product, but they are not quite fair there:xminandxmaxare still 32-bit, and a page header stores the «beginning of the epoch», which is common for the whole page.
So what's to be done? Instead of ordering transaction IDs sequentially (as numbers), imagine a circle or a clock dial. Transaction IDs are compared in the same sense as clock readings are compared. That is, for each transaction, the «counterclockwise» half of transaction IDs is regarded to pertain to the past, while the «clockwise» part is regarded to pertain to the future.
The age of the transaction is defined as the number of transactions that ran since the time when the transaction occurred in the system (regardless of the transaction ID wraparound). To figure out whether one transaction is older than the other, we compare their ages rather than IDs. (By the way, it's for this reason that the operations «greater» and «less» are not defined for the
xid data type.)But this looped arrangement is troublesome. A transaction that was in the distant past (transaction 1 in the figure), some time later will get into the half of the circle pertinent to the future. This, certainly, breaks visibility rules and would cause issues: changes done by the transaction 1 would just fall out of sight.
Tuple freezing and visibility rules
To prevent such «travels» from the past to future, vacuuming does one more task (in addition to freeing page space). It finds pretty old and «cold» tuples (which are visible in all snapshots and are unlikely to change) and marks them in a special way, that is, «freezes» them. A frozen tuple is considered older than any normal data and is always visible in all snapshots. And it is no longer needed to look at the
xmin transaction number, and this number can be safely reused. So, frozen tuples always remain in the past.To track the
xmin transaction as frozen, both hint bits are set: committed and aborted.Note that the
xmax transaction does not need freezing. Its existence indicates that the tuple is not live anymore. When it gets no longer visible in data snapshots, this tuple will be vacuumed away.Let's create a table for experiments. And let's specify the minimum fillfactor for it such that only two rows fit on each page — this makes it more convenient for us to watch what is happening. Let's also turn autovacuum off to control the vacuuming time on our own.
=> CREATE TABLE tfreeze(
id integer,
s char(300)
) WITH (fillfactor = 10, autovacuum_enabled = off);
We've already created a few variants of the function that uses the «pageinspect» extension to show the tuples located on a page. We will now create one more variant of this function: it will show several pages at once and output the age of the
xmin transaction (using the age system function):=> CREATE FUNCTION heap_page(relname text, pageno_from integer, pageno_to integer)
RETURNS TABLE(ctid tid, state text, xmin text, xmin_age integer, xmax text, t_ctid tid)
AS $$
SELECT (pageno,lp)::text::tid AS ctid,
CASE lp_flags
WHEN 0 THEN 'unused'
WHEN 1 THEN 'normal'
WHEN 2 THEN 'redirect to '||lp_off
WHEN 3 THEN 'dead'
END AS state,
t_xmin || CASE
WHEN (t_infomask & 256+512) = 256+512 THEN ' (f)'
WHEN (t_infomask & 256) > 0 THEN ' (c)'
WHEN (t_infomask & 512) > 0 THEN ' (a)'
ELSE ''
END AS xmin,
age(t_xmin) xmin_age,
t_xmax || CASE
WHEN (t_infomask & 1024) > 0 THEN ' (c)'
WHEN (t_infomask & 2048) > 0 THEN ' (a)'
ELSE ''
END AS xmax,
t_ctid
FROM generate_series(pageno_from, pageno_to) p(pageno),
heap_page_items(get_raw_page(relname, pageno))
ORDER BY pageno, lp;
$$ LANGUAGE SQL;
Note that both
committed and aborted hint bits set indicate freezing (which we denote with a parenthesized «f»). Multiple sources (including the documentation) mention a specialized ID to indicate frozen transactions: FrozenTransactionId = 2. This method was in place in PostgreSQL versions earlier than 9.4, and now it is replaced with hint bits. This permits to retain the initial transaction number in a tuple, which is convenient for maintenance and debugging. However, you can still come across transactions with ID = 2 in old systems, even upgraded to latest versions.We will also need the «pg_visibility» extension, which enables us to look into the visibility map:
=> CREATE EXTENSION pg_visibility;
In PostgreSQL versions earlier than 9.6, the visibility map contained one bit per page; the map tracked only pages with «pretty old» row versions, which are visible in all data snapshots for sure. The idea behind this is that if a page is tracked in the visibility map, the visibility rules for its tuples do not need to be checked.
Starting with version 9.6, the all-frozen bit for each page was added to the visibility map. The all-frozen bit tracks pages where all tuples are frozen.
Let's insert a few rows into the table and immediately do vacuuming for the visibility map to be created:
=> INSERT INTO tfreeze(id, s)
SELECT g.id, 'FOO' FROM generate_series(1,100) g(id);
=> VACUUM tfreeze;
And we can see that both pages are known to be all-visible, but not to be all-frozen:
=> SELECT * FROM generate_series(0,1) g(blkno), pg_visibility_map('tfreeze',g.blkno)
ORDER BY g.blkno;
blkno | all_visible | all_frozen
-------+-------------+------------
0 | t | f
1 | t | f
(2 rows)
The age of the transaction that created the rows (
xmin_age) equals one — this is the last transaction performed in the system:=> SELECT * FROM heap_page('tfreeze',0,1);
ctid | state | xmin | xmin_age | xmax | t_ctid
-------+--------+---------+----------+-------+--------
(0,1) | normal | 697 (c) | 1 | 0 (a) | (0,1)
(0,2) | normal | 697 (c) | 1 | 0 (a) | (0,2)
(1,1) | normal | 697 (c) | 1 | 0 (a) | (1,1)
(1,2) | normal | 697 (c) | 1 | 0 (a) | (1,2)
(4 rows)
Minimum age for freezing
Three main parameters control freezing, and we will discuss them one after another.
Let's start with vacuum_freeze_min_age, which defines the minimum age of the
xmin transaction for which a tuple can be frozen. The smaller this value, the more extra overhead there may be: if we deal with «hot», intensively changing, data, freezing of new and newer tuples will go down the drain. In this case, it's better to wait.The default value of this parameter specifies that a transaction starts getting frozen when 50 million of other transactions ran since the time it occurred:
=> SHOW vacuum_freeze_min_age;
vacuum_freeze_min_age
-----------------------
50000000
(1 row)
To watch freezing, let's reduce the value of this parameter to one.
=> ALTER SYSTEM SET vacuum_freeze_min_age = 1;
=> SELECT pg_reload_conf();
And let's update one row on the zero page. The new version will get onto the same page because of the small fillfactor.
=> UPDATE tfreeze SET s = 'BAR' WHERE id = 1;
This is what we now see on the data pages:
=> SELECT * FROM heap_page('tfreeze',0,1);
ctid | state | xmin | xmin_age | xmax | t_ctid
-------+--------+---------+----------+-------+--------
(0,1) | normal | 697 (c) | 2 | 698 | (0,3)
(0,2) | normal | 697 (c) | 2 | 0 (a) | (0,2)
(0,3) | normal | 698 | 1 | 0 (a) | (0,3)
(1,1) | normal | 697 (c) | 2 | 0 (a) | (1,1)
(1,2) | normal | 697 (c) | 2 | 0 (a) | (1,2)
(5 rows)
Now the rows older than vacuum_freeze_min_age = 1 are to be frozen. But note that the zero row is not tracked in the visibility map (the UPDATE command that changed the page reset the bit), while the first one is still tracked:
=> SELECT * FROM generate_series(0,1) g(blkno), pg_visibility_map('tfreeze',g.blkno)
ORDER BY g.blkno;
blkno | all_visible | all_frozen
-------+-------------+------------
0 | f | f
1 | t | f
(2 rows)
We've already discussed that vacuuming looks only through pages not tracked in the visibility map. And this is the case:
=> VACUUM tfreeze;
=> SELECT * FROM heap_page('tfreeze',0,1);
ctid | state | xmin | xmin_age | xmax | t_ctid
-------+---------------+---------+----------+-------+--------
(0,1) | redirect to 3 | | | |
(0,2) | normal | 697 (f) | 2 | 0 (a) | (0,2)
(0,3) | normal | 698 (c) | 1 | 0 (a) | (0,3)
(1,1) | normal | 697 (c) | 2 | 0 (a) | (1,1)
(1,2) | normal | 697 (c) | 2 | 0 (a) | (1,2)
(5 rows)
On the zero page, one version is frozen, but vacuuming did not look into the first page at all. So, if only live tuples are left on a page, vacuuming will not access this page and will not freeze them.
=> SELECT * FROM generate_series(0,1) g(blkno), pg_visibility_map('tfreeze',g.blkno)
ORDER BY g.blkno;
blkno | all_visible | all_frozen
-------+-------------+------------
0 | t | f
1 | t | f
(2 rows)
Age to freeze the entire table
To freeze the tuples left on pages where vacuuming does not normally look, the second parameter is provided: vacuum_freeze_table_age. It defines the age of the transaction for which vacuuming ignores the visibility map and looks through all the table pages in order to do freezing.
Each page stores the transaction ID for which all the older transactions are known to be frozen for sure (
pg_class.relfrozenxid). And this is the age of this stored transaction that the value of the vacuum_freeze_table_age parameter is compared to.=> SELECT relfrozenxid, age(relfrozenxid) FROM pg_class WHERE relname = 'tfreeze';
relfrozenxid | age
--------------+-----
694 | 5
(1 row)
Before PostgreSQL 9.6, each time vacuuming did full scan of a table in order to visit all the pages for sure. For large-size tables this operation was long and sad. The matter was even worse because if vacuuming did not complete (for example, an impatient admin interrupted the command), the process had to be started from the very beginning.
Since version 9.6, thanks to the all-frozen bit (which we can see in the
all_frozen column in the pg_visibility_map output), vacuuming goes only through pages for which the bit is not set yet. This ensures not only a considerably smaller amount of work, but also interrupt tolerance: if a vacuum process is stopped and restarted, it will not have to look again into the pages for which it already set the all-frozen bit last time.Anyway, all table pages get frozen once every (vacuum_freeze_table_age ? vacuum_freeze_min_age) transactions. With the default values, this happens once a million transactions:
=> SHOW vacuum_freeze_table_age;
vacuum_freeze_table_age
-------------------------
150000000
(1 row)
So it is clear that a too large value of vacuum_freeze_min_age is not an option either since this will start increasing the overhead rather than reduce it.
Let's see how freezing of an entire table is done, and to this end, we'll reduce vacuum_freeze_table_age to 5, so that the freezing condition is met.
=> ALTER SYSTEM SET vacuum_freeze_table_age = 5;
=> SELECT pg_reload_conf();
Let's do freezing:
=> VACUUM tfreeze;
Now, since the entire table was checked for sure, the ID of the frozen transaction can be increased because we are certain that no older unfrozen transaction is left on the pages.
=> SELECT relfrozenxid, age(relfrozenxid) FROM pg_class WHERE relname = 'tfreeze';
relfrozenxid | age
--------------+-----
698 | 1
(1 row)
Now all the tuples on the first page are frozen:
=> SELECT * FROM heap_page('tfreeze',0,1);
ctid | state | xmin | xmin_age | xmax | t_ctid
-------+---------------+---------+----------+-------+--------
(0,1) | redirect to 3 | | | |
(0,2) | normal | 697 (f) | 2 | 0 (a) | (0,2)
(0,3) | normal | 698 (c) | 1 | 0 (a) | (0,3)
(1,1) | normal | 697 (f) | 2 | 0 (a) | (1,1)
(1,2) | normal | 697 (f) | 2 | 0 (a) | (1,2)
(5 rows)
Besides, the first page is known to be all-frozen:
=> SELECT * FROM generate_series(0,1) g(blkno), pg_visibility_map('tfreeze',g.blkno)
ORDER BY g.blkno;
blkno | all_visible | all_frozen
-------+-------------+------------
0 | t | f
1 | t | t
(2 rows)
Age for «aggressive» freezing
Timely freezing of tuples is essential. If a transaction that is not frozen yet faces a risk to get to the future, PostgreSQL will shutdown in order to prevent possible issues.
Why can this happen? There are various reasons.
- Autovacuum may be turned off, and VACUUM is not launched either. We've already mentioned that you should not do so, but this is technically possible.
- Even if autovacuum is turned on, it does not reach unused databases (remember the track_counts parameter and «template0» database).
- As we observed last time, vacuuming skips tables where data is only added, but not deleted or changed.
To respond to these, «aggressive» freezing is provided, which is controlled by the autovacuum_freeze_max_age parameter. If a table in some database may have an unfrozen transaction that is older that the age specified in the age parameter, forced autovacuuming is launched (even if it is turned off) and the processes will sooner or later reach the problematic table (regardless of usual criteria).
The default value is pretty conservative:
=> SHOW autovacuum_freeze_max_age;
autovacuum_freeze_max_age
---------------------------
200000000
(1 row)
The limitation for autovacuum_freeze_max_age is 2 billion transactions, and the value used is 10 times smaller. And this makes sense: by increasing the value we also increase the risk for autovacuuming to be unable to freeze all the necessary rows during the time interval left.
Besides, the value of this parameter determines the size of the XACT structure: since the system must not retain older transactions that may require the status to be found out, autovacuuming frees space by deleting unneeded segment files of XACT.
Let's look at how vacuuming handles append-only tables by example of «tfreeze». Autovacuum is turned off for this table, but even this won't hinder.
The change of the autovacuum_freeze_max_age parameter requires the server to restart. But you can also set all the above parameters at the level of separate tables by means of storage parameters. This usually makes sense to do only in special situations when the table does require special handling.
So, we'll set autovacuum_freeze_max_age at the table level (and revert to the normal fillfactor at the same time). Unfortunately the minimum possible value is 100 000:
=> ALTER TABLE tfreeze SET (autovacuum_freeze_max_age = 100000, fillfactor = 100);
Unfortunately — because we will have to perform 100 000 transactions to reproduce the situation of interest. But for practical use this is, certainly, an extremely low value.
Since we are going to add data, let's insert 100 000 rows into the table, each in its own transaction. And again, note that you should avoid doing so in a real-case scenario. But we are only researching, so we are permitted.
=> CREATE PROCEDURE foo(id integer) AS $$
BEGIN
INSERT INTO tfreeze VALUES (id, 'FOO');
COMMIT;
END;
$$ LANGUAGE plpgsql;
=> DO $$
BEGIN
FOR i IN 101 .. 100100 LOOP
CALL foo(i);
END LOOP;
END;
$$;
As we can see, the age of the last frozen transaction in the table exceeded the threshold:
=> SELECT relfrozenxid, age(relfrozenxid) FROM pg_class WHERE relname = 'tfreeze';
relfrozenxid | age
--------------+--------
698 | 100006
(1 row)
But now if we wait for a while, a record will appear in the message log on
automatic aggressive vacuum of table "test.public.tfreeze", the number of the frozen transaction will change and its age will no longer be beyond the bounds of decency:=> SELECT relfrozenxid, age(relfrozenxid) FROM pg_class WHERE relname = 'tfreeze';
relfrozenxid | age
--------------+-----
100703 | 3
(1 row)
There is also the multixact freezing technique, but we'll put a talk on it off until we discuss locks, to avoid getting so far ahead.
Freezing manually
Sometimes it appears convenient to control freezing manually rather than rely on autovacuuming.
You can manually launch freezing by means the VACUUM FREEZE command. It will freeze all the tuples regardless of the age of transactions (as if the autovacuum_freeze_min_age parameter were equal to zero). When a table is rewritten using the VACUUM FULL or CLUSTER command, all the rows also get frozen.
To freeze all the databases, you can use the utility:
vacuumdb --all --freeze
The data can also be frozen when it is initially loaded by the COPY command if the FREEZE parameter is specified. To this end, the table must be created (or emptied with the TRUNCATE command) in the same transaction as COPY.
Since there is an exception for frozen rows in visibility rules, such rows will be visible in the snapshots of other transactions, which violates normal isolation rules (this relates to transactions with the Repeatable Read or Serializable level).
To make sure of this, in another session, let's start a transaction with the Repeatable Read isolation level:
| => BEGIN ISOLATION LEVEL REPEATABLE READ;
| => SELECT txid_current();
Note that this transaction created a data snapshot, but did not access the «tfreeze» table. We will now truncate the «tfreeze» table and load new rows there in one transaction. If a parallel transaction read the contents of «tfreeze», the TRUNCATE command would be locked to the end of this transaction.
=> BEGIN;
=> TRUNCATE tfreeze;
=> COPY tfreeze FROM stdin WITH FREEZE;
1 FOO
2 BAR
3 BAZ
\.
=> COMMIT;
Now the concurrent transaction sees the new data, although this violates isolation:
| => SELECT count(*) FROM tfreeze;
| count
| -------
| 3
| (1 row)
| => COMMIT;
But since such data loading is unlikely to regularly happen, this is hardly an issue.
What is much worse is that COPY WITH FREEZE does not work with the visibility map — loaded pages are not tracked as containing only tuples visible to all. Therefore, when a vacuum operation accesses the table first, it has to process all the table again and create the visibility map. What is even worse is that data pages have the all-visible indicator in their own headers, and therefore, vacuuming not only reads the entire table, but also entirely rewrites it to set the needed bit. Unfortunately, the solution to this problem can be expected not earlier than in version 13 (discussion).
Conclusion
This completes the series of articles on isolation and multiversion concurrency control in PostgreSQL. Thank you for your attention and especially for comments. They help improve the contents and often detect the areas that require more intense attention on my part.
Stay with us, there is more to come!