
Kubernetes — это отличный инструмент для запуска контейнеров Docker в кластеризованной производственной среде. Однако существуют задачи, которые Kubernetes решить не в состоянии. При частом развертывании в рабочей среде мы нуждаемся в полностью автоматизированном Blue/Green deployment, чтобы избежать простоев в данном процессе, при котором также необходимо обрабатывать внешние HTTP-запросы и выполнять выгрузку SSL. Это требует интеграции с балансировщиком нагрузки, таким как ha-proxy. Другой задачей является полуавтоматическое масштабирование самого кластера Kubernetes при работе в облачной среде, например, частичное уменьшение масштаба кластера в ночное время.
Хотя Kubernetes не обладает этими функциями прямо «из коробки», он предоставляет API, которым можно воспользоваться для решения подобных задач. Инструменты для автоматизированного Blue/Green развертывания и масштабирования кластера Kubernetes были разработаны в рамках проекта Cloud RTI, который создавался на основе open-source.
В этой статье, расшифровке видео, рассказывается, как настроить Kubernetes вместе с другими компонентами с открытым исходным кодом для получения готовой к производству среды, которая без простоев в продакшене воспринимает код из коммита изменений git commit.

DEVOXX UK. Kubernetes в продакшене: Blue/Green deployment, автомасштабирование и автоматизация развертывания. Часть 1
Итак, после того как вы получили доступ к своим приложениям из внешнего мира, можно приступать к полной настройке автоматизации, то есть довести ее до стадии, на которой можно выполнить git commit и убедиться в том, что этот git commit заканчивается в продакшене. Естественно, что при реализации этих шагов, при осуществлении развертывания, мы не хотим сталкиваться с простоями. Итак, любая автоматизация в Kubernetes начинается с API.
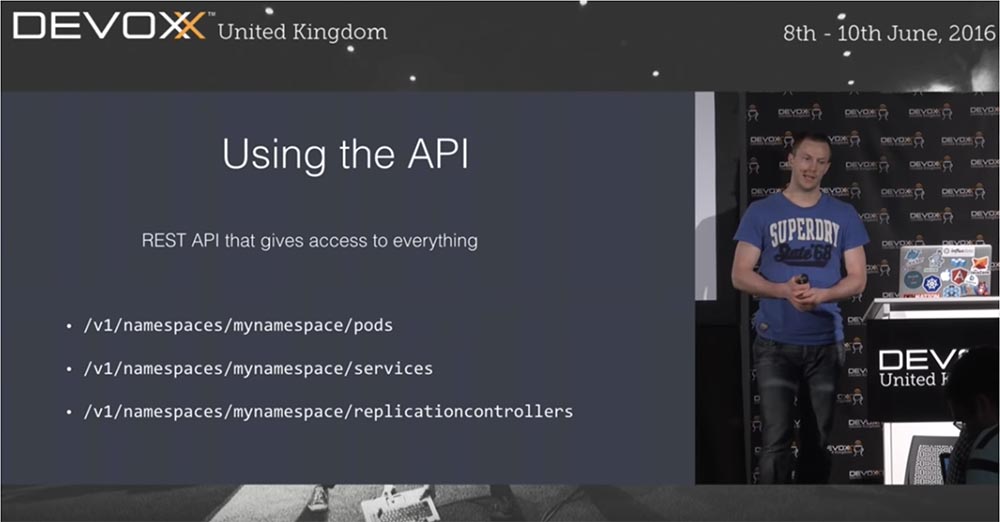
Kubernetes не тот инструмент, который можно продуктивно использовать «прямо из коробки». Конечно, вы можете так делать, использовать kubectl и так далее, но все же API является самой интересной и полезной вещью этой платформы. Используя API как набор функций, вы можете получить доступ практически ко всему, что хотите сделать в Kubernetes. Сам по себе kubectl также использует REST API.
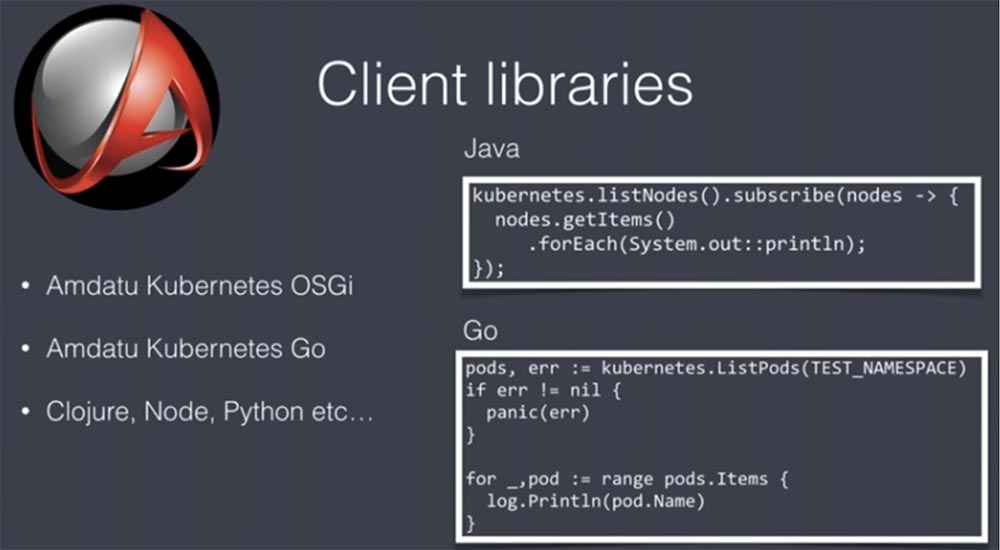
Это REST, так что вы можете использовать для работы с этим API любые языки и инструменты, но вашу жизнь значительно облегчат пользовательские библиотеки. Моя команда написала 2 такие библиотеки: одну для Java / OSGi и одну для Go. Вторая используется не часто, но в любом случае в вашем распоряжении имеются эти полезные вещи. Они представляют собой частично лицензионный open-source проект. Существует множество таких библиотек для различных языков, так что вы можете выбрать наиболее подходящие.
Итак, прежде чем приступить к автоматизации развертывания, необходимо убедиться, что этот процесс не будет подвержен никаким простоям. Например, наша команда проводит продакшн-развертывание в середине дня, когда люди максимально используют приложения, поэтому очень важно избегать задержек в этом процессе. Для того, чтобы избежать простоев, используются 2 способа: blue/green развертывание или скользящее обновление rolling update. В последнем случае, если у вас работает 5 реплик приложения, они последовательно обновляются одна за другой. Этот способ отлично работает, но он не подходит, если в процессе развертывания у вас одновременно запущены разные версии приложения. В таком случае вы можете обновить интерфейс пользователя в то время, как бэкенд будет работать со старой версией, и работа приложения будет прекращена. Поэтому с точки зрения программирования работа в таких условиях довольно затруднительна.
Это одна из причин, по которой мы предпочитаем использовать blue/green deployment для автоматизации развертывания своих приложений. При таком способе вы должны убедиться, что в определенный момент времени активна только одна версия приложения.
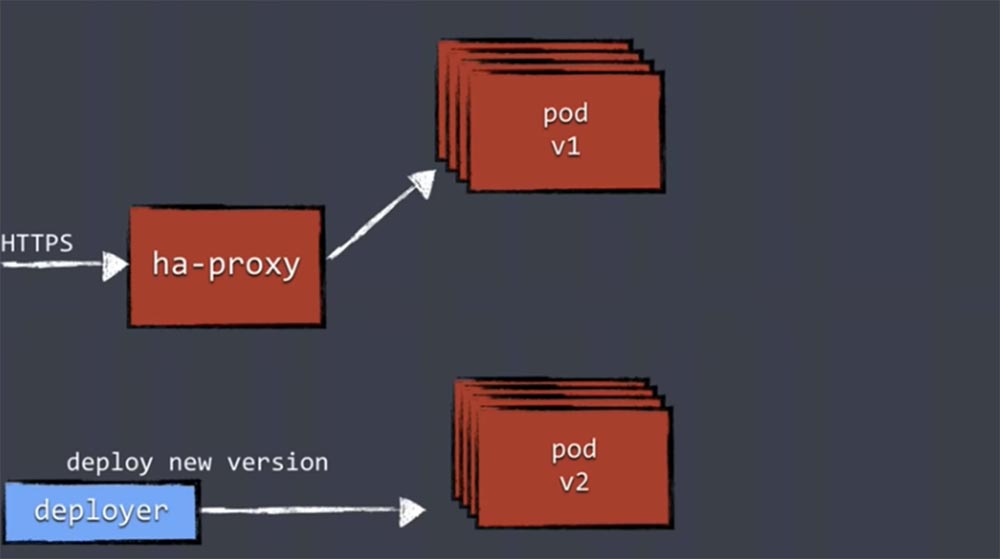
Механизм blue/green deployment выглядит следующим образом. Мы получаем трафик для своих приложений через ha-proxy, который направляет его запущенным репликам приложения одной и той же версии.
Когда осуществляется новое развертывание, мы используем Deployer, которому предоставляются новые компоненты, и он осуществляет деплой новой версии. Деплой новой версии приложения означает, что «поднимается» новый набор реплик, после чего эти реплики новой версии запускаются в отдельном, новом поде. Однако ha-proxy ничего об них не знает и пока что не направляет им никакой рабочей нагрузки.
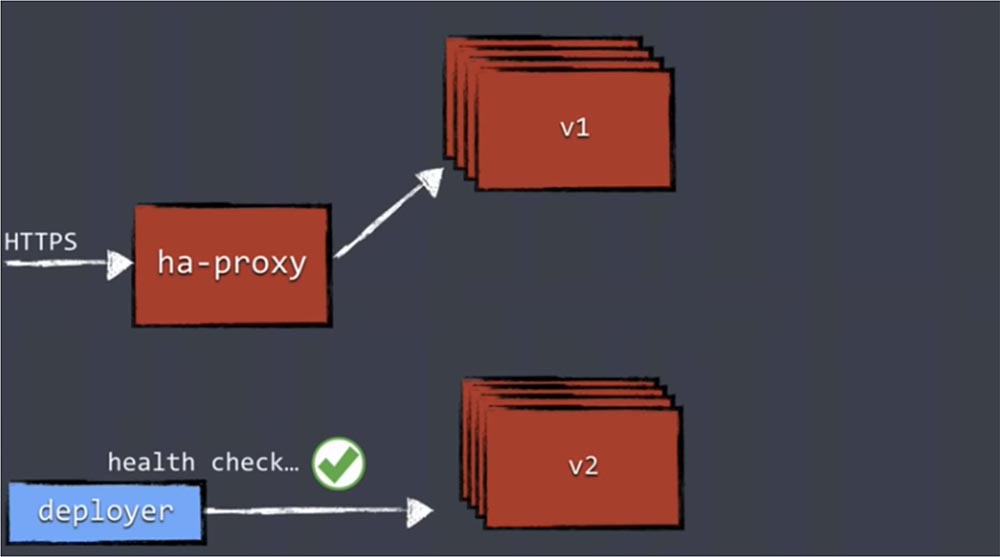
Поэтому в первую очередь необходимо выполнить проверку работоспособности новых версий health cheking, чтобы убедиться в готовности реплик обслуживать нагрузку.
Все компоненты развертывания должны поддерживать какую-либо форму health chek. Это может быть совсем простая проверка HTTP вызовом, когда вы получаете код со статусом 200, либо более глубокая проверка, при которой вы проверяете связь реплик с базой данных и другими сервисами, устойчивость связей динамического окружения, все ли запускается и работает правильным образом. Этот процесс может быть довольно сложным.
После того, как система убедиться в работоспособности всех обновленных реплик, Deployer обновит конфигурацию и передаст правильный confd, который перенастроит ha-proxy.
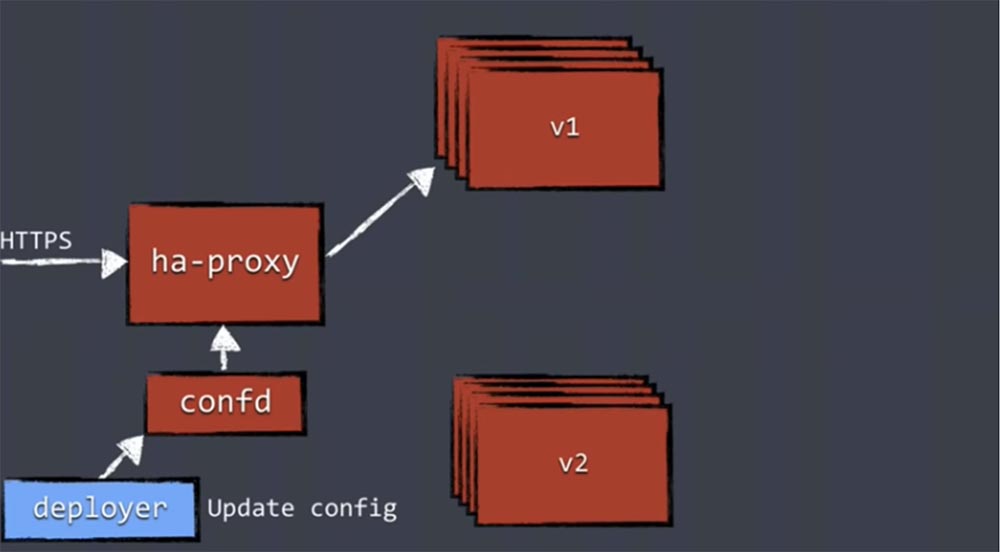
Только после этого трафик будет направлен в под с репликами новой версии, а старый под исчезнет.
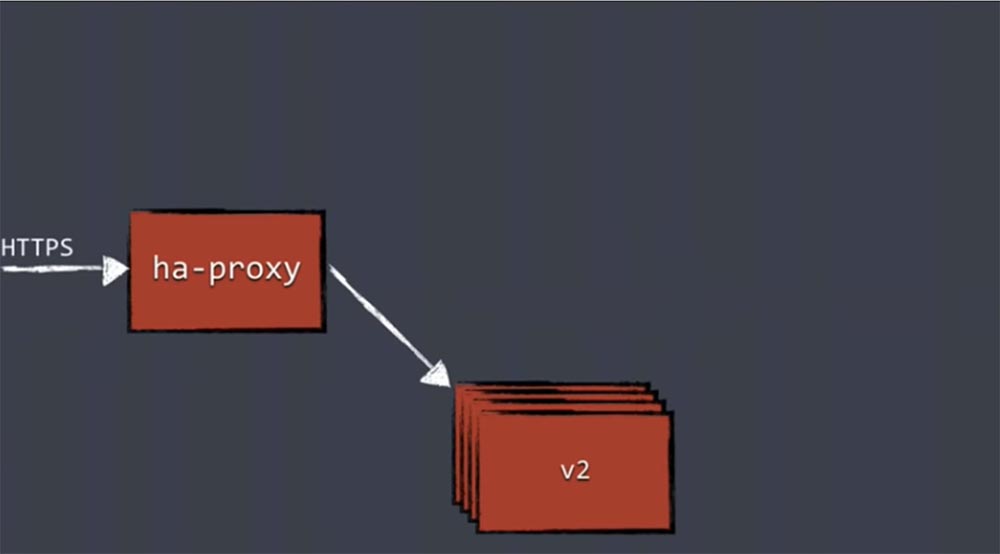
Этот механизм не является особенностью Kubernetes. Концепция Blue/green deployment существует довольно длительное время, и она всегда использовала балансировщик нагрузки. Сначала вы направляете весь трафик к старой версии приложения, а после обновления полностью переводите его на новую версию. Этот принцип используется не только в Kubernetes.
Сейчас я представлю вам новый компонент развертывания – Deployer, который выполняет проверку работоспособности, реконфигурирует прокси и так далее. Это концепт, который не относится ко внешнему миру и существует внутри Kubernetes. Я покажу, как можно создать свой собственный концепт Deployer при помощи open-source инструментов.
Итак, первое, что делает Deployer – это создает контроллер репликации RC, используя API Kubernetes. Этот API создает поды и сервисы для дальнейшего развертывания, то есть создает полностью новый кластер для наших приложений. Как только RC убедится в том, что реплики стартовали, он произведет проверку их работоспособности Health check. Для этого в Deployer используется команда GET /health. Она запускает соответствующие компоненты проверки и проверяет все элементы, обеспечивающие работу кластера.
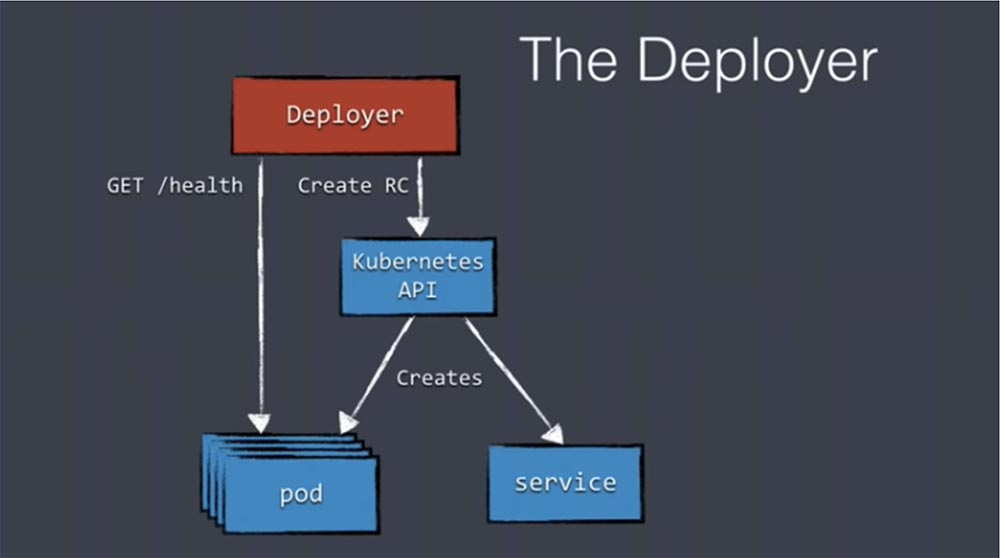
После того, как все поды сообщили о своем «здоровье», Deployer создает новый элемент конфигурации – распределенное хранилище etcd, которое используется внутри Kubernetes, в том числе для хранения конфигурации балансировщика нагрузки. Мы записываем данные в etcd, и небольшой инструмент confd отслеживает etcd на предмет появления новых данных.
Если он обнаружил какие-то изменения первоначальной конфигурации, то генерирует новый файл настроек и передает его ha-proxy. В этом случае ha-proxy перезагружается без потери каких-либо соединений и адресует нагрузку новым services, которые обеспечивают работу новой версии наших приложений.
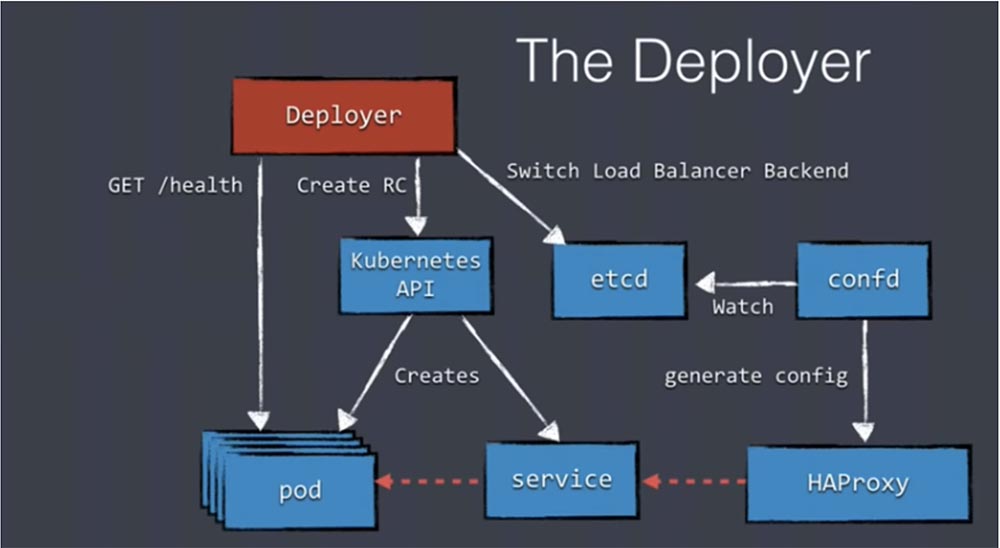
Как видите, не смотря на обилие компонентов, здесь нет ничего сложного. Вам просто нужно уделить больше внимания API и etcd. Я хочу рассказать вам об open-source деплоере, которым мы сами пользуемся – это Amdatu Kubernetes Deployer.

Это инструмент для оркестровки развертываний Kubernetes, обладающий такими функциями:
Этот Deployer создан на вершине Kubernetes API и предоставляет собой REST API для управления дескрипторами и развертываниями, а также Websocket API для потоковых логов в процессе развертывания.
Он помещает данные конфигурации балансировщика нагрузки в etcd, поэтому вы можете не пользоваться ha-proxy с поддержкой «прямо из коробки», а легко использовать свой собственный файл конфигурации балансировщика. Amdatu Deployer написан на Go, как и сам Kubernetes, и лицензирован Apache.
Перед началом применения этой версии деплоера я воспользовался следующим дескриптором развертывания, в котором указаны нужные мне параметры.

Один из важных параметров этого кода – включение флага «useHealthCheck». Нам нужно указать, что в процессе развертывания необходимо выполнять проверку работоспособности. Этот параметр может быть отключен, когда в развертывании используются контейнеры сторонних разработчиков, которые не нужно проверять. В этом дескрипторе также указано количество реплик и URL фронтенда, который нужен ha-proxy. В конце указан флаг спецификации пода «podspec», который обращается к Kubernetes для получения информации по настройке портов, образу и т.д. Это достаточно простой дескриптор в формате JSON.
Еще один инструмент, который является частью open-source проекта Amdatu, это Deploymentctl. Он имеет пользовательский интерфейс UI для конфигурирования развертывания, хранит историю развертывания и содержит webhooks для обратных вызовов сторонними пользователями и разработчиками. Вы можете не использовать UI, поскольку сам Amdatu Deployer является REST API, но этот интерфейс может намного облегчить вам развертывание без привлечения какого-либо API. Deploymentctl написан на OSGi/Vertx с использованием Angular 2.
Сейчас я продемонстрирую вышесказанное на экране, используя заранее сделанную запись, так что вам не придется ждать. Мы будем развертывать простое приложение на Go. Не беспокойтесь, если до этого не сталкивались с Go, это очень простое приложение, так что вам все должно быть понятно.
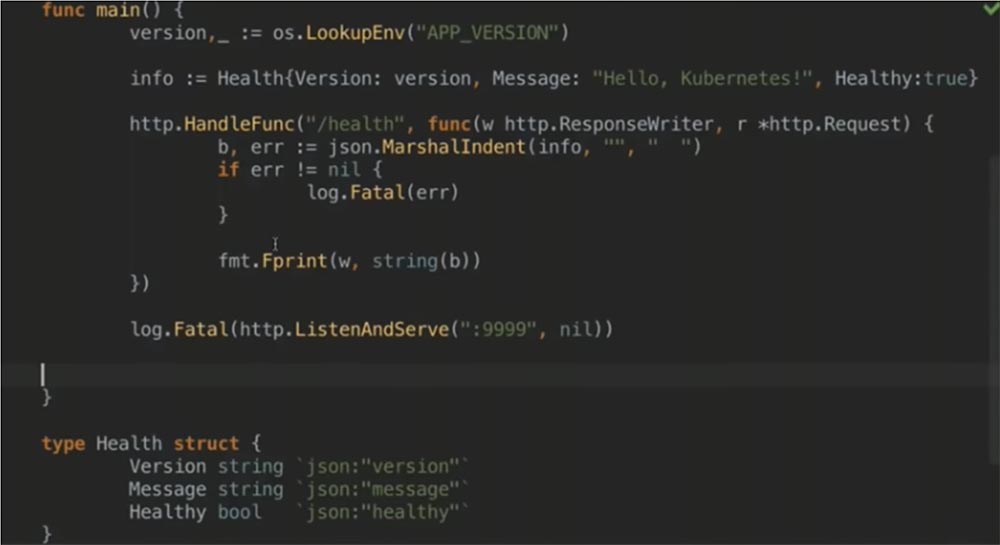
Здесь мы создаем HTTP-сервер, который отвечает только на /health, так что это приложение только проверяет работоспособность health check и ничего больше. Если проверка проходит, задействуется показанная внизу JSON-структура. Она содержит версию приложения, которое будет развернуто деплоером, message, который вы видите в верхней части файла, и логический тип данных boolean — работоспособно наше приложение или нет.
С последней строкой я немного схитрил, потому что поместил вверху файла фиксированное значение boolean, которое в дальнейшем поможет мне развернуть даже «нездоровое» приложение. Позже мы с этим разберемся.
Итак, приступим. Сначала проверяем наличие каких-либо запущенных подов с помощью команды ~ kubectl get pods и по отсутствию ответа URL фронтенда убеждаемся, что никаких развертываний в данный момент не производится.
Далее на экране вы видите упомянутый мною интерфейс Deploymentctl, в котором задаются параметры развертывания: пространство имен, имя приложения, версию развертывания, количество реплик, фронтенд-URL, название контейнера, образ, лимиты ресурсов, номер порта для проверки health check и т.д. Лимиты ресурсов очень важны, так как позволяют задействовать максимально возможное количество «железа». Здесь же можно просмотреть журнал развертывания Deployment log.
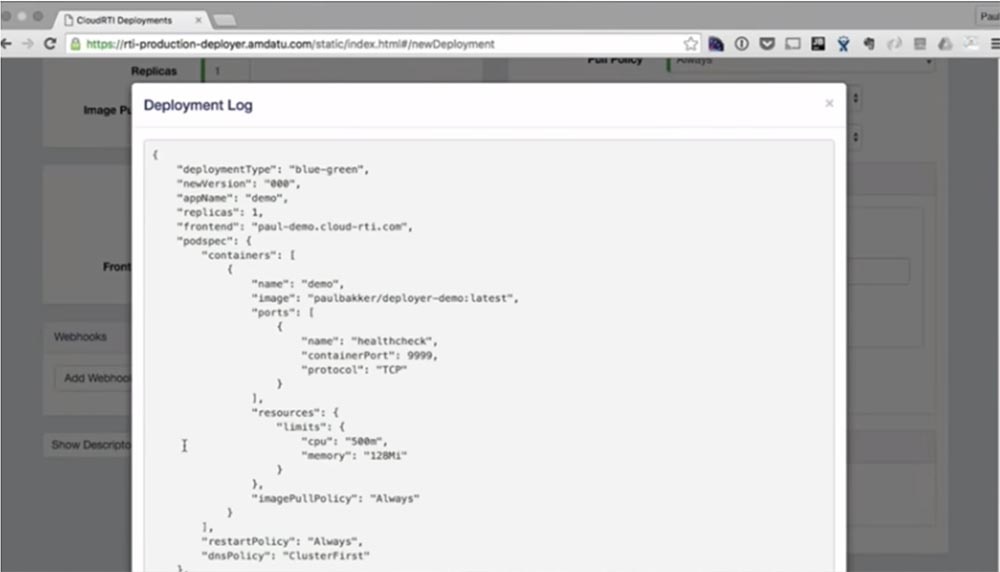
Если сейчас повторить команду ~ kubectl get pods, видно, что система «замирает» на 20 секунд, в процессе которых происходит реконфигурация ha-proxy. После этого под запускается, и нашу реплику можно увидеть в логе развертывания.
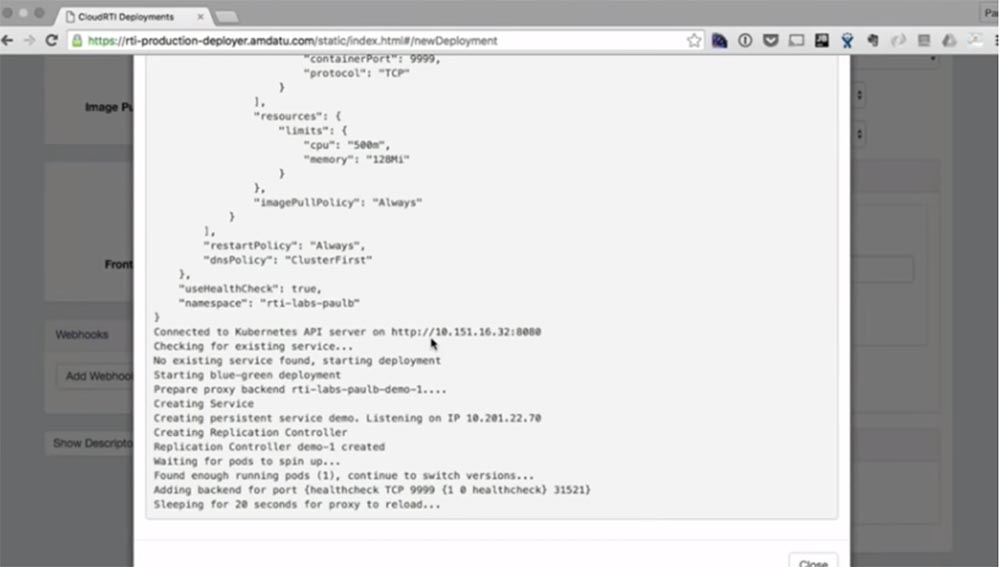
Я вырезал из видео 20-ти секундное ожидание, и сейчас вы видите на экране, что первая версия приложения развернута. Все это было проделано только при помощи UI.
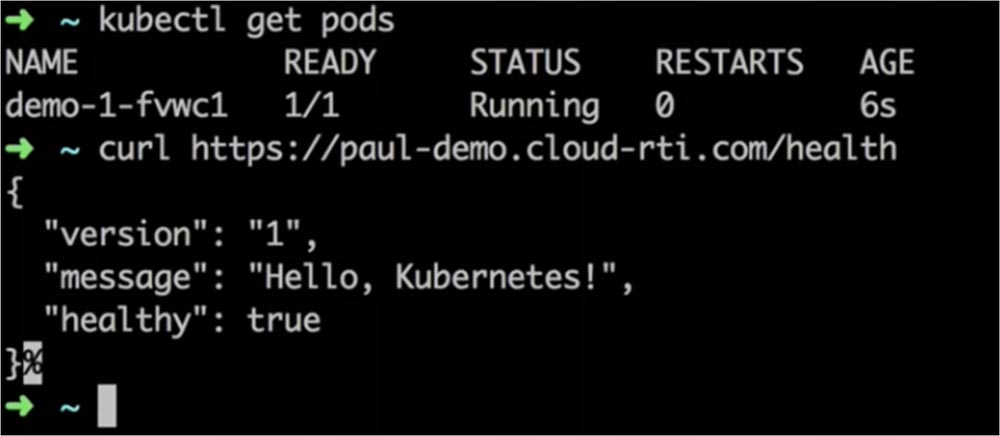
Теперь давайте попробуем вторую версию. Для этого я изменяю message приложения с «Hello, Kubernetes!» на «Hello, Deployer!», система создает этот образ и помещает его в реестр Docker, после чего мы просто еще раз нажимаем на кнопку «Deploy» в окне Deploymentctl. При этом автоматически запускается лог развертывания точно так же, как это происходило при развертывании первой версии приложения.
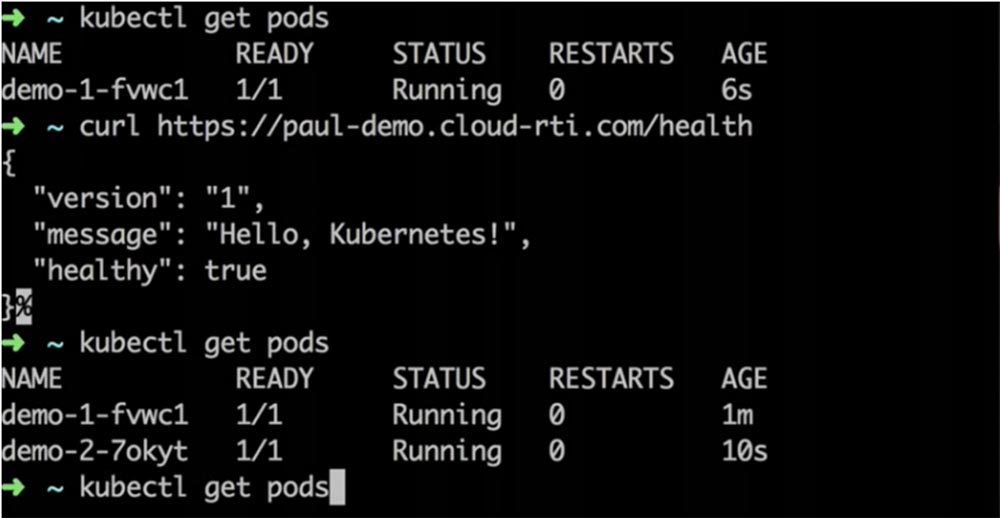
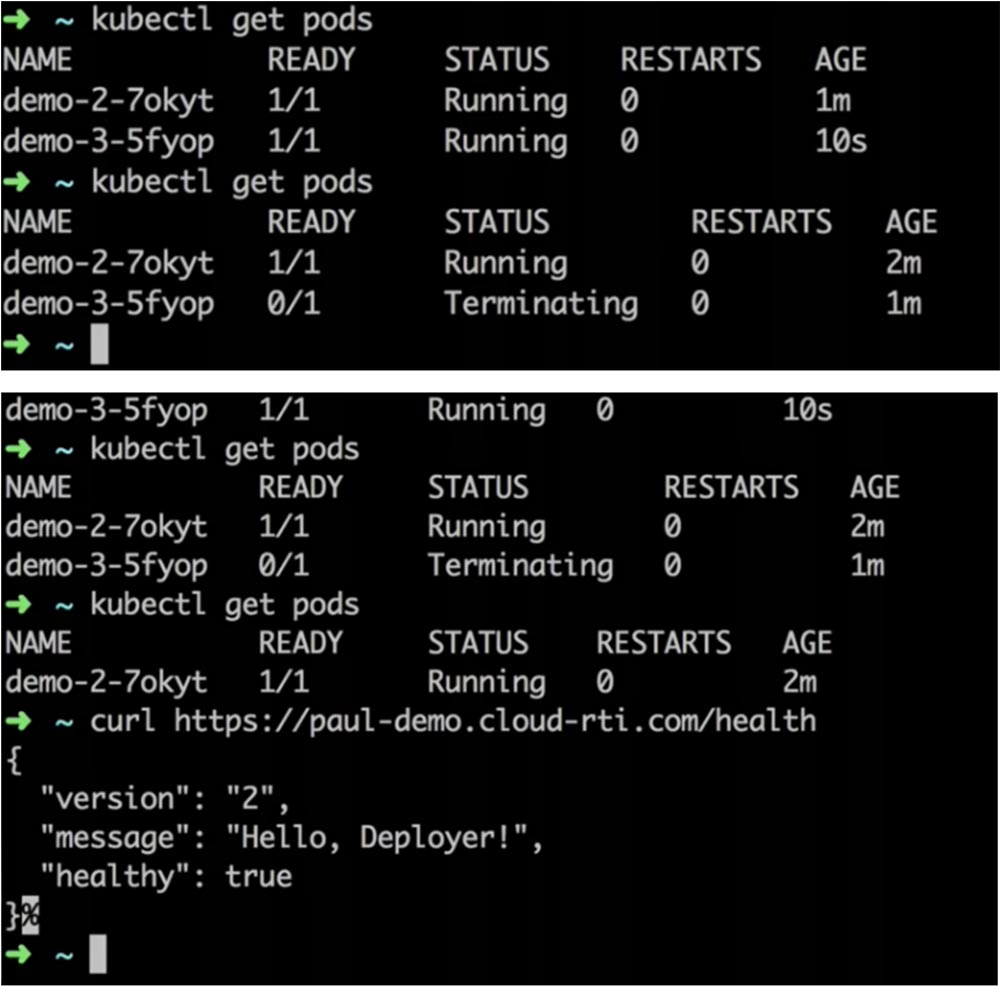
Команда ~ kubectl get pods показывает, что в данный момент запущено 2 версии приложения, однако фронтенд показывает, что у нас все еще работает версия 1.
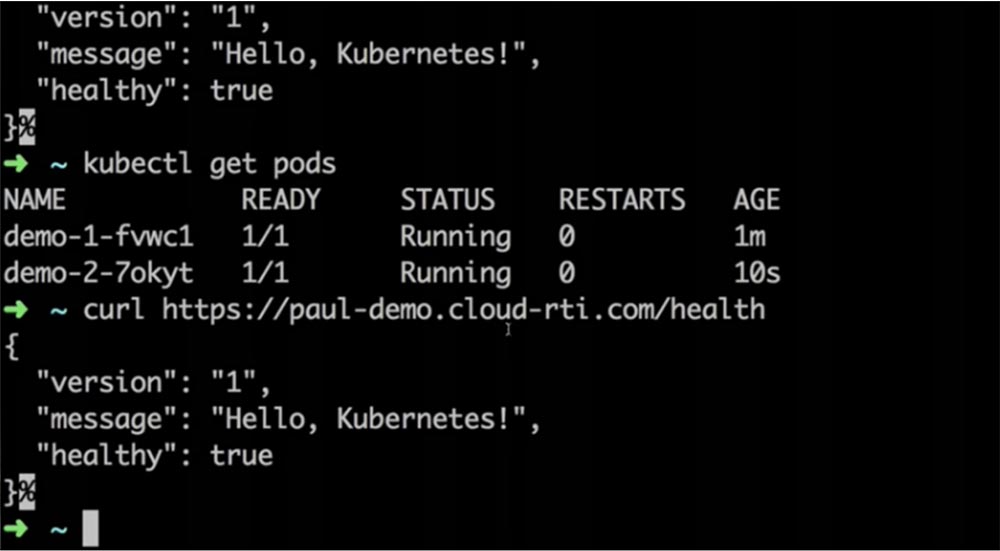
Балансировщик нагрузки ожидает, пока будет проведена проверка health check, после чего перенаправит трафик на новую версию. Спустя 20 с мы переключаемся на curl и видим, что теперь у нас развернута 2 версия приложения, а первая удалена.
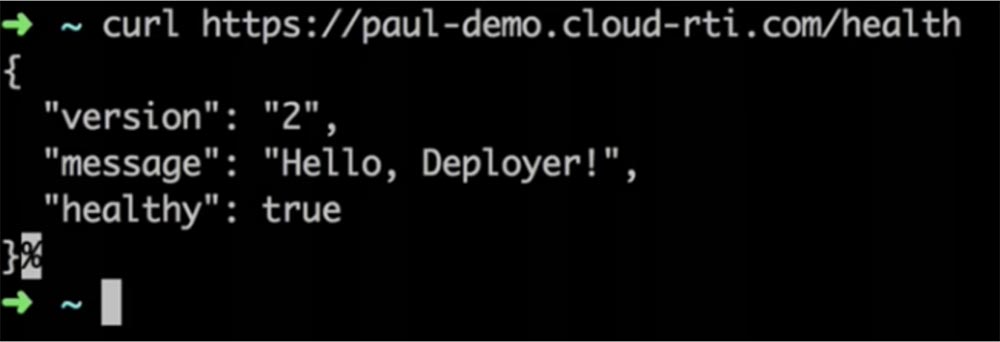
Это было развертывание «здорового» — healthy — приложения. Давайте посмотрим, что произойдет, если для новой версии приложения я изменю значение параметра Healthy с true на false, то есть попробую развернуть unhealthy приложение, которое не прошло проверку работоспособности. Это может произойти, если на стадии разработки в приложении были допущены какие-то ошибки конфигурации, и оно в таком виде отправилось в продакшн.
Как видите, развертывание проходит все вышепоказанные этапы, и ~ kubectl get pods показывает, что запущены оба пода. Но в отличие от предыдущего развертывания, лог показывает состояние timeout. То есть из-за того, что проверка health check не прошла, новая версия приложения не может быть развернута. В результате вы видите, что система вернулась к использованию старой версии приложения, а новая версия была просто удалена.
Хорошо в этом то, что даже если у вас есть огромное количество одновременных запросов, поступающих в приложение, они даже не заметят простоя во время реализации процедуры развертывания. Если протестировать это приложение с помощью фреймворка Gatling, которое посылает ему максимально возможное количество запросов, то не один из этих запросов не будет отброшен. Это означает, что наши пользователи даже не заметят обновления версий в режиме реального времени. Если оно окончится неудачей, работа продолжится на старой версии, если будет удачной – пользователи перейдут на новую версию.
Существует только одна вещь, которая может привести к неудаче – если проверка health check прошла успешно, а приложение дало сбой, как только на него поступила рабочая нагрузка, то есть коллапс наступит только после завершения развертывания. В этом случае вам придется вручную откатиться на старую версию. Итак, мы рассмотрели, как использовать Kubernetes с предназначенными для него open-source инструментами. Процедура развертывания будет проходить намного проще, если вы встроите эти инструменты в конвейеры создания/развертывания Build/Deploy pipelines. При этом для запуска развертывания вы можете использовать как пользовательский интерфейс, так и полностью автоматизировать этот процесс, применив, к примеру, commit to master.
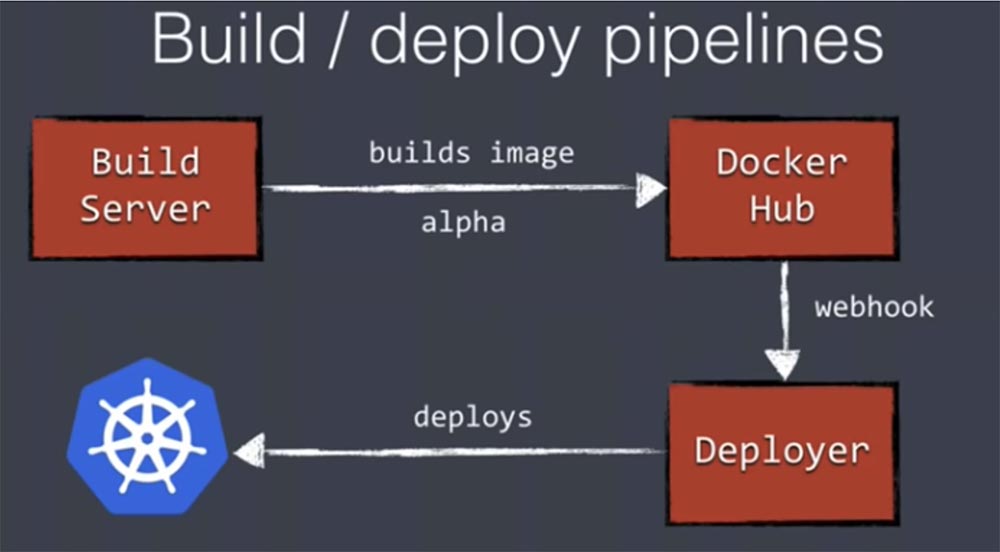
Наш сервер сборки Build Server создаст Docker-образ, вставит его в Docker Hub или любой другой используемый вами реестр. Хаб Docker поддерживает webhook, поэтому мы можем запустить удаленное развертывание через Deployer показанным выше путем. Таким образом можно полностью автоматизировать развертывание приложения в потенциальный продакшн.
Перейдем к рассмотрению следующей темы – масштабированию кластера Kubernetes. Замечу, что команда kubectl является командой масштабирования. С еще помощью можно легко увеличить количество реплик в имеющемся у нас кластере. Однако на практике мы обычно хотим увеличивать количество не подов, а нодов.

При этом в рабочее время вам может понадобиться увеличение, а в ночное время, для сокращения стоимости услуг Amazon – уменьшение количества запущенных экземпляров приложения. Это не означает, что будет достаточно масштабировать только количество подов, потому что даже если один из нодов будет ничем не занят, вам все равно придется платить за него Amazon. То есть наряду с масштабированием подов вам понадобиться масштабировать и число используемых машин.
Это может вызвать сложности, потому что не зависимо от того, используем ли мы Amazon или другой облачный сервис, Kubernetes ничего не знает о количестве используемых машин. В нем отсутствует инструмент, позволяющий масштабировать систему на уровне нодов.

Так что нам придется позаботиться и о нодах, и о подах. Мы можем легко масштабировать запуск новых нодов при помощи AWS API и машин группы масштабирования Scaling group для настройки количества рабочих узлов Kubernetes. Также можно использовать cloud-init или подобный ему скрипт для регистрации нодов в кластере Kubernetes.
Новая машина стартует в Scaling group, инициирует себя как нод, прописывается в реестре мастера и начинает работу. После этого можно увеличить количество реплик для использования на образовавшихся нодах. Уменьшение масштаба требует больший усилий, так как необходимо убедиться, что подобный шаг не приведет к уничтожению уже работающих приложений после отключения «ненужных» машин. Для предотвращения такого сценария нужно привести ноды к статусу «unschedulable». Это означает, что планировщик по умолчанию при планировании подов DaemonSet будет игнорировать эти ноды. Планировщик не станет ничего удалять с этих серверов, но и будет запускать там никаких новых контейнеров. Следующих шаг заключается в вытеснении узла drain node, то есть в переносе с него работающих подов на другую машину, или другие ноды, обладающие достаточной для этого емкостью. Убедившись, что на этих узлах больше нет никаких контейнеров, их можно удалить из Kubernetes. После этого для Kubernetes они просто перестанут существовать. Далее нужно использовать AWS API для отключения ненужных узлов, или машин.
Вы можете использовать Amdatu Scalerd — еще один open-source инструмент для масштабирования, аналогичный AWS API. Он предоставляет CLI для добавления или удаления нодов в кластере. Его интересной особенностью является возможность настроить планировщик при помощи следующего json-файла.
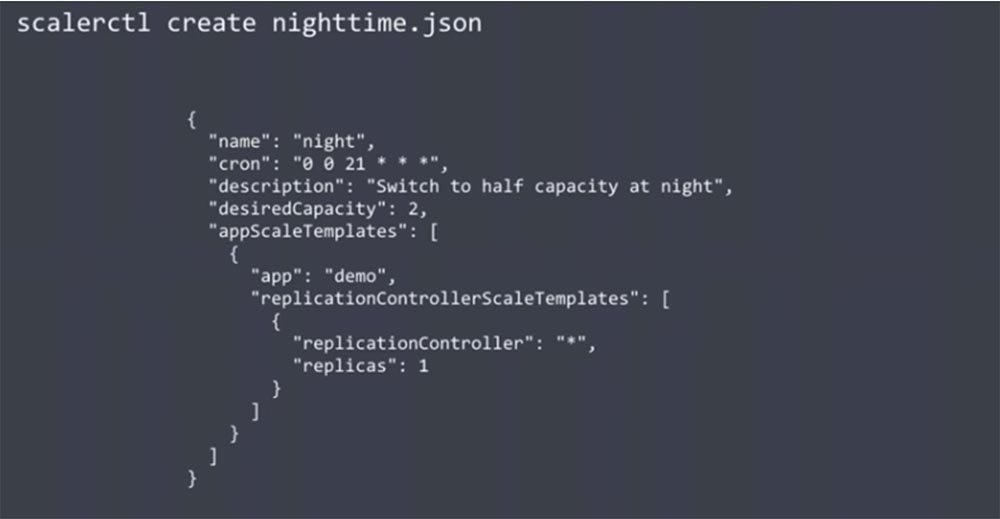
Изображенный код наполовину уменьшает емкость кластера в ночной период времени. В нем настроено как количество имеющихся реплик, так и желаемая емкость кластера Amazon. Использование этого планировщика автоматически уменьшит количество узлов ночью и увеличит их утром, позволив сэкономить стоимость использования нодов такого облачного сервиса, как Amazon. Эта функция не встроена в Kubernetes, но использование Scalerd позволит вам как угодно масштабировать эту платформу.
Хочу обратить ваше внимание на то, что многие люди говорят мне: «Все это хорошо, но как насчет моей базы данных, которая обычно пребывает в статичном состоянии?» Каким образом можно запустить нечто подобное в такой динамической среде, как Kubernetes? На мой взгляд, вы не должны этого делать, не должны пытаться организовать работу хранилища данных в Kubernetes. Технически это возможно, и в интернете есть руководства по этому вопросу, однако это серьезно осложнит вашу жизнь.
Да, в Kubernetes существует понятие постоянных хранилищ, и вы можете попытаться запускать такие хранилища данных, как Mongo или MySQL, но это достаточно трудоемкая задача. Это связано с тем, что хранилища данных не полностью поддерживают взаимодействие с динамическим окружением. Большинство баз данных требуют значительной настройки, в том числе ручной настройки кластера, не любят автомасштабирование и прочие подобные штуки.
Поэтому не стоит усложнять себе жизнь, пытаясь запустить хранилище данных в Kubernetes. Организуйте их работу традиционным способом с использование привычных сервисов и просто предоставьте Kubernetes возможность ими пользоваться.
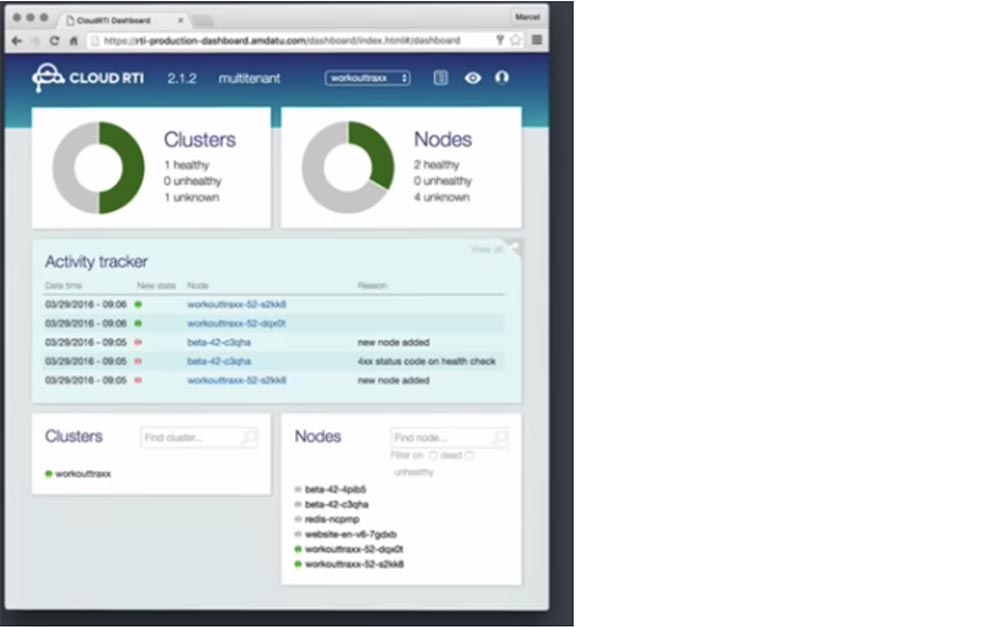
В завершение темы хочу вас познакомить с платформой Cloud RTI на базе Kubernetes, над которой работает моя команда. Она обеспечивает централизованное ведение логов, мониторинг приложений и кластеров и обладает множеством других полезных функций, которые вам пригодятся. В ней используются различные open-source инструменты, такие как Grafana для отображения мониторинга.

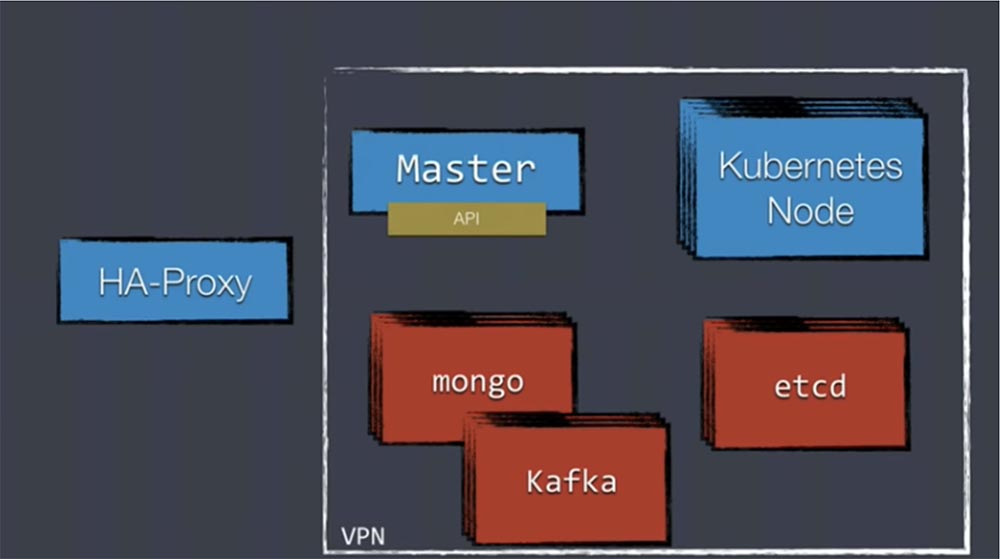
Прозвучал вопрос, зачем использовать с Kubernetes балансировщик нагрузки ha-proxy. Хороший вопрос, потому что в настоящее время существует 2 уровня балансировки нагрузки. Сервисы Kubernetes до сих пор находятся на виртуальных IP-адресах. Вы не можете использовать их для портов внешних хост-машин, потому что если Amazon перегрузит свой облачный хост, адрес поменяется. Вот почему мы размещаем перед сервисами ha-proxy — чтобы создать более статическую структуру для бесперебойного взаимодействия трафика с Kubernetes.
Еще один хороший вопрос – как можно позаботиться об изменении схемы базы данных при осуществлении blue/green deployment? Дело в том, что независимо от использования Kubernetes, изменение схемы базы данных сложная задача. Вам нужно обеспечить совместимость старой и новой схемы, после чего вы сможете обновить базу данных и затем обновить сами приложения. Вы можете выполнить «горячую замену» hot swapping базы данных, а затем обновить приложения. Я знаю людей, которые загружали совершенно новый кластер базы данных с новой схемой, это вариант, если у вас имеется schemeless база данных типа Mongo, но в любом случае это не простая задача. Если больше вопросов нет, благодарю за внимание!
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Хотя Kubernetes не обладает этими функциями прямо «из коробки», он предоставляет API, которым можно воспользоваться для решения подобных задач. Инструменты для автоматизированного Blue/Green развертывания и масштабирования кластера Kubernetes были разработаны в рамках проекта Cloud RTI, который создавался на основе open-source.
В этой статье, расшифровке видео, рассказывается, как настроить Kubernetes вместе с другими компонентами с открытым исходным кодом для получения готовой к производству среды, которая без простоев в продакшене воспринимает код из коммита изменений git commit.
DEVOXX UK. Kubernetes в продакшене: Blue/Green deployment, автомасштабирование и автоматизация развертывания. Часть 1
Итак, после того как вы получили доступ к своим приложениям из внешнего мира, можно приступать к полной настройке автоматизации, то есть довести ее до стадии, на которой можно выполнить git commit и убедиться в том, что этот git commit заканчивается в продакшене. Естественно, что при реализации этих шагов, при осуществлении развертывания, мы не хотим сталкиваться с простоями. Итак, любая автоматизация в Kubernetes начинается с API.
Kubernetes не тот инструмент, который можно продуктивно использовать «прямо из коробки». Конечно, вы можете так делать, использовать kubectl и так далее, но все же API является самой интересной и полезной вещью этой платформы. Используя API как набор функций, вы можете получить доступ практически ко всему, что хотите сделать в Kubernetes. Сам по себе kubectl также использует REST API.
Это REST, так что вы можете использовать для работы с этим API любые языки и инструменты, но вашу жизнь значительно облегчат пользовательские библиотеки. Моя команда написала 2 такие библиотеки: одну для Java / OSGi и одну для Go. Вторая используется не часто, но в любом случае в вашем распоряжении имеются эти полезные вещи. Они представляют собой частично лицензионный open-source проект. Существует множество таких библиотек для различных языков, так что вы можете выбрать наиболее подходящие.
Итак, прежде чем приступить к автоматизации развертывания, необходимо убедиться, что этот процесс не будет подвержен никаким простоям. Например, наша команда проводит продакшн-развертывание в середине дня, когда люди максимально используют приложения, поэтому очень важно избегать задержек в этом процессе. Для того, чтобы избежать простоев, используются 2 способа: blue/green развертывание или скользящее обновление rolling update. В последнем случае, если у вас работает 5 реплик приложения, они последовательно обновляются одна за другой. Этот способ отлично работает, но он не подходит, если в процессе развертывания у вас одновременно запущены разные версии приложения. В таком случае вы можете обновить интерфейс пользователя в то время, как бэкенд будет работать со старой версией, и работа приложения будет прекращена. Поэтому с точки зрения программирования работа в таких условиях довольно затруднительна.
Это одна из причин, по которой мы предпочитаем использовать blue/green deployment для автоматизации развертывания своих приложений. При таком способе вы должны убедиться, что в определенный момент времени активна только одна версия приложения.
Механизм blue/green deployment выглядит следующим образом. Мы получаем трафик для своих приложений через ha-proxy, который направляет его запущенным репликам приложения одной и той же версии.
Когда осуществляется новое развертывание, мы используем Deployer, которому предоставляются новые компоненты, и он осуществляет деплой новой версии. Деплой новой версии приложения означает, что «поднимается» новый набор реплик, после чего эти реплики новой версии запускаются в отдельном, новом поде. Однако ha-proxy ничего об них не знает и пока что не направляет им никакой рабочей нагрузки.
Поэтому в первую очередь необходимо выполнить проверку работоспособности новых версий health cheking, чтобы убедиться в готовности реплик обслуживать нагрузку.
Все компоненты развертывания должны поддерживать какую-либо форму health chek. Это может быть совсем простая проверка HTTP вызовом, когда вы получаете код со статусом 200, либо более глубокая проверка, при которой вы проверяете связь реплик с базой данных и другими сервисами, устойчивость связей динамического окружения, все ли запускается и работает правильным образом. Этот процесс может быть довольно сложным.
После того, как система убедиться в работоспособности всех обновленных реплик, Deployer обновит конфигурацию и передаст правильный confd, который перенастроит ha-proxy.
Только после этого трафик будет направлен в под с репликами новой версии, а старый под исчезнет.
Этот механизм не является особенностью Kubernetes. Концепция Blue/green deployment существует довольно длительное время, и она всегда использовала балансировщик нагрузки. Сначала вы направляете весь трафик к старой версии приложения, а после обновления полностью переводите его на новую версию. Этот принцип используется не только в Kubernetes.
Сейчас я представлю вам новый компонент развертывания – Deployer, который выполняет проверку работоспособности, реконфигурирует прокси и так далее. Это концепт, который не относится ко внешнему миру и существует внутри Kubernetes. Я покажу, как можно создать свой собственный концепт Deployer при помощи open-source инструментов.
Итак, первое, что делает Deployer – это создает контроллер репликации RC, используя API Kubernetes. Этот API создает поды и сервисы для дальнейшего развертывания, то есть создает полностью новый кластер для наших приложений. Как только RC убедится в том, что реплики стартовали, он произведет проверку их работоспособности Health check. Для этого в Deployer используется команда GET /health. Она запускает соответствующие компоненты проверки и проверяет все элементы, обеспечивающие работу кластера.
После того, как все поды сообщили о своем «здоровье», Deployer создает новый элемент конфигурации – распределенное хранилище etcd, которое используется внутри Kubernetes, в том числе для хранения конфигурации балансировщика нагрузки. Мы записываем данные в etcd, и небольшой инструмент confd отслеживает etcd на предмет появления новых данных.
Если он обнаружил какие-то изменения первоначальной конфигурации, то генерирует новый файл настроек и передает его ha-proxy. В этом случае ha-proxy перезагружается без потери каких-либо соединений и адресует нагрузку новым services, которые обеспечивают работу новой версии наших приложений.
Как видите, не смотря на обилие компонентов, здесь нет ничего сложного. Вам просто нужно уделить больше внимания API и etcd. Я хочу рассказать вам об open-source деплоере, которым мы сами пользуемся – это Amdatu Kubernetes Deployer.
Это инструмент для оркестровки развертываний Kubernetes, обладающий такими функциями:
- развертывание Blue/Green deployment;
- настройка внешнего балансировщика нагрузки;
- управление дескрипторами развертывания;
- управление фактическим развертыванием;
- проверка работоспособности Health checks во время развертывания;
- внедрение в поды переменных среды.
Этот Deployer создан на вершине Kubernetes API и предоставляет собой REST API для управления дескрипторами и развертываниями, а также Websocket API для потоковых логов в процессе развертывания.
Он помещает данные конфигурации балансировщика нагрузки в etcd, поэтому вы можете не пользоваться ha-proxy с поддержкой «прямо из коробки», а легко использовать свой собственный файл конфигурации балансировщика. Amdatu Deployer написан на Go, как и сам Kubernetes, и лицензирован Apache.
Перед началом применения этой версии деплоера я воспользовался следующим дескриптором развертывания, в котором указаны нужные мне параметры.
Один из важных параметров этого кода – включение флага «useHealthCheck». Нам нужно указать, что в процессе развертывания необходимо выполнять проверку работоспособности. Этот параметр может быть отключен, когда в развертывании используются контейнеры сторонних разработчиков, которые не нужно проверять. В этом дескрипторе также указано количество реплик и URL фронтенда, который нужен ha-proxy. В конце указан флаг спецификации пода «podspec», который обращается к Kubernetes для получения информации по настройке портов, образу и т.д. Это достаточно простой дескриптор в формате JSON.
Еще один инструмент, который является частью open-source проекта Amdatu, это Deploymentctl. Он имеет пользовательский интерфейс UI для конфигурирования развертывания, хранит историю развертывания и содержит webhooks для обратных вызовов сторонними пользователями и разработчиками. Вы можете не использовать UI, поскольку сам Amdatu Deployer является REST API, но этот интерфейс может намного облегчить вам развертывание без привлечения какого-либо API. Deploymentctl написан на OSGi/Vertx с использованием Angular 2.
Сейчас я продемонстрирую вышесказанное на экране, используя заранее сделанную запись, так что вам не придется ждать. Мы будем развертывать простое приложение на Go. Не беспокойтесь, если до этого не сталкивались с Go, это очень простое приложение, так что вам все должно быть понятно.
Здесь мы создаем HTTP-сервер, который отвечает только на /health, так что это приложение только проверяет работоспособность health check и ничего больше. Если проверка проходит, задействуется показанная внизу JSON-структура. Она содержит версию приложения, которое будет развернуто деплоером, message, который вы видите в верхней части файла, и логический тип данных boolean — работоспособно наше приложение или нет.
С последней строкой я немного схитрил, потому что поместил вверху файла фиксированное значение boolean, которое в дальнейшем поможет мне развернуть даже «нездоровое» приложение. Позже мы с этим разберемся.
Итак, приступим. Сначала проверяем наличие каких-либо запущенных подов с помощью команды ~ kubectl get pods и по отсутствию ответа URL фронтенда убеждаемся, что никаких развертываний в данный момент не производится.
Далее на экране вы видите упомянутый мною интерфейс Deploymentctl, в котором задаются параметры развертывания: пространство имен, имя приложения, версию развертывания, количество реплик, фронтенд-URL, название контейнера, образ, лимиты ресурсов, номер порта для проверки health check и т.д. Лимиты ресурсов очень важны, так как позволяют задействовать максимально возможное количество «железа». Здесь же можно просмотреть журнал развертывания Deployment log.
Если сейчас повторить команду ~ kubectl get pods, видно, что система «замирает» на 20 секунд, в процессе которых происходит реконфигурация ha-proxy. После этого под запускается, и нашу реплику можно увидеть в логе развертывания.
Я вырезал из видео 20-ти секундное ожидание, и сейчас вы видите на экране, что первая версия приложения развернута. Все это было проделано только при помощи UI.
Теперь давайте попробуем вторую версию. Для этого я изменяю message приложения с «Hello, Kubernetes!» на «Hello, Deployer!», система создает этот образ и помещает его в реестр Docker, после чего мы просто еще раз нажимаем на кнопку «Deploy» в окне Deploymentctl. При этом автоматически запускается лог развертывания точно так же, как это происходило при развертывании первой версии приложения.
Команда ~ kubectl get pods показывает, что в данный момент запущено 2 версии приложения, однако фронтенд показывает, что у нас все еще работает версия 1.
Балансировщик нагрузки ожидает, пока будет проведена проверка health check, после чего перенаправит трафик на новую версию. Спустя 20 с мы переключаемся на curl и видим, что теперь у нас развернута 2 версия приложения, а первая удалена.
Это было развертывание «здорового» — healthy — приложения. Давайте посмотрим, что произойдет, если для новой версии приложения я изменю значение параметра Healthy с true на false, то есть попробую развернуть unhealthy приложение, которое не прошло проверку работоспособности. Это может произойти, если на стадии разработки в приложении были допущены какие-то ошибки конфигурации, и оно в таком виде отправилось в продакшн.
Как видите, развертывание проходит все вышепоказанные этапы, и ~ kubectl get pods показывает, что запущены оба пода. Но в отличие от предыдущего развертывания, лог показывает состояние timeout. То есть из-за того, что проверка health check не прошла, новая версия приложения не может быть развернута. В результате вы видите, что система вернулась к использованию старой версии приложения, а новая версия была просто удалена.
Хорошо в этом то, что даже если у вас есть огромное количество одновременных запросов, поступающих в приложение, они даже не заметят простоя во время реализации процедуры развертывания. Если протестировать это приложение с помощью фреймворка Gatling, которое посылает ему максимально возможное количество запросов, то не один из этих запросов не будет отброшен. Это означает, что наши пользователи даже не заметят обновления версий в режиме реального времени. Если оно окончится неудачей, работа продолжится на старой версии, если будет удачной – пользователи перейдут на новую версию.
Существует только одна вещь, которая может привести к неудаче – если проверка health check прошла успешно, а приложение дало сбой, как только на него поступила рабочая нагрузка, то есть коллапс наступит только после завершения развертывания. В этом случае вам придется вручную откатиться на старую версию. Итак, мы рассмотрели, как использовать Kubernetes с предназначенными для него open-source инструментами. Процедура развертывания будет проходить намного проще, если вы встроите эти инструменты в конвейеры создания/развертывания Build/Deploy pipelines. При этом для запуска развертывания вы можете использовать как пользовательский интерфейс, так и полностью автоматизировать этот процесс, применив, к примеру, commit to master.
Наш сервер сборки Build Server создаст Docker-образ, вставит его в Docker Hub или любой другой используемый вами реестр. Хаб Docker поддерживает webhook, поэтому мы можем запустить удаленное развертывание через Deployer показанным выше путем. Таким образом можно полностью автоматизировать развертывание приложения в потенциальный продакшн.
Перейдем к рассмотрению следующей темы – масштабированию кластера Kubernetes. Замечу, что команда kubectl является командой масштабирования. С еще помощью можно легко увеличить количество реплик в имеющемся у нас кластере. Однако на практике мы обычно хотим увеличивать количество не подов, а нодов.
При этом в рабочее время вам может понадобиться увеличение, а в ночное время, для сокращения стоимости услуг Amazon – уменьшение количества запущенных экземпляров приложения. Это не означает, что будет достаточно масштабировать только количество подов, потому что даже если один из нодов будет ничем не занят, вам все равно придется платить за него Amazon. То есть наряду с масштабированием подов вам понадобиться масштабировать и число используемых машин.
Это может вызвать сложности, потому что не зависимо от того, используем ли мы Amazon или другой облачный сервис, Kubernetes ничего не знает о количестве используемых машин. В нем отсутствует инструмент, позволяющий масштабировать систему на уровне нодов.
Так что нам придется позаботиться и о нодах, и о подах. Мы можем легко масштабировать запуск новых нодов при помощи AWS API и машин группы масштабирования Scaling group для настройки количества рабочих узлов Kubernetes. Также можно использовать cloud-init или подобный ему скрипт для регистрации нодов в кластере Kubernetes.
Новая машина стартует в Scaling group, инициирует себя как нод, прописывается в реестре мастера и начинает работу. После этого можно увеличить количество реплик для использования на образовавшихся нодах. Уменьшение масштаба требует больший усилий, так как необходимо убедиться, что подобный шаг не приведет к уничтожению уже работающих приложений после отключения «ненужных» машин. Для предотвращения такого сценария нужно привести ноды к статусу «unschedulable». Это означает, что планировщик по умолчанию при планировании подов DaemonSet будет игнорировать эти ноды. Планировщик не станет ничего удалять с этих серверов, но и будет запускать там никаких новых контейнеров. Следующих шаг заключается в вытеснении узла drain node, то есть в переносе с него работающих подов на другую машину, или другие ноды, обладающие достаточной для этого емкостью. Убедившись, что на этих узлах больше нет никаких контейнеров, их можно удалить из Kubernetes. После этого для Kubernetes они просто перестанут существовать. Далее нужно использовать AWS API для отключения ненужных узлов, или машин.
Вы можете использовать Amdatu Scalerd — еще один open-source инструмент для масштабирования, аналогичный AWS API. Он предоставляет CLI для добавления или удаления нодов в кластере. Его интересной особенностью является возможность настроить планировщик при помощи следующего json-файла.
Изображенный код наполовину уменьшает емкость кластера в ночной период времени. В нем настроено как количество имеющихся реплик, так и желаемая емкость кластера Amazon. Использование этого планировщика автоматически уменьшит количество узлов ночью и увеличит их утром, позволив сэкономить стоимость использования нодов такого облачного сервиса, как Amazon. Эта функция не встроена в Kubernetes, но использование Scalerd позволит вам как угодно масштабировать эту платформу.
Хочу обратить ваше внимание на то, что многие люди говорят мне: «Все это хорошо, но как насчет моей базы данных, которая обычно пребывает в статичном состоянии?» Каким образом можно запустить нечто подобное в такой динамической среде, как Kubernetes? На мой взгляд, вы не должны этого делать, не должны пытаться организовать работу хранилища данных в Kubernetes. Технически это возможно, и в интернете есть руководства по этому вопросу, однако это серьезно осложнит вашу жизнь.
Да, в Kubernetes существует понятие постоянных хранилищ, и вы можете попытаться запускать такие хранилища данных, как Mongo или MySQL, но это достаточно трудоемкая задача. Это связано с тем, что хранилища данных не полностью поддерживают взаимодействие с динамическим окружением. Большинство баз данных требуют значительной настройки, в том числе ручной настройки кластера, не любят автомасштабирование и прочие подобные штуки.
Поэтому не стоит усложнять себе жизнь, пытаясь запустить хранилище данных в Kubernetes. Организуйте их работу традиционным способом с использование привычных сервисов и просто предоставьте Kubernetes возможность ими пользоваться.
В завершение темы хочу вас познакомить с платформой Cloud RTI на базе Kubernetes, над которой работает моя команда. Она обеспечивает централизованное ведение логов, мониторинг приложений и кластеров и обладает множеством других полезных функций, которые вам пригодятся. В ней используются различные open-source инструменты, такие как Grafana для отображения мониторинга.
Прозвучал вопрос, зачем использовать с Kubernetes балансировщик нагрузки ha-proxy. Хороший вопрос, потому что в настоящее время существует 2 уровня балансировки нагрузки. Сервисы Kubernetes до сих пор находятся на виртуальных IP-адресах. Вы не можете использовать их для портов внешних хост-машин, потому что если Amazon перегрузит свой облачный хост, адрес поменяется. Вот почему мы размещаем перед сервисами ha-proxy — чтобы создать более статическую структуру для бесперебойного взаимодействия трафика с Kubernetes.
Еще один хороший вопрос – как можно позаботиться об изменении схемы базы данных при осуществлении blue/green deployment? Дело в том, что независимо от использования Kubernetes, изменение схемы базы данных сложная задача. Вам нужно обеспечить совместимость старой и новой схемы, после чего вы сможете обновить базу данных и затем обновить сами приложения. Вы можете выполнить «горячую замену» hot swapping базы данных, а затем обновить приложения. Я знаю людей, которые загружали совершенно новый кластер базы данных с новой схемой, это вариант, если у вас имеется schemeless база данных типа Mongo, но в любом случае это не простая задача. Если больше вопросов нет, благодарю за внимание!
Немного рекламы :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?