
Порой, будучи дата саентистами, мы забываем за что нам платят. А платят нам за то, что мы в первую очередь разработчики, потом исследователи и, возможно, математики. Наша основная обязанность при этом состоит в том, чтобы быстро создавать работоспособные решения для бизнеса.
Тот факт что мы создаем модели не делает нас особенными. Это не дает нам права писать плохой код.

До того как я пришел к этому пониманию я делал многое не так, как сделал бы сейчас. В этой статье я хотел поделиться некоторыми общеупотребимыми для ML-инженера навыками. По моему мнению, эти же навыки являются наиболее часто отсутствующими в индустрии сейчас.
Людей без таких навков я отношу к категории компьютерно-неграмотных дата саентистов, потому что многие из них по образованию не программисты, а крещенные Курсерой инженеры других специальностей. Я сам был такой же.
Если бы у меня был выбор при найме между отличным дата саентистом и отличным ML разработчиком, я бы нанял второго.
Давайте приступим к делу и на примерах увидим, чего не хватает многим дата саентистам пришедшим из смежных областей и как можно улучшить ситуацию.
01. Научитесь писать абстрактные классы
Как только вы начнете писать абстрактные классы вы увидите, как много ясности это может принести в кодовую базу. Они насаждают одинаковые методы и названия методов. Если много людей работает на одном проекте каждый начинает писать разные методы. Это может создать контрпродуктивный хаос. Абстрактные классы помогают предотвратить это.
02. Фиксируйте инициализирующее значение псевдослучайного генератора.
Воспроизводимость экспериментов очень важна и инициализирующее значение — наш враг. Возьмите его под контоль, иначе различные значения при разных экспериментах изменят разделение на обучающие и тестовые данные и создадут разные начальные веса для нейронных сетей. Это приведет к невоспроизводимым результатам в повторных экспериментах.
03. Начните с небольшого фрагмента данных.
Если ваши данные слишком большие и вы работаете в части кода, имеющей дело с очисткой данных или моделированием, используйте nrows чтобы избежать загрузки всего объема больших данных каждый раз.
Используйте этот прием когда вам нужно всего лишь протестировать код, а не проводить полноценую обработку данных. Это очень полезно если вы работаете на локальной машине, которая с трудом справится с обьемом данных, но вы предпочитаете удобства работы в локальных блокнотах/атоме/иде [прим. переводчика: например, ваш карантинно-удаленный компьютер слабоват]
04. Ожидайте ошибки и исключения ( признак зрелого разработчика)
Всегда проверяйте отсутствующие значения в данных, потому что они создадут проблемы в последующем. Даже если сейчас в ваших нынешних данных нет отсутствующих значений, это не значит что они не появятся в последующих циклах переобучения. Так что проверяйте в любом случае.
05. Отображайте прогресс обработки.
Если вы работаете с большими данными, всегда приятно знать сколько времени займет обработка и на какой стадии процесса мы находимся.
Есть несколько доступных вариантов.
Вариант 1 — tqdm
Вариант 2 — fastprogress
06. Пандас бывает медленным.
Если вы работали с пандасом вы знаете насколько медленным он может быть в некоторых задачах, особенно в группировке.
Вместо того, чтобы ломать голову над крутым способом как ускорить обработку, просто используйте модин заменив одну строчку кода.
[прим. переводчика:
для подобной же цели можно использовать Даск, который я сравнивал с пандасом на практическом примере в прошлой статье.
ряд других способов шире рассмотрен в недавней статье 30mb1]
07. Измеряйте время исполнения функций
Потому что не все функции созданы равными.
Даже если код работает, это не значит, что вы написали хорожий код. Некоторы «мягкие» баги могут сделать ваш код медленнее, поэтому важно их найти. Используйте декоратор чтобы котролировать время исполнения функции.
08. Не тратьте попусту деньги на облачные сервисы.
Никто не любит инженера, который разбазаривает облачные ресурсы.
Некоторые наши эксперименты могут обсчитываться часами. Трудно уследить за всеми и убивать облачный инстанс сразу по окончании вычислений. Я сам так ошибался и я видел людей оставлявших инстансы работающими без нужды на несколько дней. Это особенно часто происходит если запустить обсчитываться в пятницу что-то нужное в понедельник.
Просто вызови эту функцию в конце исполнения кода и это навеки убережет тебя от попадания под раздачу. Чтобы заодно решить вопрос с остановкой кода из-за ошибки, нужно обернуть основной код в try, а команду выключения в except.
09. Создавайте и сохраняйте отчеты.
После определенной точки в моделировании все новые знания приходят из анализа ошибки и метрик. Позаботься о создании и сохранении хорошо оформленных отчетов для себя и менеджмента.
Менеджеры же любят отчеты!
10. Пишите хорошие API
Все плохое, что плохо кончается.
Ты можешь делать качественную очистку данных и моделирование, а в конце все равно устроить какое-то месиво. Мой опыт с людьми подсказывает, что многим непонятно как писать понятные API, писать к ним документацию и поднимать сервер. Я скоро напишу об этом отдельный пост, а пока коснемся вопроса на базовом уровне.
Ниже приведена методология для классического ML/DL деплоя с не слишком высокой нагрузкой до 1000 запросов в минуту
Встречайте связку— Fastapi + uvicorn
У этой связки есть ряд очевидных достоинств.
Скороть- пишите API с помощью fastapi потому что по бенчмаркам это самое быстрое API на питоне.
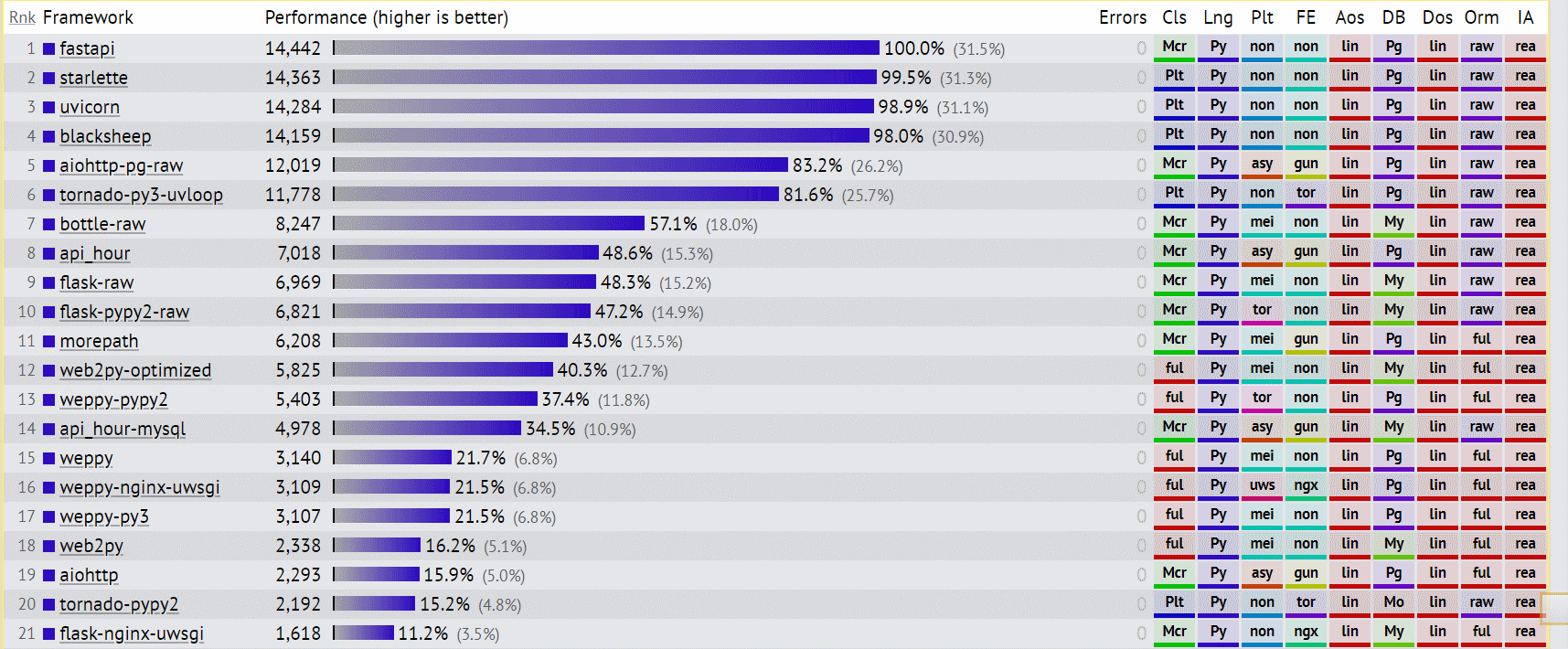
Подробные рассуждения на тему производительности можно найти по ссылке
Документация — написание API с помощью fastapi дает нам без дополнительных усилий автосгенерированную документацию и эндпойнты для тестов.
При обновлении кода документация по адресу http:url/docs обновляется самим fastapi
Воркеры — деплой API используя uvicorn
Команды приведенные ниже запустят приложение с четырьмя воркерами, количество воркеров нужно подобрать в зависимости от нагрузки
Фото на обложке поста — Photo by Chris Ried on Unsplash
Тот факт что мы создаем модели не делает нас особенными. Это не дает нам права писать плохой код.
До того как я пришел к этому пониманию я делал многое не так, как сделал бы сейчас. В этой статье я хотел поделиться некоторыми общеупотребимыми для ML-инженера навыками. По моему мнению, эти же навыки являются наиболее часто отсутствующими в индустрии сейчас.
Людей без таких навков я отношу к категории компьютерно-неграмотных дата саентистов, потому что многие из них по образованию не программисты, а крещенные Курсерой инженеры других специальностей. Я сам был такой же.
Если бы у меня был выбор при найме между отличным дата саентистом и отличным ML разработчиком, я бы нанял второго.
Давайте приступим к делу и на примерах увидим, чего не хватает многим дата саентистам пришедшим из смежных областей и как можно улучшить ситуацию.
01. Научитесь писать абстрактные классы
Как только вы начнете писать абстрактные классы вы увидите, как много ясности это может принести в кодовую базу. Они насаждают одинаковые методы и названия методов. Если много людей работает на одном проекте каждый начинает писать разные методы. Это может создать контрпродуктивный хаос. Абстрактные классы помогают предотвратить это.
Длинный пример
import os
from abc import ABCMeta, abstractmethod
class DataProcessor(metaclass=ABCMeta):
"""Base processor to be used for all preparation."""
def __init__(self, input_directory, output_directory):
self.input_directory = input_directory
self.output_directory = output_directory
@abstractmethod
def read(self):
"""Read raw data."""
@abstractmethod
def process(self):
"""Processes raw data. This step should create the raw dataframe with all the required features. Shouldn't implement statistical or text cleaning."""
@abstractmethod
def save(self):
"""Saves processed data."""
class Trainer(metaclass=ABCMeta):
"""Base trainer to be used for all models."""
def __init__(self, directory):
self.directory = directory
self.model_directory = os.path.join(directory, 'models')
@abstractmethod
def preprocess(self):
"""This takes the preprocessed data and returns clean data. This is more about statistical or text cleaning."""
@abstractmethod
def set_model(self):
"""Define model here."""
@abstractmethod
def fit_model(self):
"""This takes the vectorised data and returns a trained model."""
@abstractmethod
def generate_metrics(self):
"""Generates metric with trained model and test data."""
@abstractmethod
def save_model(self, model_name):
"""This method saves the model in our required format."""
class Predict(metaclass=ABCMeta):
"""Base predictor to be used for all models."""
def __init__(self, directory):
self.directory = directory
self.model_directory = os.path.join(directory, 'models')
@abstractmethod
def load_model(self):
"""Load model here."""
@abstractmethod
def preprocess(self):
"""This takes the raw data and returns clean data for prediction."""
@abstractmethod
def predict(self):
"""This is used for prediction."""
class BaseDB(metaclass=ABCMeta):
""" Base database class to be used for all DB connectors."""
@abstractmethod
def get_connection(self):
"""This creates a new DB connection."""
@abstractmethod
def close_connection(self):
"""This closes the DB connection."""
02. Фиксируйте инициализирующее значение псевдослучайного генератора.
Воспроизводимость экспериментов очень важна и инициализирующее значение — наш враг. Возьмите его под контоль, иначе различные значения при разных экспериментах изменят разделение на обучающие и тестовые данные и создадут разные начальные веса для нейронных сетей. Это приведет к невоспроизводимым результатам в повторных экспериментах.
def set_seed(args):
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if args.n_gpu > 0:
torch.cuda.manual_seed_all(args.seed)
03. Начните с небольшого фрагмента данных.
Если ваши данные слишком большие и вы работаете в части кода, имеющей дело с очисткой данных или моделированием, используйте nrows чтобы избежать загрузки всего объема больших данных каждый раз.
df_train = pd.read_csv(‘train.csv’, nrows=1000)
Используйте этот прием когда вам нужно всего лишь протестировать код, а не проводить полноценую обработку данных. Это очень полезно если вы работаете на локальной машине, которая с трудом справится с обьемом данных, но вы предпочитаете удобства работы в локальных блокнотах/атоме/иде [прим. переводчика: например, ваш карантинно-удаленный компьютер слабоват]
04. Ожидайте ошибки и исключения ( признак зрелого разработчика)
Всегда проверяйте отсутствующие значения в данных, потому что они создадут проблемы в последующем. Даже если сейчас в ваших нынешних данных нет отсутствующих значений, это не значит что они не появятся в последующих циклах переобучения. Так что проверяйте в любом случае.
print(len(df))
df.isna().sum()
df.dropna()
print(len(df))
05. Отображайте прогресс обработки.
Если вы работаете с большими данными, всегда приятно знать сколько времени займет обработка и на какой стадии процесса мы находимся.
Есть несколько доступных вариантов.
Вариант 1 — tqdm
from tqdm import tqdm
import time
tqdm.pandas()
df['col'] = df['col'].progress_apply(lambda x: x**2)
text = ""
for char in tqdm(["a", "b", "c", "d"]):
time.sleep(0.25)
text = text + char
Вариант 2 — fastprogress
from fastprogress.fastprogress import master_bar, progress_bar
from time import sleep
mb = master_bar(range(10))
for i in mb:
for j in progress_bar(range(100), parent=mb):
sleep(0.01)
mb.child.comment = f'second bar stat'
mb.first_bar.comment = f'first bar stat'
mb.write(f'Finished loop {i}.')
06. Пандас бывает медленным.
Если вы работали с пандасом вы знаете насколько медленным он может быть в некоторых задачах, особенно в группировке.
Вместо того, чтобы ломать голову над крутым способом как ускорить обработку, просто используйте модин заменив одну строчку кода.
import modin.pandas as pd
[прим. переводчика:
для подобной же цели можно использовать Даск, который я сравнивал с пандасом на практическом примере в прошлой статье.
ряд других способов шире рассмотрен в недавней статье 30mb1]
07. Измеряйте время исполнения функций
Потому что не все функции созданы равными.
Даже если код работает, это не значит, что вы написали хорожий код. Некоторы «мягкие» баги могут сделать ваш код медленнее, поэтому важно их найти. Используйте декоратор чтобы котролировать время исполнения функции.
import time
def timing(f):
"""Decorator for timing functions
Usage:
@timing
def function(a):
pass
"""
@wraps(f)
def wrapper(*args, **kwargs):
start = time.time()
result = f(*args, **kwargs)
end = time.time()
print('function:%r took: %2.2f sec' % (f.__name__, end - start))
return result
return wrapper
08. Не тратьте попусту деньги на облачные сервисы.
Никто не любит инженера, который разбазаривает облачные ресурсы.
Некоторые наши эксперименты могут обсчитываться часами. Трудно уследить за всеми и убивать облачный инстанс сразу по окончании вычислений. Я сам так ошибался и я видел людей оставлявших инстансы работающими без нужды на несколько дней. Это особенно часто происходит если запустить обсчитываться в пятницу что-то нужное в понедельник.
import os
def run_command(cmd):
return os.system(cmd)
def shutdown(seconds=0, os='linux'):
"""Shutdown system after seconds given. Useful for shutting EC2 to save costs."""
if os == 'linux':
run_command('sudo shutdown -h -t sec %s' % seconds)
elif os == 'windows':
run_command('shutdown -s -t %s' % seconds)
Просто вызови эту функцию в конце исполнения кода и это навеки убережет тебя от попадания под раздачу. Чтобы заодно решить вопрос с остановкой кода из-за ошибки, нужно обернуть основной код в try, а команду выключения в except.
09. Создавайте и сохраняйте отчеты.
После определенной точки в моделировании все новые знания приходят из анализа ошибки и метрик. Позаботься о создании и сохранении хорошо оформленных отчетов для себя и менеджмента.
Менеджеры же любят отчеты!
import json
import os
from sklearn.metrics import (accuracy_score, classification_report,
confusion_matrix, f1_score, fbeta_score)
def get_metrics(y, y_pred, beta=2, average_method='macro', y_encoder=None):
if y_encoder:
y = y_encoder.inverse_transform(y)
y_pred = y_encoder.inverse_transform(y_pred)
return {
'accuracy': round(accuracy_score(y, y_pred), 4),
'f1_score_macro': round(f1_score(y, y_pred, average=average_method), 4),
'fbeta_score_macro': round(fbeta_score(y, y_pred, beta, average=average_method), 4),
'report': classification_report(y, y_pred, output_dict=True),
'report_csv': classification_report(y, y_pred, output_dict=False).replace('\n','\r\n')
}
def save_metrics(metrics: dict, model_directory, file_name):
path = os.path.join(model_directory, file_name + '_report.txt')
classification_report_to_csv(metrics['report_csv'], path)
metrics.pop('report_csv')
path = os.path.join(model_directory, file_name + '_metrics.json')
json.dump(metrics, open(path, 'w'), indent=4)
10. Пишите хорошие API
Все плохое, что плохо кончается.
Ты можешь делать качественную очистку данных и моделирование, а в конце все равно устроить какое-то месиво. Мой опыт с людьми подсказывает, что многим непонятно как писать понятные API, писать к ним документацию и поднимать сервер. Я скоро напишу об этом отдельный пост, а пока коснемся вопроса на базовом уровне.
Ниже приведена методология для классического ML/DL деплоя с не слишком высокой нагрузкой до 1000 запросов в минуту
Встречайте связку— Fastapi + uvicorn
У этой связки есть ряд очевидных достоинств.
Скороть- пишите API с помощью fastapi потому что по бенчмаркам это самое быстрое API на питоне.
Подробные рассуждения на тему производительности можно найти по ссылке
Документация — написание API с помощью fastapi дает нам без дополнительных усилий автосгенерированную документацию и эндпойнты для тестов.
При обновлении кода документация по адресу http:url/docs обновляется самим fastapi
Воркеры — деплой API используя uvicorn
Команды приведенные ниже запустят приложение с четырьмя воркерами, количество воркеров нужно подобрать в зависимости от нагрузки
pip install fastapi uvicorn
uvicorn main:app --workers 4 --host 0.0.0.0 --port 8000
Фото на обложке поста — Photo by Chris Ried on Unsplash
masai
Некоторые советы новичковые.
Можно сократить до «научитесь писать код». Где-то абстрактные классы уместны, а где-то неуместны.
Для инициализации генератора случайных чисел в PyTorch достаточно одного вызова
torch.manual_seed, он инициализирует все устройства, как CPU, так и GPU. И если используется CuDNN, то этого недостаточно, нужно ещё добавить такие строчки:При этом просядет производительность, а детерминированность всё равно не будет гарантирована. См. руководство по воспроизводимости в документации PyTorch.
А вот это отличный совет.
И где в примере кода обрабатываются ошибки и исключения? И раз уж заговорили о зрелости, то, наверное, вместо
printстоит использовать логирование. Тем более, есть замечательная библиотекаloguru, которая всё сильно упрощает.Полезный совет.
В modin и dask отличается API. Бездумно заменять не стоит. Более того, можно даже замедлить работу. В документации к Dask написано, когда стоит его использовать, а когда нет.
Если писать логи, то и без декораторов, что быстро работает, а что нет. А для профилирования удобнее использовать py-spy.
Логично. :)
Хороший совет.
И не пишите плохие. :) Этот совет уже не совсем относится к анализу данных. Не уверен, что он релевантен.
Matshishkapeu Автор
Про то что часть советов новичковые — да, была даже мысль добавить в название ' начинающего ML-разработчика'. Но его нет в оригинале, а меня и так терзали мысли, что я неправильно перевожу 'Боромир улыбнулся'. Тащемта, мне кажется что во многих подборках 'x ништяков для y', самое ценное в начале и конце, а серединку принято наполнять из менее ценного, для солидности.