

Зачем вообще нужна децентрализация? Многие люди не совсем понимают смысла, ведь и так вроде все хорошо работает. Причин на самом деле несколько, но обычно сторонники подхода затрагивают только сложные технические моменты, и обывателю становится сложно углядеть суть. Для меня, например, все очень просто.
Допустим, ты запустил классный проект. С развитием, он начнет требовать все больших компьютерных ресурсов. Проблема в том, что среднестатический человек весьма ограничен в средствах. Но если твоя идея заинтересует других людей, то они смогут самостоятельно запускать свои сервера, изменять и добавлять новый функционал, расширять общие возможности и.т.д. При этом издержки не такие значительные для отдельного человека. Они распределяются между всеми, а итоговый профит для каждого суммируется. Это дает возможность простым людям создавать не простые решения.
По сути, это альтернатива текущему, доминирующему варианту, когда тебе нужно искать инвесторов, которые оплатят весь банкет. Только в этом случае, зачастую, придется закрывать проект от внешнего мира и полностью зависеть от этих людей, мириться с любыми решениями, потому что это "хорошо для бизнеса" и.т.д. В какой-то момент, ты можешь даже оказаться лишним элементом, и с тобой попрощаются.
Если какая-то идея может быть эффективно реализована децентрализованным способом, лучше так и делать. Когда критическая масса дойдет до этого, то появятся много стандартизированных и удобных механизмов для реализации более высокоуровневых решений. А пока, давайте рассмотрим один простенький алгоритм для создания децентрализованной сети — spreadable.
Вариант номер один: одноуровневый
Узлы могут выполнять две роли: master и slave (M и S). Роли распределяются рандомно и могут быть изменены в любой момент. То есть ни один узел не имеет реального преимущества над другим. Роль M нужна для ведения списков S, чтобы соединить всех в одну сеть, и в дальнейшем получать и отправлять информацию. Количество M всегда стремится к квадратному корню от размера сети: если в сети 9 узлов, то M будет 3 штуки. Каждый M ведет свой список S. Количество S в одном таком списке тоже всегда стремится к квадратному корню. В итоге, при 9 узлах у нас будет 3 M и у каждого в списке по 3 S. Информация о том, какие узлы выполняют роль M передается и хранится у всех узлов в режиме синхронизации.
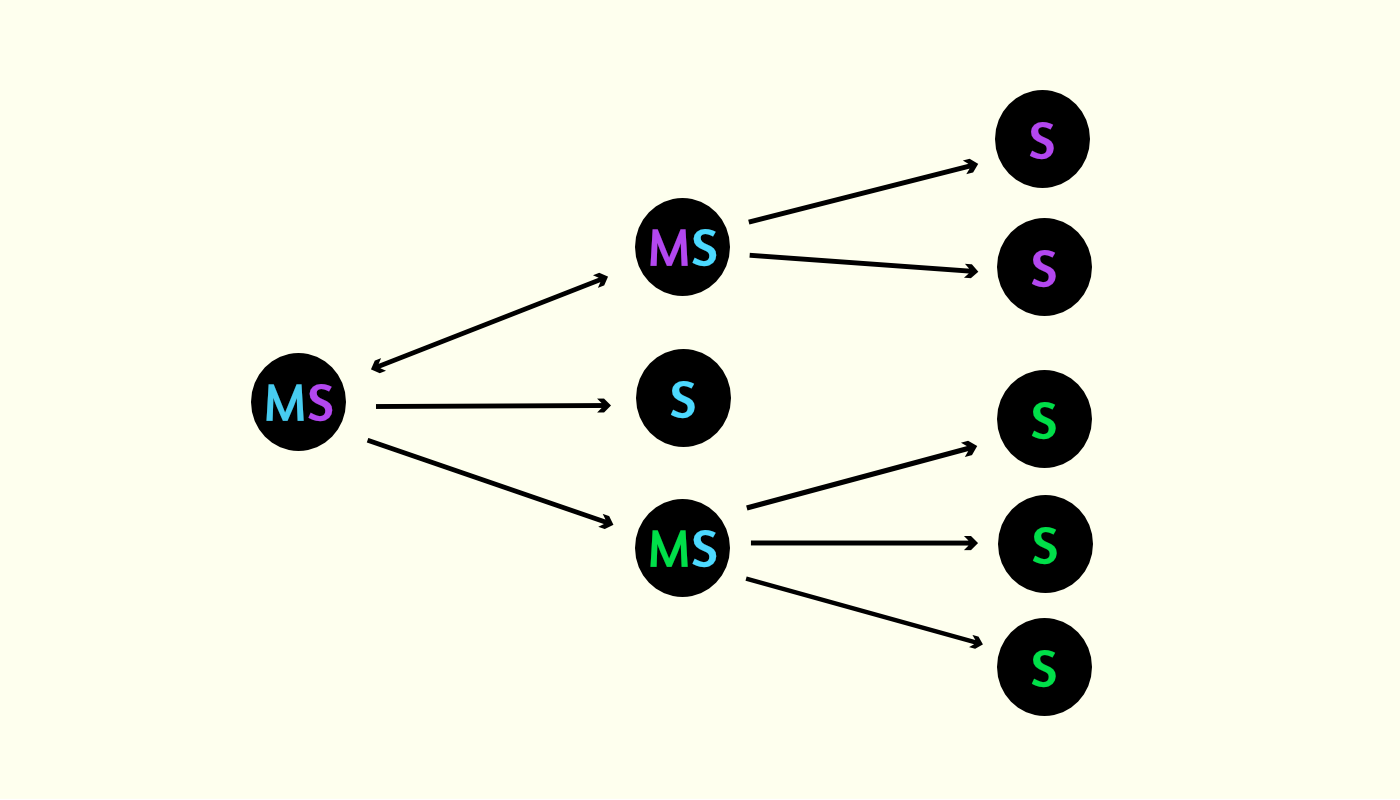
Обход сети происходит следующим образом:
- Клиент хочет совершить какое-то действие
- Для него подбирается координатор — рандомный узел, который запустит весь процесс.
- Координатор, как и любой узел имеет список всех M, поэтому он делает нужный клиенту запрос на все эти узлы параллельно.
- Каждый M при этом делает нужный запрос всем S в своем списке, тоже параллельно.
- В итоге, вся нужная информация собирается, фильтруется, превращается в какой-то результат и возвращается клиенту.
Давайте посчитаем сколько времени на все это уходит. Рассмотрим идеальный вариант. Допустим среднее время одного запроса 50ms. Тогда у нас получается общее время 3 * 50 = 150 ms вне зависимости от размера сети.
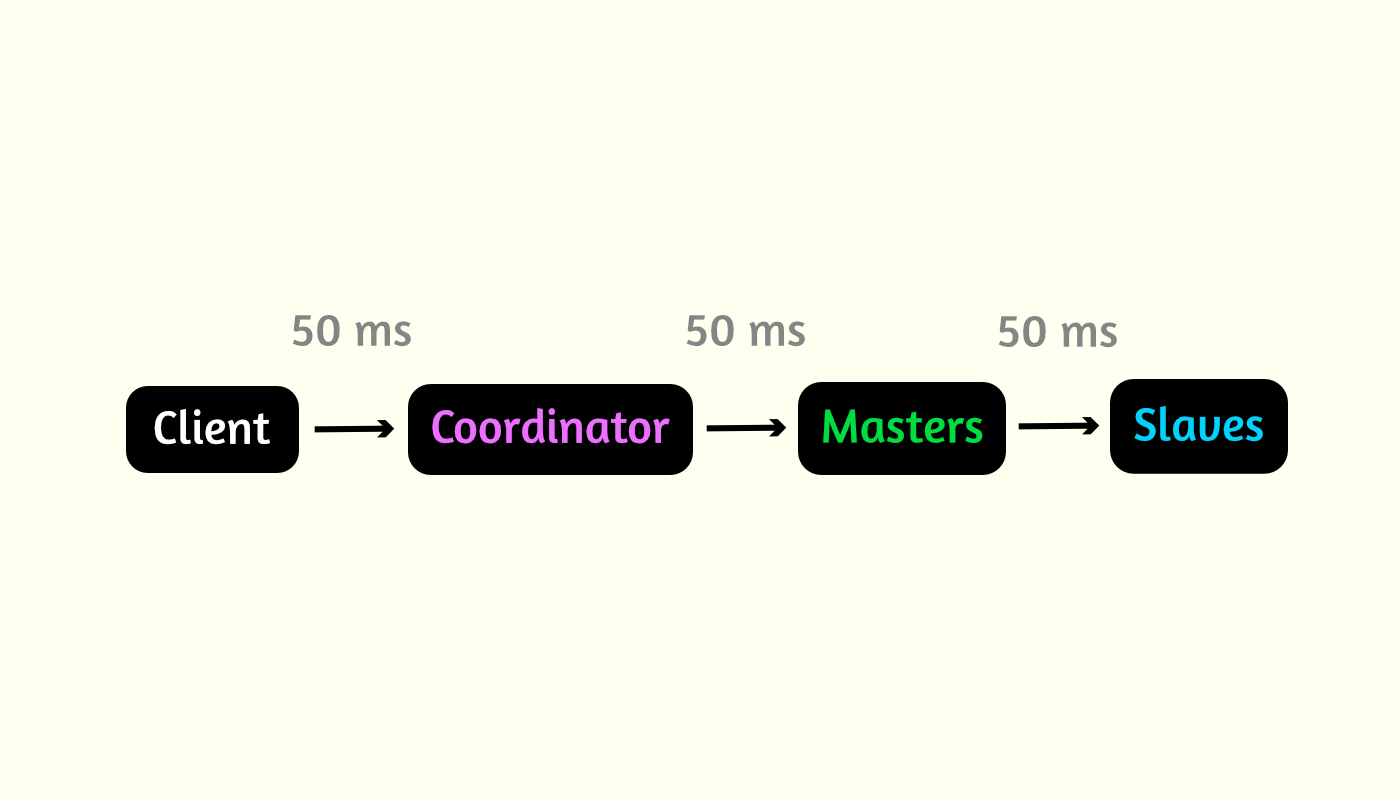
В реальности же каждый узел может отвечать с разной скоростью, либо вообще виснуть. Для этого реализован механизм таймаутов, который позволяет на каждом этапе, и в целом, контролировать допустимые отклонения.
Плюсы данного алгоритма:
- Относительная легкость в реализации
- Очень быстрый обход сети при большом количестве узлов
- Высокая устойчивость к подключению/отключению узлов и смене ролей
- Приемлемое количество работы для предотвращения атак Сивиллы
- Максимальная близость к одноранговости, несмотря на гибридность
Минусы:
- Возможность эффективного совершения параллельных запросов ограничена ОС и ресурсами сервера.
- Чем больше список у каждого мастера, тем дольше обработка данных.
Эти минусы ограничивают максимальный размер сети. По моим прикидкам 10000-100000 узлов это предел эффективной работы. Такое количество узлов достаточно для решения большинства задач, поэтому я пока остановился на этом алгоритме.
Вариант номер два: многоуровневый
Этот алгоритм почти тот же, только уровней вложенности списков становится бесконечное количество. Размер списка узлов выбирается опционально, а не квадратный корень. Возьмем число 2 для дальнейших примеров. Роль мастеров становится иерархической. Появляются мастера первого уровня, второго и.т.д. (M1, M2 ...). M3 формируют списки M2, M2 -> M1, M1 -> S.
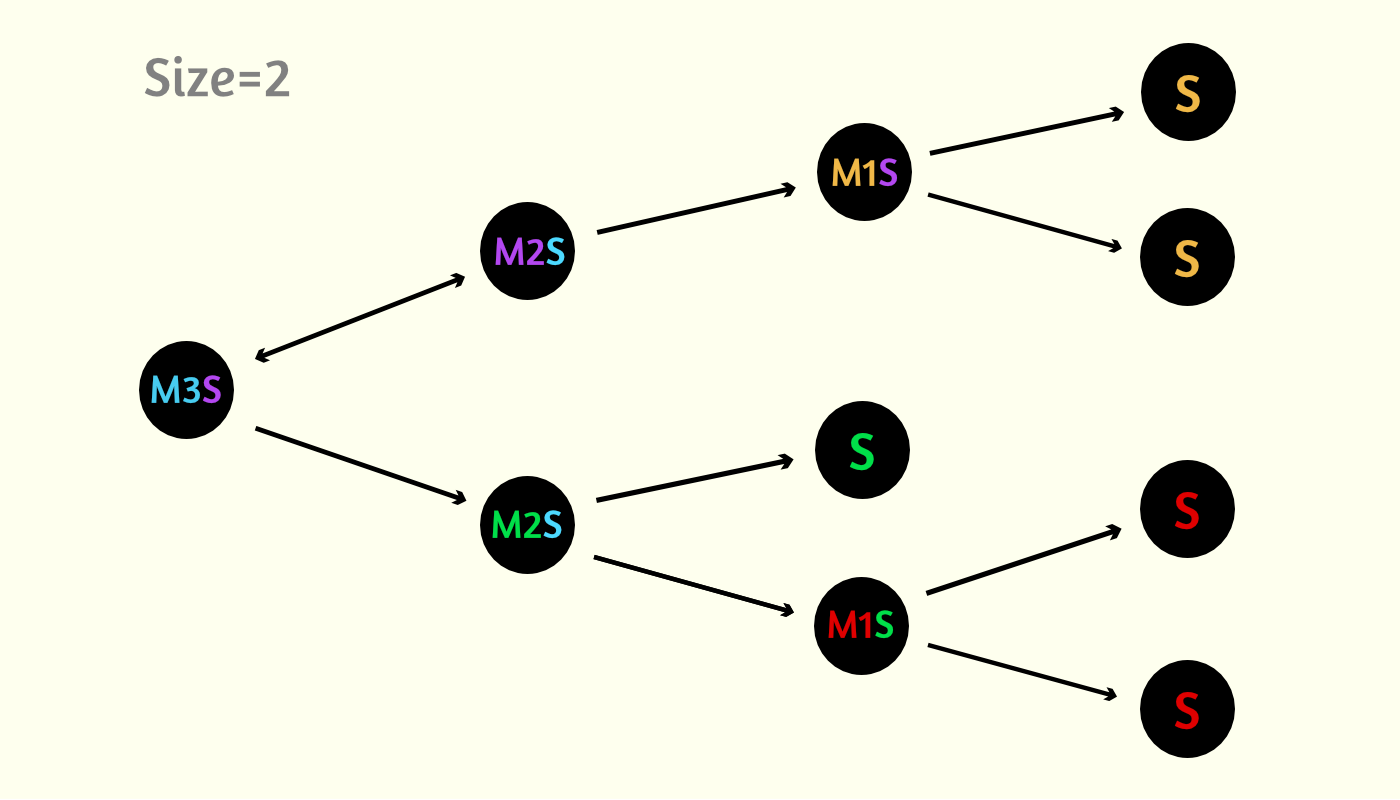
В такой схеме изначально у нас один уровень. Как только узлов станет больше 4, появится новый уровень и первый M2, когда узлов станет больше 6, появится третий уровень и M3, после 12 узла мы получаем уровень четыре и так далее.
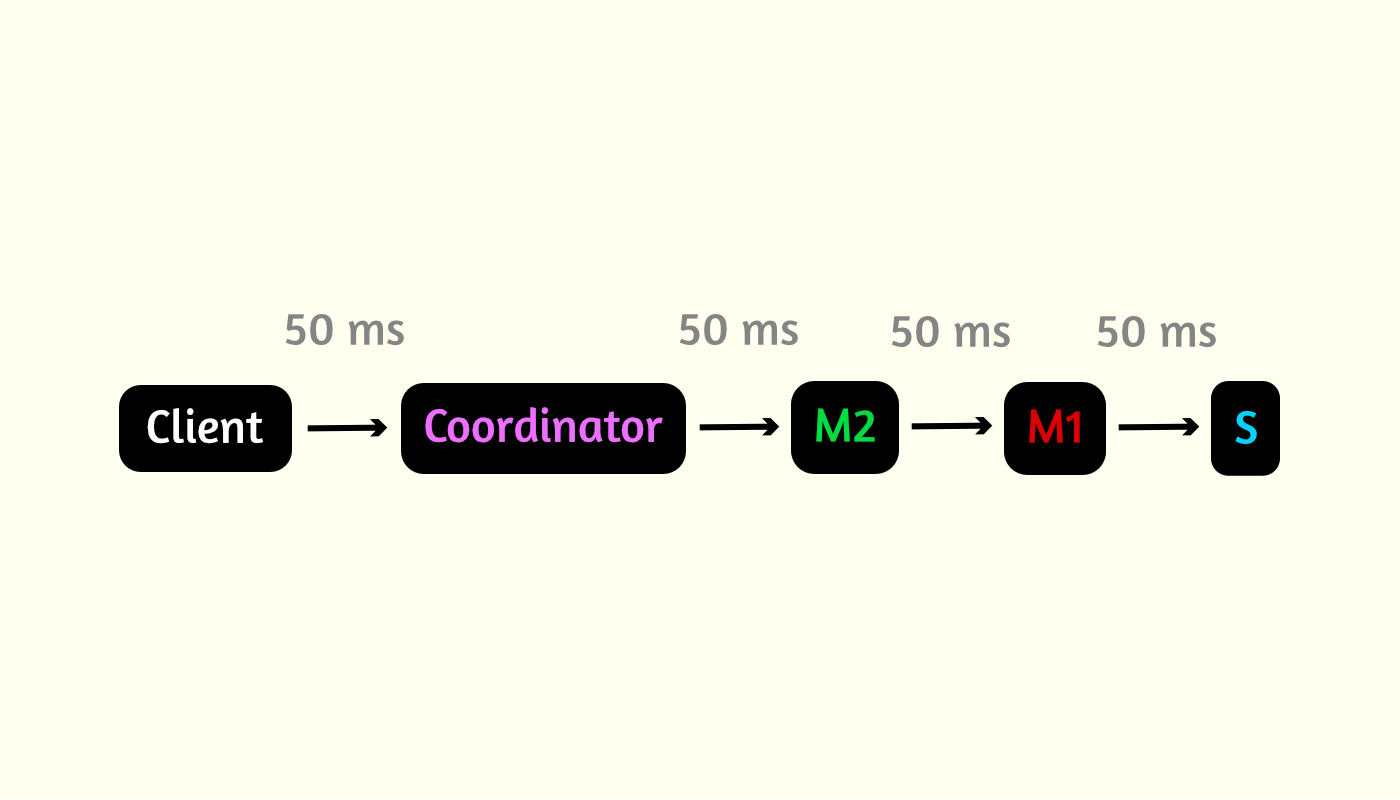
Механизм обхода сети аналогичен первому алгоритму, только цепочка становится длиннее, в зависимости от выбранного размера списков и количества узлов. При таком подходе с каждым новым уровнем мы получаем задержку результата клиента всего на время одного среднего запроса.
Плюсы данного алгоритма:
- Бесконечная масштабируемость
- Быстрый обход сети при огромном количестве узлов
- Максимальная близость к одноранговости, несмотря на гибридность
Минусы:
- Сложность реализации
- Большое количество работы для предотвращения атак Сивиллы
Безопасность
Децентрализованные сети в той или иной степени уязвимы перед различными атаками Сивиллы. Это когда узел или несколько узлов принадлежат злоумышленнику, который изменяет код таким образом, чтобы как-то скомпрометировать всю сеть. Чем более открыта сеть, тем больше узких мест для воздействия. Навскидку, некоторые наиболее очевидные способы навредить:
- Выдавать клиенту некорректные данные со своего узла.
- Проспамить базу данных, чтобы увеличивать время на обработку данных.
- Сделать все роуты узла висячими, вызывая постоянные таймауты и замедляя время совершения запросов.
- Если в сети есть какая-то система голосования, то можно попробовать набрать критическую массу узлов и влиять на решения.
- Найти узкие места в системе ведения списков и изменить код, вызывая нарушения и задержки в соединении узлов друг с другом.
Децентрализованная сеть очень похожа на человеческое общество. Представьте, что каждый узел — это отдельный человек. Нужно сделать все так, чтобы, несмотря на наличие вредных людей, система, в целом, нормально функционировала. Во время создания всего этого, я миллион раз прокручивал в голове разные варианты поведения узлов и способы балансировки всего этого. Задача это крайне сложная, потому что слишком много вариантов. В итоге, все это свелось к некой системе контроля за поведением узлов.
У каждого узла есть четкие задачи которые он должен выполнять. Особенно много задач в роли мастера. Если узел что-то делает не так, то другие, которые с ним общаются, отмечают эти нарушения у себя. Если же он ведет себя корректно, то отметки снимаются. Что-то вроде кармы или весов. Когда нарушений становится слишком много, узел банится. Все параметры опциональны, на разные нарушения — разная реакция.
Голосование
Было бы полезно, в некоторых случаях, разрешать клиенту совершать какие-то действия только при определенных условиях. Например, пройти капчу сначала, или подтвердить ip адрес, либо что угодно другое. Как в децентрализованной сети можно реализовать подобное? Один из вариантов — это голосование. Прежде чем пользователь сможет что-то сделать, определенная часть узлов должна подтвердить, что клиент имеет на это право. Управление этим происходит с помощью специального сервиса approval. Из коробки уже есть классы для проверки капчи и ip адреса. Для кастомных проверок мы должны отнаследоваться от базового класса и изменить некоторые методы.
Создавая класс, мы можем передавать некоторые базовые опции:
- approversCount — количество узлов из всех имеющихся, которые сформируют совет голосующих. По умолчанию, это квадратный корень от размера сети, но можно указать процент от размера или просто какое-то число.
- decisionLevel — достаточное количество голосов для положительного исхода. По умолчанию, 66.6%. Можно указать просто число.
- period — промежуток времени на которое будет сформирован совет голосующих. По умолчанию, 5 минут.
Опция decisionLevel необходима, так как узлы в любой момент могут подключаться и отключаться. И если в процессе принятия решения один из голосующих узлов выйдет из сети, то клиент получит отказ. Поэтому мы допускаем тут некоторое отклонение.
Давайте рассмотрим как выбираются узлы для голосования. Для каждого узла вычисляется хеш, исходя из его уникальных данных и временного периода. Допустим, approversCount=3, decisionLevel=2, period=10m для какого-то действия. Все полученные хеши сортируются, и первые 3 узла в массиве имеют право голосовать в течение десятиминутного периода. Как только наступит следующая десятиминутка, хэши узлов поменяются, и голосующими станет уже какой-то другой массив узлов.
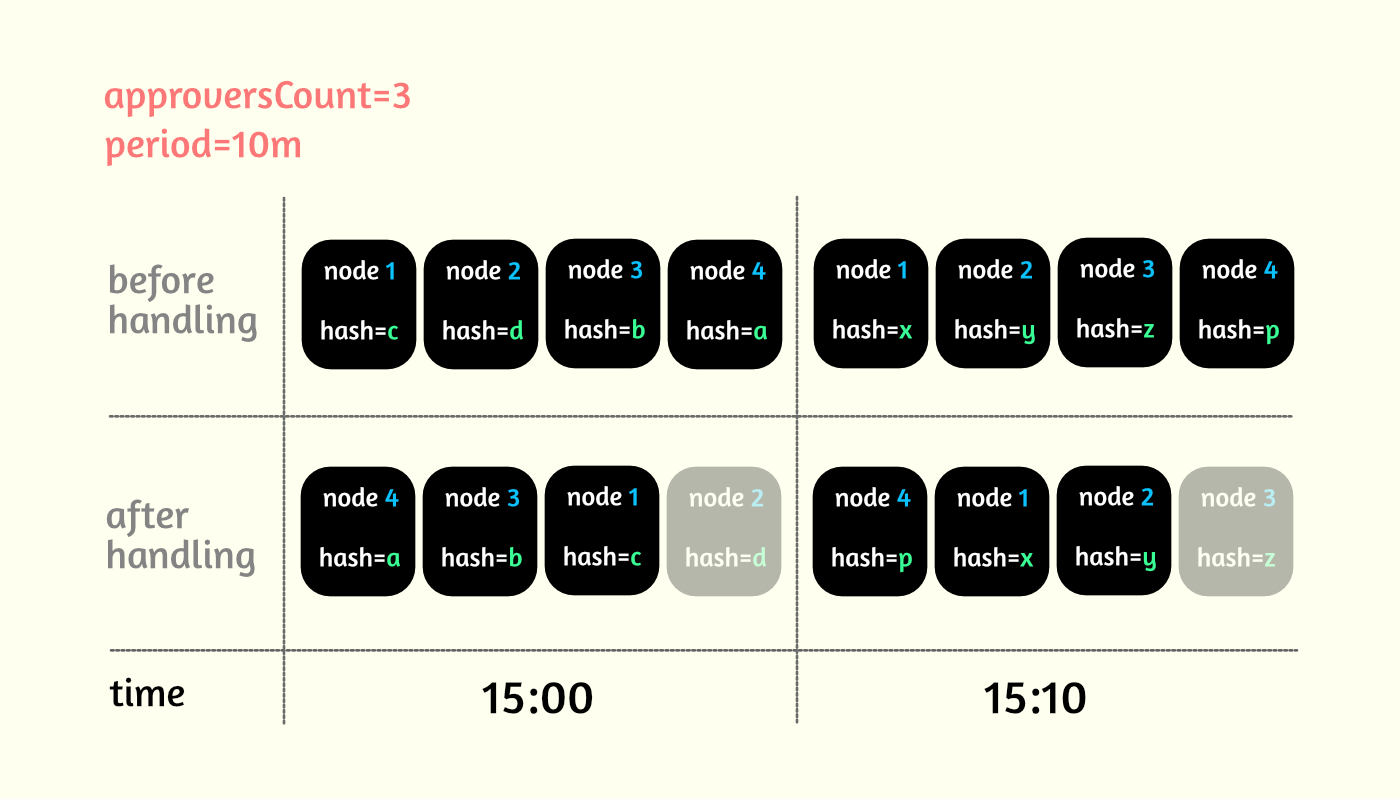
Далее, клиент, перед совершением целевого действия, сначала должен отправить голосующим некоторые данные о себе, через координатора. Они эти данные сохраняют и выдают ему свои требования (капча, например). Пользователь выполняет эти требования и во время нужного запроса дополнительно отправляет доказательства, которые будут проверятся голосующими узлами на истинность. Если хотя бы 2 узла из 3 подтвердят ответ, то клиент получает результат, который ему был нужен.
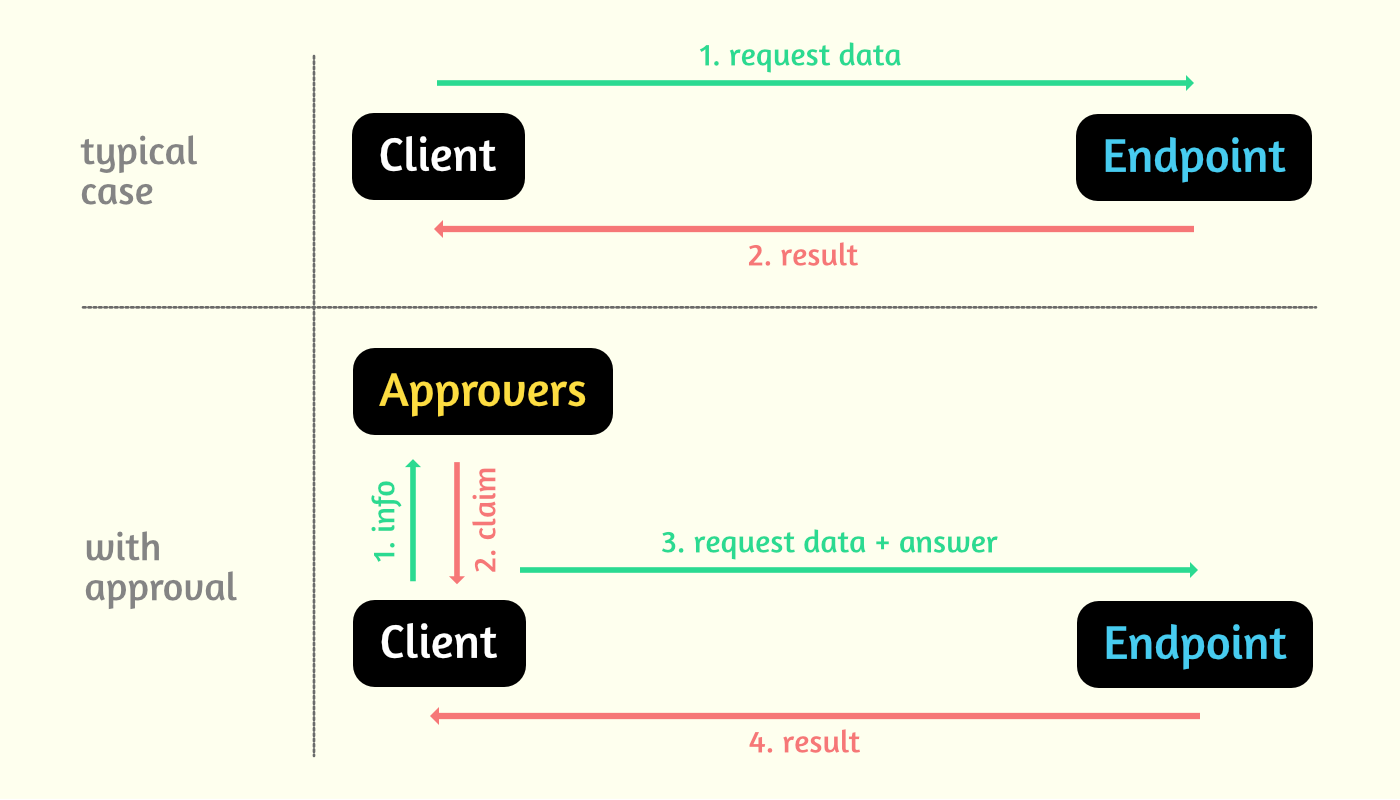
Исходя из настроек в примере, для того, чтобы "взломать алгоритм" нужно иметь контроль над 2 узлами, рассчитать когда именно эти узлы станут одновременно голосующими (при небольшом улучшении алгоритма, можно убрать возможность расчета заранее) из всех имеющихся, переписать кучу кода и тогда, в течение какого-то десятиминутного периода раз в N времени можно делать запросы без проверок.
Но количество голосующих узлов можно указывать самому, это могут быть сотни и более, при необходимости, что на порядки уменьшает вероятность контроля.
Каптча тут реализована вышеописанным путем.
Синхронизация
Для того, чтобы нормализовать состояние сети используется синхронизация. Через определенный промежуток времени запускается функция, в которой происходят все необходимые проверки и настройки, а также регистрация узла в сети и удаление неактуальной информации. Периоды синхронизации одинаковы для всех. Для регистрации узла нужен проводник. Это любой другой узел, который уже зарегистрирован в сети. Его надо указывать как опцию. Проводником для самого первого узла является он сам. Узел, с которого начинается сеть называется корневым. Если версия вашего узла отличается от версии корневого, то он не будут синхронизирован и не станет частью сети.
Библиотека
Все написано на nodejs. Рассмотрим пример использования:
Сервер:
const Node = require('spreadable').Node;
(async () => {
try {
const node = new Node({
port: 4000,
hostname: 'localhost',
initialNetworkAddress: 'localhost:4000'
});
await node.init();
}
catch(err) {
console.error(err.stack);
process.exit(1);
}
})();Клиент:
const Client = require('spreadable').Client;
(async () => {
try {
const client = new Client({
address: 'localhost:4000'
});
await client.init();
}
catch(err) {
console.error(err.stack);
process.exit(1);
}
})();Для поднятия узла работаем с классом Node. Для подключения и работы с сетью используем Client.
Некоторые особенности:
- Сеть работает через http протокол. Можно также настроить https.
- Чтобы запустить узел нужно как минимум указать порт (port) и точку входа (initialNetworkAddress). Точка входа — это любой другой узел, который уже зарегистрирован в сети. Также можно вручную передать имя хоста (hostname).
- Идентификатором узла является адрес. Он формируется как хост: порт. Хост может быть доменным именем или IP-адресом. Для ipv6 это [ip]: порт.
- Сеть может быть как открытой, так и закрытой. Для ее закрытия можно использовать базовую аутентификацию или перезаписать методы фильтрации запросов.
- Клиент библиотеки изоморфен, можно работать из браузера.
- Можно работать с узлом из командной строки.
Более подробно информация выше описана в readme.
Чего пока нет
Сейчас, чтобы использовать механизм и дописать что-то свое, нужно разобраться детально как устроено все изнутри, наследовать все необходимые классы, расширять маршруты и.т.д. С одной стороны это позволяет реализовать что угодно, но с другой стороны требует много времени, чтобы вникнуть. Поэтому в дальнейшем я думаю добавить возможность работы с сетью в стиле событий (EventEmitter). Это ограничит некоторые возможности, но упростит работу, в целом.
На данный момент, можно посмотреть как все наследовать на примере уже имеющихся расширений: metastocle, storacle, museria. Если будет смысл, то напишу как-нибудь статью как расширять и использовать библиотеку для своего проекта.
Мои контакты: