
Некоторое время назад я написал статью, в которой относительно кратко описал механику работы с BI системами на примере IBM Cognos BI. Я решил немного развить тему, и сделать своеобразное «сравнение» аналитических продуктов IBM Cognos и QlikView.
Сам материал публикации нельзя назвать сравнением, это больше инструкция «с чего начать?». Я продемонстрирую как сделать относительно несложный отчет 2-мя инструментами — IBM Cognos BI и QlikView, а вы уже сами решите, какой из них больше вам подходит (или не подходит).
Материал статьи будет изложен в виде комбинации немного текста и много видео (любители почитать могут сходить в статью про IBM Cognos BI). Я надеюсь, что такой способ донесения информации будет удобен и сократит время создания материала
Примечания
- Все материалы статьи готовились с помощью trial версий программного обеспечения (IBM Cognos Express и QlikView Personal Edition). Это значит, что каждый из вас может зайти на официальный сайт, скачать триал версию и повторить все продемонстрированное;
- У меня есть богатый опыт работы с продуктами IBM Cognos (имеется ряд успешных проектов, сертификаты и т. д.), в то же время, опыта работы с продуктами Qlik значительно меньше;
- Зачастую, одна и та же задача может иметь несколько вариантов решения, и если я выбрал и продемонстрировал конкретное решение, это не значит, что именно это решение является лучшим или наиболее оптимальным, просто в настоящий момент я решил выполнить конкретную реализацию именно так.
Постановка задачи
Я много думал какой должна быть тестовая задача. С одной стороны, мне хотелось показать побольше функционала, с другой, чем больше функций я рассмотрю, тем объемней становится материал. В итоге я решил, что рассмотренного материала должно быть достаточно, чтобы непосвященный человек мог начать работу с рассматриваемыми инструментами.
Итак, предположим, что некоторый заказчик предоставил нам образец отчета, сделанного в Excel (см. скриншот) и хочет, чтобы мы сделали такой же, выбранным BI инструментом, на базе их витрины данных.
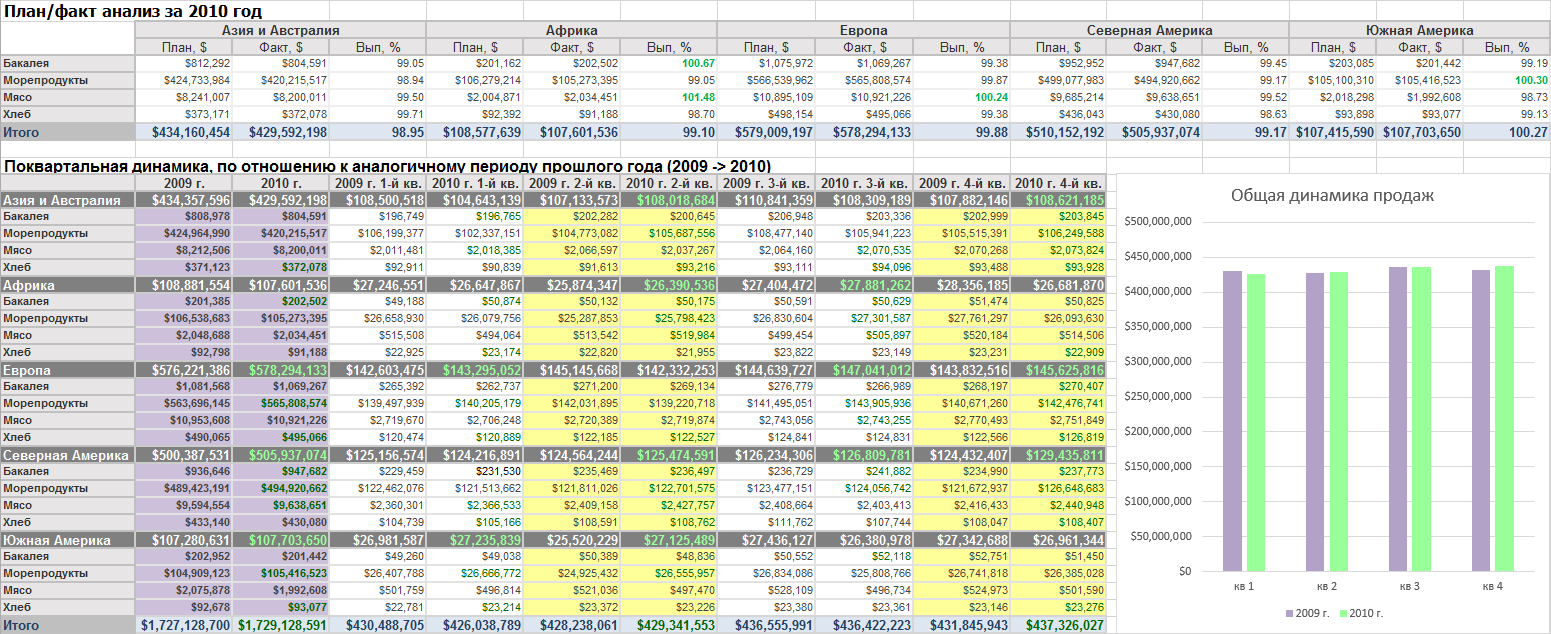
Конечно же, в реальной жизни, реальный заказчик, вряд ли предоставит вам такой структурированный и формализованный образец отчета. Реальные образцы зачастую имеют весьма произвольную форму. Но фактически всегда, все отчеты произвольного вида формализуются и структурируются, а потом реализуются в BI системах.
Также как и с отчетом, клиент вероятнее всего вам не предоставит готовую витрину данных и вам придется ее построить самостоятельно, на базе уже существующего хранилища данных (чаще всего сложного и неоднородного). Но в нашем случае мы уже будем располагать готовой витриной данных.
Метаданные
Если говорить простым языком, то метаданные в BI системах, это механизм, с помощью которого пользователь показывает BI системе каким образом организована система хранения данных и как с этими данными работать. Каждая известная мне BI система имеет механизм метаданных. Метаданные — это не всегда просто информация об источнике данных, в ряде случаев, метаданными выступают внутренние механизмы хранения BI системы (например, OLAP кубы). К примеру, метаданными в Cognos BI является формализованное описание структуры системы хранения данных, а в QlikView — таблицы с данными, загруженные в проприетарное хранилище и механизмы их формирования.
Я могу выделить 2 диаметрально противоположных подхода к разработке метаданных:
- Минималистичный — метаданные включают в себя тот минимум, который необходим для решения конкретной задачи. Чаще всего такой подход применяют тогда, когда необходимо максимально быстро решить конкретную задачу (построить конкретный отчет). Плюсом такого подхода является очень высокая скорость разработки, недостатком — неуниверсальность, отсутствие потенциала к расширению, ограниченные возможности для построения аналитиком произвольных отчетов. Также, при разработке метаданных в быстром темпе, разработчики часто пренебрегают правилами лучших практик;
- Универсальный — метаданные включают в себя максимальное описание источника данных. Такой подход применяют тогда, когда нам необходимо сделать универсальный инструмент для аналитика. Плюсами такого подхода являются высокий потенциал к расширению (обычно в такие метаданные легко добавить новый атрибут, измерение или показатель), универсальность для аналитика (аналитик может быстро и относительно просто строить отчеты фактически любого уровня детализации). Среди недостатков можно отметить длительное время разработки и пониженную скорость работы отчетов на больших объемах данных.
В нашем случае, я постараюсь остановится на золотой середине. Т. е. в метаданные я не буду включать те таблицы, которые не нужны для построения нашего отчета. Но при этом я постараюсь сохранить потенциал к расширению и учесть правила лучших практик.
Метаданные для IBM Cognos BI
Метаданные для QlikView
Отчеты
Когда метаданные готовы, мы можем приступать к разработке отчетов. В процессе разработки отчетов я также буду стараться найти некий компромисс между скоростью разработки отчета и его универсальностью. В принципе все серьезные BI инструменты поддерживают весьма широкий перечень функций (возможность создания параметризованных отчетов, Drill-Down и Drill-Trouth связи, циклическое отображение элементов и т. д.), в данной статье я постараюсь использовать исключительно базовый функционал.
Разработка отчета в IBM Cognos BI
Разработка отчета в QlikView
С моей точки зрения, разрабатывая статический регламентный отчет в QlikView, я поступаю не очень справедливо, т. к. QlikView больше ориентирован на интерактивный анализ данных в режиме реального времени. С другой стороны, моя задача показать базовую механику работы с инструментом, а для этой цели подойдет решение любой тематической задачи.Комментарии (5)

Magister-Ice
01.09.2015 13:06Если говорить именно о хранилищах данных (а не витринах), фактически всегда это либо MS SQL Server, либо Oracle (причем, по сугубо личным наблюдениям, MS SQL Server последнее время стал встречаться значительно чаще).
Тестовая витрина данных (которая используется в настоящем материале) построена на MS SQL Server 2008.
Несколько лет назад (где-то в 2011 году) сталкивался с вертикой, которая использовалась как витрина данных для IBM Cognos BI. В нашем случае были некоторые проблемы с совместимостью (возможно в современном варианте этих проблем уже нет).

SOLON7
01.09.2015 18:18MS SQL щас чаще стал использоватся, так как не требуется специалистов по другим системам.
Щас в новой редакции они еще сделали колоночные индексы, которые существенно в 10 раз быстрее выполяняют запросы.
https://youtu.be/su_SM040xKE?t=1307

DIegoR
05.09.2015 20:41Synthetic Key (как минимум две совпадающие по имени колонки в нескольких таблицах) в Qlikview это антипаттерн. Он не дает пользоваться преимуществами системы (сильно падает скорость), кроме того приводит к неоднозначности в ассоциативной логике в гуе. Дело в том, что Qlikview это колоночная база данных. Колонки с одинаковым именем в разных таблицах — это на самом деле один объект. Синтетический ключ это вынужденный эрзац такого объекта.
Стандартный способ избавления — создание ключа через хеширование конкатенированных (совпадающих) колонок во всех таблицах при загрузке. Потом колонки переименовываются уникальным образом.

FractalizeR
09.09.2015 18:15При разработке схем данных для QlikView рекомендуется делать их более звездообразными и желательно, чтобы «лучей» у звезды было как можно меньше. В большинстве случаев QlikView умеет дедублицировать данные самостоятельно. Поэтому, нормализовывать их как правило нет смысла.
SOLON7
Можно вопрос? А начем у вас построенно хранилище данных ???
Сейчас рассматриваем три варианта, Вертика, MS SQL 2012(колоночные индексы), и Оракл(еще не смотрели).
У вертики проблемы, 1 терабайт бесплатно, после 1 терабайта, 2-ой терабайт стойт 100 тыс бачинских.