

Привет, Хабр!
Наша компания специализируется на разработке программных решений класса ERP, в составе которых львиную долю занимают транзакционные системы с огромным объемом бизнес-логики и документооборотом а-ля СЭД. Современные версии наших продуктов базируются на технологиях JavaEE, но мы также активно экспериментируем с микросервисами. Одно из самых проблемных мест таких решений – интеграция различных подсистем, относящихся к смежным доменам. Задачи интеграции всегда доставляли нам огромную головную боль, независимо от применяемых нами архитектурных стилей, технологических стэков и фреймворков, однако в последнее время в решении таких задач наметился прогресс.
В предлагаемой вашему вниманию статье я расскажу об имеющихся у НПО «Криста» опыте и архитектурных изысканиях в обозначенной области. Также мы рассмотрим пример простого решения интеграционной задачи с точки зрения прикладного разработчика и выясним, что скрывается за этой простотой.
Дисклеймер
Описанные в статье архитектурные и технические решения предлагаются мной на основе личного опыта в контексте конкретных задач. Эти решения не претендуют на универсальность и могут оказаться не оптимальными при иных условиях использования.
При чем тут BPM?
Для ответа на этот вопрос нужно немного углубиться в специфику прикладных задач наших решений. Основная часть бизнес-логики в нашей типичной транзакционной системе – это ввод данных в БД через пользовательские интерфейсы, ручная и автоматизированная проверка этих данных, проведение их по некоторому workflow, публикация в другую систему / аналитическую базу / архив, формирование отчетов. Таким образом, ключевой функцией системы для заказчиков является автоматизация их внутренних бизнес-процессов.
Для удобства мы используем в общении термин «документ» как некоторую абстракцию набора данных, объединенных общим ключом, к которому можно «привязать» определенный workflow.
Но как быть с интеграционной логикой? Ведь задача интеграции порождается архитектурой системы, которая «распилена» на части НЕ по требованию заказчика, а под влиянием совсем других факторов:
- под действием закона Конвея;
- в результате повторного использования подсистем, ранее разработанных для других продуктов;
- по решению архитектора, исходя из нефункциональных требований.
Существует большой соблазн отделить интеграционную логику от бизнес-логики основного workflow, чтобы не загрязнять бизнес-логику интеграционными артефактами и избавить прикладного разработчика от необходимости вникать в особенности архитектурного ландшафта системы. У такого подхода есть ряд преимуществ, однако практика показывает его неэффективность:
- решение интеграционных задач обычно скатывается к самым простым вариантам в виде синхронных вызовов из-за ограниченности точек расширения в реализации основного workflow (о недостатках синхронной интеграции – чуть ниже);
- интеграционные артефакты все равно проникают в основную бизнес-логику, когда требуется обратная связь из другой подсистемы;
- прикладной разработчик игнорирует интеграцию и может легко ее сломать, изменив workflow;
- система перестает быть единым целым с точки зрения пользователя, становятся заметны «швы» между подсистемами, появляются избыточные пользовательские операции, инициирующие передачу данных из одной подсистемы в другую.
Другой подход – рассмотрение интеграционных взаимодействий как неотъемлемой части основной бизнес-логики и workflow. Чтобы требования к квалификации прикладных разработчиков не взлетели до небес, создание новых интеграционных взаимодействий должно выполняться легко и непринужденно, с минимальными возможностями для выбора способа решения. Это сделать сложнее, чем кажется: инструмент должен быть достаточно мощным, чтобы обеспечить пользователю необходимое множество вариантов его применения и при этом не позволить «выстрелить себе в ногу». Существует множество вопросов, на которые должен ответить инженер в контексте интеграционных задач, но о которых не должен задумываться прикладной разработчик в своей повседневной работе: границы транзакций, консистентность, атомарность, безопасность, масштабирование, распределение нагрузок и ресурсов, роутинг, маршалинг, распространение и переключение контекстов и т. п. Нужно предложить прикладным разработчикам достаточно простые шаблоны решений, в которых уже спрятаны ответы на все подобные вопросы. Эти шаблоны должны быть достаточно безопасны: бизнес-логика меняется очень часто, что повышает риски внесения ошибок, цена ошибок должна оставаться на достаточно низком уровне.
Но все-таки при чем тут BPM? Есть же множество вариантов реализации workflow…
Действительно, в наших решениях очень популярна другая реализация бизнес-процессов – через декларативное задание диаграммы переходов состояний и подключение обработчиков с бизнес-логикой на переходы. При этом состояние, определяющее текущее положение «документа» в бизнес-процессе, является атрибутом самого «документа».
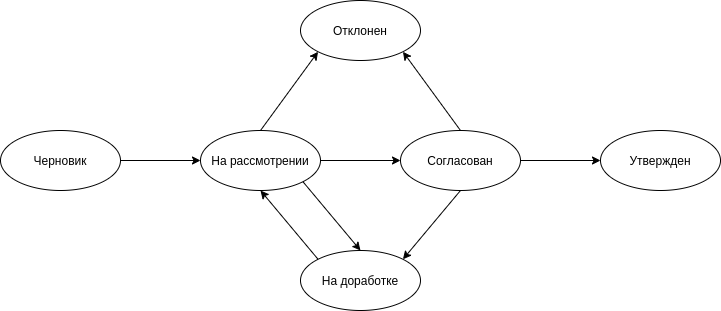
Так выглядит процесс на старте проекта
Популярность такой реализации обусловлена относительной простотой и скоростью создания линейных бизнес-процессов. Однако по мере постоянного усложнения программных систем автоматизированная часть бизнес-процесса разрастается и усложняется. Появляется необходимость в декомпозиции, повторном использовании частей процессов, а также в разветвлении процессов, чтобы каждая ветка исполнялась параллельно. В таких условиях инструмент становится неудобным, а диаграмма переходов состояний теряет информативность (интеграционные взаимодействия вообще никак не отражаются на диаграмме).

Так выглядит процесс через несколько итераций уточнения требований
Выходом из этой ситуации стала интеграция движка jBPM в некоторые продукты с наиболее сложными бизнес-процессами. В краткосрочной перспективе это решение имело определенный успех: появилась возможность реализации сложных бизнес-процессов с сохранением достаточно информативной и актуальной диаграммы в нотации BPMN2.
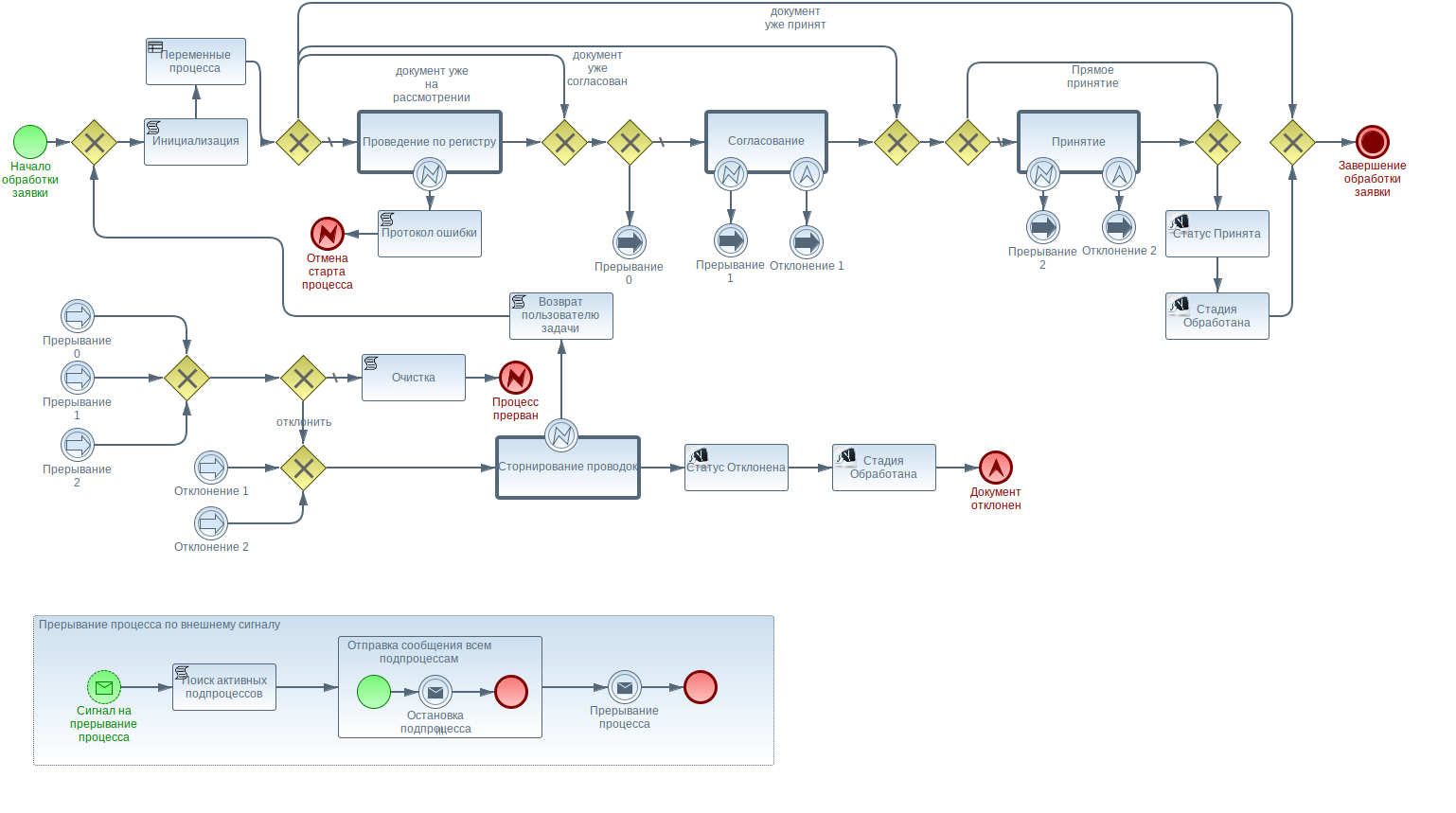
Небольшая часть сложного бизнес-процесса
В долгосрочной перспективе решение не оправдало ожиданий: высокая трудоемкость создания бизнес-процессов через визуальные инструменты не позволила достичь приемлемых показателей продуктивности, а сам инструмент стал одним из самых нелюбимых среди разработчиков. К внутреннему устройству движка тоже были претензии, которые привели к появлению множества «заплаток» и «костылей».
Главным положительным моментом применения jBPM стало осознание пользы и вреда от наличия собственного персистентного состояния у экземпляра бизнес-процесса. Также мы увидели возможность применения процессного подхода для реализации сложных протоколов интеграции между различными приложениями с применением асинхронных взаимодействий через сигналы и сообщения. Наличие персистентного состояния играет в этом важнейшую роль.
На основании сказанного можно сделать вывод: процессный подход в стиле BPM позволяет нам решать широкий спектр задач по автоматизации постоянно усложняющихся бизнес-процессов, гармонично вписывать в эти процессы интеграционные активности и сохранять возможность визуального отображения реализованного процесса в подходящей для этого нотации.
Недостатки синхронных вызовов как интеграционного паттерна
Под синхронной интеграцией понимается простейший блокирующий вызов. Одна подсистема выступает серверной стороной и выставляет API с нужным методом. Другая подсистема выступает клиентской стороной и в нужный момент выполняет вызов с ожиданием результата. В зависимости от архитектуры системы клиентская и серверная стороны могут размещаться либо в одном приложении и процессе, либо в разных. Во втором случае требуется применить некоторую реализацию RPC и обеспечить маршаллинг параметров и результата вызова.
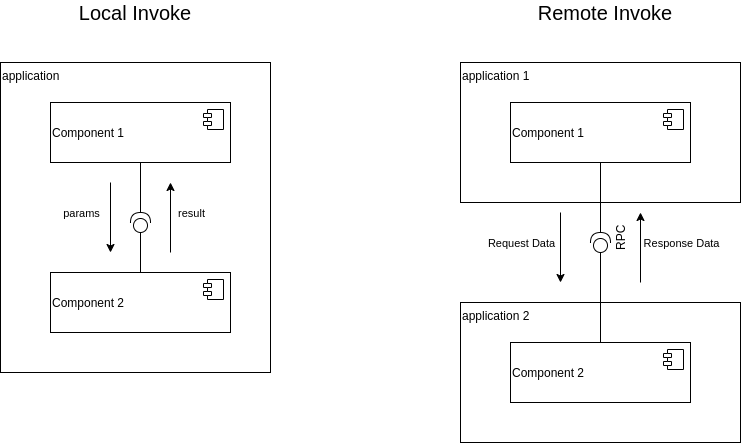
Такой интеграционный паттерн обладает достаточно большим набором недостатков, но он очень широко используется на практике в силу своей простоты. Скорость реализации подкупает и заставляет применять его снова и снова в условиях «горящих» сроков, записывая решение в технический долг. Но бывает и так, что неопытные разработчики применяют его неосознанно, просто не догадываясь о негативных последствиях.
Помимо наиболее очевидного повышения связности подсистем, есть и менее явные проблемы с «растаращиванием» и «растягиванием» транзакций. Действительно, если бизнес-логика вносит какие-то изменения, тогда не обойтись без транзакций, а транзакции, в свою очередь, блокируют определенные ресурсы приложения, затрагиваемые этими изменениями. То есть пока одна подсистема не дождется ответа от другой, она не сможет завершить транзакцию и снять блокировки. Это существенно повышает риск возникновения разнообразных эффектов:
- теряется отзывчивость системы, пользователи подолгу ждут ответов на запросы;
- сервер вообще перестает отвечать на запросы пользователей из-за переполненного пула потоков: большинство потоков «встали» на блокировке ресурса, занятого транзакцией;
- начинают появляться дэдлоки: вероятность их появления сильно зависит от длительности транзакций, количества вовлеченной в транзакцию бизнес-логики и блокировок;
- появляются ошибки истечения таймаута транзакции;
- сервер «падает» по OutOfMemory, если задача требует обработки и изменения больших объемов данных, а наличие синхронных интеграций сильно затрудняет дробление обработки на более «легкие» транзакции.
С архитектурной точки зрения применение блокирующих вызовов при интеграции приводит к потере управления качеством отдельных подсистем: невозможно обеспечить целевые показатели качества одной подсистемы в отрыве от показателей качества другой подсистемы. Если подсистемы разрабатываются разными командами, это большая проблема.
Все становится еще интереснее, если интегрируемые подсистемы находятся в разных приложениях и нужно внести синхронные изменения с двух сторон. Как обеспечить транзакционность этих изменений?
Если изменения вносятся раздельными транзакциями, тогда потребуется обеспечить надежную обработку исключений и компенсации, а это полностью нивелирует основное преимущество синхронных интеграций – простоту.
На ум также приходят распределенные транзакции, но мы их не используем в своих решениях: сложно обеспечить надежность.
«Сага» как решение проблемы транзакций
С ростом популярности микросервисов все большую востребованность обретает Saga Pattern.
Данный шаблон отлично решает обозначенные выше проблемы долгих транзакций, а также расширяет возможности управления состоянием системы со стороны бизнес-логики: компенсация после неудачной транзакции может не откатывать систему в исходное состояние, а обеспечивать альтернативный маршрут обработки данных. Это также позволяет не повторять успешно завершенные шаги обработки данных при повторных попытках довести процесс до «хорошего» финала.
Что интересно, в монолитных системах этот шаблон также актуален, если речь идет об интеграции слабо связанных подсистем и наблюдаются негативные эффекты, вызванные длительными транзакциями и соответствующими блокировками ресурсов.
Применительно к нашим бизнес-процессам в стиле BPM имплементировать «Саги» оказывается очень легко: отдельные шаги «Саги» могут быть заданы в виде активностей внутри бизнес-процесса, а персистентное состояние бизнес-процесса определяет в том числе внутреннее состояние «Саги». То есть нам не требуется никакого дополнительного координационного механизма. Потребуется лишь брокер сообщений с поддержкой «at least once» гарантий в качестве транспорта.
Но и у такого решения есть своя «цена»:
- бизнес-логика становится более сложной: нужно отрабатывать компенсации;
- потребуется отказаться от full consistency, что может быть особо чувствительным для монолитных систем;
- немного усложняется архитектура, появляется дополнительная потребность в брокере сообщений;
- потребуются дополнительные средства мониторинга и администрирования (хотя в целом это даже хорошо: качество обслуживания системы повысится).
Для монолитных систем оправданность использования «Саг» не так очевидна. Для микросервисов и других SOA, где, скорее всего, уже есть брокер, а full consistency принесена в жертву еще на старте проекта, польза от использования этого шаблона может значительно перевесить недостатки, особенно при наличии удобной API на уровне бизнес-логики.
Инкапсуляция бизнес-логики в микросервисах
Когда мы начали экспериментировать с микросервисами, возник резонный вопрос: куда помещать доменную бизнес-логику относительно сервиса, обеспечивающего персистенцию доменных данных?
При взгляде на архитектуру различных BPMS может показаться разумным отделить бизнес-логику от персистенции: создать слой платформенных и доменно-независимых микросервисов, формирующих среду и контейнер для исполнения доменной бизнес-логики, а персистенцию доменных данных оформить отдельным слоем из очень простых и легковесных микросервисов. Бизнес-процессы в таком случае выполняют оркестровку сервисов слоя персистенции.
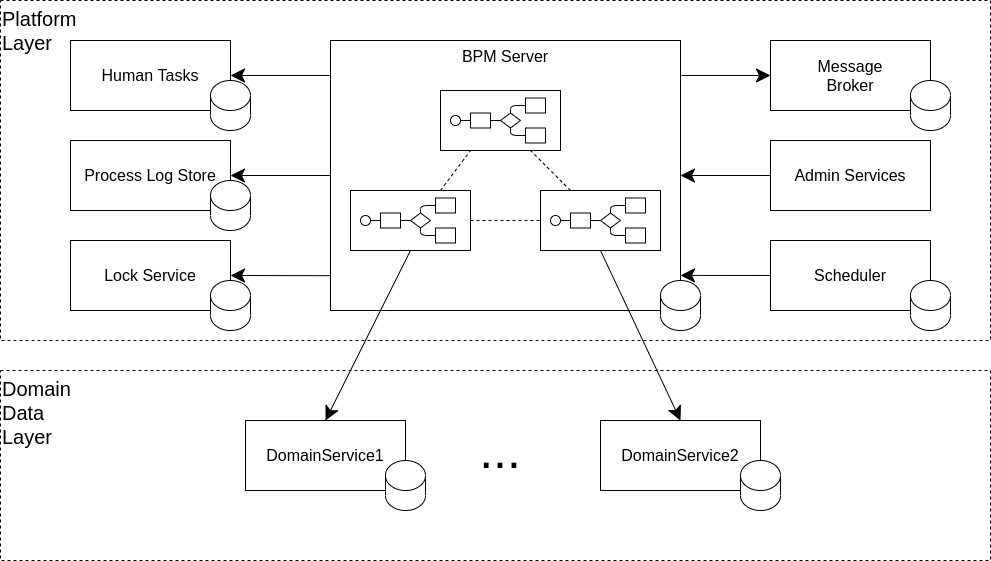
У такого подхода есть очень большой плюс: можно сколько угодно наращивать функциональность платформы, и «толстеть» от этого будет только соответствующий слой платформенных микросервисов. Бизнес-процессы из любого домена сразу получают возможность использовать новую функциональность платформы, как только она будет обновлена.
Более детальная проработка выявила существенные недостатки такого подхода:
- платформенный сервис, исполняющий бизнес-логику сразу многих доменов, несет в себе большие риски как единая точка отказа. Частые изменения бизнес-логики повышают риск возникновения ошибок, приводящих к сбоям, распространяющимся на всю систему;
- проблемы производительности: бизнес-логика работает со своими данными через узкий и медленный интерфейс:
- данные будут лишний раз маршаллиться и прокачиваться через сетевой стэк;
- доменный сервис зачастую будет отдавать больше данных, чем требуется бизнес-логике для обработки, из-за недостаточных возможностей параметризации запросов на уровне внешней API сервиса;
- несколько независимых частей бизнес-логики могут повторно перезапрашивать одни и те же данные для обработки (можно смягчить эту проблему добавлением сессионных компонентов, кэширующих данные, но это дополнительно усложняет архитектуру и создает проблемы актуальности данных и инвалидации кэша);
- проблемы транзакционности:
- бизнес-процессы с персистентным состоянием, хранением которого занимается платформенный сервис, рассогласуются с доменными данными, и простых путей решения этой проблемы не предвидится;
- вынесение блокировки доменных данных за пределы транзакции: если доменной бизнес-логике требуется внести изменения, предварительно выполнив проверку корректности актуальных данных, требуется исключить возможность конкурентного изменения обрабатываемых данных. Внешняя блокировка данных может помочь решить задачу, но такое решение несет в себе дополнительные риски и снижает общую надежность системы;
- дополнительные сложности при обновлении: в ряде случаев обновлять сервис персистенции и бизнес-логику нужно синхронно или в строгой последовательности.
В конечном итоге пришлось вернуться к истокам: инкапсулировать доменные данные и доменную бизнес-логику в один микросервис. Такой подход упрощает восприятие микросервиса как целостного компонента в составе системы и не порождает вышеперечисленные проблемы. Это тоже дается не бесплатно:
- требуется стандартизация API для взаимодействия с бизнес-логикой (в частности, для обеспечения пользовательских активностей в составе бизнес-процессов) и API-платформенных сервисов; требуется более внимательное отношение к изменению API, прямой и обратной совместимости;
- требуется добавление дополнительных runtime-библиотек для обеспечения функционирования бизнес-логики в составе каждого такого микросервиса, и это порождает новые требования к таким библиотекам: легковесность и минимум транзитивных зависимостей;
- разработчикам бизнес-логики необходимо следить за версиями библиотек: если какой-то микросервис давно не дорабатывали, то в нем, скорее всего, окажется устаревшая версия библиотек. Это может стать неожиданным препятствием для добавления новой фичи и может потребовать миграции старой бизнес-логики такого сервиса на новые версии библиотек, если между версиями были несовместимые изменения.
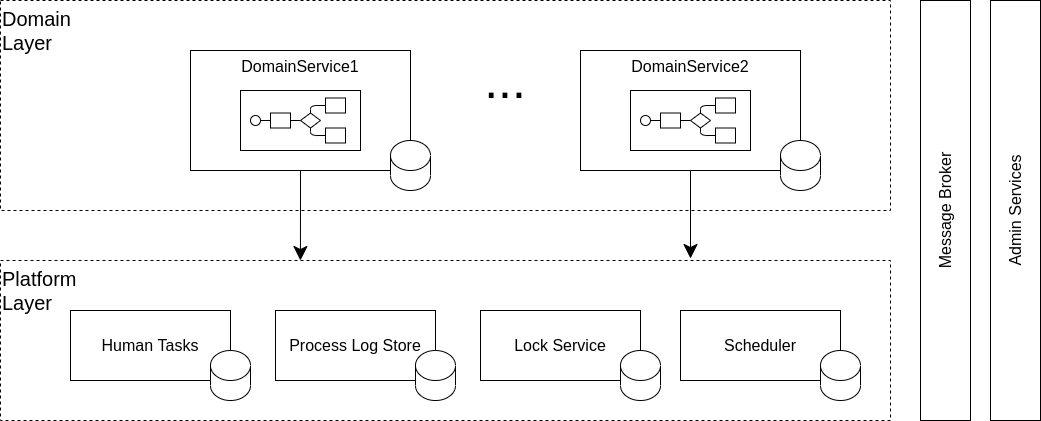
Слой платформенных сервисов в такой архитектуре также присутствует, но этот слой формирует уже не контейнер для исполнения доменной бизнес-логики, а всего лишь ее окружение, предоставляя вспомогательные «платформенные» функции. Такой слой нужен не только для сохранения легковесности доменных микросервисов, но и для централизации управления.
Например, пользовательские активности в бизнес-процессах порождают задачи. Однако, работая с задачами, пользователь должен видеть задачи из всех доменов в общем списке, а значит, должен быть соответствующий платформенный сервис регистрации задач, очищенный от доменной бизнес-логики. Сохранить инкапсуляцию бизнес-логики в таком контексте достаточно проблематично, и это еще один компромисс данной архитектуры.
Интеграция бизнес-процессов глазами прикладного разработчика
Как уже сказано выше, прикладной разработчик должен быть абстрагирован от технических и инженерных особенностей реализации взаимодействия нескольких приложений, чтобы можно было рассчитывать на хорошую продуктивность разработки.
Попробуем решить достаточно непростую интеграционную задачу, специально придуманную для статьи. Это будет «игровая» задача с участием трех приложений, где каждое из них определяет некоторое доменное имя: «app1», «app2», «app3».
Внутри каждого приложения запускаются бизнес-процессы, которые начинают «играть в мяч» через интеграционную шину. В роли мяча будут выступать сообщения с именем «Ball».
Правила игры:
- первый игрок – инициатор. Он приглашает других игроков в игру, начинает игру и может ее в любой момент закончить;
- другие игроки заявляют о своем участии в игре, «знакомятся» друг с другом и первым игроком;
- приняв мяч, игрок выбирает другого участвующего игрока и передает ему мяч. Ведется подсчет общего количества передач;
- у каждого игрока есть «энергия», которая уменьшается с каждой передачей мяча этим игроком. По истечении энергии игрок выбывает из игры, заявляя о своем уходе;
- если игрок остался один, он сразу заявляет об уходе;
- когда все игроки выбывают, первый игрок заявляет о завершении игры. Если он выбыл из игры раньше, то остается следить за игрой, чтобы завершить ее.
Для решения этой задачки я воспользуюсь нашим DSL для бизнес-процессов, позволяющим описать логику на Kotlin компактно, с минимумом бойлерплейта.
В приложении app1 будет работать бизнес-процесс первого игрока (он же инициатор игры):
import ru.krista.bpm.ProcessInstance
import ru.krista.bpm.runtime.ProcessImpl
import ru.krista.bpm.runtime.constraint.UniqueConstraints
import ru.krista.bpm.runtime.dsl.processModel
import ru.krista.bpm.runtime.dsl.taskOperation
import ru.krista.bpm.runtime.instance.MessageSendInstance
data class PlayerInfo(val name: String, val domain: String, val id: String)
class PlayersList : ArrayList<PlayerInfo>()
// Это класс экземпляра процесса: инкапсулирует его внутреннее состояние
class InitialPlayer : ProcessImpl<InitialPlayer>(initialPlayerModel) {
var playerName: String by persistent("Player1")
var energy: Int by persistent(30)
var players: PlayersList by persistent(PlayersList())
var shotCounter: Int = 0
}
// Это декларация модели процесса: создается один раз, используется всеми
// экземплярами процесса соответствующего класса
val initialPlayerModel = processModel<InitialPlayer>(name = "InitialPlayer",
version = 1) {
// По правилам, первый игрок является инициатором игры и должен быть единственным
uniqueConstraint = UniqueConstraints.singleton
// Объявляем активности, из которых состоит бизнес-процесс
val sendNewGameSignal = signal<String>("NewGame")
val sendStopGameSignal = signal<String>("StopGame")
val startTask = humanTask("Start") {
taskOperation {
processCondition { players.size > 0 }
confirmation { "Подключилось ${players.size} игроков. Начинаем?" }
}
}
val stopTask = humanTask("Stop") {
taskOperation {}
}
val waitPlayerJoin = signalWait<String>("PlayerJoin") { signal ->
players.add(PlayerInfo(
signal.data!!,
signal.sender.domain,
signal.sender.processInstanceId))
println("... join player ${signal.data} ...")
}
val waitPlayerOut = signalWait<String>("PlayerOut") { signal ->
players.remove(PlayerInfo(
signal.data!!,
signal.sender.domain,
signal.sender.processInstanceId))
println("... player ${signal.data} is out ...")
}
val sendPlayerOut = signal<String>("PlayerOut") {
signalData = { playerName }
}
val sendHandshake = messageSend<String>("Handshake") {
messageData = { playerName }
activation = {
receiverDomain = process.players.last().domain
receiverProcessInstanceId = process.players.last().id
}
}
val throwStartBall = messageSend<Int>("Ball") {
messageData = { 1 }
activation = { selectNextPlayer() }
}
val throwBall = messageSend<Int>("Ball") {
messageData = { shotCounter + 1 }
activation = { selectNextPlayer() }
onEntry { energy -= 1 }
}
val waitBall = messageWaitData<Int>("Ball") {
shotCounter = it
}
// Теперь конструируем граф процесса из объявленных активностей
startFrom(sendNewGameSignal)
.fork("mainFork") {
next(startTask)
next(waitPlayerJoin).next(sendHandshake).next(waitPlayerJoin)
next(waitPlayerOut)
.branch("checkPlayers") {
ifTrue { players.isEmpty() }
.next(sendStopGameSignal)
.terminate()
ifElse().next(waitPlayerOut)
}
}
startTask.fork("afterStart") {
next(throwStartBall)
.branch("mainLoop") {
ifTrue { energy < 5 }.next(sendPlayerOut).next(waitBall)
ifElse().next(waitBall).next(throwBall).loop()
}
next(stopTask).next(sendStopGameSignal)
}
// Навешаем на активности дополнительные обработчики для логирования
sendNewGameSignal.onExit { println("Let's play!") }
sendStopGameSignal.onExit { println("Stop!") }
sendPlayerOut.onExit { println("$playerName: I'm out!") }
}
private fun MessageSendInstance<InitialPlayer, Int>.selectNextPlayer() {
val player = process.players.random()
receiverDomain = player.domain
receiverProcessInstanceId = player.id
println("Step ${process.shotCounter + 1}: " +
"${process.playerName} >>> ${player.name}")
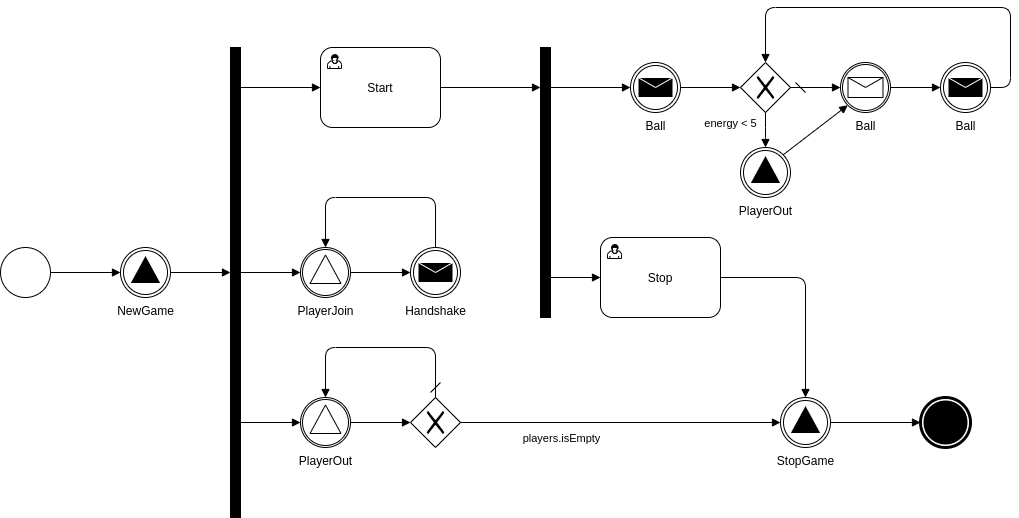
}Помимо исполнения бизнес-логики, приведенный код умеет выдавать объектную модель бизнес-процесса, которая может быть визуализирована в виде диаграммы. Визуализатор мы пока не реализовали, поэтому пришлось потратить немного времени на рисование (здесь я слегка упростил BPMN нотацию в части использования гейтов, чтобы улучшить согласованность диаграммы с приведенным кодом):
Приложение app2 будет включать бизнес-процесс другого игрока:
import ru.krista.bpm.ProcessInstance
import ru.krista.bpm.runtime.ProcessImpl
import ru.krista.bpm.runtime.dsl.processModel
import ru.krista.bpm.runtime.instance.MessageSendInstance
data class PlayerInfo(val name: String, val domain: String, val id: String)
class PlayersList: ArrayList<PlayerInfo>()
class RandomPlayer : ProcessImpl<RandomPlayer>(randomPlayerModel) {
var playerName: String by input(persistent = true,
defaultValue = "RandomPlayer")
var energy: Int by input(persistent = true, defaultValue = 30)
var players: PlayersList by persistent(PlayersList())
var allPlayersOut: Boolean by persistent(false)
var shotCounter: Int = 0
val selfPlayer: PlayerInfo
get() = PlayerInfo(playerName, env.eventDispatcher.domainName, id)
}
val randomPlayerModel = processModel<RandomPlayer>(name = "RandomPlayer",
version = 1) {
val waitNewGameSignal = signalWait<String>("NewGame")
val waitStopGameSignal = signalWait<String>("StopGame")
val sendPlayerJoin = signal<String>("PlayerJoin") {
signalData = { playerName }
}
val sendPlayerOut = signal<String>("PlayerOut") {
signalData = { playerName }
}
val waitPlayerJoin = signalWaitCustom<String>("PlayerJoin") {
eventCondition = { signal ->
signal.sender.processInstanceId != process.id
&& !process.players.any { signal.sender.processInstanceId == it.id}
}
handler = { signal ->
players.add(PlayerInfo(
signal.data!!,
signal.sender.domain,
signal.sender.processInstanceId))
}
}
val waitPlayerOut = signalWait<String>("PlayerOut") { signal ->
players.remove(PlayerInfo(
signal.data!!,
signal.sender.domain,
signal.sender.processInstanceId))
allPlayersOut = players.isEmpty()
}
val sendHandshake = messageSend<String>("Handshake") {
messageData = { playerName }
activation = {
receiverDomain = process.players.last().domain
receiverProcessInstanceId = process.players.last().id
}
}
val receiveHandshake = messageWait<String>("Handshake") { message ->
if (!players.any { message.sender.processInstanceId == it.id}) {
players.add(PlayerInfo(
message.data!!,
message.sender.domain,
message.sender.processInstanceId))
}
}
val throwBall = messageSend<Int>("Ball") {
messageData = { shotCounter + 1 }
activation = { selectNextPlayer() }
onEntry { energy -= 1 }
}
val waitBall = messageWaitData<Int>("Ball") {
shotCounter = it
}
startFrom(waitNewGameSignal)
.fork("mainFork") {
next(sendPlayerJoin)
.branch("mainLoop") {
ifTrue { energy < 5 || allPlayersOut }
.next(sendPlayerOut)
.next(waitBall)
ifElse()
.next(waitBall)
.next(throwBall)
.loop()
}
next(waitPlayerJoin).next(sendHandshake).next(waitPlayerJoin)
next(waitPlayerOut).next(waitPlayerOut)
next(receiveHandshake).next(receiveHandshake)
next(waitStopGameSignal).terminate()
}
sendPlayerJoin.onExit { println("$playerName: I'm here!") }
sendPlayerOut.onExit { println("$playerName: I'm out!") }
}
private fun MessageSendInstance<RandomPlayer, Int>.selectNextPlayer() {
val player = if (process.players.isNotEmpty())
process.players.random()
else
process.selfPlayer
receiverDomain = player.domain
receiverProcessInstanceId = player.id
println("Step ${process.shotCounter + 1}: " +
"${process.playerName} >>> ${player.name}")
}Диаграмма:

В приложении app3 сделаем игрока немного с другим поведением: вместо случайного выбора следующего игрока, он будет действовать по алгоритму round-robin:
import ru.krista.bpm.ProcessInstance
import ru.krista.bpm.runtime.ProcessImpl
import ru.krista.bpm.runtime.dsl.processModel
import ru.krista.bpm.runtime.instance.MessageSendInstance
data class PlayerInfo(val name: String, val domain: String, val id: String)
class PlayersList: ArrayList<PlayerInfo>()
class RoundRobinPlayer : ProcessImpl<RoundRobinPlayer>(roundRobinPlayerModel) {
var playerName: String by input(persistent = true,
defaultValue = "RoundRobinPlayer")
var energy: Int by input(persistent = true, defaultValue = 30)
var players: PlayersList by persistent(PlayersList())
var nextPlayerIndex: Int by persistent(-1)
var allPlayersOut: Boolean by persistent(false)
var shotCounter: Int = 0
val selfPlayer: PlayerInfo
get() = PlayerInfo(playerName, env.eventDispatcher.domainName, id)
}
val roundRobinPlayerModel = processModel<RoundRobinPlayer>(
name = "RoundRobinPlayer",
version = 1) {
val waitNewGameSignal = signalWait<String>("NewGame")
val waitStopGameSignal = signalWait<String>("StopGame")
val sendPlayerJoin = signal<String>("PlayerJoin") {
signalData = { playerName }
}
val sendPlayerOut = signal<String>("PlayerOut") {
signalData = { playerName }
}
val waitPlayerJoin = signalWaitCustom<String>("PlayerJoin") {
eventCondition = { signal ->
signal.sender.processInstanceId != process.id
&& !process.players.any { signal.sender.processInstanceId == it.id}
}
handler = { signal ->
players.add(PlayerInfo(
signal.data!!,
signal.sender.domain,
signal.sender.processInstanceId))
}
}
val waitPlayerOut = signalWait<String>("PlayerOut") { signal ->
players.remove(PlayerInfo(
signal.data!!,
signal.sender.domain,
signal.sender.processInstanceId))
allPlayersOut = players.isEmpty()
}
val sendHandshake = messageSend<String>("Handshake") {
messageData = { playerName }
activation = {
receiverDomain = process.players.last().domain
receiverProcessInstanceId = process.players.last().id
}
}
val receiveHandshake = messageWait<String>("Handshake") { message ->
if (!players.any { message.sender.processInstanceId == it.id}) {
players.add(PlayerInfo(
message.data!!,
message.sender.domain,
message.sender.processInstanceId))
}
}
val throwBall = messageSend<Int>("Ball") {
messageData = { shotCounter + 1 }
activation = { selectNextPlayer() }
onEntry { energy -= 1 }
}
val waitBall = messageWaitData<Int>("Ball") {
shotCounter = it
}
startFrom(waitNewGameSignal)
.fork("mainFork") {
next(sendPlayerJoin)
.branch("mainLoop") {
ifTrue { energy < 5 || allPlayersOut }
.next(sendPlayerOut)
.next(waitBall)
ifElse()
.next(waitBall)
.next(throwBall)
.loop()
}
next(waitPlayerJoin).next(sendHandshake).next(waitPlayerJoin)
next(waitPlayerOut).next(waitPlayerOut)
next(receiveHandshake).next(receiveHandshake)
next(waitStopGameSignal).terminate()
}
sendPlayerJoin.onExit { println("$playerName: I'm here!") }
sendPlayerOut.onExit { println("$playerName: I'm out!") }
}
private fun MessageSendInstance<RoundRobinPlayer, Int>.selectNextPlayer() {
var idx = process.nextPlayerIndex + 1
if (idx >= process.players.size) {
idx = 0
}
process.nextPlayerIndex = idx
val player = if (process.players.isNotEmpty())
process.players[idx]
else
process.selfPlayer
receiverDomain = player.domain
receiverProcessInstanceId = player.id
println("Step ${process.shotCounter + 1}: " +
"${process.playerName} >>> ${player.name}")
}В остальном поведение игрока не отличается от предыдущего, поэтому диаграмма не меняется.
Теперь нужен тест, чтобы все это запускать. Приведу только код самого теста, чтобы не загромождать статью бойлерплейтом (на самом деле я воспользовался тестовым окружением, созданным ранее для тестирования интеграции других бизнес-процессов):
@Test
public void testGame() throws InterruptedException {
String pl2 = startProcess(app2, "RandomPlayer", playerParams("Player2", 20));
String pl3 = startProcess(app2, "RandomPlayer", playerParams("Player3", 40));
String pl4 = startProcess(app3, "RoundRobinPlayer", playerParams("Player4", 25));
String pl5 = startProcess(app3, "RoundRobinPlayer", playerParams("Player5", 35));
String pl1 = startProcess(app1, "InitialPlayer");
// Теперь нужно немного подождать, пока игроки "познакомятся" друг с другом.
// Ждать через sleep - плохое решение, зато самое простое.
// Не делайте так в серьезных тестах!
Thread.sleep(1000);
// Запускаем игру, закрывая пользовательскую активность
assertTrue(closeTask(app1, pl1, "Start"));
app1.getWaiting().waitProcessFinished(pl1);
app2.getWaiting().waitProcessFinished(pl2);
app2.getWaiting().waitProcessFinished(pl3);
app3.getWaiting().waitProcessFinished(pl4);
app3.getWaiting().waitProcessFinished(pl5);
}
private Map<String, Object> playerParams(String name, int energy) {
Map<String, Object> params = new HashMap<>();
params.put("playerName", name);
params.put("energy", energy);
return params;
}Запускаем тест, смотрим лог:
Взята блокировка ключа lock://app1/process/InitialPlayer
Let's play!
Снята блокировка ключа lock://app1/process/InitialPlayer
Player2: I'm here!
Player3: I'm here!
Player4: I'm here!
Player5: I'm here!
... join player Player2 ...
... join player Player4 ...
... join player Player3 ...
... join player Player5 ...
Step 1: Player1 >>> Player3
Step 2: Player3 >>> Player5
Step 3: Player5 >>> Player3
Step 4: Player3 >>> Player4
Step 5: Player4 >>> Player3
Step 6: Player3 >>> Player4
Step 7: Player4 >>> Player5
Step 8: Player5 >>> Player2
Step 9: Player2 >>> Player5
Step 10: Player5 >>> Player4
Step 11: Player4 >>> Player2
Step 12: Player2 >>> Player4
Step 13: Player4 >>> Player1
Step 14: Player1 >>> Player4
Step 15: Player4 >>> Player3
Step 16: Player3 >>> Player1
Step 17: Player1 >>> Player2
Step 18: Player2 >>> Player3
Step 19: Player3 >>> Player1
Step 20: Player1 >>> Player5
Step 21: Player5 >>> Player1
Step 22: Player1 >>> Player2
Step 23: Player2 >>> Player4
Step 24: Player4 >>> Player5
Step 25: Player5 >>> Player3
Step 26: Player3 >>> Player4
Step 27: Player4 >>> Player2
Step 28: Player2 >>> Player5
Step 29: Player5 >>> Player2
Step 30: Player2 >>> Player1
Step 31: Player1 >>> Player3
Step 32: Player3 >>> Player4
Step 33: Player4 >>> Player1
Step 34: Player1 >>> Player3
Step 35: Player3 >>> Player4
Step 36: Player4 >>> Player3
Step 37: Player3 >>> Player2
Step 38: Player2 >>> Player5
Step 39: Player5 >>> Player4
Step 40: Player4 >>> Player5
Step 41: Player5 >>> Player1
Step 42: Player1 >>> Player5
Step 43: Player5 >>> Player3
Step 44: Player3 >>> Player5
Step 45: Player5 >>> Player2
Step 46: Player2 >>> Player3
Step 47: Player3 >>> Player2
Step 48: Player2 >>> Player5
Step 49: Player5 >>> Player4
Step 50: Player4 >>> Player2
Step 51: Player2 >>> Player5
Step 52: Player5 >>> Player1
Step 53: Player1 >>> Player5
Step 54: Player5 >>> Player3
Step 55: Player3 >>> Player5
Step 56: Player5 >>> Player2
Step 57: Player2 >>> Player1
Step 58: Player1 >>> Player4
Step 59: Player4 >>> Player1
Step 60: Player1 >>> Player4
Step 61: Player4 >>> Player3
Step 62: Player3 >>> Player2
Step 63: Player2 >>> Player5
Step 64: Player5 >>> Player4
Step 65: Player4 >>> Player5
Step 66: Player5 >>> Player1
Step 67: Player1 >>> Player5
Step 68: Player5 >>> Player3
Step 69: Player3 >>> Player4
Step 70: Player4 >>> Player2
Step 71: Player2 >>> Player5
Step 72: Player5 >>> Player2
Step 73: Player2 >>> Player1
Step 74: Player1 >>> Player4
Step 75: Player4 >>> Player1
Step 76: Player1 >>> Player2
Step 77: Player2 >>> Player5
Step 78: Player5 >>> Player4
Step 79: Player4 >>> Player3
Step 80: Player3 >>> Player1
Step 81: Player1 >>> Player5
Step 82: Player5 >>> Player1
Step 83: Player1 >>> Player4
Step 84: Player4 >>> Player5
Step 85: Player5 >>> Player3
Step 86: Player3 >>> Player5
Step 87: Player5 >>> Player2
Step 88: Player2 >>> Player3
Player2: I'm out!
Step 89: Player3 >>> Player4
... player Player2 is out ...
Step 90: Player4 >>> Player1
Step 91: Player1 >>> Player3
Step 92: Player3 >>> Player1
Step 93: Player1 >>> Player4
Step 94: Player4 >>> Player3
Step 95: Player3 >>> Player5
Step 96: Player5 >>> Player1
Step 97: Player1 >>> Player5
Step 98: Player5 >>> Player3
Step 99: Player3 >>> Player5
Step 100: Player5 >>> Player4
Step 101: Player4 >>> Player5
Player4: I'm out!
... player Player4 is out ...
Step 102: Player5 >>> Player1
Step 103: Player1 >>> Player3
Step 104: Player3 >>> Player1
Step 105: Player1 >>> Player3
Step 106: Player3 >>> Player5
Step 107: Player5 >>> Player3
Step 108: Player3 >>> Player1
Step 109: Player1 >>> Player3
Step 110: Player3 >>> Player5
Step 111: Player5 >>> Player1
Step 112: Player1 >>> Player3
Step 113: Player3 >>> Player5
Step 114: Player5 >>> Player3
Step 115: Player3 >>> Player1
Step 116: Player1 >>> Player3
Step 117: Player3 >>> Player5
Step 118: Player5 >>> Player1
Step 119: Player1 >>> Player3
Step 120: Player3 >>> Player5
Step 121: Player5 >>> Player3
Player5: I'm out!
... player Player5 is out ...
Step 122: Player3 >>> Player5
Step 123: Player5 >>> Player1
Player5: I'm out!
Step 124: Player1 >>> Player3
... player Player5 is out ...
Step 125: Player3 >>> Player1
Step 126: Player1 >>> Player3
Player1: I'm out!
... player Player1 is out ...
Step 127: Player3 >>> Player3
Player3: I'm out!
Step 128: Player3 >>> Player3
... player Player3 is out ...
Player3: I'm out!
Stop!
Step 129: Player3 >>> Player3
Player3: I'm out!Из всего этого можно сделать несколько важных выводов:
- при наличии необходимых инструментов прикладные разработчики могут создавать интеграционные взаимодействия между приложениями без отрыва от бизнес-логики;
- сложность (complexity) интеграционной задачи, требующую инженерных компетенций, можно скрыть внутри фреймворка, если изначально заложить это в архитектуру фреймворка. Трудность задачи (difficulty) скрыть не получится, поэтому решение трудной задачи в коде будет выглядеть соответственно;
- при разработке интеграционной логики обязательно нужно учитывать eventually consistency и отсутствие линеаризуемости изменения состояния всех участников интеграции. Это вынуждает усложнять логику, чтобы сделать ее нечувствительной к порядку возникновения внешних событий. В нашем примере игрок вынужден принимать участие в игре уже после того, как он заявит о выходе из игры: другие игроки будут продолжать передавать ему мяч, пока информация о его выходе не дойдет и не обработается всеми участниками. Эта логика не вытекает из правил игры и является компромиссным решением в рамках выбранной архитектуры.
Далее поговорим о различных тонкостях нашего решения, компромиссах и прочих моментах.
Все сообщения – в одной очереди
Все интегрируемые приложения работают с одной интеграционной шиной, которая представлена в виде внешнего брокера, одной очереди BPMQueue – для сообщений и одного топика BPMTopic – для сигналов (событий). Пропускать все сообщения через одну очередь само по себе является компромиссом. На уровне бизнес-логики теперь можно вводить сколько угодно новых типов сообщений, не внося изменений в структуру системы. Это значительное упрощение, но оно несет в себе определенные риски, которые в контексте наших типовых задач показались нам не такими уж значительными.
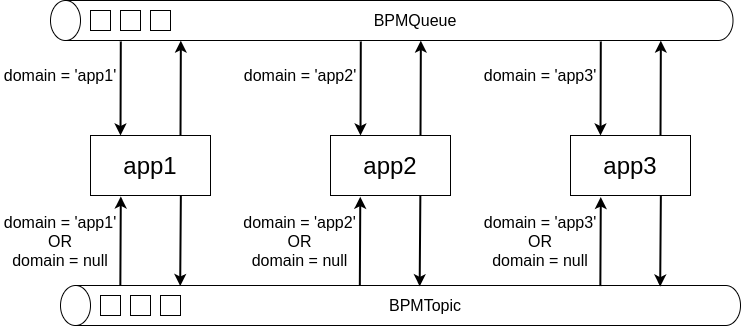
Однако здесь есть одна тонкость: каждое приложение отфильтровывает «свои» сообщения из очереди еще на входе, по имени своего домена. Также домен может быть указан и в сигналах, если нужно ограничить «область видимости» сигнала одним единственным приложением. Это должно увеличить пропускную способность шины, но бизнес-логика теперь должна оперировать именами доменов: для адресации сообщений – обязательно, для сигналов – желательно.
Обеспечение надежности интеграционной шины
Надежность складывается из нескольких моментов:
- выбранный брокер сообщений – критически важный компонент архитектуры и единая точка отказа: он должен быть достаточно отказоустойчивым. Следует использовать только проверенные временем реализации, с хорошей поддержкой и большим комьюнити;
- необходимо обеспечить высокую доступность брокера сообщений, для чего он должен быть физически отделен от интегрируемых приложений (высокую доступность приложений с прикладной бизнес-логикой обеспечить значительно сложнее и дороже);
- брокер обязан обеспечить «at least once» гарантии доставки. Это обязательное требование для надежной работы интеграционной шины. В гарантиях уровня «exactly once» нет необходимости: бизнес-процессы, как правило, не чувствительны к повторному поступлению сообщений или событий, а в особых задачах, где это важно, проще добавить дополнительную проверку в бизнес-логику, чем постоянно использовать достаточно «дорогие» гарантии;
- отправку сообщений и сигналов необходимо вовлекать в общую транзакцию с изменением состояния бизнес-процессов и доменных данных. Предпочтительным вариантом будет использование паттерна Transactional Outbox, но оно потребует наличия дополнительной таблицы в базе и ретранслятора. В JEE-приложениях можно упростить этот момент с использованием локального JTA-менеджера, но подключение к выбранному брокеру должно уметь работать в режиме XA;
- обработчики входящих сообщений и событий также должны работать с транзакцией изменения состояния бизнес-процесса: если такая транзакция откатывается, то и прием сообщения должен быть отменен;
- сообщения, которые не удалось доставить из-за ошибок, нужно складывать в отдельное хранилище DLQ (Dead Letter Queue). Мы для этого создали отдельный платформенный микросервис, который сохраняет такие сообщения в своем хранилище, индексирует их по атрибутам (для быстрой группировки и поиска), и выставляет API для просмотра, повторной отправки по адресу назначения, удаления сообщений. Администраторы системы могут работать с этим сервисом через свой веб-интерфейс;
- в настройках брокера нужно подстроить количество повторных попыток доставки и задержки между доставками, чтобы уменьшить вероятность попадания сообщений в DLQ (вычислить оптимальные параметры практически нереально, но можно действовать эмпирически и подстраивать их по ходу эксплуатации);
- хранилище DLQ должно непрерывно мониториться, и система мониторинга должна оповещать администраторов системы, чтобы при появлении недоставленных сообщений реагировать как можно быстрее. Это позволит уменьшить «зону поражения» возникшего сбоя или ошибки бизнес-логики;
- интеграционная шина должна быть нечувствительна к временному отсутствию приложений: подписки на топик должны быть durable, а доменное имя приложения должно быть уникально, чтобы за время отсутствия приложения его сообщения из очереди не попытался обработать кто-то другой.
Обеспечение потокобезопасности бизнес-логики
Одному и тому же экземпляру бизнес-процесса может поступить сразу несколько сообщений и событий, обработка которых запустится параллельно. В то же время для прикладного разработчика все должно быть просто и потокобезопасно.
Бизнес-логика процесса обрабатывает каждое внешнее событие, влияющее на этот бизнес-процесс, по отдельности. Такими событиями могут быть:
- запуск экземпляра бизнес-процесса;
- действие пользователя, относящееся к активности внутри бизнес-процесса;
- поступление сообщения или сигнала, на которое подписан экземпляр бизнес-процесса;
- срабатывание таймера, установленного экземпляром бизнес-процесса;
- управляющее воздействие через API (например, аварийное прерывание процесса).
Каждое такое событие может изменить состояние экземпляра бизнес-процесса: могут завершиться одни активности и начаться другие, могут измениться значения персистентных свойств. Закрытие любой активности может привести к активации одной или нескольких следующих активностей. Те, в свою очередь, могут остановиться на ожидании других событий или же, если им не нужны никакие дополнительные данные, могут завершиться в той же транзакции. Перед закрытием транзакции новое состояние бизнес-процесса сохраняется в БД, где будет ожидать наступления следующего внешнего события.
Персистентные данные бизнес-процесса, сохраненные в реляционную БД, являются очень удобной точкой синхронизации обработки, если использовать SELECT FOR UPDATE. Если одной транзакции удалось получить состояние бизнес-процесса из базы для его изменения, то никакая другая транзакция параллельно не сможет получить это же самое состояние для другого изменения, а после завершения первой транзакции вторая гарантированно получит уже измененное состояние.
Используя пессимистические блокировки на стороне СУБД, мы выполняем все необходимые требования ACID, а также сохраняем возможность масштабирования приложения с бизнес-логикой путем увеличения количества запущенных экземпляров.
Однако пессимистические блокировки грозят нам дэдлоками, а значит, SELECT FOR UPDATE все-таки стоит ограничить некоторым разумным таймаутом на случай возникновения дэдлоков на каких-нибудь вопиющих кейсах в бизнес-логике.
Еще одна проблема – синхронизация старта бизнес-процесса. Пока нет экземпляра бизнес-процесса, нет и его состояния в базе, поэтому описанный метод не подойдет. Если нужно обеспечить уникальность экземпляра бизнес-процесса в определенном скоупе, тогда потребуется некоторый объект синхронизации, ассоциированный с классом процесса и соответствующим скоупом. Для решения этой проблемы мы используем другой механизм блокировок, позволяющий взять блокировку произвольного ресурса, заданного ключом в формате URI, через внешний сервис.
В наших примерах бизнес-процесс InitialPlayer содержит объявление
uniqueConstraint = UniqueConstraints.singletonПоэтому в логе присутствуют сообщения о взятии и освобождении блокировки соответствующего ключа. По другим бизнес-процессам таких сообщений нет: uniqueConstraint не задан.
Проблемы бизнес-процессов с персистентным состоянием
Иногда наличие персистентного состояния не только помогает, но и очень мешает в разработке.
Проблемы начинаются, когда нужно внести изменения в бизнес-логику и/или модель бизнес-процесса. Не любое такое изменение оказывается совместимым со старым состоянием бизнес-процессов. Если в базе данных есть много «живых» экземпляров, тогда внесение несовместимых изменений может доставить массу неприятностей, с которыми мы часто сталкивались при использовании jBPM.
В зависимости от глубины изменений можно действовать двумя путями:
- создать новый тип бизнес-процесса, чтобы не вносить несовместимых изменений в старый, и использовать его вместо старого при запуске новых экземпляров. Старые экземпляры будут продолжать работать «по-старому»;
- мигрировать персистентное состояние бизнес-процессов при обновлении бизнес-логики.
Первый путь более простой, но имеет свои ограничения и недостатки, например:
- дублирование бизнес-логики во многих моделях бизнес-процессов, увеличение объема бизнес-логики;
- часто требуется моментальный переход на новую бизнес-логику (в части интеграционных задач – почти всегда);
- разработчик не знает, в какой момент можно удалять устаревшие модели.
На практике мы используем оба подхода, но приняли ряд решений, чтобы упростить себе жизнь:
- в базе данных персистентное состояние бизнес-процесса сохраняется в легко читаемом и легко обрабатываемом виде: в строке формата JSON. Это позволяет выполнять миграции как внутри приложения, так и снаружи. В крайнем случае можно и ручками подправить (особенно полезно в разработке во время отладки);
- интеграционная бизнес-логика не использует имена бизнес-процессов, чтобы в любой момент можно было заменить реализацию одного из участвующих процессов на новую, с новым именем (например, «InitialPlayerV2»). Связывание происходит через имена сообщений и сигналов;
- модель процесса имеет номер версии, который мы увеличиваем, если вносим в эту модель несовместимые изменения, и этот номер сохраняется вместе с состоянием экземпляра процесса;
- персистентное состояние процесса вычитывается из базы сначала в удобную объектную модель, с которой может работать процедура миграции, если изменился номер версии модели;
- процедура миграции размещается рядом с бизнес-логикой и вызывается «лениво» для каждого экземпляра бизнес-процесса в момент его восстановления из базы;
- если нужно мигрировать состояние всех экземпляров процесса оперативно и синхронно, применяются более классические решения по миграции БД, но там приходится работать с JSON.
Нужен ли еще один фреймворк для бизнес-процессов?
Описанные в статье решения позволили нам заметно упростить себе жизнь, расширить круг вопросов, решаемых на уровне прикладной разработки, сделать более привлекательными идеи выделения бизнес-логики в микросервисы. Для этого было проделано много работы, создан очень «легковесный» фреймворк для бизнес-процессов, а также служебные компоненты для решения обозначенных проблем в контексте широкого круга прикладных задач. У нас есть желание поделиться этими результатами, вынести разработку общих компонентов в открытый доступ под свободной лицензией. Это потребует определенных усилий и времени. Понимание востребованности таких решений могло бы стать для нас дополнительным стимулом. В предложенной статье очень мало внимания уделено возможностям самого фреймворка, но некоторые из них видны из представленных примеров. Если мы все-таки опубликуем свой фреймворк, ему будет посвящена отдельная статья. А пока будем признательны, если оставите небольшой фидбэк, ответив на вопрос:


gkislin
Спасибо, было интересно! Пожелание к повествованию- больше для технических людей, чем для менеждеров и рекламных проспектов. Например картинка синхронного вызова на мой взгляд лишняя и комментарий к ней "Такой интеграционный паттерн обладает достаточно большим набором недостатков.....". Позволит сократить объем.
IgorekBz Автор
Спасибо за отзыв! Это моя первая публикация на Хабре, и мне пока сложно почувствовать какая информация является лишней для аудитории, и какого стиля повествования лучше придерживаться. Обязательно учту Ваши пожелания в будущем.