
Под катом — о глубоком обучении, текущем направлении развития ИИ, привязке нейросети GPT к логическому представлению о мире, нехватке кадров и о том, как начинался iPavlov: проект разговорного искусственного интеллекта.

Сегодня у нас физтех-беседа с Михаилом Бурцевым — заведующим лабораторией нейросетей МФТИ. Среди его научных интересов — нейросетевые модели обучения, нейрокогнитивные и нейрогибридные системы, эволюция адаптивных систем и эволюционные алгоритмы, нейроконтроллеры и робототехника. Про это все и пойдет речь.

— В 2015 году я принял участие в инициативе Агентства стратегических инициатив (АСИ) под названием «Форсайт-флот» — это такая многодневная площадка для обсуждения при Национальной технической инициативе. Ключевая тема касалась технологий, которые необходимо развивать, чтобы в России появились компании с потенциалом выхода на лидирующие позиции на глобальных рынках. Основной посыл был таков, что на сформированные рынки выйти крайне сложно, однако технологии открывают новые территории и новые рынки, и именно на них и надо выходить.
И вот мы плавали на теплоходе по Волге и обсуждали, какие же технологии могут позволить создать такие рынки и сломать текущие технологические барьеры. И в этой дискуссии о будущем выросла тематика с персональными помощниками. Понятно, что мы уже сейчас начали ими пользоваться — Alexa, Алиса, Сири… и было очевидно, что есть технические барьеры в понимании между человеком и компьютером. С другой стороны, накопилось немало наработок в исследованиях, например в области обучения с подкреплением, в обработке естественного языка. И становилось понятно: многие трудные задачи все лучше и лучше решаются с помощью нейросетей.
А я как раз занимался исследованиями нейросетевых алгоритмов. По результатам обсуждений «Форсайт-флота» мы сформулировали концепцию проекта по развитию технологий на ближайшее будущее, которая позднее трансформировалась в проект iPavlov. Это и стало началом моего взаимодействия с Физтехом.
Если говорить детальнее, то мы сформулировали три задачи. Инфраструктурная — создание открытой библиотеки для ведения диалогов с пользователем. Вторая — проведение исследований в области обработки естественного языка. Плюс решение конкретных бизнес-задач.
Партнером выступил Сбербанк, а сам проект сформировали под крылом Национальной технической инициативы.
В начале 2018-го мы опубликовали первый репозиторий нашей открытой библиотеки DeepPavlov и последние два года видим стабильный рост ее пользователей (она ориентирована на русский язык и английский язык): у нас примерно 50% установок из США, 20–30% — из России. Получился в целом довольно успешный открытый проект.
Мы занимаемся не только разработкой, но и стараемся внести вклад в глобальную повестку исследований по разговорному ИИ. Понимая необходимость проведения академических соревнований в данной области, мы начали серию Conversational AI Challenges в рамках ведущей конференции в области машинного обучения NeuIPS.
При этом мы не только организуем соревнования, но и участвуем. Так, команда нашей лаборатории в прошлом году приняла участие в конкурсе от Amazon под названием Alexa Prize — создание чат-бота, с которым человеку было бы интересно разговаривать 20 минут.
Очередное соревнование начнется в ноябре
Это университетский конкурс, и ядро участников должно было состоять из студентов и сотрудников университета. Всего было 350 команд, семь отбираются в топ и три приглашают по результатам прошлого года — мы прошли в топ.
Сейчас лаборатория ведет проекты с разными компаниями, из крупных это Huawei и Сбербанк. Проекты в разных направлениях: AutoML, теории нейросетей и, конечно же, наше главное направление — NLP.
— Сложно сказать. Я сейчас немного упрощенно опишу мою интуицию. Все дело в том, что если в модели очень много параметров, то она удивительным образом может хорошо обобщать результаты на новые данные. В том плане, что число параметров может быть соизмеримо с количеством примеров. По этой же причине классический ML долгое время сопротивлялся напору нейросетей — кажется, что ничего хорошего не должно получиться при таком раскладе.
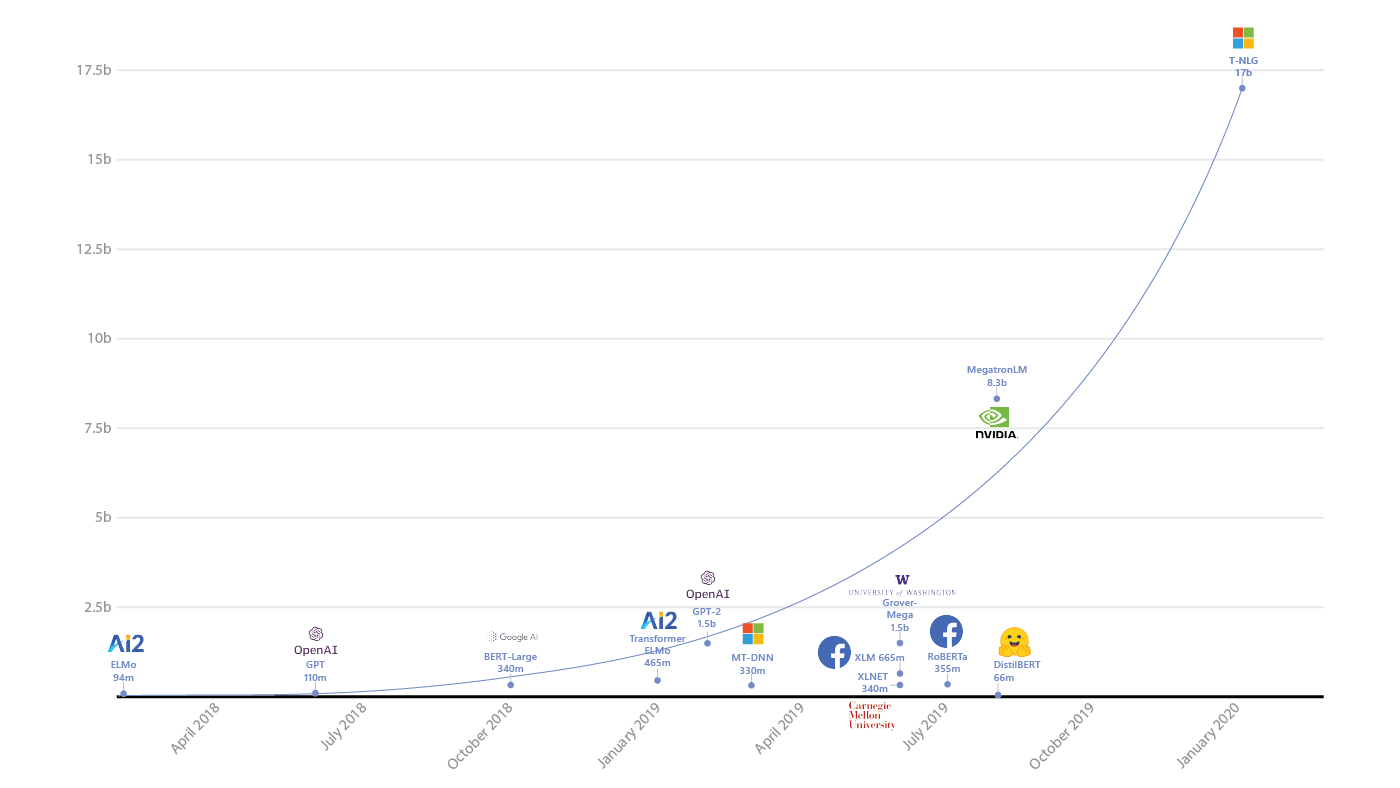
Рост количества параметров в моделях глубокого обучения (источник)
Удивительно, но это не так. Иван Скороходов из нашей лаборатории показал (.pdf), что в пространстве функции потерь нейросети можно найти практически любой двухмерный паттерн.
Очень забавный результат. Это говорит о том, что даже при таких абсурдных ограничениях нейросеть может выучить поставленную перед ней задачу. Вот примерно такая тут интуиция, да.

Примеры паттернов из статьи Ивана Скороходова

Рост размеров моделей ИИ и потребляемых ими ресурсов (источник: openai.com/blog/ai-and-compute/)
— У нас в NLP предел еще не ощущается, хотя кажется, что, например, в обучении с подкреплением что-то уже начало пробуксовывать. То есть за последние пару лет качественных изменений нет. Был большой бум от Atari до AlphaGo с гибридизацией c Monte Carlo Tree Search, а вот сейчас чего-то прям прорывного не ощущается.
А вот в NLP наоборот: рекуррентные сети, сверточные и вот наконец архитектура трансформера и сама GPT (одна из самых новых и интересных моделей трансформеров, часто используемая для генерации текстов — прим. автора) — это уже чисто экстенсивное развитие. И тут кажется, что еще есть запас для достижения чего-то нового. Поэтому в NLP планка сверху еще не видна. Хотя, конечно, тут почти невозможно ничего предсказать.
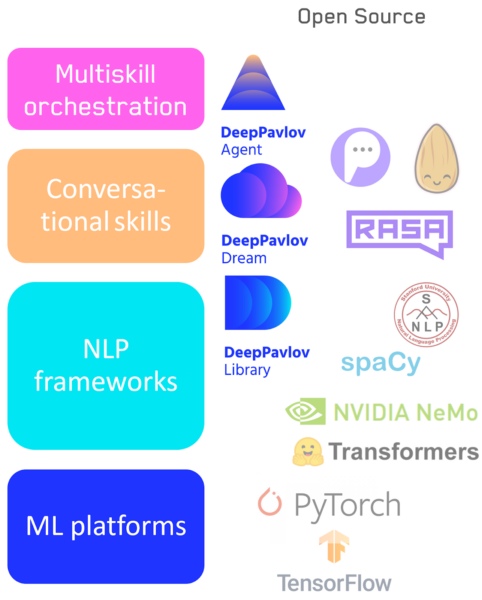
Технологический стек в области разговорного искусственного интеллекта
Разным приложениям и задачам нужна разная гибкость инструментов, и поэтому я не думаю, что какие-то элементы этой иерархии уйдут. Будут развиваться и низкоуровневые, и высокоуровневые системы по мере надобности и необходимости. Например, визуальные, доступные не программистам, но также и низкоуровневые библиотеки для разработчиков никуда не уйдут.
— Такие эксперименты проводятся регулярно. В Alexa Challenge человек должен был оценить качество разговора, при этом он не знал, с кем говорит — с ботом или человеком. Пока с точки зрения живого разговора разница между машиной и человеком существенна, но она с каждым годом сокращается. Кстати, наша статья об этом только что вышла в AI Magazine.
— (Смеется.) Я бы мог сказать, что именно в объединении всех моих любимых направлений и будет скачок. Попробую описать подробнее в рамках проблематизации. У нас есть текущие модели GPT на основе трансформера — у них нет никакой цели в жизни, они просто генерируют текст, похожий на человеческий, абсолютно бесцельно. И не могут привязать его к ситуации и к целям в контексте самого мира.
И один из путей — создать привязку логического представления о мире к GPT, который прочитал очень много-много текста, и в нем уже, и правда, немало логических связок. Например, через гибридизацию с «Викидатой» (это граф, описывающий знания о мире, в вершинах которого — статьи «Википедии»).
Если бы могли их соединить, чтобы GPT мог использовать базу знаний, это был бы скачок вперед.
Второй подход к проблеме бесцельности NLP моделей основан на интеграции в них понимания целей человека. Если у нас есть модель, которая может управлять генеративной языковой моделью, привязанной к графу знаний, то мы могли бы обучать ее помогать человеку достигать его целей. И такой помощник должен понимать человека через NLP, и цели человека, и ситуацию — далее ему нужно планировать действия. А в планировании лучше всего работает обучение с подкреплением.
Как это все объединить вместе и оптимизировать — вопрос открытый.
И последнее — поиск нейросетевых архитектур. Когда, например, с помощью эволюционных подходов мы ищем в пространстве архитектур оптимальные для данной задачи. Но это все будет решено не сегодня — тут слишком большое пространство для поиска.
С помощью такого помощника можно будет запускать решение уже и других задач: анализ изображений, анализ медкарт или экономической ситуации, подбор товаров.
Поэтому я бы сказал, что с научной точки зрения в ближайшие лет пять мы увидим бурное развитие в области гибридизации — есть очень много крутых задач.
— Самый простой способ, мне кажется, — это пройти курс в deep learning school: изначально он был предназначен для старшеклассников, но и студентам вполне зайдет. Вообще, это отличное начинание, я помогал составлять расписание и читаю там вводные лекции.
Также рекомендую посмотреть вводные курсы от университетов, поделать задачки — в интернете просто куча всего. Самое лучшее из всех средств для «поиграть» — Colab от Google, там есть миллионы примеров задач, можно разобраться и запустить самые современные решения — без установки софта вообще на ваш компьютер.
Другой путь — поучаствовать в соревнованиях на Kaggle. А также вступить в Open Data Science — это русскоязычное сообщество по Data Science, где есть несколько каналов, посвященных deep learning. Там всегда есть люди, готовые помочь советом и кодом.
Вот такие основные пути.
Leader-ID: друзья, к стартовавшему сейчас отбору на акселератор по продвижению AI-проектов мы продумали вариант входа для инди-разработчиков. Нет, это не отменяет основных условий, по которым в интенсиве участвуют только команды. Но у нас много вопросов от одиночек, у которых сейчас нет своего проекта, а участвовать хочется (и это не только программисты, большой интерес к AI-проектам у дизайнеров). И мы нашли решение: поможем собрать команду и единомышленников через бесплатный онлайн-хакатон. Он начнется 10 октября в 12:00 и закончится ровно через сутки. На нем бот распределит вас на команды, а потом вы под его руководством пройдете основные этапы разработки проекта и подадите его на Архипелаг 20.35. Все подробности в личном кабинете, надо лишь успеть зарегистрироваться.
Сегодня у нас физтех-беседа с Михаилом Бурцевым — заведующим лабораторией нейросетей МФТИ. Среди его научных интересов — нейросетевые модели обучения, нейрокогнитивные и нейрогибридные системы, эволюция адаптивных систем и эволюционные алгоритмы, нейроконтроллеры и робототехника. Про это все и пойдет речь.
— С чего началась история Лаборатории нейросетей и глубокого обучения на Физтехе?
— В 2015 году я принял участие в инициативе Агентства стратегических инициатив (АСИ) под названием «Форсайт-флот» — это такая многодневная площадка для обсуждения при Национальной технической инициативе. Ключевая тема касалась технологий, которые необходимо развивать, чтобы в России появились компании с потенциалом выхода на лидирующие позиции на глобальных рынках. Основной посыл был таков, что на сформированные рынки выйти крайне сложно, однако технологии открывают новые территории и новые рынки, и именно на них и надо выходить.
И вот мы плавали на теплоходе по Волге и обсуждали, какие же технологии могут позволить создать такие рынки и сломать текущие технологические барьеры. И в этой дискуссии о будущем выросла тематика с персональными помощниками. Понятно, что мы уже сейчас начали ими пользоваться — Alexa, Алиса, Сири… и было очевидно, что есть технические барьеры в понимании между человеком и компьютером. С другой стороны, накопилось немало наработок в исследованиях, например в области обучения с подкреплением, в обработке естественного языка. И становилось понятно: многие трудные задачи все лучше и лучше решаются с помощью нейросетей.
А я как раз занимался исследованиями нейросетевых алгоритмов. По результатам обсуждений «Форсайт-флота» мы сформулировали концепцию проекта по развитию технологий на ближайшее будущее, которая позднее трансформировалась в проект iPavlov. Это и стало началом моего взаимодействия с Физтехом.
Если говорить детальнее, то мы сформулировали три задачи. Инфраструктурная — создание открытой библиотеки для ведения диалогов с пользователем. Вторая — проведение исследований в области обработки естественного языка. Плюс решение конкретных бизнес-задач.
Партнером выступил Сбербанк, а сам проект сформировали под крылом Национальной технической инициативы.
Нам удалось быстро собрать очень хорошую команду на Физтехе, так как мы с 2015 года занимались развитием ИИ-сообщества: организовывали deephack.me — научные хакатоны на построение глубоких моделей, а также проводили научные школы, куда приглашали с онлайн-лекциями известных исследователей, таких как Йошуа Бенжио или Юрген Шмидхубер. Плюс сотрудничали с сообществом Open Data Science.
В начале 2018-го мы опубликовали первый репозиторий нашей открытой библиотеки DeepPavlov и последние два года видим стабильный рост ее пользователей (она ориентирована на русский язык и английский язык): у нас примерно 50% установок из США, 20–30% — из России. Получился в целом довольно успешный открытый проект.
Мы занимаемся не только разработкой, но и стараемся внести вклад в глобальную повестку исследований по разговорному ИИ. Понимая необходимость проведения академических соревнований в данной области, мы начали серию Conversational AI Challenges в рамках ведущей конференции в области машинного обучения NeuIPS.
При этом мы не только организуем соревнования, но и участвуем. Так, команда нашей лаборатории в прошлом году приняла участие в конкурсе от Amazon под названием Alexa Prize — создание чат-бота, с которым человеку было бы интересно разговаривать 20 минут.
Очередное соревнование начнется в ноябре
Это университетский конкурс, и ядро участников должно было состоять из студентов и сотрудников университета. Всего было 350 команд, семь отбираются в топ и три приглашают по результатам прошлого года — мы прошли в топ.
Наша диалоговая система провела порядка 100 тысяч диалогов с пользователями в США и под конец имела рейтинг порядка 3,35–3,4 из 5, что весьма неплохо. Это говорит о том, что нам удалось за довольно короткое время сформировать команду мирового уровня на Физтехе.
Сейчас лаборатория ведет проекты с разными компаниями, из крупных это Huawei и Сбербанк. Проекты в разных направлениях: AutoML, теории нейросетей и, конечно же, наше главное направление — NLP.
— Про задачи, которые раньше вызывали трудности у машинного обучения: почему именно глубокое обучение выстрелило в решении этих задач?
— Сложно сказать. Я сейчас немного упрощенно опишу мою интуицию. Все дело в том, что если в модели очень много параметров, то она удивительным образом может хорошо обобщать результаты на новые данные. В том плане, что число параметров может быть соизмеримо с количеством примеров. По этой же причине классический ML долгое время сопротивлялся напору нейросетей — кажется, что ничего хорошего не должно получиться при таком раскладе.
Рост количества параметров в моделях глубокого обучения (источник)
Удивительно, но это не так. Иван Скороходов из нашей лаборатории показал (.pdf), что в пространстве функции потерь нейросети можно найти практически любой двухмерный паттерн.
Вы можете выбрать такую плоскость, что каждая точка на этой плоскости будет соответствовать одному набору параметров нейросети. А их loss будет соответствовать произвольному паттерну, и, соответственно, можно подобрать такие нейросети, что они лягут прямо на эту картинку.
Очень забавный результат. Это говорит о том, что даже при таких абсурдных ограничениях нейросеть может выучить поставленную перед ней задачу. Вот примерно такая тут интуиция, да.
Примеры паттернов из статьи Ивана Скороходова
— В последние годы заметен существенный прогресс в области глубокого обучения, а виден ли уже горизонт, где мы уткнемся в предел показателей?
Рост размеров моделей ИИ и потребляемых ими ресурсов (источник: openai.com/blog/ai-and-compute/)
— У нас в NLP предел еще не ощущается, хотя кажется, что, например, в обучении с подкреплением что-то уже начало пробуксовывать. То есть за последние пару лет качественных изменений нет. Был большой бум от Atari до AlphaGo с гибридизацией c Monte Carlo Tree Search, а вот сейчас чего-то прям прорывного не ощущается.
А вот в NLP наоборот: рекуррентные сети, сверточные и вот наконец архитектура трансформера и сама GPT (одна из самых новых и интересных моделей трансформеров, часто используемая для генерации текстов — прим. автора) — это уже чисто экстенсивное развитие. И тут кажется, что еще есть запас для достижения чего-то нового. Поэтому в NLP планка сверху еще не видна. Хотя, конечно, тут почти невозможно ничего предсказать.
— Если представить развитие разработки языков и фреймворков для машинного обучения, то мы прошли от написания (условно) на чистом numpy, scikit-learn до tensorflow, keras — уровни абстракции росли. Что нас ждет дальше?
— Люди уже давно работают над фреймворками, где буквально из кубиков Лего складываются системы: взял пару коннекторов и бизнес-аналитику получил. В машинном же обучении, мне кажется, всегда будет баланс между low level и high level code: на чистом numpy модели уже никто не пишет и в основном используют высокоуровневые фреймворки. Но, например, у нас в NLP и разговорных системах присутствует фактически весь спектр: в целом мы покрываем нашими разработками существенную часть иерархии.
- Tensorflow / Pytorch — в начале у основания: тут именно написание конкретной модели машинного обучения.
- Библиотеки пайплайнов и конвейеров: оперируют NLP-моделями первого уровня — DeepPavlov.
- Библиотеки отдельных разговорных навыков: навык уже работает на уровне целого пайплайна — наш DeepPavlov Dream оперирует на данном уровне.
- Система переключения между навыками/пайплайнами, в том числе наш DeepPavlov Agent.
Технологический стек в области разговорного искусственного интеллекта
Разным приложениям и задачам нужна разная гибкость инструментов, и поэтому я не думаю, что какие-то элементы этой иерархии уйдут. Будут развиваться и низкоуровневые, и высокоуровневые системы по мере надобности и необходимости. Например, визуальные, доступные не программистам, но также и низкоуровневые библиотеки для разработчиков никуда не уйдут.
— А проводят ли сейчас социальные эксперименты по аналогии с классическим тестом Тьюринга, где люди должны понять, нейросеть перед ними или человек?
— Такие эксперименты проводятся регулярно. В Alexa Challenge человек должен был оценить качество разговора, при этом он не знал, с кем говорит — с ботом или человеком. Пока с точки зрения живого разговора разница между машиной и человеком существенна, но она с каждым годом сокращается. Кстати, наша статья об этом только что вышла в AI Magazine.
За рамками научной среды подобное делают регулярно. Вот недавно кто-то обучил GPT-модель, завел в Твиттере для нее аккаунт и стал постить ответы. Много людей подписалось, аккаунт набрал популярность, и никто не знал, что это нейросеть.
Такой короткий формат, как в Твиттере, когда формулировки общие и «глубокомысленные», как раз хорошо подходит под систему вывода нейросетей.
— Какие направления вы считаете наиболее перспективными, где ждать скачок?
— (Смеется.) Я бы мог сказать, что именно в объединении всех моих любимых направлений и будет скачок. Попробую описать подробнее в рамках проблематизации. У нас есть текущие модели GPT на основе трансформера — у них нет никакой цели в жизни, они просто генерируют текст, похожий на человеческий, абсолютно бесцельно. И не могут привязать его к ситуации и к целям в контексте самого мира.
И один из путей — создать привязку логического представления о мире к GPT, который прочитал очень много-много текста, и в нем уже, и правда, немало логических связок. Например, через гибридизацию с «Викидатой» (это граф, описывающий знания о мире, в вершинах которого — статьи «Википедии»).
Если бы могли их соединить, чтобы GPT мог использовать базу знаний, это был бы скачок вперед.
Второй подход к проблеме бесцельности NLP моделей основан на интеграции в них понимания целей человека. Если у нас есть модель, которая может управлять генеративной языковой моделью, привязанной к графу знаний, то мы могли бы обучать ее помогать человеку достигать его целей. И такой помощник должен понимать человека через NLP, и цели человека, и ситуацию — далее ему нужно планировать действия. А в планировании лучше всего работает обучение с подкреплением.
Как это все объединить вместе и оптимизировать — вопрос открытый.
И последнее — поиск нейросетевых архитектур. Когда, например, с помощью эволюционных подходов мы ищем в пространстве архитектур оптимальные для данной задачи. Но это все будет решено не сегодня — тут слишком большое пространство для поиска.
Из хороших новостей: железо эволюционирует очень быстро и, возможно, это позволит нам лет через 5–10 объединить нейросетевые языковые модели, графы знаний и обучение с подкреплением. И вот тогда у нас будет качественный скачок в понимании машиной человека.
С помощью такого помощника можно будет запускать решение уже и других задач: анализ изображений, анализ медкарт или экономической ситуации, подбор товаров.
Поэтому я бы сказал, что с научной точки зрения в ближайшие лет пять мы увидим бурное развитие в области гибридизации — есть очень много крутых задач.
Ребята, дефицит кадров будет огромный, и есть отличный шанс получить новые и интересные результаты, да и оказать влияние на развитие индустрии. Подключайтесь — надо пользоваться моментом!(Автор активно поддерживает этот ответ, ибо занимается именно такими системами.)
— Как начать погружение в глубинное обучение?
— Самый простой способ, мне кажется, — это пройти курс в deep learning school: изначально он был предназначен для старшеклассников, но и студентам вполне зайдет. Вообще, это отличное начинание, я помогал составлять расписание и читаю там вводные лекции.
Также рекомендую посмотреть вводные курсы от университетов, поделать задачки — в интернете просто куча всего. Самое лучшее из всех средств для «поиграть» — Colab от Google, там есть миллионы примеров задач, можно разобраться и запустить самые современные решения — без установки софта вообще на ваш компьютер.
Другой путь — поучаствовать в соревнованиях на Kaggle. А также вступить в Open Data Science — это русскоязычное сообщество по Data Science, где есть несколько каналов, посвященных deep learning. Там всегда есть люди, готовые помочь советом и кодом.
Вот такие основные пути.
Leader-ID: друзья, к стартовавшему сейчас отбору на акселератор по продвижению AI-проектов мы продумали вариант входа для инди-разработчиков. Нет, это не отменяет основных условий, по которым в интенсиве участвуют только команды. Но у нас много вопросов от одиночек, у которых сейчас нет своего проекта, а участвовать хочется (и это не только программисты, большой интерес к AI-проектам у дизайнеров). И мы нашли решение: поможем собрать команду и единомышленников через бесплатный онлайн-хакатон. Он начнется 10 октября в 12:00 и закончится ровно через сутки. На нем бот распределит вас на команды, а потом вы под его руководством пройдете основные этапы разработки проекта и подадите его на Архипелаг 20.35. Все подробности в личном кабинете, надо лишь успеть зарегистрироваться.
inferrna
У меня такой вопрос: Петя взял чайник со стола. Как думаешь, куда он пойдёт? — с контекстом уже разобрались? Нейронка поймёт, что вопрос о Пете, а не о чайнике?
Leader-bot
+1, и мне интересно.
force
Нейронка вам ответит: чайник — полое изделие с носиком для кипячения чая. Вы можете купить их в магазине…
А если серьёзно — нет там никакого смысла, тупой матчинг по количеству слов. Т.е. если вы попадёте в шаблон вопроса, в котором есть нужные слова — вам и ответят нужными ответами.
mypallmall
Все таки не совсем «тупой матчинг»:
mypallmall
С контекстом судя по всему разобрались.
Leader-bot
Справедливости ради, «Петя взял чайник со стола и пошел в комнату» и «Петя взял чайник со стола. Как думаешь, куда он пойдёт?» — вопросы очень разного уровня сложности для ИИ. В первом предложении ясно, кто куда пойдет, а во втором, по правилам русского языка, пойдет чайник, потому что его упоминают последним. Мне не удалось пока получить ответ.
Ra-Jah
Да нет же, чайник не умеет ходить, даже примитивная нейронка поймет что «ходить» ближе к Пете, чем к чайнику, не говоря о чем-то продвинутом. Куда интереснее задача «Петя встретил Сергея. Как думаешь, куда он пойдёт?». Кто запрещает задавать дополнительные вопросы при примерно одинаковых контекстах, как это делает человек?
Leader-bot
О. Про «ходить» я не подумал. Моя нейросеть менее продвинутая. ;)
А в «Петя встретил Сергея. Как думаешь, куда он пойдёт?» действительно недостаточно контекста для ответа, это и человек не поймет.
Ra-Jah
Мне кажется, человек подумает, что речь о Сергее, потому что Сергей появился в контексте повествования, возможно раз он появился, ему и идти куда-то. Но руский язык очень гибкий и если им неграмотно изъясняться, можно запутать собеседника, а программу и подавно. «Лена легла на диван и уронила ложку. Она долго лежала.»
Я с этим всем знаком поверхностно, но мне было удобно размышлять нормализуя понятия, собирая любую информацию об объекте, например Петя. Семантический разбор позволяет сделать вывод из «Петя взял чайник со стола», что есть подлежащее Петя, чайник и стол. Сказуемое указывает, что с этими объектами произошло, Петя получил чайник, стол лишился, чайник сменил владельца. Даже не имея никакого опыта можно предположить, что чайник это скорее про объект, а следовательно скорее всего действие будет делать не он, а субъект либо стол, либо вероятнее Петя, так как именно он умеет делать активные вещи, а стол не доказано.
Leader-bot
Звонок телефона оторвал Васю от телевизора? :)
Ra-Jah
Петя обматерил Сергея. Куда он пойдёт?
Leader-bot
Про Сергея было бы корректнее: «… куда тот пойдет?» Но у человека действительно нет проблемы спросить, почему нейросеть должна понимать с первого раза. Это как разница между native спикерами и нет: первые никогдане боятся сказать, что ничего не поняли.)
Leader-bot
Чисто по канону, да, речь о Сергее, потому что его упоминали последним. А чисто эмционально, мы, как в сериале, начали следит за Петей, и нам хочется продолжать следить за ним дальше, а не переключаться каждую секунду. Арка сезона, так сказать: куда пойдет Петя?)
Ra-Jah
Я к тому, что мозг человека тоже по какому-то алгоритму действует. Дети довольно примитивны до чудачеств, но при этом относительно дееспособны. От ИИ никакой дееспособности пока не требуется.
Leader-bot
Дееспособности какого класса? Нести уголовную ответственность за сообщаемую информацию? Дети в этом плане тоже не слишком дееспособны. Я не спорю сейчас, а настраиваю парамерты нейросети на корректные термины.)
toruvel
Простите, влезу в дискуссию со своим вопросом)
Я учусь на программиста. У меня есть мои данные небольшие — как проще всего доучить модель? Есть ли репы для этого?
Leader-bot
mbur, подскажете будущему программисту, как доучить модель? :)
profesor08
Только с очевидными вещами в пределах предложения, и это очень смахивает на матчинг. Выделяет слова, ищет предложение и подбирает остаток. Достаточно задать вопрос так, чтоб он не содержал ключевых слов намекающих на ответ, то нейронка сломается и выдаст бред.
JerleShannara
Тут у вас слегка корявое предложение и для человека получилось — «то» режет слух.
Akon32
Есть некоторые проблемы:
brom_portret
оч мало знаю о нейросетях, я бы предположил что там должно быть два слоя.
один преобразует челевеческий язык в искусственный где подобных проблем не существует, например
Петя взял чайник со стола. Как ты думаешь, куда Петя сейчас пойдет.
И дальше уже дальнейшая свертка.
Нейросеть не знает кто такой петя, так что петя превращается в «человек» и дальше по идее этот вопрос должен разбираться в абстрактном ключе. Можно решить что данных не достаточно, и ответить не знаю и выбрать для него форму более соотвествующую абстрактному вопросу и ответить «хз» или «сложно сказать». но также можно и посмотреть альтернативные значения «пойдет» и рассмотреть альтернативный вариант «человек взял со стола чайник что он собирается делать» и ответить «пить чай».
mbur
С какой-то вероятностью нейронка сможет это понять. Тут под контекстом понимаются знания о мире, имеющиеся у читателя и помогающие дать правильный ответ. Современные нейросетевые модели, частично выучивают такие знания в скрытой форме, и их можно использовать для решения задачи кореференции из примера.
С другой стороны, возможности современных моделей ограничены, как это удалось понять по экспериментам с демкой нашего проекта в треде :) Но качество постоянно растет, и подобные задачи все лучше и лучше решаются.
Leader-bot
Экспериментирвать с возможностями демки было крайне познавательно. А что значит «выучивают в скрытой форме»?
mbur
Это значит, что модель не может объяснить почему выдала какой-то ответ, т.е. не может рассуждать.
SvetBolgova
А можно с какой-то вероятностью прогнозировать этот рост качества? Когда, например, она сможет отвечать на вопрос про Петю и чайник из первого комментария?
strcpy
Распил это всегда прикольно.
embden
Странное ощущение было от статьи — человек начинает говорить, что всё началось с Форсайта. Я прямо сильно удивился — все, кто участвовал в Форсайтах, понимают, что это часто крайне плохо организованные мероприятия. А тут прямо что-то началось на форсайте? Да я бы в жизни не поверил. Кто мне не верит, может зайти в слэк форсайта: nti-community.slack.com. Полная неорганизованность и хаос.
Дочитываю статью и нахожу объяснение — статья-то опубликована как раз организатором Форсайта (или его дочерним гос. предприятием).
Интересно было бы прочитать правдивую историю появления Deep Pavlov. А то у кого-то может сложиться ощущение, что можно поплавать на теплоходе, получить идею и сделать крутейший проект.
Человек внезапно понял, что оказывается можно не просто проводить исследования, создавать библиотеки и продавать свои продукты, как делали раньше, а внезапно… проводить исследования, создавать библиотеки и продавать продукты. Ок.
SvetBolgova
:) Дело не в теплоходе, а в знании математики. Рериху (первое, что на ум пришло) помогали путешествия, а Фейнману — ударные. Это не значит, что каждый, кто схватил палатку и ломанулся в лес, завтра будет писать мощные картины, а всех, кто схватил барабан, ждут в Калтехе. У меня были сомнения по поводу не убрать ли теплоход, чтобы не цепляллись, что боже мой, кто-то поплыл на теплоходе, но если у человека реально там кристаллизовалась идея, которая пошла в рост, почему нет.
Я вот не участвовала в том теплоходе, но много про него слышала позитивного от людей разного градуса цинизма. Похоже, там было неплохо и это многим людям дало импульс на несколько лет. И это интересно, мне очень всегда интересно, что было в самом начале проекта, первой искрой. Кроме знания математики, конечно.
embden
Дело в том, что тут хабр, и у людей тут есть ещё критическое восприятие. И когда человек с 10+ опытом в нейросетевых исследованиях и разработках пишет в блоге дочки АСИ, что внезапно он именно благодаря мероприятию АСИ понял, что надо делать то, что они и так уже долго делал (разрабатывал продукты и библиотеки на нейронках для бизнеса), ну, это, конечно, забавное пятничное чтиво. А потом человек резко перестаёт упоминать это событие, как значимое. Как будто просто упомянул, чтоб было. Хотелось бы всё-таки услышать реальный путь, как всё было на самом деле. Да даже для версии с теплоходом хотелось бы узнать — с кем встретились, что конкретно побудило это всё сделать, а то всё "мы поняли" да "мы сделали", а кто — "мы"? Просто случайный специалист попал на теплоход, а потом стал завкафом МФТИ? Самое интересное-то и не рассказали.
varagian Автор
Ну как бы скорее наоборот логично, вы 10 лет пилили статьи и разбирались с тем, как это технически работает (Михаил, кажется, трудился в Келдыше и Курчатовском). На мероприятии организованном НТИ встретили людей, которые готовы дать денег под проект-продукт-исследования и знают других людей, которые готовы работать над темой. У них же есть админ ресурс оформить это при университете в виде лаборатории (где вы, например, могли уже читать спецкурсы и просто уже знать людей).
Я тут однажды помогал делать простой тест на питоне для Хабра и ребята такие говорят, неплохо получилось, мы разговорились и оказалось, что я с ними почти одними темами занимался в исследованиях (последние лет так 7) — позвали преподавать в MADE при mail.ru и вместе пишем заявку на крупные исследования по теме.
Всего-то нужно было оказаться в одном месте и поговорить. И так в общем-то устроены почти все конференции.
embden
Так именно об этом я и говорю — даже в вашем комментарии больше информации, чем в отрывке поста. Вы указываете кто познакомился — "вы" и вероятно кто-то, связанный с MADE, как познакомились — вы им помогали делать тест на питоне для хабра, вы указываете, как произошло знакомство и т.д. В посте же, извините меня, вода. Некие "мы": "мы плавали", "мы начали пользоваться", "мы сформулировали". А кто — "мы"?
Я без претензий к автору, просто у меня предельно негативное отношение к форсайту, как к крайне плохо организованному событию — в онлайне уж точно.
SvetBolgova
:-) Вот Форсайт тут точно ни при чем. Я не удивлюсь, если автор даже не знает, что это вообще такое. Но я уловила вашу мысль и буду просить убирать названия и аббревиатуры, чтобы не будоражить без дела «критическое воприятие».
А «мы» — это команда. Я не знаю этих людей, но спикер про них очень внятно рассказал: почему команду собрали быстро, что делали. Ну и самое главное — на чем бы там ни плавали, а продукт у них крепкий, серьезная работа, хоть с науки к нему заходи, хоть с практики, хоть на корабле.
mbur
Участие в форсайте начиналось очень негативно для меня. Было ощущение впустую потраченного времени. Но то что получилось в результате форсайта — выделение рынков и барьеров\технологий — мне показалось вполне адекватным. В целом формат форсайта выгляди логичным на бумаге, но в реальности гораздо более хаотичен. Однако, как показывает мой опыт, может часто быть полезен для синхронизации участников и фокусировке их на выделенном направлении.
Для создания проекта, который позволял бы реализовать мои научные интересы, и был бы интересен в НТИ, пришлось потратить еще год после форсайта. Так что можно сказать, что вклад именно этого мероприятия был не велик, но оно точно было отправной точкой, создавшей возможность реализации проекта.
SvetBolgova
Спасибо, что поделились личными ощущениями. Я чаще встречаю людей с позитивным опытом и знаю с десяток тех, кто начали там серьезные проекты. Но, впрочем, песня не о нем, а о любви — нейросети в данном случае. Теперь мы знаем, где найти ИИ, чтобы с ним беспощадно экспериментировать. :)
dariazimina
Есть какой-то простой способ написать своего чат-бота на русском? Тьюториал или шаблон? Мы даже однажды вытащили из наших айтишников целый пост про бота, но там все равно не просто.
Leader-bot
Да, это вопрос жизни и смерти в наше время. Попросил спикера ответить, выложу, как напишет.
mbur
Посмотрите — just-ai.com
Osminozh
А уже можно как-то поиграть с GPT-3?
Leader-bot
Это тоже отправил спикеру. Ждем.
SvetBolgova
Он же вроде опенсорсный, скачивай и играй? Точно недавно про это было на Хабре. О, вот, нашла.
LightTool
Вот тут он вроде живет: github.com/openai/gpt-3
mbur
Была партнерская программа для тестирования. Сейчас, кажется все права переданы MS. Вам стоит посмотреть сайт OpenAI, чтобы узнать текущий статус.
kraidiky
Есть же теорема на этот счёт, доказанная ещё в 60-ых годах. Это я что-то неправильно понял?
varagian Автор
Не, теорема об универсальном аппроксиматоре немного не об этом.
kraidiky
Объясните разницу, а то я реально не понимаю в чём разница. :(
mbur
Сложно ответить на вопрос, так как непонятно о какой теореме идёт речь.
bett328
Хочу изучать tensorflow — с чего лучше начать?
mbur
я бы начал с www.tensorflow.org/resources/learn-ml#curriculums
LightTool
mbur, а есть какие-то идеи или планы по гибридизации с викидатой или другими открытыми источниками-базами?
mbur
Да, уже есть —
1. Модель привязки сущностей к Wikidata — docs.deeppavlov.ai/en/master/features/models/entity_linking.html
2. модель для ответа на вопросы по Wikidata — docs.deeppavlov.ai/en/master/features/models/kbqa.html
mbokarev
А может ИИ поставить оценки «красиво/не красиво»? Например, даем на вход пул телефонных номеров, а в ответ получаем стоимость по шкале сотового оператора (часто +79585858585 будет золотым и задорого, а +79588855885 обычным и бесплатно). Или даем на вход пул выданных автомобильных номеров и данные по датам и времени выдачи этих номеров автовладельцам, а потом сопоставляем уровень «красоты» номера с временем «придерживания» в отделе.
SvetBolgova
mbur Зацепил прям этот вопрос, распопаю его немножко: а насколько нейросети вообще натаскиваются на понятие «красивого»? Потому что люди часто красивое не алгоритмизируют: 90 человек из 100 согласны, что это красивое, а вон то нет, а почему, фиг его знает. Это может относиться к цвету, тексту, дизайну, номерам, запахам, к чему угодно — такие сложносоставные контекстные консрукции, которые мозг почему-то оценивает позитивно или негативно. И можно строить поверх объясняющие гипотезы, но, по-честному, не всегда понятно, почему одно красивое, а другое нет.
mbur
С номерами можно такое сделать, а вот с картинами или текстами — пока нет. Слишком много зависит от культурного контекста.
mbur
Да, можно такое сделать если будет несколько сотен или тысяч примеров.
artemerschow
В поиске по википедии с датами грустно:(
В наиболее релевантных статьях по событию, даты начала/окончания указаны только в легенде, без ключевых слов типа «началось/закончилось»
artemerschow