

Тернист и труден путь человека, столкнувшегося с ФГИС ЕГРН Росреестра. Его ждут бесконечные ожидания загрузки браузера, ключи, капчи, интервалы между запросами в 5 минут. За что ему такие страдания? Он же уже внес свои кровные, когда решился работать с данной системой и заказывать свои выписки. Но нет — получение выписки из ЕГРН, это как раздевание репчатого лука. Последний шаг, который поджидает страдальца — скачанная, вожделенная выписка представлена zip архивом, в котором, гм, еще один архив и файл sig. А уже внутри лежит сам файл выписки. Но прочитать его тоже непросто — он в xml. И чтобы все срослось, необходимо, оказывается загружать этот xml вместе с sig на специальную страницу Росреестра. А там, там еще капча ждет. И так с каждой выпиской! Вот эту последнюю боль будем сегодня побеждать, используя python.
Задача:
- распаковать все zip в папке,
- загрузить по спец. ссылке в Росреестр,
- скачать, наконец!, человекочитаемый вид выписки.
Итак, первоначально в папке имеются скачанные zip архивы выписок:
После импорта модулей python:
import os
import zipfile
import webbrowser,time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
Распакуем все zip архивы и удалим их, чтобы они не путались с содержимым:
zipFiles = []
sigFiles = []
for filename in os.listdir('.'):
if filename.endswith('.zip'):
zipfile.ZipFile(filename, 'r').extractall()
os.remove(filename)
Получились zip архивы и sig файлы к ним, которые далее будут загружаться на сайт Росреестра:
Переходим к основному циклу программы по всем файлам в директории (в моем случае «С:/2»):
for filename in zipFiles:
act = browser.find_element_by_id('sig_file')
act.send_keys('C:\\2\\'+str(filename)+'.sig')
act = browser.find_element_by_id('xml_file')
#распаковываем zip файл
zip_ref = zipfile.ZipFile(filename, 'r').extractall()
#берем xml из распакованного
for f in os.listdir('.'):
if f.endswith('.xml'):
print(f)
#вводим xml файл на сайте
act.send_keys('C:\\2\\'+str(f))
act = browser.find_element_by_css_selector('input.brdg1111')
act.click()
i = str(input("Введите каптчу: "))
for b in i:
act.send_keys(b)
time.sleep (0.1)
#act.submit()
act = browser.find_element_by_css_selector('.terminal-button-bright')
act.click()
time.sleep (5)
try:
act = browser.find_element_by_link_text('Показать в человекочитаемом формате')
act.click()
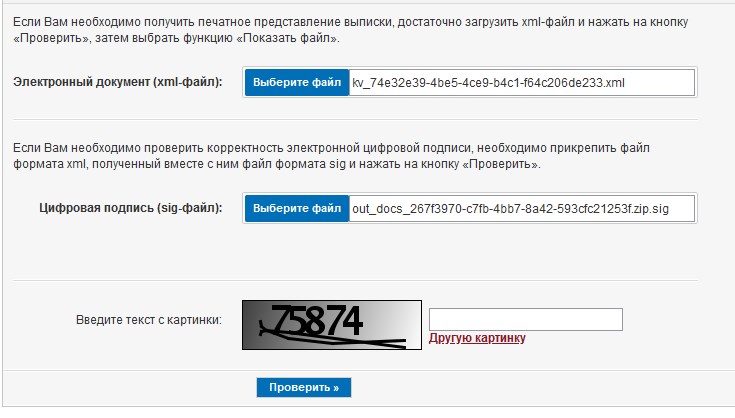
После успешной загрузки страницы портала Росреестра rosreestr.gov.ru/wps/portal/cc_vizualisation, программа найдет в директории zip архив, достанет оттуда xml файл выписки и вставит в нужное поле на сайте. То же самое программа сделает с файлом sig, прилагаемым к xml:
Далее программа будет ждать ввода капчи:
После ввода пользователем капчи, она отправит ее на сайт и нажмет на ссылку скачивания уже «нормальной» выписки из ЕГРН:
Откроется окно, в котором будет готовая выписка, сохранить которую можно в html либо, нажав в Chrome CTRL+P, — в pdf.
Осталось добавить авторазгадывание капчи и автоскачивание человекочитаемых выписок. Но это ведь самое простое здесь, не так ли?
Код программы — здесь.



TheGodfather
Вы бы хоть код в каком-нибудь авто-форматтере прогнали что ли перед тем, как публиковать… PEP8? Не, не слышал.