

До недавнего времени в Одноклассниках в качестве основного Linux-дистрибутива использовался частично обновлённый OpenSuSE 10.2. Однако, поддерживать его становилось всё труднее, поэтому с прошлого года мы перешли к активной миграции на CentOS 7. На подготовительном этапе перехода для CentOS были отработаны все внутренние процедуры, подготовлены конфиги и политики настройки (мы используем CFEngine). Поэтому сейчас во многих случаях миграция с одного дистрибутива на другой заключается в установке ОС через kickstart и развёртывании приложения с помощью системы деплоя нашей разработки — всё остальное осуществляется без участия человека. Так происходит во многих случаях, хотя и не во всех.
Но с самыми большими проблемами мы столкнулись при миграции серверов раздачи видео. На их решение у нас ушло полгода.
Вкратце об их конфигурации:
- 4 x 10 Гбит к пользователям
- 2 x 10 Гбит к хранилищу
- 256 Гбайт RAM — кэш в памяти
- 22 х 480 Гбайт SSD — кэша на SSD
- 2 х E5-2690 v2
Несколько метрик, характеризующих раздачу видео:
- 600 Гбит/сек. — общая пиковая скорость отдачи видео
- 220М просмотров видео в день
- 600К одновременно просматриваемых видео
Проблема 1 — сильный рост CPU system time

Вскоре после запуска первого сервера начала сильно расти нагрузка на процессор по system time.
В это же время в top было видно множество migration и ksoftirqd процессов. Сначала мы попробовали крутить настройки ядра. Что нам не помогло:
- увеличение sched_migration_cost
- отключение transparent_hugepage
- увеличение vfs_cache_pressure
- отключение NUMA
При очередном росте нагрузки perf top показал 50% нагрузки на isolate_freepages_block. Само по себе название вызова нам, к сожалению, ничего не говорит. Но вот слово freepages несколько смутило, т.к. свободной памяти на сервере было около 45 Гбайт. Из своего опыта мы уже знали, что если на сервере много свободной памяти, а ядро всё равно жалуется на его нехватку (иногда это выражается в запуске OOM killer), то, скорее всего, проблема во фрагментации. Сброс дискового кеша (
echo 3 > /proc/sys/vm/drop_caches) моментально исцелял сервер, что только подтверждало наши предположения.Фрагментация памяти — нередкая проблема (и характерна не только для Linux), и в ядро регулярно вносятся изменения для борьбы с ней. Одним из виновников фрагментации является само ядро, точнее дисковый кеш, который нельзя ни отключить, ни ограничить в объёме. Это не значит, что фрагментация в нашем случае была вызвана именно дисковым кешем, но точные причины были не так важны. Важнее было решение — дефрагментация. Такой механизм есть в ядре, но очевидно, что он не справлялся (либо вместо него запускалось высвобождение памяти — global reclaim). Дефрагментация запускается только тогда, когда свободная память опускается ниже определённой отметки (zone watermark), и в нашем случае это происходило слишком поздно. Единственный способ заставить её запускаться раньше — это повысить min_free_kbytes через sysctl. Данный параметр говорит ядру стараться держать часть памяти свободной, а чтобы удовлетворить это требование, ему приходится запускать дефрагментацию раньше. В нашем случае хватило значения в 1 Гбайт.
Проблема 2 — уход в swap
Для начала стоит упомянуть, что мы используем vm.swappiness=0, так как точно знаем, что для нас своп — это зло. Итак, на сервере около 45 Гбайт свободной памяти и всё же он периодически уходит в своп. Как такое возможно? Для начала стоит напомнить, что память в Linux — это не один большой кусок.
- Память делится на ноды: один физический процессор — одна нода.
- Каждая нода делится на зоны (представление для 64-битных систем) — ZONE_DMA (0-16 Мбайт), ZONE_DMA32 (0-4 Гбайт), ZONE_NORMAL (4+ Гбайт).
- Каждая зона делится на области памяти размером степеней двойки (order of 2), т.е. 20*PAGE_SIZE, 21*PAGE_SIZE...210*PAGE_SIZE (текущее распределение можно посмотреть в /proc/buddyinfo). Отсутствие свободных областей большого размера — это и есть фрагментация, о которой мы говорили в предыдущем разделе.
Сначала мы опять винили фрагментацию, но дальнейшее увеличение min_free_kbytes, а также увеличение vfs_cache_pressure нам не помогло. Пришлось познакомиться с утилитой numastat (
numastat -m < PID >).Но сначала ещё одно отступление про работу приложения раздачи видео. На сервере замонтирован tmpfs (занимает почти всю память), на котором приложение создаёт 1 файл и использует его в качестве кеша.
Что же мы увидели в выводе numastat? А то, что различные типы памяти распределены между нодами крайне неравномерно:
| Per-node process memory usage (in MBs) for PID 7781 (java) | |||
|---|---|---|---|
| Node 0 | Node 1 | Total | |
| Huge | 0 | 0 | 0 |
| Heap | 0.20 | 0.14 | 0.34 |
| Stack | 118.82 | 137.87 | 256.70 |
| Private | 80200.73 | 123323.81 | 203524.55 |
| Total | 80319.76 | 123461.82 | 203781.58 |
| Per-node system memory usage (in MBs): | |||
| Node 0 | Node 1 | Total | |
| MemTotal | 131032.75 | 131072.00 | 262104.75 |
| MemFree | 1228.93 | 639.84 | 1868.78 |
| MemUsed | 129803.82 | 130432.16 | 260235.98 |
| Active | 23224.13 | 121073.42 | 144297.55 |
| Inactive | 101138.88 | 3753.98 | 104892.85 |
| Active(anon) | 1690.50 | 120997.86 | 122688.36 |
| Inactive(anon) | 79528.66 | 3560.95 | 83089.61 |
| Active(file) | 21533.63 | 75.57 | 21609.20 |
| Inactive(file) | 21610.21 | 193.03 | 21803.24 |
| Unevictable | 0 | 0 | 0 |
| Mlocked | 0 | 0 | 0 |
| Dirty | 0.11 | 0.02 | 0.13 |
| Writeback | 0 | 0 | 0 |
| FilePages | 122397.46 | 124295.47 | 246692.93 |
| Mapped | 78436.03 | 122947.26 | 201383.29 |
| AnonPages | 1966.62 | 532.02 | 2498.64 |
| Shmem | 79251.21 | 123964.70 | 203215.90 |
| KernelStack | 2.44 | 2.57 | 5.01 |
| PageTables | 158.62 | 252.29 | 410.91 |
| NFS_Unstable | 0 | 0 | 0 |
| Bounce | 0 | 0 | 0 |
| WritebackTmp | 0 | 0 | 0 |
| Slab | 1801.95 | 1932.29 | 3734.23 |
| SReclaimable | 1653.13 | 1818.79 | 3471.92 |
| SUnreclaim | 148.82 | 113.49 | 262.31 |
| AnonHugePages | 1856.00 | 498.00 | 2354.00 |
| HugePages_Total | 0 | 0 | 0 |
| HugePages_Free | 0 | 0 | 0 |
| HugePages_Surp | 0 | 0 | 0 |
За распределение памяти между нодами отвечает технология NUMA, и она не может равномерно распределить 1 файл в tmpfs между нодами. Запуск приложения в режиме interleave (numactl —interleave=all, равномерное распределение памяти приложения между нодами) решило нашу проблему.
Проблема 3 — неравномерное распределение нагрузки по ядрам
Пожалуй, все, кто работал с большим трафиком, сталкивались с проблемой распределения прерываний между ядрами процессоров. Чаще всего проблема исследуется и решается так (здесь приведены все шаги, но не обязательно, что вы столкнётесь с каждым):
- CPU0 нагружен больше остальных (особенно много softirq). Проблема в том, что у сетевого адаптера только одна очередь, она работает на одном прерывании, которое работает на одном ядре. Настраиваем очереди сетевой карты (раньше это делалось через опции драйвера, сейчас через
ethtool -l/-L). Например, для 1 Гбит карт Intel очередей может быть 8, для 10 Гбит карт — до 128. - Нагрузка не перераспределилась. Очередей много, прерываний много, но все на CPU0. Включаем демон irq_balancer.
- Нагрузка распределяется не равномерно. Ну что же, автоматика не идеальна, нужен ручной режим. Находим в сети популярный set_irq_affinity (или его аналог) и запускаем — так мы настроили RSS (receive side scaling) — первую технологию из увлекательного документа от разработчиков ядра https://www.kernel.org/doc/Documentation/networking/scaling.txt.
- Нагрузка ложится только на 8 первых ядер, если у нас всего 8 очередей, или нагрузка ложится только на 16 ядер, даже если очередей больше.
Эээ?.. Об этом расскажу подробнее.
Для начала разберёмся с ограничением в 16 ядер и с тем, почему Intel позволяет делать много очередей (на 10 Гбит), а загружает, в основном, первые 16.
Волшебная цифра 16 — это максимальное количество очередей, на которое может распределить трафик RSS. Длина хеша RSS-индекса нормальная, но используются только последние 4 бита, поэтому максимальное количество очередей, которое он может выдать — 16. Это ограничение самой технологии и с ним ничего сделать нельзя.
Что касается конкретно карт Intel, то тут всё несколько интереснее. Во-первых, у карт есть возможность статически привязывать трафик на основе классификаторов к определённым очередям (причём классификация работает на стороне карты, без задействования ресурсов процессора). Мы не тестировали эту технологию, т.к. статическая конфигурация нам, в данном случае, не подходит.
Во-вторых, у карт есть Flow director.
Сразу оговорюсь, что в коде драйверов, в документации драйверов, в документации карт и в документации утилит часто используются разные термины для одних и тех же вещей, что порождает много путаницы. Надеюсь, нам удалось распутать этот клубок правильно.
Flow director
Flow director, судя по доке Intel, работает в 2 режимах — Signature Filter (он же ATR — Application Targeted Receive) и Perfect filter. Flow director не воспринимает не-IP пакеты, туннелированные пакеты и фрагментированные пакеты. Можно посмотреть статистику попавших/не попавших пакетов в flow director:
ethtool -S ethN|grep fdirPerfect filter (ntuple)
Может содержать не более 8 000 правил. Классификатор пакетов Perfect filter просматривается/настраивается через
ethtool -u/U flow-type.Signature Filter
Может содержать не более 32 000 правил. Согласно интернетам, ATR запоминает, в какую очередь (и на каком процессоре) _ушёл_ SYN пакет и направляет приходящие пакеты этого потока через ту же очередь.
During transmission of a packet (every 20 packets by default), a hash is calculated based on the 5-tuple. The (up to) 15-bit hash result is used as an index in a hash lookup table to store the TX queue. When a packet is received, a similar hash is calculated and used to look up an associated Receive Queue. For uni-directional incoming flows, the hash lookup tables will not be initialized and Flow Director will not work. For bidirectional flows, the core handling the interrupt will be the same as the core running the process handling the network flow.
[1]
Т.е., для входящего пакета будет использоваться та же очередь, в которую был помещён первый исходящий SYN, или каждый 20 пакет (конфигурация этого числа в новом драйвере отсутствует, а в старых называлась AtrSampleRate). Если пакет не попадает в ATR, то он классифицируется по RSS (т.е. на первые 16 ядер). Последний факт и навёл нас на правильный путь. Посмотрев статистику flow director через
ethtool -S ethN | grep fdir, мы увидели большое количество fdir_miss. Т.е. пакеты не обрабатывались в ATR, а проваливались до RSS. В результате большая часть нагрузки ложилась на первые 16 ядер. Разработчики драйвера ответили (https://sourceforge.net/p/e1000/bugs/464/), что у нас слишком много потоков, поэтому нам лучше использовать софтверный аналог этой технологии — RPS.Раз оно нам не помогает, то лучше отключить совсем — для этого делаем
ethtool -k ethN ntuple on. Эта команда не только выключает ATR, но и включает Perfect filter, который, однако, без правил совсем никак не помогает, но и не мешает.RPS (receive packet steering)
Чисто софтверный механизм. Технология номер 2 (после RSS) в уже упомянутом документе от разработчиков ядра — scaling.txt.
Прерывания не трогает вообще (можно распределить статически или через irq_balancer).
Изначально этот механизм был создан для распределения нагрузки по ядрам на картах с одной очередью. Однако, как мы теперь понимаем, он также хорош, когда количество очередей и ядер больше 16. Суть этого механизма в том, что независимо от того, в какую очередь пришёл пакет, обрабатываться он будет на ядре, выбранном по хешу. Хеш RPS, в отличие от RSS, может выдать результат больше 16 (т.к. использует его целиком), поэтому задействуются все ядра (если быть точнее, то в файле rps_cpus можно указать, какие конкретно ядра разрешено использовать).
Т.к. эта технология использует ресурсы процессора, то, конечно, есть некоторый оверхед, но он незначительный, т.к. самую тяжёлую операцию — расчёт хеша — всё равно делает карта. Не останавливаясь на достигнутом, продолжаем читать уже полюбившийся scaling.txt и находим там RFS.
RFS (receive flow steering)
Что же нам даёт замена одного слова в названии? При использовании этого механизма пакеты распределяются между ядрами не только на основе хеша, но и на основе того, на каком ядре висит тред приложения, ожидающий эти пакеты. Т.е. пакет отправляется не на фиксированное ядро, а туда, где его ждут, что ускоряет его обработку.
Разница хорошо видна на диаграммах[2]:
| RPS | RFS |
|---|---|
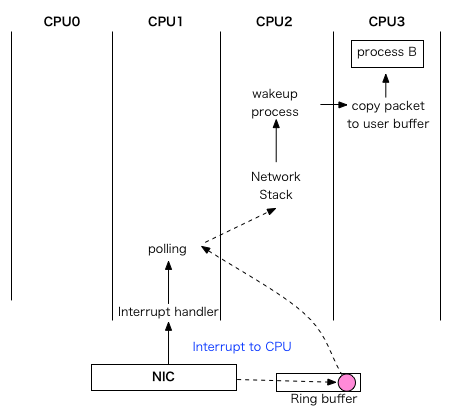 |
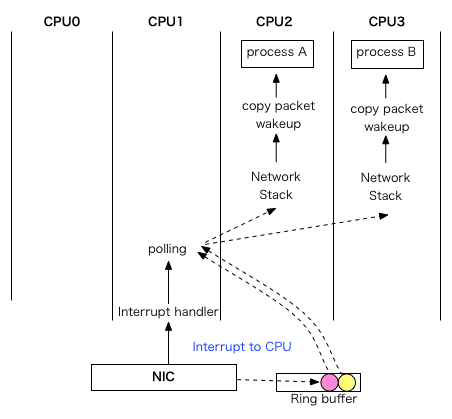 |
Accelerated RFS
Чтобы закончить разбор технологий из scaling.txt, стоит также рассказать и про Accelerated RFS. Кто и что тут ускоряет? В случае с RFS работу по распределению пакетов по нужным ядрам в зависимости от хеша пакета выполняет центральный процессор. А в случае с Accelerated RFS этим занимается сетевая карта, снимая нагрузку с процессора. Но из известных нам сетевых адаптеров эту технологию на сегодняшний день поддерживает только Mellanox.
По счастливому совпадению, часть раздачи видео работает как раз на картах этого производителя. По несчастливому совпадению, каждая попытка включить этот режим заканчивается kernel panic.
В последних версиях драйвера проблема с падениями решена, но в этом режиме пропускная способность в нашей конфигурации оказалась значительно ниже. Похоже, что драйверы или firmware карт ещё не готовы к таким нагрузкам и режимам.
Проблема 4 — большое количество broken pipe
Регулярно появление ошибок broken pipe наблюдалось в приложении ещё на OpenSuSE, но с переходом на CentOS было принято решение положить этому конец. Тогда мы ещё не знали, сколько времени это займёт, ведь “пощупать” эти ошибки очень сложно.
Broken pipe — это ошибка, которая возникает, когда приложение не может записать данные в pipe. На одном конце pipe находится приложение, на другом — файл или соединение. Если пропадёт диск, на котором находится файл, или компьютер, с которым установлено соединение, то попытка записи в pipe завершится ошибкой broken pipe. В ходе изучения дампов трафика было замечено, что клиенты не просто пропадают, а закрывают соединения в ускоренном режиме (half-duplex tcp close sequence), что само по себе не является чем-то некорректным. Так почему же некоторые наши клиенты закрывают соединения не получив все данные и даже не пытаясь нормально закрыть соединение? Откуда такое безразличие к запрошенным данным и спешка? Дальнейшее расследование происходило исключительно эмпирическим путём, т.к. поймать такие эти ошибки на стороне клиентов и понять, что у них происходит, было бы слишком трудоёмким занятием. Поэтому поиск решения занял много времени.
Наиболее вероятная причина — это «packet reordering» (http://en.wikipedia.org/wiki/Out-of-order_delivery), хотя доказательств нет. Т.к. некоторые проблемы, описанные в данной статье, решались параллельно, то оказалось, что включение RFS резко снижает количество broken pipe.
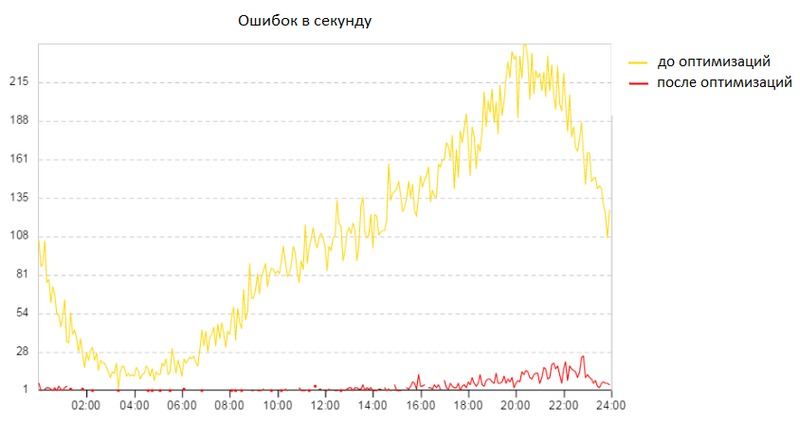
Второй фактор, который повлиял на снижение количества ошибок — это interrupt coalescing. Что это за зверь, рассказывается в следующей главе.
Проблема 5 — большое количество прерываний
Трафик бывает разный, и если фанаты Counter Strike крайне болезненно относятся к высокому latency, то для любителей торрентов (и любых других приложений, работающих с большим количеством трафика) куда важнее пропускная способность. Что касается раздачи видео, то это очень много трафика (десятки гигабит с сервера) и очень много пакетов (миллионы), а значит очень много процессорной нагрузки типа softirq. Во время тестов при пиковой нагрузке на сервер softirq мог достигать 50% от всей нагрузки на процессор.
Настройка, которая уменьшает нагрузку на CPU, — мечта любого админа. В данном случае нам помог interrupt coalescing, который настраивается через
ethtool -c/-C. При увеличении параметров interrupt coalescing прерывания генерируются реже — не на каждый пакет, а сразу на пачку.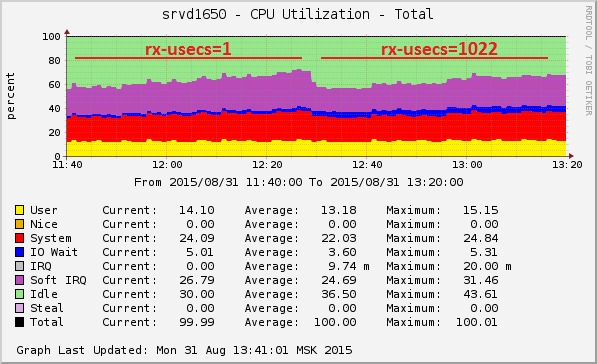
Стоит отметить, что нагрузка softirq растёт нелинейно, так что чем больше трафик, тем сильнее эффект.
Описание параметров:
- [rx|tx]-usecs — максимальное время в микросекундах между получением пакета и генерированием прерывания
- [rx|tx]-frames — количество пакетов, после получения которого генерируется прерывание
- *-irq — то же самое для обновления статуса при отключенных прерываниях
- *-[low|high] — то же самое для адаптивного режима
Итоги
В результате проделанных работ мы получили:
- дистрибутив, поддерживаемый до 2024 года [3]
- снижение количества ошибок broken pipe в 40 раз
- повышение производительности серверов (один сервер способен обработать 50 Гбит в секунду)
- опыт работы с различными новыми технологиями (а также политики CFEngine для их автоматического конфигурирования)
А всё это вместе позволит нам в будущем отдать с одного сервера ещё больше трафика.
Постскриптум
В заключение хочется сказать спасибо нашим разработчикам, которые помогали в работе и оптимизировали приложение, а также коллегам-администраторам, благодаря которым у меня было время на все эти изыскания. Самые сложные задачи дают больше всего знаний, опыта и удовлетворения. Хотя и треплют нервы.
Сноски
Комментарии (57)


baltazorbest
03.09.2015 14:36+13Одна из не многих статей за последнее время для меня, которую я прочитал на одном дыхании. Большое спасибо.

evg_krsk
03.09.2015 16:08+1Круто, но сразу же возникает вопрос: а как это вообще работало на OpenSuSE, что стало «плохо» на CentOS? Ну т.е. разве не был прописан в манифестах CFEngine аналогичный набор крутилок (которые нужно лишь перенести в манифест для CentOS)? Или у этих двух дистрибутивов насколько сильно различаются настройки ядра, что у вас это вылезло.
Или же вы просто решили заодно с миграцией и оптимизировать использование ресурсов, чиня существующие на OpenSuSE проблемы?
dmitrysamsonov
03.09.2015 16:52Спасибо.
Часть описанных проблем не проявлялась в OpenSuSE ввиду его возраста. Часть проблем и оптимизаций действительно были проведены заодно.
Что касается политик CFEngine, то процесс его внедрения у нас в компании ещё не завершён (и мы обязательно напишем подробно о том как это происходит), поэтому не все инструменты были готовы. Кроме того, переход на другой дистрибутив так же требует доработки политик.
erlyvideo
03.09.2015 16:11> дисковый кеш, который нельзя ни отключить, ни ограничить в объёме.
cgroups, не?
И второй вопрос: зачем вообще вам swap на видеостримере?dmitrysamsonov
03.09.2015 17:09+1Не нашёл такой возможности в cgroups. Расскажите поподробнее.
По поводу swap, если бы его не было, то с началом «Проблемы N2» приложения попадали бы от OOM Killer. Кроме того наличие swap даёт нам ещё одну возможность косвенным способом обнаруживать проблемы с серверами. Если в swap появились данные — это повод для расследования.erlyvideo
03.09.2015 17:10+1подробно к сожалению не отвечу.
Возможно поможет: lwn.net/Articles/516431dmitrysamsonov
03.09.2015 17:19На сколько я вижу по описанию этого патча он исправляет поведение global reclaim, который (до исправлений) при запуске для одного memcg мог освобождать память другого memcg.

catharsis
15.09.2015 15:09Во многих сценариях попадание в swap аналогично полному отказу сервиса, при этом возврат в работу из OOM может быть быстрее.
У вас похоже не совсем такой случай :)
cgroups memory.limit_in_bytes
sets the maximum amount of user memory (including file cache).
ну и такое же значение в memory.memsw.limit_in_bytes.dmitrysamsonov
15.09.2015 15:51+1С помощью cgroups грубо говоря вы порежете page cache на куски и в разные его части будут попадать страницы от разных приложений, но ядро по прежнему сможет использовать под page cache всю свободную память.

laphroaig
03.09.2015 16:49+2Спасибо большое, очень интересно. Сталкивался с подобными проблемами, но с другим профилем нагрузки и решал в основном программным путем. Может кому интересно будет:
Неравномерное распределение нагрузки по ядрам может происходить по разным причинам. На linux одним из самых эффективных решений — это фиксированный пул потоков, в каждом из котором свой цикл epoll, а слушающий сокет дублируется и может акцептиться в любом из потоков. После акцепта новый сокет продолжает обрабатываться в том же цикле потока. Все это работает очень шустро, т.к. нет оверхеда на всевозможные очереди и пр. Однако здесь есть подводный камень — по каким-то причинам, приоритет при акцепте, отдается потоку с меньшим id и в результате одни из потоков становиться более нагруженным. Если сервер работает в режиме “запрос на подключение”, то особых проблем не возникает даже на больших нагрузках, а вот если сервер работает с большим числом постоянных подключений при перезапуске будет сюрприз. Несколько сот тысяч клиентов одновременно пытается подключиться, и почти всех практически моментально заакцептит одно ядро, а у остальных ядер будет возможность подхватывать только новые подключения, в то время как первое будет перегружено. В этом случае имеет смысл сделать отдельный поток для акцептора и каким либо образом распределять сокеты по остальным потокам в зависимости от нагрузки.
Broken pipe может возникать при попытке записать в разорванное соединение. Например, в синхронном сервере (ответ на запрос формируется сразу в том же потоке) во время обработки запроса клиент закрывает соединение, т.е. к моменту вызова write клиент уже отключился, но вы не знаете об этом и получаете при записи Broken pipe. Вы конечно же узнаете о том, что сокет закрыт при следующем вызове epoll. В асинхронных серверах broken pipe, случаются реже, но также возможны. Если Broken pipe слишком много, то возможно, epoll цикл реализован не оптимально, например происходит попытка записать большой объем данных кусками в сокет без вызова epoll.
Bloof
03.09.2015 18:57+3… фиксированный пул потоков, в каждом из котором свой цикл epoll, а слушающий сокет дублируется и может акцептиться в любом из потоков.
В приложении раздачи мы используем epoll и обертку над нативными сокетами one-nio. Принимает соединения один тред-акцептор, однако читают/пишут данные уже несколько тредов-селекторов. Число селекторов равно числу ядер на сервере, причем каждый селектор привязан к своему ядру через thread affinity.
… происходит попытка записать большой объем данных кусками в сокет без вызова epoll.
Селектор неблокирующе пишет в сокет только один раз, затем снова использует epoll.
Про устройство сервера раздачи и детали приложения также планируется статья.
Godless
03.09.2015 22:21+1с нетерпением будем ждать.
ps: почему то думалось, что one-nio это для c/c++, а оказалось чуточку не так))


mrjj
03.09.2015 20:33по поводу broken pipes
Первый вариант что пришел мне в голову — вы по каким-то причинам сами не до конца корректно обрабатываете FIN-shake или отвечаете на него медленно и получаете RST по таймауту.
Второй — я не знаю что у вас на клиенте, но если там есть мобильные браузеры, то телеком провайдерам вряд ли имеет смысл держать долгие таймауты и незачем дополучать данные, RST и все, а клиенты за ними мигают часто.

smartlight
03.09.2015 20:45+6Спасибо отличная статья!
Может вы сможете или попросите ваших девопс инженеров написать статью про CFEngine.
Какую версию используете, платная или Community Version, что менеджите им, как справляетесь с его однопоточностью, начали ли писать свои костыли для того, когда cf-agent не может обновиться с мастер хоста, подготовились ли к тому что прийдется перенести /var/cfengine в память?dmitrysamsonov
04.09.2015 12:24Спасибо за отзыв.
С неразрешимыми проблемами с CFEngine мы пока что не столкнулись.
Обязательно расскажем подробно в отдельной статье.

nucleusv
04.09.2015 00:00+1Вы наверняка используете bonding на интерфейсах, вы не сравнивали производительность bonding драйвера и нового для centos 7 — teaming?

derwin
04.09.2015 06:10+4интересно было бы услышать про отказоустойчивость в проектах такого масштаба.
Что используется — свой самописный велосипед, или что то из энтерпрайз продуктов?
И мой особый интерес — защита от DDoS.
Спасибо!dmitrysamsonov
04.09.2015 19:22+1Это очень большая тема.
Постараемся раскрыть её в будущих статьях.
Если коротко, то используем и свои решения, и open source.



pavelodintsov
04.09.2015 12:15-2Чтобы не было вот таких казусов «Может содержать не более 8 000 правил. Классификатор пакетов Perfect filter просматривается/настраивается через ethtool -u/U flow-type. Возможно, это та же фильтрация, которая настраивается утилитой testpmd (см. выше).» предлагаю к прочтению это
T0R
04.09.2015 18:52+1День добрый.
Настривается фильтрация утилитой testpmd
testpmd — это не утилита, это sample application из фреймворка intel dpdk, в котором показано, как программисту работать с pmd (poll mode driver). К ядерному драйверу (например ixgbe) не имеет отношения. Для ядерных драйверов есть ethtool.
Может содержать не более 8 000 правил.
зависит от регистра PBALLOC. Максимальное значение для perfect — 8k — 2, при этом из 512 кбайт пакетного буфера на порт будет заимствовано 256кбайт. Чем это чревато — потерей пакетов в определенных ситуациях (например сильные всплески мелкопакетного трафика, при нехватке dma).
Может содержать не более 32 000 правил.
Не более 32k — 2 при максимальном PBALLOC
ATR запоминает, в какую очередь (и на каком процессоре) _ушёл_ SYN пакет и направляет приходящие пакеты этого потока через ту же очередь.
ATR — это видимо какая-то софтовая часть. Signature filter работает не так. Он просто роутит по очередям по 13-15 (в зависимости от PBALLOC) least significant bits от хеша по packet tuple. Сам fpga чипа не может следить за проходящими syn и создавать динамически фильтры.
И да, в вышей ситуации, когда у вас 16+ ядер при 4-х 10G портах, почему бы не полагаться на RSS, ведь можно балансить по 4*16 очередям.
dmitrysamsonov
04.09.2015 19:56+2Здравствуйте!
Поправлю информацию про testpmd.
Проблема с регистром PBALLOC в том, что его нельзя изменить в драйвере ixgbe 3.15.1-k из состава CentOS 7 (я писал об этом в багрепорте, который упоминается в статье). Более новых драйверов тогда ещё не было выпущено.
В любом случае, Flow director не подходит для нашей задачи.
Про ATR сам Intel пишет так:
The Intel® Ethernet Flow Director and the Application Target Routing (ATR) service found in Intel’s Ethernet controllers, is an advanced network offload technology that provides the benefits of parallel receive processing in multiprocessing environments that automatically steer incoming
network data to the same core on which its application process resides. Intel Ethernet Flow Director and ATR preserve the Traffic Flow>Core (Application) relationship. As a result, Intel Ethernet Flow Director and ATR can significantly lower latency and improve CPU usage.
Т.е. это аналог RPS+RFS.
Про RSS: У нас была вариант сократить количество очередей до 10 и он подходил для WAN, т.к. там 4 карты (при 40 ядрах), но для LAN такой вариант уже не сработал бы, т.к. там всего 2 карты и нагрузка бы легла только на 32 ядра.
Спасибо за ваш полезный комментарий.

Nastradamus
04.09.2015 20:40+2Теперь листаю rss хабра в надежде что появилась еще одна техническая статья от Одноклассников. :)
Особенно жду техническую статью про факап с даунтаймом ОК несколько лет назад (было на roem, но не для технарей).

stalkerg
08.09.2015 12:32+1А вы не смотрели/пробовали последние ядра и изменения в них (4.2)? Есть вероятность, что от Qued Spinlocks будет буст и в сетевых нагрузках.
dmitrysamsonov
09.09.2015 10:17Ещё не пробовали.
perestrelka
09.09.2015 11:47Присоединяюсь к вопросу — почему не поиспользовать хотя бы 3.18+ — в сетевой части должен быть хороший прирост от Bulk network packet transmission, который реализован в ванильных драйверах для ixgbe и в драйверах от Intel начиная с версии 4.0.3
sidorvm
09.09.2015 03:51а почему бы вам не начать использовать CDN для фото и видео?

23derevo
09.09.2015 12:32+2а почему вы думаете, что Одноклассники не используют CDN?
sidorvm
09.09.2015 12:52картинки грузятся с *.mycdn.me но если вы посмотрите IP адреса, то все они принадлежат одноклассникам. То есть CDN у них есть но свой. Все адреса расположены в москве, даже если запрос с другого конца шара сделан. То есть это не совсем CDN, а больше как вэширующие сервера.
23derevo
09.09.2015 12:59+1А почему вы думаете, что если адрес в Москве, то и сервер в Москве? В общем случае, насколько я знаю, это совсем не так.
У многих российских провайдеров «юридически» айпишники московские, а по факту — могут находиться где угодно. Особенно этот факт доставляет нашей команде внутренней статистики, когда они хотят, например, четко нарисовать на карте России какое-нибудь географическое распределение — трафик по городам, число пользователей по регионам и т.п. :)sidorvm
09.09.2015 13:20да согласен. просто я опирался не совсем на официальную базу данных. и все ип были из Москвы. то есть в России в регионах тоже есть сервера?
privatelv
09.09.2015 13:47+3С CDN точек раздается статический контент, видео, фото и музыка. Точки расположены как в регионах России, так и за рубежом. Вы совершенно верно заметили домен mycdn.me. Он используется для контента, который можно балансировать с использованием DNS и отличен от основного домена (ок.ru) в целях безопасности.
Snowbird
09.09.2015 17:24+3Дмитрий, огромное спасибо вам и вашим коллегам за информацию, потраченные силы и время, это крайне интересно. Вы, безусловно, помогли экосистеме, поделившись опытом и находками.
DimaSmirnov
Без сарказма, отличная работа.
dmitrysamsonov
Спасибо, Дмитрий. Рад, что вам понравилось.
DimaSmirnov
У нас общая тема в настоящее время R&D, было интересно, спасибо. У меня немного потяжелее — UHD, стукнись в личку, поделимся опытом)
erlyvideo
Какой у вас битрейт?
DimaSmirnov
Опа, Лапшин, привет) Ну сам посчитай, если профиль FHD это от 9 мегабит. Если UHD — От 24. Всё зависит от клиентского устройства, обычно готовятся несколько профилей потоков, для телефона, для планшета, смарттв итд