
Егор Матешук (CDO AdTech-компании Квант и преподаватель в OTUS) приглашает Data Engineer'ов принять участие в бесплатном Demo-уроке «Spark 3.0: что нового?». Узнаете, за счет чего Spark 3.0 добивается высокой производительности, а также рассмотрите другие нововведения.
Также приглашаем посмотреть запись трансляции Demo-урока «Написание эффективных пользовательских функций в Spark» и пройти вступительное тестирование по курсу «Экосистема Hadoop, Spark, Hive»!

У вас уже есть все, что вам нужно для дебаггинга запросов
Spark - самый широко используемый фреймворк для big data вычислений, способный выполнять задачи на петабайтах данных. Spark предоставляет набор веб-UI, которые можно использовать для отслеживания потребления ресурсов и состояния кластера Spark. Большинство проблем, с которыми мы сталкиваемся при выполнении задачи (job), можно отладить, перейдя в UI Spark.
spark2-shell --queue=P0 --num-executors 20
Spark context Web UI available at http://<hostname>:<port>
Spark context available as 'sc'
Spark session available as 'spark'В этой статье я попытаюсь продемонстрировать, как дебажить задачу Spark, используя только Spark UI. Я запущу несколько задач Spark и покажу, как Spark UI отражает выполнение задачи. Также я поделюсь с вами несколькими советами и хитростями.
Вот как выглядит Spark UI.

Мы начнем с вкладки SQL, которая включает в себя достаточно много информации для первоначального обзора. При использовании RDD в некоторых случаях вкладки SQL может и не быть.
А вот запрос, который запускаю в качестве примера
spark.sql("select id, count(1) from table1 group by id”).show(10, false)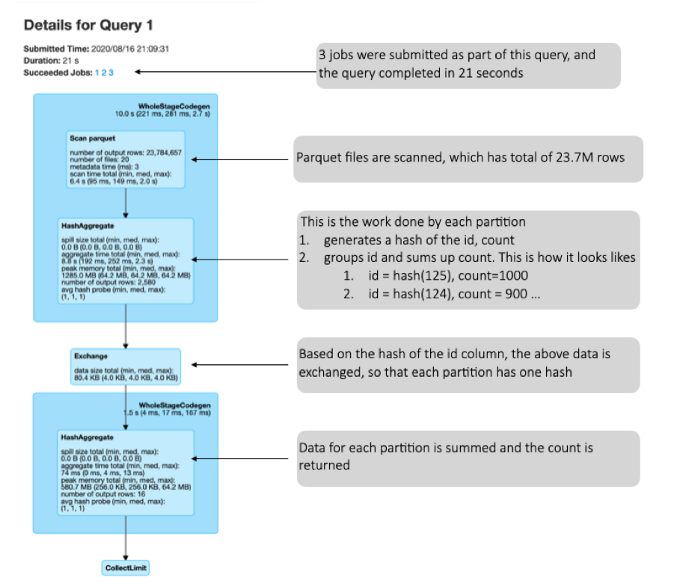
Перевод разъяснений в правой части:
<-- В рамках запроса было запущено 3 задачи, а сам запрос был выполнен за 21с.
<-- Файлы Parquet отсканированы, они содержат в сумме 23.7М строк
<-- Это работа выполненная каждой партицией
1. генерирует хеш id, count
2. группирует id и суммирует count. Вот как это выглядит
1.
id = hash(125), count=10002.
id = hash(124), count=900 …<-- Происходит обмен данных, приведенных выше, на основе хеша id колонки, чтобы в результате каждая партиция имела один хеш
<-- Данные каждой партиции суммируются и возвращается count
Теперь давайте сопоставим это с физическим планом запроса. Физический план можно найти под SQL DAG, когда вы раскрываете вкладку details. Мы должны читать план снизу вверх
== Physical Plan ==
CollectLimit 11
+- *(2) HashAggregate(keys=[id#1], functions=[count(1)], output=[id#1, count(1)#79])
+- Exchange hashpartitioning(id#1, 200)
+- *(1) HashAggregate(keys=[id#1], functions=[partial_count(1)], output=[id#1, count#83L])
+- *(1) FileScan parquet [id#1] Batched: true, Format: Parquet, Location: InMemoryFileIndex[hdfs://<node>:<port><location>, PartitionFilters: [], PushedFilters: [], ReadSchema: struct<id:string>Вот как следует читать план:
Сканирование файла parquet. Обратите внимание на PushedFilters. Я продемонстрирую, что это означает позже
Создание HashAggregate с ключами. Обратите внимание на partial_count. Это означает, что агрегированный count является частичным, поскольку агрегирование было выполнено в каждой отдельной задаче и не было смешанно для получения полного набора значений.
Теперь сгенерированные данные агрегируются на основе ключа, в данном случае id.
Теперь вычисляется вообще весь count.
Полученный результат
Теперь, когда с этим мы разобрались, давайте посмотрим на данные PuedFilters. Spark оптимизирован для предикатов, и любые применяемые фильтры пушатся к источнику. Чтобы продемонстрировать это, давайте рассмотрим другую версию этого запроса
spark.sql("select id, count(1) from table1 where status = 'false' group by id”).show(10, false)А это его план
+- *(2) HashAggregate(keys=[id#1], functions=[count(1)], output=[id#1, count(1)#224])
+- Exchange hashpartitioning(id#1, 200)
+- *(1) HashAggregate(keys=[id#1], functions=[partial_count(1)], output=[id#1, count#228L])
+- *(1) Project [id#1]
+- *(1) Filter (isnotnull(status#3) && (status#3 = false))
+- *(1) FileScan parquet [id#1,status#3] Batched: true, Format: Parquet, Location: InMemoryFileIndex[hdfs://mr25p01if-ingx03010101.mr.if.apple.com:50001/home/hadoop/work/news/20200..., PartitionFilters: [], PushedFilters: [IsNotNull(status), EqualTo(status,false)], ReadSchema: struct<id:string,status:string>Обратите внимание на изменения по сравнению с предыдущим планом.
Мы видим в PushedFilters уже кое-что другое — проверка на null и проверка на равенство. Столбец, к которому мы применяем фильтр пушится к источнику, т.е. при чтении данных эти строки игнорируются. Результат этого переносится на следующие этапы.
Можем ли мы, применяя фильтры, уменьшить общее количество прочитанных данных (или файлов)?
Да мы можем. В обоих приведенных выше примерах общее количество прочитанных данных составляет ~ 23,8M. Чтобы уменьшить его, мы можем использовать магию файлов parquet. В Parquet есть группа строк, в которой есть статистика, которую можно использовать для игнорирования нескольких групп/файлов строк. Это приводит к тому, что эти файлы вообще не читаются. Вы можете прочитать о том, как это сделать, в другой моей статье на medium Insights Into Parquet Storage.
Вкладка Executor
Эта вкладка дает нам представление о количестве активных в настоящее время исполнителей в вашей сессии spark.
spark2-shell — queue=P0 — driver-memory 20g — executor-memory 20g — num-executors 40
Я запросил 40 исполнителей для сессии, однако при запуске вы можете увидеть, что он предоставил мне всего 10 активных исполнителей. Это может быть связано с тем, что не работают хосты или Spark не нуждается в таком большом количестве исполнителей. Это также может вызвать задержку в планировании задач, поскольку у вас всего 10 исполнителей, а вам нужно 40, что скажется на параллелизме.
Вкладка Environment
Вкладка Environment содержит подробную информацию обо всех параметрах конфигурации, которые в данный момент использует сессия spark.

Посмотрите, как здесь отражены параметры, отраженные мной ранее. Это полезно хотя бы просто для того, чтобы убедиться, что предоставленная вами конфигурация принята.
Вкладка Storage
Здесь отображается информация об одной из наиболее обсуждаемых функций Spark - кэшировании. В Интернете доступно множество статей с разными мнениями относительно того, стоит ли кэшировать или нет. К счастью, эта статья не о том, когда стоит кэшировать и т. д. Он больше о том, что происходит, когда мы кэшируем.
Но перед этим давайте вернемся немного назад и потратим несколько минут на некоторые основы кэширования.
Есть два способа кэширования Dataframe:
> df.persist
Для кэширования набора данных требуется несколько свойств.
> df.cache
Под капотом это вызывает метод «persist». Обратимся к исходному коду
def cache(): this.type = persist()
/**
* Persist this Dataset with the given storage level.
* @param newLevel One of: `MEMORY_ONLY`, `MEMORY_AND_DISK`, `MEMORY_ONLY_SER`,`MEMORY_AND_DISK_SER`, `DISK_ONLY`, `MEMORY_ONLY_2`,`MEMORY_AND_DISK_2`, etc.
* @group basic
* @since 1.6.0
*/DISK_ONLY: хранить (persist) данные на диске только в сериализованном формате.
MEMORY_ONLY: [хранить данные в памяти только в десериализованном формате.
MEMORY_AND_DISK: хранить данные в памяти, а если памяти недостаточно, вытесненные блоки будут сохранены на диске.
MEMORY_ONLY_SER: этот уровень Spark хранит RDD как сериализованный объект Java (однобайтовый массив на партицию). Это более компактно по сравнению с десериализованными объектами. Но это увеличивает накладные расходы на CPU.
MEMORY_AND_DISK_SER: аналогично MEMORY_ONLY_SER, но с записью на диск, когда данные не помещаются в памяти.
Давайте воспользуемся df.cache в нашем примере и посмотрим, что произойдет a.cache() -> На вкладке Storage ничего не видно. Как вы можете догадаться, это из-за ленивого вычисления
Давайте воспользуемся df.cache в нашем примере и посмотрим, что произойдет
a.cache()
—> На вкладке Storage ничего не видно. Как вы можете догадаться, это из-за ленивого вычисления
a.groupBy(“id”).count().show(10,false)
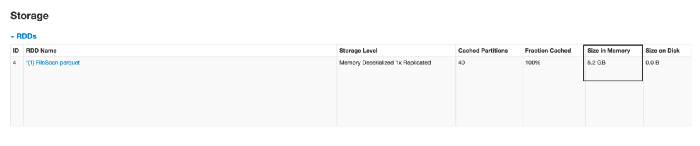
Мы видим какой-то кэш данных. Размер в памяти составляет 5,2 ГБ, а размер моего файла - 2 ГБ… хммм… что здесь произошло
hadoop dfs -dus <dirName>
2,134,751,429 6,404,254,287 <dirName>Это потому, что данные в памяти десериализованы и несжаты. Это результирует в большем объеме памяти по сравнению с диском.
Так что, когда вы хотите принимаете решение о том, кэшировать или нет, помните об этом.
Я видел несколько толковых статей о том, следует ли кэшировать или нет. Ознакомиться с ними - хорошая идея
Далее мы рассмотрим вкладки Jobs и Stages, причины множества проблем можно отдебажить с помощью этих вкладок.
spark.sql("select is_new_user,count(1) from table1 group by is_new_user").show(10,false)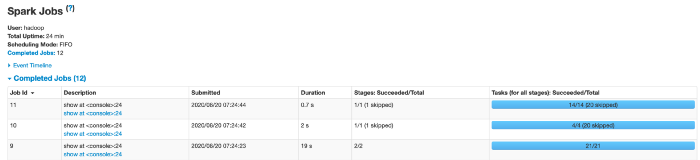
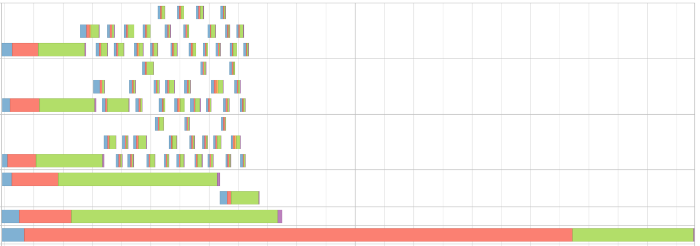
Я вижу, что для указанного выше запроса запускаются 3 задачи. Но 2 из них пропущены. Обычно это означает, что данные были извлечены из кэша и не было необходимости повторно выполнять данный этап. Кроме того, Spark выполняет множество фиктивных задач для оценки данных. Пропуск задач мог быть связан и с этим.
Давайте же глубоко погрузимся в задачу, которая не была пропущена. Это визуализация DAG для задачи

Мы ясно видим, что эта задача состоит из двух этапов, разделенных операцией перемешивания/обмена. Stages означают, что данные были записаны на диск для использования в следующем процессе.
Давайте углубимся во вкладку stages.
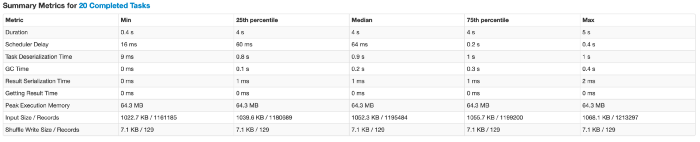
Первое, что всегда нужно проверять, - это сводные метрики для задач. Вы можете нажать «show additional metrics» для получения дополнительных фактов. Это покажет множество необходимых параметров по минимуму, медиане и максимуму. В идеальном мире минимальное значение должно быть близко к максимальному.
Вот несколько моментов, которые следует отметить:
> Продолжительность (duration): В нашем примере минимальная и максимальная продолжительность составляет 0,4 и 4 секунды соответственно. Это может быть связано с несколькими причинами, и мы постараемся отдебажить их в пунктах ниже.
> Время десериализации задачи (Task deserialization time):
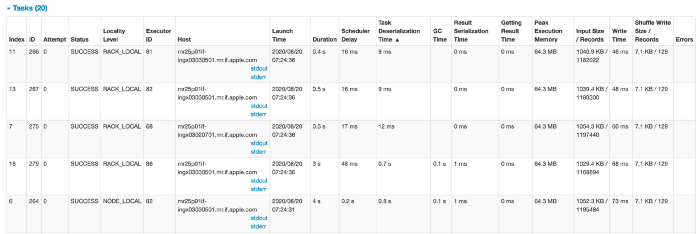
В нашем примере в рамках десериализации задачи некоторое время тратится и на другие задачи. Одной из основных причин было выполнение процессов сборки мусора в исполнителях. У меня выполнялись другие процессы, в которых были кэшированы некоторые данные, что приводило к сборке мусора. Процессам сборки мусора предоставляется наивысший приоритет, и они останавливают все запущенные процессы в угоду обслуживания процесса сборки мусора. Если вы видите, что ваш процесс не потребляет много памяти, первым шагом для решения такой проблемы может быть разговор с администратором/OPS.
> Задержка планировщика (Scheduler delay): максимальная задержка планировщика составляет 0,4 секунды. Это означает, что одна из задач должна была ждать отправки еще 0,4 секунды. Большое это значение или маленькое, зависит от вашего конкретного юзкейса.
> Размер ввода очень сильно распределен. Это очень хорошо, поскольку все задачи читают одинаковый объем данных. Это одна из самых важных вещей при поиске неверного/искаженного запроса. Это можно увидеть в столбце «“shuffle read”» в разделе «Summary metrics for tasks». Самая простая логика для решения таких проблем - это добавление соли к группе, которая может распараллеливать данные, а затем, наконец, агрегирование данных без соли. Этот принцип может применяться во многих формах для решения проблемы асимметрии данных.
Еще одна вещь, на которую стоит обратить внимание, - это уровень локальности.
* PROCESSLOCAL > Эта задача будет запущена в том же процессе, что и исходные данные
* NODELOCAL > Эта задача будет запущена на том же компьютере, что и исходные данные
* RACKLOCAL > Эта задача будет запущена в том же блоке, что и исходные данные
* NOPREF (Отображается как ANY) > Эта задача не может быть запущена в том же процессе, что и исходные данные, или это не имеет значения.
Предположим, мы потребляем данные из узла Cassandra в кластере Spark, состоящем из трех узлов. Cassandra работает на машине X узлов Spark X, Y и Z. Для узла X все данные будут помечены как NODELOCAL. Это означает, что после того, как каждое ядро ??на X будет занято, мы останемся с задачами, предпочтительное расположение которых - X, но у нас есть пространство для выполнения только на Y и Z. У Spark есть только два варианта: дождаться, пока ядра станут доступны на X, или понизить уровень локальности задачи и попытаться найти место для них и принять любые штрафы за нелокальное выполнение.
Параметр spark.locality.wait описывает, как долго ждать перед понижением уровня задач, которые потенциально могут выполняться с более высокого уровня локальности до более низкого уровня. Этот параметр, по сути, является нашей оценкой того, сколько стоит ожидание локального места. Значение по умолчанию - 3 секунды, что означает, что в нашем примере с Cassandra, как только наш совместно расположенный узел X будет забит задачами, другие наши машины Y и Z будут простаивать в течение 3 секунд, прежде чем задачи, которые могли быть NODELOCAL, будут понижены до ANY* и запущены.
Вот пример кода для этого.
Я надеюсь, что эта статья послужит вам в качестве руководства по дебаггингу на Spark UI с целью устранения проблем с производительностью Spark. В Spark 3 есть много дополнительных функций, которые тоже стоит посмотреть.
Также хорошая идея — почитать документацию Spark UI.
Вы также можете связаться со мной в Linkedin.
Хотите узнать, как Apache Druid индексирует данные для сверхбыстрых запросов? Узнайте об этом здесь:
Insights into Indexing using Bitmap Index
Интересно развиваться в данном направлении? Участвуйте в трансляции мастер-класса «Spark 3.0: что нового?» и оцените программу курса «Экосистема Hadoop, Spark, Hive»!
sshikov
Вполне годный перевод в целом, но неужели переводчик не в курсе, что такое rack?