

Публикую продолжение сборника вопросов-ответов с собеседований на Backend-Java-разработчика. В первой части мы прошлись по Java и Spring. А в этой поговрим о Hibernate, базах данных, паттернах и практиках разработки, об одной популярной библиотеке, поддержке и сопровождении наших приложений, а также посмотрим на альтернативные шпаргалки и подведём итоги.
GitHub-репозиторий с полной шпаргалкой тут, а Хабр всё ещё торт.
Вопросы
Hibernate
3 уровня кеширования:
- Кеш первого уровня (First-level cache). По умолчанию включен.
- Кеш второго уровня (Second-level cache). По умолчанию отключен.
- Кеш запросов (Query cache). По умолчанию отключен.
Подробнее:
- Статья на Хабре
- Документация и на Хабре есть перевод
- Статья на Baeldung
- Статьи с практическими примерами о First Level Cache и Second Level Cache
Углубиться в Hibernate нам всегда поможет Vlad Mihalcea:
- Конечно же в его книге High-Performance Java Persistence: Часть 2, глава 16 — Caching
- How does Hibernate Query Cache work
- How does Hibernate Collection Cache work
- How does Hibernate store second-level cache entries
- How does Hibernate NONSTRICT_READ_WRITE CacheConcurrencyStrategy work
- How does Hibernate TRANSACTIONAL CacheConcurrencyStrategy work
- How does Hibernate READ_ONLY CacheConcurrencyStrategy work
- How does Hibernate READ_WRITE CacheConcurrencyStrategy work
- Eager Loading — стратегия загрузки, при которой подгрузка связанных сущностей происходит сразу. Для применения необходимо в аннотацию отношения (
@OneToOne,@ManyToOne,@OneToMany,@ManyToMany) передатьfetch = FetchType.EAGER. Используется по умолчанию для отношений@OneToOneи@ManyToOne. - Lazy Loading — стратегия загрузки, при которой подгрузка связанных сущностей откладывается как можно дольше. Чтобы задать такое поведение, нужно в аннотацию отношения (
@OneToOne,@ManyToOne,@OneToMany,@ManyToMany) передатьfetch = FetchType.LAZY. Используется по умолчанию для отношений@OneToMany,@ManyToMany. До момента загрузки используется proxy-объект, вместо реального. Если обратиться к такому LAZY-полю после закрытия сессии Hibernate, то получим LazyInitializationException.
Вопрос также связан с проблемой "N+1" и может плавно перетечь в её обсуждение.
Почитать подробнее и с примерами можно в блоге Vlad Mihalcea: раз, два и про LazyInitializationException три.
Проблема N+1 может возникнуть не только при использовании Hibernate, но и других библиотек и фреймворков для доступа к данным.
В общем случае говорят о проблеме N+1 запроса, когда фреймворк выполняет N дополнительных запросов выборки данных, когда можно было обойтись всего одним. Соответственно от размера N зависит влияние проблемы на время ответа нашего приложения. Эту ситуацию нельзя обнаружить с помощью slow query log, ибо сами по себе запросы могут выполняться быстро, но их количество окажется большим или даже огромным.
На такое можно нарваться даже при использовании plain sql (jdbc, JOOQ), когда у нас одна сущность (и соответственно таблица) связана с другой. И вот мы подгрузили одним запросом просто список из первых, а потом пошли и в цикле для каждой подгрузили связанную по одному запросу. "Да как вы это допустили!?". Да просто по запарке кто-то в цикле начал вызывать метод, у которого в глубине где-то делается запрос и привет. Как исправить? Использовать JOIN со связанной таблицей при чтении списка. Тогда понадобиться лишь один запрос.
Теперь к Hibernate. Если на странице документации поискать "N+1", то можно обнаружить несколько упоминаний данной проблемы. Тут опишу самые явные и распространённые.
Например, возьмём стратегию выборки FetchType.EAGER. Она склонна к порождению N+1. А в отношении @ManyToOne по умолчанию используется именно она. Забыли в своём JPQL запросе заиспользовать JOIN FETCH и привет. А если нам и не нужны были связанные сущности, то тогда стоит задать стратегию FetchType.LAZY.
Если уж упомянули FetchType.LAZY, то сразу стоит сказать, что одно её наличие не гарантирует отсутствие проблемы N+1. При выборке списка сущностей, связанные автоматически не подгрузились. А мы потом пошли в цикле по загруженному списку и стали обращаться к полям связанной сущности — и снова здравствуйте. Всё тот же JOIN FETCH нас спасёт и в этой ситуации.
Но JOIN FETCH во многих случаях нас может привести к декартовому произведению, и тогда будет совсем bonjour. Для отношения @OneToMany это можно решить с помощью FetchMode.SUBSELECT — будет 2 запроса, но во втором запросе на получение списка связанных сущностей в условии выборки будет подзапрос на получение идентификаторов родительских сущностей. Т.е. запрос практически повторяется и он может быть тяжеловесным.
Есть вариант лучше — вычитывать связанные сущности пачками. Мы можем добавить аннотацию @BatchSize и указать размер подгружаемой пачки записей в одном запросе.
Ещё варианты:
Чтобы обнаружить проблему N+1, нужно писать тесты с использованием библиотеки db-util от Vlad Mihalcea. Подробнее можно прочитать у него же в блоге.
А вот JOOQ умеет обнаруживать N+1 автоматически, послушать об этом можно в 17-м эпизоде (01:16:36) подкаста Паша+Слава. Подробнее в документации JOOQ.
Углубиться в проблему можно:
- В блоге Vlad Mihalcea: раз и два
- На хабре упоминалась в статье Hibernate — о чем молчат туториалы
- На DOU про стратегии загрузки коллекций в JPA и Hibernate
- В видео формате в докладе Николая Алименкова на JPoint "Сделаем Hibernate снова быстрым"
На всякий случай: составной ключ — первичный ключ, состоящий из двух и более атрибутов. Вообще про ключи есть большая статья на Хабре с ценными комментариями.
Чтобы описать составной ключ при использовании Hibernate, нам необходимо создать под этот ключ отдельный класс с необходимыми полями и добавить ему аннотацию @Embeddable. Кроме того, он должен быть Serializable и иметь реализацию equals и hashcode.
В самой же сущности, для которой мы описываем составной ключ, добавляем поле только что созданного класса ключа и вешаем на него аннотацию @EmbeddedId.
Посмотреть примеры и углубиться в тему можно в статье Vlad Mihalcea или в документации Hibernate.
Есть 4 способа отобразить наследование на БД с помощью JPA (Hibernate):
- MappedSuperclass — поля родителя содержатся в каждой таблице для каждого дочернего класса. Базовый класс отдельной таблицы не имеет. На базовый класс навешиваем @MappedSuperClass, а вот на дочерние
@Entity. Если в таблице потомка поле родителя называется не так, как указано в родительском классе, то его нужно смаппить с помощью аннотации @AttributeOverride в классе этого потомка. Родитель не может участвовать в ассоциации. При полиморфных запросах у нас будут отдельные запросы для каждой таблицы. - Single table — вся иерархия классов в одной таблице. Чтобы различать классы, необходимо добавить колонку-дискриминатор. В данной стратегии на родительский
@Entity-класс навешивается@Inheritance(strategy = InheritanceType.SINGLE_TABLE)и@DiscriminatorColumn(name = "YOUR_DISCRIMINATOR_COLUMN_NAME")(по умолчанию имя колонкиDTYPEи типVARCHAR). В каждом подклассе указываем@DiscriminatorValue("ThisChildName")со значением, которое будет храниться в колонке-дискриминаторе для данного класса. Если нет возможности добавить колонку, то можно использовать аннотацию @DiscriminatorFormula, в которой указать выражениеCASE...WHEN— это не по JPA, фишка Hibernate. Денормализация. Простые запросы к одной таблице. Возможное нарушение целостности — столбцы подклассов могут содержатьNULL. - Joined table — отдельные таблицы для всех классов иерархии, включая родителя. В каждой таблице только свои поля, а в дочерних добавляется внешний (он же первичный) ключ для связи с родительской таблицей. В
@Entity-класс родителя добавляем@Inheritance(strategy = InheritanceType.JOINED). Для полиморфных запросов используютсяJOIN, а также выражениеCASE...WHEN, вычисляющее значение поля_clazz, которое заполняется литералами (0 (родитель), 1, 2 и т.д.) и помогает Hibernate определить какого класса будет экземпляр. - Table per class — также как и в
MappedSuperclass, имеем отдельные таблицы для каждого подкласса. Базовый класс отдельной таблицы не имеет. По спецификации JPA 2.2 (раздел 2.12) данная стратегия является опциональной, но в Hibernate реализована, поэтому продолжим. В данном случае на базовый класс мы навешиваем@Entityи@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS). Поле первичного ключа (@Id) обязательно для родительского класса. Также аннотация@AttributeOverrideв этой стратегии не работает — называйте родительские поля в таблицах сразу единообразно. Полиморфный запрос будет использоватьUNIONдля объединения таблиц. Чтобы различить при создании экземпляров подклассы, Hibernate добавляет поле_clazzв запросы, содержащие литералы (1, 2 и т.д.). А одинаковый набор столбцов для объединения добирается какNULL AS some_field. Родитель может участвовать в ассоциации с другими сущностями.
Почитать ещё по теме с примерами можно:
- На Хабре: раз, два
- В блоге Vlad Mahalcea: Влад демонстрирует лучшую стратегию и рассказывает про MappedSuperclass
Кроме того, можно заглянуть в JavaDoc с аннотациями:
Или почитать спецификацию JPA 2.2. Ещё есть книжка с толкованием данного pdf.
Базы данных
Есть исчерпывающий ответ на этот вопрос в документации к Postgresql. Вот его перевод с сайта Postgres Pro:
Основное отличие WHERE от HAVING заключается в том, что WHERE сначала выбирает строки, а затем группирует их и вычисляет агрегатные функции (таким образом, она отбирает строки для вычисления агрегатов), тогда как HAVING отбирает строки групп после группировки и вычисления агрегатных функций. Как следствие, предложение WHERE не должно содержать агрегатных функций; не имеет смысла использовать агрегатные функции для определения строк для вычисления агрегатных функций. Предложение HAVING, напротив, всегда содержит агрегатные функции. (Строго говоря, вы можете написать предложение HAVING, не используя агрегаты, но это редко бывает полезно. То же самое условие может работать более эффективно на стадии WHERE.)
Но вас также может заинтересовать:
- Как работает реляционная БД на Хабре
- How does a relational database work
- How does a relational database execute SQL statements and prepared statements
- How Database Internally Works
- Курс по БД от Ильи Тетерина или курс от Вадима Цесько
- Let's Build a Simple Database
- Database internals
- A — Атомарность (Atomicity). Гарантирует, что никакая транзакция не будет зафиксирована в системе частично.
- C — Согласованность (Consistency). Каждая успешная транзакция фиксирует только допустимые результаты.
- I — Изолированность (Isolation). Во время выполнения транзакции параллельные транзакции не должны оказывать влияния на её результат.
- D — Стойкость (Durability). Подтверждённые изменения не будут отменены (например, из-за сбоя).
Краткий конспект статьи из Википедии:
Read uncommitted(чтение незафиксированных данных). Он гарантирует только отсутствие потерянных обновлений (ситуация, когда при одновременном изменении одного блока данных разными транзакциями одно из изменений теряется).Read committed(чтение фиксированных данных). Именно он чаще всего является уровнем по умолчанию. Обеспечивает защиту от «грязного» чтения (чтение данных, добавленных или изменённых транзакцией, которая впоследствии откатится).Repeatable read(повторяемость чтения). Решает проблему неповторяющегося чтения (ситуация, когда при повторном чтении в рамках одной транзакции ранее прочитанные данные оказываются изменёнными).Serializable(упорядочиваемость). Транзакции полностью изолируются друг от друга, каждая выполняется так, как будто параллельных транзакций не существует — защищает от фантомного чтения (ситуация, когда при повторном чтении в рамках одной транзакции одна и та же выборка дает разные множества строк).
На Хабре есть несколько статей по теме на любой вкус:
- Для самых маленьких
- Для MSSQL: раз, два, три
- Для PostgreSQL. Тут вообще стоит упомянуть для любителей углубиться в тему статьи из блога Postgres Professional, и в частности цикл статей egorov по внутреннему устройству PostgreSQL (например, раз, два и т.д.). А также на сайте Postgres Professional есть документация на русском языке и страница по данному вопросу.
- Для MySQL: раз, два
- Транзакции и механизмы их контроля
Индекс БД — это структура данных, которая повышает скорость операций поиска данных в таблице БД за счет дополнительных операций записи и хранения для поддержания структуры данных индекса. Индексы используются для быстрого поиска данных без необходимости поиска каждой строки в таблице базы данных каждый раз при обращении к таблице БД. Ключом индекса выступает значение индексируемого столбца/столбцов. Некоторые БД позволяют строить индексы по выражениям.
В основе индексов чаще всего лежат следующие структуры данных:
- Семейство B-Tree
- HASH-таблицы
- Bitmap
- Фильтр Блума
- Spatial grid
- Quadtree
- R-Tree
- и другие.
Классификацию индексов можно разделить по различным критериям. Следует уточнить или предложить интервьюверу какой именно критерий имеется в виду.
Например, по порядку сортировки:
- Упорядоченные — индексы, в которых записи упорядочены по возрастанию или убыванию. Реализуются на B-деревьях.
- Неупорядоченные — индексы, в которых записи неупорядоченны. Реализуются на хешах.
Или по воздействию на источник данных: - Некластерные — такие индексы организуют ссылки на соответствующие строки и значения. Ссылка содержит информацию об ID файла, в котором хранится строка; ID страницы соответствующих данных; номер искомой строки на соответствующей странице; содержимое столбца. В таблице БД может быть несколько некластерных индексов.
- Кластерные — такие индексы представляют собой древовидную структуру данных, при которой значения индекса хранятся вместе с соответствующими им данными. Физическое расположение данных перестраивается в соответствии с порядком индекса, поэтому может быть только один такой индекс на таблицу БД.
Подробнее:
- Обзор типов индексов Oracle, MySQL, PostgreSQL, MS SQL на Хабре
- Великолепная серия статей от Егора Рогова про индексы в PostgreSQL: часть 1, часть 2, часть 3, часть 4, часть 5, часть 6, часть 7, часть 8, часть 9, часть 10
- Кластерные и «обычные» индексы MySQL (InnoDB) на Хабре
- «Под капотом» индексов Postgres на Хабре
- Типы индексов, виды индексов, или какие вообще бывают индексы?
- Индекс базы данных: типы индексов
- Индекс базы данных: методы индексирования, приложения и ограничения
- Индекс базы данных
- Database Indexes Explained
- Bitmap-индекс или B*tree-индекс: какой и когда применять?
- Индексы в MySQL
- Как работает реляционная БД на Хабре
- Здоровье индексов в PostgreSQL глазами Java-разработчика на Хабре
- 14 вопросов об индексах в SQL Server, которые вы стеснялись задать на Хабре
- Вопросы про индексы, которые вам не надо будет задавать на Хабре
- Используем все возможности индексов в PostgreSQL
- Anatomy of an SQL Index
- SQL Indexing and Tuning e-Book
- Deep dive into Hash indexes for In-Memory OLTP tables
- Indexing based on Hashing
- SQL Server Indexes Interview Questions and Answers
- Top 25 SQL interview questions and answers about indexes
- An in-depth look at Database Indexin
Блокировка (lock) в СУБД — отметка о захвате объекта транзакцией в ограниченный или исключительный доступ с целью предотвращения коллизий и поддержания целостности данных.
Пессимистическая блокировка — накладывается перед предполагаемой модификацией данных на все строки, которые такая модификация предположительно затрагивает. Во время действия такой блокировки исключена модификация данных из сторонних сессий, данные из блокированных строк доступны согласно уровню изолированности транзакции. По завершению предполагаемой модификации гарантируется непротиворечивая запись результатов. Недостатком является то, что записи могут быть заблокированы на очень долгое время, тем самым замедляя общую реакцию системы.
Пессимистическая блокировка может быть двух типов:
- shared (read) — блокирует писателей, но позволяет читателям продолжить работу. Иными словами, разрешает другим транзакциям захватывать блокировку на чтение, но запрещает блокировку на запись.
- exclusive (write) — блокирует и писателей, и читателей. Делает все операции записи последовательными. Иными словами, запрещает другим транзакциям захватывать блокировки на чтение и на запись.
Оптимистическая блокировка — не ограничивает модификацию обрабатываемых данных сторонними сессиями, однако перед началом предполагаемой модификации запрашивает значение некоторого выделенного атрибута каждой из строк данных (обычно используется наименование VERSION и целочисленный тип с начальным значением 0). Перед записью модификаций в базу данных перепроверяется значение выделенного атрибута, и если оно изменилось, то транзакция откатывается или применяются различные схемы разрешения коллизий. Если значение выделенного атрибута не изменилось — производится фиксация модификаций с одновременным изменением значения выделенного атрибута (например, инкрементом) для сигнализации другим сессиям, что данные изменились.
Основное отличие в том, что оптимистическая блокировка приводит к накладным расходам только в случае конфликта, в то время как пессимистическая блокировка уменьшает накладные расходы на конфликт. Поэтому оптимистическая блокировка лучше всего подходит в случае, когда большинство транзакций не конфликтуют.
Много статей про блокировки с кодом и картинками можно прочитать в блоге Vlad Mihalcea:
- A beginner’s guide to Java Persistence locking
- A beginner’s guide to database locking and the lost update phenomena
- How do LockModeType.PESSIMISTIC_READ and LockModeType.PESSIMISTIC_WRITE work in JPA and Hibernate
- How does LockModeType.PESSIMISTIC_FORCE_INCREMENT work in JPA and Hibernate
- How does LockModeType.OPTIMISTIC work in JPA and Hibernate
- How does LockModeType.OPTIMISTIC_FORCE_INCREMENT work in JPA and Hibernate
- How to prevent OptimisticLockException with Hibernate versionless optimistic locking
- How does database pessimistic locking interact with INSERT, UPDATE, and DELETE SQL statements
- How does MVCC (Multi-Version Concurrency Control) work
- How does the 2PL (Two-Phase Locking) algorithm work
- How to prevent lost updates in long conversations
Подробнее на Хабре:
- Конкурентный доступ к реляционным базам данных
- Базы данных. Конфликты параллельного доступа
- Замечательная аннотация Version в JPA
- Документация разработчика Hibernate – Глава V. Блокировки
- Блокировки в PostgreSQL: 1. Блокировки отношений
- Блокировки в PostgreSQL: 2. Блокировки строк
- Блокировки в PostgreSQL: 3. Блокировки других объектов
- Блокировки в PostgreSQL: 4. Блокировки в памяти
Подробнее в других источниках:
- Pessimistic Locking in JPA
- Optimistic Locking in JPA
- Enabling Transaction Locks in Spring Data JPA
- Deadlock
- Enum LockModeType
- Явные блокировки в Postgresql
- PostgreSQL Concurrency with MVCC
- Locking в документации Hibernate
- Optimistic locking в документации JOOQ
- Optimistically Locking Your Spring Boot Web Services
- Optimistic and pessimistic locking with SQL
Принципы, паттерны, практики и подходы разработки ПО
Обычно просто просят расшифровать, что каждая буква означает с минимальным пояснением. Никто из моих интервьюеров не стал размусоливать или обсуждать. Один раз спросили, зачем оно вообще надо. Но, я думаю, чем больше сеньорности в вакансии, тем глубже и интереснее дискуссия может возникнуть.
- S — Принцип единственной ответственности (The Single Responsibility Principle). Каждый класс должен иметь одну и только одну причину для изменений.
- O — Принцип открытости/закрытости (The Open Closed Principle). Сущности должны быть открыты для расширения, но закрыты для модификации.
- L — Принцип подстановки Барбары Лисков (The Liskov Substitution Principle). Объекты должны быть заменяемыми на экземпляры их подтипов без изменения правильности выполнения программы. Наследующий класс должен дополнять, а не изменять базовый.
- I — Принцип разделения интерфейса (The Interface Segregation Principle). Много специальных интерфейсов лучше, чем один универсальный.
- D — Принцип инверсии зависимостей (The Dependency Inversion Principle). Зависеть нужно от абстракций, а не от реализаций.
Первоисточником, сформулировавшим данные принципы, является дядюшка "Свет наш чистый код" Боб Мартин, а акроним придумал один из его читателей. Хотите погрузиться глубже? Тогда читайте часть 3 его книги "Чистая архитектура". Книжка годная, читается легко, не пожалеете. Однако пропускайте всё через свой опыт и оценивайте критически, мало ли что :)
Сама по себе тема богатая и холиворная, ибо многие начинают трактовать эти принципы по-своему. На этой почве может случиться недопонимание с собеседующим, будьте аккуратны и конструктивны. Достаточно поискать статьи на Хабре по SOLID или каким-нибудь принципам в отдельности и заглянуть в комментарии. Кому-то SOLID вообще не по душе.
Также, могу посоветовать, самостоятельно разобрать каждый принцип на практическом примере, ибо за это тоже могут спросить. Или заглянуть на Baeldung.
Обычно советуют и в вакансиях пишут про книжку GoF. Но, на мой взгляд, сейчас есть вариант даже лучше — refactoring.guru. Там и сравнение, и на родной мове (русский, украинский, английский, китайский), и примеры на вашем любимом ЯП, прекрасные иллюстрации и диаграммы. Там также можно купить книжку по паттернам. Автору большой-большой респект.
Coupling (Зацепление) — степень зависимости между программными компонентами. Должна быть низкой.
Cohesion (Связность) — степень сфокусированности методов класса. Должна быть высокой.
Подробнее почитать и посмотреть картинки можно тут на английском или тут на русском.
Тема периодически затрагивается на Хабре в контексте построения хорошей архитектуры и написания качественного кода. Как и всегда, особую ценность составляют комментарии:
- Создание архитектуры программы или как проектировать табуретку
- Принцип единственной ответственности: глубокое погружение. Есть раздел, где тема разобрана с примерами кода.
- Утрата слабой связанности
Также coupling и cohesion часто упоминаются или ведут к обсуждению GRASP. Об этом можно почитать на Хабре: раз и два.
Куб масштабирования (scale cube, из книги The Art of Scalability) является наглядным изображением трёх ортогональных способов увеличения производительности приложения: sharding, mirrorring и microservices.
- Sharding (data partioning) — разбиение и размещение однотипных данных по разным узлам.
- Mirroring (horizontal duplication) — дублирование или клонирование данных для уменьшения времени отклика.
- Microservices — архитекутрный подход, при котором функциональность системы разбивается на отдельные сервисы по бизнес-задачам.
Наглядно:
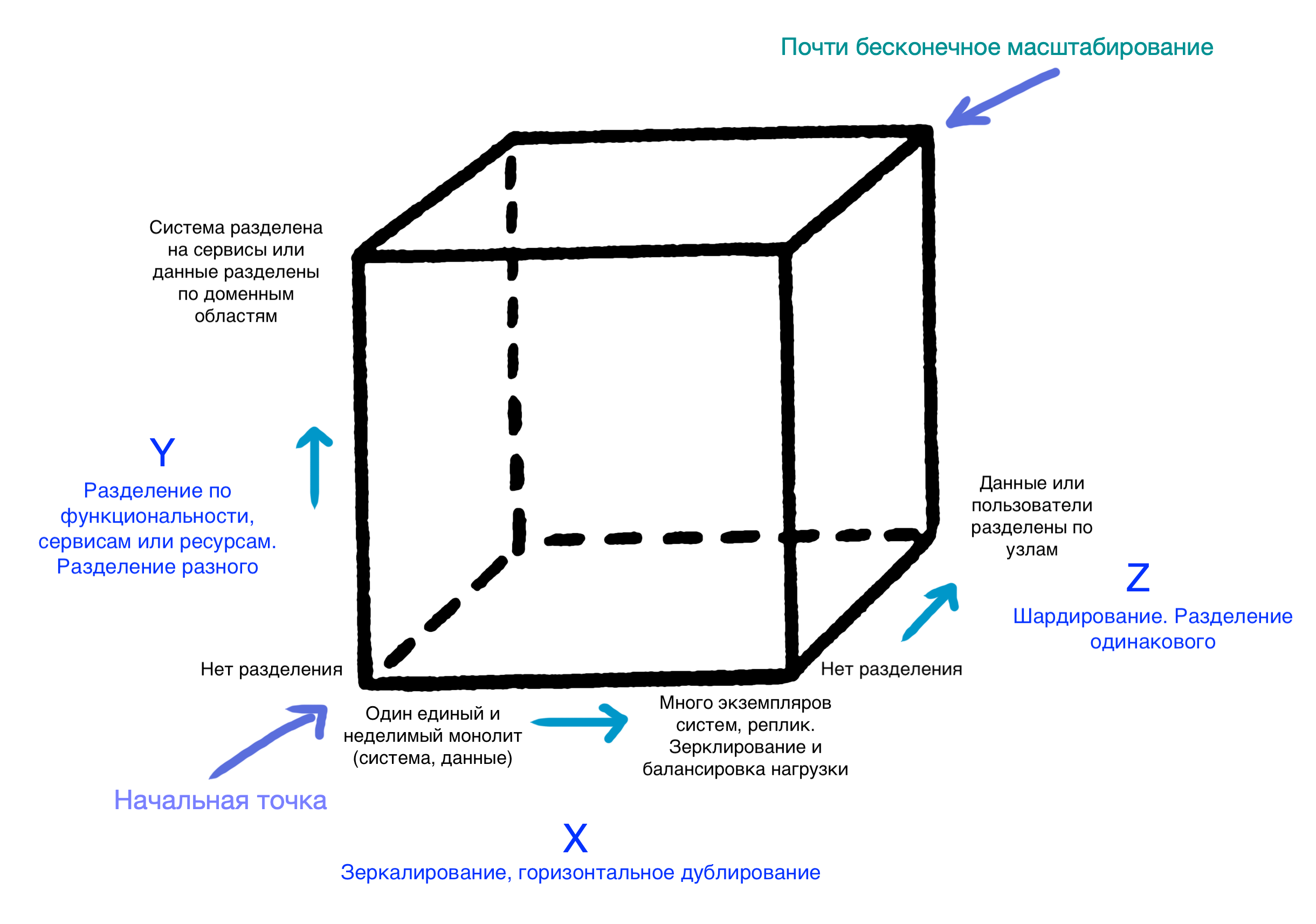
Почитать подробнее:
- Упоминание в статье на Хабре.
- В статье на microservices.io.
- Даже в wiki есть с pros и cons.
- SCALING APPLICATIONS: THE SCALE CUBE.
- И вот ещё.
- А тут с картинками.
- Также куб упоминается в книгах Microservice Patterns and Best Practices и Microservices Patterns (есть на русском).
Как и в случае с ООП-паттернами, существует книжка с одноимённым названием. Переведена на русский. На Хабре опубликована статья-затравочка от ИД "Питер".
И есть другая книжка — Microservice Patterns and Best Practices. На Medium имеется на неё обзор.
На microservices.io можно найти наглядные и интерактивные схемы паттернов микросервисной архитектуры: тут или здесь. Каждый блок на схемах — это ссылка на статью по данному паттерну. Строго рекомендую.
Также на Хабре есть статья по теме. Первым же комментарием к ней советуют тоже интересную книжку — Enterprise Integration Patterns и список паттернов из неё.
Теорема CAP — эвристическая теорема, утверждающая, что любая распределённая система может удовлетворять не более двум из трёх свойств:
- Consistency (согласованность) — во всех вычислительных узлах в один момент времени данные не противоречат друг другу — каждое чтение вернёт самую последнюю запись. Подразумевает под собой линеаризуемость — если произошла какая-либо операция, то её результат доступен сразу после того, как был получен ответ о её выполнении.
- Availability (доступность) — любой запрос получает успешный ответ без гарантии, что ответы со всех узлов системы совпадают.
- Partition tolerance (устойчивость к разделению) — система продолжает функционировать, несмотря на потерю (или задержку) произвольного числа сообщений между узлами из-за сетевых проблем (асинхронная сеть).
MongoDB, по мнению большинства (например), это — CP, но вот есть статья… Держим в уме, что теорема эвристическая и носит упрощательный характер. Также вызывает много споров.
Про большинство БД можно найти ответы в статьях по дополнительным ссылкам ниже.
Подробности:
- Есть несколько статей на Хабре: раз, два, три, четыре, пять
- Visual Guide to NoSQL Systems с красивой иллюстрацией треугольника CAP и БД на его сторонах
- The CAP FAQ
- Статья на bigdataschool
- Споры вокруг MongoDB на stackoverflow
- CAP Theorem на портале IBM
- CAP Theorem and Distributed Database Management Systems с картинками
- What is the CAP Theorem? на богомерзком medium
Сервис-ориентированная архитектура (SOA) — независимый от технологий, компаний и программных продуктов подход к разработке программного обеспечения на основе распределённых, слабосвязанных заменяемых компонентов с чётко определёнными интерфейсами и протоколами взаимодействия. Область охвата SOA — это всё предприятие, где происходит взаимодействие между приложениями. SOA делает ставку на доступ к бизнес-функциям предприятия через повторно используемые интерфейсы.
Сервис в данной архитектуре:
- представляет бизнес-логику с определённым результатом (много ответственностей, связанных единой бизнес-областью, целью, смыслом и т.п.);
- может состоять из других сервисов или зависеть от них;
- является "чёрным ящиком" для своих клиентов.
Как и все серьёзные подходы к чему-либо имеет свой манифест
Микросервисная архитектура (MSA) — частный случай SOA, побуждающий строить взаимодействие насколько это возможно и необходимо небольших, слабосвязанных, легко изменяемых и взаимозаменяемых компонентов (микросервисов). MSA ориентирована, в первую очередь, на структуру и компоненты отдельного приложения.
Микросервис: - выполняет только одну достаточно элементарную и определённую функцию (Unix way — единственная ответственность);
- деплоится и разрабатывается независимо от других микросервисов;
- является независимым от других микросервисов (в том числе максимальная минимизация общего кода);
- является "чёрным ящиком" для своих клиентов.
Можно найти несколько источников, где MSA представляется как нечто новое и хорошее, а SOA — старое и умирающее. Часто это ещё и подаётся под соусом технологий. ИМХО — это больше маркетинговая туфта, чем хорошее сравнение. MSA и SOA не завязаны на технологии и не ограничивают в их использовании. Более того, оба подхода можно совмещать с пользой для бизнеса.
Подробнее:
- Стандарты SOA
- Микросервисы, SOA и API на ibm с отличными картинками о различиях SOA и MSA
- Monolith vs SOA vs MSA на medium
- Microservices vs SOA на DZone
- Колонка сравнения MSA и SOA на сайте Мартина Фаулера
- SOA и MSA
Достоинства:
- Меньше кода на программный компонент (микросервис) -> проще и быстрее разрабатывать, поддерживать, тестировать, понимать, выбросить и переписать, реализовывать с помощью наиболее подходящих технологий и инструментов (в том числе на новье)
- Меньше команда -> меньше проблем и конфликтов при мёрже и совместной разработке
- Проще горизонтально масштабировать
- Быстрее и проще как внедрять, так и откатывать
Недостатки:
- Увеличение накладных расходов на взаимодействие между программными компонентами (микросервисами) — обмен между ними выполняется по сети со всем вытекающим (сериализация/десериализация, задержки и т.д.)
- Возможно появление необходимости распределённых транзакций
- Увеличение объёмов логирования и мониторинга
- Дублирование кода
- Сложнее дебажить и отлавливать ошибки
- Нужно быть готовым и способным продолжить работать, когда любой из микросервисов отвалится
- Общая сложность растёт с количеством микросервисов
Подробнее:
- На Хабре есть целый хаб на тему микросервисов. Отмечу несколько статей по вопросу: раз, два, три, четыре, пять, шесть и Смерть микросервисного безумия в 2018 году
- Записка программиста Преимущества и недостатки микросервисной архитектуры
- Статья на Wikipedia
- Microservices — Not A Free Lunch!
- Микросервисы — за и против
- What are microservices?
- To go or not to go micro: the pros and cons of microservices
- Microservices in a Nutshell. Pros and Cons
Посмотреть:
Композиция (composition) — отношение "является частью" (HAS-A Relationship), при котором целое явно контролирует время жизни своей составной части.
Агрегация (aggregation) — отношение "является частью" (HAS-A Relationship), при котором целое хоть и содержит свою составную часть, время их жизни не связано.
Подробнее:
Тестовый объект (Test Double) — объекты, которые необходимы в тестах для подмены внешних зависимостей тестируемого кода
Типы тестовых объектов:
- Dummy — объекты, которые передаются в методы, но не используются. Например: заполнение списка параметров, часто это просто null
- Fake — заглушка, являющаяся рабочей имплементацией, но с урезанной функциональностью и неприменима в production-окружении. Например: in-memory БД (fake database)
- Stub — заглушка с жестко заданными ответами на вызовы со стороны тестируемого объекта (system under test — SUT) во время теста
- Spy — это разновидность Stub, которая записывает информацию о произошедшем с ней, какие вызовы её методов были выполнены и сколько раз, как изменилось состояние и т.п.
- Mock — заглушка с ожиданиями определённого набора вызовов, которые будут на ней выполнены в ходе теста
Из данного набора заглушек только Mock используется для верификации поведения, остальные — для верификации состояния тестируемого объекта .
Подробнее:
- В статье на Хабре
- Mock vs Stub
- Mocks Aren't Stubs от Мартина Фаулера
- Test Double
- Test Stub
- Test Spy
- Mock Object
- Fake Object
- Interaction Based Testing в Spock Framework
- Документация Mockito
- Mockito Mock vs. Spy in Spring Boot Tests
- Tag: Mockito на Bealdung
В общем виде определение полиморфизма приводит Бенджамин Пирс в своей книге Типы в языках программирования:
Термин “полиморфизм” обозначает семейство различных механизмов, позволяющих использовать один и тот же участок программы с различными типами в различных контекстах.
Полиморфизм бывает следующих видов:
- Универсальный полиморфизм. Он подразделяется на:
- Параметрический полиморфизм — описывает вычисления в общем виде, абстрагируясь от конкретных типов, которые будут использованы. Параметрически полиморфные функции также называются обобщенными (Generic).
- Полиморфизм включений (inclusive) — описывает вычисления не только для конкретного типа, но для и всех его возможных подтипов. Отражает принцип подстановки Барбары Лисков.
- Специальный полиморфизм (или ad-hoc) — диспетчеризация (перенаправление) к одной или нескольким функциям для конкретного типа аргумента. Из него выделяют подтипы:
- Перегрузка (overloading) позволяет объявлять функции с одним и тем же именем, но с разными типами аргументов и их количеством (арностью).
- Неявное приведение типов — преобразование одного типа в другой по определённым правилам, описанным в стандарте языка, и выполняемое компилятором.
Безотносительно к Java полиморфизм хорошо разобран в статье Полиморфизм простыми словами.
В других источниках:
- Java Challengers #3: Полиморфизм и наследование на Хабре
- Как полиморфизм реализован внутри JVM на Хабре
- Все о переопределении в Java на Хабре
- Неформальное введение в теорию типов
- Несколько глав из Java Virtual Machine Specification: Invoking Methods, invokevirtual, Linking
- Несколько глав из Java Language Specification: Inheritance, Overriding, and Hiding, Conversions and Contexts, Type Inference
REST – это архитектурный стиль, который можно применить для реализации взаимодействия web-сервисов.
Вот несколько признаков REST, которые хотят услышать большинство интервьюеров:
- Концентрация на ресурсах
- Ресурс имеет уникальный URI
- Формат передачи — обычно JSON, но можно XML
- Транспортный протокол — HTTP. Строго говоря — это необязательно, но по факту и в большинстве случаев так. Следующие пункты тоже.
- Использование различных методов HTTP в соответствии с их семантикой и предназначением. GET: получить информацию о ресурсе; POST: создать новый ресурс; PUT: обновить существующий ресурс; DELETE: удалить ресурс. Иногда спорят об обновлении — PUT vs PATCH vs POST.
- Использование кодов ответа HTTP в соответствии с их семантикой и предназначением. Хорошая картинка по определению HTTP-кода ответа.
- HATEOAS обычно не используют и не спрашивают, но это тоже относится к REST, о чём можно упомянуть
Чаще всего, на моей практике, спрашивают какой HTTP-метод для чего должен использоваться или как назвать URI, чтобы API было RESTful. Однако, никакой спецификации или стандарта под это нет. И вообще, строго говоря, изначально REST — это архитектурный стиль, непривязанный ни к каким протоколам. Тема раскрыта в этой статье или в этой на Хабре — комментарии сочные.
Вот принципы REST-архитектуры по Филдингу:
- Модель клиент-сервер (Client–server)
- Отсутствие состояния (Stateless) — у клиента и сервера нет необходимости отслеживать состояние друг друга
- Кэширование (Cacheable) — ответы сервера должны помечаться как кэшируемы и некэшируемые
- Единообразие интерфейса (Uniform interface) — идентификация ресурсов, манипуляция ресурсами через представление, "самодостаточные" сообщения, HATEOAS
- Слои (Layered system) — в системе может быть больше одного слоя, но компоненты системы видит и взаимодействует только с соседним слоем. Кроме клиента и сервера может быть ещё прокси и шлюз
- Код по требованию (необязательное ограничение) (Code on demand (optional)) — отправка сервером исполняемого кода клиенту
SOAP — стандартизованный протокол обмена данными.
Основные характеристики SOAP:
- Формат сообщений — XML (SOAP-XML — Envelope, Header, Body, Fault)
- SOAP-сервис должен иметь описание на языке WSDL(тоже XML)
- SOAP поддерживает множество протоколов — (TCP, UDP, HTTP, SMTP, FTP и т.д.)
- При использовании HTTP, поддерживаются методы GET и POST
Тема горячая, интересная всем web-разработчикам, поэтому на Хабре имеется уйма статей на любой вкус.
Теоритическо-практические:
- Серия постов про REST — введение, REST vs SOAP, Contract First, Code First, HATEOAS, Рекомендации и примеры на Java и Spring
- REST vs SOAP. Часть 1. Почувствуйте разницу и REST vs SOAP. Часть 2. Как проще и эффективнее организовать общение платформ?
- Дао Вебсервиса. (Или да хватит же изобретать велосипеды!)
- REST API Best Practices
- Что такое RESTful на самом деле
- Важные аспекты RESTful API для вашего проекта
- Как построить REST-like API в крупном проекте
- Разработка web API
- RESTful API для сервера – делаем правильно (Часть 1) и RESTful API для сервера – делаем правильно (Часть 2)
- Шпаргалки по безопасности: REST
- 7 вредных советов проектировщику REST API
- Самодокументированный JAX-WS с поддержкой XSD Restrictions
- REST API на Java без фреймворков
- Введение в Spring Boot: создание простого REST API на Java
- Наипростейший RESTful сервис на Kotlin и Spring boot
- SOAP-сервер на Java при участии Apache CXF и Spring
- SOAP Web-сервис средствами Spring-WS
Холиварно-дискусионные:
- REST — это новый SOAP
- REST страсти по 200
- REST API должен основываться на гипертексте
- RESTful API — большая ложь
И на всякий случай: - Сравнение REST и GraphQL
- REST? Возьмите тупой JSON-RPC
А кроме Хабра: - A Brief Introduction to REST
- REST CookBook
- RESTful Web APIs
- Introduction to Spring Data REST
- What is REST
- Building REST services with Spring
- Создание SOAP Web-сервиса
- Спецификация SOAP
Популярные библиотеки
Осторожно, холиворный вопрос! Возможны ожоги и прочие неприятности!
На Хабре найдётся много больше одной статьи демонстрирующей народную любовь к Lombok — ведь он знаменитый победитель бойлерплейтов, сократитель кода, ускорятель кодонабора, любимый сундучок исцеляющих костылей и прочее, и прочее. О прелести Lombok вам расскажут из любого утюга.
Но как там с подводными камнями? Что с надводными вилами? Этот вопрос на собеседовании о том, как хорошо вы знаете недостатки своего любимого инструмента. И на сдачу — тест на совместимость.
А ответ на вопрос стоит начать с переворота стрелочки — с хитрым ленинским прищуром спросите у интервьюера: "А как в вашем стайл-гайде написано?". Заодно узнаете о его отсутствии наличии. Ибо холиварные вопросы решить нужно однажды на сходе Архитектурного Синода и на весь простор компании сии решения распространить, увековечив их в стайл-гайде, дабы раскола избежать и не соблазнять неокрепшие умы неофитов спорами на рабочем месте посреди спринта горящего.
Самая лайтовая и, возможно, притянутая за уши причина не использовать Lombok — плагин постоянно отваливается с выходом новой версии IDEA. А если отваливается плагин, то работа летит коту под хвост. Но это уже уходит в прошлое! С версии 2020.3 Lombok-плагин будет поставляться вместе с IDEA.
Большинство из проблем с Lombok связаны с особенностями и нюансами реализации как самих аннотаций библиотеки, так и сторонних фреймворков и библиотек. Например, эксперты по Hibernate советуют (например тут) избегать использования Lombok в entity-классах. Хотя бы исключить использование @EqualsAndHashCode, @ToString и @Data, потому что генерируемый ими код для методов equals, hashCode и toString может либо отработать неверно, либо привести к потере производительности или исключениям в некоторых определённых случаях для entities. А как нужно правильно реализовывать данные методы для entities написано тут или тут.
Интересная дискуссия, затянувшаяся на два дня, была по данному вопросу в чатике подкаста "Паша+Слава" 7-8 марта — начало тут. В ней asm0dey задаёт каверзные вопросы по использованию Lombok и рассказывает почему он забанил Lombok как тимлид. Например: "Что произойдёт если библиотека, которую ты используешь, использует @SneakyThrows и ты её вызываешь в рамках транзакции?" (об этом можно почитать тут), "Тебе наверное нравится аннотация @Data. Как она строит equals для коллекций и для массивов?", "Знаешь ли ты что @EqualsAndHashCode может вызвать StackOverflowException и тебе даже нечего будет дебажить?".
Главная проблема Lombok — простота хуже воровства — его волшебная лёгкость провоцирует не читать документацию, что потом может повлечь за собой горе и страдания. Но может и не повлечь — тут как задача в джиру ляжет. Не даром не заросла к Lombok народная тропа — можно ограничиться использованием некоторого минимального джентельменского набора из Lombok, следить за собой. Но всё-таки мойте руки, предохраняйтесь читайте документацию перед активным использованием ваших инструментов, ведь они могут иметь неочевидные нюансы и сюрпризы в реализации.
P.S. У Lombok есть занятная экспериментальная фича onX — у неё интересный синтаксис (@__ правда только для Java 7) и его описание в документации. А вот тут рассказывается зачем оно вам может понадобиться, например в Spring-приложении.
Подробнее:
Прочее
Благодаря нагрузочному тестированию появляется возможность оценить производительность приложения при различных нагрузках от действий определённого количества пользователей приложения.
Существует несколько решений для проведения подобного рода тестирования:
- Apache JMeter — самый известный, opensource, поддерживает работу с различными сетевыми протоколами разных уровней HTTP, HTTPS, FTP, LDAP, SOAP, TCP, почтовых протоколов и shell-скриптов. Он, как java-based инструмент, предоставляет возможности по работе с JDBC, Message-oriented middleware (MOM) через JMS и Java Objects.
- LoadRunner — это сложный и универсальный инструмент для нагрузочного тестирования различных платформ. Платный, ориентирован в первую очередь на Enterprise.
- LoadNinja — платный, позволяет пользователям создавать нагрузочные тесты без использования каких-либо скриптов. Средствами браузера собирает метрики, которые позволяют оценить производительность приложения.
- WebLOAD — коммерческий комплексный инструмент. Предоставляет пользователям расширенные функции, такие как анализ производительности и интеллектуальная аналитика, а также интеграцию с рядом инструментов, начиная от мониторинга производительности до конвейеров CI/CD.
- LoadUI Pro — коммерческий инструмент от создателей SOAP UI, тесты которого можно использовать как сценарии нагрузочного тестирования. Предназначен для веб-сервисов и позволяет пользователям оценивать масштабируемость, скорость и производительность API.
- K6 — opensource инструмент, ориентированный на разработчиков и тестирования производительности сайтов. Скрипты пишутся на JavaScript. Запуск тестов происходит в консольном режиме, результаты тестирования по умолчанию также выводятся в консоль, однако доступна поддержка таких плагинов для вывода результатов, как Kafka, Datadog, InfluxDB, JSON и StatsD. Доступна интеграция с CI-инструментами.
- Яндекс.Танк — инструмент от Яндекс с модульной архитектурой, которая позволяет использовать различные генераторы нагрузок — высокопроизводительный асинхронный hit-based-генератор HTTP-запросов Phantom и сценарный инструмент jMeter. Встроенный мониторинг ресурсов, автоматическая остановка теста по заданным условиям, вывод результатов в консоль и в виде графиков, подключение пользовательских модулей.
- Gatling — opensource инструмент на Scala с использованием Netty и Akka. Скрипты пишутся на Scala, есть возможность интеграции с Jenkins.
Подробнее:
- Обзор инструментария для нагрузочного и перформанс-тестирования на Хабре
- Нагрузочное тестирование: с чего начать и куда смотреть на Хабре
- Нагрузочное тестирование на Gatling на Хабре
- Top 10 лучших инструментов для нагрузочного тестирования
- 9 этапов тестирования производительности
- 10 шагов для запуска тестирования производительности с Apache JMeter
- jMeter — Краткое руководство
- Rest API Load testing with Apache JMeter
- Load Testing with Gatling — The Complete Guide
- Открытые бенчмарки для нагрузочного тестирования серверов и веб-приложений
Виртуальная машина (Virtual Machine — VM) — программная и/или аппаратная система, эмулирующая аппаратное обеспечение и исполняющее приложения некоторой целевой платформы на платформе хоста. Иными словами — это виртуальный компьютер с виртуальными устройствами и независимой операционной системой, управлением памятью и другими компонентами. Т.о. на одном реальном компьютере может существовать несколько виртуальных, изолированных друг от друга, со своими ОС. Запускаемые внутри виртуальной машины приложения не имеют понятия о её виртуальности и взаимодействуют с ней как с реальной. Хотя VM изолирована от реального хоста, она может иметь доступ к его диску и периферийным устройствам. Существует возможность сделать backup'ы VM в виде текущего состояния системы и содержимого дисков для возможности последующего восстановления системы в исходное состояние.
Каждая VM несёт дополнительные расходы на эмуляцию оборудования и работу своей ОС.
Управляет виртуальными машинами на реальном железе гипервизор — это программное и/или аппаратное решение, процесс, который отделяет операционную систему компьютера и приложения от базового физического оборудования.
Самими популярными решениями виртуализации являются KVM с QEMU, XEN, решения от VMWare и Hyper-V.
Docker — программное решение, использующее виртуализацию на уровне операционной системы для доставки, развёртывания, изоляции и упаковки приложения со всеми его зависимостями в т.н. контейнер.
Контейнеры расходуют меньше места на диске и ресурсов хоста, потому что переиспользуют большее количество общих ресурсов хоста и обеспечивает виртуализацию на уровне ОС. Каждый из контейнеров работает как отдельный процесс основной ОС, у которого есть своё собственное виртуальное адресное пространство. Изоляция контейнеров достигается с помощью linux namespaces. Ограничить потребление системных ресурсов контейнером можно через cgroups.
Контейнер создаётся из образа, который в свою очередь основан на Dockerfile проекта, и представляет собой набор файловых систем (слоёв) наслоённых друг на друга и сгруппированных вместе, доступных только для чтения. Контейнеры всегда создаются из образов, добавляя свой собственный доступный для записи верхний слой, в который вносятся необходимые для контейнера в процессе работы изменения. Это позволяет нескольким контейнерам переиспользовать один образ.
Docker-контейнеры используются различными системами оркестрации и CI/CD.
Для существует большой общедоступный репозиторий Docker-образов — Docker-Hub
Кроме Docker, существуют и другие контейнеры.
На Хабре есть множество статей на тему Docker:
- VM или Docker?
- Серия статей "Изучаем Docker": част 1, часть 2, часть 3, часть 4, часть 5, часть 6
- Docker. Начало
- Как устроен процесс создания docker-контейнера (от docker run до runc)
- Полное практическое руководство по Docker: с нуля до кластера на AWS
- Лабораторная работа: введение в Docker с нуля. Ваш первый микросервис
- Исповедь docker хейтера
- Глубокое погружение в Linux namespaces
- Как я запускал Докер внутри Докера и что из этого получилось
- Понимая Docker
- Поняв Docker
- Основы Docker за Х часов и Y дней
- Docker и все, все, все
- Безопасность для Docker-контейнеров
- Методики уменьшения размеров образов Docker
- 10 практических рекомендаций по безопасности образов Docker: часть 1, часть 2
- Docker: вредные советы
- Docker: невредные советы
- Зачем нужен containerd и почему его отделили от Docker
- Зрелая исполняемая среда для контейнеров: containerd стал "выпускником" CNCF
А также на тему виртуализации:
- Гипервизоры. Что же это и как работает виртуальный сервер?
- Автоматизация Для Самых Маленьких. Часть 1.1. Основы виртуализации
- Архитектура Hyper-V: Глубокое погружение
- Hyper-V для разработчиков под Windows 10
- Общие принципы работы QEMU-KVM
- Работа с виртуальными машинами KVM. Введение
- Показатели эффективности: KVM vs. Xen
- Hyper-V или KVM?
Кроме того, можно углубиться в других источниках:
- Containers vs. virtual machines
- Play with Docker
- Документация Docker
- The Docker EcoSystem
- Hardware-assisted virtualization
- Full virtualization
- Сравнение гипервизоров: KVM, Hyper-V или VMware?
- Вся правда о гипервизорах
- Перестаем бояться виртуализации при помощи KVM
- Основы виртуализации и введение в KVM
- Виртуализация в Unix. Часть 1: Kernel-based Virtual Machine (KVM)
- Настольная книга по Linux/Cgroups
- Механизмы контейнеризации: cgroups
- Введение в контейнеры, VM и Docker для новичков
- containerd
- awesome-compose
- Learn Docker & Containers using Interactive Browser-Based Scenarios
- What Is Docker & Docker Container? A Deep Dive Into Docker!
- Docker for beginners
Контейнер сервлетов — это компонент веб-сервера для взаимодействия с Java-сервлетами — обеспечивает их жизненный цикл, сопоставление URL-адреса к определённому сервлету и имеет ли отправитель запроса по данному URL необходимые права доступа и т.п.
Примеры (также являются самостоятельными веб-серверами, но НЕ серверами приложений (реализуют неполный стек Java EE)):
- Самый известный — Apache Tomcat. Есть несколько вариаций: от простого контейнера до полноценного сервера приложений (TomEE)
- Jetty
- Undertow
Сервер приложений — сервер, который включает в себя контейнер сервлетов и реализует весь стек Java EE (ныне Jakarta EE).
Примеры: - Wildfly
- Apache TomEE
- IBM WebSphere
- Eclipse GlassFish
- Сводная таблица
Исчерпывающий ответ на вопрос "Зачем нужны сервера приложений, если есть Tomcat" можно найти в одноимённой статье.
Аналогичные источники вопросов-ответов и прочие полезности
- Вопросы к собеседованию Java-backend, Java core (60 вопросов) на Хабре
- Spring: вопросы к собеседованию на Хабре
- Шпаргалка Java программиста 1: JPA и Hibernate в вопросах и ответах на Хабре
- JavaSobes и в telegram
- Awesome-interview-questions/Java
- Вопросы для собеседования на Java Developer
- Вопросы и ответы на собеседование Java Developer
- Список вопросов с ответами для собеседования по Java
- JBook
- Telegram-канал Java: fill the gaps
- Telegram-канал middlejava
- Telegram-канал Java Developer
- Telegram-каналы microJUG и miniJUG
- Telegram-канал javaswag
- 50 вопросов по Docker, которые задают на собеседованиях, и ответы на них
- Антон Архипов — Неадекватное Java-интервью
- Every Programmer Should Know
- Работа не волк: часть 1, часть 2, часть 3
Итого
Собеседование Backend-Java-разработчика охватывает широкий диапазон используемых в работе практик и инструментов. Судя по дополнительным источникам, которые я приводил в ответах, на Хабре можно отыскать статьи по каждому вопросу, однако много источников уровня "Нетленная классика" лежит за его пределами. Например, в докладах с конференций JUG.RU.
Если у вас есть интересный вопрос с интерьвю, которым вы хотите поделиться, то вы можете написать его в комментариях или открыть PR в репозитории на GitHub с данной шпаргалкой.
Внимание! Будьте бдительны и осторожны! Во всех подобных статьях (моя не исключение) и сборниках могут прятаться ошибки. Помните, что лучшие источники знаний — это исходный код и документация.
Кроме того, зазубривание ответов на вопросы выше не даёт гарантий успешного трудоустройства, хорошой работы и шелковистости волос.







{kind=link}
Sergunka
Очень качественная подборка.
P.S. И где Вас такие вопросы спрашивали?
frozen_coder Автор
Спасибо.
Это сборная солянка по Москве. Все спрашивают плюс-минус эти вопросы. Глубина обсуждения может отличаться.