
О популярной библиотеке SQLAlchemy для работы с разными СУБД из Python было написано довольно много статей. Предлагаю вашему вниманию обзор и сравнение запросов с использованием ORM и SQL подходов. Данное руководство будет интересно прежде всего начинающим разработчикам, поскольку позволяет быстро окунуться в создание и работу с SQLAlchemy, поскольку документация от разработчика SQLAlchemy на мой скромный взгляд тяжела для чтения.

Немного о себе: я также начинающий разработчик, прохожу обучение по курсу «Python разработчик». Данный материал был составлен не в результате ДЗ, а в порядке саморазвития. Мой код может быть достаточно наивным, в связи с чем прошу не стесняться и свои замечания оставлять в комментариях. Если я вас еще не напугал, прошу под кат :)
Мы с вами разберем практический пример нормализации плоской таблицы, содержащей дублирующиеся данные, до состояния 3НФ (третьей нормальной формы).
Из вот такой таблицы:
сделаем вот такую БД:
Для нетерпеливых: код, готовый к запуску находится в этом репозитории. Интерактивная схема БД здесь. Шпаргалка по составлению ORM запросов находится в конце статьи.
Договоримся, что в тексте статьи мы будем использовать слово «Таблица» вместо «Отношение», и слово «Поле» вместо «Аттрибута». По заданию нам надо таблицу с музыкальными файлами поместить в БД, при этом устранив избыточность данных. В исходной таблице (формат CSV) имеются следующие поля (track, genre, musician, album, length, album_year, collection, collection_year). Связи между ними такие:
Для упрощения предположим что названия жанров, имена музыкантов, названия альбомов и коллекций не повторяются. Названия треков могут повторяться. В БД мы запроектировали 8 таблиц:
* данная схема тестовая, взята из одного из ДЗ, в ней есть некоторые недостатки — например нет связи треков с музыкантом, а также трека с жанром. Но для обучения это несущественно, и мы опустим этот недостаток.
Для теста я создал две БД на локальном Postgres: «TestSQL» и «TestORM», доступ к ним: логин и пароль test. Давайте наконец писать код!
По сути мы создаем пакетами справочники (жанры, музыкантов, альбомы, коллекции), а затем в цикле связываем остальные данные и строим вручную промежуточные таблицы. Запускаем код и видим что БД создалась. Главное не забыть вызывать commit() у сессии.
Теперь пробуем сделать тоже самое, но с применением ORM подхода. Для того чтобы работать с ORM нам надо описать классы данных. Для этого мы создадим 8 классов (по одному на кажую таблицу).
Нам достаточно создать базовый класс Base для декларативного стиля описания таблиц и унаследоваться от него. Вся магия отношений между таблицами заключается в правильном использовании relationship и ForeignKey. В коде указано в каком случае мы создаем какое отношение. Главное не забыть прописать relationship с обеих сторон связи «многие ко многим».
Непосредственно создание таблиц с использованием ORM подхода происходит путем вызова:
Обновление от 08.12.20: создать отдельные таблицы можно используя следующий синтаксис:
Но для этого требуется инстанцировать объекты классов.
Наполнение таблиц при использовании ORM подхода выглядит так:
Приходится поштучно заполнять каждый справочник (жанры, музыканты, альбомы, коллекции). В случае SQL запросов можно было генерировать пакетное добавление данных. Зато промежуточные таблицы в явном виде не надо создавать, за это отвечают внутренние механизмы SQLAlchemy.
По заданию нам надо написать 15 запросов используя обе техники SQL и ORM. Вот список поставленных вопросов в порядке возрастания сложности:
Как видите, вышеизложенные вопросы подразумевают как простую выборку так и с объединением таблиц, а также использование агрегатных функций.
Ниже предоставлены решения по каждому из 15 запросов в двух вариантах (используя SQL и ORM). В коде запросы идут парами, чтобы показать идентичность результатов на выводе в консоль.
Для тех, кому не хочется погружаться в чтение кода, я попробую показать как выглядит «сырой» SQL и его альтернатива в ORM выражении, поехали!
1. название и год выхода альбомов, вышедших в 2018 году:
SQL
ORM
2. название и продолжительность самого длительного трека:
SQL
ORM
3. название треков, продолжительность которых не менее 3,5 минуты:
SQL
ORM
4. названия сборников, вышедших в период с 2018 по 2020 год включительно:
SQL
ORM
* обратите внимание что здесь и далее фильтрация задается уже с использованием filter, а не с использованием filter_by.
5. исполнители, чье имя состоит из 1 слова:
SQL
ORM
6. название треков, которые содержат слово «me»:
SQL
ORM
7. количество исполнителей в каждом жанре:
SQL
ORM
8. количество треков, вошедших в альбомы 2019-2020 годов:
SQL
ORM
9. средняя продолжительность треков по каждому альбому:
SQL
ORM
10. все исполнители, которые не выпустили альбомы в 2020 году:
SQL
ORM
11. названия сборников, в которых присутствует конкретный исполнитель (Steve):
SQL
ORM
12. название альбомов, в которых присутствуют исполнители более 1 жанра:
SQL
ORM
13. наименование треков, которые не входят в сборники:
SQL
ORM
* обратите внимание что несмотря на предупреждение в PyCharm надо именно так составлять условие фильтрации, если написать как предлагает IDE («Collection.id is None») то оно работать не будет.
14. исполнителя(-ей), написавшего самый короткий по продолжительности трек (теоретически таких треков может быть несколько):
SQL
ORM
15. название альбомов, содержащих наименьшее количество треков:
SQL
ORM
Как видите, вышеизложенные вопросы подразумевают как простую выборку так и с объединением таблиц, а также использование агрегатных функций и подзапросов. Все это реально сделать с SQLAlchemy как в режиме SQL так и в режиме ORM. Разноообразие операторов и методов позволяет выполнить запрос наверное любой сложности.
Надеюсь данный материал поможет начинающим быстро и эффективно начать составлять запросы.
Немного о себе: я также начинающий разработчик, прохожу обучение по курсу «Python разработчик». Данный материал был составлен не в результате ДЗ, а в порядке саморазвития. Мой код может быть достаточно наивным, в связи с чем прошу не стесняться и свои замечания оставлять в комментариях. Если я вас еще не напугал, прошу под кат :)
Мы с вами разберем практический пример нормализации плоской таблицы, содержащей дублирующиеся данные, до состояния 3НФ (третьей нормальной формы).
Из вот такой таблицы:
Таблица с данными

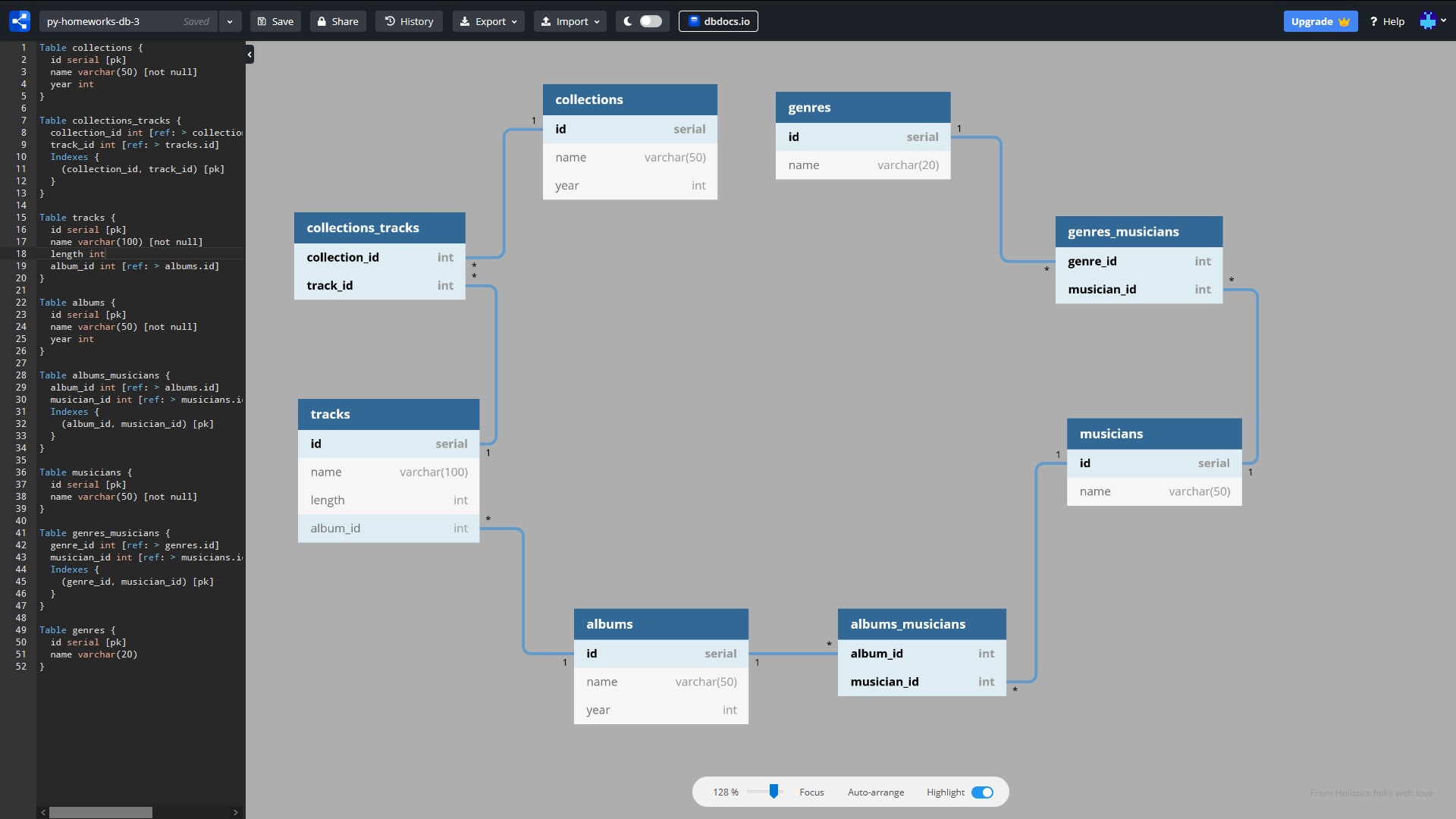
сделаем вот такую БД:
Схема связей БД
Для нетерпеливых: код, готовый к запуску находится в этом репозитории. Интерактивная схема БД здесь. Шпаргалка по составлению ORM запросов находится в конце статьи.
Договоримся, что в тексте статьи мы будем использовать слово «Таблица» вместо «Отношение», и слово «Поле» вместо «Аттрибута». По заданию нам надо таблицу с музыкальными файлами поместить в БД, при этом устранив избыточность данных. В исходной таблице (формат CSV) имеются следующие поля (track, genre, musician, album, length, album_year, collection, collection_year). Связи между ними такие:
- каждый музыкант может петь в нескольких жанрах, как и в одном жанре могут выступать несколько музыкантов (отношение многие ко многим)
- в создании альбома могут участвовать один или несколько музыкантов (отношение многие ко многим)
- трек принадлежит только одному альбому (отношение один ко многим)
- треки могут в ходить в состав нескольких сборников (отношение многие ко многим)
- трек может не входить ни в одну в коллекцию.
Для упрощения предположим что названия жанров, имена музыкантов, названия альбомов и коллекций не повторяются. Названия треков могут повторяться. В БД мы запроектировали 8 таблиц:
- genres (жанры)
- genres_musicians (промежуточная таблица)
- musicians (музыканты)
- albums_musicians (промежуточная таблица)
- albums (альбомы)
- tracks (треки)
- collections_tracks (промежуточная таблица)
- collections (коллекции)
* данная схема тестовая, взята из одного из ДЗ, в ней есть некоторые недостатки — например нет связи треков с музыкантом, а также трека с жанром. Но для обучения это несущественно, и мы опустим этот недостаток.
Для теста я создал две БД на локальном Postgres: «TestSQL» и «TestORM», доступ к ним: логин и пароль test. Давайте наконец писать код!
Создаем подключения и таблицы
Создаем подключения к БД
* код функций read_data и clear_db есть в репозитории.
DSN_SQL = 'postgresql://test:test@localhost:5432/TestSQL'
DSN_ORM = 'postgresql://test:test@localhost:5432/TestORM'
# Прочитаем данные из CSV в память в виде словаря.
DATA = read_data('data/demo-data.csv')
print('Connecting to DB\'s...')
# Мы будем работать с сессиями, поэтому создадим их раздельными для каждой БД.
engine_orm = sa.create_engine(DSN_ORM)
Session_ORM = sessionmaker(bind=engine_orm)
session_orm = Session_ORM()
engine_sql = sa.create_engine(DSN_SQL)
Session_SQL = sessionmaker(bind=engine_sql)
session_sql = Session_SQL()
print('Clearing the bases...')
# Удаляем все таблицы из БД перед заливкой содержимого. Используем только для учебы.
clear_db(sa, engine_sql)
clear_db(sa, engine_orm)
Создаем таблицы классическим путем через SQL
* код функции read_query есть в репозитории. Тексты запросов также есть в репозитории.
print('\nPreparing data for SQL job...')
print('Creating empty tables...')
session_sql.execute(read_query('queries/create-tables.sql'))
session_sql.commit()
print('\nAdding musicians...')
query = read_query('queries/insert-musicians.sql')
res = session_sql.execute(query.format(','.join({f"('{x['musician']}')" for x in DATA})))
print(f'Inserted {res.rowcount} musicians.')
print('\nAdding genres...')
query = read_query('queries/insert-genres.sql')
res = session_sql.execute(query.format(','.join({f"('{x['genre']}')" for x in DATA})))
print(f'Inserted {res.rowcount} genres.')
print('\nLinking musicians with genres...')
# assume that musician + genre has to be unique
genres_musicians = {x['musician'] + x['genre']: [x['musician'], x['genre']] for x in DATA}
query = read_query('queries/insert-genre-musician.sql')
# this query can't be run in batch, so execute one by one
res = 0
for key, value in genres_musicians.items():
res += session_sql.execute(query.format(value[1], value[0])).rowcount
print(f'Inserted {res} connections.')
print('\nAdding albums...')
# assume that albums has to be unique
albums = {x['album']: x['album_year'] for x in DATA}
query = read_query('queries/insert-albums.sql')
res = session_sql.execute(query.format(','.join({f"('{x}', '{y}')" for x, y in albums.items()})))
print(f'Inserted {res.rowcount} albums.')
print('\nLinking musicians with albums...')
# assume that musicians + album has to be unique
albums_musicians = {x['musician'] + x['album']: [x['musician'], x['album']] for x in DATA}
query = read_query('queries/insert-album-musician.sql')
# this query can't be run in batch, so execute one by one
res = 0
for key, values in albums_musicians.items():
res += session_sql.execute(query.format(values[1], values[0])).rowcount
print(f'Inserted {res} connections.')
print('\nAdding tracks...')
query = read_query('queries/insert-track.sql')
# this query can't be run in batch, so execute one by one
res = 0
for item in DATA:
res += session_sql.execute(query.format(item['track'], item['length'], item['album'])).rowcount
print(f'Inserted {res} tracks.')
print('\nAdding collections...')
query = read_query('queries/insert-collections.sql')
res = session_sql.execute(query.format(','.join({f"('{x['collection']}', {x['collection_year']})" for x in DATA if x['collection'] and x['collection_year']})))
print(f'Inserted {res.rowcount} collections.')
print('\nLinking collections with tracks...')
query = read_query('queries/insert-collection-track.sql')
# this query can't be run in batch, so execute one by one
res = 0
for item in DATA:
res += session_sql.execute(query.format(item['collection'], item['track'])).rowcount
print(f'Inserted {res} connections.')
session_sql.commit()По сути мы создаем пакетами справочники (жанры, музыкантов, альбомы, коллекции), а затем в цикле связываем остальные данные и строим вручную промежуточные таблицы. Запускаем код и видим что БД создалась. Главное не забыть вызывать commit() у сессии.
Теперь пробуем сделать тоже самое, но с применением ORM подхода. Для того чтобы работать с ORM нам надо описать классы данных. Для этого мы создадим 8 классов (по одному на кажую таблицу).
Список классов БД
Код скрипта объявления классов.
Base = declarative_base()
class Genre(Base):
__tablename__ = 'genres'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(20), unique=True)
# Объявляется отношение многие ко многим к Musician через промежуточную таблицу genres_musicians
musicians = relationship("Musician", secondary='genres_musicians')
class Musician(Base):
__tablename__ = 'musicians'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50), unique=True)
# Объявляется отношение многие ко многим к Genre через промежуточную таблицу genres_musicians
genres = relationship("Genre", secondary='genres_musicians')
# Объявляется отношение многие ко многим к Album через промежуточную таблицу albums_musicians
albums = relationship("Album", secondary='albums_musicians')
class GenreMusician(Base):
__tablename__ = 'genres_musicians'
# здесь мы объявляем составной ключ, состоящий из двух полей
__table_args__ = (PrimaryKeyConstraint('genre_id', 'musician_id'),)
# В промежуточной таблице явно указываются что следующие поля являются внешними ключами
genre_id = sa.Column(sa.Integer, sa.ForeignKey('genres.id'))
musician_id = sa.Column(sa.Integer, sa.ForeignKey('musicians.id'))
class Album(Base):
__tablename__ = 'albums'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50), unique=True)
year = sa.Column(sa.Integer)
# Объявляется отношение многие ко многим к Musician через промежуточную таблицу albums_musicians
musicians = relationship("Musician", secondary='albums_musicians')
class AlbumMusician(Base):
__tablename__ = 'albums_musicians'
# здесь мы объявляем составной ключ, состоящий из двух полей
__table_args__ = (PrimaryKeyConstraint('album_id', 'musician_id'),)
# В промежуточной таблице явно указываются что следующие поля являются внешними ключами
album_id = sa.Column(sa.Integer, sa.ForeignKey('albums.id'))
musician_id = sa.Column(sa.Integer, sa.ForeignKey('musicians.id'))
class Track(Base):
__tablename__ = 'tracks'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(100))
length = sa.Column(sa.Integer)
# Поскольку по полю album_id идет связь один ко многим, достаточно указать чей это внешний ключ
album_id = sa.Column(sa.Integer, ForeignKey('albums.id'))
# Объявляется отношение многие ко многим к Collection через промежуточную таблицу collections_tracks
collections = relationship("Collection", secondary='collections_tracks')
class Collection(Base):
__tablename__ = 'collections'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50))
year = sa.Column(sa.Integer)
# Объявляется отношение многие ко многим к Track через промежуточную таблицу collections_tracks
tracks = relationship("Track", secondary='collections_tracks')
class CollectionTrack(Base):
__tablename__ = 'collections_tracks'
# здесь мы объявляем составной ключ, состоящий из двух полей
__table_args__ = (PrimaryKeyConstraint('collection_id', 'track_id'),)
# В промежуточной таблице явно указываются что следующие поля являются внешними ключами
collection_id = sa.Column(sa.Integer, sa.ForeignKey('collections.id'))
track_id = sa.Column(sa.Integer, sa.ForeignKey('tracks.id'))Нам достаточно создать базовый класс Base для декларативного стиля описания таблиц и унаследоваться от него. Вся магия отношений между таблицами заключается в правильном использовании relationship и ForeignKey. В коде указано в каком случае мы создаем какое отношение. Главное не забыть прописать relationship с обеих сторон связи «многие ко многим».
Непосредственно создание таблиц с использованием ORM подхода происходит путем вызова:
Base.metadata.create_all(engine_orm)И вот тут включается магия, буквально все классы, объявленные в коде через наследование от Base становятся таблицами. Сходу я не увидел как указать экземпляры каких классов надо создать сейчас, а какие отложить для создания позже (например в другой БД). Наверняка такой способ есть, но в нашем коде все классы-наследники Base инстанцируются одномоментно, имейте это ввиду.
Обновление от 08.12.20: создать отдельные таблицы можно используя следующий синтаксис:
genre.create(engine_orm)Но для этого требуется инстанцировать объекты классов.
Наполнение таблиц при использовании ORM подхода выглядит так:
Заполнение таблиц данными через ORM
print('\nPreparing data for ORM job...')
for item in DATA:
# создаем жанры
genre = session_orm.query(Genre).filter_by(name=item['genre']).scalar()
if not genre:
genre = Genre(name=item['genre'])
session_orm.add(genre)
# создаем музыкантов
musician = session_orm.query(Musician).filter_by(name=item['musician']).scalar()
if not musician:
musician = Musician(name=item['musician'])
musician.genres.append(genre)
session_orm.add(musician)
# создаем альбомы
album = session_orm.query(Album).filter_by(name=item['album']).scalar()
if not album:
album = Album(name=item['album'], year=item['album_year'])
album.musicians.append(musician)
session_orm.add(album)
# создаем треки
# проверяем на существование трек не только по имени но и по альбому, так как имя трека по условию может
# быть не уникально
track = session_orm.query(Track).join(Album).filter(and_(Track.name == item['track'],
Album.name == item['album'])).scalar()
if not track:
track = Track(name=item['track'], length=item['length'])
track.album_id = album.id
session_orm.add(track)
# создаем коллекции, учитываем что трек может не входить ни в одну в коллекцию
if item['collection']:
collection = session_orm.query(Collection).filter_by(name=item['collection']).scalar()
if not collection:
collection = Collection(name=item['collection'], year=item['collection_year'])
collection.tracks.append(track)
session_orm.add(collection)
session_orm.commit()Приходится поштучно заполнять каждый справочник (жанры, музыканты, альбомы, коллекции). В случае SQL запросов можно было генерировать пакетное добавление данных. Зато промежуточные таблицы в явном виде не надо создавать, за это отвечают внутренние механизмы SQLAlchemy.
Запросы к базам
По заданию нам надо написать 15 запросов используя обе техники SQL и ORM. Вот список поставленных вопросов в порядке возрастания сложности:
- название и год выхода альбомов, вышедших в 2018 году;
- название и продолжительность самого длительного трека;
- название треков, продолжительность которых не менее 3,5 минуты;
- названия сборников, вышедших в период с 2018 по 2020 год включительно;
- исполнители, чье имя состоит из 1 слова;
- название треков, которые содержат слово «me».
- количество исполнителей в каждом жанре;
- количество треков, вошедших в альбомы 2019-2020 годов;
- средняя продолжительность треков по каждому альбому;
- все исполнители, которые не выпустили альбомы в 2020 году;
- названия сборников, в которых присутствует конкретный исполнитель;
- название альбомов, в которых присутствуют исполнители более 1 жанра;
- наименование треков, которые не входят в сборники;
- исполнителя(-ей), написавшего самый короткий по продолжительности трек (теоретически таких треков может быть несколько);
- название альбомов, содержащих наименьшее количество треков.
Как видите, вышеизложенные вопросы подразумевают как простую выборку так и с объединением таблиц, а также использование агрегатных функций.
Ниже предоставлены решения по каждому из 15 запросов в двух вариантах (используя SQL и ORM). В коде запросы идут парами, чтобы показать идентичность результатов на выводе в консоль.
Запросы и их краткое описание
print('\n1. All albums from 2018:')
query = read_query('queries/select-album-by-year.sql').format(2018)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album).filter_by(year=2018):
print(item.name)
print('\n2. Longest track:')
query = read_query('queries/select-longest-track.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).order_by(Track.length.desc()).slice(0, 1):
print(f'{item.name}, {item.length}')
print('\n3. Tracks with length not less 3.5min:')
query = read_query('queries/select-tracks-over-length.sql').format(310)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).filter(310 <= Track.length).order_by(Track.length.desc()):
print(f'{item.name}, {item.length}')
print('\n4. Collections between 2018 and 2020 years (inclusive):')
query = read_query('queries/select-collections-by-year.sql').format(2018, 2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Collection).filter(2018 <= Collection.year,
Collection.year <= 2020):
print(item.name)
print('\n5. Musicians with name that contains not more 1 word:')
query = read_query('queries/select-musicians-by-name.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Musician).filter(Musician.name.notlike('%% %%')):
print(item.name)
print('\n6. Tracks that contains word "me" in name:')
query = read_query('queries/select-tracks-by-name.sql').format('me')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).filter(Track.name.like('%%me%%')):
print(item.name)
print('Ok, let\'s start serious work')
print('\n7. How many musicians plays in each genres:')
query = read_query('queries/count-musicians-by-genres.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Genre).join(Genre.musicians).order_by(func.count(Musician.id).desc()).group_by(
Genre.id):
print(f'{item.name}, {len(item.musicians)}')
print('\n8. How many tracks in all albums 2019-2020:')
query = read_query('queries/count-tracks-in-albums-by-year.sql').format(2019, 2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track, Album).join(Album).filter(2019 <= Album.year, Album.year <= 2020):
print(f'{item[0].name}, {item[1].year}')
print('\n9. Average track length in each album:')
query = read_query('queries/count-average-tracks-by-album.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album, func.avg(Track.length)).join(Track).order_by(func.avg(Track.length)).group_by(
Album.id):
print(f'{item[0].name}, {item[1]}')
print('\n10. All musicians that have no albums in 2020:')
query = read_query('queries/select-musicians-by-album-year.sql').format(2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery = session_orm.query(distinct(Musician.name)).join(Musician.albums).filter(Album.year == 2020)
for item in session_orm.query(distinct(Musician.name)).filter(~Musician.name.in_(subquery)).order_by(
Musician.name.asc()):
print(f'{item}')
print('\n11. All collections with musician Steve:')
query = read_query('queries/select-collection-by-musician.sql').format('Steve')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Collection).join(Collection.tracks).join(Album).join(Album.musicians).filter(
Musician.name == 'Steve').order_by(Collection.name):
print(f'{item.name}')
print('\n12. Albums with musicians that play in more than 1 genre:')
query = read_query('queries/select-albums-by-genres.sql').format(1)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album).join(Album.musicians).join(Musician.genres).having(func.count(distinct(
Genre.name)) > 1).group_by(Album.id).order_by(Album.name):
print(f'{item.name}')
print('\n13. Tracks that not included in any collections:')
query = read_query('queries/select-absence-tracks-in-collections.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
# Important! Despite the warning, following expression does not work: "Collection.id is None"
for item in session_orm.query(Track).outerjoin(Track.collections).filter(Collection.id == None):
print(f'{item.name}')
print('\n14. Musicians with shortest track length:')
query = read_query('queries/select-musicians-min-track-length.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery = session_orm.query(func.min(Track.length))
for item in session_orm.query(Musician, Track.length).join(Musician.albums).join(Track).group_by(
Musician.id, Track.length).having(Track.length == subquery).order_by(Musician.name):
print(f'{item[0].name}, {item[1]}')
print('\n15. Albums with minimum number of tracks:')
query = read_query('queries/select-albums-with-minimum-tracks.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery1 = session_orm.query(func.count(Track.id)).group_by(Track.album_id).order_by(func.count(Track.id)).limit(1)
subquery2 = session_orm.query(Track.album_id).group_by(Track.album_id).having(func.count(Track.id) == subquery1)
for item in session_orm.query(Album).join(Track).filter(Track.album_id.in_(subquery2)).order_by(Album.name):
print(f'{item.name}')Для тех, кому не хочется погружаться в чтение кода, я попробую показать как выглядит «сырой» SQL и его альтернатива в ORM выражении, поехали!
Шпаргалка по сопоставлению SQL запросов и ORM выражений
1. название и год выхода альбомов, вышедших в 2018 году:
SQL
select name
from albums
where year=2018ORM
session_orm.query(Album).filter_by(year=2018)2. название и продолжительность самого длительного трека:
SQL
select name, length
from tracks
order by length DESC
limit 1ORM
session_orm.query(Track).order_by(Track.length.desc()).slice(0, 1)3. название треков, продолжительность которых не менее 3,5 минуты:
SQL
select name, length
from tracks
where length >= 310
order by length DESCORM
session_orm.query(Track).filter(310 <= Track.length).order_by(Track.length.desc())4. названия сборников, вышедших в период с 2018 по 2020 год включительно:
SQL
select name
from collections
where (year >= 2018) and (year <= 2020)ORM
session_orm.query(Collection).filter(2018 <= Collection.year, Collection.year <= 2020)* обратите внимание что здесь и далее фильтрация задается уже с использованием filter, а не с использованием filter_by.
5. исполнители, чье имя состоит из 1 слова:
SQL
select name
from musicians
where not name like '%% %%'ORM
session_orm.query(Musician).filter(Musician.name.notlike('%% %%'))6. название треков, которые содержат слово «me»:
SQL
select name
from tracks
where name like '%%me%%'ORM
session_orm.query(Track).filter(Track.name.like('%%me%%'))7. количество исполнителей в каждом жанре:
SQL
select g.name, count(m.name)
from genres as g
left join genres_musicians as gm on g.id = gm.genre_id
left join musicians as m on gm.musician_id = m.id
group by g.name
order by count(m.id) DESCORM
session_orm.query(Genre).join(Genre.musicians).order_by(func.count(Musician.id).desc()).group_by(Genre.id)8. количество треков, вошедших в альбомы 2019-2020 годов:
SQL
select t.name, a.year
from albums as a
left join tracks as t on t.album_id = a.id
where (a.year >= 2019) and (a.year <= 2020)ORM
session_orm.query(Track, Album).join(Album).filter(2019 <= Album.year, Album.year <= 2020)9. средняя продолжительность треков по каждому альбому:
SQL
select a.name, AVG(t.length)
from albums as a
left join tracks as t on t.album_id = a.id
group by a.name
order by AVG(t.length)ORM
session_orm.query(Album, func.avg(Track.length)).join(Track).order_by(func.avg(Track.length)).group_by(Album.id)10. все исполнители, которые не выпустили альбомы в 2020 году:
SQL
select distinct m.name
from musicians as m
where m.name not in (
select distinct m.name
from musicians as m
left join albums_musicians as am on m.id = am.musician_id
left join albums as a on a.id = am.album_id
where a.year = 2020
)
order by m.nameORM
subquery = session_orm.query(distinct(Musician.name)).join(Musician.albums).filter(Album.year == 2020)
session_orm.query(distinct(Musician.name)).filter(~Musician.name.in_(subquery)).order_by(Musician.name.asc())11. названия сборников, в которых присутствует конкретный исполнитель (Steve):
SQL
select distinct c.name
from collections as c
left join collections_tracks as ct on c.id = ct.collection_id
left join tracks as t on t.id = ct.track_id
left join albums as a on a.id = t.album_id
left join albums_musicians as am on am.album_id = a.id
left join musicians as m on m.id = am.musician_id
where m.name like '%%Steve%%'
order by c.nameORM
session_orm.query(Collection).join(Collection.tracks).join(Album).join(Album.musicians).filter(Musician.name == 'Steve').order_by(Collection.name)12. название альбомов, в которых присутствуют исполнители более 1 жанра:
SQL
select a.name
from albums as a
left join albums_musicians as am on a.id = am.album_id
left join musicians as m on m.id = am.musician_id
left join genres_musicians as gm on m.id = gm.musician_id
left join genres as g on g.id = gm.genre_id
group by a.name
having count(distinct g.name) > 1
order by a.nameORM
session_orm.query(Album).join(Album.musicians).join(Musician.genres).having(func.count(distinct(Genre.name)) > 1).group_by(Album.id).order_by(Album.name)13. наименование треков, которые не входят в сборники:
SQL
select t.name
from tracks as t
left join collections_tracks as ct on t.id = ct.track_id
where ct.track_id is nullORM
session_orm.query(Track).outerjoin(Track.collections).filter(Collection.id == None)* обратите внимание что несмотря на предупреждение в PyCharm надо именно так составлять условие фильтрации, если написать как предлагает IDE («Collection.id is None») то оно работать не будет.
14. исполнителя(-ей), написавшего самый короткий по продолжительности трек (теоретически таких треков может быть несколько):
SQL
select m.name, t.length
from tracks as t
left join albums as a on a.id = t.album_id
left join albums_musicians as am on am.album_id = a.id
left join musicians as m on m.id = am.musician_id
group by m.name, t.length
having t.length = (select min(length) from tracks)
order by m.nameORM
subquery = session_orm.query(func.min(Track.length))
session_orm.query(Musician, Track.length).join(Musician.albums).join(Track).group_by(Musician.id, Track.length).having(Track.length == subquery).order_by(Musician.name)15. название альбомов, содержащих наименьшее количество треков:
SQL
select distinct a.name
from albums as a
left join tracks as t on t.album_id = a.id
where t.album_id in (
select album_id
from tracks
group by album_id
having count(id) = (
select count(id)
from tracks
group by album_id
order by count
limit 1
)
)
order by a.nameORM
subquery1 = session_orm.query(func.count(Track.id)).group_by(Track.album_id).order_by(func.count(Track.id)).limit(1)
subquery2 = session_orm.query(Track.album_id).group_by(Track.album_id).having(func.count(Track.id) == subquery1)
session_orm.query(Album).join(Track).filter(Track.album_id.in_(subquery2)).order_by(Album.name)Как видите, вышеизложенные вопросы подразумевают как простую выборку так и с объединением таблиц, а также использование агрегатных функций и подзапросов. Все это реально сделать с SQLAlchemy как в режиме SQL так и в режиме ORM. Разноообразие операторов и методов позволяет выполнить запрос наверное любой сложности.
Надеюсь данный материал поможет начинающим быстро и эффективно начать составлять запросы.




mSnus
Если я правильно посчитал в уме, в п.7 SQL выдаст не количество музыкантов в жанре, а количество имён музыкантов в жанре. Там count(m.name), а не count(m.id)… к тому же считаются не уникальные значения, а все (без distinct). Проверьте на всякий случай, может, я и неправ O:-)
В любом случае, спасибо, прокручивать такие штуки в голове — отличная разминка поутру и способ проснуться!
Yuribtr Автор
Да, вы все правильно заметили, однако по условию задачи у нас имена музыкантов уникальные поэтому в данном случае разницы нет. Я поправлю запросы в коде. Спасибо.
mSnus
Разве уникальные? Mary и Kate встречаются много раз… рад помочь.
Yuribtr Автор
Да, музыканты уникальные, они конечно могут повторяться несколько раз в таблице, но при нормализации БД мы их группируем по имени. Такое условие данной задачи.