
На Хабре уже не раз писали о том, что у Selenium Grid есть проблемы, которые не решить простым способом (например: раз, два, три). В этой статье мы поделимся нашим опытом и расскажем, как нам в Wrike удалось построить стабильную инфраструктуру для Selenium-тестов.
TLDR: Мы написали своё open source решение и полностью заменили им Selenium Grid.
Мы уже рассказывали о том, как масштабировали свою Selenium-ферму с помощью Google Cloud Engine и Kubernetes. От очередей на запуск тестов мы избавились, но из QA-департамента регулярно поступали жалобы на нестабильность тестовой инфраструктуры.
Выбор пути
У нас не получилось заставить работать Selenium Grid в GKE так, чтобы нас это устраивало. В GKE мы использовали короткоживущие Preemptible VMs. Запуски тестов создают непродолжительную, но интенсивную нагрузку, и именно для таких случаев хорошо подходят эти короткоживущие инстансы. Их использование позволяет снизить расходы на инфраструктуру в несколько раз. Но, так как они могут быть выключены в любой момент, это увеличивает нестабильность Selenium Grid, который и сам по себе достаточно нестабилен. Так мы пришли к выводу, что надо искать ему замену.
Больше всего нам понравился Selenoid от Aerokube, в том числе потому, что в нём не используются компоненты Selenium Grid (Selenium Hub и Selenium Node). Но, к сожалению, он не работает в Kubernetes, а это было критично для нас: мы широко используем его в других частях нашей инфраструктуры.
В качестве альтернатив, работающих в Kubernetes, мы рассматривали Zalеnium, jsonwire-grid и Moon. Zalenium и jsonwire-grid используют в своей архитектуре Selenium Node, а мы очень хотели этого избежать. К тому же Zalenium прекратили разрабатывать.
Moon выглядел неплохо, но это платное решение с закрытым исходным кодом. У него богатая функциональность: например, в конфигурации Moon можно указать список поддерживаемых браузеров, организовав единую точку входа для всех тестов (такой подход используют в Яндексе). Нам это не требовалось, так как мы делали по-другому — перед запуском тестов запускали Selenium Grid, настроенный на запуск определенной версии браузера, и после окончания тестов удаляли его.
В первую очередь мы хотели повысить стабильность тестовой инфраструктуры, поэтому новая функциональность нас не так интересовала. Тогда мы решили оценить, насколько сложно будет создать простое и надежное решение, которое бы удовлетворяло нашим потребностям.
Нужен ли свой «велосипед»?
Кодовая база Selenium Grid огромна. Но хорошая новость заключается в том, что писать такое же большое и сложное решение не нужно. Много кода в Selenium относится к работе с устаревшими версиями браузеров, а все популярные современные браузеры совместимы со стандартом W3C Webdriver.
В комплекте с каждым браузером идёт сервер, который предоставляет HTTP API (совместимый со стандартом W3C Webdriver) для управления этим браузером (дальше в тексте этот сервер будем называть просто веб-драйвером). Например, для Google Chrome это ChromeDriver, для Mozilla Firefox — geckodriver и т. д. Поэтому при написании своего решения не требуется делать полноценную реализацию стандарта W3C — она уже реализована в веб-драйвере.
Нам не требовалась единая точка входа для всех тестов, которая бы поддерживала запуск разных браузеров. Таким образом, мы отказались от логики обработки capabilities и решили запускать только один браузер определенной версии, указанной в конфигурации.
С учетом этих условий остается только 2 основные задачи — запуск/удаление браузеров и маршрутизация запросов до браузеров. Именно этим и занимается Callisto — open source решение, которое мы разработали. Для запуска/удаления браузеров мы написали небольшое приложение, используя готовую библиотеку для работы с Kubernetes, а за маршрутизацию запросов отвечает Nginx. Получилось простое и надежное решение.
Архитектура Callisto
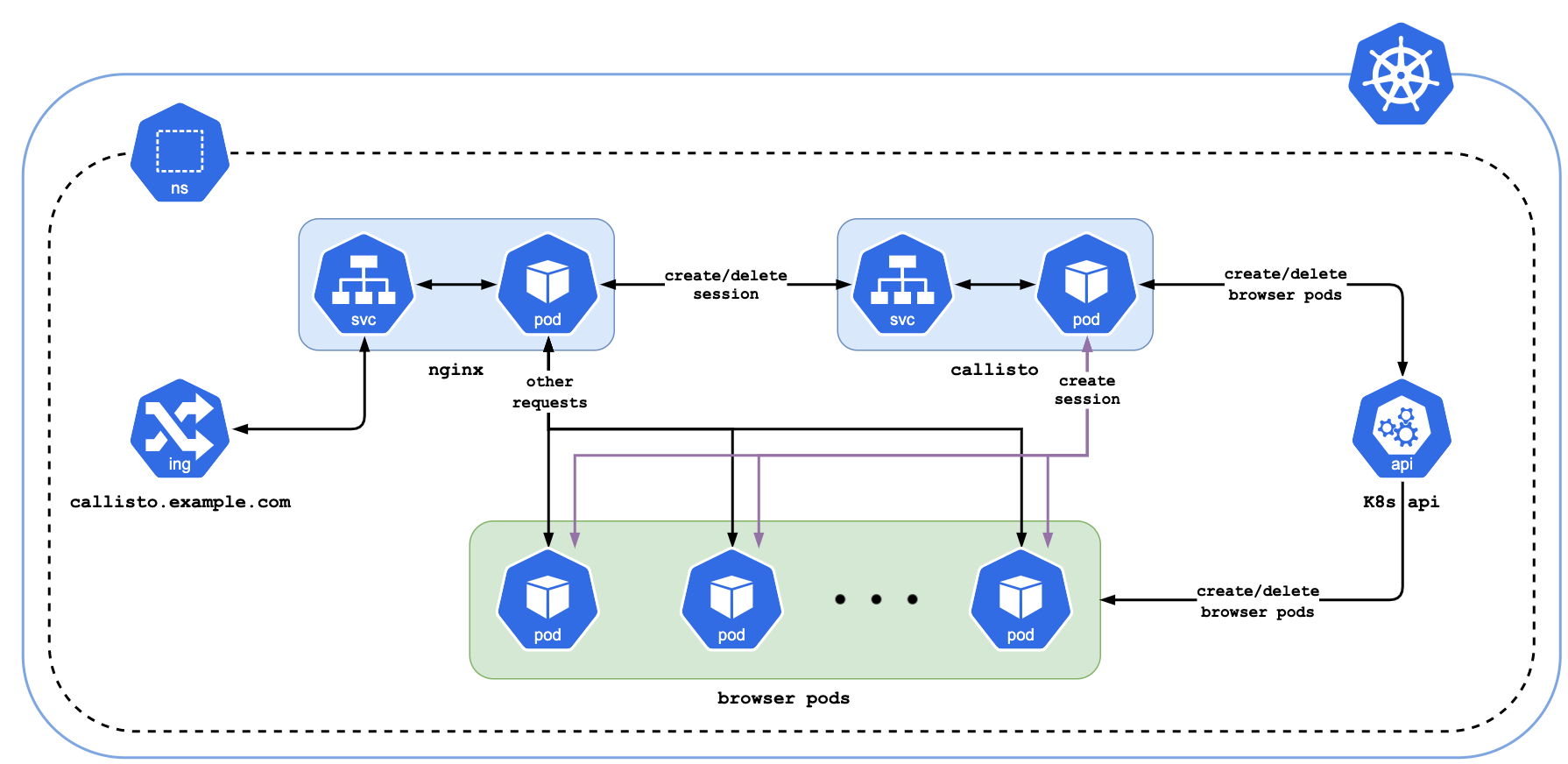
В архитектуре Callisto три основных компонента: Nginx, Callisto и pod’ы с браузером и веб-драйвером.
Nginx делит все запросы на 2 группы:
Запросы на создание/удаление сессии отправляет в Callisto.
Все остальные запросы отправляет напрямую веб-драйверу.
Callisto при получении запроса на создание сессии:
Создает pod с браузером и веб-драйвером.
Перенаправляет запрос на создание сессии веб-драйверу и возвращает ответ.
При получении запроса на удаление сессии:
Возвращает успешный ответ.
Удаляет pod с браузером.
В качестве Docker-образов с браузерами используются образы от Selenoid.
Маршрутизация запросов до браузеров
Важным моментом является маршрутизация запросов от тестов к нужному pod’у с браузером. Нужно где-то хранить соответствие между session_id, которое вернул веб-драйвер, и конкретным pod’ом. Первое, что приходит в голову — это хранение информации на стороне Callisto. Мы немного изучили этот вопрос и смогли найти более простое и изящное решение, благодаря которому Callisto остался stateless-решением.
Как это работает: после того, как веб-драйвер создал сессию, Callisto модифицирует поле session_id в ответе веб-драйвера, добавляя имя и ip-адрес pod’а, и после этого возвращает ответ тестам. Соответствие session_id — pod_ip хранится на стороне тестов.
Благодаря тому, что в стандарте W3C Webdriver session_id используется только в URL-ах, вторую часть обработки достаточно просто выполнить на стороне Nginx. Когда на Nginx приходит запрос, содержащий модифицированный session_id, он извлекает ip-адрес pod’а и оригинальный session_id и перенаправляет запрос этому pod’у с оригинальным значением session_id.
Примечание: имя pod’а Callisto использует при обработке запроса на удаление сессии.
Пример на картинке:

Дополнительные возможности Callisto
Web UI. В качестве Web UI используется Selenoid UI.
В Callisto поддерживается:
Отображение текущего статуса Selenium-сессий.
VNC.
Отображение логов веб-драйвера в реальном времени.
Таким образом можно удобно отлаживать тесты.
Примечание: поддерживаются не все функции Selenoid UI. Например, не работает ручное создание сессий и просмотр видеозаписей.
Мониторинг. Callisto экспортирует метрики в формате Prometheus: можно удобным образом наблюдать за состоянием Selenium-фермы.
Чистое окружение под каждый тест
Callisto, как и Selenoid, запускает свежий браузер под каждый тест. Таким образом исключается влияние тестов друг на друга. Практика показала, что это очень важно для стабильности тестовой инфраструктуры.
Платить за это приходится тем, что на создание каждой сессии уходит больше времени из-за создания pod’а и запуска веб-драйвера. Kubernetes-кластер также при этом испытывает заметную нагрузку при большом количестве параллельных тестов, что может выражаться в увеличении времени создания pod’ов.
Время создания pod’а с браузером сильно зависит от используемой инфраструктуры, но ориентироваться можно на ~10 секунд (может занимать до 2-х минут, если в Kubernetes-кластере включен автоскейлинг).
С какими проблемами мы столкнулись при разработке Callisto
Кодовая база Callisto небольшая — меньше 2000 строк кода. Рассказ о решении был бы неполным без описания проблем, с которыми мы столкнулись при его разработке. На их решение мы потратили больше времени и сил, чем на саму разработку. Надеемся, что для кого-то из читателей эта информация окажется полезной.
499-е ошибки на Nginx. В логах Nginx периодически попадались 499-е ошибки. Они воспроизводились нестабильно: при максимальной нагрузке на Kubernetes-кластер (в середине рабочего дня) их было больше, а утром и вечером они практически не появлялись. При этом на стороне тестов ошибка проявлялась как “Server disconnected error”.
Nginx считал, что проблема на стороне клиента, а тесты считали, что проблема на стороне сервера.
В результате исследований мы выяснили, что причина в некорректном значении параметра worker-shutdown-timeout. Его увеличение с 10 секунд (значение по-умолчанию) до 120 секунд помогло решить проблему.
Примечание: в ingress-nginx версии 0.26.0 значение по-умолчанию для этого параметра было увеличено с 10 до 240 секунд.
Медленное создание сервисов. При первоначальной реализации мы создавали Kubernetes-сервис для каждого pod’а с браузером, при этом имя сервиса соответствовало session_id.
Такое решение является более простым — не требуется модифицировать session_id, имя сервиса можно использовать как доменное имя, при этом конфигурация Nginx выглядит очень просто.
При проведении нагрузочных тестов мы столкнулись с проблемой: создание сервисов начинает выполняться очень медленно при росте нагрузки на кластер (мы проверяли на GKE 1.12):
Так как мы хотели запускать 1000+ тестов параллельно в одном кластере, такое положение дел нас не устраивало. Мы пришли к решению с модификацией session_id, которое описано в разделе про маршрутизацию запросов до браузеров.
Примечание: время создания pod’ов с ростом нагрузки на кластер увеличивалось совсем незначительно, поэтому отказ от сервисов решил проблему.
Медленные ответы от Kubernetes-API. При 100 параллельных тестах Kubernetes-API отвечал довольно быстро, но при дальнейшем увеличении нагрузки время ответа составляло уже единицы секунд, что заметно сказывалось на общей производительности. При профилировании мы обнаружили, что количество запросов от Callisto к Kubernetes-API росло экспоненциально с увеличением количества тестов. Мы быстро нашли ошибку в коде и исправили ее.
Медленное создание pod’ов с браузерами. Нам удалось достичь приемлемого времени создания/удаления pod’ов при одновременно бегущих ~500 тестах. Но нам требовалось обслуживать больше 1000 параллельных тестов.
Проблема решилась при обновлении GKE кластера с версии 1.12 до 1.14. В версии 1.14 время создания pod’ов не превышало 10 секунд при более чем 2000 параллельно бегущих тестах.
504-е ошибки на Nginx. Некоторое количество тестов падало из-за того, что Nginx возвращал 504-ую ошибку. Проблема оказалась в том, что мы использовали Preemptible VMs. Когда Google забирал VM, все запросы к pod’ам на этой VM падали по таймауту, что и приводило к данной ошибке.
В итоге мы настроили таймауты на стороне Nginx (чтобы такие запросы не висели долго) и добавили обработку этой ошибки на стороне тестов: при ее возникновении тест перезапускается.
Результаты внедрения Callisto
У нас получилось сделать простое и надежное решение, которое позволило значительно повысить стабильность нашей тестовой инфраструктуры.
Кроме увеличения стабильности, оказалось, что при примерно том же количестве запускаемых тестов платить за GKE мы стали на 30-40% меньше. Такая экономия достигается за счет того, что Callisto более эффективно использует ресурсы кластера, запуская pod’ы только тогда, когда от тестов приходят запросы. При использовании Selenium Grid pod'ы с браузерами часть времени находятся в запущенном состоянии, ожидая нагрузку. Также каждому pod'у с браузером нужно меньше ресурсов, т.к. не используется Selenium Node.
Красной линией отмечен переход с Selenium Grid на Callisto:
Репозитории:
Мы каждый день используем Callisto, и его текущая функциональность нас устраивает. В данный момент мы не развиваем его активно, но готовы принимать пул-реквесты.
Будем рады ответить на вопросы и комментарии про наше решение.

gigimon
не совсем понял, а как вы запускаете браузеры? У вас в кластере несколько копий callisto с указанием разных браузеров? 1 callisto = 1 браузер?
vpokotilov Автор
Сначала запускаем Callisto, потом запускаем тесты, и сразу после окончания тестов удаляем Callisto — так для каждого запуска тестов.
Получается, что каждый запуск тестов использует только свой экземпляр Callisto (который настроен на запуск нужного именно этим тестам браузера).
Одновременно в кластере может быть запущено несколько копий Callisto.
На запуск самого Callisto уходит 20-30 секунд.
Да, тесты могут использовать только одну версию браузера после запуска. Если нужен другой бразуер, или другая версия того же браузера, то тесты надо перезапустить с другими настройками Callisto.
Каждый экземпляр Callisto может запустить параллельно неограниченное (в разумных пределах) количество браузеров, но все они будут одной версии.