

Привет, Хабр! Меня зовут Кирилл, я инженер по решениям в Cloudera, и сегодня мне выпала честь представлять всю команду, работающую с регионом СНГ. Мы очень рады, что наконец-то можем делиться полезными материалами и новинками мира больших данных с вами. В последнее время у нас появилось много нового, поэтому начиная писать эту статью волновались, как бы она не превратилась в неподъемный лонгрид. Постарались собрать ниже только самое основное и, к сожалению, в этой статье не будет много технической информации, но мы быстро это исправим.
Что новенького в Cloudera?
Пожалуй, начнём немного издалека для тех, кто не так активно следит за развитием проектов экосистемы Hadoop: компании Hortonworks и Cloudera объединились в 2019 году под общим названием Cloudera. С этого момента началась новая ветка в истории развития дистрибутива Hadoop, так как усилиями уже общей команды стартовала работа над новой сборкой, которая включила в себя всё лучшее из обоих миров. В 2019 году состоялся первый релиз нового дистрибутива Cloudera Data Platform (дальше - CDP), в который вошло более 50 лучших в своем классе инструментов с открытым исходным кодом для работы с большими данными.
Так что же такого интересного предлагает Cloudera Data Platform? В рамках платформы мы предоставляем корпоративное облако данных для данных любого типа, в любой инстраструктуре, от периферии до ИИ. CDP работает в различных средах: локальной, в частном и публичном облаке, или в гибридном варианте архитектуры.

Теперь более подробно о названиях всех вариантов дистрибутива. Версия для традиционной локальной инсталляции на железо называется CDP Private Cloud Base. Она является фундаментом для расширения локальной архитектуры до частного облака (поэтому и имеет такое название). Полноценная же архитектура частного облака, куда входит часть Base (уровень хранилища) и аналитические приложения на Kubernetes (уровень вычислений), называется CDP Private Cloud Plus/Max. С версией для публичных облаков всё проще - CDP Public Cloud. При этом это полноценный PaaS, тесно интегрированный с нативными сервисами большой тройки: AWS, Azure и GCP.
Благодаря единой панели управления, фреймворку Cloudera SDX (Shared Data Experience) и неизменному набору сервисов, работа с платформой выглядит одинаково, независимо от среды развёртывания, что позволяет реализовать полноценную гибридную архитектуру. При этом набор доступных сервисов позволяет работать с данными любого типа от периферии до ИИ с обеспечением безопасности корпоративного уровня (шифрование данных в пути и покое, полная керберизация кластера) и data governance:
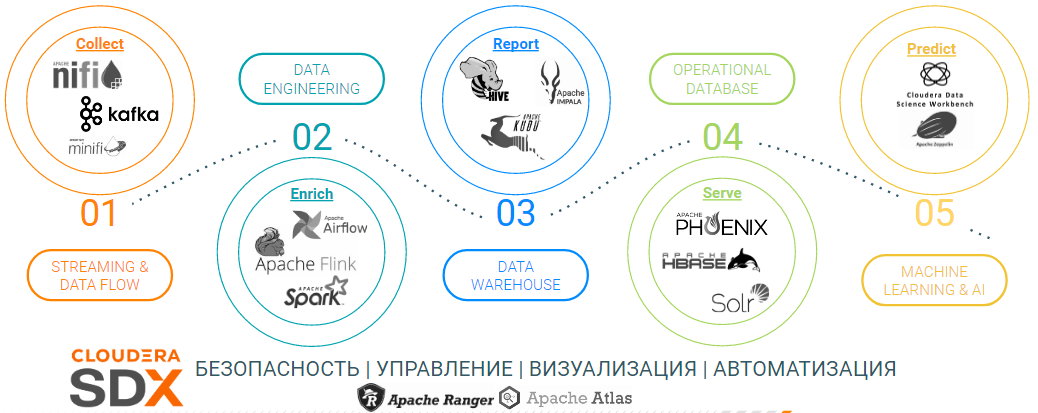
Также в самом наборе инструментов появились интересные новинки:
С декабря 2020 года для всех пользователей CDP стал доступен Spark 3.0, а добавление 3.1 запланировано на первую половину 2021.
В конце лета прошлого года в дистрибутив был добавлен доработанный и готовый к работе в продуктиве Apache Ozone - S3 совместимое объектное хранилище, своего рода преемник HDFS, который закрывает многие из его слабых мест и позволяет делать гораздо более плотные конфигурации узлов (мы тестировали 350TB на узел - стабильная работа всех нагрузок).
После приобретения компании Arcadia Data в стеке появился полноценный BI компонент Cloudera Data Visualization, работающий со всеми основными движками аналитики данных: Hive/Impala, Solr, Druid.
Приобретение компании Eventador в 2020 году позволило добавить функционал аналитики потоковых данных с помощью SQL на базе Flink - теперь с потоками данных из Кафка можно работать как со стандартными таблицами в СУБД и создавать материализованные представления для, например, передачи трансформированных потоков обратно в Кафку.
В начале этого года Cloudera объявила о включении проекта Apache Iceberg в дистрибутив, что позволит ещё более гибко работать с огромными наборами данных благодаря снапшотам, поддержке эволюции схемы и возможностям откатов к предыдущим версиям по времени.
Изначально архитектура частного облака поддерживалась только на базе платформы Red Hat OpenShift, но в ближайшее время выходит CDP Private Cloud Plus с поддержкой встроенного кубернетеса, что значительно упростит инсталляцию и ускорит внедрение гибридной архитектуры. Пользователи смогут быстрее начинать работу с данными, получат все преимущества облачной инфраструктуры, и при этом данные будут храниться в локальном ЦОДе.
Как вы можете видеть дистрибутив Hadoop от Cloudera активно развивается и эволюционирует, у нас большие планы на этот год. В конце хотели бы сразу ответить на пару вопросов, которые могли у вас появиться во время прочтения этой статьи.
Есть ли бесплатная версия дистрибутива, как это было раньше с HDP/CDH?
Выпуск бесплатной версии для коммерческого использования дистрибутива CDP не планируется. На данный момент можно скачать триальную версию с сайта или получить временную лицензию через аккаунт менеджера, а также рассматривается возможный выпуск версии для образовательных целей в будущем.
А что же со всеми любимыми сборками HDP/CDH?
Эти дистрибутивы не будут обновляться и постепенно заканчивают свой жизненный цикл поддержки (HDP2x/CDH5x уже закончили с концом 2020 года, такая же судьба настигнет HDP3/CDH6 в скором времени). Более того, репозитории даже этих версий уже не доступны для публичного доступа - для этого теперь также требуется лицензия.
В тексте упоминался ИИ, что платформа предлагает для работы с моделями МО кроме Zeppelin?
В дистрибутиве есть дополнительный компонент - Cloudera Machine Learning (также известный как Cloudera Data Science Workbench), отвечающий за организацию полного цикла работы над моделями МО. Это полноценная MLOps платформа на кубере с центральным репозиторием метаданных, версионированием моделей, возможностью совместной работы в любом IDE (Jupyter Lab/Notebook включён по умолчанию) и любыми библиотеками, безопасным соединением с основным кластером и возможностью внедрения готовых моделей как функций в бизнес-процессы через REST API.
Пожалуйста, оставляйте свои комментарии к статье, какие еще вопросы о наших продуктах и технологиях вам было бы интересно обсудить?


Cheypnow
"С декабря 2020 года для всех пользователей CDP стал доступен Spark 3.0, а добавление 3.1 запланировано на первую половину 2021."
Можно уточнить о какой конкретно версии идет речь? Релиз Spark 3.1.0 же отменили и вроде пока не ясно когда будет 3.1.1
Kiryl_Halozhyn
Все верно, тк 3.1.0 официально не будет, то речь идёт о 3.1.1. Версия у нас в дистрибутиве сейчас это 3.0.1. Мы планируем добавить 3.1.1 версию почти сразу после официального релиза вместе с коннекторами к Куду и Hbase, которые не успели выпустить с 3.0. Ходят слухи, что 3.1.1 будет в конце марта