

Введение и обоснование
Выпуск версии Cloudera Data Platform (CDP) Private Cloud Base означает появление гибридной облачной архитектуры следующего поколения. Ниже представлен обзор методов проектирования и развертывания кластеров («лучшие практики»), включая конфигурацию оборудования и операционной системы, а также руководство по организации сети и построению системы безопасности, интеграции с существующей корпоративной инфраструктурой.
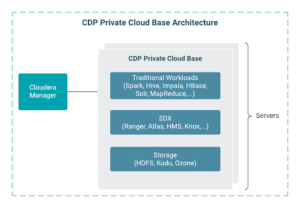
Обзор Private Cloud Base
CDP Private Cloud Base – локальная версия Cloudera Data Platform (то есть развертываемая на площадке заказчика), которая сочетает в себе все лучшее из Cloudera Enterprise Data Hub и Hortonworks Data Platform Enterprise, а также добавляет новые функции и улучшения во всем стеке. Этот унифицированный дистрибутив представляет собой масштабируемую и настраиваемую платформу, на которой вы можете безопасно запускать многие типы рабочих нагрузок.
Подробности и документацию можно найти по ссылке
Основные изменения
Прежде чем углубляться в передовой опыт и знакомиться с лучшими отраслевыми практиками, стоит остановиться на ключевых улучшениях, которые отличают CDP от прежних дистрибутивов. Этот дистрибутив включает:
Лучшее из CDH и HDP с добавленными аналитическими и платформенными функциями.
Уровень хранения для частного облака CDP, в том числе хранилище объектов.
Cloudera SDX для согласованной безопасности и управления в масштабе всей платформы.
Чтобы заказчики могли получить максимальную выгоду от этих функций, развертывать свои среды с гарантированным успехом и минимизировать риски, лучшие практики Cloudera отражают опыт развертывания у тысяч клиентов и тестирование релизов.
Рекомендуемые шаблоны развертывания
Экосистема программного обеспечения с открытым исходным кодом очень динамична и быстро меняется. Cloudera включает в регулярные выпуски продуктов, развертываемых Cloudera Manager в виде пакетов, улучшения функционала, исправления, касающиеся безопасности и производительности. Чтобы получать выгоду от этих постоянных усовершенствований, рекомендуется поддерживать согласованность с актуальными релизами платформы. Для проверки работы этих изменений в производственную среду можно затем использовать смежные среды тестирования и разработки. Тем, кто не может подключить Cloudera Manager напрямую или через прокси к репозиторию Cloudera, следует создать автономное зеркало репозитория. Также при внесении серьезных изменений нужно периодически и по мере возможности планировать отправку пакетов диагностики кластера и пользоваться новыми функциями поддержки, такими как предиктивные проверки состояния кластера на сайте.
Многие для единообразия и повторяемости предпочитают автоматизировать развертывание кластера. Недавно выпущенные коллекции Ansible предлагают шаблоны, которые включают описанные здесь передовые практики. Их можно скачать здесь.
Сборник содержит шаблоны для всех типовых ролей кластера и задач, использующих для упрощения реализации сборок и обеспечения безопасности Cloudera Manager API.
Назначение ролей
Типичный кластер содержит ряд ролей, которые потребуют определенной памяти, емкости, а иногда - сетевого подключения для оптимизации производительности и устойчивости. Вот эти роли:
Master (главный)
Узлы, которым присвоены роли «главных» (master), обычно управляют набором сервисов распределенного кластера. К ним относятся HDFS NameNode, менеджер ресурсов YARN, Impala Statestore, главный сервер HBase и мастер-сервер Kudu. Должно быть не менее трех главных узлов, на двух из которых будут HDFS NameNode и YARN RM. Все три требуют кворума узлов Zookeepers и HDFS Journal для отслеживания изменений метаданных HDFS, хранящихся на NN. Для достижения консенсуса большинства нужно минимум три узла. В кластерах из более 200 узлов, могут быть пять и более главных узлов.
Worker (рабочий)
Это узлы, которые выполняют большую часть вычислительных ресурсов и операций ввода-вывода, работают для поддержки соответствующих сервисов. HDFS DataNodes, YARN NodeManagers, HBase ReigonServers, Impala Daemons, Kudu Tablet Servers и Solr Servers - примеры рабочих ролей.
Edge/Gateway (граничный узел или шлюз)
Граничные узлы действуют как шлюз между остальной частью корпоративной сети и кластером CDP. Многие сервисы CDP Private Cloud поставляются с edge ролями. Они используются вместе с конечными точками для вызовов REST API и соединений типа JDBC/ODBC из корпоративной сети. Если вы разрешаете трафику корпоративной сети проходить только к этим узлам, в отличие от прямого доступа к «мастерам» и «рабочим», это часто упрощает защиту периметра сети.
Ingest (узел приема)
Обычно узлы приема работают по той же схеме, что и рабочие узлы. Ключевыми требованиями для них являются несколько выделенных дисков как для ролей брокера Kafka, так и для ролей Nifi. Размер диска Kafka требует отдельного обсуждения, однако количество выделенных дисков пропорционально предполагаемому объему хранимых данных и настройкам длительности хранения и/или требуемой пропускной способности тем сообщений с минимум 3 узлами-брокерами для обеспечения устойчивости.
Utility (служебный узел)
Служебные узлы содержат сервисы и службы, которые позволяют управлять кластером и контролировать его. К таким сервисам относятся Cloudera Manager (CM) и связанные с ним сервисы управления Cloudera (CMS), СУБД Hive metastore (если она также размещена в кластере), хранящая метаданные от имени различных сервисов и, возможно, настраиваемые сценарии администратора для резервного копирования, развертывания специальных двоичных файлов и многое другое.
Сеть
Нагруженные кластеры могут генерировать значительный сетевой трафик «восток-запад», поэтому рекомендуется разрешить агрегирование каналов LACP в сети «leaf-spine» с коммутаторами уровня распределения и уровня стойки (top-of-rack). Коэффициент переподписки - не более 1:4, в идеале – как минимум сетевые карты 2x10 Гбит/с или даже 2x25 Гбит/с для перспективных возможностей CDP Private Cloud Experiences и будущего разделения уровней хранилища и вычислений. Вообще говоря, несколько сетевых карт (multi-homing) не поддерживаются, и мы считаем, что для большинства архитектур Hadoop это не нужно, поскольку может привести к утечке значительного трафика Hadoop на неверные сетевые интерфейсы, нарушая функционирование непроизводственных сетей и влияя на производительность. Протокол IPV6 не поддерживается и должен быть отключен.
Для более крупных кластеров, распределенных по нескольким физическим стойкам, мы рекомендуем воспользоваться функциями CDP для получения информации о стойках. YARN пытается разместить вычислительную нагрузку в стойке рядом с данными, минимизируя сетевой трафик между стойками, а HDFS гарантирует, что каждый блок реплицируется на несколько стоек.
По периметру кластера устанавливают межсетевые экраны, поэтому объем сетевого трафика и число портов, используемых для внутрикластерной связи, будет значительным. Многие службы, такие как Spark, будут использовать динамические порты, чтобы роли мастера приложений, такие как драйвер Spark, могли управлять исполнителями, выполняющими работу. Внешние сервисы, такие как роли Hue и Hive on Tez (HS2), могут быть в большей степени ограничены определенными портами и сбалансированы по нагрузке, если это необходимо для обеспечения высокой доступности.
Cloudera поддерживает работу кластеров частного облака CDP с SELinux в режиме разрешения (permissive mode), однако Cloudera не предоставляет конфигурации политик SELinux для включения принудительного режима (enforcing mode). Если заказчику требуется принудительное выполнение SELinux, то необходимо самостоятельно протестировать и реализовать политики. Учитывая сложность платформы, Cloudera рекомендует придерживаться разрешающего режима или полностью отключить SELinux.
Ознакомьтесь с полными требованиями к сети и безопасности.
Диски операционной системы
Обычно операционную систему устанавливают на пару зеркалируемых дисков емкостью 4 ТБ или более, которые можно разделить с помощью диспетчера логических томов, обеспечивая достаточную емкость для журналов (логов) и временных файлов. Следует отметить, что файловая система /tmp и требования к логам могут быть значительными, и нужно предусмотреть достаточную емкость. Кроме того, мы также рекомендуем отключить Transparent Huge Pages (THP), настроенный демон и свести к минимуму подкачку (свопинг).
Поддерживаются файловые системы ext3, ext4 и XFS. Обычно XFS v5 используют для каталогов данных. Как правило, они монтируются как напрямую подключенные диски JBOD, чтобы максимально увеличить производительность ввода-вывода для HDFS в формате / data1, / data2, dataN для каждого соответствующего диска с данными. Обычно используют 12-24 диска емкостью 4–8 ТБ с максимальной емкостью 100 ТБ на каждый узел. Схема доступа к диску для мастер-сервисов несколько отличается от выделенных дисков, рекомендованных для узлов журнала Zookeeper и HDFS, и какого-нибудь отказоустойчивого хранилища, например, RAID 5 или 10 для каталогов HDFS NameNode. Чтобы повысить производительность чтения, диски следует монтировать как noatime. Полная информация о требованиях к оборудованию приведена в руководстве по релизу.
CDP особенно чувствительна к разрешению имен хостов, поэтому очень важно, чтобы DNS-серверы были правильно настроены, а имена хостов были полностью квалифицированными. Часы также должны быть синхронизированы. Демон кэширования службы имен может помочь в больших кластерах, предоставляя локальный кэш для общих запросов службы имен, таких как группы паролей и хосты.
Поддерживающие инфраструктурные сервисы
Для Hive, Atlas, Ranger, Cloudera Manager, Hue и Oozie требуется реляционная СУБД. Их следует развертывать с учетом как устойчивости работы, так и производительности, поскольку неэффективная база данных будет негативно влиять на производительность кластера.
Интеграция средств безопасности
Безопасность кластера требует отдельного обсуждения, однако для интеграции базовых средств безопасности кластеру потребуется разрешение пользователей и группы через корпоративный каталог. Службы аутентификации и каталогов обычно реализуются с помощью комбинации Kerberos и LDAP, что можно считать преимуществом, поскольку упрощает управление паролями и пользователями при интеграции с существующими корпоративными системами, такими как Active Directory.
Kerberos используется в качестве основного метода проверки подлинности для служб кластера, состоящих из отдельных ролей узла, а также, как правило, для приложений. Корпоративные кластеры будут использовать существующий корпоративный каталог, такой как Microsoft Active Directory, для создания этих участников Kerberos и управления ими. Кроме того, конечную точку аутентификации для кластерных REST API и пользовательских интерфейсов, поддерживающих LDAP и SAML, предоставляет Apache Knox.
Авторизация
Apache Ranger предоставляет ключевую структуру политики, определяющую права доступа пользователей к ресурсам. Администраторы могут определять политики безопасности на уровне базы данных, таблицы, столбца и файла, а также управлять разрешениями для определенных групп, ролей или отдельных пользователей на основе LDAP. Также можно определить политики потока данных и потоковой передачи (NiFi, Kafka и т. Д.).
Apache Ranger позволяет поддерживать авторизацию через членство в корпоративной группе с помощью таких инструментов, как sssd или Centrify, синхронизировать права доступа к сервисам и данным с корпоративным каталогом. Затем эта авторизация периодически синхронизируется с соответствующими объектами Hive.
Для надежной аутентификации, целостности и конфиденциальности в сети коммуникации между службами кластера шифруются с использованием TLS 1.2. Cloudera Manager упрощает управление сертификатами TLS с помощью функции AutoTLS, которая позволяет администраторам определять и развертывать полностью интегрированную схему инфраструктуры открытых ключей (Public Key Infrastructure, PKI).
Заключение
Надеемся, что вы получили некоторое представление о настройке ресурсов хоста, о том, как добиться максимальной производительности и безопасности вашего кластера. Во второй части этой серии публикаций мы более подробно рассмотрим, как управлять, отслеживать и настраивать приложения.