
Думаю, ни для кого не секрет, что в разговорах опытных разработчиков Python, и не только, часто проскальзывают фразы о том, что Django это зло, что в Django плохая архитектура и на ней невозможно написать большой проект без боли. Часто даже средний Django проект сложно поддерживать и расширять. Предлагаю разобраться, почему так происходит и что с Django проектами не так.
Немного теории
Когда мы начинаем изучать Django без опыта из других языков и фреймворков, помимо документации мы читаем туториалы, статьи, книги, и почти во всех видим что-то подобное:
Django — это фреймворк, использующий шаблон проектирования Model-View-Controller (MVC).
И дальше куча неточных схем и объяснений о том, что такое MVC. Почему они неточные и что с ними не так, можно посмотреть здесь или здесь.
Обычно в таких схемах MVC описывают подобным образом:
Model — доступ к хранилищу данных
View — это интерфейс, с которым взаимодействует пользователь
Controller — некий связывающий объект между model и view.
Данные распространенные схемы только запутывают и мешают, когда вы хотите написать приложение, в котором есть бизнес-логика.
Стоит обратить внимание на две вещи.
Первое, часто под M в MVC подразумевают — модель данных, и говорят, что это некий класс, который отвечает за предоставление доступа к базе данных. Что неверно, и не соответствует классическому MVC и его потомкам MV*. В классическом MVC под M подразумевается domain model — объектная модель домена, объединяющая данные и поведение. Если говорить точнее, то M в MVC это интерфейс к доменной модели, так как domain model это некий слой объектов, описывающий различные стороны определенной области бизнеса. Где одни объекты призваны имитировать элементы данных, которыми оперируют в этой области, а другие должны формализовать те или иные бизнес-правила.
Второе, в Django нет выделенного слоя controller, и когда вам говорят, что в Django слой views — это контроллер, не верьте этим людям. Обратитесь к официальной документации, а точнее к FAQ, тогда можно увидеть, что этот слой вписывается в принципы слоя View в MVC, особенно, если рассматривать DRF, а как такового слоя Controller в Django нет. Как говорится в FAQ, если вам очень хочется аббревиатур, то можно использовать в контексте Django аббревиатуру MTV (Model, Template, and View). Если очень хочется рассматривать Web MVC и сравнивать Django с другими фреймворками, то для простоты можно считать view контроллером.
Несмотря на то, что Django не соответствует MVC аббревиатуре, в ней реализуется главный смысл MVC — отделение бизнес-логики от логики представления данных. Но на практике это не всегда так по нескольким причинам, которые мы рассмотрим ниже.
Перейдем к практике
Выделим в Django приложениях несколько слоев, которые есть в каждом туториале и почти в каждом проекте:
front-end/templates
serializers/forms
views
models
Не будем рассматривать каждый слой подробно, это все можно найти в документации. В основном будем рассматривать Django c использованием DRF. Попробуем разобрать на двух простых кейсах, что стоит помещать в каждом из слоев и какая ответственность у каждого слоя.
Первый кейс — создание заказа. При создании заказа нам нужно:
проверить валидность заказа и доступность товаров
создать заказ
зарезервировать товар на складе
передать заявку менеджеру
оповестить пользователя о том, что его заказ принят в работу
Второй кейс — просмотр списка моих заказов. Здесь все просто, мы должны показать пользователю список его заказов:
получить список заказов пользователя
Слой serializers/forms
У слоя serializers три основные функции (все выводы для serializers справедливы и для forms):
валидировать данные
преобразовывать данные запроса в типы данных Python
преобразовывать сложные Python объекты в простые типы данных Python (например, Django модели в dict)
Дополнительно сериалайзеры имеют два метода, create и update, которые вызываются в методе save() и почти всегда используются во view.
Пример использования из документации:
class CommentSerializer(serializers.Serializer):
email = serializers.EmailField()
content = serializers.CharField(max_length=200)
created = serializers.DateTimeField()
def create(self, validated_data):
return Comment.objects.create(**validated_data)
def update(self, instance, validated_data):
instance.email = validated_data.get('email', instance.email)
instance.content = validated_data.get('content', instance.content)
instance.created = validated_data.get('created', instance.created)
instance.save()
return instanceГде-то в нашей view:
# .save() will create a new instance.
serializer = CommentSerializer(data=data)
# .save() will update the existing `comment` instance.
serializer = CommentSerializer(comment, data=data)
comment = serializer.save()В данном подходе за сохранение и обновление сущностей отвечает сериалайзер, точнее он оперирует методами модели.
Можно использовать ModelSerializer и ModelViewSet, что позволяет писать CRUD методы в пару-тройку строк.
# serializers.py
class OrderSerializer(serializers.ModelSerializer):
class Meta:
model = Order
fields = ‘__all__’
# views.py
class OrderViewsSet(viewsets.ModelViewSet):
queryset = Order.objects.all()
serializer_class = OrderSerializer
Если углубиться в реализацию ModelViewSet и ModelSerializer, то можно заметить, что за сохранение и обновление сущностей также отвечает сериалайзер.
В таком случае, кажется, что переопределение create отличное место для того, чтобы описать там все бизнес-процессы и правила создания заказа.
# serializers.py
class OrderSerializer(serializers.ModelSerializer):
class Meta:
model = Order
fields = []
def create(self, validated_data):
# Проверяем, что все товары есть и заказ валиден
...
# Создаем запись о заказе в БД
instance = super(OrderSerializer, self).create(validated_data)
# Бронируем товары на складе
...
# Передаем заявку менеджеру
...
# Оповещаем пользователя
...
return instance
# views.py
class OrderViewsSet(viewsets.ModelViewSet):
queryset = Order.objects.all()
serializer_class = OrderSerializerЕсли с методом создания мы что-то придумали, то логику получения заказов пользователя придется помещать в view.
Получается такая схема:
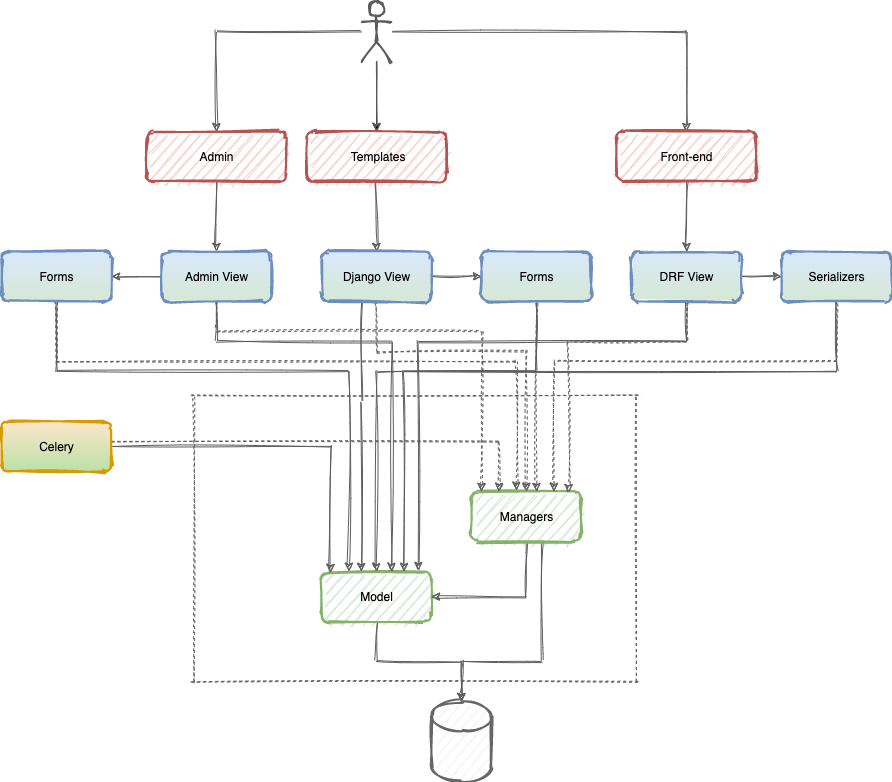
Плюсы данного подхода:
Легко делать CRUD
Django и DRF предоставляют очень удобные инструменты с помощью которых можно легко создавать CRUD.
Минусы данного подхода:
Нарушение идей MVC
Мы смешиваем бизнес-логику с задачей сериализации (получения/отображения) данных в одном слое. Ни о каком выделенном слое бизнес-логики у нас нет и речи.
Сериалайзеры стоит относить к слою View в MVC в контексте Django. Когда мы располагаем в сериалайзерах свою бизнес логику, мы нарушаем главный принцип MVC — отделение логики представления данных от бизнес-логики.
Нельзя переиспользовать
Не получится переиспользовать логику одного сериалайзера в другом сериалайзере, или в каком-то другом компоненте.
Сложно тестировать
Сложно протестировать бизнес-логику независимо от логики сериализации и валидации данных.
Сложно поддерживать
Остается открытым вопрос — куда помещать методы на чтение данных, можно перенести их в слой views.Не все правила бизнес-логики можно поместить в сериалайзеры, иногда это излишне, потому что мы не используем сами сериалайзеры.
В итоге мы получаем разбросанные бизнес-правила по всему проекту, которые невозможно переиспользовать и очень сложно поддерживать.
Высокая зависимость от фреймворка
Высокая зависимость от DRF Serializers или Django Forms. Если мы захотим поменять способ сериализации и отказаться от serializers, то придется переносить или переписывать нашу логику. Также будет сложно переехать с Django Forms на DRF Serializers или наоборот.
Правильные обязанности слоя
Сериализация/десериализация данных
Сериалайзер хорошо умеет сериализовывать данные, для этого его и нужно использовать.
Валидация данных
Без написания кастомных валидаторов. Если вам требуется написать кастомный валидатор, то, скорее всего, это бизнес-правило, и данную проверку лучше вынести в слой с бизнес-логикой (где бы он ни был).
Заключение
Сериалайзеры точно не подходят для написания в них бизнес-логики. Если вам нужно что-то большее, чем CRUD, то стоит отказаться от использования метода save у сериалайзеров, так как сохранение данных не должно входить в их обязанности.
Стоит отказаться от ModelSerializer с его магическими методами create и update и заменить их на обычные сериалайзеры (можно использовать ModelSerializer как read only — для удобства). Если вы пишете какое-то простое приложение, где кроме CRUD ничего не нужно, то можно не отказываться от удобства DRF и использовать сериалайзеры как предлагается в документации.
Слой Views
Слой View в контексте Django отвечает за представление и обработку пользовательских данных, в нем мы описываем, какие данные нам нужны и как мы хотим их представить. Если вспомнить то, о чем мы говорили в начале, то можно сразу сделать вывод, что во views не нужно писать бизнес-логику, иначе мы смешиваем логику представления данных с бизнес-логикой. Даже если считать, что views в Django это контроллеры, то размещать в них бизнес-логику тоже не стоит, иначе у вас получатся ТТУКи («Толстые, тупые, уродливые контроллеры»; Fat Stupid Ugly Controllers).
Но часто можно увидеть что-то подобное:
# views.py
class OrderViewsSet(viewsets.ModelViewSet):
queryset = Order.objects.all()
serializer_class = OrderSerializer
def perform_create(self, serializer):
# Проверяем, что все товары есть и заказ валиден
...
# Создаем запись о заказе в БД
super(OrderViewsSet, self).perform_create(serializer)
# Бронируем товары на складе
...
# Передаем заявку менеджеру
...
# Оповещаем пользователя
...По дефолту, в ModelViewSet для сохранения и обновления данных используется сериалайзер, что не входит в его обязанности. Это можно исправить, полностью переопределить метод perform_create (не вызывать super, но тогда встает вопрос об объективности наследования от ModelViewSet). Можно написать кастомные методы в ModelViewSet или написать кастомные APIView:
# views.py
class OrderCreateApi(views.APIView):
class InputSerializer(serializers.ModelSerializer):
number = serializers.IntegerField()
...
def post(self, request):
serializer = self.InputSerializer(data=request.data)
serializer.is_valid(raise_exception=True)
# Проверяем, что все товары есть и заказ валиден
...
# Создаем запись о заказе в БД
order = Order.objects.create(**serializer.validated_data)
# Бронируем товары на складе
...
# Передаем заявку менеджеру
...
# Оповещаем пользователя
...
return Response(status=status.HTTP_201_CREATED)
В отличии от слоя serializers, мы теперь легко можем поместить нашу логику получения заказов в слой views.
# views.py
class OrderViewsSet(viewsets.ModelViewSet):
queryset = Order.objects.all()
serializer_class = OrderSerializer
def get_queryset(self):
queryset = super(OrderViewsSet, self).get_queryset()
queryset = queryset.filter(user=self.request.user)
return querysetТем самым, ограничив не только получение списка, но и другие методы CRUD, что, иногда, очень удобно и быстро. Также, можно переопределить каждый метод по отдельности.
Получается такая схема:
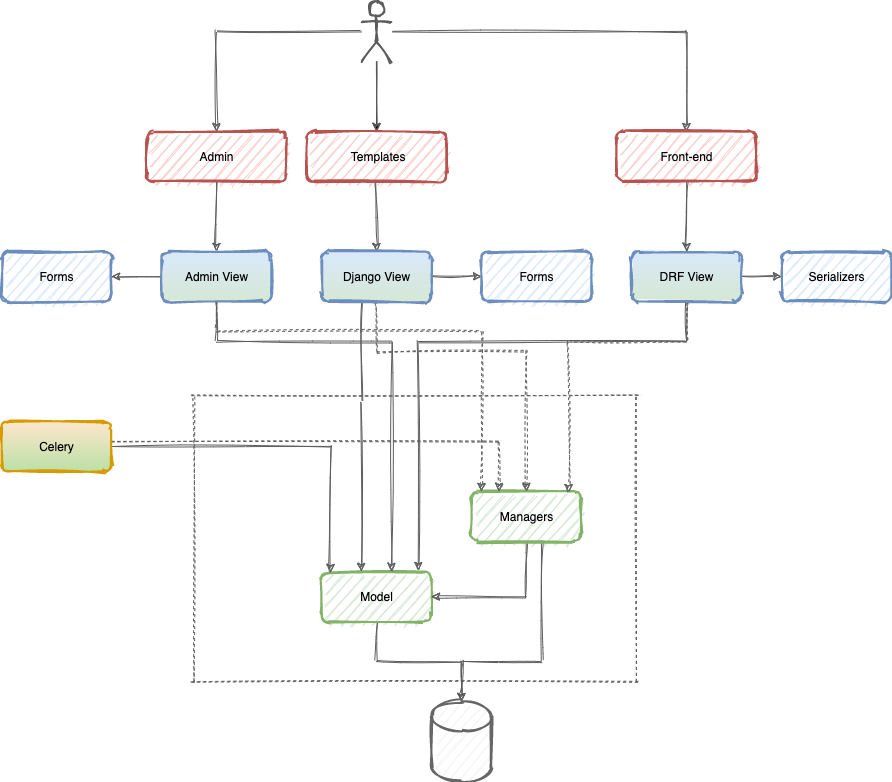
Стоит помнить, что мы отказались от использования save у serializers. В таком случае слой serializers остается “чистым” и выполняет только “правильные” обязанности.
Плюсы данного подхода
Легко делать CRUD
Django и DRF предоставляют очень удобные инструменты, с помощью которых можно легко создавать CRUD и views не исключение.
Минусы данного подхода
Нарушение идей MVC
Мы смешиваем в одном слое логику представления данных и бизнес-логику приложения.
Нельзя переиспользовать
Не получится переиспользовать логику одной view в другой view, или в каком-то другом компоненте. Так же будут проблемы, если мы захотим вызывать нашу бизнес-логику из других интерфейсов, например, из Celery задач.
Высокая зависимость от фреймворка
Высокая зависимость от DRF View или Django View. Если мы захотим поменять способ обработки запроса и отказаться от views, то придется переносить или переписывать нашу логику. Будет сложно переехать с Django View на DRF View или наоборот.
Сложно тестировать
Достаточно сложно протестировать код во views независимо от serializers и остальной инфраструктуры Django + придется использовать http client для тестирования.
Сложно поддерживать
Со временем views разрастаются, часть логики переносится в Celery задачи, часть в модели, код во views дублируется, так как их нельзя переиспользовать — все это приводит к тому, что проект сложно поддерживать.
Правильные обязанности слоя
Обработка запроса
Во view мы принимаем и обрабатываем запрос клиента, подготавливаем данные для передачи в бизнес-логику.
Делегирование сериализации данных сериалайзерам
Всю логику сериализации данных должны выполнять сериалайзеры.
Вызов методов бизнес-логики
После подготовки и сериализации данных вызывается интерфейс бизнес-логики.
Логика представления данных
Мы должны обработать ответ от методов бизнес-логики и предоставить нужные данные клиенту.
Заключение
Вывод примерно такой же как и с serializers — в views не стоит размещать бизнес-логику.
Стоит отказаться от ModelViewSet и миксинов, так как они используют сериалайзеры для сохранения данных, вместо этого использовать обычные APIView или GenericAPIView.
Если вам нужен только CRUD, то можно использовать подход который предоставляет ModelViewSet и не усложнять себе жизнь.
Слой models
Если опираться на более продвинутые туториалы или вспомнить слой Model в MVC, то кажется, что models отличное место для размещения бизнес-логики.
Это может выглядеть примерно так:
# models.py
class Order(models.Model):
number = serializers.IntegerField()
created = models.DateTimeField(auto_now_add=True)
status = models.CharField(max_length=16)
def update_status(self, status: str) -> None:
self.status = status
self.save(update_fields=('status',))
...
@classmethod
def create(cls, data...):
instance = cls(...)
# Проверяем, что все товары есть и заказ валиден
...
# Создаем запись о заказе в БД
instance = instance.save()
# Бронируем товары на складе
...
# Передаем заявку менеджеру (например на почту или создаем какую то запись в БД)
...
# Оповещаем пользователя
...
# views.py
class OrderCreateApi(views.APIView):
class InputSerializer(serializers.ModelSerializer):
number = serializers.IntegerField()
...
def post(self, request):
serializer = self.InputSerializer(data=request.data)
serializer.is_valid(raise_exception=True)
Order.create(**serializer.validated_data)
return Response(status=status.HTTP_201_CREATED)
В view мы сериализуем данные с помощью serializer и вызываем метод создания заказа у класса модели. В данном случае мы реализовали classmethod, что бы не было необходимости создавать экземпляр модели. Иначе нам придется понимать какие данные относятся к полям модели, а какие мы должны передать в метод создания, а это уже некие бизнес- правила.
Стоит заметить, что не нужно писать бизнес-логику в методе save(), так как это базовый метод модели и он может неоднократно использоваться в различных частях кода.
Для методов получения данных в таком случае стоит использовать Managers.
# views.py
class OrderListApi(views.APIView):
class OutputSerializer(serializers.ModelSerializer):
class Meta:
model = Order
fields = ‘__all__’
def get(self, request):
orders = Order.objects.filter(user=request.user)
# если у вас сложные условия фильтрации
# например, Order.objects.filter(user=request.user, is_deleted=False, is_archived=False...)
# то стоит написать кастомные методы в Manager
data = self.OutputSerializer(orders, many=True).data
return Response(data)Получается такая схема:

В данном случае слои serializers и views становятся “чистыми” и правила бизнес-логики концентрируются в одном слое.
Плюсы данного подхода
Следование идеям MVC
Мы отделили логику представления данных от логики предметной области. View только подготавливает данные и вызывает методы модели, все бизнес правила и процессы описаны в методах модели. Данный подход соответствует главной идее MVC.
Легко тестировать
Вся бизнес-логика собрана в одном слое, который не зависит от других слоев, например, от views или serializers. Каждый метод модели можно протестировать по отдельности как обычный python код. Остается только замокать метод save и базовые методы managers или использовать базу данных, если требуется.
Можно переиспользовать
Методы модели можно вызывать из любого компонента, DRF Views, Django Views, Celery задачи и т.д.
Минусы данного подхода
Зависимость от фреймворка
У нас все еще есть зависимость от фреймворка, но это не так критично. Так как отказ от Django models и ORM или их замена — очень редкий кейс.
Сложно поддерживать большие проекты
В больших проектах много бизнес-правил и если все их описывать в одном классе модели, то модель разрастается и превращается в божественный объект, который сложно читать и поддерживать. Сложно масштабировать и разделять код по файлам, так как мы ограничены требованиями фреймворка. Непонятно, куда помещать методы, которые оперируют несколькими моделями, возможно, из разных модулей.
Усложнение CRUD проектов
Если вам нужен только CRUD, то данный подход увеличивает время разработки и не приносит плюсов.
Заключение
Мы не нарушили главных идей MVC и наш код соответствует им. Такой подход можно использовать в малых проектах, когда бизнес-логики не много и она умещается в классах моделей.
Слой Services
Мы перебрали все дефолтные слои в Django приложении, теперь можем вспомнить о том, что под слоем Model в MVC подразумевается не один объект, а набор объектов.
Выделим отдельный сервисный слой services внутри слоя Model, который будет отвечать за бизнес-правила предметной области и приложения. В models оставить только простые property, в которых нет сложных бизнес-правил, и методы для работы с собственными данными модели, например обновление полей. Тогда наши кейсы можно реализовать так:
# models.py
class Order(models.Model):
number = serializers.IntegerField()
created = models.DateTimeField(auto_now_add=True)
status = models.CharField(max_length=16)
def update_status(self, status: str) -> None:
self.status = status
self.save(update_fields=('status',))
...
# services.py
# вместо пречесления всех аргументов можно реализовать DTO
def order_create(name: str, number: int ...) -> bool:
# Проверяем, что все товары есть и заказ валиден
...
# Создаем запись о заказе в БД
order = Order.objects.create(...)
# Бронируем товары на складе
...
# Передаем заявку менеджеру (например на почту или создаем какую то запись в БД)
...
# Оповещаем пользователя
...
# views.py
class OrderCreateApi(views.APIView):
class InputSerializer(serializers.ModelSerializer):
number = serializers.IntegerField()
...
def post(self, request):
serializer = self.InputSerializer(data=request.data)
serializer.is_valid(raise_exception=True)
services.order_create(**serializer.validated_data)
return Response(status=status.HTTP_201_CREATED)Стоит придерживаться следующему подходу:
views — подготовка данных запроса, вызов бизнес логики, подготовка ответа
serializers — сериализация данных, простая валидация
services — простые функции с бизнес правилами или классы (Service Objects)
managers — содержит в себе правила работы с данными (доступ к данным)
models — единственный окончательный источник правды о анных
Получение заказов пользователя:
# services.py
def order_get_by_user(user: User) -> Iterable[Order]:
return Order.objects.filter(user=user)
# views.py
class OrderListApi(views.APIView):
class OutputSerializer(serializers.ModelSerializer):
class Meta:
model = Order
fields = ('id', 'number', ...)
def get(self, request):
orders = services.order_get_by_user(user=request.user)
data = self.OutputSerializer(orders, many=True).data
return Response(data)Получается такая схема:

Плюсы данного подхода
Следование идеям MVC
Как и в предыдущем подходе, мы полностью отделили бизнес-логику от логики представления.
Легко тестировать
Сервисы представляют собой простые Python функции, которые легко тестировать.
Можно переиспользовать
Мы можем вызывать наши сервисы из любого компонента + можем повторно использовать какие-то сервисы в других проектах.
Легко поддерживать и расширять
В данном подходе выделен отдельный слой под бизнес-логику и логику приложения, при росте проекта сервисы можно декомпозировать и расширять.
Гибкость
Существует множество подходов написания и расширения сервисного слоя.
Минусы данного подхода
Зависимость от фреймворка
Доменный слой не отделен от слоя приложения и инфраструктуры. Мы все еще используем Django модели в качестве сущностей. У нас могут возникнуть проблемы, когда мы захотим отказаться от Django ORM, но это очень редкий кейс и для многих проектов неактуален.
Усложнение CRUD проектов
Если вам нужен только CRUD, то данный подход увеличивает время разработки и не приносит плюсов.
Заключение
Данный подход удобно использовать в проектах различной сложности и размера. В проекте понятна структура, каждый слой и компонент имеет свою ответственность и не нарушает ее границы. Сервисы легко декомпозировать и отделять друг от друга, в более сложных случаях их можно объединять за фасадами.
На самом деле, каким может быть сервисный слой и как его лучше выделять и разделять это тема отдельной статьи и даже книги, об этом много пишут Мартин Фаулер, Роберт Мартин и другие.
Что касается Django, советую обратить внимание на стайл гайд от HackSoftware у них схожие взгляды, но они разделяют сервисный слой на два компонента (services и selectors) и не используют кастомные методы в managers. Подход написания serializers и включения их во views я взял у них. Также стоит посмотреть на идеи ребят из dry-python.
Общий итог
Получается, что поддерживаемость и “чистота” Django проектов страдает от удобства и плюшек фреймворка. Django и DRF очень классные инструменты, но не все их возможности стоит использовать. Можно сделать вывод, что, чем больше ваш проект и чем сложнее в нем бизнес-правила и сущности, тем более абстрактным и независимым от фреймворка должен быть ваш код. И выделение сервисного слоя — это далеко не предел и не идеал архитектуры приложения.

Magikan
Нету хороших или плохих фреймворков — вы просто не умеете их готовить.
Вообще прочитал статью по диагонали и зерно здравого смысла в словах автора имеется, однако если капнуть чуть поглубже то:
1- во вьюхах не должно быть обращений к бд, только валиадция, сериализация и десериализация
2- дрф хоть и позволяет делать crud легко и быстро, но так же оно размазывает бизнес логику по разным уровням приложения. Если следить очень, очень, реально очень внимательно за кодом — не проблема, но шаг в сторону и привет макароны.
3- логика в моделях. Этим страдают всякие django-fsm тут даже говорить не о чем.
Автору могу посоветовать познакомиться и внимательно изучить паттерн репозиторий решает если не все, то большинство из описанных выше проблем в тч и какие-то проблемы из самой статьи.
Если оч коротко, то
вьюха принимает запрос и отдает ответ.
Дрф только валидирует запрос, (де)сериализует
Модель — тупо описание схемы бд (близко по смыслу sqlalchemy.Table)
Слой общения с бд (тот самый репозиторий)
И слой бизнес логики — по сути функция с параметрами которая принимает на вход какие-то параметры согласно контрактам (интерфейсам), общается репозиторием, и отдает какой-то результат согласно контрактам. Вызывать ее можно хоть от куда угодно.
Схему рисовать не буду, лень)
Jsty
Возможно, глупый вопрос.
Предположим, сервис меняет данные в БД.
Есть два варианта:
1. Сервис принимает модель объекта (которую из get_object() во view получили) и ее меняет. Попутно меняются данные в связанных записях. Ненадежно даже в рамках транзакции, т.к. при приеме двух идентичных запросов есть риск дублирования.
2. Сервис принимает id объекта, делает select_for_update() для надежности. Таким образом избегаем ошибок с дублями запросов. Но это доп. запрос уже после того, как get_object() объект вернул. Проще говоря, лучше бы просто id объекта сразу получить во view, но там могут быть проверки permissions, которые на конкретный объект завязаны.
Какой из подходов можно считать общепринятым в django/drf?
Magikan
открою вам маленький секрет: нету ни каких общепринятых практик. есть дока по джанге и дока дрф, а дальше кто во что горазд. только набив приличную кучу шишек и снаварив макарон на армию порождаются практики внутри компании / команды. и если вас озадачивает такой вопрос: делайте как считаете правильным и подходящим здесь и сейчас, потом придет более лучшее решение, а потом ещё одно и ещё одно. всегда будут компромиссы
sentyaev
Если я вас правильно понял, то у вас проблема — concurrency update.
Безотносительно Django вопрос в том, что вам нужно — pessimistic concurrency или optimistic concurrency? Это зависит от вашего юзкейса.
Если pessimistic — то используйте select_for_update.
Если optimistic — тут несколько вариантов, можно использовать номер версии, или timestamp как версию. Когда писал на Django использовал Django Concurrency.
Arvardan
А статью написать можете? Для неопытных
tripcher Автор
Согласен с вами. Как раз такая схема описывается в последнем подходе в статье, только без репозитория.
Репозиторий отличный паттерн, но у него есть одна особенность, что бы он был настоящим и приносил плюсы, нам нужно использовать отдельные модели для сущностей, а не Django модели. Такой подход наиболее чистый и приносит массу плюсов, особенно, в приложениях, где много бизнес-логики и сложные бизнес-сущности, которые могут не укладываться в одну таблицу БД. Что-то подобное можно посмотреть тут github.com/dry-python/bookshelf
Но можно пойти на компромисс, если ваши бизнес-сущности не так сложны и всегда будут просто дублировать Django модели. Можно скрывать детали реализации доступа к данным за сервисным слоем или менеджером модели.
Придерживаться такому подходу:
MikhailVi
Вот про паттерн «Репозиторий» — правильная тема. Но у нас на Django-проекте репозитории не прижились, как раз из-за «толстых» моделей (вижу, Вы уже написали про это комментарий ниже).
Django ORM построен по принципу Active Record. Действия над базой могут производиться явно или еще хуже — неявно — в ответ на вызовы методов объектов-моделей.
Для правильного репозитория нужен Data Mapper, чтобы объекты, представляющие собой строки в БД или сущности бизнес логики, не содержали в себе методов изменения БД. Чтобы править базу можно было только через репозиторий, который бы обеспечивал соблюдение всех правил бизнес логики.
Как было у нас:
Чтобы избавиться от логики, размазанной по разным углам приложения, попытались писать репозитории, комбинирующие в себе методы, касающиеся отдельных смысловых аспектов работы системы.
И вот метод репозитория производит какие-то действия и должен вернуть нечто.
Половина системы заточена на работу с query_set, либо с моделями. Слой view ожидает Django-модели. Сериализаторы тоже ожидают кверисет или отдельные модели. Есть сигналы Django, обработчики методов save() моделей.
Вроде получается, из репозитория надо бы тоже вернуть кверисет или модель, чтобы дальше она была пригодна для обработки остальными компонентами Django-проекта.
Но они содержат методы, позволяющие модифицировать базу в обход логики репозитория. И эти методы используются.
Дальше либо делать, чтобы репозиторий возвращал какие-то DTO, но тогда теряем половину преимуществ (batteries included) Django по работе с моделями и кверисетами.
Либо договариваемся, что репозитории лишь группируют логику на смысловом уровне, но не изолируют ее полностью, и мы просто сами не будем обращаться к их методам, изменяющим состояние БД.
Договорились. Кто-то забыл, кто-то пропустил. Где-то стало не удобно. Стало казаться, что Django сопротивляется такому подходу. В коде пошла та же лапша но с репозиториями.
На новом проекте хотим попробовать отказаться от Django REST Framework и ее «как бы-сериализаторов» и использовать Django Ninja для АПИ (клон FastAPI под Django), и таким образом уменьшить количество неявных/спрятанных в абстракциях операций над кверисетами и моделями. Возможно получится более сильно изолировать бизнес-логику в сервисах, а в методах АПИ непосредственно вызывать действия сервисов/репозиториев в коде и возвращать DTO объекты, которые оно уже сериализует в JSON 1-в-1.
tripcher Автор
Спасибо за такой развернутый комментарий, думаю, это распространенная проблема, когда не используются отдельные Entity классы.
Мы в своем проекте, что бы отказаться от соблазна использовать методы queryset во всех слоях кроме сервисного, решили возвращать из сервисов и селекторов обычные Python коллекции, например листы. Мы основываемся на github.com/HackSoftware/Django-Styleguide с некоторыми изменениями и используем только обычные классы Serializer и APIView, также стараемся не использовать Relation филды, которые требуют передачи в них queryset. Валидация и поиск сущности в БД происходит в сервисах. Не всем данный подход подходит, так как приходится отказываться от некоторых удобств DRF. Также от использования методов модели это не защищает, и работают только договоренности.
Magikan
напишу ответ под свой комментарий в виде некоторой выдержки из комментариев и личного опыта:
Джанго + дрф = прекрасный инструмент для разработки crud api без сложной бизнес логики. всякие там интернет-магазины, бложеки и тп. ровно эту же задачу прекрасно решает и паттерн репозиторий, но в таком приложении он нафиг не нужен.
когда речь заходит про проект средней сложности по бизнес логике, тут можно и нужно комбинировать разные подходы и практики чтобы и не затянуть сроки выпуска фич, и не погрязнуть в макарошках. уже тут всплывают всякие нюансы и компромиссы.
а вот когда у вас сложный проект, толстые модели, вся логика держится только на SQL тут джанга и дрф — практически антипаттерн. и чтобы вы не пытались привнести в проект все равно получится не очень. и компромиссов будет ещё больше.
это не означает что джанго — это зло, просто оно о другом, и создавалась как раз под потоковую разработку бложеков, а не проекты на миллион строк со сложными отношениями сущностей.
и всегда есть не нулевая вероятность того, что вы выбрали не правильный инструмент для решения конкретной задачи.