
1. Вступление
Сталкиваясь с необходимостью контролировать работу других программистов, начинаешь понимать, что, помимо вещей, которым люди учатся достаточно легко и быстро, находятся проблемы, для устранения которых требуется существенное время.
Сравнительно быстро можно обучить человека пользоваться необходимым инструментарием и документацией, правильной коммуникации с заказчиком и внутри команды, правильному целеполаганию и расстановке приоритетов (ну, конечно, в той мере, в которой сам всем этим владеешь).
Но когда дело доходит собственно до кода, все становится гораздо менее однозначно. Да, можно указать на слабые места, можно даже объяснить, что с ними не так. И в следующий раз получить ревью с абсолютно новым набором проблем.
Профессии программиста, как и большинству других профессий, приходится учиться каждый день в течение нескольких лет, а, по большому счету, и всю жизнь. Вначале ты осваиваешь набор базовых знаний в объеме N семестровых курсов, потом долго топчешься по различным граблям, перенимаешь опыт старших товарищей, изучаешь хорошие и плохие примеры (плохие почему-то чаще).
Говоря о базовых знаниях, надо отметить, что умение писать красивый профессиональный код — это то, что по тем или иным причинам, в эти базовые знания категорически не входит. Вместо этого, в соответствующих заведениях, а также в книжках, нам рассказывают про алгоритмы, языки, принципы ООП, паттерны дизайна…
Да, все это необходимо знать. Но при этом, понимание того, как должен выглядеть достойный код, обычно появляется уже при наличии практического (чаще в той или иной степени негативного) опыта за плечами. И при условии, что жизнь “потыкала” тебя не только в сочные образцы плохого кода, но и в примеры всерьез достойные подражания.
В этом-то и заключается вся сложность: твое представление о “достойном” и “красивом” коде полностью основано на личном многолетнем опыте. Попробуй теперь передать это представление в сжатые сроки человеку с совсем другим опытом или даже вовсе без него.
Но если для нас действительно важно качество кода, который пишут люди, работающие вместе с нами, то попробовать все же стоит!
2. Зачем нам нужен красивый код?
Обычно, когда мы работаем над конкретным программным продуктом, эстетические качества кода заботят нас далеко не в первую очередь.
Нам гораздо важнее наша производительность, качество реализации функционала, стабильность его работы, возможность модификации и расширения и т.д.
Но являются ли эстетические качества кода фактором, положительно влияющим на вышеперечисленные показатели?
Мой ответ: да, и при этом, одним из самых важных!
Это так, потому что красивый код, вне зависимости от субъективной трактовки понятия о красоте, обладает следующими (в той или иной степени сводимыми друг к другу) важнейшими качествами:
- Читаемость. Т.е. возможность, глядя на код, быстро понять реализованный алгоритм, и оценить, как будет вести себя программа в том или ином частном случае.
- Управляемость. Т.е. возможность в минимальные сроки внести в код требуемые поправки, избежав при этом различных неприятных предсказуемых и непредсказуемых последствий.
Почему эти качества действительно являются важнейшими, и как они способствуют повышению показателей, указанных в начале параграфа, уверен, очевидно любому, кто занимается программированием.
А теперь, чтобы от общих слов перейти к конкретике, давайте сделаем обратный ход и скажем, что именно читаемый и управляемый код обычно воспринимается нами как красивый и профессионально написанный. Соответственно, на обсуждении того, как добиться этих качеств, мы далее и сосредоточимся.
3. Три базовых принципа.
Переходя к изложению собственного опыта, отмечу, что, работая над читаемостью и управляемостью своего и чужого кода, я постепенно пришел к следующему пониманию.
Вне зависимости от конкретного языка программирования и решаемых задач, для того, чтобы фрагмент кода в достаточной степени обладал этими двумя качествами необходимо, чтобы он был:
- максимально линейным;
- коротким;
- самодокументированным.
Можно бесконечно перечислять различные хинты и техники, с помощью которых можно сделать код красивее. Но я утверждаю, что наилучших, или, во всяком случае, достаточно хороших результатов можно достигнуть, ориентируясь именно на эти три принципа.
Поэтому дальше я постараюсь подробно пояснить их суть, а также описать набор основных техник, с помощью которых можно привести свой код в соответствие с этими принципами.
4. Линеаризация кода.
Мне кажется, что из трех базовых принципов, именно линейность является самым неочевидным, и именно ей чаще всего пренебрегают.
Наверное, потому что за годы учебы (и, возможно, научной деятельности) мы привыкли обсуждать от природы нелинейные алгоритмы с оценками типа O(n3), O(nlogn) и т.д.
Это все, конечно, хорошо и важно, но, говоря о реализации бизнес-логики в реальных проектах, обычно приходится иметь дело с алгоритмами совсем другого свойства, больше напоминающими иллюстрации к детским книжкам по программированию. Что-то типа такого (взято из гугла):
Таким образом, с линейностью я связываю не столько асимптотическую сложность алгоритма, сколько максимальное количество вложенных друг в друга блоков кода, либо же уровень вложенности максимально длинного подучастка кода.
Например, идеально линейный фрагмент:
do_a();
do_b();
do_c();
И совсем не линейный:
do_a();
if (check) {
something();
} else {
anything();
if (whatever()) {
for (a in b) {
if (good(a)) {
something();
}
}
}
}
Именно “куски” второго типа мы и будем пытаться переписать при помощи определенных техник.
Примечание: поскольку здесь и далее нам потребуется примеры кода для иллюстрации тех или иных идей, сразу условимся, что они будут написаны на абстрактном обобщенном C-like языке, кроме тех случаев, когда потребуются особенности конкретного существующего языка. Для таких случаев будет явно указано, на каком языке написан пример (конкретно будут встречаться примеры на Java и Javascript).
4.1. Техника 1. Выделяем основную ветку алгоритма.
В подавляющем большинстве случаев в качестве основной ветки имеет смысл взять максимально длинный успешный линейный сценарий алгоритма.
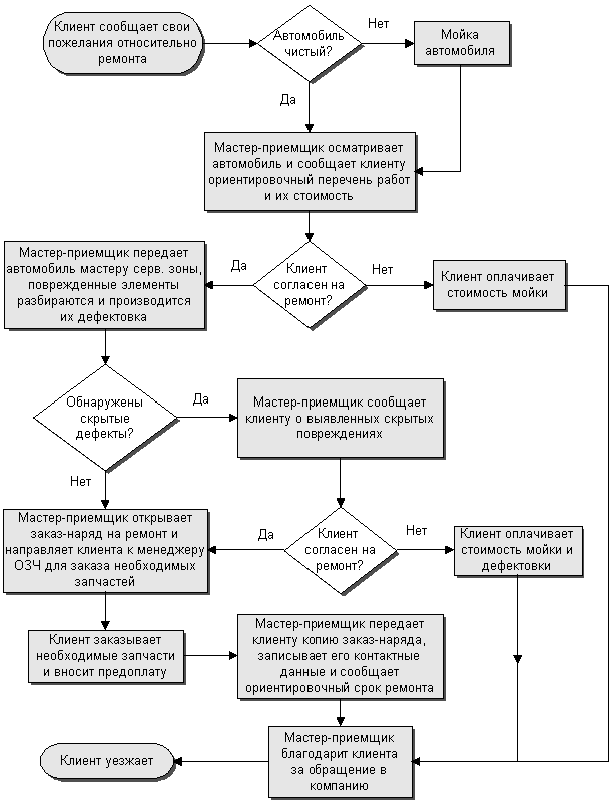
Попробуем сделать это на основе “алгоритма авторемонта” на диаграмме выше:
- Клиент сообщает пожелания.
- Мастер осматривает и говорит стоимость.
- Поиск дефектов.
- Составляем заказ на запчасти.
- Берем предоплату, обозначаем срок.
- Клиент уезжает.
Именно эта основная ветка у нас в идеале должна быть на нулевом уровне вложенности.
listen_client();
if (!is_clean()) {
...
}
check_cost();
if (!client_agree()) {
...
}
find_defects();
if (defects_found()) {
...
}
create_request();
take_money();
bye();
Давайте для сравнения рассмотрим вариант, где на нулевом уровне находится альтернативная ветка, вместо основной:
listen_client();
if (!is_clean()) {
...
}
check_cost();
if (client_agree()) {
find_defects();
if (defects_found()) {
...
}
create_request();
take_money();
} else {
...
}
bye();
Как видно, уровень вложенности значительной части кода вырос, и смотреть на код в целом уже стало менее приятно.
4.2. Техника 2. Используем break, continue, return или throw, чтобы избавиться от блока else.
Плохо:
...
if (!client_agree()) {
...
} else {
find_defects();
if (defects_found()) {
...
}
create_request();
take_money();
bye();
}
Лучше:
...
if (!client_agree()) {
...
return;
}
find_defects();
if (defects_found()) {
...
}
create_request();
take_money();
bye();
Разумеется, неверным был бы вывод, что вообще никогда не нужно использовать оператор else. Во-первых, не всегда контекст позволяет поставить break, continue, return или throw (хотя часто как раз таки позволяет). Во-вторых, выигрыш от этого может быть не столь очевиден, как в примере выше, и простой else будет выглядеть гораздо проще и понятней, чем что-либо еще.
Ну и в-третьих, существуют определенные издержки при использовании множественных return в процедурах и функциях, из-за которых многие вообще расценивают данный подход как антипаттерн (мое личное мнение: обычно преимущества все-таки покрывают эти издержки).
Поэтому эта (и любая другая) техника должна восприниматься как подсказка, а не как безусловная инструкция к действию.
4.3. Техника 3. Выносим сложные подсценарии в отдельные процедуры.
Т.к. в случае “алгоритма ремонта” мы довольно удачно выбрали основную ветку, то альтернативные ветки у нас все остались весьма короткими.
Поэтому продемонстрируем технику на основе “плохого” примера из начала главы:
Плохо:
do_a()
if (check) {
something();
} else {
anything();
if (whatever()) {
for (a in b) {
if (good(a)) {
something();
}
}
}
}
Лучше:
procedure do_on_whatever() {
for (a in b) {
if (good(a)) {
something();
}
}
}
do_a();
if (check) {
something();
} else {
anything();
if (whatever()) {
do_on_whatever();
}
}
Обратите внимание, что правильно выбрав имя выделенной процедуре, мы, кроме того, сразу же повышаем самодокументированность кода. Теперь для данного фрагмента в общих чертах должно быть понятно, что он делает и зачем нужен.
Однако следует иметь в виду, что та же самодокументированность сильно пострадает, если у вынесенной части кода нет общей законченной задачи, которую этот код выполняет. Затруднения в выборе правильного имени для процедуры могут быть индикатором именно такого случая (см. п. 6.1).
4.4. Техника 4. Выносим все, что возможно, во внешний блок, оставляем во внутреннем только то, что необходимо.
Плохо:
if (check) {
do_a();
something();
if (whatever()) {
for (a in b) {
if (good(a)) {
something();
}
}
}
} else {
do_a();
anything();
if (whatever()) {
for (a in b) {
if (good(a)) {
something();
}
}
}
}
Лучше:
do_a();
if (check) {
something();
} else {
anything();
}
if (whatever()) {
for (a in b) {
if (good(a)) {
something();
}
}
}
4.5. Техника 5 (частный случай предыдущей). Помещаем в try...catch только то, что необходимо.
Надо отметить, что блоки try...catch вообще являются болью, когда речь идет о читаемости кода, т.к. часто, накладываясь друг на друга, они сильно повышают общий уровень вложенности даже для простых алгоритмов.
Бороться с этим лучше всего, минимизируя размер участка внутри блока. Т.е. все строки, не предполагающие появление исключения, должны быть вынесены за пределы блока. Хотя в некоторых случаях с точки зрения читаемости более выигрышным может оказаться и строго противоположный подход: вместо того, чтобы писать множество мелких блоков try..catch, лучше объединить их в один большой.
Кроме того, если ситуация позволяет не обрабатывать исключение здесь и сейчас, а выкинуть вниз по стеку, обычно лучше именно так и поступить. Но надо иметь в виду, что вариативность тут возможна только в том случае, если вы сами можете задавать или менять контракт редактируемой вами процедуры.
4.6. Техника 6. Объединяем вложенные if-ы.
Тут все очевидно. Вместо:
if (a) {
if (b) {
do_something();
}
}
пишем:
if (a && b) {
do_something();
}
4.7. Техника 7. Используем тернарный оператор (a? b: c) вместо if.
Вместо:
if (a) {
var1 = b;
} else {
var1 = c;
}
пишем:
var1 = a ? b : c;
Иногда имеет смысл даже написать вложенные тернарные операторы, хотя это предполагает от читателя знания приоритета, с которым вычисляются подвыражения тернарного оператора.
Вместо:
if (a) {
var1 = b;
} else if (aa) {
var1 = c;
} else {
var1 = d;
}
пишем:
var1 = a ? b :
aa ? c : d;
Но злоупотреблять этим, пожалуй, не стоит.
Заметим, что инициализация переменной var1 теперь осуществляется одной единственной операцией, что опять же сильно способствует самодокументированности (см п. 6.8).
4.8. Суммируя вышесказанное, попробуем написать полную реализацию алгоритма ремонта максимально линейно.
listen_client();
if (!is_clean()) {
wash();
}
check_cost();
if (!client_agree()) {
pay_for_wash();
bye();
return;
}
find_defects();
if (defects_found()) {
say_about_defects();
if (!client_agree()) {
pay_for_wash_and_dyagnosis();
bye();
return;
}
}
create_request();
take_money();
bye();
На этом можно было бы и остановиться, но не совсем здорово выглядит то, что нам приходится 3 раза вызывать bye() и, соответственно, помнить, что при добавлении новой ветки, его придется каждый раз писать перед return (собственно, издержки множественных return).
Можно было бы решить проблему через try...finally, но это не совсем правильно, т.к. в данном случае не идет речи об обработке исключений. Да и делу линеаризации такой подход бы сильно помешал.
Давайте сделаем так (на самом деле, я тут применил п. 5.1 еще до того, как его написал):
procedure negotiate_with_client() {
check_cost();
if (!client_agree()) {
pay_for_wash();
return;
}
find_defects();
if (defects_found()) {
say_about_defects();
if (!client_agree()) {
pay_for_wash_and_dyagnosis();
return;
}
}
create_request();
take_money();
}
listen_client();
if (!is_clean()) {
wash();
}
negotiate_with_client();
bye();
Если вы думаете, что мы сейчас записали что-то тривиальное, то, в принципе, так и есть. Однако уверяю, что во многих живых проектах вы увидели бы совсем другую реализацию этого алгоритма…
5. Минимизация кода.
Думаю, было бы лишним пояснять, что уменьшая количество кода, используемого для реализации заданного функционала, мы делаем код гораздо более читаемым и надежным.
В этом смысле, идеальное инженерное решение — это, когда ничего не сделано, но все работает, как требуется. Разумеется, в реальном мире крайне редко доступны идеальные решения, и поэтому у нас, программистов, пока еще есть работа. Но стремиться стоит именно к такому идеалу.
5.1. Техника 1. Устраняем дублирование кода.
О копипасте и вреде, от него исходящем, сказано уже так много, что добавить что-то новое было бы сложно. Тем не менее, программисты, поколение за поколением, интенсивно используют этот метод для реализации программного функционала.
Разумеется, самым очевидным методом борьбы с проблемой является вынесение переиспользуемого кода в отдельные процедуры и классы.
При этом всегда возникает проблема выделения общего из частного. Зачастую даже не всегда понятно, чего больше у похожих кусков кода: сходства или различий. Выбор тут делается исключительно по ситуации. Тем не менее, наличие одинаковых участков размером в пол-экрана сразу говорит о том, что данный код можно и нужно записать существенно короче.
Стоит также упомянуть весьма полезную технику устранения дублирования, описанную в п. 4.3.
Распространить ее можно дальше одних лишь операторов if. Например, вместо:
procedure proc1() {
init();
do1();
}
procedure proc2() {
init();
do2();
}
proc1();
proc2();
запишем:
init();
do1();
do2();
Или обратный вариант. Вместо:
a = new Object();
init(a);
do(a);
b = new Object();
init(b);
do(b);
запишем:
procedure proc(a) {
init(a);
do(a);
}
proc(new Object());
proc(new Object());
5.2. Техника 2. Избегаем лишних условий и проверок.
Лишние проверки — зло, которое можно встретить практически в любой программе. Сложно описать, насколько самые тривиальные процедуры и алгоритмы могут быть засорены откровенно ненужными, дублирующимися и бессмысленными проверками.
Особенно это касается, конечно же, проверок на null. Как правило, вызвано подобное извечным страхом программистов перед вездесущими NPE и желанием лишний раз от них перестраховаться.
Далеко не редким видом ненужной проверки является следующий пример:
obj = new Object();
...
if (obj != null) {
obj.call();
}
Не смотря на свою очевидную абсурдность, встречаются такие проверки с впечатляющей регулярностью. (Cразу же оговорюсь, что пример не касается тех редких языков и сред, где оператор new() может вернуть null. В большинстве случаев (в т.ч. в Java) подобное в принципе невозможно).
Сюда же можно включить десятки других видов проверок на заведомо выполненное (или заведомо не выполненное) условие.
Вот, например, такой случай:
obj = factory.getObject();
obj.call1();
// если бы obj был null, мы бы уже умерли )
if (obj != null) {
obj.call2();
}
Встречается в разы чаще, чем предыдущий тип проверок.
Третий пример чуть менее очевиден, чем первые два, но распространен просто повсеместно:
procedure proc1(obj) {
if (!is_valid(obj)) return;
obj.call1();
}
procedure proc2(obj) {
if (!is_valid(obj)) return;
obj.call2();
}
obj = factory.getObject();
if (is_valid(obj) {
proc1(obj);
proc2(obj);
}
Как видно, автор данного отрезка панически боится нарваться на невалидный объект, поэтому проверяет его перед каждым чихом. Не смотря на то, что иногда такая стратегия может быть оправдана (особенно, если proc1() и proc2() экспортируются в качестве API), во многих случаях это просто засорение кода.
Варианты тут могут быть разными:
- Для каждой процедуры обозначить входной контракт, требующий от вызывающего соблюдения определенных условий валидности. После этого удалить страхующие проверки и целиком перенести ответственность за валидность входных данных на вызывающий код. Для Java, например, хорошей практикой может быть пометка “опасных” методов и полей аннотацией @Nullable. Таким образом, мы неявно обозначим, что остальные поля и методы могут принимать/возвращать значение null.
- Вообще не создавать невалидных объектов! Этот подход предполагает выполнение всех процедур валидации на этапе создания объекта, чтобы сам факт успешного создания уже гарантировал валидность. Разумеется, для этого как минимум требуется, чтобы мы контролировали класс фабрики или иные механизмы создания объектов. Либо, чтобы имеющаяся реализация давала нам такую гарантию.
Может быть, на первый взгляд, эти варианты кажутся чем-то невозможным или даже страшным, тем не менее, в реальности с их помощью можно существенно повысить читаемость и надежность кода.
Еще одним полезным подходом является применение паттерна NullObject, предполагающего использование объекта с ничего не делающими, но и не вызывающими ошибок, методами вместо “опасного” null. Частным случаем такого подхода можно считать отказ от использования null для переменных-коллекций в пользу пустых коллекций.
Сюда же относятся специальные null-safe библиотеки, среди которых хотелось бы выделить набор библиотек apache-commons для Java. Он позволяет сэкономить огромное количество места и времени, избавив от необходимости писать бесконечные рутинные проверки на null.
5.3. Техника 3. Избегаем написания “велосипедов”. Используем по максимуму готовые решения.
Велосипеды — это почти как копипаст: все знают, что это плохо, и все регулярно их пишут. Можно лишь посоветовать хотя бы пытаться бороться с этим злом.
Большую часть времени перед нами встают задачи или подзадачи, которые уже множество раз были решены, будь то сортировка или поиск по массиву, работа с форматами 2D графики или long-polling сервера на Javascript. Общее правило заключается в том, что стандартные задачи имеют стандартное решение, и это решение дает нам возможность получить нужный результат, написав минимум своего кода.
Порой есть соблазн, вместо того, чтобы что-то искать, пробовать и подгонять, быстренько набросать на коленке свой велосипед. Иногда это может быть оправдано, но если речь идет о поддерживаемом в долгосрочной перспективе коде, минутная “экономия” может обернуться часами отладки и исправления ошибок на пропущенных корнер-кейсах.
С другой стороны, лишь слегка затрагивая достаточно обширную тему, хотелось бы сказать, что иногда “велосипедная” реализация может или даже должна быть предпочтена использованию готового решения. Обычно это верно в случае, когда доверие к качеству готового решения не выше, чем к собственному коду, либо в случае, когда издержки от внедрения новой внешней зависимости оказываются технически неприемлемы.
Тем не менее, возвращаясь к вопросу о краткости кода, безусловно, использование стандартных (например, apache-commons и guava для Java) и нестандартных библиотек является одним из наиболее действенных способов уменьшить размеры собственного кода.
5.4. Техника 4. Оставляем в коде только то, что действительно используется.
“Висящие” функции, которые никем нигде не вызываются; участки кода, которые никогда не выполняются; целые классы, которые нигде не используются, но их забыли удалить — уверен, каждый мог наблюдать такие вещи в своем проекте, и может быть, даже воспринимал их, как должное.
На деле же, любой код, в том числе неиспользуемый, требует плату за свое содержание в виде потраченного внимания и времени.
Поскольку неиспользуемый код реально не выполняется и не тестируется, в нем могут содержатся некорректные вызовы тех или иных процедур, ненужные или неправильные проверки, обращения к процедурам и внешним библиотекам, которые больше ни для чего не нужны, и множество других сбивающих с толку или просто вредных вещей.
Таким образом, удаляя ненужные и неиспользуемые участки, мы не только уменьшаем размеры кода, но и, что не менее важно, способствуем его самодокументированности.
5.5. Техника 5. Используем свои знания о языке и полагаемся на наличие этих знаний у читателя.
Одним из эффективных способов сделать свой код проще, короче и понятней является умелое использование особенностей конкретного языка: различных умолчаний, приоритетов операций, кратких форм записи и т.д.
В качестве иллюстрации приведу наиболее, с моей точки зрения, яркий пример для языка Javascript.
Очень часто при разборе строковых выражений можно увидеть такие нагромождения:
if (obj != null && obj != undefined && obj.s != null && obj.s != undefined && obj.s != '') {
// do something
}
Выглядит пугающе, в том числе и с точки зрения “а не забыл ли автор еще какую-нибудь проверку”. На самом деле, зная особенность языка Javascript, в большинстве подобных случаев всю проверку можно свести до тривиальной:
if (obj && obj.s) {
// do something
}
Дело в том, что благодаря неявному приведению к boolean, проверка if (obj) {} отсеет:
- false
- null
- undefined
- 0
- пустую строку
В общем, она отсеет большинство тривиальных значений, которые мы можем себе представить. К сожалению, повторюсь, программисты используют эту особенность достаточно редко, из-за чего их “перестраховочные” проверки выглядят весьма громоздко.
Аналогично, сравните следующие формы записи:
if (!a) {
a = defaultValue;
}
и
a = a || defaultValue;
Второй вариант выглядит проще, благодаря использованию специфичной семантики логических операций в скриптовых языках.
6. Самодокументированный код.
Термин “самодокументированность” наиболее часто употребляется при описании свойств таких форматов, как XML или JSON. В этом контексте подразумевается наличие в файле не только набора данных, но и сведений об их структуре, о названиях сущностей и полей, задаваемых этими данными.
Читая XML файл мы, даже ничего не зная о контексте, почти всегда можем составить представление о том, что описывает данный файл, что за данные в нем представлены и даже, возможно, как они будут использованы.
Распространяя эту идею на программный код, под термином “самодокументированность” хотелось бы объединить множество свойств кода, позволяющих быстро, без детального разбора и глубокого вникания в контекст понять, что делает данный код.
Хотелось бы противопоставить такой подход “внешней” документированности, которая может выражаться в наличии комментариев или отдельной документации. Не отрицая необходимости в определенных случаях того и другого, отмечу, что, когда речь идет о читаемости кода, методы самодокументирования оказываются значительно более эффективными.
6.1. Техника 1. Тщательно выбираем названия функций, переменных и классов. Не стоит обманывать людей, которые будут читать наш код.
Самое главное правило, которое следует взять за основу при написании самодокументированного кода — никогда не обманывайте своего читателя.
Если поле называется name, там должно храниться именно название объекта, а не дата его создания, порядковый номер в массиве или имя файла, в который он сериализуется. Если метод называется compare(), он должен именно сравнивать объекты, а не складывать их в хэш таблицу, обращение к которой можно будет найти где-нибудь на 1000 строк ниже по коду. Если класс называется NetworkDevice, то в его публичных методах должны быть операции, применимые к устройству, а не реализация быстрой сортировки в общем виде.
Сложно выразить словами, насколько часто, несмотря на очевидность этого правила, программисты его нарушают. Думаю, не стоит пояснять, каким образом это сказывается на читаемости их кода.
Чтобы избежать таких проблем, необходимо максимально тщательно продумывать название каждой переменной, каждого метода и класса. При этом надо стараться не только корректно, но и, по возможности, максимально полно охарактеризовать назначение каждой конструкции.
Если этого сделать не получается, причиной обычно являются мелкие или грубые ошибки дизайна, поэтому воспринять такое надо минимум как тревожный “звоночек”.
Очевидно, так же стоит минимизировать использование переменных с названиями i, j, k, s. Переменные с такими названиями могут быть только локальными и иметь только самую общепринятую семантику. В случае i, j, это могут счетчики циклов или индексы в массиве. Хотя, по возможности, и от таких счетчиков стоит избавляться в пользу циклов foreach и функциональных выражений.
Переменные же с названиями ii, i1, ijk42, asdsa и т.д, не стоит использовать никогда. Ну разве что, если вы работаете с математическими алгоритмами… Нет, лучше все-таки никогда.
6.2. Техника 2. Стараемся называть одинаковые вещи одинаково, а разные — по-разному.
Одна из самых обескураживающих трудностей, возникающих при чтении кода — это употребляемые в нем синонимы и омонимы. Иногда в ситуации, когда две разных сущности названы одинаково, приходится тратить по несколько часов, чтобы разделить все случаи их использования и понять, какая именно из сущностей подразумевается в каждом конкретном случае. Без такого разделения нормальный анализ, а следовательно и осмысленная модификация кода, невозможны в принципе. А встречаются подобные ситуации намного чаще, чем можно было бы предположить.
Примерно то же самое можно сказать и об “обратной” проблеме — когда для одной и той же сущности/операции/алгоритма используется несколько разных имен. Время на анализ такого кода может возрасти по сравнению с ожидаемым в разы.
Вывод простой: в своих программах к возникновению синонимов и омонимов надо относиться крайне внимательно и всеми силами стараться подобного избегать.
6.3. Техника 3. “Бритва Оккама”. Не создаем сущностей, без которых можно обойтись.
Как уже говорилось в п. 5.4., любой участок кода, любой объект, функция или переменная, которые вы создаете, в дальнейшем, в процессе поддержки, потребует себе платы в виде вашего (или чужого) времени и внимания.
Из этого следует самый прямой вывод: чем меньше сущностей вы введете, тем проще и лучше в итоге окажется ваш код.
Типичный пример “лишней” переменной:
...
int sum = counSum();
int increasedSum = sum + 1;
operate(increasedSum);
...
Очевидно, переменная increasedSum является лишней сущностью, т.к. описание объекта, который она хранит (sum + 1) характеризует данный объект гораздо лучше и точнее, чем название переменной. Таким образом код стоит переписать следующим образом (“заинлайнить” переменную):
...
int sum = counSum();
operate(sum + 1);
...
Если далее по коду сумма нигде не используется, можно пойти и дальше:
...
operate(countSum() + 1);
...
Инлайн ненужных переменных — это один из способов сделать ваш код короче, проще и понятней.
Однако применять его стоит лишь в случае, если этот прием способствует самодокументированности, а не противоречит ей. Например:
double descr = b * b - 4 * a *c;
double x1 = -b + sqrt(descr) / (2 * a);
В этом случае инлайн переменной descr вряд ли пойдет на пользу читаемости, т.к. данная переменная используется для представления определенной сущности из предметной области, а, следовательно, наличие переменной способствует самодокументированности кода, и сама переменная под “бритву Оккама” не попадает.
Обобщая принцип, продемонстрированный на данном примере, можно заключить следующее: желательно в своей программе создавать переменные/функции/объекты, только если они имеют прототипы в предметной области. При этом, в соответствии с п. 6.1, надо стараться, чтобы название этих объектов максимально ясно выражало это соответствие. Если же такого соответствия нет, вполне возможно, что использование переменной/функции/объекта лишь перегружает ваш код, и их удаление пойдет программе только на пользу.
6.4. Техника 4. Всегда стараемся предпочитать явное неявному, а прямое — косвенному.
Общий принцип прост: любые явно выписанные алгоритмы или условия уже являются самодокументированными, т. к. их назначение и принцип действия уже описаны ими же самими. Наоборот, любые косвенные условия и операции с сайд-эффектами сильно затрудняют понимание сути происходящего.
Можно привести грубый пример, подразумевая, что жизнь подкидывает подобные примеры совсем не редко.
Косвенное условие:
if (i == abs(i)) {
}
Прямое условие:
if (i >= 0) {
}
Оценить разницу в читаемости, думаю, несложно.
6.5. Техника 5. Все, что можно спрятать в private (protected), должно быть туда спрятано. Инкапсуляция — наше все.
Говорить о пользе и необходимости следования принципу инкапсуляции при написании программ в данной статье я считаю излишним.
Хотелось бы только подчеркнуть роль инкапсуляции, как механизма самодокументирования кода. В первую очередь, инкапсуляция позволяет четко выделить внешний интерфейс класса и обозначить его “точки входа”, т. е. методы, в которых может быть начато выполнение кода, содержащегося в классе. Это позволяет человеку, изучающему ваш код, сохранить огромное количество времени, сфокусировавшись на функциональном назначении класса и абстрагировавшись от деталей реализации.
6.6. Техника 6. (Обобщение предыдущего) Все объекты объявляем в максимально узкой области видимости.
Принцип максимального ограничения области видимости каждого объекта можно распространить шире, чем привычная нам инкапсуляция из ООП.
Простой пример:
Object someobj = createSomeObj();
if (some_check()) {
// Don't need someobj here
} else {
someobj.call();
}
Очевидно, такое объявление переменной someobj затрудняет понимание ее назначения, т. к. читающий ваш код будет искать обращения к ней в значительно более широкой области, чем она используется и реально нужна.
Нетрудно понять, как сделать этот код чуть-чуть лучше:
if (some_check()) {
// Don't need someobj here
} else {
Object someobj = createSomeObj();
someobj.call();
}
Ну или, если переменная нужна для единственного вызова, можно воспользоваться еще и п. 6.3:
if (some_check()) {
// Don't need someobj here
} else {
createSomeObj().call();
}
Отдельно хотелось бы оговорить случай, когда данная техника может не работать или работать во вред. Это переменные, инициализируемые вне циклов. Например:
Object someobj = createSomeObj();
for (int i = 0; i < 10; i++) {
someobj.call();
}
Если создание объекта через createSomeObj() — дорогая операция, внесение ее в цикл может неприятно сказаться на производительности программы, даже если читаемость от этого и улучшится.
Такие случаи не отменяют общего принципа, а просто служат иллюстрацией того, что каждая техника имеет свою область применения и должна быть использована вдумчиво.
6.7. Техника 7. Четко разделяем статический и динамический контекст. Методы, не зависящие от состояния объекта, должны быть статическими.
Смешение или вообще отсутствие разделения между статическим и динамическим контекстом — не самое страшное, но весьма распространенное зло.
Приводит оно к появлению ненужных зависимостей от состояния объекта в потенциально статических методах, либо вообще к неправильному управлению состоянием объекта. Как следствие — к затруднению анализа кода.
Поэтому необходимо стараться обращать внимание и на данный аспект, явно выделяя методы, не зависящие от состояния объекта.
6.8. Техника 8. Стараемся не разделять объявление и инициализацию объекта.
Данный прием позволяет совместить декларацию имени объекта с немедленным описанием того, что объект из себя представляет. Именно это и является ярким примером следования принципу самодокументированности.
Если данной техникой пренебречь, читателю придется для каждого объекта искать по коду, где он был объявлен, нет ли у него где-нибудь инициализации другим значением и т.д. Все это затрудняет анализ кода и увеличивает время, необходимое для того, чтобы в коде разобраться.
Именно поэтому, например, функциональные операции из apache CollectionUtils и guava Collections2 часто предпочтительней встроенных в Java foreach циклов — они позволяют совместить объявление и инициализацию коллекции.
Сравним:
// getting “somestrings” collection somehow
...
Collection<String> lowercaseStrings = new ArrayList<String>();
/* collection is uninitialized here, need to investigate the initializion */
for (String s : somestrings) {
lowercaseStrings.add(StringUtils.lowerCase(s));
}
c:
// getting “somestrings” collection somehow
...
Collection<String> lowercaseStrings = Collections2.transform(somestrings, new Function<String, String>() {
@Override
public String apply(String s) {
return StringUtils.lowerCase(s);
}
}));
Если мы используем Java 8, можно записать чуть короче:
...
Collection<String> lowercaseStrings = somestrings.stream()
.map( StringUtils::lowerCase ).collect(Collectors.toList());
Ну и стоит упомянуть случай, когда разделять объявление и инициализацию переменных так или иначе приходится. Это случай использования переменной в блоках finally и catch (например, для освобождения какого-нибудь ресурса). Тут уже ничего не остается, кроме как объявить переменную перед try, а инициализировать внутри блока try.
6.9. Техника 9. Используем декларативный подход и средства функционального программирования для обозначения, а не сокрытия сути происходящего.
Данный принцип может быть проиллюстрирован примером из предыдущего пункта, в котором мы использовали эмуляцию функционального подхода в Java с целью сделать наш код понятнее.
Для большей наглядности рассмотрим еще и пример на Javascript (взято отсюда: http://habrahabr.ru/post/154105).
Сравним:
var str = "mentioned by";
for(var i =0; l= tweeps.length; i < l; ++i){
str += tweeps[i].name;
if(i< tweeps.length-1) {str += ", "}
}
c:
var str = "mentioned by " + tweeps.map(function(t){
return t.name;
}).join(", ");
Ну а примеры использования функционального подхода, убивающие читаемость… Давайте на этот раз сэкономим свои нервы и обойдемся без них.
6.10. Техника 10. Пишем комментарии только, если без них вообще не понятно, что происходит.
Как уже говорилось выше, принцип самодокументирования кода противопоставляется документированию с помощью комментариев. Хотелось бы коротко пояснить, чем же так плохи комментарии:
- В хорошо написанном коде они не нужны.
- Если поддержка кода часто становится трудоемкой задачей, поддержкой комментариев обычно просто никто не занимается и через некоторое время комментарии устаревают и начинают обманывать людей (“comments lie”).
- Они засоряют собой пространство, тем самым ухудшая внешний вид кода и затрудняя читаемость.
- В подавляющем большинстве случаев они пишутся лично Капитаном Очевидностью.
Ну а нужны комментарии в случаях, когда написать код хорошо по тем или иным причинам не представляется возможным. Т.е. писать их надо для пояснения участков кода, без них трудночитаемых. К сожалению, в реальной жизни такое встречается регулярно, хотя расценивать это следует лишь как неизбежный компромисс.
Также как разновидность подобного компромисса следует расценивать необходимость спецификации контракта метода/класса/процедуры при помощи комментариев, если его не получается явно выразить другими языковыми средствами (см п. 5.2).
7. Философское заключение.
Закончив изложение основных техник и приемов, с помощью которых можно сделать код чуть красивее, следует еще раз явно сформулировать: ни одна из техник не является безусловным руководством к действию. Любая техника — лишь возможное средство достижения той или иной цели.
В нашем случае целью является получение максимально читаемого и управляемого кода. Который одновременно будет приятен с эстетической точки зрения.
Изучая примеры, приведенные в текущей статье, можно легко заметить, что, как сами исходные принципы (линейность, минимальность, самодокументированность), так и конкретные техники не являются независимыми друг от друга. Применяя одну технику мы можем также косвенно следовать и совсем другой. Улучшая один из целевых показателей, мы можем способствовать улучшению других.
Однако, у данного явления есть и обратная сторона: нередки ситуации, когда принципы вступают в прямое противоречие друг с другом, а также со множеством других возможных правил и догм программирования (например с принципами ООП). Воспринимать это надо совершенно спокойно.
Встречаются и такие случаи, когда однозначно хорошего решения той или иной проблемы вообще не существует, или это решение по ряду причин нереализуемо (например, заказчик не хочет принимать потенциально опасные изменения в коде, даже если они способствуют общему улучшению качества).
В программировании, как и в большинстве других областей человеческой деятельности, не может существовать универсальных инструкций к исполнению. Каждая ситуация требует отдельного рассмотрения и анализа, а решение должно приниматься исходя из понимания особенностей ситуации.
В целом, этот факт нисколько не отменяет полезности как вывода и понимания общих принципов, так и владения конкретными способами их воплощения в жизнь. Именно поэтому я надеюсь, что все изложенное в статье может оказаться действительно полезно для многих программистов.
Ну и еще пара слов о том, с чего мы начинали — о красоте нашего кода. Даже зная о “продвинутых” техниках написания красивого кода, не стоит пренебрегать самыми простыми вещами, такими, как элементарное автоформатирование и следование установленному в проекте стилю кодирования. Зачастую одно лишь форматирование способно сотворить с уродливым куском кода настоящие чудеса. Как и разумное группирование участков кода с помощью пустых строк и переносов.
Не стоит забывать и о таком средстве, как статические анализаторы кода, которые позволяют выявить множество проблем (в том числе, описанных в данной статье) автоматически, благо сейчас они встроены в большинство популярных IDE.
И самое последнее. Всегда стоит помнить о субъективности эстетического восприятия вещей. Поэтому уделяя внимание этому вопросу, следует с пониманием относиться к чужим вкусам и привычкам.
Приятного вам программирования!
Комментарии (143)

lair
16.09.2015 15:10+12В этом-то и заключается вся сложность: твое представление о “достойном” и “красивом” коде полностью основано на личном многолетнем опыте. Попробуй теперь передать это представление в сжатые сроки человеку с совсем другим опытом или даже вовсе без него.
А как же соответствующая литература?
(Собственно, поэтому же удивляет ваш пассаж «в книжках [...] нам рассказывают про алгоритмы, языки, принципы ООП, паттерны дизайна…». Создается ощущение, что вы просто не читали «те» книжки.)
Temirkhan
16.09.2015 16:00+1Почему-то у меня такая же мысль закралась уже сразу после прочтения заголовка.

maaGames
16.09.2015 16:20-32Плюсую ссылку. Не прочитавшему Макконнелла — не место в профессии.

xoposhiy
16.09.2015 18:10+7сейчас по количеству минусиков мы узнаем, сколько человек не читали Макконнелла ;-)
NeoNN
18.09.2015 19:15+1Сколько людей — столько и мнений, а я вот возьму и скажу (это не значит, что я так на самом деле думаю, но все же), что Макконелл — пижон, и говорит прописные истины, а Фаулер пишет слишком сложно и академично, из за этого над его книгами засыпаешь, будет примерно такое же голословное утверждение, как и выше. Кто-то будет убеждать, что читать надо только интересные книжки издательства Manning с человечками в костюмах на обложках, где в большинстве случаев все написано простым языком и на высоком уровне. А кто-то скажет, что вообще книжек не читает, а смотрит какой-нибудь Pluralsight, и тоже будет по-своему прав.
maaGames
18.09.2015 20:17Эти истины становятся прописными только с опытом, после кучи сломанных костылей и велосипедов. Так что чем раньше потенциальный программист эти прописные истины прочитает, тем лучше и ему и окружающим.

Sirion
16.09.2015 15:25+15if (obj && obj.s) {
// do something
}
Вот так и возникают внезапные баги при obj.s == 0.
Galiaf47
16.09.2015 17:54-1Безусловно, баги возникают, но автор говорил о применении такого подхода программистами хорошо знающими язык. Такие программисты, знают о том, что если число может быть нулевым, то проверка должна это учитывать.
Реальные проблемы начинаются, когда менее опытные коллеги работают с таким кодом.
DemetrNieA
17.09.2015 03:33+1В случае, когда код настолько не очевиден, проблемы не прекращаются и когда работает его автор.

DenimTornado
16.09.2015 23:54-1var obj = {};
obj.s = 0;
!!obj.s;Sirion
17.09.2015 08:05Простите, кажется, этот код недостаточно самодокументирован. Что он символизирует?
DenimTornado
17.09.2015 10:42-1Я к тому что булевый 0 это false, в чём баг?
Sirion
17.09.2015 10:58+1Баг в том, что разработчик этот момент может не предусмотреть. Если obj.s может быть произвольным числом, а кодер по привычки поставил obj && obj.s как «проверку на всякую бяку», случается беда. Или, в случае не совсем новичка, если изначально obj.s обязано было быть положительным числом, а потом требования изменились.
DenimTornado
17.09.2015 11:06-1Ах вот вы о чём, ну тогда вам вот ниже коммент оставили. НЕочевидное поведение предусматривать надо.

Aingis
17.09.2015 00:10Если obj.s — число, то необходимости в такой проверке проверке вообще нет. Если хочется проверить существование поля «s», то «'s' in obj» в помощь. На null/undefined можно сделать простую проверку «obj.s != null». (Но вообще говоря, если может приходить что угодно, то код уже дурно пахнет.) Если кодер не понимает даже этого, то это не программист.

kloppspb
16.09.2015 15:37+5>6.3… желательно в своей программе создавать переменные/функции/объекты, только если они имеют прототипы в предметной области.
Или, например, если в списке используемых инструментов имеется отладчик, и слова «точка останова» о чём-нибудь говорят. IMHO, весь этот пункт вообще не про красоту кода, а про микрооптимизации. Более того, не только ради отладки, но и ради ясности кода я иногда предпочитаю вводить «промежуточные» переменные.

danl
16.09.2015 15:53+3Как обычно на любой «книжный» пример автора аудитория найдёт по 10 контр-примеров из реальных проектов.
Спрашивается — как задокументировать и привить здравый смысл и чувство прекрасного, на которые всё в итоге опирается?maaGames
16.09.2015 16:25+5Элементарно! Достаточно подождать пару лет и заставить рефакторить собственный код двухлетней выдержки. Повторять до просветления. Так буддистские монахи дзен познают.) Ну или книжки «другие» почитать.
nnesterov
16.09.2015 16:40+1Упертые товарищи в этом случае просто засунут в код еще немного костылей и заплаток и будут считать, что это и есть самый верный подход к работе. «Лишь бы работало»

Mistx
16.09.2015 16:46+4Вы забыли про магические константы, которые следует заменять именованными с целью централизации управления ими + повышения читабельности кода

seregamorph
16.09.2015 17:39-2Они спасают не всегда
public static final double INFINITY = 1000000000.0d;

alan008
16.09.2015 23:35-2На кой хрен мне централизация управления константами, относящимися к разным местам кода, не имеющим ничего общего между собой?

Mrrl
16.09.2015 23:44+3Например, чтобы весь проект быстро перевести из метров и килограммов в дюймы и фунты.
MacIn
16.09.2015 23:56+5Ни на кой.
А вот для управления константами, относящимися к разным местам кода, имеющим что-то общее — пригодится. Ваш к.о.alan008
17.09.2015 00:25Не испытываю такого благоговения перед константами. По сути они те же переменные, только константы )) Просто еще один аспект кода. Выносить константы из всех модулей в одно общее место — странное занятие. Сгруппировать похожие по смыслу и назначению константы (например какие-то идентификаторы) близко друг от друга в коде — да, смысл есть.
Mrrl
17.09.2015 00:35+3Действительно. Зачем нам общая константа Math.PI? Давайте в каждом классе определим своё значение числа пи. Или 1296000 — ведь все знают, что это такое. Зачем ему давать название, да ещё и выносить в общее для всех место?
Sirion
17.09.2015 08:09Кстати, а что это? 15 суток в секундах? Или два развёрнутых угла в угловых секундах? Не уверен, что из этого чаще встречается в программировании.
Mrrl
17.09.2015 15:46Второе — число угловых секунд в полном обороте. Встречается, когда угловая секунда — единица измерения углов во всём проекте.
alan008
17.09.2015 08:52В исходном сообщение, на которое я ответил, была фраза
«магические константы, которые следует заменять именованными с целью централизации управления ими».
Под «централизацией» я обычно понимаю сосредоточение в одном месте (с т.з. русского языка).MacIn
17.09.2015 13:18Например, не в каждой процедуре своя, а одна на все. В этом модуле. Централизация.
MacIn
17.09.2015 00:42+3С чего вы взяли, что речь идет только про «выносить из всех модулей в одно общее место»? Это ваша выдумка.
Это может быть именованная константа в пределах одного модуля или одной процедуры.
seregamorph
16.09.2015 17:506.6. Все объекты объявляем в максимально узкой области видимости.
Это зависит. Конкретно это очень важно в случае public api, в нем полное скрытие внутренней логики иногда свидетельствует о плохом class design. В грамотном случае внутренняя логика (где это уместно) может быть сделана protected. В каждом конкретном случае, нужно, конечно, смотреть отдельно.
xanep
18.09.2015 05:56>>Конкретно это очень важно в случае public api, в нем полное скрытие внутренней логики иногда свидетельствует о плохом class design
Приведите пример, пожалуйста. Не представляю когда сокрытие логики может быть плохим дизайном.seregamorph
21.09.2015 11:38Хорошие примеры:
Самый банальный пример — LinkedHashMap, protected-метод removeEldestEntry — здесь на уровне класс-дизайна заложили расширенную функциональность, не вытаскивая это в public (например, конструктор с параметром int вводил бы в заблуждение как initialSize, но не maxSize).
В более сложном случае — Spring Jdbc Templates я рассматриваю как один из образцов хорошего API. Развитая структура классов, которая в том числе содержит protected-логику — что позволяет встраиваться через наследование и делать то, что через делегирование требовало бы большого количества повторенного кода, а в некоторых местах было бы невозможно без форка библиотеки.
Плохой пример — любая библиотека, которую пришлось форкнуть, потому что ее class design не позволял изменить логику нужным образом. Здесь может быть много различных оговорок, например, об уместности конкретных доработок, нюансов security (из-за которых часть API может быть приватна или final) и пр., но, надеюсь, я донес свою мысль.

BalinTomsk
16.09.2015 18:04-2----var1 = a? b: c;
это пример как писать не надо.
попробуйте поставить точку останова на ветку ELSE?
К тому же если автор использует TDD то код и так напишется чистым и красивым.
---Лишние проверки — зло, которое можно встретить практически в любой программе.
Если пишете bulletproof код, то лишние проверки нужны как для юнит тестов так и для будушей гарантии в случае рефакторинга.
Замените new Object на new myObject с возможностью возврашения null и всему коду можно ставить жирный минус.
Такое ошушение что статья писалась теоретиком, все кодирование которого сводилось к написанию академических примеров.
В реальной жизни в компании постоянно покупаются сторонние компании и в проект вливается жуткий код.mird
16.09.2015 18:49+5А зачем в данном коде ставить точку останова на else? Здесь простое присвоение и что присвоилось вы можете узнать остановившись на следующей строчке.
palebluedot
16.09.2015 18:56+4Более того, тернарный оператор это выражение, а не набор инструкций, и там нет такого понятия как ветка вообще.
MacIn
16.09.2015 19:53Для отладки. В более сложном примере. Допустим, вам надо поймать только присвоение c, а в остальных случаях — пройти без остановки. Например, у вас var1 = b происходит десятьтыщьмильонов раз, а var1 = c — единожды. У нас в команде, например, договорились всегда разносить if с условием и ветки в один оператор как раз для установки BPтов.
Mrrl
16.09.2015 20:14+8А допустим, что вам надо поймать присвоение b для конкретного случая a==73, а в остальных случаях пройти без остановки. Что будете делать? Наверное, поставите условный breakpoint или временно измените код. И чем эта ситуация отличается от ловли присваивания при a==0? Да, она встречается несколько реже. Но для каждого конкретного присваивания шансы, что именно на нём придётся что-то такое ловить, составляют, скажем, 0.01% для случая a==73 против 0.1% для случая a==0. Стоит ли ради этого портить весь код, вставляя ненужные if/else вместо тернарного оператора?
BalinTomsk
16.09.2015 20:34-4— 0.01% для случая a==73 против 0.1% для случая a==0. Стоит ли ради этого портить весь код
Когда я дебажу код по присланному pdb для сервера BOA и тамошние админы полчаса настраивают среду чтобы для воспроизвести баг, я в первую очередь думаю как решить проблему крупного клиента, а не о том как лаконичен код.
В шарпе я уже понял не актуально разбирать дампы и удаленно отлаживать.
Если я не смогу поставить break по условию я не смогу помочь клиенту и меня могут попросить расстаться с работой при таком подходе.
MacIn
16.09.2015 21:11+1Это более редкая задача, чем ловля одной из веток. Более того, условие может сложным и не всегда можно поставить условный останов на такое или он сильно замедляет выполнение.
Стоит ли ради этого портить весь код, вставляя ненужные if/else вместо тернарного оператора?
Стоти ли портить весь код, вставляя ненужный тернарный оператор, вместо if/else? Тернарный оператор, напомню, сложнее, чем просто if/else «в строчку» и позволяет творить интересные трюки — есть места, где он реально нужен и красив. Но не здесь. Зачем было уходить от однострочной мешанины, чтобы опять к ней вернуться?Mrrl
16.09.2015 21:35Зачем было уходить от однострочной мешанины,
Не знаю, что понимается под «мешаниной», но когда в экранах было 24 строчки, программы с однострочными конструкциями читались гораздо легче, чем многострочные. И сейчас это позволяет охватить взглядом гораздо больший кусок кода, а не возить его по экрану взад-вперёд.
Что касается отладки, то, вероятно, код, нацеленный на наиболее эффективную отладку, должен обладать своими особенностями — не обязательно совпадающими с «лаконичностью», «читабельностью» или «эффективностью».
Насчёт того, что тернарный оператор сложнее — не понял. Он слегка другой, чем if/else — потому что является выражением, а не двумя отдельными операторами. Где-то это помогает, где-то мешает, где-то — всё равно, и можно выбрать более подходящий из двух вариантов. Конечно, если из тернарных операторов в сочетании с && и || строится конструкция длиной в 6 строк, большая часть выражений в которой имеет побочный эффект, это может быть страшно. Но может быть, и нет — если она грамотно написана, то её можно просто прочитать, как инструкцию…MacIn
17.09.2015 00:02+1Не знаю, что понимается под «мешаниной», но когда в экранах было 24 строчки, программы с однострочными конструкциями читались гораздо легче, чем многострочные
И тем не менее,
a=b; b=c; c=d; if (a==5) d = 7;
дурной тон.
Что касается отладки, то, вероятно, код, нацеленный на наиболее эффективную отладку, должен обладать своими особенностями — не обязательно совпадающими с «лаконичностью», «читабельностью» или «эффективностью».
Выражение вида
if (a==5) doSomething;
позволяет ставить BP и читается лучше, чем
if (a==5) doSomething;
особенно, если doSomething и условие — массивные. Здесь одновременно лаконичный и красивый, читаемый код, и отлаживать можно.
Насчёт того, что тернарный оператор сложнее — не понял. Он слегка другой, чем if/else — потому что является выражением, а не двумя отдельными операторами.
Нет. Тернарный оператор может возвращать lvalue, и там он действительно красив.Mrrl
17.09.2015 00:22И тем не менее,
a=b; b=c; c=d; if (a==5) d = 7;
дурной тон.
Пожалуй. Хотя про
var t=a; a=b; b=t;
(при отсутствии или нежелании использовать swap) я не был бы так уверен.
Выражение вида
if (a==5)
doSomething;
позволяет ставить BP и читается лучше, чем
if (a==5) doSomething;
Насчёт BP — вопрос к среде. Visual Studio позволяет ставить breakpoint на оператор, являющийся частью строки, в C#, но не позволяет в C++. Если условие и действие массивные, то отдельные строчки лучше (а я бы ещё и скобки поставил :( ), но если нет — предпочту одну строку.
Тернарный оператор может возвращать lvalue,
Везёт вам. В C# не может. Там и функций, возвращающих lvalue, нет :(
Flammar
17.09.2015 12:03Везёт вам. В C# не может. Там и функций, возвращающих lvalue, нет :(
Что-то типа
— нет?a[b ? 1 : 0] = c;

KReal
16.09.2015 18:26+34.2. Техника 2. Используем break, continue, return или throw, чтобы избавиться от блока else.
Про return — довольно неоднозначный совет.lair
16.09.2015 18:27Почему?
mird
16.09.2015 18:51+1Тот же Макконел не рекомендует увлекаться множественными выходами из метода. (Вернее в одном месте книги он рекомендует делать это, а в другом советует не увлекаться).
lair
16.09.2015 19:00+3Ну просто ничем не стоит «увлекаться», а то случится беда. Но в среднем ранний выход упрощает чтение кода (иногда — настолько, что я рефакторю код так, чтобы сложный кусок оказался в отдельном методе, где можно сделать ранний выход).

retran
16.09.2015 21:11Множественные выходы из метода мешают тогда и только тогда когда функция не умещается на экране.
Если писать код маленькими функциями (как и советует Макконел), то никаких проблем нет.bogushevich
17.09.2015 06:05+2Если писать код маленькими функциями (как и советует Макконел)
Макконел как раз утверждает, что нет ничего плохого в использовании относительно больших функций. Он предлагает не превращать маленький размер функций в самоцель, а определять размер функции в зависимости от задачи, которая на нее возложена и сложности внутренней структуры (та самая линейность, о которой говорит автор статьи). Ссылается он на исследования связи количества ошибок с размером функций, в которых они были найдены. От себя добавлю, что одна относительно большая функция, состоящая в основном из стандартных операторов, может быть значительно читабельней, чем пять маленьких ссылающихся друг на друга по цепочке.
Рекомендация про умещение в размер экрана у него тоже была, но мониторы нынче большие, шрифты маленькие, поэтому к маленьким функциям это отношения не имеет. Просто, как сказал lair, «ничем не стоит «увлекаться», а то случится беда».
VolCh
22.09.2015 14:38Тут камень преткновения в том можно ли считать код с множественными return линейными, с простой структурой. Скорее нет, чем да, а потому функции с ним должны быть небольшими.

StepEv
16.09.2015 19:13-2Потому что при анализе кода, меня может интересовать именно альтернативная ветка и тогда:
1) её сложнее найти визуально, так как нет явного маркера else
2) код выглядит линейным, по сути им не являясь, что вводит в заблуждение при беглом просмотре
3) если я начал читать с закрывающей скобки блока if (ну не интересне мне сейчас основной сценарий, мне надо изменить что-то в альтернативном), я сочту, что код после блока выполняется всегда, что не так.
Так что совет 4.2 — ВРЕДНЫЙ, НЕ НАДО ТАК ДЕЛАТЬMacIn
16.09.2015 19:56+1Совет нормальный, просто не везде он подходит. Если вы проверяете, например, не пуста ли входная строка и выходите из метода, это лучше, чем заключать все тело метода в блок при чтении кода. Потому что сразу видно — вот они, условия проверки, по которым мы сразу вываливаемся.
StepEv
17.09.2015 08:13-1В таком случае, соглашусь, допустимо. Но, если кроме выхода из блока в ветке ничего нет, скорее всего, более читаемо будет инвертировать условие и избавиться и от return и от else.

sophist
17.09.2015 12:11+2Тогда вся основная ветка будет вложена в if и идти с отступом. А если проверочных условий хотя бы два или три, то и с двумя или тремя отступами.
lair
16.09.2015 20:56+3Начнем с простого вопроса: а в языке, которым вы пользуетесь, есть исключения? И если они есть, пользуетесь ли вы ими?
StepEv
17.09.2015 08:15Исключения, по моему, лучше использовать для исключений. Строить логику алгоритма на исключениях, чаще всего, не очень хорошая идея.
StepEv
17.09.2015 08:18Я понял. Я сосредоточился на примере кода с return и мне он не понравился. В совете речь идёт о наборе конструкций, и сам по себе совет нормальный. Как любой инструмент, применять его надо с умом, что бы не возникало перечисленных мной последствий.
Mrrl
16.09.2015 18:39+1Все советы неоднозначные. Кому-то не нравится множественный return. Кому-то throw в штатной ситуации. Кому-то break, применённый не совсем по назначению. Как здесь использовать continue, не очень понятно (если код не находится в конце тела цикла изначально). Ну, и в список можно добавить goto — он тоже кому-то не понравится.
Teacher
16.09.2015 18:52+1Про пример в 4.4. А потом выясниться, что метода do_a() иногда меняет состояние check и получим такой вкусный баг…
NeoNN
16.09.2015 19:48На мой взгляд, на примере C# на красивый код должны посмотреть:
1) сам программист
2) его коллеги при код-ревью
3) решарпер
4) стайл-коп
5) юнит-тесты
6) NCrunch
когда у всех шести нет замечаний — код красивый


deniskreshikhin
16.09.2015 20:08>> Второй вариант выглядит проще, благодаря использованию специфичной семантики логических операций в скриптовых языках.
Это называется — операторы короткого действия или кротокозамкнутые операторы.
sim-dev
16.09.2015 21:51+3По-моему, это краткое вольное изложение содержимого книги «Веревка достаточной длины, чтобы выстрелить себе в ногу» Ален И. Голуб.
В сущности, в контексте упомянутой книги и данной статьи красивым следует назвать просто правильно написанный код. И это так и есть, согласно принципу бритвы Оккама.
В соответствии с этим же принципом данная статья должна быть этой бритвой отрезана — она лишняя сущность.

solver
16.09.2015 22:06+4>Ну а нужны комментарии в случаях, когда написать код хорошо по тем или иным причинам не представляется возможным.
И опять это глупое, безапелляционное упрощение ситуации с комментариями.
Вы ни разу не видели хороший код со сложной предметной областью?
То, что многие используют каменты в стиле КО, не означает их полную ненужность и ни в коем случае не говорит о плохом коде. Ситуации и проекты разные бывают, это надо просто понимать.Mrrl
16.09.2015 22:20-1>Ну а нужны комментарии в случаях, когда написать код хорошо по тем или иным причинам не представляется возможным.
Вы ни разу не видели хороший код со сложной предметной областью?
И где здесь логика? Правильнее было бы спросить «Вы ни разу не видели плохой код, которому не нужны комментарии?» А так совершенно непонятно, с чем вы спорите.solver
17.09.2015 01:02+1Вообще-то я ни с чем не спорю)
Просто смешно выглядят потуги неопытных людей, выдать чьи-то фантазии за вселенскую мудрость.
Фишка в том, что проблема не в комментариях, а в людях.
Как говорят в одном подкасте: «Технологии великолепны, просто есть люди мудаки».
P.S. А спросил я абсолютно правильно. В хорошем коде, со сложной предметной областью, комментарии более чем уместны.Mrrl
17.09.2015 01:27-1Но процитированная фраза про хороший код ничего не говорила! Она про плохой код.
А что дадут комментарии в коде со сложной предметной областью? Разве что «вывод и смысл этой формулы описан на стр. 284 такого-то тома технической документации»?
Меня сейчас начальник просит прокомментировать некоторые фрагменты (не слишком сложные, так — несколько интерполяций в рантайме). Но я не понимаю, как это сделать, чтобы хоть чем-то ему помочь.

SDSWanderer
16.09.2015 22:38+10Сейчас работаю на проекте, где не признают множественных точек выхода из функции, и как следствие операторы возбуждения исключений. Такой БОЛИ я еще никогда не испытывал. Постоянные вложенные проверки на «if ( not $error)» только для того чтоб сделать один return… И ни здравый смысл, ни сухие цифры (составлял им отчет о цикломатической сложности двух версий одного и того же куска программы написанного так как пишу я и как хотят они, где разрыв был от 1.3 до 1.6 раз) не их не убедили. Говорят мол, нас в универе учили что это плохо. Facepalm.png



berman
17.09.2015 00:19+1Ну и вам друзья тоже посоветую книжечку называется Clean Code.

burjui
17.09.2015 13:40+1Отлична книга, как раз перечитываю. Мне нравится логичный и структурированный подход Дядюшки Боба к созданию ПО. В отличие от большинства из нас, он смог после хождения по граблям сделать выводы и придумать, как уменьшить вероятности наступить на грабли в дальнейшем, не нарушая чистоты кода. Большим плюсом книги является также тот факт, что многие примеры плохого и хорошего кода взяты из реальных проектов (в основном, из FitNesse).

ragesteel
17.09.2015 00:43Если мы используем Java 8, то вместо StringUtils::lowerCase можно написать просто String::toLowerCase, чтобы не зависеть от внешней библиотеки.
Collection<String> lowercaseStrings = somestrings.stream() .map( StringUtils::lowerCase ).collect(Collectors.toList());

FiresShadow
17.09.2015 06:58-2procedure proc1() {
init();
do1();
}
procedure proc2() {
init();
do2();
}
proc1();
proc2();
запишем:
init();
do1();
do2();
А вот Фаулер советует прямо противоположное, и я с ним согласен. Он рекомендует вместо
for(int i=0; i<N; i++)
{
doA();
doB();
}
писать:
for(int i=0; i<N; i++)
{
doA();
}
for(int i=0; i<N; i++)
{
doB();
}
в случаях, если doA() и doB() по смыслу делают разные вещи.lair
17.09.2015 11:11Если не секрет, где именно Фаулер это советует?
FiresShadow
17.09.2015 12:33Насколько я помню, в «Рефакторинг»е. Хотя сейчас полистал и не нашёл этого места в книге. Может быть ошибся с книгой.
Там основная аргументация была в том, что for(int i=0; i<N; i++){sum += коллекция[i];} и for(int i=0; i<N; i++){коэффициент *= (коллекция[i]+i*коллекция[i / 2])/N;} делают совершенно разные по смыслу вещи и не стоит лепить их в одну кучу. Тогда проще произвести выделение метода, и в целом код становится более самодокументированным и структурированным.
Особенно если вместо «sum += коллекция[i]» 10 строчек кода и вместо «коэффициент *= (коллекция[i]+i*коллекция[i / 2])/N» ещё 15 строчек. Тогда сначала разбиваем этот цикл на два цикла, а потом выделяем два метода РассчитатьСумму(Коллекция) и РассчитатьКоэффициент(Коллекция).
procedure proc1() {
init();
do1();
}
Тут похожая ситуация. Есть некое действие proc1(), которое заключается в init() и do1(). А завтра оно может заключаться уже в do1() и doSomethingElse(), но по смыслу это всё равно будет proc1(). Тут автор заметил, что есть некая procedure proc2() {init();do2();} и предложил заменить код «proc1(); proc2();» на «init(); do1(); do2();». Это оптимизация с потерей качества кода, но никак не улучшение качества кода. По смыслу тут должно быть proc1(); proc2();, а как они внутри делаются — не столь важно. Это называется инкапсуляцией.
Хотя, конечно, если они и прям буквально называются в точности proc1() и proc2(), то конечно же придётся заинлайнить эти методы с бессмысленными именами, если не удастся подобрать им более подходящие названия. Но будем считать, что автор дал им такие имена просто в силу схематичности примера.lair
17.09.2015 12:36+1Есть некое действие proc1(), которое заключается в init() и do1(). А завтра оно может заключаться уже в do1() и doSomethingElse(), но по смыслу это всё равно будет proc1().
Вот тут, собственно, и вопрос. Может быть, это действиеproc1, а может быть, это действиеdo1, аproc1создана только для удобства инициализации (потому что все всегда забывали). А еще зависит от того, насколько связаны вызовыproc1иproc2FiresShadow
17.09.2015 13:16proc1 создана только для удобства инициализации (потому что все всегда забывали)
Значит это проблема на уровне архитектуры. И использование попеременно и на усмотрение автора то do1, то proc1 только добавят путаницы в коде.
В таком случае proc1 будет называться InitializeAndDo1(), что говорит о нарушении srp. Кроме того, тут введён лишний уровень абстракции.
Не совсем понимаю, почему автор утверждает, что тут есть дублирование кода. Да, Init() вызывается в нескольких местах в программе, ну и что? Согласен, с функцией нужно что-то делать, потому что она, по всей видимости, нарушает srp, но дублирование кода, имхо, тут ни при чём. И не всегда нужно сваливать с первого взгляда похожие части кода в одну кучу, если по смыслу они делают разные вещи.FiresShadow
17.09.2015 13:47Как вариант, тут можно или Init() поместить в конструктор, или поставить в начало функций Do1() и Do2() метод CheckInitialize(), который бы проверял, инициализирован ли уже объект и инициализировал бы его при необходимости (а-ля защитное программирование). Избавиться от функции InitializeAndDo1(), во всех местах вызывать Do1().
FiresShadow
17.09.2015 07:09procedure proc1(obj) {
if (!is_valid(obj)) return;
obj.call1();
}
… Не смотря на то, что иногда такая стратегия может быть оправдана (особенно, если proc1() и proc2() экспортируются в качестве API), во многих случаях это просто засорение кода.
Лучше было бы описать, в каких случаях так делать надо, а в каких не надо, вместо того чтобы говорить, что во многих случаях так делать не надо.

dgstudio
17.09.2015 09:07Эй-эй, это что за хренотень? :)
find_defects();
if (defects_found()) {
…
}
У вас что, функция хранит результат своей работы в каком-то внешнем состоянии? Может быть, вы ещё Stateful-код пишете и глобальными переменными балуетесь? А с параллелизацией никогда не имели дел?
Функция, выполняющая работу, должна возвращать инкапсулированный объект, из которого можно достать результат операции. Должно быть так:
# псевдокод
if ( find_defects().getResult().isSuccess() ) {… }
Или хотя бы так:
# псевдокод
try { find_defects(); } catch Exception $e {… }
А совсем правильно — так:
# псевдокод:
successManager.subscribe('find_defects.results.success');
failManager.subscribe('find_defects.results.fail');
function find_defects() {
# do some work…
dispatch(results)
}
Так оно будет правильно работать в распределённых системах.lair
17.09.2015 11:11+2Ну началось, война функциональщиков с ООП-шниками…
burjui
17.09.2015 13:50В данном примере функциональщина ни при чём, это базовые принципы разработки ПО. Совершенно очевидно, что с оригинальным find_defects() пропустить ошибку настолько просто, насколько это вообще возможно — для этого даже не нужно писать код. Лучше использовать исключения. И «совсем правильный вариант» мне тоже не нравится, т.к. нужно озаботиться получением экземпляров successManager и failManager (ну и названия!) и не забыть подписаться на соответствующие события — и это только для find_defects().
lair
17.09.2015 15:02В данном примере функциональщина ни при чём, это базовые принципы разработки ПО.
… которые отличаются в зависимости от используемого стиля.
Лучше использовать исключения.
Если обнаружение дефектов — это нормальная ветка сценария, то исключения бросать нельзя. В алгоритме выше дело обстоит именно так, поэтому забудьте про исключения.
А теперь представьте себе, что поиск дефектов заканчивается не просто признаком «нашли/не нашли», а одним из трех состояний (не нашли/нашли, но можно принять в работу/нашли и в работу принимать нельзя), причем для второго и третьего из них нужен список найденных дефектов (а для третьего — еще и разбитый на приемлимые и неприемлимые). Вот в ФП я это реализую легко:
type DefectInspectionResult = | None | Acceptable of defects : seq<Defect> | Unacceptable of acceptable : seq<Defect> * unacceptable : seq<Defect>
И что важно, когда я буду делать по нему pattern matching, компилятор предупредит меня, если я не учту вариант.
А в ООП (на примере C#)? Мне надо либо порождать дополнительный класс-результат с кучкой полей, которые все равно надо проверять, либо использоватьout(который геморроен), либо просто использовать поля класса, в котором уже происходит обработка. Собственно, если у нас на один процесс обработки создается один экземпляр класса, никаких фундаментальных проблем с этим не будет. Здравствуй, рефакторинг Method Object.burjui
17.09.2015 21:10Если обнаружение дефектов — это нормальная ветка сценария, то исключения бросать нельзя. В алгоритме выше дело обстоит именно так, поэтому забудьте про исключения.
Точно, это меня переклинило, и я отчего-то решил, что find_defects() должен работать как check_defects(), а забыв о семантике слова find.
А принцип «явное лучше неявного» одинаково хорошо работает и в ООП, и в ФП, и совет про возвращение значения из функции вместо установки поля класса — как раз из этой серии.lair
17.09.2015 23:11А принцип «явное лучше неявного» одинаково хорошо работает и в ООП, и в ФП, и совет про возвращение значения из функции вместо установки поля класса — как раз из этой серии.
Лучше-то лучше, но не всегда удобно.
VolCh
22.09.2015 14:56По семантике find_defects как раз должна возвращать результат поиска (пускай пустой), а вот check_defect может изменять состояние какого-то объекта (например, заполняя его приватный defect_list), не возвращая ничего.
FYR
17.09.2015 10:04+1На самом деле автор прав лишь отчасти. Требования к «хорошему» коду очень сильно зависят от требования непосредственно к продукту, способа его использования, перспектив поддержки, перспектив развития.
Пример — надо быстро выйти на рынок, а спустя три месяца после начала написания первого релиза для первого заказчика мы уже запланировали ресурсы для переписать все по другому. Первый релиз не будет поддерживатся и фикситься — его пишем для «застолбить место». — Так и нечего тратить время на красивый код — важно писать быстро.
Другой пример — мы вообще плохо представляем предметную область или пишем а-ля библиотеку или нечто что должно строиться из кубиков — тут начинаются фабрики, стратегии, фасады, интерфейсы.
Или все тоже самое но поддерживать это будут 100 студентов — там будет совсем другое.
Или пишем нечто абстрактное в академических целях или статью про говнокод :)

raacer
17.09.2015 11:33+6Простите, но, похоже, Вы просто не умеете пользоваться комментариями. Хорошие комментарии должны описывать не действия кода, а причину этих действий. Сюда относятся смысловые описания фич, отсылки на документацию о странных, неочевидных или малоизвестных особенностях, отсылки к багрепортам в сторонних проектах при написании заплаток и костылей по независящим от Вас причинам, и т.д. Также очень удобно пользоваться комментариями для описания действия блока кода, ибо создание функций и процедур только для самодокументируемости приведет к огромному количеству этих самых функций и процедур, в которых потом черт ногу сломит.
Если ваша методология разработки предполагает, что заранее известно как будет выглядеть конечный продукт, или если для вашей компании не является роскошью содержание технического писателя, то не менее половины комментариев можно убрать за счет наличия хорошей, подробной и актуальной спецификации продукта.
Пример плохого комментария:
// Check if the user is returning. if (user.isReturning) { alert('Try our premium features!'); }
Пример хорошего комментария:
// Don't scare away new users by telling them about paid features. // We want to let them see how good our service is before asking to pay. if (user.isReturning) { alert('Try our premium features!'); }
Простите за мой английский если что.
sophist
17.09.2015 13:08+1Ваш окончательный вариант алгоритма ремонта автомобиля
Кодprocedure negotiate_with_client() { check_cost(); if (!client_agree()) { pay_for_wash(); return; } find_defects(); if (defects_found()) { say_about_defects(); if (!client_agree()) { pay_for_wash_and_dyagnosis(); return; } } create_request(); take_money(); } listen_client(); if (!is_clean()) { wash(); } negotiate_with_client(); bye();
romy4
17.09.2015 13:55+1Экономя строку на переносе скобки — вы тратите мои драгоценные минуты на поиск этой скобки по коду, когда она не подсвечивается или находится за пределами половины одного экрана.

lain8dono
17.09.2015 14:29+1Попробуйте найти или написать тулзу, которая будет форматировать код по тем кодстайлам, которые нравятся именно вам.
Вообще единственная веская причина для выбора конкретного варианта отступов, положения скобочек, пробелов и прочего это кодстайл конкретного проекта.
Моё личное мнение: ориентироваться лучше не по скобочкам как таковым, а по уровню отступа. С такой точки зрения перенос скобки плох, ибо скобка воспринимается отдельным выражением. А к экономии места по вертикали можно сказать, что обычно оно и так ограничено существенно в сравнении с горизонтальным. И далеко не всегда можно перевернуть монитор.romy4
17.09.2015 14:57Тут можно было бы спорить, что скобка слишком мала, чтобы восприниматься выражением. Но читабельность — это прежде всего. Объясню почему: если я могу бегло читать код, не останавливаясь и не разбирая где же это начало блока и где конец, то мне не прийдётся листать постоянно вверх-вниз и достаточно одного прохода по коду, чтобы уловить суть не вникая при этом в детали реализации и не ища глазами в строка скобку начала блока — это тормозит и сбивает запоминание. В таком случае неважно насколько вертикально растянут код, когда в голове последовательно сложена картинка.
FiresShadow
17.09.2015 15:05Везёт же человеку: достаточно определённым образом скобки расставить, и он может за один проход понять суть кода любого качества. Как вы приобрели этот волшебный навык?
romy4
17.09.2015 15:10Не использую в разборе кода сарказмы.
lain8dono
17.09.2015 15:53Если стоит задача переспорить оппонента любой ценой, то и в этом случае вы скорее проиграете спор с сильным спорщиком. Если вы хотите по какой либо причине выиграть спор, где не подразумевается правильного ответа, то для начала надо осознать, что этого самого правильного ответа нет. Пусть это и кажется очевидным, но одно уже это знание даёт вам возможность посмотреть на вопрос со стороны. Например даёт возможность использовать в разгар спора «аргументы ниже пояса», «авторитетное мнение», «давление на жалость» и прочее вроде «а давайте тогда использовать golang — там же тоже скобочки не переносятся. Нет? Ну вот и я говорю, что в c# принято скобочки переносить на следующую строку».
То, о чём вы говорите есть причины субъективные, равно как и мои. Единственная причина выбирать субъективное решение — абсолютное большинство голосов в сторону этого решения.
Единственная абсолютно объективная причина использовать определённый способ расставления скобок — результат подброса монетки.
romy4
17.09.2015 19:08Я не спорю, а выразил своё субъективное мнение и обосновал почему. Если для вас всё иначе — можете выразить почему именно так. Ну, ещё можете минусов расставить. В любом случае, если есть реакция, значит я по-своему прав.
lain8dono
18.09.2015 04:34Если для вас всё иначе — можете выразить почему именно так.
У меня есть даже маленький пример для понимания моей точки зрения. Из двух этих листингов я выберу первый:
def add(x, y): print "x is {0} and y is {1}".format(x, y) return x + y
def add(x, y): print "x is {0} and y is {1}".format(x, y) return x + y
Я вижу начало блока не в скобке, а в его «заголовке», но при этом отчётливо вижу конец блока, будто это ruby:
def sum(x, y) x + y end
Открывающая скобка для меня похожа на пустую строку, которой я разделяю код по вертикали операторы, которые идут последовательно.
Как с вашим кодстайлом читается вот такой код:
var a = 5 { fmt.Println("a:", a) }Mrrl
18.09.2015 04:50var a = 5
{
fmt.Println(«a:», a)
}
На C++ я специально для таких случаев писал
#define block
чтобы слово block можно было поставить перед открывающейся скобкой. Тогда оно смотрелось не совсем дико.
К счастью, такие ситуации встречаются не чаще, чем раз в несколько лет.
romy4
18.09.2015 09:59Это какое-то написание кода в стиле «итальянской забастовки». Можно извратить всё что угодно таким подходом. В вашем случае в code-style-ref будет прописано, что после определения функции пустую строчку вставлять не надо. И как в примере ниже, будет прописано, что комментарий пишется над функцией, а не между её объявлением и телом. Везде надо находить золотую середину.
// function foo void foo() { } void boo() // function boo { }
Flammar
18.09.2015 12:10Читать просто глазами и читать с помощью IDE или редактора с подсветкой скобок — это очень разные вещи. Я читаю программы, по крайней мере на Java, исключительно с помощью IDE — там ещё есть такая полезная штука как подсветка переменных. Опять-таки, по части вынесения части кода в метод с говорящим названием — IDE фактически превращает код программы в гипертекст, и читаемость повышается от наличия кучи коротких методов вместо одного длинного.
kloppspb
17.09.2015 15:19Если речь идёт только о форматировании, а не об организации кода в принципе — это вообще не проблема. Любая вменяемая IDE или даже редактор позволяют сделать «как удобно» в один шорткат :)
romy4
17.09.2015 15:23Только о форматировании. Организация кода — отдельная тема. Но сколько бы любая IDE не делала код красивым, такой код, например, нельзя будет закомитить (имею в виду чужой код, если пришлось исправить в нём ошибку по таске), такой код ужасно читать в mc.
kloppspb
17.09.2015 16:35Закомитить, наверное, можно — если известен тамошний кодинг стайл. Во всяком случае отформатировать по-новому перед комитом особых проблем нет.
А насчёт mc не понял. У меня всё форматирование настроено одинаково и для эклипса (основная ide), и для комоды, и для других редакторов, и в том же mc всё нормально читается.romy4
17.09.2015 22:25Редактировать чужой code-style есть зло
kloppspb
17.09.2015 22:50Кто-то предложил его редактировать? Как раз наоборот, надо после своих правок вернуть всё как было.
Вопрос только в сложности этой процедуры и в том, как этот стайл описан (идеальный вариант, конечно, если он в принципе поддаётся автоматизации, и описан в виде набора ключей к каким-нибудь astyle/*indent*/*tidy/greatcode etc)romy4
18.09.2015 10:01На мой взгляд писать внутри чужого кода своим стилем — плохо. По крайней мере, такой контраст зрительно мешает.
kloppspb
18.09.2015 11:46Попытка номер три :)
1) Открыл чужой исходник, нажал на кнопочку, отформатировал как тебе удобно.
2) Попоравил, отладил — нажал на другую кнопочку, отформатировал как было.
А при постоянной работе с источником можно всё это и в виде хуков организовать.Mrrl
18.09.2015 16:37Проблема: когда «отформатировал как было», могли измениться положения отдельных элементов текста — комментарии, например. И текстовое сравнение выдало кучу мелких изменений, которых в действительности не существует.
А в каких ide возможна описанная картина — с двумя альтернативными настройками форматирования, переключаемыми по кнопочке?kloppspb
18.09.2015 17:20Форматирование комментариев тоже вполне описывается правилами, поддающимися автоматизации. Не, конечно, есть «авторское», но это уже из разряда исключений :)
С текстовыми сравнениями — так есть же немало утилит, которые вполне позволяют настраивать всякие вещи: meld, tkdiff, diffmerge, diffuse, smartsynchronize etc. Во всяком случае всякие мелочи типа побелов/табуляций/пустых строк они отлавливают, а всё остальное — и есть значимые различия в *одинаково отформатированых* исходниках.
>А в каких ide возможна описанная картина
В любых, которые позволяют, например, подключать внешние утилиты. То есть во всех, включая просто редакторы. Ну, я про линуксы, как в других не знаю.
Flammar
18.09.2015 12:17Поэтому надо 1) писать не в mc, а в IDE с настраиваемым стилем 2) на всём проекте унифицировать стиль.
romy4
18.09.2015 22:32+1не всегда есть IDE под рукой, чаще Sublime какой-нибудь. Да и если я открыл в IDE, то она знает мой стиль, но не знает стиля, которым написан открываемый код. Обратно вернуть к стилю не получится.
Для своих проектов стиль почти всегда унифицируется — это правило перед началом работы.kloppspb
18.09.2015 23:14О способе форматирования должен знать сам проект и передавать его вместе с исходниками. Либо в виде общеупотребительных названий (например, для сей — «BSD/Allman», «GNU», «K&R», «Whitesmiths»), либо в виде ключей к стандартным утилитам, начиная с банальных *indent.
А уж повесить вызор форматёра с нужными ключами на кнопку — это мало кто нынче не умеет :)
romy4
17.09.2015 13:59-1За свою практику я вывел одно жёсткое правило: когда код написан разборчиво (а именно: с пробелами вокруг операторов, переносом скобок, пробелами между атомарными блоками кода и без сокращений в именах переменных), то сделать такой код говно-кодом тяжело, в то же время в таком коде можно легко найти даже неправильную логику лихого школьника. Приучайте писать код читабельным и красивым.
Flammar
18.09.2015 12:14Для того, чтоб код был читабельным и красивым и писать его было при этом легко — нужны IDE с автоматическим настраиваемым форматированием и рефакторингом плюс привычка «причёсывать» код.

VladimirAndreev
17.09.2015 18:05ох, как сложно найти баланс между Дартом Копипастиусом и Дартом Ифусом…
еще и Дарт Тринариус рядом ручки потирает…

Shablonarium
18.09.2015 18:21Оператор return не позволяет вынести этот участок кода в отдельную процедуру.
whitepen
24.09.2015 17:23-1Вы так интересно пишете, что кто то де будет читать мою программу? Может и будет конечно, но обычно не правильный класс просто выбрасывается и на его место пишется новый с теми же public. Все, что за рамками public просто никого не интересует. Все красивости только в интерфейсе. Внутри разбираться некому, некогда и не зачем. Может кто то и посмотрит в качестве примера при переписывании. У каждого свое видение и логики и красивости. Это где такое интересное место, чтобы кому то смотреть внутрь кривого класса?
VolCh
24.09.2015 20:38Как минимум, придётся читать ваш код, чтобы бы понять, а что, собственно, реализовывать в новом классе, перед тем как выбросить ваш. Тестов же, покрывающих все граничные случаи нет? Или, может, имена точно описывают реализацию? Включая такие нюансы, как что возвращает метод типа find, если ничего не находит — null, false, отрицательный код ошибки, пустой массив или ещё что?
eaa
Ваша статья нарушает Ваше правило «быть коротким».
Множество приводимых Вами альтернатив нарушает Ваше правило «быть линейным».
fyudanov
Ну хоть требование самодокументированности-то не нарушено? )
matiouchkine
Это все прекрасная беллетристика, которая никак не применима к реальной жизни (к сожалению.)
Простой пример: пункт про бритву Оккама противоречит пункту про линейность. Как всегда, нужно найти компромисс и тут улинеить, а вот тут не нарушать принцип Оккама и не плодить сущности. В смысле этом ваша статья полностью подпадает под введение в нее же: красивая, стройная, неприменимая теория, обучение которой не дает ровным счетом ничего, помимо общей образованности (которая важна и нужна, разумеется).
Рецептов не существует, и именно поэтому так сложно воспитать из жуниора мастера. Смысл в том, что вы седьмым чувством определяете: тут нужно вынести вот этот кусок кода в отдельную функцию, а тут — нет. А жуниор, пока не вырастет, будет смотреть на это и думать: «чистое шаманство» (в лучшем случае), или «да он идиот, сам не знает, чего хочет, это же одинаковые куски» в худшем.
Ну и тот код, который пишут не жуниоры как правило точится по совсем другим лекалам. Как вы мне предлагаете залинеить генерацию кода? Рантайм патчинг? Несанкционированный хук? Аспекты, луа внутри песочницы? Вызов DLL на удаленной Win98, just because?
А нелинейный спагетти я прочту за минуту, вместо шестидесяти секунд. Любой не жуниор прочтет.
? вот это все, разумеется, не про то, что нужно писать говнокод. Вы правильные вещи говорите, конечно. Просто бесполезные :)
fyudanov
Вы говорите, что описанное в статье бесполезно, потому что:
1. Не всегда возможно соблюсти все советы сразу.
2. Решения все равно принимаются «седьмым чувством».
3. «Любой не-джуниор» все равно быстро прочтет адский спагетти-код (на мой взгляд, очень странное утверждение).
Если написанное в заключении к статье ничего не проясняет, то вот еще раз мое видение по данным вопросам:
1. Из того, что нельзя сделать дело идеально, не значит, что не надо делать хорошо. И тем более, что не надо понимать, что такое хорошо.
2. Я всегда стараюсь при возникновении вопросов объяснять коллегам, почему мое решение хорошее, а другое — хуже. Если не могу объяснить, то на решении не настаиваю. «Седьмое чувство» без логического обоснования — это отмазка, за которую можно спрятать все, что угодно.
3. Умеющим читать (и править) любой говнокод за минуту, статью можно игнорировать )
matiouchkine
Давайте я еще раз попробую объяснить, что я имею в виду. Вы не обижайтесь только, я сто раз же оговорился: годный текст :)
Знаете, бывают такие библиотеки, фреймворки, языки программирования даже, на которых авторы написали офигенную реализацию todo-списка и движка блога. Смотрите, как у нас тут все красиво, говорят они — и не поспоришь. Гораздо красивее, чем на любых существующих языках.
Но как только пытаешься решать задачу из реального мира — вылезает большая голодная крыса и съедает всю красоту необходимостью воздвигать костыльнуб подпорку для потолка шестнадцатого этажа.
Так же и ваша линейность, и декларативные подходы, и все прочее. Это все работает на вашем примере — прекрасно работает, не спорю. Только вот беда, у разработчика в реальном мире обычно есть еще десять мегабайт легаси и пять мегабайт написанного жуниорами и три мегабайта написанного им самим с похмелья, о нон работает #прямосейчас. Поэтому поломать все нафиг и написать красиво — как бы не вариант. Ну если мы про бизнес, а не про школьный класс.
Поэтому техника чтения спагетти, рефакторинга костылей (перекуем костыль на миксин, как большевики говорили), умение правильно оценить место, куда фикс воткнуть, и так далее — в миллион раз важнее, чем способность написать читаемый код (что, повторяб, тоже круто, но не всегда возможно.)
Вот вам пример из реальной жизни: живой проект, нужно воткнуть перпендикулярные существующим права доступа. Я написал такой код, что вы бы меня даже на собеседование не пригласили, наверное. Полностью на аспектах, горячие заплатки на классы, трассировка кода в реалтайме, половина генерируемго кода читается из строковых файлов и парсится регулярками. Кровь, кишки. Писал где-то пару недель. Покрыл тестами так, что не вздохнуть. Работает (как? — сам в шоке). За это время в дев-ветку накоммитили килобайт сто, все в тот код, который мне патчить. И мой некрасивый, нелинейный, костыльный код влился без единого конфликта. А красивый линейный — я бы до сих пор писал.
fyudanov
Без обид, спасибо за отзыв.
Просто забавно, что вы рассказываете, что все то, что я использую в своей работе ежедневно и при этом вижу результаты, оказывается, неприменимо к реальности )
Касательно вашего примера, допускаю, что при определенных обстоятельствах я бы мог поступить так же. Но при этом:
1. Осознавал бы, что время, которое я, казалось бы, выиграл, вернется в десятикратном размере в процессе поддержки кода.
2. Ни в коем случае не считал бы свою работу сделанной качественно.
3. И уж совершенно точно не стал бы утверждать, что вот это и есть реальная жизнь, а все остальное — фантазии.
nsinreal
fyudanov, matiouchkine
У каждого из вас просто-напросто разная практика. На деле, множество аутсорсинговых компаний не заморачивается качеством. Как правило долгосрочную поддержку они не оказывают, продукты педалятся быстро, умирают тоже быстро. В итоге в долгосрочной перспективе качество кода не важно. А в краткосрочной перспективе очень сложно объяснять почему нужен рефакторинг. Зато плохое качество кода приводит к тому, что проект не заканчивается раньше чем нужно, что является хорошим фактом с финансовой точки зрения кампании. Ну и оправдываться в стиле «очень много функционала, каждая новая фича пишется труднее» — это нормально и привычно всем. В некоторых компаниях очень заморачиваются на эстимейты, поэтому сделать больше, чем нужно — это неприемлемо для менеджмента.
Вообще, на разной длительности проекта и с ростом размеров кода нужно придерживаться разных правил. Глупо писать свою инфраструктуру/фреймворк когда вам нужно реализовать одну-две апих. И глупо не писать, когда апих становится много. Прикол заключается в том, что многие разработчики не понимают концепт «рефакторить все время», в итоге получаем легаси и говнокод во все бока.
Также стоит отметить, что отрефакторить что-то за один раз не всегда получается. А пока ты занимался чем-то другим другой разработчик приходит и дописывает еще херни.
matiouchkine
У меня лично очень разная практика. В идеальном мире я писал проекты с нуля, в команде людей, умнее и опытнее меня, с бесконечным временем выделенным на рефакторинг.
Но чаще приходится работать в мире реальном. В проекте, который достался тебе таким, какой есть. В который другие разработчики дописывают херни, да :)
Именно поэтому все без исключения успешные стартапы были в какой-то момент переписаны с нуля. Но это эммм… не интересно же. Ну разве что с академической точки зрения. Так то куда интереснее в горящем танке порядок наводить, чем фигачить по паттернам. С последним прекрасно справляются жуниоры под присмотром.
Ну и да: качество кода не есть просто функция его читаемости. Качество кода есть функция полезности проекту. Просто чаще всего тут прямая зависимость от читаемости и новички путают эти вещи.
VolCh
Есть две функции от параметра «исходный код», как минимум: его полезность (чаще всего доход или экономия финансов и/или времени) проекту и его цена (чаще всего расходы финансов и/или времени). Качество, грубо говоря, это соотношение этих функций. Читаемость тут лишь один из параметров обеих функций.
loz
Правила, вроде, относятся к коду, а не к статьям и подаче информации впринципе.