

Задача обогащения данных напрямую связана с темой их обработки и анализа. Обогащение нужно для того, чтобы конечные потребители данных получали качественную и полную информацию.
Сам термин "обогащение данных" — это перевод англоязычного Data enrichment, который проводит аналогию между данными и... ураном. Точно так же, как промышленники насыщают урановую руду, увеличивая долю изотопа 235U, чтобы её можно было использовать (хочется надеяться, в мирных целях), в процессе обогащения данных мы насыщаем их информацией.

Обогащение данных — это процесс дополнения сырых данных той информацией, которая в исходном виде в них отсутствует, но необходима для качественного анализа.
Конечными потребителями такой информации чаще всего являются аналитики, но могут быть и нейронные сети, пользователи приложения или предоставляемого API.
Заметим, что обогащение данных — термин широкий, и получать данные из внешних источников можно весьма разнообразными способами. Например, представим бизнес-процесс регистрации нового клиента. Если в данных этого клиента отсутствует e-mail, то взаимодействие с внешним источником в этом случае может быть буквально следующим: взяли телефон, позвонили клиенту, узнали его e-mail. Получается, этот процесс может включать в себя такие совершенно не автоматизированные операции, как обычный телефонный разговор со всеми этими «эс как доллар, "а" как русская». Это тоже можно считать обогащением данных, но данный пласт проблем в этой статье мы затрагивать не будем. Нас интересуют вполне конкретные случаи, когда данные хранятся в базе данных и именно БД служит внешним источником данных для обогащения.
Источниками сырых исходных данных могут быть:
Система кассовых платежей, которая отслеживает транзакции и отправляет в хранилище данных: время, id торговой точки, количество и стоимость купленного товара и т.д.
Логистическая система, которая отслеживает движение товара: id транспорта и его водителя, gps-координаты в заданные моменты времени, статус, маршрут и т.д.
Телеметрия с датчиков интернета вещей.
Система мониторинга инфраструктуры.
Все эти примеры объединяет то, что в них регулярно передаются относительно небольшие пакеты данных, каждый из которых имеет идентификатор. То есть каждый источник «знает» свой идентификатор и передает его вместе с пакетом данных. По этому идентификатору в хранилище данных можно получить справочную информацию об источнике.
Таким образом, типовую задачу можно сформулировать следующим образом: на вход поступают данные вида <таймстамп, идентификатор источника, содержимое пакета>, а конечному потребителю требуется соединить (в смысле join) справочную информацию об источнике из хранилища данных с идентификатором источника из сырых данных.
Как обогащаем данные
Один из вариантов решения задачи сопоставления данных — по расписанию запускать скрипты, которые подготовят подходящие для аналитиков представления. Например, это можно делать с помощью Apache Airflow. Но в любом случае потребуется ждать и сохранять данные из внешних источников.
Другой вариант — использовать инструменты потоковой обработки данных. В этом случае нужно определиться, где же всё-таки хранить справочную информацию и что будет являться Single Source of Truth (SSOT), или единым источником «истины» для справочных данных. Если хранить справочные данные в хранилище, то к нему придется каждый раз обращаться, и это может быть накладным, так как к сетевым издержкам добавится ещё и обращение к диску. Вероятно, оптимальнее хранить справочную информацию в оперативной памяти или другом горячем хранилище, например, в Tarantool.
Мы, очевидно, отдаём предпочтению именно последнему варианту, и наша схема приобретает завершенный вид.
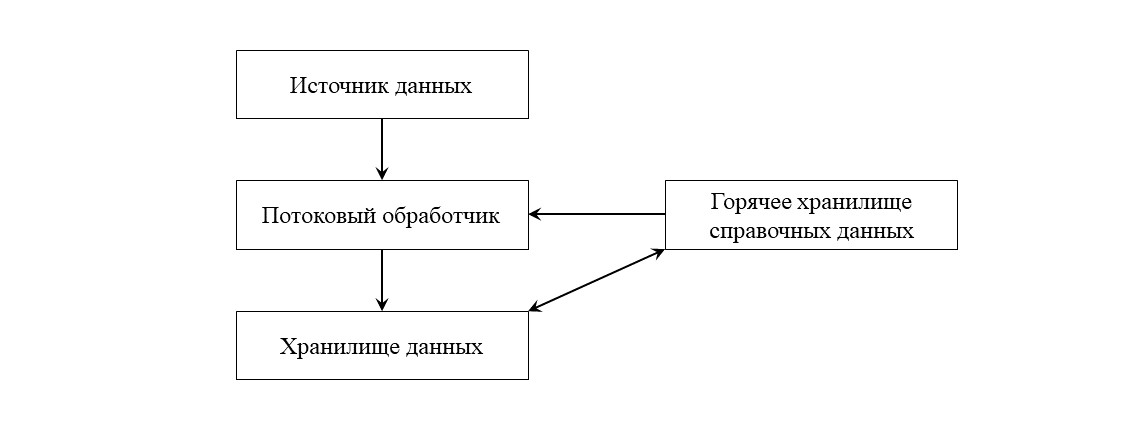
Она отличается от первой иллюстрации процесса обогащения данных тем, что появилась конкретика: процесс обогащения происходит на лету с помощью потокового обработчика, справочные данные хранятся в горячем хранилище (оперативной памяти).
Давайте посмотрим, какие плюсы и минусы мы получим, если возьмем за основу данную схему.
Преимущества потокового обогащения данных:
В хранилище всегда актуальные данные, которые готовы к использованию. В нашем динамичном мире зачастую необходимо иметь доступ к реалтайм-данным и сразу их использовать, не тратя время на дополнительную подготовку, распаковку и т.д. Потоковый обработчик, можно сказать, приносит их нам на блюдечке.
Схема хорошо масштабируется, если подобрать соответствующие технологии. С правильными инструментами можно масштабироваться под требуемую пропускную способность платформы и под объемы справочной информации.
Недостатки:
Источник «истины» для справочной информации вынесен из надёжного дискового хранилища данных в менее надёжную оперативную память. При сбое это грозит потерей всех несинхронизированных данных.
Требуется гораздо больше памяти — как оперативной, так и постоянной. В целом, для любой системы аналитики желательно иметь побольше дискового пространства и оперативной памяти, но здесь это становится обязательным условием.
Какие технологии используем
Что касается технологий, то мы выбираем более-менее устоявшиеся на рынке решения с открытым исходным кодом и хорошей документацией, учитывая совместимость.
Выбранный стек технологий:
Apache Kafka — источник данных и брокер очередей;
Apache Spark — потоковый обработчик данных;
Apache Ignite — горячее хранение справочной информации;
Greenplum и Apache Hadoop— хранилище данных.
В выборе Greenplum мы немного поступились совместимостью. Связать его со Spark — не совсем тривиальная задача, для этого не существует стандартного open source коннектора (подробнее рассказывали в этой статье). Поэтому мы разрабатываем такой коннектор сами.
В остальном набор достаточно стандартный. Hadoop держим на всякий случай, например, чтобы использовать тот же Hive поверх HDFS вместо Greenplum.
Каждое из этих решений масштабируемо. Поэтому мы можем построить любую архитектуру, в зависимости от объемов справочной информации и ожидаемой пропускной способности.
Итак, вот окончательные очертания нашей схемы обогащения данных.

Версии, которые используем:
Apache Spark 2.4.6.
Apache Ignite 2.8.1.
Apache Kafka 2.4.1.
Greenplum 6.9.0.
Apache Hadoop 2.10.1.
Обращаю на это внимание, потому что от версий выбранных компонент зависит совместимость и возможность этих компонент взаимодействовать. Например, если нужно, чтобы Apache Spark писал данные в базу данных Greenplum, это может стать отдельной проблемой, и версии также будут важны. Наш коннектор на текущий момент работает именно со Spark v2, для Spark v3 его нужно отдельно дорабатывать.
Что в результате
Если объединять данные, применяя предложенную схему обогащения, в дальнейшем аналитикам не потребуется каждый раз делать JOIN-запрос, что сэкономит как ценное время людей, так и машинные ресурсы.
Но есть и ограничения, связанные с тем, что source of truth, по сути, находится в оперативной памяти. Поэтому при редактировании справочной информации надо напрямую работать с Ignite — через интерфейсы самого Ignite. Кроме этого, нужен аккуратный механизм синхронизации, чтобы кэш Ignite был персистентным. У Ignite есть собственный механизм для записи на диск, но все же Ignite больше ориентирован на работу в ОЗУ, поэтому для резервирования справочной информации в хранилище данных лучше использовать что-нибудь специально для этого предназначенное, например, Airflow.
Полезные ссылки, чтобы понять, как строить взаимодействие между Spark и Ignite и насколько это уже проработанный механизм:
О том, как можно использовать содержимое базы Apache Ignite в качестве объекта dataframe, можно почитать здесь.
Видео (на английском) про развитие Apache Ignite и его специфику, где-то с 12 минуты будет про использование Hadoop+Spark+Ignite.
Каким образом использовать Apache Spark + Apache Ignite (с хорошим и детальным техническим разбором), можно прочитать в блоге Сбербанка здесь же на Хабре.
Информацию о том, каким образом можно взаимодействовать с содержимым базы Apache Ignite через обычный интерфейс SQL, можно найти здесь.
Пользуясь случаем: мы расширяем отдел систем обработки данных. Если вам интересно заниматься с подобного рода задачами, пишите мне в личку, в телеграм @its_ihoziainov или на job@itsumma.ru с пометкой «data engineering».
Если вы уже сталкивались с такого рода задачами, делитесь мнением в комментариях, задавайте вопросы — они, как известно, очень помогают находить лучшие решения. Спасибо.