

Недавно я описывал, как осуществлять запуск и управление Java Flight Recorder (JFR). Теперь решил затронуть тему записи в JFR метрик, специфичных для приложения, а также способов их анализа в Java Mission Control (JMC). Это позволяет расширить понимание происходящего с приложением и значительно упростить анализ производительности и поиск узких мест.
В предлагаемой статье мы рассмотрим пример создания своих событий, записываемых в JFR, и то, как эти данные могут помогать в анализе работы приложения. Будет рассмотрен только один частный пример, не претендующий на полноту описания всех возможностей и нюансов использования JFR и JMC.
Что такое JFR?
NOTE: JFR - это механизм легковесного профилирования Java-приложения. Он позволяет записывать и впоследствии анализировать огромное количество метрик и событий, происходящих внутри JVM, что значительно облегчает анализ проблем. Более того, при определённых настройках его накладные расходы настолько малы, что многие (включая Oracle) рекомендуют держать его постоянно включённым везде, в том числе на продуктовых серверах, чтобы в случае возникновения проблем сразу иметь полную картину происходившего с приложением. Просто мечта любого SRE!
Раньше этот механизм был доступен только в коммерческих версиях Java от корпорации Oracle версии 8 и более ранних. В какой-то момент его реимплементировали с нуля в OpenJDK 12, затем бэкпортировали в OpenJDK 11, которая является LTS-версией. Однако вот OpenJDK 8 оставалась за бортом этого праздника жизни. Вплоть до выхода апдейта 8u272, в который наконец-то тоже бэкпортировали JFR. Теперь все (за редким исключением) пользователи OpenJDK могут начинать использовать эту функциональность.
Краткое описание задачи
Для начала определимся с тем, что мы собираемся мониторить и какие данные собирать.
В одном из приложений, разрабатываемых нашей компанией, реализована уникальная система контроля, досчёта и свода вводимых данных. Даже между документами, что позволяет формировать один документ из множества других автоматически.
Так как данные вводятся в табличном виде, то их обработка очень хорошо ложится на выражения наподобие формул Excel. Причём эти формулы являются фактически основной бизнес-логикой приложения, покрывая почти все потребности. У нас они называются "контрольными соотношениями".
Таким образом, для того, чтобы проверить корректность заполнения документа, досчитать промитоги или произвести свод в новый документ из пачки существующих, достаточно запустить механизм вычислений, который пройдётся по каждому разделу документа и запустит в нём соответствующие запущенной операции выражения с формулами:

Дополнительными бонусами этого подхода являются:
Возможность обратного вычисления. То есть, если в итоговом документе, после всех досчётов и сводов, выявляется ошибочное значение, источник ошибки можно достаточно легко найти, посмотрев, откуда пришли исходные данные для его вычисления.
Простота обновления. Можно выкатывать в день по несколько обновлений, которые содержат только новые строки контрольных соотношений.
Простота задания. Формулы в Excel знакомы практически всем. И такая форма задания достаточно проста, чтобы её могли использовать не только разработчики, но и аналитики, техподдержка и кто угодно ещё.
Однако при этом имеется и обратная сторона медали: достаточно легко получить слишком тяжёлую для вычисления формулу. Типичные проблемы:
Инварианты, неинвариантны при вычислении.
В обработку попадает слишком много неправильно отфильтрованных данных, которые на самом деле не нужны.
При вычислении формулы генерируются слишком сложные запросы в БД.
Генерируется слишком много запросов в БД, где может быть только один запрос.
Используется слишком много памяти из кучи.
И т. п.
Как видно, различных проблем довольно много, и решаться они могут по-разному: или путём написания более корректной формулы, или путём создания новой операции, которую можно использовать в формулах. Реже приходится исправлять уже имеющиеся операции для оптимизации производительности.
Понятно, что для быстрой диагностики и поиска узких мест требуется некий инструмент профилирования, заточенный под данную конкретную задачу.
Изначально для таких целей был создан простой аудит, который пишет в файлы время выполнения как всех формул целиком, так и каждой части формулы в отдельности. Плюс некоторую метаинформацию, облегчающую понимание, что именно вычислялось. Так можно диагностировать эффективность вычисления и понимать, где требуется доработка.
Только подобный подход всё равно имеет изъян. Не всегда можно легко понять причину медленного вычисления результата. Помимо просто неэффективно написанной формулы, могут быть и другие факторы:
Сработал GC.
Долго отвечала БД.
Было много запросов в БД.
CPU был занят чем-то ещё.
И т. д.
И сопоставлять медленную работу конкретной формулы с этими внешними факторами приходится "на глазок", сталкивая аудит с мониторингом. Что неудобно, неточно и зачастую напоминает гадание на кофейной гуще.
Наше приложение до сих пор работает на Java 8 (хотя и есть планы по обновлению версии Java). А значит, мы не могли использовать JFR, как это можно было делать в Java 11 и старше.
Но времена меняются, и JFR пришёл в Java 8 с обновлением 8u272. Теперь появляется возможность использовать его для большого количества задач вообще и для аудита вычисления контрольных соотношений в частности.
Так давайте посмотрим, как это можно сделать и что от этого получить.
Описание своих событий JFR
Для того, чтобы записать в JFR какую-либо свою информацию, необходимо объявить события, которые будут записываться. Сделать это можно двумя путями: статически и динамически.
Статический способ подразумевает написание своего класса, унаследованного от класса jdk.jfr.Event. А динамический способ подразумевает не написание самого класса, а создание описания модели через метаданные.
В данной статье мы будем использовать первый способ. А те, кого интересует второй, могут обратиться к JavaDoc документации класса jdk.jfr.EventFactory.
Модель событий
Всё, что записывает JFR, - это события, объекты специальных классов, унаследованных от jdk.jfr.Event и содержащих как предопределённые поля, так и предметные, специфичные для конкретного типа события. Каждое такое поле доступно для просмотра и анализа при открытии результирующего файла с записью.
Стандартные поля наследуются от класса jdk.jfr.Event, но не объявлены явно, а формируются при старте JVM. Это сделано для того, чтобы в случае отключенного JFR не создавать накладные расходы на работающее приложение. К таким полям относятся:
eventType- идентификатор типа события. Может отличаться от реального программного типа и предназначен для стабильности идентификации события, невзирая на жизненный цикл приложения и возможные переименования программного класса;startTime- время начала события. Точнее, момент времени, в который был создан объект события;endTime- время завершения события. Точнее, момент времени, когда был вызван метод Event.commit();duration- длительность события. То есть разница междуendTimeиstartTime;eventThread- поток, в котором было создано событие.
Также можно объявлять свои дополнительные поля. Но эти поля могут быть только следующих типов:
Примитивные типы:
boolean,char,byte,short,int,long,floatиdouble.Строки:
java.lang.String.Потоки:
java.lang.Thread.Классы:
java.lang.Class.
Никакие другие типы не допускаются. Это требуется для обеспечения максимально компактного хранения записи JFR на диске. Соответственно, требуется внимательно подходить к выбору типов полей и не использовать, например, String для хранения времени, когда для этого достаточно использовать long и аннотацию jdk.jfr.Timestamp.
Возвращаясь к нашей задаче, получается, что необходимо создать три вида событий:
InterpreterReportEvent- для измерения времени выполнения всех вычислений для одного конкретного отчёта.InterpreterSectionEvent- для измерения времени выполнения вычислений для раздела.InterpreterRelationEvent- для измерения времени выполнения отдельного вычисления.
Также в каждое из этих событий необходимо добавить метаинформацию, которая может помочь в идентификации и диагностике событий. Таким образом, мы получаем следующие классы:
Код классов событий
@Name("ru.krista.consolidation.interpreter.Report")
public class InterpreterReportEvent extends Event {
public long key;
public String docState;
public String caption;
public String formCode;
public String formName;
public long endDate;
public long beginDate;
public long deliveryDate;
public long evalDate;
public long checkDate;
public int deliveryYear;
public String collectingPeriod;
public String inputMode;
public String operationUuid;
public boolean assignAsEquality;
public String section;
public long formDescriptorId;
}@Name("ru.krista.consolidation.interpreter.Section")
public class InterpreterSectionEvent extends Event {
public String key;
public String name;
}@Name("ru.krista.consolidation.interpreter.Relation")
public class InterpreterRelationEvent extends Event {
public int order;
public long sectionId;
public long relationId;
public int rowsCount;
public long groupId;
public String groupName;
public String sectionName;
public transient CheckRelationResult results;
}Как видно, это весьма простые классы, унаследованные от jdk.jfr.Event.
Также каждый класс помечен аннотацией jdk.jfr.Name. Эта аннотация необходима для явного задания имени события. По умолчанию в качестве имени берётся полное имя класса. Но со временем полное имя класса может поменяться, и тогда будет утеряно соответствие метрик между новой и старой версиями приложения. Чтобы этого избежать, рекомендуется явно задавать имя событий и не менять их.
Ещё один интересный момент находится в классе InterpreterRelationEvent. Это поле result. Оно, с одной стороны, имеет неподдерживаемый тип, с другой, помечено как транзиентное. В результате JFR будет игнорировать его при сохранении. А нужно оно по техническим причинам: для того, чтобы туда сохранился статус результата вычисления в бизнес-логике, и в конце можно было бы вынуть этот результат в виде строки и положить в событие (просто такая особенность реализации, которую я посчитал уместным продемонстрировать тут).
Добавляем описания для модели событий
На данный момент мы описали саму модель в таком виде, что её уже можно использовать, но это будет несколько неудобно. Дело в том, что в инструментах анализа записей JFR модель в данном виде будет отображаться, как есть. И это не очень-то информативно видеть, например, на поле с именем `evalDate` и пытаться понять, что это значит. Да и формат отображения получится не дата, а число, которое тоже ещё как-то интерпретировать надо:

Чтобы это исправить, модель необходимо разметить специальными аннотациями:
Аннотированные классы событий
@Name("ru.krista.consolidation.interpreter.Report")
@Label("КС: Отчёт")
@Category({"consolidation", "interpreter", "report"})
@SuppressWarnings({"squid:S1820", "pmd:TooManyFields"})
public class InterpreterReportEvent extends Event {
@Label("ID")
public long key;
@Label("Состояние")
public String docState;
@Label("Заголовок")
public String caption;
@Label("Код формы")
public String formCode;
@Label("Имя формы")
public String formName;
@Timestamp
@Label("Дата окончания сбора")
public long endDate;
@Timestamp
@Label("Дата начала сбора")
public long beginDate;
@Timestamp
@Label("Дата сдачи")
public long deliveryDate;
@Timestamp
@Label("Дата последнего досчёта")
public long evalDate;
@Timestamp
@Label("Дата последней проверки")
public long checkDate;
@Label("Год сдачи")
public int deliveryYear;
@Label("Период сдачи")
public String collectingPeriod;
@Label("Режим параметров вычислений")
public String inputMode;
@Label("Идентификатор операции")
public String operationUuid;
@Label("Запущена проверка КС")
public boolean assignAsEquality;
@Label("ID секции")
public String section;
@Label("ID дескриптора формы")
public long formDescriptorId;
}@Name("ru.krista.consolidation.interpreter.Section")
@Label("КС: Секция")
@Category({"consolidation", "interpreter", "report", "section"})
public class InterpreterSectionEvent extends Event {
@Label("ID")
public String key;
@Label("Имя")
public String name;
}@Name("ru.krista.consolidation.interpreter.Relation")
@Label("КС: Контрольное соотношение")
@Category({"consolidation", "interpreter", "report", "section", "relation"})
public class InterpreterRelationEvent extends Event {
@Label("Порядок вычисления")
public int order;
@Label("ID секции")
public long sectionId;
@Label("ID контрольного соотношения")
public long relationId;
@Label("Обработано строк")
public int rowsCount;
@Label("ID группы КС")
public long groupId;
@Label("Имя группы КС")
public String groupName;
@Label("Имя секции")
public String sectionName;
public transient CheckRelationResult results;
}В новом варианте модели использованы следующие дополнительные аннотации:
jdk.jfr.Label - для задания человекочитаемых имён как у самих типов событий, так и у полей.
jdk.jfr.Timestamp - для задания формата отображения полей с датами.
jdk.jfr.Category - для задания категории событий. В Java Mission Control эта информация используется для группировки всех типов событий в некое подобие дерева.
Существует ещё некоторое количество аннотаций, как минимум для форматирования отображения значения полей. Но в данном конкретном примере они не используются, так что оставлю их для самостоятельного изучения в JavaDoc.
В результате события окажутся сгруппированными:

и поля будут иметь осмысленные описание и формат:

Создание экземпляров событий и их запись
Для того, чтобы записать событие JFR, необходимо выполнить следующие действия:
Создать новый объект события.
Заполнить поля созданного объекта.
Вызвать метод Event.begin() перед выполнением соответствующего действия.
Вызвать метод Event.commit() после этого действия.
В случае с событием InterpreterSectionEvent описанные события могут иметь следующий вид:
void calcSection(ReportSection section) {
// Создание объекта события
InterpreterSectionEvent event = new InterpreterSectionEvent();
// Наполнение события метаданными
event.key = section.getKeyString();
event.name = section.getReportFormSection(session).getName();
// Фиксация времени начала события
event.begin();
// Выполнение полезной работы
calcSectionInternal(section);
// Фиксация времени завершения события
// и запись его в выходной файл JFR
event.commit();
}Всё выглядит довольно просто, но надо не забывать, что в настройках JFR запись данного события может быть отключена. В таком случае получится, что операции по заполнению полей объекта события будут проделываться вхолостую, создавая бессмысленные накладные расходы. И если в данном примере это не выглядит чем-то страшным, то для события InterpreterReportEvent накладные расходы уже могут быть весьма существенными.
Для того, чтобы избегать подобного рода накладных расходов, можно запросить у объекта события статус его активности методом Event.isEnabled(). В таком случае приведённый ранее пример должен принять следующий вид:
void calcSection(ReportSection section) {
// Создание объекта события
InterpreterSectionEvent event = new InterpreterSectionEvent();
// Если запись данного типа событий активирована в JFR
if (event.isEnabled()) {
// Наполнение события метаданными
event.key = section.getKeyString();
event.name = section.getReportFormSection(session).getName();
}
// Фиксация времени начала события
event.begin();
// Выполнение полезной работы
calcSectionInternal(section);
// Фиксация времени завершения события
// и запись его в выходной файл JFR
event.commit();
}Причём экранировать подобным образом вызовы методов begin() и commit() не обязательно, так как механизм JFR гарантирует отсутствие накладных расходов, если событие отключено в настройках.
Но это не единственный способ оптимизации конструирования объекта события. Дело в том, что в настройках JFR, помимо полного отключения записи события, может ещё присутствовать настройка записи события, только если длительность этого события превысила некоторый порог. Таким образом, если необходимо сделать какие-то действия непосредственно перед вызовом метода commit(), нужно проверить, а действительно ли это событие будет записано или оно будет отброшено как слишком короткое. Для этого необходимо использовать метод Event.shouldCommit().
Вот как это выглядит при записи события InterpreterRelationEvent:
void calcRelation(
TreeAndRelation tar,
CheckRelationResult checkRelationResult,
PrimaryReportSection section) {
// Создание объекта события
InterpreterRelationEvent event = new InterpreterRelationEvent();
// Если запись данного типа событий активирована в JFR
if (event.isEnabled()) {
// Наполнение события метаданными
event.order =
tar.getRelation().getOrder() != null ?
tar.getRelation().getOrder() : 0;
event.relationId = tar.getRelation().getId();
if (tar.getRelation().getGroup() != null) {
event.groupId = tar.getRelation().getGroup().getId();
event.groupName = tar.getRelation().getGroup().getName();
}
ReportFormSection formSection = section.getReportFormSection(session);
event.sectionId = formSection.getId();
event.sectionName = formSection.getName();
}
// Фиксация времени начала события
event.begin();
// Выполнение полезной работы
calcRelationInternal(tar, checkRelationResult, section);
// Если продолжительность события превысила заданный порог
if (event.shouldCommit()) {
// Записываем статистику выполнения
event.rowsCount = checkRelationResult.getRowsCount();
}
// Фиксация времени завершения события
// и запись его в выходной файл JFR
event.commit();
}В данном примере видно, что экранировано не только сложное формирование метаинформации на случай, если событие будет полностью отключено, но также экранирован сбор результатов вычисления непосредственно перед коммитом. Таким образом, мы можем полностью избежать ненужных накладных расходов в зависимости от настроек JFR.
Настройка событий в конфигурации JFR
В предыдущей статье я описывал, как создать свой файл настроек JFR с помощью Java Mission Control. На этот раз отредактируем такой файл вручную, чтобы добавить в него настройки для вновь созданных событий.
Для этого можно добавить в .jfc файл следующие строки:
<event name="ru.krista.consolidation.interpreter.Relation">
<setting name="enabled">true</setting>
</event>
<event name="ru.krista.consolidation.interpreter.Report">
<setting name="enabled">true</setting>
</event>
<event name="ru.krista.consolidation.interpreter.Section">
<setting name="enabled">true</setting>
</event>Тем самым активируются все три типа событий. Тут важно отметить, что в качестве имени события необходимо использовать тот идентификатор, который задавался в аннотации jdk.jfr.Name.
Если по какой-то причине нас не интересуют короткие события, то это также можно настроить. Например, чтобы игнорировать события короче секунды, необходимо дополнить настройки следующим образом:
<event name="ru.krista.consolidation.interpreter.Relation">
<setting name="enabled">true</setting>
<setting name="threshold">1 s</setting>
</event>
<event name="ru.krista.consolidation.interpreter.Report">
<setting name="enabled">true</setting>
<setting name="threshold">1 s</setting>
</event>
<event name="ru.krista.consolidation.interpreter.Section">
<setting name="enabled">true</setting>
<setting name="threshold">1 s</setting>
</event>
В дальнейшем для этой статьи использовался первый вариант конфигурации без порога по времени.
Анализ результатов в Java Mission Control
Как произвести запись JFR, подробно рассматривалось в предыдущей статье. Сейчас же рассмотрим, как можно проанализировать записанную информацию.
Настройка отображения событий
Прежде всего открываем файл с записью JFR в Java Mission Control:

Переходим в окно Outline.
Ищем в дереве пункт Event Browser.
В основном окне появляется список всех возможных типов событий. Наши события оказываются в самом низу.
Теперь мы видим список всех записанных событий наших типов и можем их просматривать. Но в таком представлении сложно что-то понять. Гораздо лучше будет вывести эти события в отдельное представление и как-то их там организовать.
Для этого щелкаем правой кнопкой мыши по узлу consolidation и из контекстного меню выбираем пункт Create a new page using the selected event types:

Теперь разберёмся с получившимся новым представлением:

Выбираем представление в дереве представлений.
В открывшемся представлении виден раздел фильтра. Этот фильтр определяет набор типов событий, с которыми мы работаем. Видно, что добавились все три наших типа.
Но сейчас нам этот фильтр только мешает, так что его можно убрать с помощью соответствующей кнопки.
Внизу отображается таблица со всеми событиями выбранных типов.
Но нам нужен не список, а графики, так что переключаемся на соответствующую вкладку.

В итоге мы увидим столбчатую диаграмму количества событий всех типов за равные промежутки времени (1). Такая диаграмма бесполезна, так что перенастроим всё под свои нужды. Прежде всего сгруппируем события по типам, нажав на кнопку группировки (2) и выбрав пункт Event Type.
В результате появится раздел группировки со списком отображаемых типов и количеством событий каждого типа в отдельности:

Если выбирать отдельные пункты списка группировки (или несколько пунктов сразу), то на диаграмме будут отображаться только данные по событиям выбранных типов. Но нам надо или выбрать все типы, или не выбирать ни одного (что по сути то же самое).
Далее уберём диаграмму количества событий, так как она нам не нужна: щёлкнем правой кнопкой по диаграмме и в подменю Show in Bar Chart уберём отметку с пункта Count:
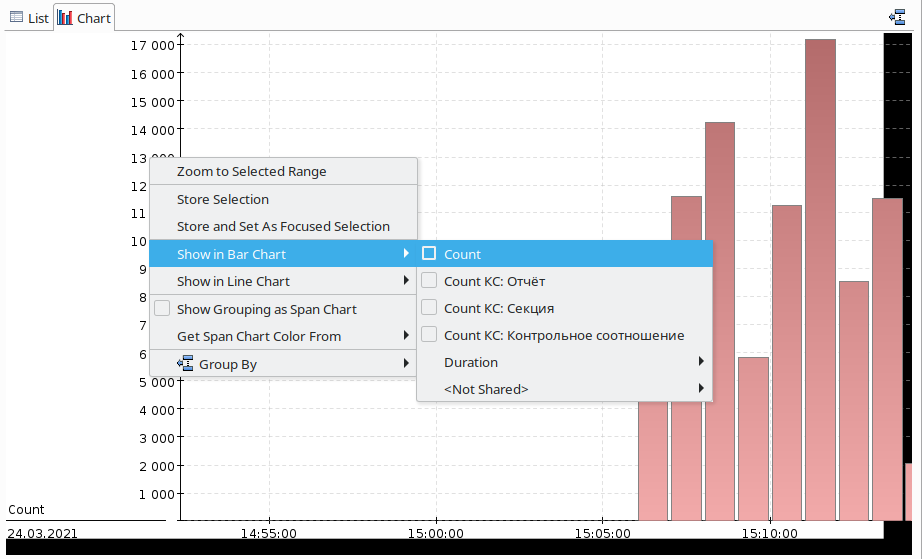
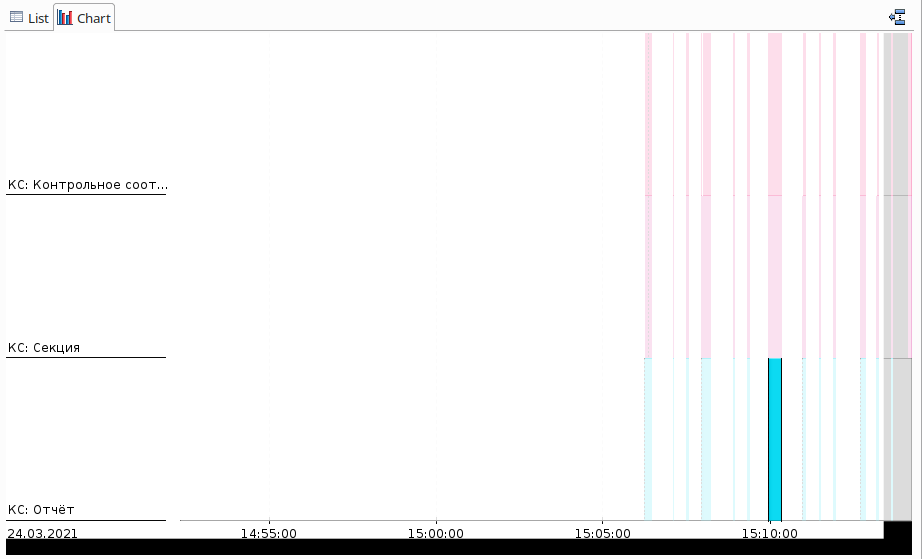
А теперь самое главное: в том же контекстном меню выберем пункт Show Grouping as Span Chart. В результате сформируется диаграмма, показывающая временные отрезки, в течение которых выполнялось каждое отдельно взятое событие:

И вот с этим представлением уже очень удобно работать.
Анализ выполнения отдельного отчёта
Например, чтобы проанализировать выполнение отдельного отчёта, достаточно отмасштабировать график по границам события вычисления этого отчёта. Самый быстрый способ - кликнуть по интересующему нас событию левой кнопкой мыши, чтобы выделить его:
И сразу правой кнопкой - по нему же (не снимая выделения), а затем выбрать пункт Zoom to Selected Range. Тогда график автоматически отмасштабируется, и станут видны детали в событиях выполнения секций и отдельных вычислений:

Теперь нам стало понятно, на какие вычисления стоит обратить внимание в первую очередь, так как они дольше всего выполняются, и к какой секции и какому отчёту они относятся.
Но не всегда так просто выделить отдельный отчёт, так как приложение многопоточное и множество вычислений может быть запущено одновременно. В результате на данном графике эти события будут накладываться одно на другое, и понять, что происходит, не получится.
В таком случае можно проделать следующее:

Переключиться на табличное представление событий.
В разделе группировки выделить только тип события отчётов. Тогда в таблице останутся события только этого типа.
Далее дважды щёлкаем на столбце
Duration, чтобы отсортировать события по убыванию по этому параметру.И выбираем самое первое событие как самое длительное, а значит, самое интересное для анализа.
Далее - в окне
Properties:Щёлкаем правой кнопкой мыши по пункту
Event ThreadИ выбираем пункт меню
Store and Set As Focused Selection
В результате все события в открытом файле JFR отфильтруются по данному потоку глобально во всех представлениях. Таким образом мы избавимся от перекрывающих друг друга событий и сможем нормально анализировать отдельно взятый отчёт.
Сопоставление с другими метриками JFR
Хорошо. Мы определили самые проблемные вычисления. Но как понять причину их долгого выполнения?
И тут мы подходим к тому, ради чего вообще имеет смысл записывать прикладные метрики в JFR: их можно сопоставлять с большим набором имеющихся в JFR событий. Продемонстрирую это на примере.
Для этого в браузере событий выберем два типа событий: Socket Read и Socket Write. Затем щёлкнем правой кнопкой мыши по выделенным пунктам и выберем Store Selection:

Далее переходим в наше отображение, открываем фильтр событий и из контекстного меню фильтра выбираем: Add Filter from Selection ? Event Types Tree Selection ? Event Type is included in set of 2:

События чтения и записи из сокета добавятся под отдельной группой OR:

Но это некорректный фильтр. По этому события надо перетащить в группу к остальным и удалить лишний OR. В результате на диаграмме мы увидим ещё и информацию о том, когда происходил активный сетевой обмен в процессе вычислений (что зачастую и является причиной долгого выполнения):

А так как события чтения и записи из сокета фиксируют ещё и стектрейс, то, выделив участок с большим количеством чтений, мы сможем узнать, какой именно код привёл к этим чтениям:

Часто этого достаточно, чтобы выявить первопричину неоптимального выполнения.
Заключение
В данной статье мы рассмотрели, как можно создавать свои типы событий JFR в приложении и использовать их для анализа поведения приложения. Но это только верхушка айсберга. Очень большое количество аспектов не было рассмотрено. Java Flight Recorder совместно с Java Mission Control представляют из себя весьма мощную пару инструментов, позволяющую анализировать и глубже понимать особенности выполнения приложений. А если приложить немного труда и добавить свои прикладные события, то это может дать безграничные возможности для анализа работы приложения как на тестовых стендах, так и на боевых серверах.
Надеюсь, статья послужит толчком для более полного использования данных инструментов и поможет гораздо быстрее диагностировать проблемы, а то и вовсе избегать их.