

Если вы когда-нибудь сталкивались с распределёнными СУБД или системами обработки данных, то слышали о двух теоремах: CAP и PACELC, определяющих грани возможных конфигураций этих систем. Споры об их универсальности не утихают до сих пор, однако альтернативы, способные полностью заместить данные научные изыскания, ещё не сформулированы и вряд ли в ближайшее время появятся. Поэтому всем, кто работает с распределёнными системами, необходимо учитывать эти теории. Мы, команда разработки СУБД Jatoba, также столкнулись с противоречивостью теорем, детально разобрались и готовы помочь всем, кто только начинает работу с ними.
Введение
В 2000 году Эрик Брюер выдвинул гипотезу, суть которой можно описать так: в распределённой системе невозможно обеспечить одновременное выполнение всех трёх условий: корректности, доступности и устойчивости к разделению узлов CAP (Consistency-Availability-Partition tolerance). За 20 лет применения теорема действительно доказала свою состоятельность, однако показалась недостаточной. Так в 2010 году появилась PACELC как расширение CAP, которое гласит, что в случае разделения сети в распределённой компьютерной системе необходимо выбирать между доступностью и согласованностью, но даже если система работает нормально в отсутствии разделения, нужно выбирать между задержками и согласованностью.
Как это работает, рассмотрим далее.
CAP
Смысл теоремы прост: при наличии сетевого разделения – (P)artitioning система может выбрать одно из двух: доступность – (A)vailability или консистентность – (С)onsistensy.
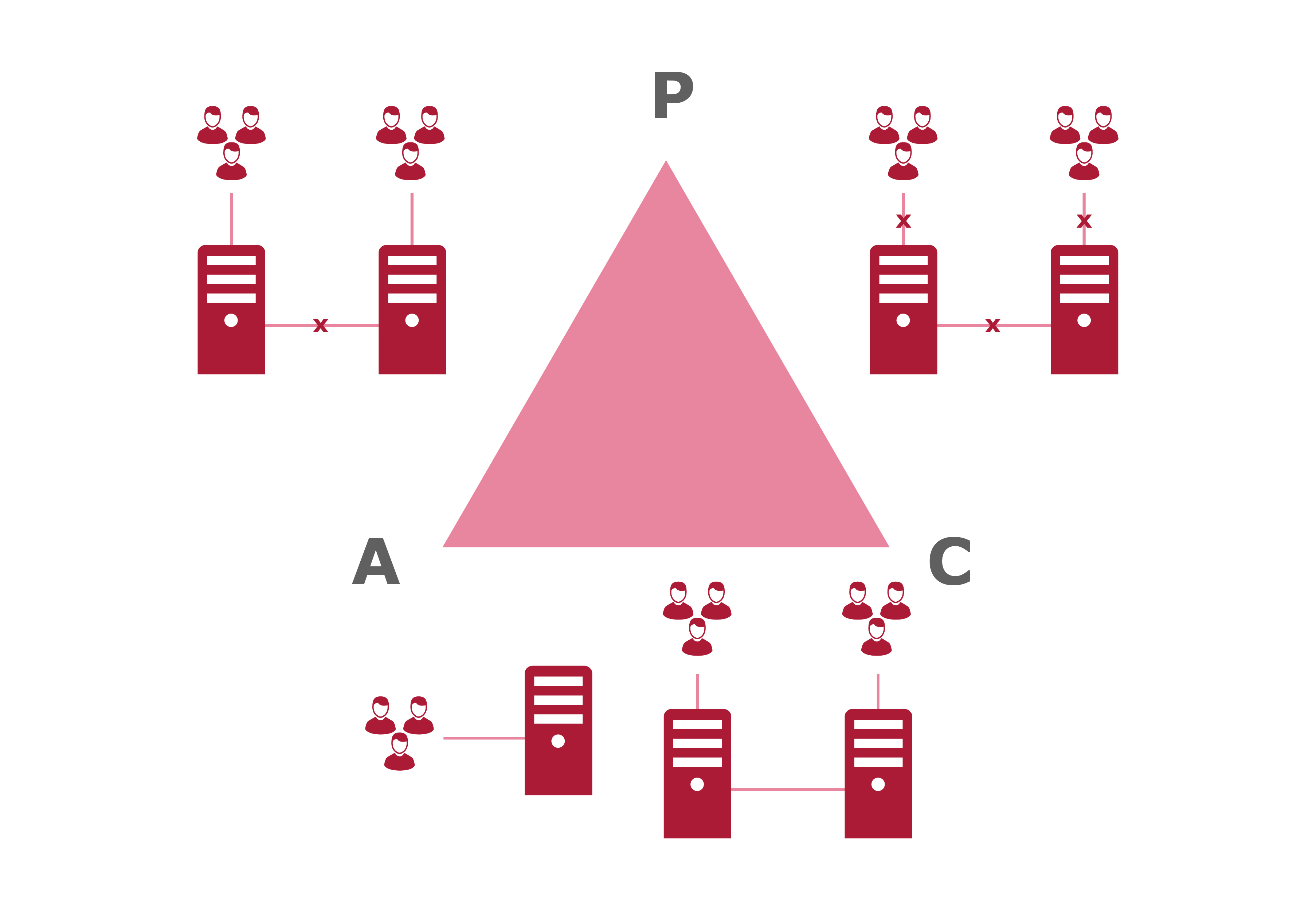
Грани CAP можно описать так:
PA – в случае сетевого разделения узлов системы она продолжает отвечать пользователям на запросы, при этом не гарантируя консистентности данных.
PC – в случае сетевого разделения узлов системы она прекращает отвечать пользователям на запросы, данные остаются консистентными.
CA – в случае отсутствия сетевого разделения данные доступны и консистентны (нормальный режим работы).
Далее рассмотрим основные сложности, возникающие при применении этих утверждений на практике.
Проблемы (P)artitioning
В тексте теоремы сказано: «The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes». Вольный перевод: «Система продолжает работать несмотря на то, что часть сообщений не доставлена или задержана между узлами», то есть, если данные от одного узла не поступили на другой, оба узла продолжают работать. Проблема заключается в том, что если мы возьмём за протокол связи любую сетевую связь LAN/WAN, то сразу подпишемся под тем, что система подвержена разделению, ибо нет такой сети, которая гарантирует 100 % доставки информации. Как следствие, любая система должна быть P (A/C). Однако, согласно CAP, любая такая система не может быть консистентной и доступной одновременно. Решить данную задачу легко – пересмотрев (читай: подстроив под ситуацию) смыслы консистентности и доступности. Об этом расскажем дальше.
Если мы взглянем шире на теорию систем, убедимся, что системы и протоколы связи между ними могут быть абсолютно разные, в том числе и такие, в которых отсутствие доставки информации между частями системы является поломкой. Как следствие, любая несломанная система такого типа гарантирует передачу информации между своими распределёнными частями, а значит, классические CA-системы вполне могут существовать, хотя, скорее всего, вне контекста LAN/WAN.
Проблема(С)onsistensy
Одна из причин, по которой теорема до сих пор подвергается критике, – это допущение её текстом множественных трактовок. Например, «Consistency — consistency (С) equivalent to having a single up-to-date copy of the data». Вольный перевод: «Консистентность – это когда у нас есть копия последних изменений данных». Также мы видим следующее: «Every read receives the most recent write or an error». Вольный перевод: «Каждое прочтение получает самую последнюю запись или ошибку», то есть упоминание именно строгой консистентности. Актуальный вопрос – лишится ли система (С)onsistensy, если это не строгая консистентность? Опять возвращаемся к особенностям работы системы в LAN/WAN-сетях. В большинстве случаев из-за сетевых задержек системы работают в режиме асинхронности с механизмом окончательной консистентности (eventual consistency), и это расценивается как абсолютно нормальное и правильное состояние распределённой системы. Все мы прекрасно понимаем, что в этом случае изменение, сделанное, например, в Калифорнии, не может в тот же момент быть зафиксировано в Бангкоке. Следуя трактовке из теоремы, можно сказать, что не подверженная разделению система, асинхронно работающая в LAN/WAN-сетях, не может иметь в своих характеристиках букву С.
Наглядное сравнение строгой и окончательной консистентности:
Строгая консистентность – результат выполнения параллельных операций гарантированно представляется как последовательное выполнение действий. Данный вид консистентности возможен в синхронных системах. Пример: правильна только запись результата в виде: 1 – 2 – 3.
Окончательная консистентность гарантирует, что в итоге запись будет того вида, в каком она была сделана, но в каждый момент времени может представлять собой только часть записи. Пример: правильны записи результата в любом виде: 1 / 1 – 2 / 2 – 3 / 1 – 2 – 3. Более того, счёт видов консистентности в современных распределённых системах идёт на десятки, а если прибавить их гибриды и производные, то это станет темой отдельной книги.
Проблемы (A)vailability
Само определение доступности в теореме звучит примерно так: «Every request receives a (non-error) response, without the guarantee that it contains the most recent write». Вольный перевод: «Любой запрос к функционирующему узлу распределённой системы завершается корректным откликом, однако без гарантии, что ответ содержит наиболее актуальные данные». И опять перед нами вопрос: – а что, если данные частично доступны?
Простой пример:
ЗАПРОС> Хочется посмотреть результаты всех чемпионатов по шахматам за всё время.
ОТВЕТ> Данные недоступны. (Вероятно, какая-то часть системы (к примеру, шард) стала недоступна).
ЗАПРОС> Хочется посмотреть результаты Венгерских чемпионатов по шахматам 2019 год. ОТВЕТ> Смотрите на здоровье.
И вот после просмотра статистики о Венгерских шахматных турнирах за 2019 год на ум приходит понимание, что система, которая отдала данные, в терминах CAP-теоремы – недоступна, так как запрос прошёл на доступный узел, но полных данных он предоставить не смог. Речь не про актуальность, а именно про полноту.
Только когда пользователь сузил свой запрос, данные смогли быть предоставлены, так как данная виртуальная система работает в том числе и в режиме частичной доступности. Другими словами, в данном примере часть системы доступна и может удовлетворять запросы пользователей, но в классическом понимании CAP-теоремы даже если 0,0001 % данных будут недоступны, то система недоступна, так как при запросе всех данных корректного отклика не будет.
Рассмотрим ещё один пример частичной доступности.
Есть 2 пользователя. Иван хочет писать в систему, а Ольга хочет читать из неё. Но случилось так, что единственный мастер в системе «упал», а слейв по какой-либо причине не сделал failover и всё так же принимает только Read-only-запросы. Что в итоге: Иван, не получив результата, пошёл пить чай с лимонным кексом. Ольга получила нужные данные, обработала их и присоединилась к Ивану, пока тот не съел весь кекс.
Время ответа
Данный параметр не рассматривается в CAP-теореме. Если в высоконагруженном и геораспределённом кластере из 10 узлов «погибает» 9, то едва ли оставшийся мастер может обслужить всех пользователей в сроки, которые пользователи назовут удовлетворительными. В итоге, часть пользователей будут считать систему недоступной и окажутся правы. Если говорить откровенно, не совсем понятно, почему это не взволновало автора CAP настолько, чтобы явно упомянуть этот параметр в своей работе. Можно предположить, что в 2000-е годы людей не так сильно волновала прямая зависимость «более высокая скорость работы системы = более высокая конверсия». Данное предположение разбивается о доткомы… Да, во времена бума доткомов конкуренция за клиентов была сумасшедшая, тем более потребителей в интернете было гораздо меньше, а культура онлайн-шопинга только зарождалась. Поэтому выбор хостинга, систем хранения и обработки данных и иных прикладных систем был ориентирован в том числе на скорость отклика и сильно беспокоил архитекторов того времени.
Данное утверждение в 2001 году подтвердил Якоб Нильсен, сказав, что, если в течение 10 секунд пользователь не получает информацию у вас на сайте, он ищет её в другом месте. В своей книге 2003 года «Веб-дизайн» он сузил пороговые значения до 6 секунд. Проблематика времени ответа на запрос, не рассмотренная в CAP-теореме, получила развитие в PACELC профессора Дэниела Абади.
Итог для мистера Брюера
Мы надеемся, что то количество «разоблачений», опровержений и дискуссий вокруг CAP-теоремы, которое можно встретить на просторах интернета, не сильно задело её автора Эрика Брюера. На наш взгляд, её суть – показать фундаментальные особенности систем и переложить догму тройственной ограниченности их мира. Многочисленные трактовки и разночтения как самих терминов, так и совокупностей их значений, привели к спорам, недопониманию, и как следствие, к недовольству. Это объяснимо, ведь при проецировании теоремы на реальный мир появляется много вопросов. В своей работе мы приняли, что теория остаётся теорией, а на практике всё гораздо сложнее. Система не может быть «чёрной» или «белой», реализуя какие-либо опции доступности или консистентности, необходимо находить компромисс, однако для полной картины мы пользуемся PACELC.
PACELC
В данной теореме мы видим не просто треугольник СAP, а условное дерево, которое можно представить в виде if (P, then A or C, else L or C), где есть уже знакомые нам (P)artitioning, (A)valability, (С)onsistency, а также новое понятие (L)atency – общее время задержки от момента выполнения действия пользователем до момента предоставления ему результата. Краткий вид (L)atency – время на доставку действия пользователя к системе + время на обработку действия + время на доставку ответа от системы к пользователю. (E)lse – иначе. Простыми словами, при условии наличия сетевого разделения (P)artitioning система может выбрать одно из двух: доступность (A)vailability или консистентность (С)onsistensy, иначе (E)lse, если сетевого разделения нет, система может выбрать одно из двух: время задержки (L)atency или консистентность (С)onsistensy. Опишем две стороны работы одной системы:
1. При сетевом разделении система или консистентна, или доступна.
2. Без сетевого разделения – или консистентна, или обеспечивает высокую скорость ответа.
Система, которая стремится к консистентности и при сетевом разделении, и без него, обозначается так: PC/EC.
Отметим, что хоть PACELC и расширила возможности для классификации систем, добавив параметр «скорость ответа», но одновременно унаследовала и остальные проблемы классической CAP-теоремы, которые были рассмотрены выше. В CAP в режиме без сетевого разделения система классифицировалась как CA – доступная и консистентная, но как мы уже говорили, обсуждая проблемы консистентности, географически сильно разнесённая система в режиме строгой консистентности будет иметь весьма существенное время отклика. Вероятно, такую систему доступной назвать сложно, особенно если она и высоконагруженная. Поэтому в PACELC было решено расширить CA-грань, где система будет либо быстро отвечающей, либо строго консистентной.
Так как грани теоремы PACELC стали более детально описывать системы, то назначения систем, использующих разные комбинации граней, могут быть не до конца понятны. Рассмотрим их более детально.
PA/EL
Внутренние бизнес-процессы больших компаний, в частности internet-based, зачастую ставят два условия для решений, предназначенных для хранения и обработки данных: высокая доступность (A) при разделении (P) системы иначе (E) высокая скорость ответа (L).
Выпадение сегмента системы так же, как и высокие показатели скорости работы с данными, гарантированно приводит к серьезным издержкам, как финансовым, так и репутационным. Единовременная консистентность данных здесь играет менее важную роль, хотя тоже существенную.
Примерами БД, которые изначально построены максимально приближено к этой конфигурации, можно назвать:
Cassandra – база данных для работы с системой сообщений от компании Facebook, в дальнейшем переданная Apache Foundation.
Voldemort – платформа, поддерживающая систему массовых записей и обновлений от сервисов LinkedIn (несколько лет назад, по ряду причин компания отказалась от Voldemort в пользу своего нового продукта Venice).
DynamoDB от Amazon.
Riak от Basho Technologies.
PC/EC
Как мы видим по названию, системы, которые стараются максимально приблизиться к парадигме ACID с большой долей вероятности будут жертвовать доступностью (A) в угоду консистентности (С), используя огораживание (fencing) при разделении (P) в распределённых системах. В неразделённых (E)lse системах «под нож» пойдёт скорость (L)atency, так как консистентность – это один из столпов ACID. Также объяснимо применение синхронных коммитов при репликации или максимально приближённых к ним внутренних решений.
Примеры тут:
VoltDB/H-Store – ACID-совместимые БД, разработаны группой ученых. К созданию причастен и сам автор PACELS теории, профессор Дэниель Абади.
Megastore – проект от компании Google, для закрытия определённых ACID-потребностей в собственных облачных хранилищах.
PC/EL
Данная архитектура при разделении стремится оставаться консистентной, а в случае без сетевых разделений, фокусируется на скорости ответа, отводя консистентность на второй план. Классическим, но не идеальным примером данной архитектуры стала PNUTS – база данных, разработанная компанией Yahoo!, которая в распределённых средах обеспечивает «Timeline (С)onsistency» на всех репликах. Для обеспечения данного уровня консистентности система может стать недоступной при отключении реплики мастера. Не сразу понятно, зачем мы идем на компромиссную (С)onsistency при условии, что (A)valability так и не достигнута. Именно это и заставило профессора Абади ввести (L)atency и расширить стандартную CAP-теорему. Тут мы видим суть крупных бизнесов вроде Amazon и Yahoo!, где (L)atency стоят огромных денег. Не используя надёжной системы общей синхронизации, а предоставляя только «Timeline (С)onsistency» для каждой реплики, они повышают общую скорость отклика системы, то есть ради (L)atency жертвуют всем. Однако при определённых настройках PNUTS (A)valability может быть гарантирована.
PA/EC
При наличии сетевого разделения системы ставка делается на доступность, а при отсутствии распределения – на консистентность. Со слов самого автора теории PACELS – In Memory Data Grid, решения в определённых конфигурациях имеют характеристики PA/EC. В частности, решение Hazelcast может быть сконфигурировано с использованием специальной настройки гибридной синхронности. В случае разделения – (P)artitioning, сконфигурированная таким образом система не даст консистентности, но предоставит (A)valability, а в (E)lse и строгую (С)onsistency.
Послесловие
Завершая разговор о теоремах CAP и PACELC, мы ещё раз хотим сказать, что поставить штамп на свою систему можно, лишь не разобравшись в сути теорем. Практически любая система может быть сконфигурирована под запросы бизнеса. Но даже если есть какое-то ограничение, мы понимаем, что гетерогенность среды, в которой система работает, позволяет нам конфигурировать несколько систем в одну большую, практически с бесконечной вариативностью конфигураций.
Занимаясь разработкой СУБД Jatoba, построенной на ядре Postgres, для обеспечения приближения к PA-системе «из коробки» мы решили разработать свою утилиту для контроля и управления кластером – JaDog. JaDog – это кроссплатформенный модуль, который размещается на серверах БД для мониторинга состояния ноды и её управления в составе кластера через удобный веб-интерфейс. В дальнейшем мы расскажем, как с помощью JaDog построить отказоустойчивый кластер, покажем, как сервис реагирует на всевозможные ситуации (switchover / failover / rewind и т.д.) во время использования и поговорим о планах развития данного модуля.
Над статьей работали: Сиренко Евгений, Рожков Денис.