

А не пора ли нам шардить коллекции?
Не-е-е:
- у нас нет времени, мы пилим фичи!
- CPU занят всего на 80% на 64 ядерной виртуалке!
- данных всего 2Tb!
- наш ежедневный бекап идет как раз 24 часа!
В принципе, для большинства проектов вcё оправдано. Это может быть еще прототип или круг пользователей ограничен… Да и не факт, что проект вообще выстрелит.
Откладывать можно сколько угодно, но если проект не просто жив, а еще и растет, то до шардинга он доберется. Одна беда, обычно, бизнес логика не готова к таким "внезапным" вызовам.
А вы закладывали возможность шардинга при проектировании коллекций?
Эта статья для продвинутых разработчиков.
Для тех, кто планирует шардинг своего кластера.
Для тех, кто уже шардировал кластер ранее, но админы все еще плачут.
Для тех, кто руками перемещал jumbo-чанки.
Сначала, мы будем учится жить со слонами.
Потом, мы их победим, но не сможем вернуться назад.
Всем привет, от команды разработки Smartcat и наших счастливых админов!
Мы разберём распространенный сценарий, который обычно мешает нам равномерно распределять данные. И опишем способ ослабления требований к ключу шардирования, который при этом не приведет к деградации производительности нашего кластера.
Зачем нам шардинг
Шардинг — штатная возможность горизонтального масштабирования в MongoDB. Но, чтобы стоимость нашего шардинга была линейной, нам надо чтобы балансировщик MongoDB мог:
- выровнять размер занимаемых данных на шард. Это сумма размера индекса и сжатых данных на диске.
- выровнять нагрузку по CPU. Его расходуют: поиск по индексу, чтение, запись и агрегации.
- выровнять размер по update-трафику. Его объем определяет скорость ротации oplog. Это время за которое мы можем: поднять упавший сервер, подключить новую реплику, снять дамп данных.
Конечно, мало толку будет от нового шарда, если на него переместится только пара процентов данных или не дойдет нагрузка на CPU или update-трафик.
Особенности шардинга в MongoDB
Как мы знаем балансировщик MongoDB при отсутствии ограничений (превышение размера данных на шард, нарушение границ зон) выравнивает только количество чанков на шард. Это простой, надежный и сходящийся алгоритм.
Есть документация про лимиты количества чанков и про порядок выбора размещения чанка.
Этот алгоритм и определяет главные ограничения на балансируемые данные:
- Ключ шардирования должен быть высокоселективный. В противном случае мы не получим достаточного числа интервалов данных для балансировки.
- Данные должны поступать с равномерным распределением на весь интервал значений ключа. Тривиальный пример неудачного ключа — это возрастающий int или ObjectId. Все операции по вставке данных будут маршрутизироваться на последний шард (maxKey в качестве верхней границы).
Самое значимое ограничение — гранулярность ключа шардирования.
Или, если сформулировать отталкиваясь от данных, на одно значение ключа должно приходиться мало данных. Где "мало" — это предельный размер чанка (от 1Mb до 1Gb) и количество документов не превышает вот эту вот величину.
К сожалению, в реальной жизни, не всегда удается подогнать модель данных под эти требования.
Бизнес логика требует слонов
Теперь давайте посмотрим, с чем мы будем сталкиваться при проектировании бизнес логики.
Я рассмотрю только самый чувствительный для шардирования случай, который заставляет наши данные группироваться в неравномерные объемы.
Рассмотрим следующий сценарий:
- мы шардируем коллекцию работ
- работа принадлежит только одному проекту
- идентификатор проекта равномерно распределен (а если это не так, то помогает хешированный индекс)
- большая часть поисковых запросов знает только идентификатор проекта
- число работ на проект не лимитировано. Могут быть проекты с одной работой, а могут быть и гиганты с миллионом работ.
Пример модели:
{
_id: ObjectId("507c7f79bcf86cd7994f6c0e"),
projectId: UUID("3b241101-e2bb-4255-8caf-4136c566a962"),
name: "job name 1",
creation: ISODate("2016-05-18T16:00:00Z"),
payload: "any additional info"
}Как может выглядеть логика выбора ключа шардирования?
Совершенно точно, в качестве первого поля стоит взять projectId. Он есть в большинстве запросов, т.е. бОльшая часть запросов будет направлена роутером на нужный шард.
Теперь, надо выбрать второе поле ключа или оставить только первое.
Например, у нас 20% запросов используют только поле name, еще 20% только поле creation, а остальные опираются на другие поля.
Если в ключ шардирования включить второе поле, то крупные проекты, те у которых объем работ не помещается в одном чанке, будут разделены на несколько чанков. В процессе разделения, высока вероятность, что новый чанк будет отправлен на другой шард и для сбора результатов запроса нам придётся обращаться к нескольким серверам. Если мы выберем name, то до 80% запросов будут выполняться на нескольких шардах, тоже самое с полем creation. Если до шардирования запрос выполнялся на одном сервере, а после шардирования на нескольких, то нам придется дополнительную читающую нагрузку компенсировать дополнительными репликами, что увеличивает стоимость масштабирования.
С другой стороны, если оставить в ключе только первое поле, то у нас "идеальное" линейное разделение нагрузки. Т.е. каждый запрос с полем projectId будет сразу отправлен на единственный шард. Поэтому имеет смысл остановиться на этом выборе.
Какие риски есть у этого выбора:
- у нас могут появляться не перемещаемые jumbo-чанки. При большом объеме работ в одном проекте мы обязательно превысим предельный размер чанка. Эти чанки не будут разделены балансировщиком.
- у нас будут появляться пустые чанки. При увеличении проекта, балансировщик будет уменьшать диапазон данных чанка для этого проекта. В пределе, там останется только один идентификатор. Когда большой проект будет удален, то на этот узкий чанк данные больше не попадут.
Оба этих случая несколько искажают KPI штатного балансировщика. В первом случае чанк вообще не перемещается. Во втором, он перемещается, но это не приводит к смещению данных. С течением времени, мы можем получить ситуацию когда число пустых чанков превышает число чанков с данными, а еще часть чанков не перемещаемые.
В общем, мы можем посмотреть текущее распределение данных или просто прикинуть развитие проекта и допустить, что хоть jumbo-чанки и будут появляться, но их должно быть не много.
Проблемы с масштабированием
Итак, мы, вопреки ожиданиям, набрали достаточно неперемещаемых чанков, чтобы это стало заметно. То есть буквально, случай из практики. Вы заказываете админам новый шард за X$ в месяц. По логам видим равномерное распределение чанков, но занимаемое место на диске не превышает половины. С одной стороны весьма странное расходование средств было бы, а с другой стороны возникает вопрос: мы что же, не можем прогнозировать совершенно рутинную операцию по добавлению шарда? Нам совсем не нужно участие разработчика или DBA в этот момент.
Что интересно, на этапе проектирования схемы данных, у нас и нет особого выбора. Мы не можем предсказать характер использования на годы вперед. А владельцы продукта очень не охотно формулируют строгие ограничения при проектировании. Даже оглядываясь назад, не всегда понятно, как можно было бы перепроектироваться, чтобы успеть все сделать тогда. Так что продолжаем работать с тем шардированием, которое заложили.
Ну, самое топорное решение — просто назначить зоны размещения коллекции на новые сервера, чтобы на старых остались только неперемещаемые чанки. Конечно, о предсказуемости занимаемого места речи не идет.
Еще можно увеличить максимальный размер чанка, но это глобальный параметр для всего кластера.
Можно попытаться перемещать чанки в ручную, но это может привести к блокировке данных на длительное время и все равно нет гарантии переноса.
Надеюсь, тут все уже запуганы и потеряли надежду. ;)
Решение
Попробуем сначала поправить основную боль администрирования.
Конечно, не хочется заново писать балансировку данных, нам надо просто "попросить" существующий балансировщик перекинуть часть чанков туда, где есть неиспользуемое место. Вариантов у нас два.
1-й воспользоваться командой moveChunk — прямое указание балансировщику о перемещении конкретного чанка.
2-й воспользоваться командой addTagRange — привязка диапазона значений ключа шардирования к некоторому шарду и их группе.
В обоих случаях потребуется также точное знание размера чанка. Это можно сделать командой dataSize, которая возвращает некоторую статистику по объектам в коллекции на заданном интервале ключей.
Предварительное прототипирование 1-го варианта выявило дополнительные особенности.
Команды moveChunk не отменяют работы штатного балансировщика. Он вполне может принять решение об обратном переносе. Тут надо блокировать работу штатного балансировщика. Или кроме перемещения больших чанков на недогруженный шард, надо искать на нем маленькие чанки и синхронно перемещать их на перегруженный шард.
Данные dataSize вычисляются "долго", и при этом устаревают. На практике получается, что надо просканировать некоторое количество чанков, прежде чем найдешь чанк больше среднего. В идеале, надо искать самые большие перемещаемые чанки, т.е. некоторые варианты распределения данных в коллекции могут нам значительно замедлить сканирование.
Массовые сканирования dataSize ухудшают отзывчивость сервера на боевых запросах.
Ну и остается тупиковая ситуация, когда все чанки кроме jumbo просто равны по размеру. В этом случае перемещать просто нечего, или опять же придется блокировать работу штатного балансировщика.
По совокупности проблем с прямой балансировкой, я решил развивать балансировку через привязку диапазона значений ключа шардирования.
Основная идея проста.
Давайте подберем такие диапазоны ключей на каждам шарде, чтобы в итоге части коллекции занимали одинаковый размер на шардах.
Диапазоны ключей привязываются к тегу, а не к шарду. А сам шард может содержать несколько тегов. Поэтому для упрощения дальнейшего описания и работы условимся, что на каждый шард мы добавляем по одному тегу с названием этого шарда. Это позволит привязывать диапазон ключей на конкретный шард.
Процесс выравнивания разделим на 2 основных этапа:
Первый этап — это предварительное разбиение. Оно по сути дефрагментирует данные на непрерывные отрезки на каждый шард.
Второй этап — коррекция границ ключей. Этот этап можно повторять периодически, ориентируясь по фактическому занимаемому месту на диске.
Группировка данных
Данные в шардированной коллекции разбиваются на чанки — интервалы значений ключа шардирования. При штатной работе, балансировщик распределяет чанки по шардам по мере разделения данных без учета их соседства.
Нам же, наоборот, нужно сгруппировать чанки по шардам так, чтобы на одном шарде все чанки принадлежали одному интервалу ключа шардирования. Это позволит разделять такие интервалы минимальным числом границ.
Итак, коллекция уже шардирована.
- Читаем все ее чанки из коллекции
config.chunksс сортировкой по возрастанию ключа{min: 1} - Распределяем чанки по шардам, так чтобы их было примерно одинаковое количество. Но при этом все чанки на одном шарде должны объединяться в один интервал.
Например:
У нас есть три шарда — sh0, sh1, sh2 с одноименными тегами.
Мы вычитали поток из 100 чанков по возрастанию в массив
var chunks = db.chunks.find({ ns: "demo.coll"}).sort({ min: 1}).toArray();Первые 34 чанка будем размещать на sh0
Следующие 33 чанка разместим на sh1
Последние 33 чанка разместим на sh2
У каждого чанка есть поля min и max. По этим полям мы выставим границы.
sh.addTagRange( "demo.coll", {shField: chunks[0].min}, {shField: chunks[33].max}, "sh0");
sh.addTagRange( "demo.coll", {shField: chunks[34].min}, {shField: chunks[66].max}, "sh1");
sh.addTagRange( "demo.coll", {shField: chunks[67].min}, {shField: chunks[99].max}, "sh2");Обратите внимание, что поле max совпадает с полем min следующего чанка. А граничные значения, т.е. chunks[0].min и chunks[99].max, всегда будут равны MinKey и MaxKey соответственно.
Т.е. мы покрываем этими зонами все значения ключа шардирования.
Балансировщик начнёт перемещать чанки в указанные диапазоны.
А мы просто ждем окончания работы балансировщика. Т.е. когда все чанки займут свое место назначения. Ну за исключением jumbo-чанков конечно.
Коррекция размера
Продолжим пример выше и возьмем конкретные значения ключей. Первоначальная настройка будет выглядеть так:
sh.addTagRange( "demo.coll", {shField: MinKey}, {shField: 1025}, "sh0");
sh.addTagRange( "demo.coll", {shField: 1025}, {shField: 5089}, "sh1");
sh.addTagRange( "demo.coll", {shField: 5089}, {shField: MaxKey}, "sh2");Вот так будет выглядеть размещение чанков:

Командой db.demo.coll.stats() можно получить объем данных, которые хранятся на каждом шарде. По всем шардам можно вычислить среднее значение, к которому мы хотели бы привести каждый шард.
Если шард надо увеличить, то его границы надо перемещать наружу, если уменьшить, то внутрь.
Так как уже явно заданы диапазоны ключей, то балансировщик не будет их перемещать с шарда на шард. Следовательно, мы можем пользоваться командой dataSize, мы точно знаем данные какого шарда мы сканируем.
Например, нам надо увеличить sh0 за счет h1. Границу с ключем будем двигать в бОльшую сторону. Сколько именно данных мы сместим перемещением конкретного 34-го чанка, мы можем узнать командой dataSize с границами этого чанка.
db.runCommand({ dataSize: "demo.coll", keyPattern: { shField: 1 }, min: { shField: 1025 }, max: { shField: 1508 } })Последовательно сканируя чанки по одному мы мы можем смещать границу до нужного нам размера sh0.
Вот так будет выглядеть смещение границы на один чанк

Вот пример команд для фиксации нового состояния границ в конфигурации кластера.
Мы сначала удаляем пару интервалов со старыми значениями границ, потом заводим новые интервалы с актуальными значениями границ.
sh.removeTagRange( "demo.coll", {shField: MinKey}, {shField: 1025}, "sh0");
sh.removeTagRange( "demo.coll", {shField: 1025}, {shField: 5089}, "sh1");
sh.addTagRange( "demo.coll", {shField: MinKey}, {shField: 1508}, "sh0");
sh.addTagRange( "demo.coll", {shField: 1508}, {shField: 5089}, "sh1");После применения команд балансировщик самостоятельно переместит 34-й чанк на нужный нам шард. Конечно, нет необходимости менять границы после каждого сканирования чанка. Мы можем учесть полученный эффект, продолжить сканирование и сформировать уже итоговый пакет изменений границ. Таким образом, мы можем выровнять размер коллекции по шардам с точностью до максимального размера чанка.
Конечно, в процессе сканирования нам будут попадаться jumbo-чанки. Но ничего страшного, мы их просто игнорируем и переносим границу через него без учета эффекта от перемещения.
В общем случае, мы можем планировать произвольное распределений данных таких коллекций на шардах кластера.
Выгодные особенности этого подхода:
- до смещения границ, данные не перемещаются. Мы можем их сканировать без опасения, что эта информация устареет. Ну конечно, исключая работу приложения для которого и заведена эта БД.
- команда
dataSizeприменяется только к перемещаемым данным. Мы не сканируем лишнего. - путь к целевому состоянию непрерывный. Т.е. мы можем проводить частичные коррекции, например если видим, что сканирование идет долго и реальное распределение данных успевает сильно измениться.
Дополнительные возможности
Вообще, на практике требуется выравнивание используемого объема диска на шардах, а не только части шардированных коллекции. Частенько, нет времени или возможности проектировать шардирование вообще всех БД и коллекций. Эти данных лежат на своих primary-shard. Если их объем мал, то его легко учесть при коррекции размера и просто часть данных оттащить на другие шарды.
С течением времени, особенно после частых удалений, будут образовываться пустые чанки. Не то чтобы они теперь сильно мешают, но их может быть сильно больше чанков с данными. Чтобы они не заставляли страдать роутер, было бы хорошо их прибрать. Раньше (до дефрагментации) их надо было найти, переместить к другому чанку-соседу на один шард, потом запустить команду mergeChunks. Перемещение нужно, т.к. команда объединяет только соседние чанки на одном шарде.
Есть даже скрипты для автоматизации, но они долго работают, и есть один тикет с печально низким приоритетом.
Теперь все значительно проще. Соседние чанки и так на одном шарде. Можно объединять хоть весь интервал целиком. Если он конечно без jumbo-чанков, их надо исключить. Есть на интервале пустые чанки или нет, это уже не важно. Балансировщик заново сделает разбиение по мере добавления или изменения данных.
Почти итог
Итак, проблема решена.
Хорошо, что не пришлось заменять или сильно вмешиваться в работу штатного балансировщика. Он продолжает рулить другими коллекциями или диапазонами данных. А в наших настроенных диапазонах он выполняет разделение чанков и таскает чанки между серверами как мы попросим.
Наши плюсы:
- точная балансировка занимаемого размера
- лучшее распределение update-трафика
- минимальное сканирование при коррекциях
- бесплатная уборка пустых чанков
- минимальные допуски на запасное/неиспользуемое дисковое пространство на каждом шарде
- мы всегда можем удалить привязки диапазонов ключей и вернуться к исходному состоянию
Минусы:
- требуется настройка и сопровождение привязок диапазонов ключей.
- усложняется процесс добавления нового шарда.
Но это было бы слишком скучно… Время победить слонов и не вернуться!
Победа над слонами!
Как мы уже отмечали, единственная причина неперемещаемых чанков — недостаточная селективность ключа шардирования. Мы сами снижали селективность ключа для привязки запроса к шарду. Но мы уже сгруппировали данные, а теперь мы можем этим коварно воспользоваться!
Можно увеличить селективность ключа шардирования, если добавить к нему второе поле с достаточной селективностью. Поле может быть любым. Подойдет даже _id.
Вспомним пример модели:
{
_id: ObjectId("507c7f79bcf86cd7994f6c0e"),
projectId: UUID("3b241101-e2bb-4255-8caf-4136c566a962"),
name: "job name 1",
creation: ISODate("2016-05-18T16:00:00Z"),
payload: "any additional info"
}Ранее мы выбрали ключ шардирования {projectId: 1}
Но теперь при проектировании можно выбрать любые уточняющие поля для ключа шардирования:
{projectId: 1, name: 1}{projectId: 1, creation: 1}{projectId: 1, _id: 1}
А если вы пользуетесь MongoDB версии 4.4 и выше, то там есть удобная функция — уточнение ключа шардирования на существующих данных.
Данные дефрагментированы, а это дает нам гарантии того, что основной объем документов работ с одинаковым projectId будет находиться на одном шарде. Как это выглядит на практике?
Вот иллюстрация примеров размещения работ по чанкам. В случае, если мы выбрали ключ шардирования {projectId: 1, _id: 1}
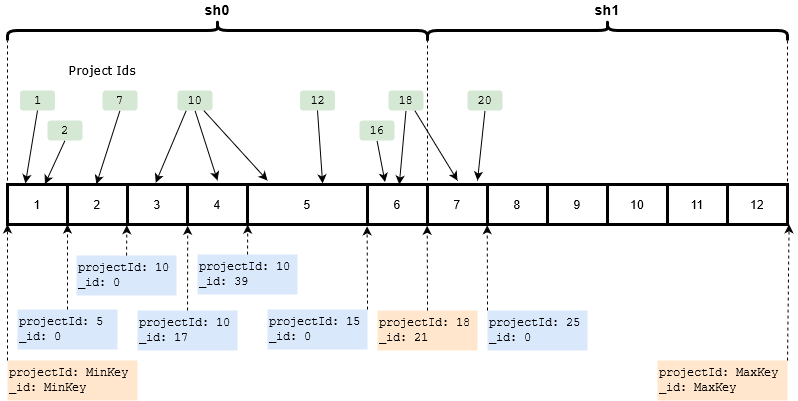
Здесь, для упрощения примера, идентификаторы представлены целыми числами.
А термином "проект" я буду называть группу работ с одинаковым projectId.
Некоторые проекты будут полностью умещаться в один чанк. Например, проекты 1 и 2 размещены в 1м чанке, а 7-й проект во 2-м.
Некоторые проекты будут размещены в нескольких чанках, но это будут чанки с соседними границами. Например, проект 10 размещен в 3, 4 и 5 чанках, а проект 18 в 6 и 7 чанках.
Если мы будем искать работу по ее полю projectId, но без _id, то как будет выглядеть роутинг запросов?
Планировщик запросов MongoDB отлично справляется с исключением из плана запроса тех шардов, на которых точно нет нужных данных.
Например, поиск по условию {projectId: 10, name: "job1"} будет только на шарде sh0
А если проект разбит границей шарда? Вот как 18-й проект например. Его 6-й чанк находится на шарде sh0, а 7-й чанк находится на шарде sh1.
В этом случае поиск по условию {projectId: 18, name: "job1"} будет только на 2х шардах sh0 и sh1. Если известно, что размер проектов у нас меньше размера шарда, то поиск будет ограничен только этими 2-мя шардами.
Т.е. мы берем условия исходной задачи, и практически полностью убираем все недостатки решения с составным ключом шардирования.
Теперь переформулируем для более общего случая.
У нас есть составной ключ шардирования. По первому полю нам требуется группировка, но оно слабоселективное. Второе поле, нужно просто чтобы увеличить общую селективность ключа.
С помощью дефрагментации, мы добиваемся следующих свойств:
- группа располагается на одном, максимум двух шардах.
- число групп которые имели несчастье разместиться на 2х шардах ограничено числом границ. Для N шардов будет N-1 граница.
Больше одно шардовых запросов, меньше лишней нагрузки на чтение, меньше дополнительных реплик!
Мало нам было бы радости, но с таких сильно селективным ключом мы и от jumbo-чанков избавляемся.
И вот теперь, от дефрагментации данных нам уже никуда не деться.
Точно итог
Изначально мы хотели просто выровнять коллекций по шардам.
По пути избавились от jumbo-чанков.
В итоге, мы можем поднять долю одно шардовых запросов, при этом не добавляя в условия запросов дополнительных полей.
Теперь уже можно оценить достижения и потери.
Достижения:
- гарантированный способ выравнивания занимаемого места для данных, которые мы хоть как нибудь смогли расшардить.
- простая компенсация размера не шардированных коллекций. Сложно представить себе проект, в котором найдется время проектировать каждую коллекцию с учетом шардирования.
- больше никаких jumbo-чанков.
- больше никаких пустых чанков. Соседние чанки на одном шарде — это слияние всего в одну в одну команду всего диапазона.
Потери:
- если за счет дефрагментации мы убирали jumbo-чанки, то мы теперь с ней навсегда. Вернуть ключ мы не можем. Удаление границ приведет к фрагментации данных и снижению доли одно шардовых запросов.
- периодически надо проводить коррекции границ. Но кажется это мы сможем автоматизировать.
- при добавлении нового шарда надо явно планировать переразбиение.
Осталось спроектировать весь процесс дефрагментации, расчета поправок и коррекции границ… Ждите!