

В первой части мы уже познакомились с тем, какие существуют методы для повышения производительности, что такое DL Workbench, как в него загрузить модель для оптимизации. Настало время познакомиться еще с двумя методами повышения производительности инференса - квантизация моделей и Throughput mode.
Квантизация моделей
Следующим приемом для оптимизации производительности является квантизация глубоких моделей. Данное направление оптимизации начало активно внедряться с 2018 года, с момента появления возможности вычислений в формате INT8 в процессорах архитектуры Intel Xeon Scalable 2-го поколения (Cascade Lake). В данную архитектуру были заложены AVX-512 инструкции и специальные регистры, позволяющие выполнить операции над INT8 числами для 512 / 8 = 64 INT8 чисел в одном операнде. Конечно, такое количество операций нужно еще подобрать и скомпоновать, но для операций в глубоких моделях сейчас это не является важной проблемой, поскольку глубокие модели состоят из большого множества однотипных операций. Помимо того, чтобы железо поддерживало INT8 тип данных, необходимо также, чтобы фреймворк запуска также поддерживал возможность вывода слоев глубокой модели в INT8 формате, но с этим у OpenVINO все в порядке.
Изображение с сайта показывает, как происходит векторизация вычислений с помощью различных наборов команд SSE, AVX и AVX-512 для чисел двойной точности, при этом за один раз удается сложить восемь чисел. При использовании INT8 в каждый вектор помещается уже 64 числа.
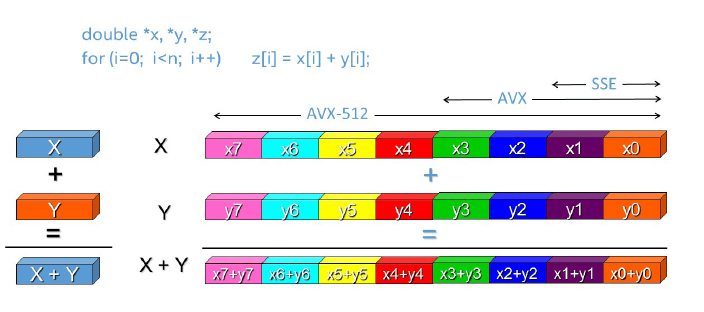
Квантизация моделей – мощный инструмент для повышения производительности вывода. Во время операции квантизации модели вычисляются диапазоны значений параметров весов и функций активации, и затем данные диапазоны масштабируются к целочисленным значениям с округлением к самому близкому целому значению — теперь вычисления происходят не с флотами, а с целочисленными значениями. Процесс квантизации модели в OpenVINO реализован как добавление специальных слоев квантизации в модель. Чтобы компенсировать изменение качества модели (если оно произошло), может быть выполнено дообучение квантованных весов на небольшой части тренировочного набора данных. Квантовать можно не только в INT8, но и в INT4 и даже меньше, но фишка INT8 в поддержке со стороны железа, что и дает самое большое ускорение.
Буквально на днях вышла новая версия DL Workbench, в которой все функции аккуратно рассортировали по вкладкам, поэтому некоторые скриншоты будут отличаться от скриншотов из первой части.
Чтобы провести квантизацию модели в DL Workbench, нужно после загрузки и конвертации модели перейти во вкладку "Perform" -> "Optimize performance". Для квантизации модели в DL Workbench используется другой инструмент из пакета Intel Distribution of OpenVINO Toolkit с очень красноречивым названием POT — Post-training Optimization Toolkit. В нем реализованы несколько алгоритмов квантизации моделей. Мы воспользуемся методом по умолчанию - DefaultQuantization, который позволяет получить быстрые модели с аналогичной точностью работы. Погрузиться в нюансы алгоритмов квантизации из POT можно в официальной документации. Кстати, на различных семинарах инженеры Intel квантовать рекомендуют именно FP16 модель.
Чтобы выполнить квантизацию модели, нам понадобится датасет, на котором модель была обучена. В связи с лицензионными ограничениями, датасет нам придется добыть самостоятельно, в DL Workbench он не входит. Для MobileNet и классификационных моделей понадобится валидационная часть датасета ImageNet. Официальный сайт ImageNet требует регистрации, но при заявке на регистрацию ответа не приходит. Это не страшно, в интернете можно найти валидационный датасет ImageNet 2012 на 50000 картинок. Затем в DL Workbench мы возвращаемся к созданию конфигурации и вместо автогенерируемого датасета загружаем наш ImageNet.zip, и генерируем новую конфигурацию экспериментов. Теперь нужно перейти к вкладке Optimize и выбрать метод оптимизации INT8. Начинается квантование, вы великолепны!
Квантизованная модель


В моем десктопе на Intel Core i5-10600 нет поддержки AVX-512 и соответственно нет хардварной поддержки вычислений в INT8, но использование INT8 моделей даже без поддержки в железе дает значительное ускорение.
Throughput mode
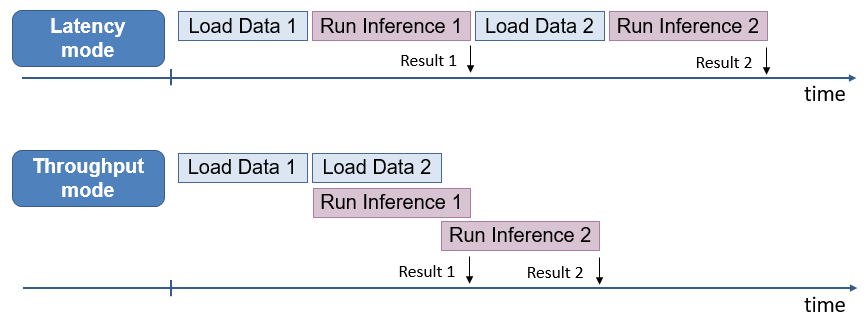
Стоит рассказать про способы увеличения производительности через параллелизацию инференса. Если мы будет подавать изображения в нейросеть по одному, а сама сеть маленькая и работает быстро, то никакой самый крутой фреймворк просто не успеет загрузить все ядра работой, и они будут простаивать. А вот если мы подадим несколько картинок на обработку одновременно, то сможем загрузить все ядра работой, и тогда за фиксированное время мы можем обработать намного больше картинок, чем если бы мы обрабатывали их по одной последовательно.
В OpenVINO появился дополнительный вариант повышения производительности - Throughput mode. Данный режим позволяет разделить ядра на логические группы, в которые можно подавать картинки на обработку независимо, что ведет к двум плюсам: нет расходов на ожидание загрузки в конвейер большого батча и задержка обработки каждого маленького батча меньше, чем у одного большого. В интерфейсе DL Benchmark за за количество таких логических групп отвечает параметр Streams Number. А еще мы можем скомпоновать данный прием с увеличением размера пачки в из предыдущей статьи и получить таким образом прирост еще больше.
Пример работы OpenVINO в Throughput режиме (картинка отсюда)
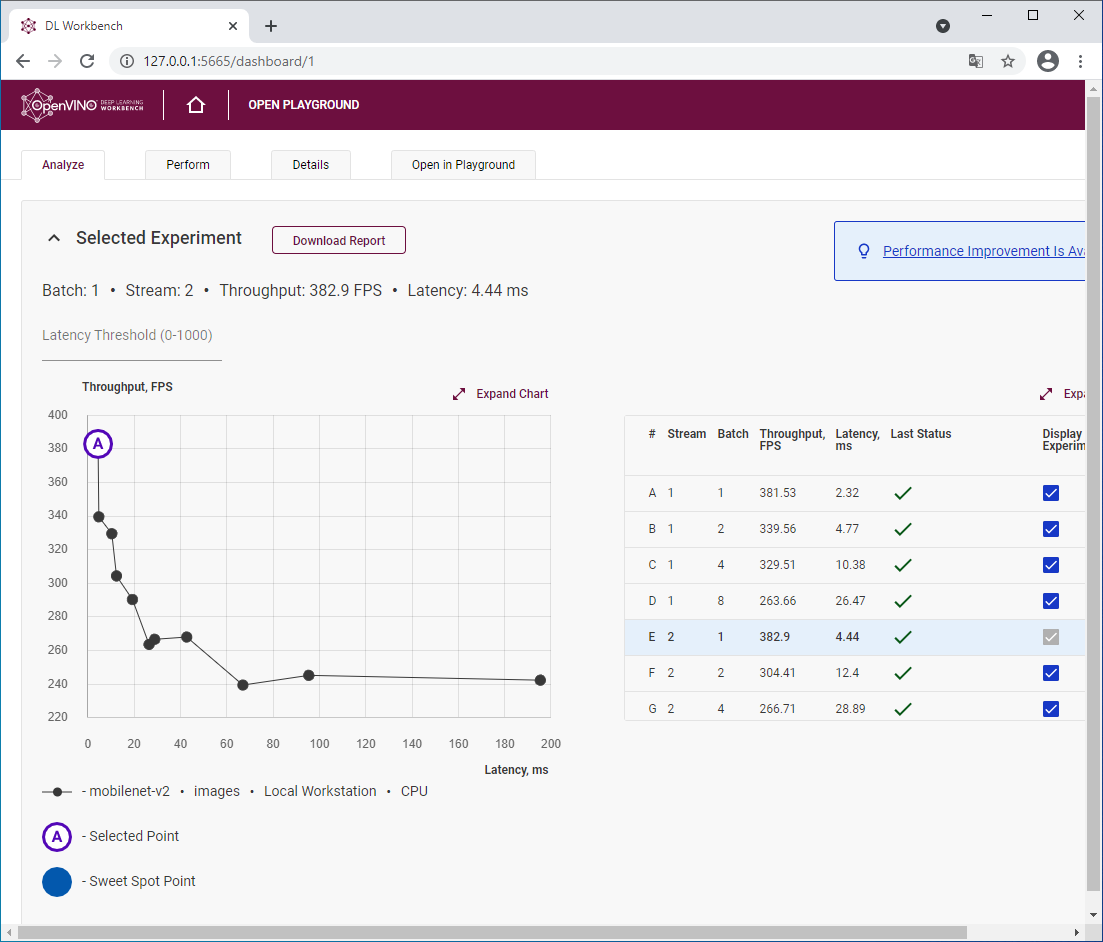
В Throughput режиме у нас добавляются новые параметры для перебора. Впрочем, некоторые из них можно оставить по умолчанию, например Requests number и Stream number по умолчанию равны числу физических ядер, и это дает оптимальные результаты или близкие к ним. В интерфейсе DL Workbench с помощью галочек можно установить параметры для последовательного перебора значений. Для
В 6-ядерном i5-10600 я пробую запускать с 1,2,6 логическими группами (streams)

Если мы попробуем объединить изменение размера батча, конвертацию в INT8 и Troughput mode для получения максимального ускорения, мы получим ускорение с 326 fps в эксперименте из первой статьи до 659 fps с применением всех оптимизаций: очень хорошо для нескольких кликов мышкой. И это еще без применения AVX-512 инструкций, которые уже доступны в серверных моделях, десктопных Core-X и ноутбучных IceLake, а с 11 поколения Core AVX-512 будут доступны и в других десктопных CPU.
Результаты для INT8 модели в Throughput режиме с разными размерами пачки

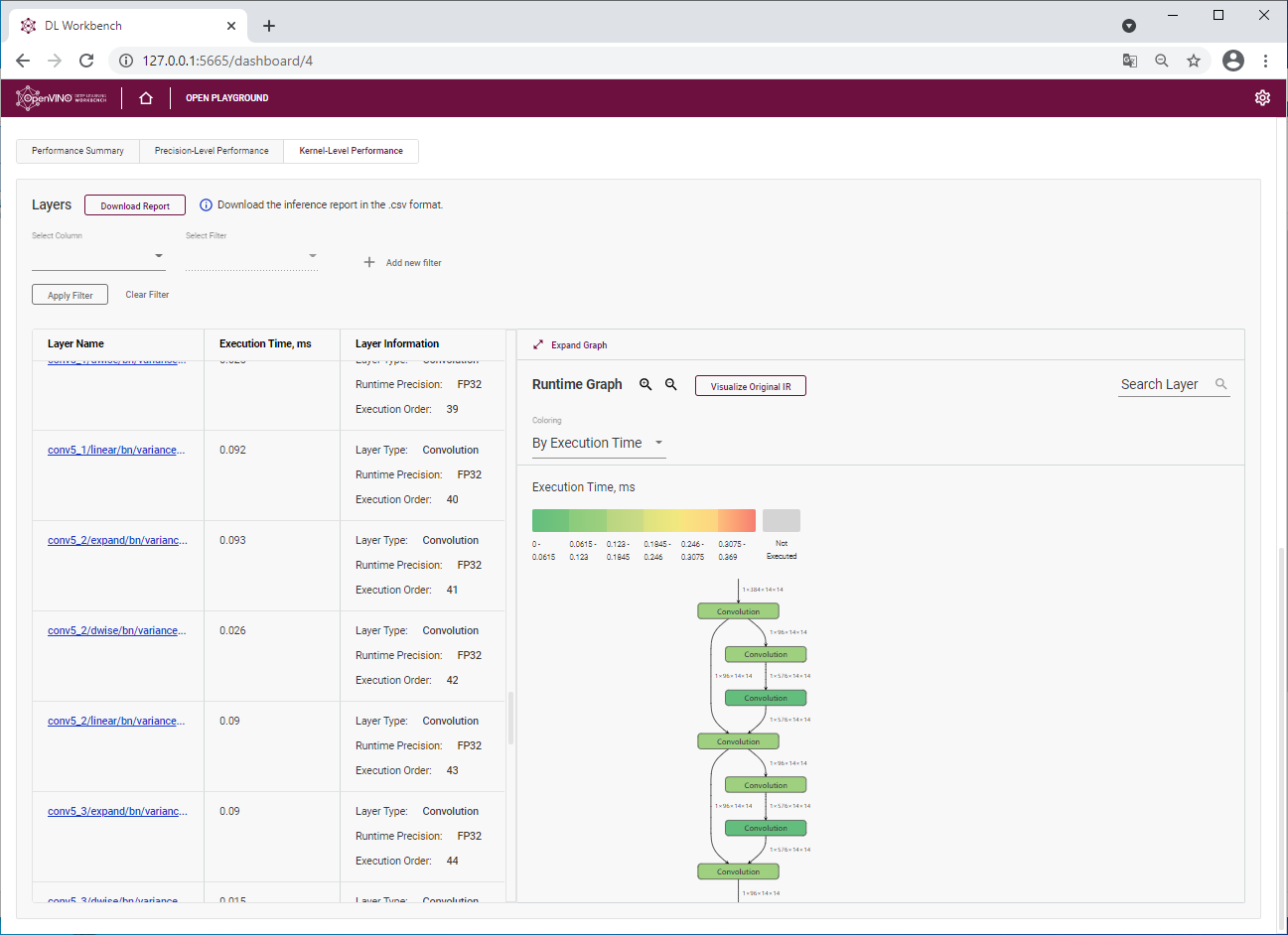
Бонусом для разработчиков моделей является диаграмма времени выполнения слоев. Во вкладке "Abalyze" -> "Kernel-level performance"можно отследить время выполнения каждого слоя, а для наглядности слои можно раскрасить в зависимости от времени исполнения, чтобы увидеть очевидные проблемы с производительностью. Кстати, у меня такая проблема однажды возникла - и в оригинальной модели слой трилинейного трехмерного апскейлинга в PyTorch пришлось переписать через обычные операции над тензорами (я создавал issue в гитхабе OpenVINO и мне очень оперативно помогли).
Мы можем посмотреть время выполнения каждого слоя модели

Еще одним интересным приемом оптимизации производительности является виртуализация большого сервера для одновременного запуска целого вороха одинаковых приложений с инференсом глубокой нейронной сети, но такой вариант запуска я считаю более сложным и затратным. Почитать про такую реализацию можно в отчете VMware “Optimize Virtualized Deep Learning Performance with New Intel Architectures” (сcылка на pdf).
Из новых фишек, которые недавно появились в DL Workbench - возможность посмотреть на результаты работы модели в графическом окне. Если использовать вместо генерируемого датасета настоящий, то можно увидеть объекты какого класса были найдены нейросетью на изображении. Для этого в интерфейсе нужно найти вкладку "Perform" -> "Visualize Output", загрузить и изображение и запустить картинку в обработку.

В нашем примере мы видим, что нейросеть предсказывает класс 273 с уверенностью 35%, класс 248 с уверенностью в 15%, и класс 260 с уверенностью в 9%. Для датасета ImageNet это соответствует описаниям «Dingo», «Eskimo dog, husky», и «chow chow» соответственно (Для моделей Caffe обычно подходит этот файл, в TensorFlow моделях классы те же, но вот их последовательность другая). В самом датасете к сожалению нет отдельного класса для породы Шиба-ину, поэтому в результаты мы видим классы собак, которые имеют внешние сходства с породой Шиба.
Заключение
Методы оптимизации инференса глубоких моделей не ограничиваются разобранными выше, но я рассказал именно про те, которые просты в использовании и дают самый ощутимый эффект.
В связи с проникновением глубокого обучения в самые различные сферы жизни, теме оптимизации моделей посвящается все больше сил и средств. Например, 24 марта в рамках проекта Intel CV Academy прошел открытый вебинар «Компиляторы для нейронных сетей», на котором были рассмотрены концепциям построения существующих компиляторов для нейронных сетей, это отдельная очень интересная тема для изучения.