
Самой дорогой ошибкой в истории, вызванной неправильными исходными данными, считается авария ракеты Ариан-5. Суммарный урон по итогу этого случая оценивают в 0.5 миллиардов долларов в ценах начала 1996 года.
Ещё одной, возможно, самой курьёзной, стала ошибка в огромном заказе от французских железных дорог SNCF на 2 тыс. поездов в 2014 году. Команда, которая формировала технические требования, собственноручно провела замеры габаритов перронов на нескольких десятках станций. Желая увеличить комфорт, они задали ширину составов впритык к максимальной. Измерения они проводили в окрестностях Парижа — и о том, что в регионах на многих станциях перроны находятся ближе к путям, узнали уже при испытаниях. Цена ошибки — модернизация всей инфраструктуры на сотни миллионов евро. Им бы там MDM с характеристиками станций…

Следом идёт огромное количество биржевых и банковских ошибок, когда неправильные данные в реквизитах, в цифрах и стоимости размещаемых акций приводили к миллиардным потерям или даже к банкротству.
Эта статья продолжает статью "мастер-данные и интеграция" — и более подробно освещает вопрос контроля качества данных, в первую очередь — мастер-данных. Статья будет особенно интересна руководителям IT, архитекторам, интеграторам, а также всем, кто работает в достаточно крупных компаниях.
1. Словарь, виды бизнес-данных: мастер-данные, нормативно-справочная информация, операционные данные.
2. Коротенько о том, какие бывают ошибки.
3. Архитектура решений DQS.
4. Технические и нетехнические приёмы борьбы с ошибками:
4.1. НСИ.
4.2. Мастер-данные.
4.3. Операционка.
5. Что делать, когда ничего из перечисленного не помогло — внедрять DQS.
6. И как делить ответственность?
Если терминология и проблематика вам уже знакомы, переходите сразу к части 3, про архитектуру DQS.
Уже пару десятков лет IT-евангелисты убеждают нас, что данные — новая нефть. Что любой бизнес всё больше зависит от обладаемой информации. Аналитические и дата-отделы появляются не только в IT-компаниях, но и в максимально далёких от «цифры» индустриальных и промышленных отраслях.
Многим уже набил оскомину пример того, как компании General Electric и Boeing создают «цифровых» дочек и зарабатывают на огромном объёме информации, собираемой от владельцев их техники — самолётов, турбин, электростанций. Эти данные позволяют им повышать надёжность техники, предсказывать возможные отказы, сильно экономя на потенциальном ущербе, наконец, просто спасать жизни людей!
Данных становится всё больше, и накопление их нелинейно зависит от роста бизнеса, рост опережающий. Любая растущая компания на определенном этапе своего развития (примерно на 6-7 уровне по шкале из прошлой статьи) сталкивается с проблемами некорректных данных, и обязательно происходит несколько случаев, когда цена этих ошибок оказывается достаточно высокой.

Традиционная картинка про рост объёма данных — почти всегда экспонента.
По ходу деятельности особую важность для компании представляют собой три вида данных:
Если НСИ можно сравнить с несущим скелетом, мастер-данные — с венами и артериями, то операционка — это кровь, которая бежит по этим венам.
Разграничение видов бизнес-данных нужно по той причине, что для каждого будет свой подход к работе над ошибками, про это ниже.

Основные виды ошибок, от которых страдает бизнес:
И если третье — это предмет работы службы информационной безопасности, там есть свои методы, то с человеческим фактором и неполнотой мы поработаем предметно.
Перед тем, как рассказать непосредственно о системах управления качеством данных (DQS — это не столько конкретное программное обеспечение, сколько подход к работе с данными), опишу IT-архитектуру.
Обычно, к тому моменту, когда возникает вопрос управления качеством данных, IT-ландшафт представляет собой следующее:
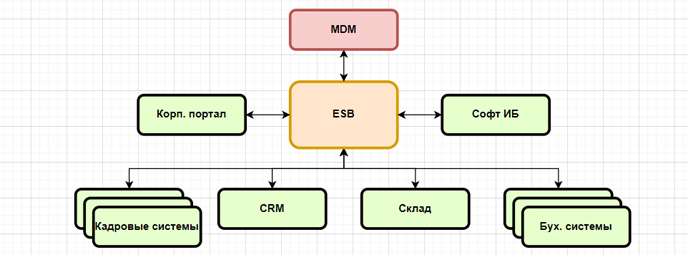
(схема из предыдущей статьи)
Где MDM — система для ведения мастер-данных и нормативки, а ESB — единая шина данных предприятия. Часта ситуация, когда не все данные и потоки информации между системами пока ещё вовлечены в общий контур, и некоторые системы общаются напрямую друг с другом — с этим нужно будет поработать, иначе ряд процессов будет «слепой зоной» для DQS.
Традиционно на первом этапе DQS подключается к системе MDM, поскольку управление качеством мастер-данных считается более приоритетным, чем операционки. Однако, в дальнейшем она включается в общую шину данных как один из этапов процессов, либо представляет свои «услуги» в формате API. В конкретных цифрах между первой и второй схемой примерно десятикратная разница в объёме данных или один уровень по шкале из прошлой статьи.
4. Технические и нетехнические приёмы борьбы с ошибками.
В следующем предложении будет написана самая грустная мысль этой статьи. Серебряной пули не существует. Нет такой кнопки или системы, которую поставишь — и ошибки пропадут. И вообще, у этой сложной проблемы нет простого и однозначного решения. То, что прекрасно подходит для одного вида или набора данных, будет бесполезным для другого.
Однако, есть и хорошая новость: набор технических и организационных методов, описанных в этой статье ниже, позволит значительно сократить количество ошибок. Компании, внедряющие подход DQM, сокращают количество выявленных ошибок в 50-500 раз. Конкретная цифра — это результат разумного баланса между эффектом, затратами и удобством работы.
4.1. Нормативно-справочная информация.
В случае нормативно-справочной информации (по сути, государственных классификаторов) есть максимально категоричное решение, и оно универсальное: вы не должны вести нормативку самостоятельно! Никогда, не при каких обстоятельствах!
Нормативка всегда и строго должна загружаться из внешних источников, а ваша главная задача — реализовать такую загрузку и наладить оперативный мониторинг на случай сбоев.
По итогу этих мер ни в одном месте вашей компании никому не должна прийти в голову мысль ввести, например, курс доллара к рублю на вчера вручную. Только выбор из справочников, загружаемых из официальных источников.

Категоричность этого пункта вызвана тем, что его выполнение снимает практически все ошибки в нормативке. И если в мастер-данных ошибки полностью побороть невозможно, то в НСИ таким образом можно сократить количество ошибок до одной-двух в год — и это будут уже не ваши ошибки, а ошибки в государственных данных.
Главная стратегия в отношении мастер-данных прозвучит, возможно, парадоксально: превращайте их в нормативку!
Здесь подходов уже больше. Первый аналогичен предыдущему — подключать внешние источники информации.
Да, не во всех процессах получится быстро найти необходимые источники информации, потребуется поиск и аналитика. Также источники могут оказаться платными, и дальше происходит взвешивание плюсов и минусов, но подход рабочий и многократно проверенный на практике.
Информация (данные) — новая нефть, и все государства стремятся к тому, чтобы получить максимально возможный объем информации о своих субъектах, включая бизнес, обо всех процессах, в которых они участвуют.
Нам даже тяжело представить, какую информацию государство собирает, могу сказать только, что на момент написания этой статьи на портале открытых данных России представлено около 20 тысяч наборов данных. И Россия только в начале этого пути, так, на аналогичном портале Евросоюза доступно больше миллиона наборов открытых данных!
www.europeandataportal.eu/en
— Где же здесь DQS, — спросит внимательный читатель?
А про неё ещё ничего и не было.
Всё вышеперечисленное — это, по сути, стандартные инструменты и методы для организации бизнес-процессов с минимальным количеством ошибок.
Ситуация с внедрением DQS чем-то похожа.
Ваша задача — постараться по максимуму превращать мастер-данные и даже операционку в НСИ, и в некоторых отраслях, особенно в сфере услуг, это возможно почти на 100%. Больше всего в банковской сфере, поэтому в ней степень автоматизации бизнес-процессов куда больше, чем у многих других.
Тем не менее, если битву избежать не получается, к ней нужно максимально правильно подготовиться.
На каком уровне развития компании нужно вводить DQS? Как процесс DQM — на 4-5 (раньше MDM-системы!), как организационно выделенную функцию — на 7-8.
Если у вас в компании есть бухгалтерская или кадровая система, то и процесс DQM в каком-то виде у вас будет. Во все эти системы встроен определённый набор правил для вводимых данных. Например, обязательность и строгий формат даты рождения для сотрудника, обязательность наименования для контрагентов.
Ваша задача на данном этапе будет заключаться в выстраивании процесса DQM. Он следующий:
Если вы сумели внедрить в компании MDM, значит, пункты со второго и далее не должны вызвать у вас особых затруднений, это текущая планомерная работа.
Наибольшие затруднения в таком случае возникают с придумыванием новых правил.
Если для такой сущности, как ФИО, ваша фантазия ограничивается обязательностью фамилии и имени, а для даты — проверкой на “не больше ста лет”, не расстраивайтесь!
Существует шикарная методика разработки новых правил для проверки самых невообразимых данных. Для её освоения не нужно быть семи пядей во лбу — и, как показывает практика, её в состоянии освоить любой начинающий системный или бизнес-аналитик, даже операторы по вводу мастер-данных.
По сути, это пошаговый скрипт, у которого на входе определение ваших данных, а на выходе — набор правил на все случаи жизни. Методика, известная под названием “таксономия грязных данных”, была разработана группой европейских data-scientist’ов в начале XXI века.
Суть подхода, а также практические примеры приведены в их системной статье, к счастью, уже опубликованной в переводе здесь, на Хабре — habr.com/ru/post/548164
Если проблема качества данных для вас — не пустой звук, то после вдумчивого прочтения той статьи вы обнаружите себя в состоянии, близком к достижению нирваны :)
Хорошим способом ввода даты являются три поля с явным обозначением (день, месяц, год) и быстрым переходом при вводе двух цифр в каждом из полей. Если вы хоть раз платили за что-нибудь картой в интернете, поймёте.
В вопросах управления и ответственности правильных ответов не бывает, скорее всё зависит от конкретных команд и личностей. Инженер-ракетчик может быть главным бухгалтером, художник — финансовым директоров, а учительница начальных классов — руководителем службы охраны.
Вопрос про ответственность за процесс DQM, на самом деле, даже более общий: кто несёт ответственность за качество данных в компании? Традиционно бизнес-пользователи и IT-департамент в ответе на этот вопрос выступают антагонистами.
Бизнес часто начинает диалог с утверждения “мы заметили ошибку в вашей системе местер-данных”.
Служба IT, напротив, считает, что её задача — обеспечить бесперебойную работу систем, а какие конкретно данные бизнес-пользователи вводят в систему — это зона ответственности бизнеса.
Выстраивание работающего процесса DQM и запуск DQS является тем самым компромиссом, удовлетворяющим обе стороны. Задача IT и аналитиков заключается в разработке максимально возможного количества правил и ограничений для вводимых данных, чтобы свести риск возникновения ошибки к минимуму.
Позиция “бизнеса”, как правило, вызвана отсутствием прозрачности в процессах DQM. Однако, если свести его до наглядной демонстрации ошибки, позиция смягчается. И может дойти до согласия в случае демонстрации последствий тому, кто вводит первичные данные.
Восхитительнейший пример и мотивацией и даже визуализацией последствий ошибок приведён в статье habr.com/ru/post/347838 — в этом примере ответственным за процесс DQM выступает служба IT с развитыми компетенциями бизнес-анализа. Причём сами по себе компетенции в DQM не сложны, и могут быть развиты у любого аналитика за пару месяцев.
Ещё один пример, интересный тем, что в процесс DQM включено также управление качеством бизнес-процессов, приведён в статье habr.com/ru/company/otus/blog/526174.
Общие выводы из этой статьи парадоксальны.
Если в вашей компании был задан вопрос “кто несёт ответственность за качество данных”, то вы попали в ловушку. На него нет правильного ответа, т.к. сам вопрос неправильный. Если вы попробуете сходить по этому пути, со временем поймёте, что единственный подходящий ответ на этот вопрос (“все”) ничего не даст вам на практике.
Правильный подход — разделение вопроса на два блока.
Первый — выстраивание DQM как процесса, внедрение DQS, формирование правил (не на разовой основе, а как постоянно идущий процесс). Этот блок живёт там, где сильны функции анализа, обычно, в IT, но необязательно.
Второй блок — сам ввод первичных данных — это место, где принимаются решения о конкретных данных, но не наобум, а на основании всех правил. Таким образом, внедрение DQS — важный шаг в сторону data driven company.
Приглашаю к дискуссии!
Ещё одной, возможно, самой курьёзной, стала ошибка в огромном заказе от французских железных дорог SNCF на 2 тыс. поездов в 2014 году. Команда, которая формировала технические требования, собственноручно провела замеры габаритов перронов на нескольких десятках станций. Желая увеличить комфорт, они задали ширину составов впритык к максимальной. Измерения они проводили в окрестностях Парижа — и о том, что в регионах на многих станциях перроны находятся ближе к путям, узнали уже при испытаниях. Цена ошибки — модернизация всей инфраструктуры на сотни миллионов евро. Им бы там MDM с характеристиками станций…
Следом идёт огромное количество биржевых и банковских ошибок, когда неправильные данные в реквизитах, в цифрах и стоимости размещаемых акций приводили к миллиардным потерям или даже к банкротству.
Эта статья продолжает статью "мастер-данные и интеграция" — и более подробно освещает вопрос контроля качества данных, в первую очередь — мастер-данных. Статья будет особенно интересна руководителям IT, архитекторам, интеграторам, а также всем, кто работает в достаточно крупных компаниях.
Содержание
1. Словарь, виды бизнес-данных: мастер-данные, нормативно-справочная информация, операционные данные.
2. Коротенько о том, какие бывают ошибки.
3. Архитектура решений DQS.
4. Технические и нетехнические приёмы борьбы с ошибками:
4.1. НСИ.
4.2. Мастер-данные.
4.3. Операционка.
5. Что делать, когда ничего из перечисленного не помогло — внедрять DQS.
6. И как делить ответственность?
Если терминология и проблематика вам уже знакомы, переходите сразу к части 3, про архитектуру DQS.
1. Словарь, виды бизнес-данных
Уже пару десятков лет IT-евангелисты убеждают нас, что данные — новая нефть. Что любой бизнес всё больше зависит от обладаемой информации. Аналитические и дата-отделы появляются не только в IT-компаниях, но и в максимально далёких от «цифры» индустриальных и промышленных отраслях.
Многим уже набил оскомину пример того, как компании General Electric и Boeing создают «цифровых» дочек и зарабатывают на огромном объёме информации, собираемой от владельцев их техники — самолётов, турбин, электростанций. Эти данные позволяют им повышать надёжность техники, предсказывать возможные отказы, сильно экономя на потенциальном ущербе, наконец, просто спасать жизни людей!
Данных становится всё больше, и накопление их нелинейно зависит от роста бизнеса, рост опережающий. Любая растущая компания на определенном этапе своего развития (примерно на 6-7 уровне по шкале из прошлой статьи) сталкивается с проблемами некорректных данных, и обязательно происходит несколько случаев, когда цена этих ошибок оказывается достаточно высокой.
Традиционная картинка про рост объёма данных — почти всегда экспонента.
По ходу деятельности особую важность для компании представляют собой три вида данных:
- мастер-данные — это информация, которая должна быть единой и синхронизированной во всех местах организации, во всех информационных системах. Это список клиентов компании, перечень товаров и услуг (со всеми дополнительными реквизитами: цена, категория, условия), организационная структура компании, персонал, имущество и т.д.;
- нормативно-справочная информация (НСИ) — это понятие близко к мастер-данным, и во многих компаниях объединяется с ними. Разница в том, что эти данные существуют независимо от вашей компании: список (классификатор) стран мира, адресный классификатор, реестры банков, курсы валют;
- операционные (они же транзакционные) данные — факт продажи конкретного товара конкретному клиенту, счета и акты, пройденные курсы, заказы курьеров и поездки на такси — в зависимости от того, чем занимается ваша компания.
Если НСИ можно сравнить с несущим скелетом, мастер-данные — с венами и артериями, то операционка — это кровь, которая бежит по этим венам.
Разграничение видов бизнес-данных нужно по той причине, что для каждого будет свой подход к работе над ошибками, про это ниже.
2. Коротенько о том, какие бывают ошибки
Ошибки неизбежны, они возникают всегда и везде, и, видимо, отражают хаотическую природу самого мироздания. Можно считать их чем-то плохим, расстраиваться из-за них, но, задумайтесь: ошибки лежат в основе эволюции! Да, каждый следующий вид — это предыдущий с несколькими случайными ошибками в ДНК, только последствия этих ошибок при определенных условиях оказались полезными.
Основные виды ошибок, от которых страдает бизнес:
- человеческий фактор. Опечатки всех видов, перепутанные поля и не туда внесённая информация. Забытые или случайно пропущенные действия и шаги при её внесении (у вас ведь тоже в карточке клиента по 50 полей?) Статически это самый вероятный вид ошибок, поэтому частота и эффект от них может оказаться самым большим. К счастью, для борьбы с ними придумано и самое большое количество методов;
- неполнота информации. Говорят, что полуправда хуже неправды, и в бизнесе это часто бывает критичным. Например, вы заключили крупный контракт с организацией — и через некоторое время узнали, что в отношении руководства компании ведётся судопроизводство. Ваш контрагент может уклоняться от налогов или, чего хуже, заниматься противозаконной деятельностью. Через некоторое время с вами свяжутся… конечно, ваш бизнес полностью легален, но кого обрадуют лишние проверки? А как хорошо было бы, если бы тогда, при нанесении контрагента в базу, ваша учётная система или CRM предупредила бы: внимание! Контрагент не прошёл проверку на благонадёжность!
- сознательные ошибки. Сотрудник умышленно перевёл себе несколько миллионов — и пропал. Это, конечно, экстремальный пример, криминал, но по дороге к нему есть немало шагов. Например, одному из клиентов в CRM назначена незаслуженно высокая скидка или стоимость товара установлена ниже себестоимости.
И если третье — это предмет работы службы информационной безопасности, там есть свои методы, то с человеческим фактором и неполнотой мы поработаем предметно.
3. Архитектура решений DQS
DQM — data quality management, управление качеством данных.
DQS — data quality system, система [управления] качеством данных.
Перед тем, как рассказать непосредственно о системах управления качеством данных (DQS — это не столько конкретное программное обеспечение, сколько подход к работе с данными), опишу IT-архитектуру.
Обычно, к тому моменту, когда возникает вопрос управления качеством данных, IT-ландшафт представляет собой следующее:
(схема из предыдущей статьи)
Где MDM — система для ведения мастер-данных и нормативки, а ESB — единая шина данных предприятия. Часта ситуация, когда не все данные и потоки информации между системами пока ещё вовлечены в общий контур, и некоторые системы общаются напрямую друг с другом — с этим нужно будет поработать, иначе ряд процессов будет «слепой зоной» для DQS.
Традиционно на первом этапе DQS подключается к системе MDM, поскольку управление качеством мастер-данных считается более приоритетным, чем операционки. Однако, в дальнейшем она включается в общую шину данных как один из этапов процессов, либо представляет свои «услуги» в формате API. В конкретных цифрах между первой и второй схемой примерно десятикратная разница в объёме данных или один уровень по шкале из прошлой статьи.
4. Технические и нетехнические приёмы борьбы с ошибками.
В следующем предложении будет написана самая грустная мысль этой статьи. Серебряной пули не существует. Нет такой кнопки или системы, которую поставишь — и ошибки пропадут. И вообще, у этой сложной проблемы нет простого и однозначного решения. То, что прекрасно подходит для одного вида или набора данных, будет бесполезным для другого.
Однако, есть и хорошая новость: набор технических и организационных методов, описанных в этой статье ниже, позволит значительно сократить количество ошибок. Компании, внедряющие подход DQM, сокращают количество выявленных ошибок в 50-500 раз. Конкретная цифра — это результат разумного баланса между эффектом, затратами и удобством работы.
4.1. Нормативно-справочная информация.
В случае нормативно-справочной информации (по сути, государственных классификаторов) есть максимально категоричное решение, и оно универсальное: вы не должны вести нормативку самостоятельно! Никогда, не при каких обстоятельствах!
Нормативка всегда и строго должна загружаться из внешних источников, а ваша главная задача — реализовать такую загрузку и наладить оперативный мониторинг на случай сбоев.
Пример #1. Наверняка вам для работы понадобится список стран мира. На него будут ссылаться многие другие справочники: контрагенты и клиенты (страна регистрации), валюты (курс какой страны), ваша география (в какой стране и по какому адресу расположен офис).
Значит, любая сущность, которая содержит в себе страну мира (даже если вы в ней выбираете из двух-трёх стран) должна ссылаться на этот справочник. А сам справочник должен заполняться строго на основании официальных классификаторов, в случае РФ — это ОКСМ (общероссийский классификатор стран мира).
Если вы работаете на международном рынке, обратите внимание на нюанс: в разных странах разное представление о странах мира и их количестве. И речь не только про такие частично-признанные республики, как Абхазия или Южная Осетия. Например, около двадцати стран не признают существование Израиля и Китайской Народной Республики. Есть и точечные непризнания на территории СНГ, например, Армения не признаётся… Пакистаном.
Страны мира (в РФ это и ниже — ОКСМ), валюты (ОКВ), виды экономической деятельности (ОКВЭД), адреса (ФИАС), банки и их счета, клиенты и поставщики (ЕГРЮЛ и ЕГРИП) — эта и множество другой информации публикуется государственными органами практически всех стран в виде открытых API и сервисов, и она должна загружаться только таким образом.
По итогу этих мер ни в одном месте вашей компании никому не должна прийти в голову мысль ввести, например, курс доллара к рублю на вчера вручную. Только выбор из справочников, загружаемых из официальных источников.
Категоричность этого пункта вызвана тем, что его выполнение снимает практически все ошибки в нормативке. И если в мастер-данных ошибки полностью побороть невозможно, то в НСИ таким образом можно сократить количество ошибок до одной-двух в год — и это будут уже не ваши ошибки, а ошибки в государственных данных.
4.2. Мастер-данные
Главная стратегия в отношении мастер-данных прозвучит, возможно, парадоксально: превращайте их в нормативку!
Пример #2. Справочник контрагентов — юридических лиц и ИП, являющихся вашими клиентами или поставщиками (в компаниях уровня выше 5-6 — часто одновременно и тем, и тем).
Какой бы набор полей вы не решили добавить в справочник контрагентов в систему MDM, ваша цель такова: все данные должны заполняться автоматически, с поиском по одному из естественных полей. В случае контрагентов РФ — это наименование или ИНН.
Это не значит, что вы должны занести в свой справочник контрагентов все несколько миллионов записей из открытых данных. Но новые записи должны добавляться как раз на их основании. Базовые реквизиты можно взять с сайта налоговой. Если вас интересуют данные бухгалтерской отчётности или среднесписочной численности (например, в целях аналитики, развивать отношения с наиболее крупными клиентами) — берите их у Росстата (ссылка). Если у вас есть процедура проверки на благонадёжность — берите данные с сайтов соотв. служб с помощью своей ИТ-команды, либо есть вариант покупать уже подготовленные и выверенные данные у провайдеров (например, СПАРК-Интерфакс). Цена вопроса, сотни тысяч рублей в год, при ваших масштабах окупается за несколько месяцев.
Самое главное, что проблему неактуальных реквизитов и потенциально нежелательных контрагентов вы решите полностью. Правда, в каждой стране присутствия её нужно решать отдельно.
Пример #3. Физические лица, сотрудники вашей компании. Ошибки в паспортных данных, неправильные ФИО и дата рождения, СНИЛС. Сокрытая информация о судимости, просроченной задолженности перед госорганами, алиментах.
Список сотрудников почти всегда является мастер-данными в крупных компаниях. Как их сделать нормативкой? Самый простой способ — наладить интеграцию с порталом Госуслуг. Возможен также вариант авторизации на ваших сервисах через портал Госуслуг. Ключевое слово для поиска: ЕСИА. Нужно будет обзавестись рядом сертификатов, но при ваших масштабах и уровне развития это не составит проблем.
Естественным продолжением этой истории будет электронный кадровый документооборот — электронная трудовая книжка, электронные больничные и др., что значительно сэкономит трудозатраты у кадровиков. В пределе это позволит одному кадровику обслуживать не 200-300 сотрудников, а 1000+.
Также все сотрудники автоматом получают электронные ключи-подписи — и смогут использовать их как во внутренних бизнес-процессах, так и при документообороте с клиентами.
Информация о задолженностях, судимостях и т.д. доступна в открытом виде через API соотв. госслужб, интеграция с ними предельно простая, и позволит вашей компании закрыть сразу большое количество рисков.
4.3. Операционка
Здесь подходов уже больше. Первый аналогичен предыдущему — подключать внешние источники информации.
Пример #4. — Хорошо, — скажете вы, — контрагенты и физлица — это просто. Но что делать с более бизнес-специфичными процессами и данными? Искать государственные классификаторы и другие гарантированные источники этой информации.
Попробуем разобрать точечный пример. У вас есть парк автомобилей. Не обязательно, что вы — служба такси, в любой достаточно крупной компании будет техника для служебных нужд. Вам нужно наладить учёт этих автомобилей, заправок и поездок, т.е. учёт расходов.
Создаём справочник автомобилей — это мастер-данные. Модель автомобиля, его нормы расхода топлива и характеристики выбираем из гос. классификатора моделей (не забывайте настроить регулярную интеграцию, чтобы данные не устаревали!)
Информацию о конкретном автомобиле заполняем строго по госномеру на основании подключаемого справочника (например, Автокод).
Откуда получить информацию, что конкретный водитель заправился на такую-то сумму в такой-то день? Оформить топливные карты (они стоят денег, но быстро окупят себя за счёт накопительной скидки) — и забирать данные у провайдера топливных карт в автоматическом режиме. Конечно, сам список топливных карт в этом случае станет мастер-данными, но вестись он будет автоматически, на основании данных провайдера.
Пример #5. Командировки сотрудников: билеты, гостиницы и прочие расходы.
Для билетов и гостиниц — пользоваться агрегаторами, все они позволяют, во-первых, значительно экономить на организации поездок (цены на билеты, гостиницы). Во-вторых, дают API со всей возможной информацией, вплоть до ЭДО. По всем прочим расходам — пользоваться электронными чеками, они уже принимаются везде. Т.е. человеческий фактор будет если не исключён, то сведён к минимуму.
Да, не во всех процессах получится быстро найти необходимые источники информации, потребуется поиск и аналитика. Также источники могут оказаться платными, и дальше происходит взвешивание плюсов и минусов, но подход рабочий и многократно проверенный на практике.
Информация (данные) — новая нефть, и все государства стремятся к тому, чтобы получить максимально возможный объем информации о своих субъектах, включая бизнес, обо всех процессах, в которых они участвуют.
Нам даже тяжело представить, какую информацию государство собирает, могу сказать только, что на момент написания этой статьи на портале открытых данных России представлено около 20 тысяч наборов данных. И Россия только в начале этого пути, так, на аналогичном портале Евросоюза доступно больше миллиона наборов открытых данных!
www.europeandataportal.eu/en
— Где же здесь DQS, — спросит внимательный читатель?
А про неё ещё ничего и не было.
Всё вышеперечисленное — это, по сути, стандартные инструменты и методы для организации бизнес-процессов с минимальным количеством ошибок.
5. Что делать, когда ничего из перечисленного не помогло — внедрять DQS
Сунь-цзы учит, что лучшая битва — та, которую удалось избежать.
Ситуация с внедрением DQS чем-то похожа.
Ваша задача — постараться по максимуму превращать мастер-данные и даже операционку в НСИ, и в некоторых отраслях, особенно в сфере услуг, это возможно почти на 100%. Больше всего в банковской сфере, поэтому в ней степень автоматизации бизнес-процессов куда больше, чем у многих других.
Тем не менее, если битву избежать не получается, к ней нужно максимально правильно подготовиться.
На каком уровне развития компании нужно вводить DQS? Как процесс DQM — на 4-5 (раньше MDM-системы!), как организационно выделенную функцию — на 7-8.
5.1. DQM как процесс
Если у вас в компании есть бухгалтерская или кадровая система, то и процесс DQM в каком-то виде у вас будет. Во все эти системы встроен определённый набор правил для вводимых данных. Например, обязательность и строгий формат даты рождения для сотрудника, обязательность наименования для контрагентов.
Ваша задача на данном этапе будет заключаться в выстраивании процесса DQM. Он следующий:
- придумать правило;
- протестировать правило на применимость и адекватность, обкатать на кейсах;
- разработать регламент применения правила, провести коммуникацию с пользователями, обосновать;
- внедрить в продакшн;
- следить за попытками обхода правила.
Если вы сумели внедрить в компании MDM, значит, пункты со второго и далее не должны вызвать у вас особых затруднений, это текущая планомерная работа.
Наибольшие затруднения в таком случае возникают с придумыванием новых правил.
5.2. Правила
Если для такой сущности, как ФИО, ваша фантазия ограничивается обязательностью фамилии и имени, а для даты — проверкой на “не больше ста лет”, не расстраивайтесь!
Существует шикарная методика разработки новых правил для проверки самых невообразимых данных. Для её освоения не нужно быть семи пядей во лбу — и, как показывает практика, её в состоянии освоить любой начинающий системный или бизнес-аналитик, даже операторы по вводу мастер-данных.
По сути, это пошаговый скрипт, у которого на входе определение ваших данных, а на выходе — набор правил на все случаи жизни. Методика, известная под названием “таксономия грязных данных”, была разработана группой европейских data-scientist’ов в начале XXI века.
Суть подхода, а также практические примеры приведены в их системной статье, к счастью, уже опубликованной в переводе здесь, на Хабре — habr.com/ru/post/548164
Если проблема качества данных для вас — не пустой звук, то после вдумчивого прочтения той статьи вы обнаружите себя в состоянии, близком к достижению нирваны :)
Пример #6. Строгая типизация. Если в справочнике используется тип данных “дата”, то структура даты должна быть максимально явной. Если вы решили сэкономить две секунды для операторов, и сделали шаблон вида “__.__.__” с подсказкой “день, месяц, год”, будьте уверены, что в первый же день появятся записи “18.04.21”, “21.04.18” и “04.18.21”.
Хорошим способом ввода даты являются три поля с явным обозначением (день, месяц, год) и быстрым переходом при вводе двух цифр в каждом из полей. Если вы хоть раз платили за что-нибудь картой в интернете, поймёте.
Пример #7. Запрещённые символы в максимально широком списке полей, словарные проверки. Например, если речь идёт про образование (должность), и классификаторы специальностей не помогли, вы позволяете пользователю ввести данные в текстовом поле, пусть там будут запрещены точки, кавычки, отдельно стоящие чёрточки (список не полный). Пример информации, качество которой повышается: “доктор технических наук”, “д.т.н.”, “ДТН”, “д-р техн. наук” и т.д.
Пример #8. Пустое и неуказанное значение (NULL) — это два разных значения. Например, неуказанное высшее образование/отсутствие высшего образования, неуказанное отчество/отсутствие отчества — разница велика, и она должна быть зафиксирована в явном виде. Хороший пример реализации — сайты по продаже билетов справа от отчества размещают галочку “нет отчества”.
Кстати, про ФИО, и особенно про отчество. Если вы предполагаете работу с физическими лицами из стран Средней Азии или Ближнего Востока, кейсы с “ибн”, “бен”, “кызы”, “оглы” (и др.) могут стать критичными в вопросах качества данных, например, при поиске дубликатов. Аналогичная история с порядком употребления этих данных (“Джон Смит”, “Смит, Джон”) и с двойными именами (“Анна Мария”, “Анна-Мария”, “Джон Чарьлз Смит”). Также для многих не иметь фамилию — это нормально. А ещё, с точки зрения одних, “Наталья” и “Наталия” — разные имена, а с точки зрения других — одинаковые. А ещё есть “сэр”, “доктор”…
Имя человека, на самом деле, отличный пример. Правил и исключений в именах настолько много, что лучшим выходом из ситуации будет не изобретать собственный велосипед, а подключить одну из готовых библиотек, содержащих в себе заведомо большое количество кейсов.
6. Кто несёт ответственность за DQS?
В вопросах управления и ответственности правильных ответов не бывает, скорее всё зависит от конкретных команд и личностей. Инженер-ракетчик может быть главным бухгалтером, художник — финансовым директоров, а учительница начальных классов — руководителем службы охраны.
Вопрос про ответственность за процесс DQM, на самом деле, даже более общий: кто несёт ответственность за качество данных в компании? Традиционно бизнес-пользователи и IT-департамент в ответе на этот вопрос выступают антагонистами.
Бизнес часто начинает диалог с утверждения “мы заметили ошибку в вашей системе местер-данных”.
Служба IT, напротив, считает, что её задача — обеспечить бесперебойную работу систем, а какие конкретно данные бизнес-пользователи вводят в систему — это зона ответственности бизнеса.
Выстраивание работающего процесса DQM и запуск DQS является тем самым компромиссом, удовлетворяющим обе стороны. Задача IT и аналитиков заключается в разработке максимально возможного количества правил и ограничений для вводимых данных, чтобы свести риск возникновения ошибки к минимуму.
Позиция “бизнеса”, как правило, вызвана отсутствием прозрачности в процессах DQM. Однако, если свести его до наглядной демонстрации ошибки, позиция смягчается. И может дойти до согласия в случае демонстрации последствий тому, кто вводит первичные данные.
Восхитительнейший пример и мотивацией и даже визуализацией последствий ошибок приведён в статье habr.com/ru/post/347838 — в этом примере ответственным за процесс DQM выступает служба IT с развитыми компетенциями бизнес-анализа. Причём сами по себе компетенции в DQM не сложны, и могут быть развиты у любого аналитика за пару месяцев.
Ещё один пример, интересный тем, что в процесс DQM включено также управление качеством бизнес-процессов, приведён в статье habr.com/ru/company/otus/blog/526174.
Итоги
Общие выводы из этой статьи парадоксальны.
Если в вашей компании был задан вопрос “кто несёт ответственность за качество данных”, то вы попали в ловушку. На него нет правильного ответа, т.к. сам вопрос неправильный. Если вы попробуете сходить по этому пути, со временем поймёте, что единственный подходящий ответ на этот вопрос (“все”) ничего не даст вам на практике.
Правильный подход — разделение вопроса на два блока.
Первый — выстраивание DQM как процесса, внедрение DQS, формирование правил (не на разовой основе, а как постоянно идущий процесс). Этот блок живёт там, где сильны функции анализа, обычно, в IT, но необязательно.
Второй блок — сам ввод первичных данных — это место, где принимаются решения о конкретных данных, но не наобум, а на основании всех правил. Таким образом, внедрение DQS — важный шаг в сторону data driven company.
Приглашаю к дискуссии!