
Антипаттерны, или просто — примеры неэффективного кода, могут быть очень коварными засланцами, даже в исходном тексте бывалых разработчиков. Иногда это следствие постановки задачи или очень сжатых сроков, иногда подводит невнимательность.
В этой статье я расскажу вам об антипаттерне проектирования — «Ёлочка». Суть этого антипаттерна заключается в том, что в некоторых случах, императивный подход пораждает гараздо более сложный для понимания и сопровождения исходный текст. Одно усложнение провоцирует следующее и так далее, до тех пор, пока мы не осознаем, что проще переписать всё с нуля.
Я нахожу этот антипаттерн интересным потому, что получить его можно не однократным внесением изменений, а целой цепочкой улучшений, связанной с развитием кода. И да, вы правильно поняли, мы убеждаем себя и заказчика в том, что код становится лучше, но в итоге — получаем ёлочку. Чтобы лучше это понять, рассмотрим каскад задач, от простого к сложному, и попытаемся проследить ход суждений, приводящих к неэффективному коду.
Рождение проблемы
Представим, что существует несложный компонент, отображающий некое число — «Counter»
const Counter = ({ value }) => {
return <div>{ value }</div>;
};«Counter» не следует воспринимать буквально. Это просто упрощённая модель для контрастного выражения сути проблемы.
Нам поступила задача сделать его более функциональным, скажем после числа ставить единицы измерения — digits. Теперь компонент имеет следующий вид:
const Counter = ({ value, digits }) => {
return <div>{ `${value} ${digits}` }</div>
};В процессе разработки оказалось, что иногда есть необходимость брать единицы измерения в скобки, например вот так: 10 (см). Мы решаем это сделать внутри компонента, для удобства:
const Counter = ({ value, digits, type }) => {
const temp = type ? `(${digits})` : digits;
return <div>{ `${value} ${temp}` }</div>
};Пожалуй, достаточно. Будем считать, что «Counter» достаточно функциональный компонент и пригоден к использованию в том виде, в котором сейчас существует.
Для начала введём такую условность, как «прогнозируемая сложность по входным данным» (далее будем называть просто — сложностью). Это такая гипотетическая функция, которая которая показывает, как быстро могут расти иные метрики сложности компонента относительно входных данных. Чем больше получиться значение функции, тем мудрёнее будет устроен компонент. Например, если мы собираемся обрабатывать два операнда взаимосвязано, то значение функции будет равно
a * b(как бы пытаемся учесть все возможные комбинации входных данных). Если эти операнды обрабатываются независимо, тогдаa + b.
Теперь рассмотрим «Counter» с этой точки зрения. Представим, что входные параметры этого компонента — a, b и c, а y - это некая функция вида f(a, b, c), решение которой будет символизировать обработку всех возможных состояний и отрисовку компонента. (наша прогнозируемая сложность)

Из реализации «Counter» видно, что как минимум два аргумента (digits и type) взаимосвязаны, т. е. всё множество вариантов их обработки имеет решение a * b, соответственно. Функция сложности, в этом случае, будет выглядеть так:

Не так уж и плохо, ведь digits это однотипная константа, которую мы просто конкатенируем, как и value, а это значит, что аргумент a, можно принять за единицу, т. е. 1 * b = b. В итоге мы смогли немного всё упростить и показать, что общее количество обрабатываемых состояний растёт линейно, т. е. только вместе с type.

А теперь внимание... На этом моменте разработчик уже попал в ловушку. Ведь наша упрощённая функция является результатом пренебрешения значением операнда a. При попытке усложнить условие, например, на основании digits выбирать тип скобок, наша функция проявит себя резким скачком своего значения, а это означает, что и содержание компонента «Counter» может резко усложниться.
Причина ловушки проста, мы видим простую, линейно растущую функцию, но на самом деле, она сохранила свой геометрический рост.
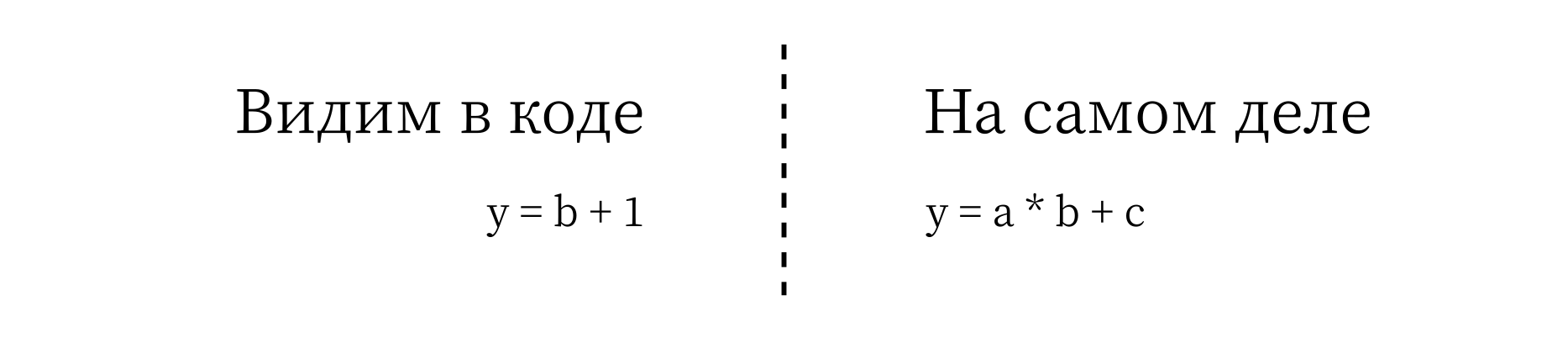
Возможно, что на примере с «Counter» это будет не так очевидно, но попробуйте представить подобное на компоненте с десятками параметров.
Где ошибка?
Очевидно, что ошибка возникла, когда внутри «Counter» появились взаимосвязанные аргументы, вырианты использования которых мы не продумали. Тоесть, при определении входных данных, мы не приняли во внимание, что digits может влиять на то, как будет интерпретирован type. Выходов из данной ситуации может быть много. Например, представив сущности digits и type, как отношение b' = f(b), мы бы смогли уменьшить сложность самого «Counter». Скажем так:
const getCoveredDigits = (digits) => `(${digits})`;
<Counter
value={value}
digits={getCoveredDigits(digits)}
/>В итоге, записать функцию сложности можно следующим образом:

Обратите внимание, f(b) будет сохранять линейный рост сложности там, где нет необходимости в замысловатых преобразованиях (привентивно избавились от ветвлений там, где они не нужны). Таким образом, мы немного улучшили декомпозицию, и понимание исходного текста всего приложения в целом.
Выводы
Очень сложно оценивать развитие кода программы во времени, особенно, когда вы даже не представляете то, каким исходный текст будет в будущем. Очень много нюансов лежит в поле большой субъективности. Надеюсь, предложенная методика поможет немного "разложить всё по полочкам" и вовремя принимать решения о рефакторинге.
Разумеется, при реализации «Counter» мы намеренно допустили несколько ошибок, которые часто остаются незамеченными на реальном производстве. Хоть и идеальной компонентной модели не существует, но при более выгодной декомпозиции, удаётся сократить замысловатость исходного текста и, как следствие, повысить общую надёжность и масштабируемость своих приложений.







lair
Четыре раза прочитал, все равно не понимаю. У вас внешний интерфейс вашего Counter изменился или нет?
vovikilelik Автор
Мы его меняли несколько раз. Но тут акцент падает именно на момент появления аргумента type, как взаимосвязанного с digits.
lair
Для решения проблемы надо его поменять, или нет?
vovikilelik Автор
Нет. Нужно провести более выгодную декомпозицию. Интерфейс Counter может не меняться до случая с type
lair
Если его не надо менять, нет никакого антипаттерна. Разработчик принял решение, которое подходило для существующих требований, а потом, когда и если требования поменялись так, что существующая реализация не подходил, надо делать рефакторинг и выносить что-то куда-то.
vovikilelik Автор
Мы рассматривали проблему во времени. Это значит, что на каком-то из этапов появилось 2 пути, где мы провели декомпозицию и где стали усложнять входные данные. В статье показана разница этих двух путей и объяснено, почему это может быть плохо.
Не стоит ориентироваться на Counter, т.к. это идеализированный пример.
lair
А теперь давайте представим себе, что на следующем этапе усложнения требований выяснилось, что скобки должны выбираться на основании числа. То есть отрицательное — скобки угловые, положительные — круглые.
Так какая декомпозиция правильная?
Проблема идеализированных примеров в том, что декомпозиция должна делаться на основании семантики и использования компонентов. А в вашем идеализированном примере первое банально ошибочно, а второе неизвестно.
fzn7
Куда type делся из итогового кода?
vovikilelik Автор
Он преобразовался в функцию getCoveredDigits()