
Этот пост — о том, как я решил сделать систему коллаборативной фильтрации постов из пабликов Телеграма на основе машинного обучения.
И сделал: OLEG AI
Идея
В мире наступает революция ИИ, и в какой то момент мне стало казаться, что без меня она наступить не сможет. Поэтому я нашел курс по программированию нейросетей на Питоне Fast.AI, и решил придумать себе небольшой проект, чтобы поучиться на практике.
Я люблю Телеграм. И люблю иногда потупить в какую-нибудь ленту "информационного корма". В разное время я любил поразлагаться на Лепре, Дёти, Пикабу, но в итоге всеми этими источниками сладкого яда я остался недоволен.
И тогда я подумал: в Телеграме ведь куча источников, но Телеграм их не агрегирует по типу Фейсбука. Телеграм не собирает с нас лайки. Да, лайки это чистое зло и гореть им в аду, но иногда так хочется лайкнуть жопу фотомодели, нет?
А рекомендательные сервисы — это одно из направлений ML. А Телеграм — открытая система. Должно быть не сложно, подумал я. Оказалось чуть сложнее чем я думал, но получилось.
Стоит заметить, что я не профессиональный программист, и опыта в программировании у меня не было примерно с 2004 года. Так что, помимо собственно нейросетей, мне пришлось еще и быстренько расчухать основы Питона, вспомнить SQL, погрузиться в Докер и практику CI/CD. Это было потрясающе.
Процесс
Начал я с того, что убедился, что задуманное мной в принципе возможно.
Мне нужно было слушать некий набор каналов (пабликов) Телеграма, и передавать посты подписчикам бота. Поизучал доки Telegram Bot API, понял, что при помощи одного только Telegram Bot API сделать это не получится. Бот не может подписываться на каналы по своему выбору.
Придется писать своего клиента для Telegram. К счастью, с нуля писать не пришлось: есть неплохая основа в виде либы python-telegram. Апишка там не самая проработанная, но самое тяжелое она делает за нас: процесс логина, предоставляет классы для создания запросов и получения асинхронных ответов от TDLib. TDLib это сишная либа-Телеграм-клиент. Так что я вооружился доками от TDLib, и принялся ковырять ее. Заодно разобрался как работает Телеграм, прикольно.
Я завел доску miro.com, чтобы накидывать туда идеи, рисовать схемы. Например, схему БД я нарисовал там. Оказалось очень удобно для маленького проекта — всё в одном месте и в то же время не мешает.
Как я представлял себе то, что хочу сделать:
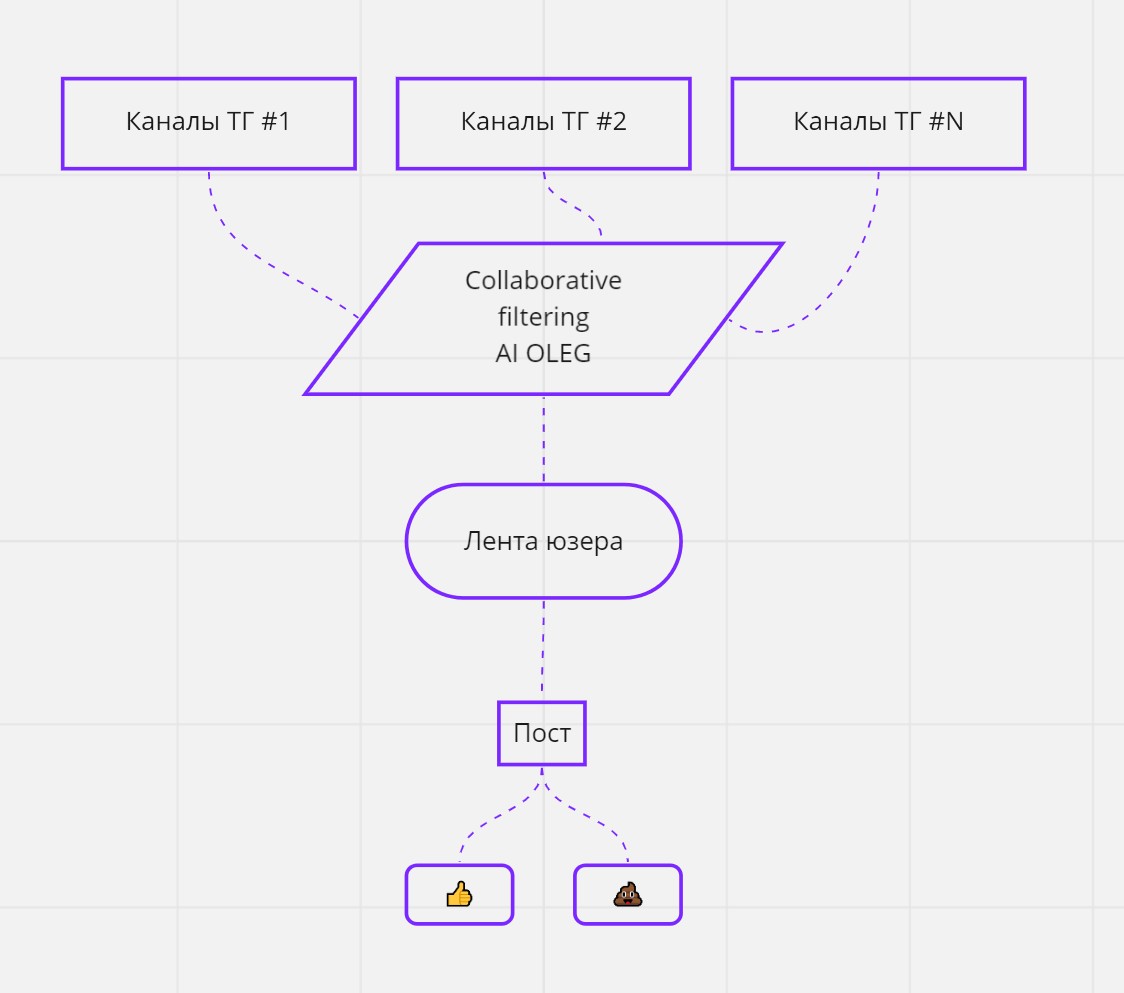
Довольно быстро я накидал приложение, схема которого в итоге оказалась примерно такой:
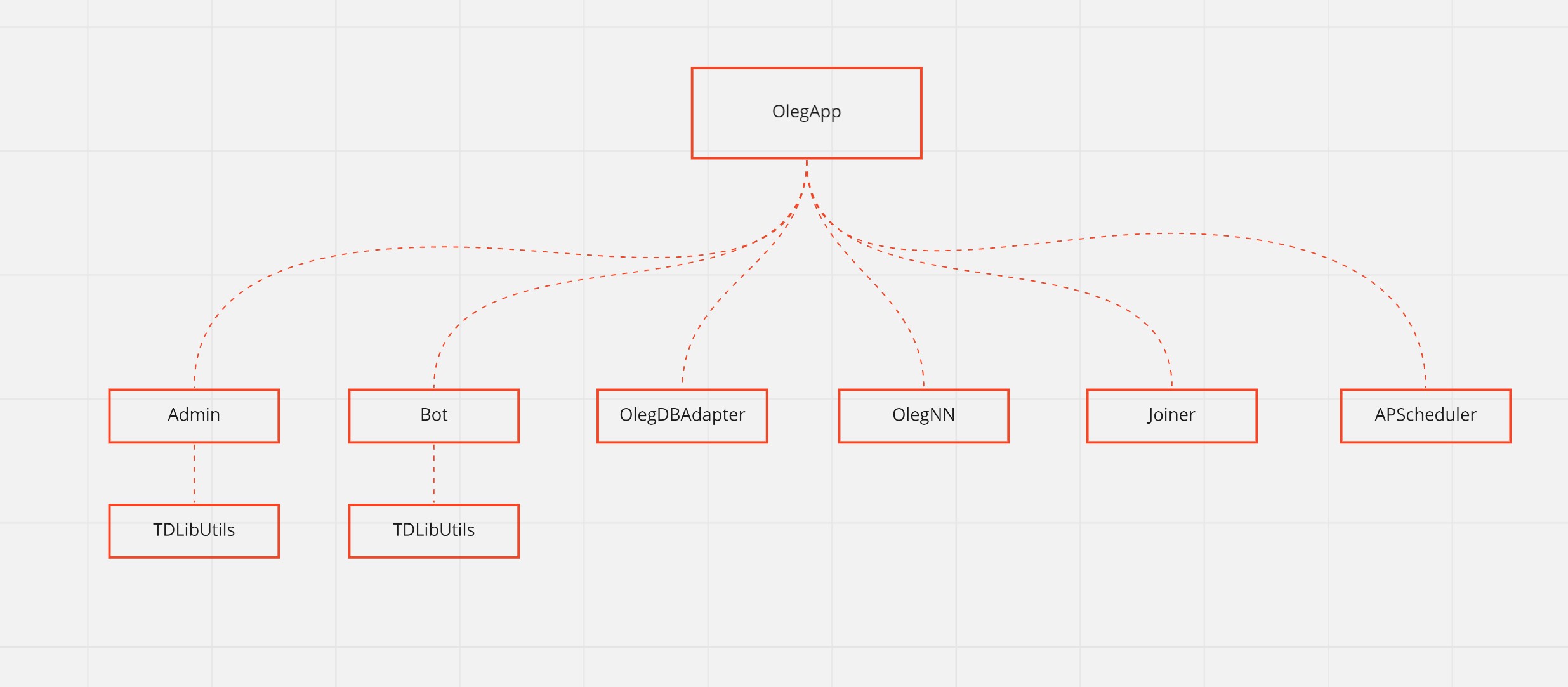
Блоки — объекты.
Тут не все объекты, конечно, а только основные.
Admin — это обычный аккаунт Телеги, залогиненный через TDLib и подписанный на интересующие нас каналы. Слушает апдейты каналов и записывает. Причем он не пишет контент, а только метаданные сообщения: tg_channel_id и tg_msg_id. По этим двум полям можно найти любое сообщение в Телеге (если оно было показано аккаунту).
Bot — аккаунт бота, общение с которым тоже происходит через TDLib (до этого я даже не знал, что так можно, думал, что только через Bot API можно работать с ботом).
К ним подключены TDLibUtils — всякие методы для работы с TDLib низкого уровня. Типа, найти юзера, найти сообщение, вытащить имя канала из инфы о канале и тп.
OlegDBAdapter — методы для работы с базой (get_users, get_posts etc)
OlegNN — то, ради чего всё затевалось — алгоритм коллаборативной фильтрации. Правда, по итогу никакой нейросети там внутри не осталось, но об этом позже.
Joiner — логика подписки на каналы. Нельзя так просто взять список каналов и подписаться на него: быстро срабатывает рейт лимитинг. На вычисление безопасной логики подписки, логирование, организацию базы ушло около недели.
APScheduler — сторонняя либа-планировщик тасков. Использую для периодической рассылки сообщений подписоте.
Контент
Схемы работы с контентом могло быть две:
- забирать контент каждого сообщения, хранить его, и собирать из него сообщение для подписчика по запросу. Плохо, тк придется качать и хранить кучу контента. Ладно бы текст, но там еще и медиа
- не хранить контент, а забирать его из Телеграма по необходимости
- в идеале — не выкачивать медиа, а придумать, как его передавать юзеру прямо внутри Телеграма. Этот вариант и реализовал, правда, пришлось помаяться.
Чтобы не выкачивать медиа, в Телеграме у каждого ассета есть свой уникальный айди. Когда собираешь сообщение, можно вместо файла указать этот айди. Я думал, что этого достаточно, но посты не отправлялись. Оказалось, дело в том, что аккаунт отправляющий медиа с помощью айдишника, должен сначала этот айдишник встретить в Телеграме. Например, получить сообщение с этой картинкой. Проблема в том, что у меня за получение сообщений отвечает аккаунт Admin, а за отсылку — Bot. Я долго думал, и в итоге придумал: а что, если каждое полученное сообщение Админ будет форвардить Боту, таким образом Бот "увидит" всё медиа. Это сработало. Я боялся, что за такое количество форвардов поймаю рейтлимит и огребу гемморой, обходя это дело, но в итоге обошлось.
Каналы
Не мудрствуя лукаво, я купил список топовых каналов по количеству подписчиков у TGStat.ru. 45 категорий по 100 каналов, вышло 4500 каналов. Пока этого хватает, возможно допишу еще паука, который сам лезет в каналы упомянутые в постах, и подписывается на них. Я сразу сделал логику Joiner'а так, чтобы можно было легко докинуть ему в пул свежих каналов, а он с ними сам разберется.
С каналами уперся в неожиданный лимит: один аккаунт Телеграма может быть подписан только на 500 каналов. Придется теперь превращать Admin'а в хаб, управляющий несколькими аккаунтами, и добавлять аккаунты, следить какой аккаунт подписан на какой канал, и всё в таком духе. Пока отложил это, решил, что для старта 500 каналов хватит.
Нейросеть, которой нет
Затевал я всё это ради практики программирования нейросетей, как вы помните.
Когда внедряешь машинное обучение, сталкиваешься с тем, что это всё-таки черный ящик, у которого наружу торчат некие гиперпараметры, а на выходе получается какой-то результат, причем, если при разработке ты правильно учел всякие там размерности тензоров и не наделал глупых ошибок, оно будет работать. Как-то будет. Будет ли результат, выдаваемый ящиком, иметь какой-то смысл — это вопрос. Чтобы ответить на этот вопрос, приходится сидеть, расковыривать ее так и эдак, смотреть на результаты разных этапов вычисления, читать тематические статьи, узнавать практику, прикидывать baseline результат и сравнивать с тем, что получилось у тебя. Короче, это весело. На первых этапах машинное обучение создает гораздо больше проблем, чем решает. И заставить его реально решать какие то проблемы, создавая прибавленную стоимость для вашего проекта — большая работа, не очень похожая на обычное программирование и дебаг.
Так что трижды подумайте, прежде чем бросаться решать проблемы этим методом. ML требует жирных проблем, которые точно не решаются классическими методами и сулят повышенный профит. ML ради ML истощает бюджеты и роняет мораль!
Прежде чем прикрутить ML к Олежке, я долго крутил системы коллаборативной фильтрации на тренировочном датасете MovieLens (ой, только не надо).
Я делал решение как для задачи регрессии (в конце один нейрон который угадывает рейтинг фильма по шкале 1..5), так и для задачи классификации (в конце 5 нейронов, каждый отвечает за свой рейтинг 1..5, и какой нейрон сильнее активируется, тот рейтинг мы и считаем за предсказание).
Эти изыскания заняли прилично времени, кажется 2-3 недели. По ходу дела я даже с нуля написал классификатор MNIST, благодаря чему сильно продвинулся в понимании работы нейронок. Кто еще не делал этого: очень рекомендую. Времени занимает от силы 2 дня, а пользу приносит годами.
В итоге стало ясно, что если задачу рассматривать как регрессию (а не классификацию), предсказательная сила модели будет намного лучше, так я и сделал.
В основе механизма у меня эмбеддинги. Кто не в курсе — читаем дальше, кто знает — может промотать следующий раздел.
Embeddings
Идея простая, но гениальная: каждой сущности (юзеру, посту) противопоставляется вектор параметров. Например, K=10 параметров. Они еще называются латентные факторы (latent factors).
Получается, что если у нас N юзеров, то мы можем расположить все вектора друг под другом, и получить тензор формы (N,K). Матрицу из N рядов и K колонок, если по-колхозному.
Для постов получится такой же тензор, только другой.
Эти тензоры называются эмбеддингами.
Cистема спрашивает у алгоритма фильтрации: вот есть юзер U, пост P, предскажи мне рейтинг, который юзер поставит посту.
В самом простом варианте (без нейронки) мы ищем в тензоре юзеров нужный ряд соответствующий юзеру, в тензоре постов — вектор поста, и перемножаем эти два вектора (как в школе). На выходе получается скаляр (число) — это и есть предсказанный рейтинг.
В варианте посложнее, эти два вектора подаются на вход нейросети, и дальше сигнал продвигается уже механизмом нейросети. На выходе — один нейрон, величина активации которого — скаляр — и есть предсказанный рейтинг.
Почему эти тензоры назвали отдельным словом "эмбеддинг", что в них особенного? Дело в том, что эмбеддинг — это первый шаг вычисления результата работы нейронки.
Когда мы ищем нужный ряд для юзера или поста в тензоре, мы могли бы просто взять индекс нужного ряда, и вытащить вектор соответствующий этому индексу. Но операция "взять ряд по индексу" не является алгебраической, это программатик-операция работы с памятью. Это означает, что данная операция разрывает граф вычислений градиента нейросети. Градиент можно вычислить только для алгебраических операций. То есть, во время обучения механизм back propagation не сможет дойти до самого конца — непосредственно до эмбеддинга. Как же быть?
Вместо того, чтобы брать ряд тензора по индексу, мы можем умножить этот тензор на one-hot-encoded vector. Например, нам нужен третий по счету ряд тензора. Умножаем тензор на вектор [0 0 1 0 ...] На выходе получаем нужный нам ряд тензора. Это алгебраическая операция (умножение тензора на тензор), она не ломает граф вычислений! Но это компутационно дорогая операция. Каждый раз так умножать GPU замучается. Поэтому в PyTorch и других пакетах нейровычислений есть специальный компутационный шорткат для эмбеддингов, который с одной стороны и граф вычислений не ломает, и компутационно дешев.
Где же взять эмбеддинги?
Допустим, у нас есть обучающий датасет: энное количество оценок, которые юзеры поставили постам.
Давайте проинициализируем эмбеддинги случайным образом, и для каждой оценки из датасета будем вычислять предсказание и сравнивать с оценкой. У нас получатся некие дельты, на этих дельтах мы и будем обучать нейросеть и эмбеддинги с помощью стохастического градиентного спуска (SGD).
В итоге через несколько эпох обучения (эпоха — проход всего датасета) наши эмбеддинги из случайных превратятся в обученные, и будут иметь некий смысл.
Каждый из параметров эмбеддинга действительно приобретает некий смысл. Какой — не совсем понятно, да и не нужно понимать. Будем считать, что этот смысл ведом только самой системе рекомендаций. Для нас главное, что в итоге система работает: рекомендует юзерам более релевантные посты. А какой "смысл" она видит в этих постах — какая разница?
Длина вектора латентных параметров
Число параметров K — какое оно должно быть? Лучший ответ, что мне удалось найти, был в этой статье: A social recommender system using item asymmetric correlation.
Если коротко, единого ответа нет, всё зависит от глубины сложности ваших item'ов, постановки задачи, функции потерь, короче, от всего. Rule of thumb: 5 — маловато, 50 — многовато, где-то посередине — в самый раз. Надо пробовать: смотреть, насколько гладко обучается модель, не провоцирует ли выбранное количество параметров переобучение, обучается ли модель вообще.
Я выбрал K=13
Где нейросеть?
Поиграв некоторое время с разными конфигурациями, я понял что для моей задачи регрессии оценки в диапазоне 0..1 лучше всего подходит конфигурация без нейросети. У меня просто перемножаются эмбеддинги. В таком варианте, без глубинного обучения, обучение происходит гораздо быстрее и плавнее. В данном случае проще оказалось лучше.
Обучение
Самый большой мой просчёт в архитектуре был связан с тем, что я думал, будто результаты обучения — очень ценная инфа, и её надо хранить персистентно, на диске в виде бинарника или в базе. Я написал код, который сохраняет вектора для каждого поста и юзера в базу в виде BLOB'а. Написал, потестил время выполнения, оказалось, что процесс обучения занимает 1-2 секунды, а процесс записи результатов — около минуты. Сама модель занимает в памяти 52 мегабайта для 1 млн постов. Так и зачем вообще сохранять ее в памяти? В любой момент можно обучить ее с нуля за пару секунд. Пришлось переписать.
Вот так выглядит процесс обучения. По вертикали — ошибка, по горизонтали — номер мини-батча:
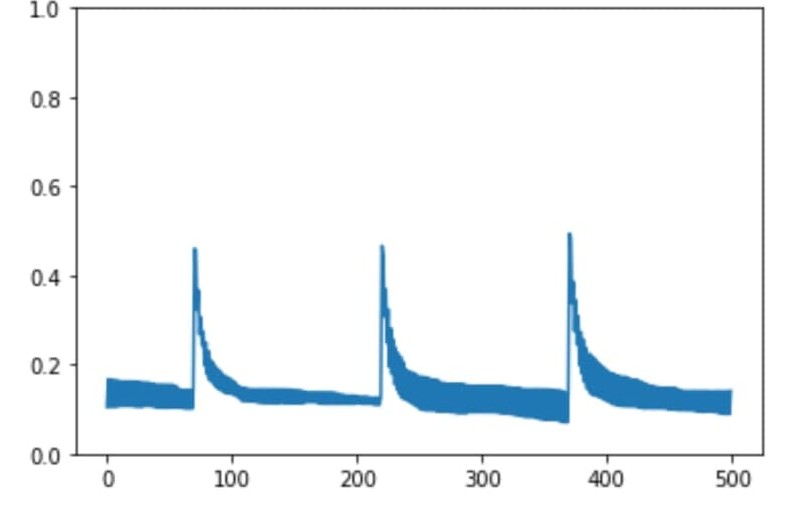
Мини-батч — это некоторое число оценок, которые одновременно подаются на вход модели для обучения. В моем случае batch_size = 512.
Каждый пик — это старт обучения с нуля. Видно, как по мере обучения падает ошибка.
Вот так выглядит инференс (процесс предсказания) модели:
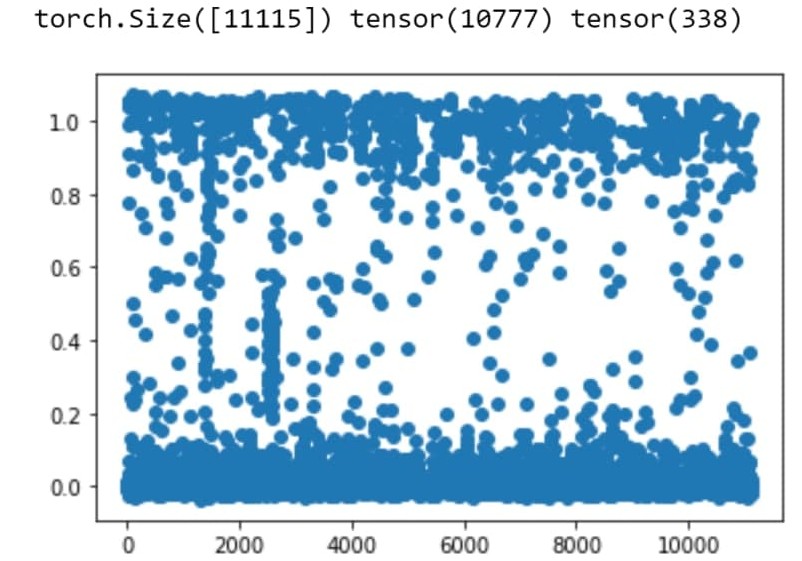
Каждая точка — это пост из базы. По вертикали — предсказанная оценка. Из 11 115 постов всего 338 имеют предсказанную оценку выше 1, из них в итоге модель и выберет тот пост, который попадет юзеру в ленту.
Обучение с нуля и инкрементное обучение
Когда переходишь от игрушечных моделей для учебы к реальной модели для проекта, возникают вопросы:
- Как быть, если приходит новая оценка от юзера? Стартовать обучение сразу, или ждать N новых оценок?
- При получении новой оценки, обучать модель "на старые дрожжи" (инкрементно), то есть взять те веса и эмбеддинги, которые есть, и на них натравить датасет из новых оценок? Или просто переобучить всё с нуля?
Когда передо мной встали эти вопросы, беглый поиск ответов мне ничего не принес, поэтому я вооружился здравым смыслом и практикой. Соображения у меня были такие:
- Инкрементное обучение плохо тем, что если запускать только его, и никогда не обучать с нуля, параметры застревают в некой области значений. Кривая обучения становится очень резкой. На практике это означает, что при поступлении новых данных и запуске инкрементного обучения, несколько эпох ошибка почти не меняется, потом делает резкий скачок вниз или вверх, и потом опять стоит как вкопанная. Это — очень нездровая ситуация, если вы столкнулись с таким, ищите как сделать обучение гладким, вплоть до переформулирования задачи как таковой.
- Обучение "с нуля" почти ничего нам не стоит, поэтому не надо этого стесняться.
- Глядя в будущее, можно предположить, что когда-нибудь у Олежки скопится датасет из 1 млн оценок, который будет занимать заметное время на обучение (десятки секунд). Юзеров будет достаточно много, и при получении каждой новой оценки запускать обучение с нуля мы не сможем.
Поэтому я сделал интерфейс и для инкрементного обучения, и для обучения с нуля. И написал логику, которая запускает полное обучение раз в N циклов инкрементного. А также сделал таймаут между циклами обучения. Всё это вынесено в конфиг. По мере взросления сервиса я смогу легко поменять эти настройки.
Холодный старт и взросление сервиса
Если вам доводилось читать о рекомендательных системах, вам должно быть известно, что одной из самых больших проблем в них является "холодный старт" и бутсртап свежего юзера. Холодный старт — это когда в системе в принципе мало оценок, а свежий юзер — это юзер, о вкусах которого мы ничего пока не знаем.
Действительно, если в системе мало оценок (и много постов), как ее ни обучай, данных будет недостаточно, чтобы выученные эмбеддинги имели какой-то смысл. Рекомендации продуцируемые этой системой будут малорелевантными.
Со свежим юзером похожая проблема.
Как решить эти вопросы? Единого решения не существует. Все пользуются здравым смыслом и той информацией, которая доступна.
Например, для свежего юзера мы можем сделать некий опросник (так сделано в Netflix), который сможет быстро сообщить нам хоть что-то о юзере, чтобы сделать первый опыт пользования системой не ужасным.
Я решил, что опросник для Олежки будет слишком тяжеловесным решением, юзеры хотят просто тыкать лайки, а не отвечать на вопросы типа "ваш любимый цвет". Поэтому я решил так: первые 30 постов, которые Олежка присылает юзеру, я выбираю из числа тех, которые максимально нравятся всем. Говоря строго, они имеют максимальный bias.
Железо
Сейчас Олежка работает на самом дешевом инстансе Digital Ocean ($5/мес), без GPU. База расположена на этом же инстансе, в другом докер-контейнере. Думать о скейлинге пока рановато.
Итог
Олежка стабильно работает, перестал жрать память и чувствует себя хорошо.
Юзеров пока маловато, так что, пожалуйста, лайк-шер. Можно просто шерить посты из ленты друзьям в Телеграме.
Больше юзеров — релевантнее рекомендации!






d4rw1n1s7
не хватает третьей кнопки, чтоб скипать когда не хочется оценивать пост, чтоб алгоритм не переобучался в какую-то одну сторону
Yorick Автор
Можно запросить новый пост командой /send_new
Я делал третью кнопку в начале, но потом убрал, не хотел захламлять
d4rw1n1s7
хороший бот, спасибо за ваш труд, буду пользоваться, жду рекламу между постов =)
Yorick Автор
Спасибо )