
Мы запустили новую услугу: резервирование маршрутизатора с использованием протокола VRRP (за рубежом она известна под названием failover IP. Насколько нам известно, в России до нас никто ничего подобного не делал. Услуга будет интересна в первую очередь тем, кто хотел бы обеспечить постоянную доступность бизнес-значимых интернет-ресурсов, но при этом не обладает для этого достаточными техническими возможности: не имеет ни собственной автономной системы, ни блока IP-адресов, ни подключений к провайдерам по протоколу BGP.
Об особенностях её технической реализации мы подробно расскажем в этой статье.
Выбираем схему резервирования
Представим себе, что у нас есть критически важный для бизнеса интернет-ресурс, который должен всегда доступен большому количеству пользователей. У этого ресурса www.mysite.ru есть IP-адрес 12.34.56.78, выданный провайдером в составе блока 12.34.56.72/29.
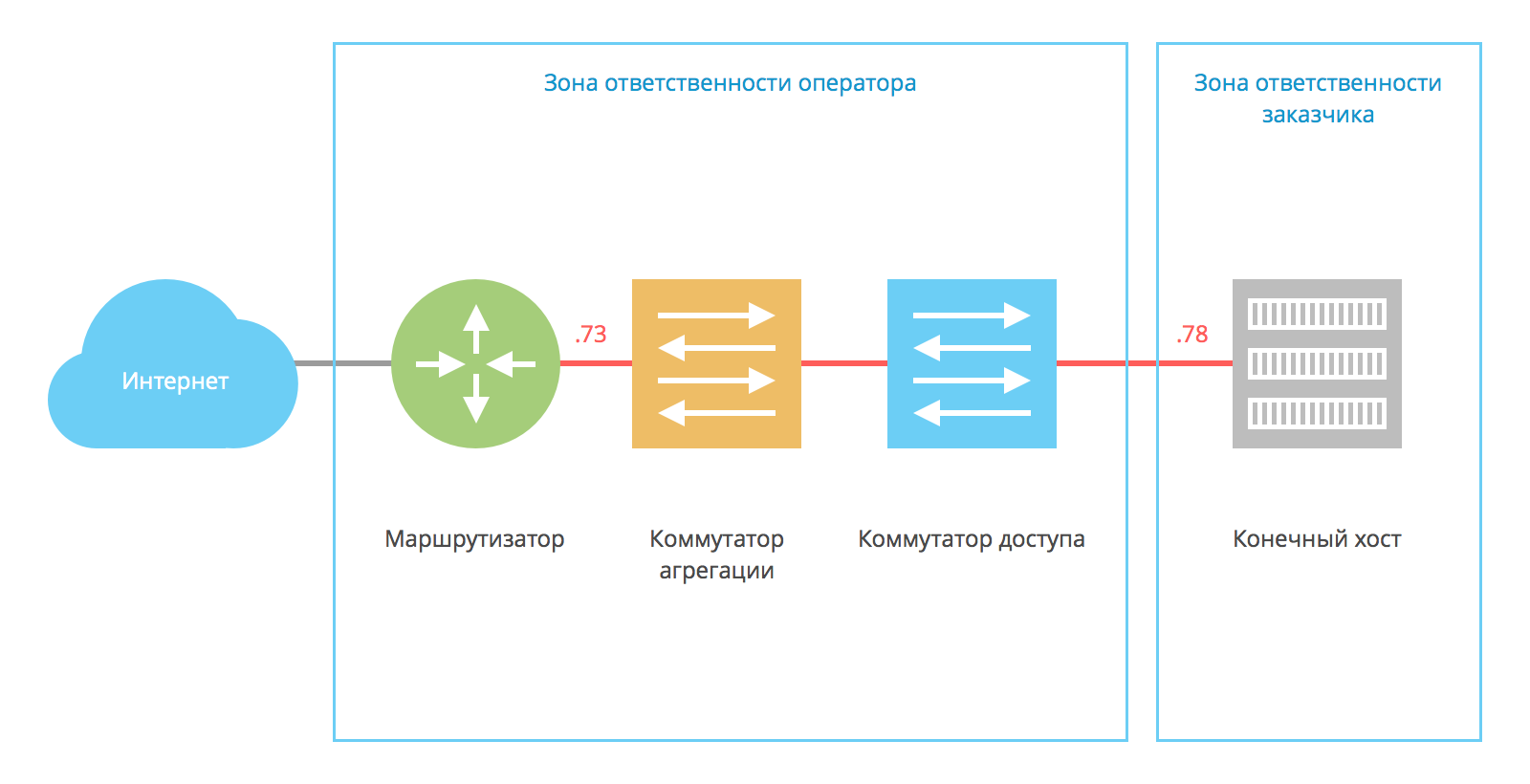
Сетевые настройки ресурса (адрес, маска и шлюз по умолчанию) выглядят так:
ifconfig eth0 address 12.34.56.78 mask 255.255.255.248 gw 12.34.56.73
Если .78 — это адрес хоста, то .73 — адрес шлюза по умолчанию. Этот адрес — зона ответственности оператора, а если хост размещен в дата-центре — то зона ответственности дата-центра. Графически эту схему можно представить так:
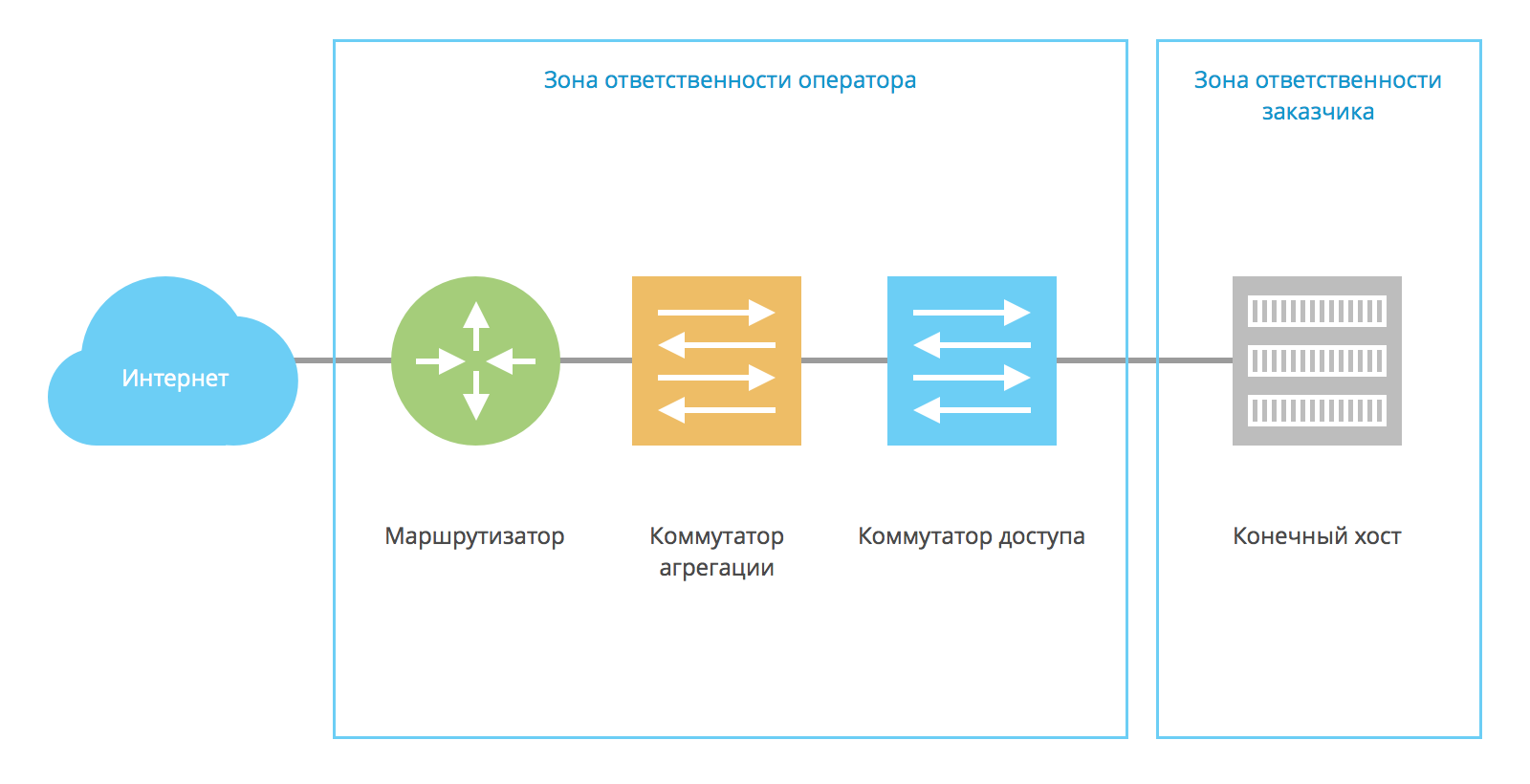
На конечном хосте прописывается адрес 12.34.56.78, на маршрутизаторе — .73, и между ними организуется единый L2-домен (как правило, это отдельный VLAN):
Чтобы повысить уровень доступности конечного хоста, требуется резервирование сетевой инфраструктуры.
Для резервирования на уровне L2 в простейшем случае используется Virtual Chassis/Fabric/MC-LAG. Тогда конечный хост подключается сети дата-центра с использованием LAG (Etherchannel):

Возможными точками отказа являются сам конечный хост и маршрутизатор.
Резервирование конечного хоста — это ответственность заказчика. Очень желательно, чтобы конечный и резервный хост были расположены в разных дата-центрах. Это позволит избежать многих проблем (с сетевой структурой, с доступностью конкретного физического сервера, с электропитанием и охлаждением на отдельно взятых площадках).
Организовать перенос IP-адреса между основным и резервным хостами можно разными способами.В пределах одного L2-сегмента это можно сделать с помощью протоколов CARP/HSRP/VRRP и их аналогов:

О полноценном резервировании на уровне дата-центра можно вести речь только в случае, если все компоненты сервиса зарезервированы, и у них нет единой точки отказа.
Идеальную схему резервирования можно представить так:
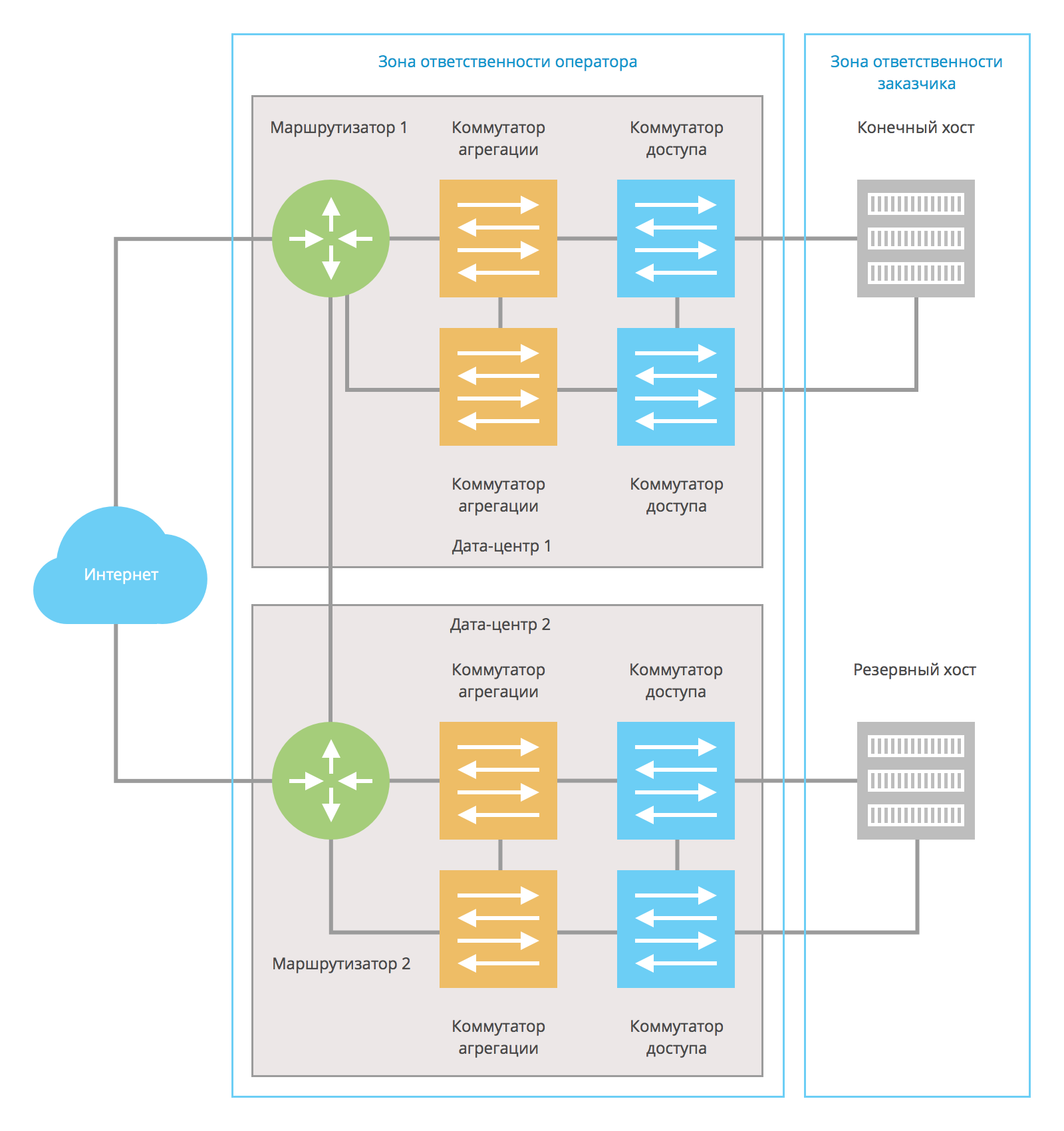
Конечный и резервный хосты заказчика находятся в разных дата-центрах. Маршрутизаторы, принадлежащие оператору, также расположены в разных дата-центрах. Дата-центры могут быть соединены несколькими каналами связи.
При возникновении неисправности в одном из дата-центров конечный хост все равно остаётся доступным. Описанный подход можно использовать для резервирования как по L2-, так и по L3-схемам.
Резервирование маршрутизаторов
Примером резервирования на уровне L3 может служить anycast-маршрутизация и использованием BGP с вышестоящим оператором. Каждый из хостов анонсирует на маршрутизаторы оператора связи сеть 12.34.56.72/29 с разным приоритетом. При этом каждый хост подключается к маршрутизаторам оператора связи отдельной подсетью, отдельным VLAN’ом:

Такая схема обладает следующими преимуществами:
- она широко используется в Интернете (BGP);
- масштабирование осуществляется не на два, а на несколько дата-центров;
Не лишена она и недостатков, в числе которых нужно назвать:
- низкую скорость работы (по умолчанию скорость сходимости BGP — от 1.5 минут);
- сложность настройки;
- необходимость выделения отдельных подсетей для подключения в каждом дата-центре.
Скорость переключения на резервный хост можно ускорить, если использовать не BGP, а другой протокол — OSPF или IS-IS. Сложность здесь заключается в том, что далеко не каждый оператор связи даст возможность использовать эти протоколы: с их помощью обычно осуществляется передача служебных данных (например, MPLS-меток или служебных адресов), а полноценных возможностей ограничения нет.
При использовании L2-схемы оператор организует единый L2-домен между основным и резервным хостами. Между маршрутизаторами организуется VXLAN или MPLS-туннель:
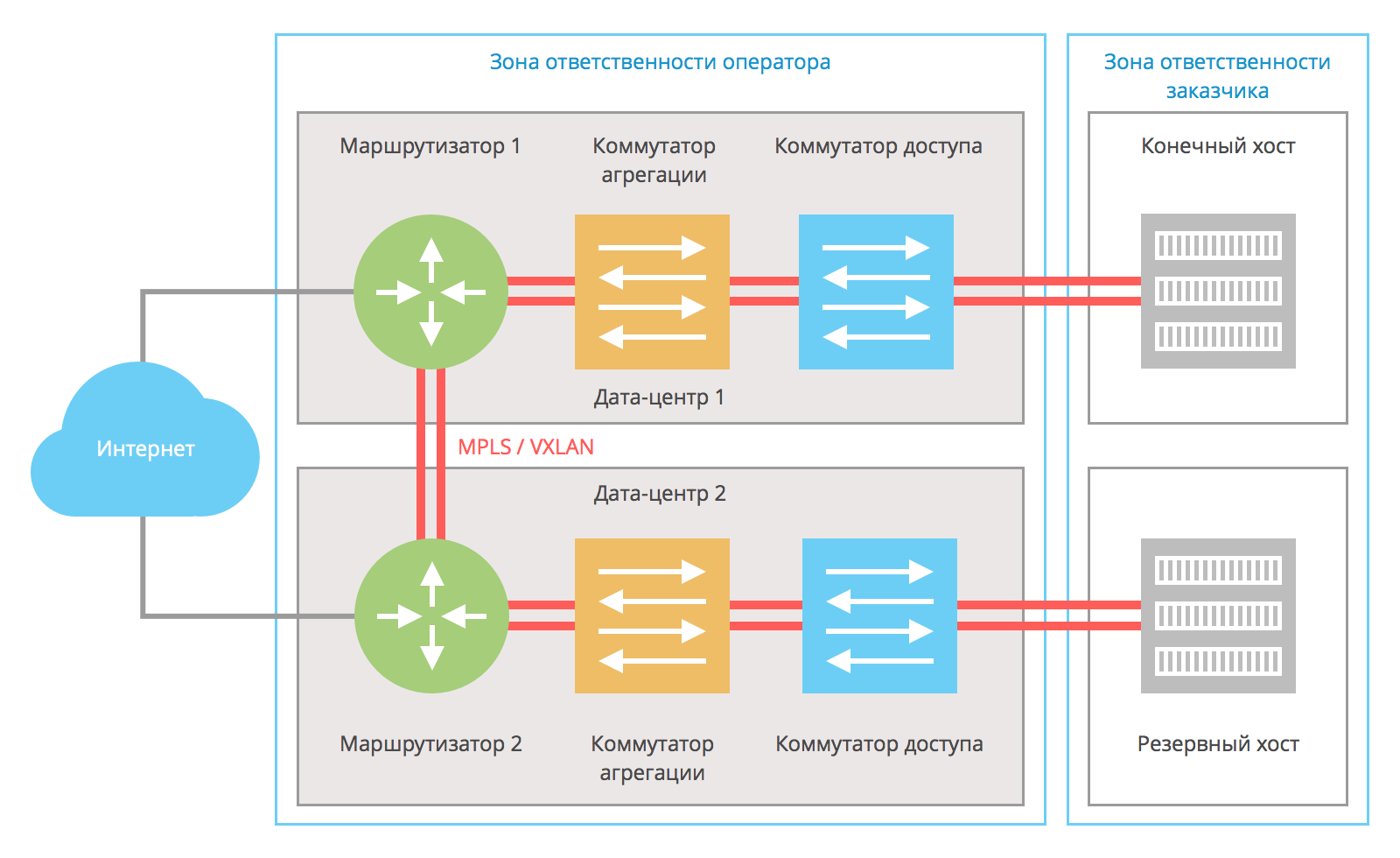
VXLAN / MPLS помогают организовать резервирование с использованием нескольких каналов связи между маршрутизаторами провайдера.
Конечный и резервный хосты между собой используют VRRP или его аналоги. Таким образом IP-адрес 12.34.56.78 оказывается на активном в текущий момент хосте (если оба хоста активны — то на сконфигурированном master-хосте). Конечный хост получает IP-адрес из этой сети — 12.34.56.77, резервый хост получает адрес из той же сети — 12.34.56.76. Если на хостах установлена ОС Windows, то вместо VRRP можно использовать NLB-кластеризацию.

Аналогичная схема строится и со стороны оператора. Оба маршрутизатора участвуют в одном VRRP-домене и разделяют между собой адрес шлюза по умолчанию —12.34.56.73/29. Маршрутизатор 1 является предварительно сконфигурированным мастером с физическим IP-адресом 12.34.56.73, а маршрутизатор 2 — резервным маршрутизатором с физическим адресом 12.34.56.74; адрес 12.34.56.73 для него является виртуальным и активным только в момент недоступности маршрутизатора 1.

Несомненными преимуществами такой схемы являются:
- использование стандартных протоколов (VRRP);
- простоту настройки, как со стороны заказчика, так и со стороны оператора;
- высокую скорость работы;
Недостаток только один: схему неудобно масштабировать на более чем два дата-центра.
Если случится неисправность: как это работает
В нормальной ситуации работают оба маршрутизатора и оба хоста заказчика. Один из маршрутизаторов на этапе построения схемы назначается основным (мастером) и отвечает на адрес 12.34.56.73. Аналогичным образом обстоит дело и с хостами: один из них является основным и отвечает на запросы на адрес 12.34.56.78. Второй маршрутизатор и второй хост являются резервными.
Запросы из Интернета проходят через маршрутизатор 1 и попадают на основной конечный хост. На маршрутизаторах присутствует ARP-запись 12.34.56.78 с МАС-адресом 0000:5E00:01xx, указывающим в сторону основного хоста. Основной хост отвечает хостам в Интернете по роутингу через маршрутизатор 1 (для хостов указан default gateway 12.34.56.73). Для сокращения сетевой задержки основной маршрутизатор размещается в том же дата-центре, что и основной хост.
Что происходит, когда один из хостов недоступен? VRRP на резервном хосте определяет, что основной хост перестал отвечать на keep-alive запросы, и на резервном хосте устанавливается IP-адрес 12.34.56.78:
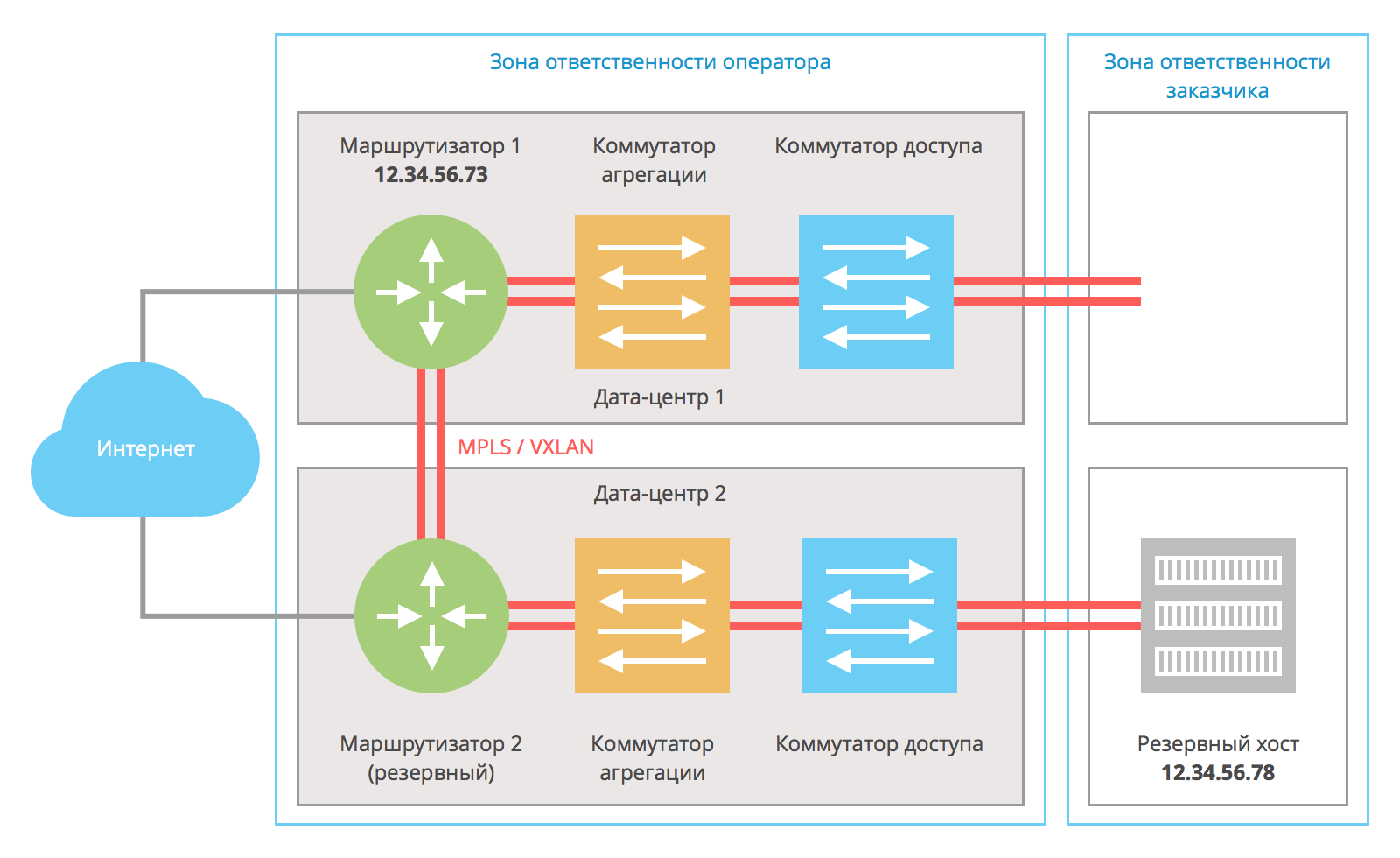
апросы из интернета попадают на маршрутизатор 1; он в своей ARP-таблице видит МАС-адрес, соответствующий IP-адресу 12.34.56.78 со стороны маршрутизатора 2 и отправляет трафик на резервный хост. Резервный хост отправляет ответный трафик на шлюз по умолчанию 12.34.56.73, т.е. через маршрутизатор 1. При использовании этой схемы увеличивается сетевая задержка между хостами в Интернете и резервируемым хостом.
После устранения неисправностей IP-адрес 12.34.56.78 снова становится доступен на основном хосте, и схема работает в штатном режиме.
Аналогичным образом эта схема работает в случае неисправности сетевой инфраструктуры между маршрутизатором и конечным хостом:
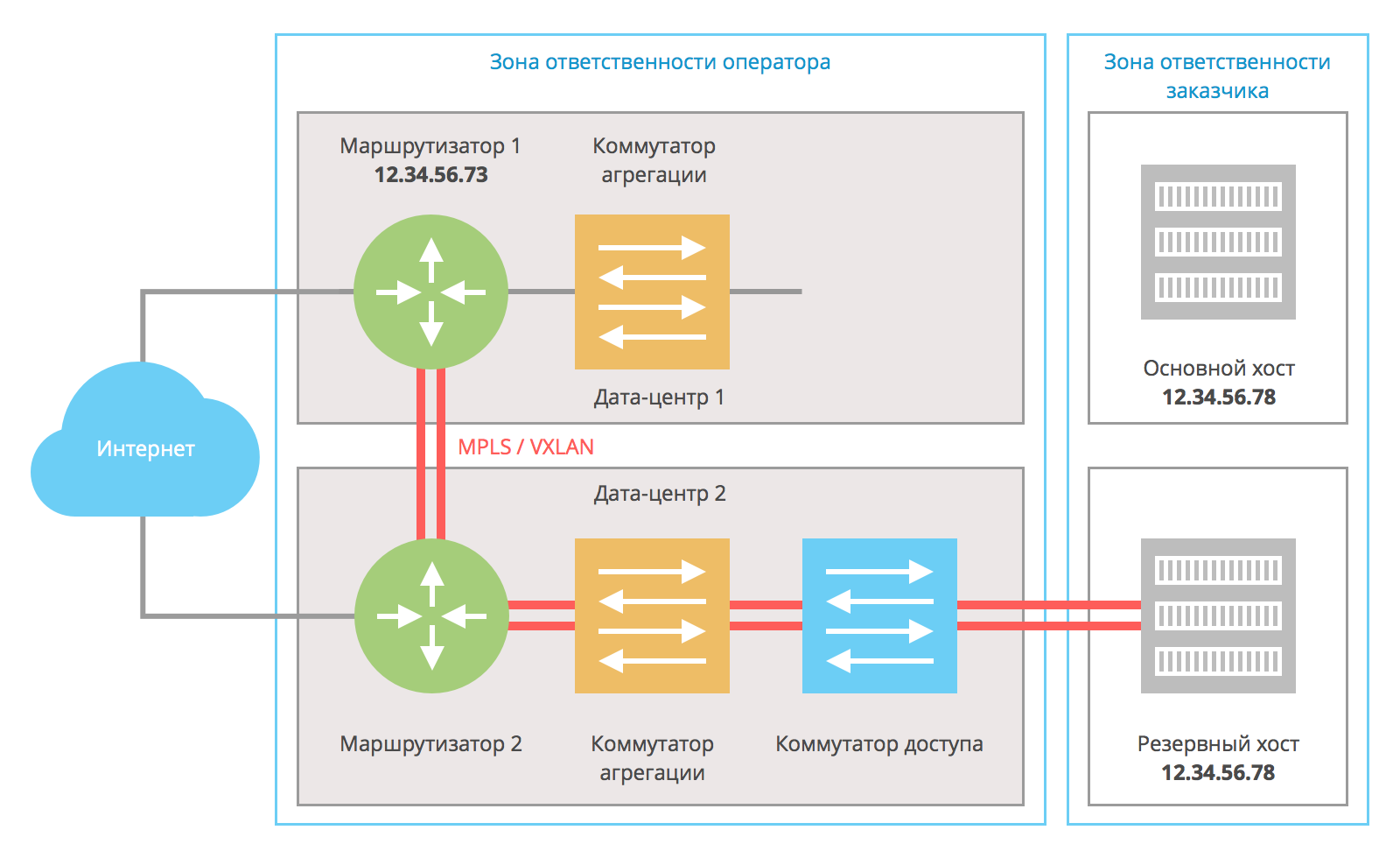
При выходе промежуточного коммутатора из строя основной хост по-прежнему остаётся носителем адреса 12.34.56.78, но у него нет сетевой связи с маршрутизатором и он не участвует в обработке запросов из Интернета. Резервный хост, потеряв связность с основным, становится ответственным за адрес 12.34.56.78.
Если становится недоступным маршрутизатор 1 или вообще весь дата-центр 1 целиком, то схема работает исключительно через маршрутизатор 2 и резервный хост:
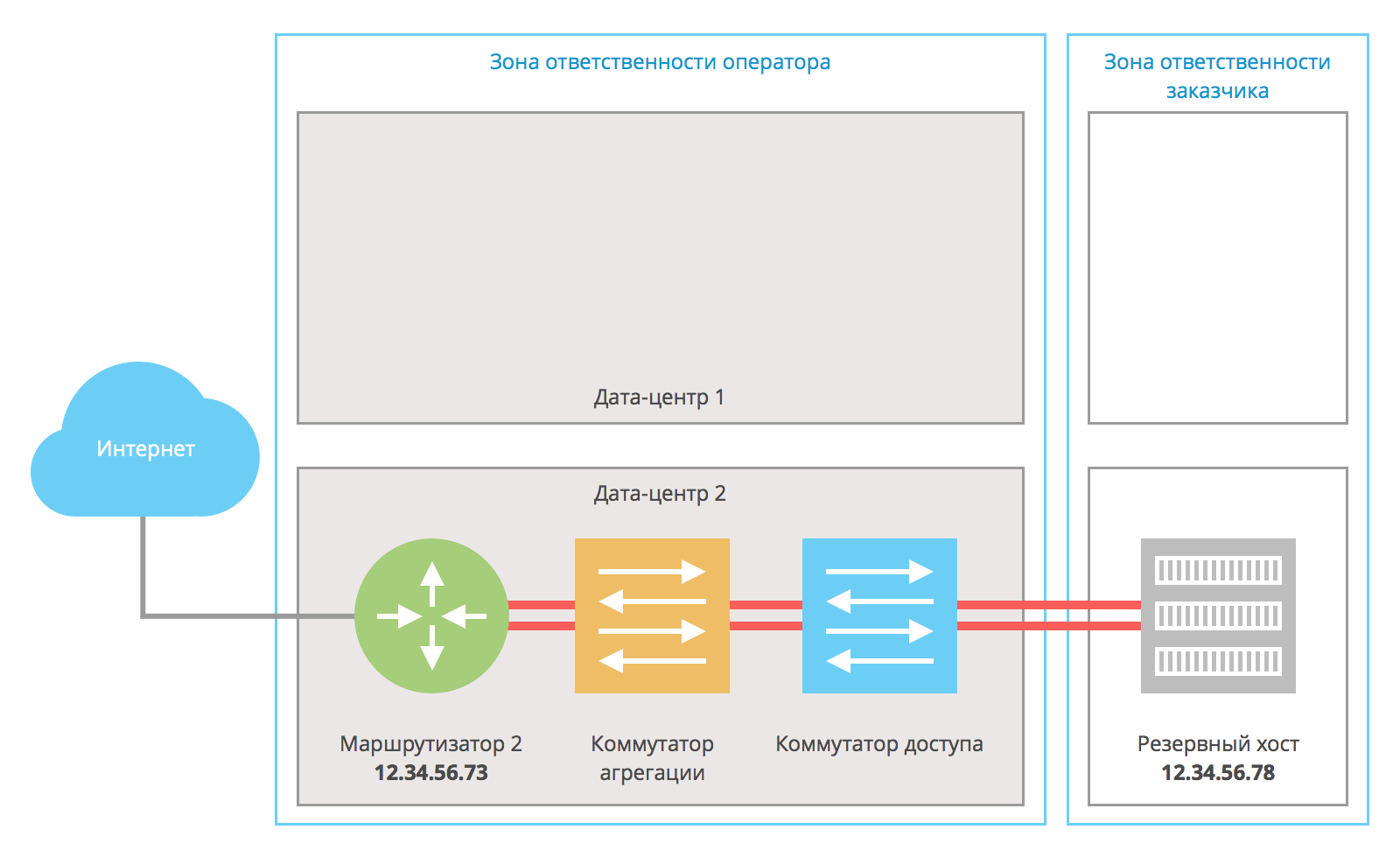
После восстановления инфраструктуры схема переходит в работу в штатном режиме. Практически никакие неисправности в дата-центре 2 не влияют на доступность конечного хоста.
Данное решение позволяет осуществлять инсталляцию и обслуживание высокодоступных ресурсов, полноценное их резервирование и разнесение в раздельные дата-центры.
Заключение
В этой статье мы рассмотрели технологии резервирования сетевых подключений с использованием протокола VRRP. Соответствующую услугу можно заказать в нашей панели управления.
Если у вас есть вопросы — добро пожаловать в комментарии. Читателей, которые по тем или иным причинам не могут оставлять комментарии здесь, приглашаем к нам в блог.
Комментарии (8)


ibKpoxa
23.09.2015 15:18Маршрутизаторы на картинках без резервирования, что будет если выйдет из строя маршрутизатор? В схеме, когда у клиента 1 сервер, как сейчас в реальности к многих.

CMHungry
23.09.2015 17:43+1Даунтайм будет, к сожалению.
В маршрутизаторе компоненты сами по себе redundant — два модуля управления, 4 блока питания, несколько модулей системной шины, несколько линейных карт.
По опыту — сервер имеет больше шансов сломаться, нежели чем маршрутизатор.

tgz
26.09.2015 13:14Скучно. Раз уж пишете про ЦОДы, рассказали бы как при дефиците IP раздавать на сервера /32.
Впрочем у вас же ждунипер, там такое не бывает.
И вообще ни один вендор до сих пор vrrp от используемой подсети не отвязал, так и городят костыли, нещасные…

Karroplan
Лучше вместо обвязки вокруг vrrp у которого есть мноооого проблем, тем более в облаке, сделайте для доступный для клиентов балансировщик нагрузки. Я уже не знаю на чем у вас внутренний sdn (надеюсь он у вас есть), но вот у vmWare NSX есть встроенная функция балансировщика, причем распределенного. вместо того чтоб городить костыли вокруг протоколов с 20-летней историей начните использовать современные технологии.
CMHungry
балансировщики у VMWare — это программные решения, и ограничения реальные около 1-1.5 мппс. В случае VRRP мы это делаем на железных маршрутизаторах и можем переварить бОльшую нагрузку.