
Привет! Меня зовут Артём, я учусь на совместной кафедре анализа данных Яндекса и Физтеха. Хочу поделиться с ML-сообществом Хабра темой, тесно связанной с моей научной работой: «Удаление отражений с помощью свёрточной сети, обученной на синтетическом датасете». А чтобы вы могли попробовать всё описанное далее самостоятельно, прилагаю PyTorch-код на GitHub и в Yandex DataSphere.

Источник: SIRR Using Deep Encoder-Decoder Network
Вы наверняка знаете, что стёкла не бывают полностью прозрачными. Часто это можно заметить при съёмке через стекло — на фото видны отражения окружающих объектов (например, самой камеры). Такие дефекты уже научились удалять во время съёмки, если есть доступ к текущему видеопотоку камеры.
Но что делать, если фотография уже сделана? В интернете много гайдов по удалению отражений с помощью графических редакторов, но это занимает много времени. Хочется качественно исправить фото «одним кликом». Если вы знаете о плагине или приложении, которое умеет так делать, обязательно поделитесь им в комментариях.
А в этой статье мы построим своё удаление отражений, используя нейросети. Такой подход:
Поговорим о задаче удаления отражений в автоматическом режиме при наличии лишь одного изображения. В статьях эту задачу называют Single Image Reflection Removal (SIRR, пример) — «удаление отражений с одного изображения». Если используется множество изображений (скажем, тот же видеопоток), задача называется уже Multiple Image Reflection Removal (MIRR, пример). MIRR имеет свои особенности, и его рассмотрение, к сожалению, выходит за рамки нашей статьи.
В чём же сложность SIRR?
Дело в неоднозначности решения задачи — для одного фото с отражениями сложно подобрать наиболее правильную версию без отражений, так как существует множество возможных вариантов. Большую роль здесь играет «сжатие диапазонов»: при фотографировании через стекло сцена за стеклом обычно будет тусклее, но незначительно отличающиеся сцены (в полном диапазоне яркости 0–255) после потускнения могут выглядеть почти одинаково. Ещё острее проблема построения правильного отображения изначальной сцены встаёт, когда отражения очень яркие — в этом случае то, что за бликами, восстановить невозможно.
Как же тогда решают задачу SIRR? И решаема ли она?
Оказывается, что решаема. Ключом к решению служат особенности формирования отражений. По своей природе отражения чаще всего:
На основе этих свойств можно попробовать построить математические модели и затем решить задачу классическими оптимизационными методами (например, смесями гауссиан).

Источник: Benchmarking SIRR Algorithms
Мы же пойдём другим путём — научим свёрточную нейросеть удалять отражения. Поскольку наша задача не имеет точного решения, достаточно просто находить правдоподобные ответы — свёрточные сети отлично справляются с подобными ситуациями при решении задач компьютерного зрения (например, в тех же задачах сверхразрешения).
Перед тем, как что-то обучать, обязательно требуется то, на чём обучать: датасет. Самый простой датасет для задачи SIRR выглядит как набор пар изображений (I, T), где I — изображение с отражением, T — изображение без отражения (в литературе это называется transmission). Имея такой датасет, можно обучить нейросеть по I предсказывать T, что и будет соответствовать удалению отражений.
Подобные датасеты очень удобны и для валидации, и для обучения, но их невероятно трудно собирать руками. Пары (I, T) обычно получают съёмкой одной и той же сцены сначала со стеклом, а затем без стекла. Основная сложность состоит в том, чтобы ни сцена, ни положение камеры сильно не изменились за время удаления стекла из кадра. Именно поэтому такие датасеты обычно очень малы (10–100 пар) и на практике пригодны лишь для валидации.

Источник: SIRR with Perceptual Losses
Что делать? Надо же на чём-то обучить нейросеть…
На помощь приходит синтетика. Оказывается, можно не мучаться со сбором реальных пар (I, T), а сгенерировать их! Для этого достаточно набора фотографий из интернета и математических моделей, о которых мы говорили ранее.

Источник: Benchmarking SIRR Algorithms
Рецепт по приготовлению пары изображений (I, T) из датасета:
По сути, мы просто добавляем искусственное отражение R к T. Итоговая формула для отображения I:
Стоит отметить, что в такой постановке можно применять аугментации к изображениям T и R, тем самым получая ещё большее разнообразие синтетики.
Мы будем вытягивать изображения T и R из двух мест:
В первом датасете очень большое разнообразие сцен, а во втором — много разных людей в выделяющейся одежде. Обучившись на синтетике, нейросетевая модель сможет научиться удалять даже самые сложные отражения.
Датасет слепили, дело осталось за малым — за моделью.

Источник: SIRR Using Deep Encoder-Decoder Network
Оказывается, для удаления отражений достаточно небольшой свёрточной сети, описанной в статье SIRR Using Deep Encoder-Decoder Network. Это свёрточный автоэнкодер с дополнительным энкодер-декодером (UNet) посередине. Основная идея в том, чтобы подсетка посередине вычленяла отражение и последним вычитанием удаляла его с фото.
К сожалению, авторы в своей статье не проверили, действительно ли подсеть посередине учится вычленять отражения, а не делать что-то другое. Тем не менее, такая архитектура хорошо решает задачу SIRR, поэтому воспользуемся ей, но к идее о вычленении отражений будем относится с осторожностью.
Иллюстрация архитектуры видна на рисунке выше. Код модели авторы оригинальной статьи не выложили, но мы его воспроизвели — посмотреть можно на GitHub или в ноутбуке в Yandex DataSphere.
Детальный разбор архитектуры
Авторы архитектуры разделяют сеть на три смысловые части: подсеть извлечения признаков, подсеть удаления отражения и подсеть восстановления изображения.
Подсеть извлечения признаков — это шесть последовательных двумерных свёрток с активациями и достаточно большими ядрами (размер первых двух — 9x9, остальных — 5x5). Цель этой подсети — преобразовать изначальную картинку в многомерный тензор с признаками, полезными для удаления отражений. Большие ядра помогают нарастить receptive field, то есть сделать так, чтобы каждый признак в выходе подсети зависел от как можно большего куска изначального изображения.
Подсеть удаления отражения — это трёхуровневый энкодер-декодер с двумя свёртками 5x5 до и после skip-connection. В отличие от стандартного UNet, в такой архитектуре отсутствуют poolings по дороге «вниз» и skip-connections завершаются сложением, а не конкатенацией, что делает эту подсеть чем-то ближе к ResNet. Основная цель подсети — извлечь из признаков отражение. На практике подсети нужно найти тензор, вычитание которого из тензора с признаками удаляло бы отражения. Архитектуры типа энкодер-декодер хорошо подходят для подобных задач благодаря наращиванию receptive field и пробрасыванию информации через skip-connections.
Подсеть восстановления изображения — это зеркально отражённая подсеть извлечения признаков: шесть последовательных свёрток с большими ядрами, где последние две ещё сильнее увеличены. Цель — восстановить изображение из тензора признаков. На вход подсети подаётся тензор признаков, из которого вычли отражения, поэтому она должна не только обращать подсеть извлечения признаков, но и убирать все дефекты, связанные с вычитанием отражения.
Если отказаться от мысли, что подсеть посередине вычленяет отражения, объяснить принцип действия всей сети можно проще: каждая свёртка последовательно увеличивает receptive field, а интересное расположение skip-connections просто помогает в пробрасывании информации. При этом ни на каком отдельном моменте отражения не удаляются — они убираются постепенно, свёртка за свёрткой.
Сеть состоит из типичных для компьютерного зрения слоёв, которых неожиданно оказывается достаточно для решения задачи SIRR (при наличии хорошего датасета, конечно). Итак, архитектуру для модели придумали, осталось только обучить её с помощью датасета.
Вспомним, что датасет представляет собой пары (I, T), где I — изображение с отражением, а T — изображение той же самой сцены, но уже без отражений. Построенная модель M у нас end-to-end — по изображению I сразу выдаёт изображение M(I).
Для обучения модели нужно выбрать функцию потерь (loss L(T, M(I))), которую мы хотим минимизировать. Главное, чтобы выбранная функция как-то отражала похожесть изображений. Тогда при её минимизации изображение M(I) будет стремиться к T, и сеть будет учиться выдавать изображения без отражений. Примеры таких функций:
Конечно, все эти функции можно использовать одновременно — достаточно просто сложить их с разными весами и получить итоговую функцию потерь. Пример использования такой смеси функций можно найти в статье SIRR with Perceptual Losses.
Но начинать всегда стоит с чего-то простого: например, с MSE на RGB-изображениях. Оказывается, для первого приближения нам этого будет более чем достаточно.
В качестве схемы оптимизации параметров, как и для большинства подобных задач, применим ADAM. А чтобы найти наилучший learning rate, используем следующую процедуру перебора learning rate по логарифмической шкале:
Кстати, описанная процедура работает для любого оптимизатора и здорово экономит время по сравнению с перебором руками — всем рекомендую попробовать на своих задачах и взять на вооружение.
Здесь теоретическая часть заканчивается, остаётся всё запрограммировать. Современные фреймворки TensorFlow и PyTorch в этом плане мало чем отличаются, можно выбирать любой — мы взяли PyTorch.
На GitHub можно посмотреть полностью реализованный пайплайн, а в Yandex DataSphere — попробовать позапускать и пообучать модель на GPU. В том числе и бесплатно — в рамках пробного периода Yandex.Cloud.
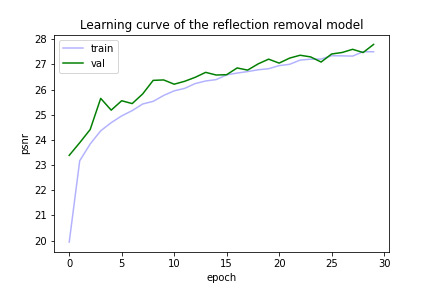
Попробуем обучить нашу модель на изображениях размера 128x128. В процессе полезно смотреть на графики функций потерь, чтобы понимать, обучается ли модель вообще. Часто от MSE между изображениями переходят к PSNR (минус прологарифмированному MSE — чем PSNR больше, тем эффективнее). Так лучше заметно последовательное улучшение модели. График ниже показывает, что модель действительно обучается, потому что PSNR на валидационной выборке у неё растёт.

А чтобы понимать, действительно ли модель выдаёт желаемый результат, нужно смотреть ещё и на примеры её работы, особенно когда вы имеете дело с изображениями. Это ещё и очень хороший способ дебага модели — на изображениях большие баги будут очень хорошо видны. На примерах ниже, взятых из нашего датасета, заметно, что модель действительно научилась удалять отражения.

Наконец, когда мы поняли, что модель всё делает правильно на наших синтетических данных, стоит проверить её уже на реальном изображении (которое мы взяли из статьи SIRR with Perceptual Losses).

Источник image, transmission: SIRR with Perceptual Losses
В примере выше видно, что с простыми отражениями (тусклыми, на однородном фоне) модель уже справляется, но сильные блики на фоне сложных текстур всё ещё остаются. Часть из них, вероятно, вообще неустранима — например, яркий блик посередине. Для остальных потребуется подумать над усложнением функции потерь, архитектуры модели, возможно — над расширением границ генерируемой синтетики.
Итак, пройдя долгий путь, мы получили работающую базовую модель для удаления отражений.
Есть много путей по улучшению качества удаления отражений нейросетями.
Что если поменять гиперпараметры обучения в текущей конфигурации — например, количество эпох, размер батча, learning rate, параметры оптимизатора? Также можно попробовать другие функции потерь и их комбинации или вообще взять в качестве таргета само отражение, а не transmission — изображение с удалённым отражением.
Опять же, можно действовать очень локально — менять у свёрток гиперпараметры: количество фильтров, размеры ядер, тип паддинга.
Изначально наша модель вообще не содержала паддингов: пространственные размерности изображения уменьшались до середины сети, а затем увеличивались с помощью транспонированных свёрток. Эта архитектура ближе к философии энкодера-декодера, потому что у неё есть «горлышко» посередине по пространственным направлениям.
Можно развить предположения авторов статьи SIRR Using Deep Encoder-Decoder Network о том, что центральная подсеть вычленяет отражения. То есть — добавить в текущую модель отдельную голову, которая будет учиться по выходу центральной подсети выдавать отражения, тем самым улучшая «вычленяющую способность» этой подсети. У нас, к сожалению, такая идея не завелась, и новая голова не сумела нормально предсказывать отражения. Если у вас получится, обязательно напишите в комментариях, как вам это удалось.
Кстати, если забыть об идее, что сеть учится вычленять отражения, то вся модель сводится к применению свёрток и skip-connections. Тогда вместо «длинных» skip-connections в UNet можно поставить «короткие», как в ResNet.
Кроме того, как всегда в нейросетях, можно попробовать добавить больше слоёв или тех же самых уровней в UNet. Также интересно было бы посмотреть, как другие свёрточные (и не только!) архитектуры показывают себя в этой задаче. Хороший источник альтернативных архитектур можно найти в решениях задач компьютерного зрения, таких как классификация, сверхразрешение и других.
Самое простое — изменить размер изображений, которые есть в датасете. Можно смешать изображения различных размеров, чтобы модель обобщалась лучше. Или пойти ещё более интересным путём и при обучении постепенно увеличивать размер изображений. Так сеть сначала быстро научится удалять отражения на малых размерах, а дальше будет постепенно улучшаться на размерах побольше.
Не стоит забывать и главное достоинство синтетического датасета — мы можем управлять гиперпараметрами его генерации. Можно научиться удалять более широкий спектр отражений. Для этого нужно просто расширить спектр возможных коэффициентов пропускания , гауссовых ядер размытия G и ядер раздвоения K.
Ещё такой синтетический датасет хорош тем, что можно легко перейти к удалению любых дефектов: бликов с глянца, сетчатых заборов и других. Достаточно уметь генерировать подобные дефекты.
То есть у построенного нами пайплайна есть множество возможностей для расширения и улучшения.
Задача удаления отражений с изображения (SIRR) трудна тем, что у неё нет точного решения. В таких случаях часто применяют нейронные сети, которые умеют генерировать правдоподобные ответы. Основная сложность такого подхода — в сборе данных для обучения.
Датасетов с реальными картинками для SIRR довольно мало, но здесь помогают физические свойства отражений. Благодаря им можно легко генерировать синтетику на основе обыкновенных изображений. Таких данных достаточно, чтобы обучить свёрточную нейросеть типа энкодер-декодер — хорошую для первого захода модель SIRR.
Код доступен на GitHub, а запустить его можно попробовать в Yandex DataSphere.
Статьи
[1] Recognizing Indoor Scenes, A.Quattoni et al., doi:10.1109/CVPR.2009.5206537.
[2] Robust Separation of Reflection from Multiple Images, X.Guo et al., CVPR 2014.
[3] Clothing Co-Parsing by Joint Image Segmentation and Labeling, W.Yang et al., arXiv:1502.00739.
[4] U-Net: Convolutional Networks for Biomedical Image Segmentation, O.Ronneberger et al., arXiv:1505.04597.
[5] Reflection Removal Using Ghosting Cues, Y.C.Shih et al., CVPR 2015.
[6] A Computational Approach for Obstruction-Free Photography, T.Xue et al., doi:10.1145/2766940.
[7] Deep Residual Learning for Image Recognition, K.He et al., arXiv:1512.03385.
[8] Benchmarking Single-Image Reflection Removal Algorithms, R.Wan et al., doi:10.1109/ICCV.2017.423.
[9] Single Image Reflection Removal Using Deep Encoder-Decoder Network, Z.Chi et al., arXiv:1802.00094.
[10] Single Image Reflection Separation with Perceptual Losses, X.Zhang et al., arXiv:1806.05376.
Источник: SIRR Using Deep Encoder-Decoder Network
Что за удаление отражений?
Вы наверняка знаете, что стёкла не бывают полностью прозрачными. Часто это можно заметить при съёмке через стекло — на фото видны отражения окружающих объектов (например, самой камеры). Такие дефекты уже научились удалять во время съёмки, если есть доступ к текущему видеопотоку камеры.
Но что делать, если фотография уже сделана? В интернете много гайдов по удалению отражений с помощью графических редакторов, но это занимает много времени. Хочется качественно исправить фото «одним кликом». Если вы знаете о плагине или приложении, которое умеет так делать, обязательно поделитесь им в комментариях.
А в этой статье мы построим своё удаление отражений, используя нейросети. Такой подход:
- позволит достичь хороших показателей по качеству и скорости,
- даст возможность управлять соотношением качества и скорости с помощью настройки размера обучаемой модели,
- откроет дорогу к удалению других дефектов (например, бликов с глянцевых поверхностей) с помощью датасетов, аналогичных тому, что мы будем использовать при решении нашей задачи.
SIRR — Single Image Reflection Removal
Поговорим о задаче удаления отражений в автоматическом режиме при наличии лишь одного изображения. В статьях эту задачу называют Single Image Reflection Removal (SIRR, пример) — «удаление отражений с одного изображения». Если используется множество изображений (скажем, тот же видеопоток), задача называется уже Multiple Image Reflection Removal (MIRR, пример). MIRR имеет свои особенности, и его рассмотрение, к сожалению, выходит за рамки нашей статьи.
В чём же сложность SIRR?
Дело в неоднозначности решения задачи — для одного фото с отражениями сложно подобрать наиболее правильную версию без отражений, так как существует множество возможных вариантов. Большую роль здесь играет «сжатие диапазонов»: при фотографировании через стекло сцена за стеклом обычно будет тусклее, но незначительно отличающиеся сцены (в полном диапазоне яркости 0–255) после потускнения могут выглядеть почти одинаково. Ещё острее проблема построения правильного отображения изначальной сцены встаёт, когда отражения очень яркие — в этом случае то, что за бликами, восстановить невозможно.
Как же тогда решают задачу SIRR? И решаема ли она?
Оказывается, что решаема. Ключом к решению служат особенности формирования отражений. По своей природе отражения чаще всего:
- тусклые — лишь малая часть света отражается от стекла,
- расплывчатые — отражаемые объекты обычно лежат не в фокусе камеры,
- раздвоенные — идёт отражение как от ближней, так и от дальней границы стекла.
На основе этих свойств можно попробовать построить математические модели и затем решить задачу классическими оптимизационными методами (например, смесями гауссиан).
Источник: Benchmarking SIRR Algorithms
Мы же пойдём другим путём — научим свёрточную нейросеть удалять отражения. Поскольку наша задача не имеет точного решения, достаточно просто находить правдоподобные ответы — свёрточные сети отлично справляются с подобными ситуациями при решении задач компьютерного зрения (например, в тех же задачах сверхразрешения).
Датасет, или Рубрика «не всё так просто»
Перед тем, как что-то обучать, обязательно требуется то, на чём обучать: датасет. Самый простой датасет для задачи SIRR выглядит как набор пар изображений (I, T), где I — изображение с отражением, T — изображение без отражения (в литературе это называется transmission). Имея такой датасет, можно обучить нейросеть по I предсказывать T, что и будет соответствовать удалению отражений.
Подобные датасеты очень удобны и для валидации, и для обучения, но их невероятно трудно собирать руками. Пары (I, T) обычно получают съёмкой одной и той же сцены сначала со стеклом, а затем без стекла. Основная сложность состоит в том, чтобы ни сцена, ни положение камеры сильно не изменились за время удаления стекла из кадра. Именно поэтому такие датасеты обычно очень малы (10–100 пар) и на практике пригодны лишь для валидации.
Источник: SIRR with Perceptual Losses
Что делать? Надо же на чём-то обучить нейросеть…
На помощь приходит синтетика. Оказывается, можно не мучаться со сбором реальных пар (I, T), а сгенерировать их! Для этого достаточно набора фотографий из интернета и математических моделей, о которых мы говорили ранее.
Источник: Benchmarking SIRR Algorithms
Рецепт по приготовлению пары изображений (I, T) из датасета:
- возьмите любую пару изображений, назовём их T и R (сразу получили T!),
- выберите произвольные: коэффициент пропускания (тускление), гауссово ядро G (размытие), ядро раздвоения K (раздвоение),
- примените ядра к R, получив R’,
- замешайте с коэффициентом alpha изображения T и R’, получив I.
По сути, мы просто добавляем искусственное отражение R к T. Итоговая формула для отображения I:
Стоит отметить, что в такой постановке можно применять аугментации к изображениям T и R, тем самым получая ещё большее разнообразие синтетики.
Мы будем вытягивать изображения T и R из двух мест:
- датасет изображений различных помещений из статьи Recognizing Indoor Scenes,
- датасет фотографий уличной моды из статьи Clothing Co-Parsing by Joint Image Segmentation and Labeling.
В первом датасете очень большое разнообразие сцен, а во втором — много разных людей в выделяющейся одежде. Обучившись на синтетике, нейросетевая модель сможет научиться удалять даже самые сложные отражения.
Датасет слепили, дело осталось за малым — за моделью.
Модель, или All You Need Is… свёртки
Источник: SIRR Using Deep Encoder-Decoder Network
Оказывается, для удаления отражений достаточно небольшой свёрточной сети, описанной в статье SIRR Using Deep Encoder-Decoder Network. Это свёрточный автоэнкодер с дополнительным энкодер-декодером (UNet) посередине. Основная идея в том, чтобы подсетка посередине вычленяла отражение и последним вычитанием удаляла его с фото.
К сожалению, авторы в своей статье не проверили, действительно ли подсеть посередине учится вычленять отражения, а не делать что-то другое. Тем не менее, такая архитектура хорошо решает задачу SIRR, поэтому воспользуемся ей, но к идее о вычленении отражений будем относится с осторожностью.
Иллюстрация архитектуры видна на рисунке выше. Код модели авторы оригинальной статьи не выложили, но мы его воспроизвели — посмотреть можно на GitHub или в ноутбуке в Yandex DataSphere.
Детальный разбор архитектуры
Авторы архитектуры разделяют сеть на три смысловые части: подсеть извлечения признаков, подсеть удаления отражения и подсеть восстановления изображения.
Подсеть извлечения признаков — это шесть последовательных двумерных свёрток с активациями и достаточно большими ядрами (размер первых двух — 9x9, остальных — 5x5). Цель этой подсети — преобразовать изначальную картинку в многомерный тензор с признаками, полезными для удаления отражений. Большие ядра помогают нарастить receptive field, то есть сделать так, чтобы каждый признак в выходе подсети зависел от как можно большего куска изначального изображения.
Подсеть удаления отражения — это трёхуровневый энкодер-декодер с двумя свёртками 5x5 до и после skip-connection. В отличие от стандартного UNet, в такой архитектуре отсутствуют poolings по дороге «вниз» и skip-connections завершаются сложением, а не конкатенацией, что делает эту подсеть чем-то ближе к ResNet. Основная цель подсети — извлечь из признаков отражение. На практике подсети нужно найти тензор, вычитание которого из тензора с признаками удаляло бы отражения. Архитектуры типа энкодер-декодер хорошо подходят для подобных задач благодаря наращиванию receptive field и пробрасыванию информации через skip-connections.
Подсеть восстановления изображения — это зеркально отражённая подсеть извлечения признаков: шесть последовательных свёрток с большими ядрами, где последние две ещё сильнее увеличены. Цель — восстановить изображение из тензора признаков. На вход подсети подаётся тензор признаков, из которого вычли отражения, поэтому она должна не только обращать подсеть извлечения признаков, но и убирать все дефекты, связанные с вычитанием отражения.
Если отказаться от мысли, что подсеть посередине вычленяет отражения, объяснить принцип действия всей сети можно проще: каждая свёртка последовательно увеличивает receptive field, а интересное расположение skip-connections просто помогает в пробрасывании информации. При этом ни на каком отдельном моменте отражения не удаляются — они убираются постепенно, свёртка за свёрткой.
Сеть состоит из типичных для компьютерного зрения слоёв, которых неожиданно оказывается достаточно для решения задачи SIRR (при наличии хорошего датасета, конечно). Итак, архитектуру для модели придумали, осталось только обучить её с помощью датасета.
Как обучать-то будем?
Вспомним, что датасет представляет собой пары (I, T), где I — изображение с отражением, а T — изображение той же самой сцены, но уже без отражений. Построенная модель M у нас end-to-end — по изображению I сразу выдаёт изображение M(I).
Для обучения модели нужно выбрать функцию потерь (loss L(T, M(I))), которую мы хотим минимизировать. Главное, чтобы выбранная функция как-то отражала похожесть изображений. Тогда при её минимизации изображение M(I) будет стремиться к T, и сеть будет учиться выдавать изображения без отражений. Примеры таких функций:
- MSE между изображениями как тензорами чисел в любом цветовом пространстве (RGB, LAB, YCbCr и других).
- Feature loss — MSE между признаками, которые получаются на неком свёрточном слое другой предобученной сети (VGG, ResNet) при прогоне изображений через эту сеть. Так изображения сближаются по содержанию: учитываются наличие, размер, число объектов разных форм и расцветок (линий, углов, кругов...).
- Adversarial loss — обучаем уже в схеме GAN'ов, где M становится генератором и добавляется дискриминатор, который позволяет M генерировать более реалистичные изображения. Особенно помогает в улучшении генерации текстур.
Конечно, все эти функции можно использовать одновременно — достаточно просто сложить их с разными весами и получить итоговую функцию потерь. Пример использования такой смеси функций можно найти в статье SIRR with Perceptual Losses.
Но начинать всегда стоит с чего-то простого: например, с MSE на RGB-изображениях. Оказывается, для первого приближения нам этого будет более чем достаточно.
В качестве схемы оптимизации параметров, как и для большинства подобных задач, применим ADAM. А чтобы найти наилучший learning rate, используем следующую процедуру перебора learning rate по логарифмической шкале:
- Фиксируем диапазон для перебора learning rate [min_lr, max_lr] (например, от min_lr=10^{-7} до max_lr=10^2).
- Берём только что инициализированную нейросеть и тренировочный датасет из n_batches батчей.
- Делаем сетью один проход обучения по тренировочному датасету, но по мере прохода датасета меняем learning rate по логлинейному расписанию. Для батча под номером m ставим следующий learning rate в оптимизаторе:
Формула для learning rate-батча под номером m - Строим график функции потерь в зависимости от learning rate (шага).

- Выбираем наилучший learning rate по эвристике: где ошибка падает быстрее всего, там и находятся самые подходящие значения. Такая learning rate:
- гарантирует, что сеть не будет «разрываться», а обучение будет происходить максимально быстро,
- предназначен для обучения сети со свежей инициализацией (сеть, обученную в пункте 3, можно спокойно удалить).
Кстати, описанная процедура работает для любого оптимизатора и здорово экономит время по сравнению с перебором руками — всем рекомендую попробовать на своих задачах и взять на вооружение.
Здесь теоретическая часть заканчивается, остаётся всё запрограммировать. Современные фреймворки TensorFlow и PyTorch в этом плане мало чем отличаются, можно выбирать любой — мы взяли PyTorch.
На GitHub можно посмотреть полностью реализованный пайплайн, а в Yandex DataSphere — попробовать позапускать и пообучать модель на GPU. В том числе и бесплатно — в рамках пробного периода Yandex.Cloud.
Что в итоге получается?
Попробуем обучить нашу модель на изображениях размера 128x128. В процессе полезно смотреть на графики функций потерь, чтобы понимать, обучается ли модель вообще. Часто от MSE между изображениями переходят к PSNR (минус прологарифмированному MSE — чем PSNR больше, тем эффективнее). Так лучше заметно последовательное улучшение модели. График ниже показывает, что модель действительно обучается, потому что PSNR на валидационной выборке у неё растёт.
А чтобы понимать, действительно ли модель выдаёт желаемый результат, нужно смотреть ещё и на примеры её работы, особенно когда вы имеете дело с изображениями. Это ещё и очень хороший способ дебага модели — на изображениях большие баги будут очень хорошо видны. На примерах ниже, взятых из нашего датасета, заметно, что модель действительно научилась удалять отражения.
Наконец, когда мы поняли, что модель всё делает правильно на наших синтетических данных, стоит проверить её уже на реальном изображении (которое мы взяли из статьи SIRR with Perceptual Losses).
Источник image, transmission: SIRR with Perceptual Losses
В примере выше видно, что с простыми отражениями (тусклыми, на однородном фоне) модель уже справляется, но сильные блики на фоне сложных текстур всё ещё остаются. Часть из них, вероятно, вообще неустранима — например, яркий блик посередине. Для остальных потребуется подумать над усложнением функции потерь, архитектуры модели, возможно — над расширением границ генерируемой синтетики.
Итак, пройдя долгий путь, мы получили работающую базовую модель для удаления отражений.
А что ещё можно попробовать?
Есть много путей по улучшению качества удаления отражений нейросетями.
Обучение
Что если поменять гиперпараметры обучения в текущей конфигурации — например, количество эпох, размер батча, learning rate, параметры оптимизатора? Также можно попробовать другие функции потерь и их комбинации или вообще взять в качестве таргета само отражение, а не transmission — изображение с удалённым отражением.
Модель
Опять же, можно действовать очень локально — менять у свёрток гиперпараметры: количество фильтров, размеры ядер, тип паддинга.
Изначально наша модель вообще не содержала паддингов: пространственные размерности изображения уменьшались до середины сети, а затем увеличивались с помощью транспонированных свёрток. Эта архитектура ближе к философии энкодера-декодера, потому что у неё есть «горлышко» посередине по пространственным направлениям.
Но в наших экспериментах такая модель плохо восстанавливала края изображения — они получались очень размытыми. Поэтому в итоге мы отказались от «горлышка» и перешли на зеркальный паддинг.

Можно развить предположения авторов статьи SIRR Using Deep Encoder-Decoder Network о том, что центральная подсеть вычленяет отражения. То есть — добавить в текущую модель отдельную голову, которая будет учиться по выходу центральной подсети выдавать отражения, тем самым улучшая «вычленяющую способность» этой подсети. У нас, к сожалению, такая идея не завелась, и новая голова не сумела нормально предсказывать отражения. Если у вас получится, обязательно напишите в комментариях, как вам это удалось.
Кстати, если забыть об идее, что сеть учится вычленять отражения, то вся модель сводится к применению свёрток и skip-connections. Тогда вместо «длинных» skip-connections в UNet можно поставить «короткие», как в ResNet.
В наших экспериментах модель, упрощённая до простой последовательности ResNet-блоков, по качеству получается очень близка к текущей UNet-модели.
Что будет, если заменить UNet на простую ResNet-сеть?
Попробуем следующую архитектуру:
Кроме того, давайте использовать батч-нормализацию для ускорения сходимости (как в обычном ResNet).
Итоговая сеть будет иметь примерно втрое меньше параметров и обучаться примерно вдвое быстрее! А что по поводу качества?
По PSNR и результатам на синтетике модели примерно одинаковы.

Но на реальном изображении проявляются некоторые отличия. ResNet:


Источник image, transmission: SIRR with Perceptual Losses
В целом упрощённая архитектура показала себя достойно. Поэтому эксперименты по улучшению модели можно проводить и с ней.
Эксперимент: простая архитектура ResNet-like тоже работает?
Что будет, если заменить UNet на простую ResNet-сеть?
Попробуем следующую архитектуру:
- свёртка 1x1, раздувающая 3 канала в 64,
- 10 ResNet-блоков (блок — это две свёртки 3x3 и skip-connection),
- свёртка 1x1, схлопывающая 64 канала обратно в 3.
Кроме того, давайте использовать батч-нормализацию для ускорения сходимости (как в обычном ResNet).
Итоговая сеть будет иметь примерно втрое меньше параметров и обучаться примерно вдвое быстрее! А что по поводу качества?
По PSNR и результатам на синтетике модели примерно одинаковы.
Но на реальном изображении проявляются некоторые отличия. ResNet:
- более агрессивно удаляет размытость от блюра с отражений, чем UNet,
- но при этом немного чаще не справляется с полным удалением отражения.
Источник image, transmission: SIRR with Perceptual Losses
В целом упрощённая архитектура показала себя достойно. Поэтому эксперименты по улучшению модели можно проводить и с ней.
Кроме того, как всегда в нейросетях, можно попробовать добавить больше слоёв или тех же самых уровней в UNet. Также интересно было бы посмотреть, как другие свёрточные (и не только!) архитектуры показывают себя в этой задаче. Хороший источник альтернативных архитектур можно найти в решениях задач компьютерного зрения, таких как классификация, сверхразрешение и других.
Датасет
Самое простое — изменить размер изображений, которые есть в датасете. Можно смешать изображения различных размеров, чтобы модель обобщалась лучше. Или пойти ещё более интересным путём и при обучении постепенно увеличивать размер изображений. Так сеть сначала быстро научится удалять отражения на малых размерах, а дальше будет постепенно улучшаться на размерах побольше.
Не стоит забывать и главное достоинство синтетического датасета — мы можем управлять гиперпараметрами его генерации. Можно научиться удалять более широкий спектр отражений. Для этого нужно просто расширить спектр возможных коэффициентов пропускания , гауссовых ядер размытия G и ядер раздвоения K.
Ещё такой синтетический датасет хорош тем, что можно легко перейти к удалению любых дефектов: бликов с глянца, сетчатых заборов и других. Достаточно уметь генерировать подобные дефекты.
То есть у построенного нами пайплайна есть множество возможностей для расширения и улучшения.
Заключение
Задача удаления отражений с изображения (SIRR) трудна тем, что у неё нет точного решения. В таких случаях часто применяют нейронные сети, которые умеют генерировать правдоподобные ответы. Основная сложность такого подхода — в сборе данных для обучения.
Датасетов с реальными картинками для SIRR довольно мало, но здесь помогают физические свойства отражений. Благодаря им можно легко генерировать синтетику на основе обыкновенных изображений. Таких данных достаточно, чтобы обучить свёрточную нейросеть типа энкодер-декодер — хорошую для первого захода модель SIRR.
Код доступен на GitHub, а запустить его можно попробовать в Yandex DataSphere.
Полезные ссылки
- Indoor Scene Recognition — датасет изображений различных помещений,
- Clothing Co-Parsing (CCP) Dataset — датасет с фотографиями уличной моды,
- GitHub SIRR with Perceptual Losses — код к статье и ссылки на датасет из реальных изображений,
- How Do You Find A Good Learning Rate — описание процедуры перебора learning rate по логарифмической шкале,
- PSNR_RU, PSNR_EN — статьи в Википедии про PSNR (peak signal-to-noise ratio),
- Пробный период на Yandex.Cloud — для бесплатного использования Yandex DataSphere,
- Quickstart-гайд по Yandex DataSphere.
Статьи
[1] Recognizing Indoor Scenes, A.Quattoni et al., doi:10.1109/CVPR.2009.5206537.
[2] Robust Separation of Reflection from Multiple Images, X.Guo et al., CVPR 2014.
[3] Clothing Co-Parsing by Joint Image Segmentation and Labeling, W.Yang et al., arXiv:1502.00739.
[4] U-Net: Convolutional Networks for Biomedical Image Segmentation, O.Ronneberger et al., arXiv:1505.04597.
[5] Reflection Removal Using Ghosting Cues, Y.C.Shih et al., CVPR 2015.
[6] A Computational Approach for Obstruction-Free Photography, T.Xue et al., doi:10.1145/2766940.
[7] Deep Residual Learning for Image Recognition, K.He et al., arXiv:1512.03385.
[8] Benchmarking Single-Image Reflection Removal Algorithms, R.Wan et al., doi:10.1109/ICCV.2017.423.
[9] Single Image Reflection Removal Using Deep Encoder-Decoder Network, Z.Chi et al., arXiv:1802.00094.
[10] Single Image Reflection Separation with Perceptual Losses, X.Zhang et al., arXiv:1806.05376.




Mishootk
Для автоматической тренировки надо сделать сборку из камеры и поляризационного фильтра на поворотной раме. Съемка в автоматическом режиме сначала ищет наименее забликованное изображение (подбором поворота фильтра), затем наиболее забликованное. У вас оказываются в наличии пары фото для обучения. При наличии нескольких разноориентированных стеклянных плоскостей каждая обрабатывается независимо.
После обучения ваша сеть сможет корректировать не только блики от стекол, но и уменьшать блики от металлических и водных поверхностей (посмотрите на результат съемки с поляриком через поверхность воды). Возможно научите ее полностью эмулировать наличие поляризационного фильтра.
topilskiyak Автор
Классная идея!
Действительно сильно упрощает сборку реального датасета.
Судя по примерам с водой пары должны получиться качественными.
Правда, надо будет определить, по какому критерию считать «забликованность» изображения.
И проверить, что пары получаются получаются без сильных дефектов из-за использования такого метода с поляризацией.
Скорее всего сбор и подготовка такого датасета все еще займет довольно большое время, но даже маленький реальный датасет может сильно помочь — им можно разбавить синтетику и улучшить качество модели.
Mishootk
Если не заморачиваться с механикой, то установка на раму двух камер, на одной камере поляризатор в плоскости максимального устранения бликов от вертикальных стекол. Тренируете на витринах. и окнах.
Далее поворот на 90 градусов и тренируете на горизонтальных стеклах (например, прилавки).
С автомобильными стеклами и водой на фиксированном угле увы не получится.
Информации об электронно управляемой плоскости поляризации у меня нет. Знаю о наличии нейтрального поляризатора с электронным управлением.
Управление поворотом фильтра делать или шаговым двигателем (контроллер обучения получает команду на поворот на нужный угол) или вращением фильтра с постоянной скоростью и считыванием его ориентации для съемки в нужный момент.
Идея подсказанная тут с видео достойна применения. Поставить перед камерой вращающийся полярик и снимать видео. В постобработке выбирать близкие по времени кадры максимально похожие по геометрии, но сильно различающиеся по отражениям. Детектор наличия отражений у вас уже есть на той же сети, а этим процессом вы повышаете качество обучения (сеть самообучающаяся получается).
topilskiyak Автор
Спасибо за разъяснения!
Идея с видео действительно интересная получается.
enclis
Методов вращения и вообще синтеза поляризации (из произвольной в заданную) довольно много, для вращения подойдёт любой ЖК.
koreychenko
Задача несколько сложнее, ИМХО. Блик = пересвет. Потеря части информации, причем не только непосредственно на отражающей поверхности, но и вокруг нее на некотором расстоянии из-за засветки. Т.е. большинство изображений восстановить не получится в принципе, потому что там только #ffffff и больше нету ничего.
Ну, или это будет тупо додумывание нейросетью до какого-то среднестатистического результата ничего не имеющего с реальностью.
Мне кажется, что тут, скорее, с видео прокатит, чем с фотографией. Потому что некорректность с логической точки зрения (вдруг там нейросеть крокодила нарисует), одного кадра практически не заметна будет.
topilskiyak Автор
Задача действительно сложная при сильных бликах.
Иногда детали под ними невозможно восстановить (полный пересвет на большом участке).
Но иногда с виду кажется, что нельзя, а на деле немного можно (когда не полный пересвет).
Наконец, если поверхность на самом однородная на участке с бликом, то модель может такой блик научится «затушёвывать» благодаря большому receptive field. Конечно, никакие детали таким затушёвыванием восстановить невозможно.
Про идею удалять отражения переводя с видео на видео (если я правильно понял):
С одной стороны это проще — больше данных для восстановления каждого кадра, и вроде бы промахи в одиночных кадрах не так заметны.
С другой сложнее — надо будет согласовывать между собой кадры, чтобы получалось действительно видео, а не последовательность изображений (думаю в статьях video2video много про такое уже написано, правда).