

В GitHub мы обслуживаем несколько самых крупных Git-репозиториев в мире. Кроме того, на нашем попечении находятся одни из самых быстрорастущих репозиториев. И каждый день самые большие из поддерживаемых нами репозиториев неуклонно продолжают расти. Примерно год назад мы заметили, что задание, используемое нами для переупаковки Git-репозиториев, начало превышать по времени выполнения те тайм-ауты, которые мы отвели для крупных репозиториев. Но даже при увеличении этих тайм-аутов происходившие при обслуживании этих репозиториев сбои обычно приводили к снижению производительности, и это трудно было предотвратить.
Специально к новому старту курса по разработке на С++ мы решили поделиться переводом статьи Тейлора Блау — разработчика Git, старшего инженера-программиста в Github, о решении проблемы слишком долгой переупаковки репозиториев.
Сегодня этой проблемы не существует. GitHub может переупаковывать даже самые большие из размещённых у нас репозиториев всего за малую часть того времени, которое нам требовалось для этой задачи ранее. В этой статье мы расскажем о проблемах, с которыми сталкивались, расскажем о созданных решениях и о том, как они были безопасно развёрнуты, а также опишем возможные направления дальнейшего развития.
Вся проведённая нами работа направлена на поддержку проекта Git с открытым исходным кодом, её результаты станут доступны в готовящемся к выпуску релизе.
Проблема
Почему задание по обслуживанию репозиториев GitHub первоначально требовало таких больших трудозатрат? Причина в том, что при обслуживании каждого из репозиториев мы выбирали всё их содержимое для упаковки в один файл пакета. Это очень трудоёмкая операция, но работа с одним файлом пакета имеет и свои преимущества. С одним файлом при поиске объектов не требуется открывать сразу несколько пакетов. Также это означает, что все объекты могут быть упакованы как дельты (изменения) относительно других объектов. Хотя формат файлов пакета на Git поддерживает межпакетные дельты, но в настоящий момент Git не сохраняет их на диск. Но наиболее важной причиной является то, что поддержка битмапов достижимости, этой важнейшей, с точки зрения быстродействия системы, структуры данных, возможна только при работе с одним пакетом.
Новая функция Git, мультипакетный индекс, решает первую проблему, обеспечивая поиск всех объектов с помощью одного индекса, но последняя проблема сохраняется. Таким образом, мы решили восполнить пробелы, обеспечив поддержку битмапов в мультипакетных индексах, чтобы снять ограничение на использование только одного пакета при работе с битмапами достижимости.
Но, чтобы создавать мультипакетные битмапы, попутно нам нужно было решить ряд других интересных проблем. Во-первых, требовалось решить, как должны быть упорядочены объекты в мультипакетном индексе, чтобы достигалась хорошее сжатие битмапов. Нам также нужно было найти способ, как быстро инвертировать этот порядок для преобразования битовых позиций обратно в объекты, на которые они ссылаются. Выполнение некоторых из этих шагов также вызвало заметное повышение производительности в репозиториях с одним пакетом. Наконец, нам нужно было выработать новую стратегию переупаковки, которая бы масштабировалась с учётом объёмов последних отправок изменений на сервер, а не исходя из размеров всего репозитория.
Но, прежде чем переходить к рассмотрению всего этого, давайте начнём с самого начала.
Объекты, пакеты и выборка данных
Наверное, вам известно, что в системе Git ваши репозитории хранятся в виде наборов объектов. Каждый объект представляет собой отдельный фрагмент вашего репозитория: отдельный файл, дерево, коммит (фиксацию изменений) или тэг. Эти объекты могут храниться по отдельности как «несвязанные» объекты или совместно в одном файле пакета.
Если вы когда-либо слышали, что репозиторий Git — это «всего лишь направленный ациклический граф», то тогда вы знаете, что эти объекты могут содержать ссылки друг на друга. Деревья имеют ссылки на наборы BLOB-объектов (которые соответствуют файлам) и на другие деревья (соответствующие вложенным каталогам). Коммит связан с отдельным деревом (корнем репозитория) и определённым числом (от нуля и больше) других коммитов, являющихся родительскими по отношению к данному.
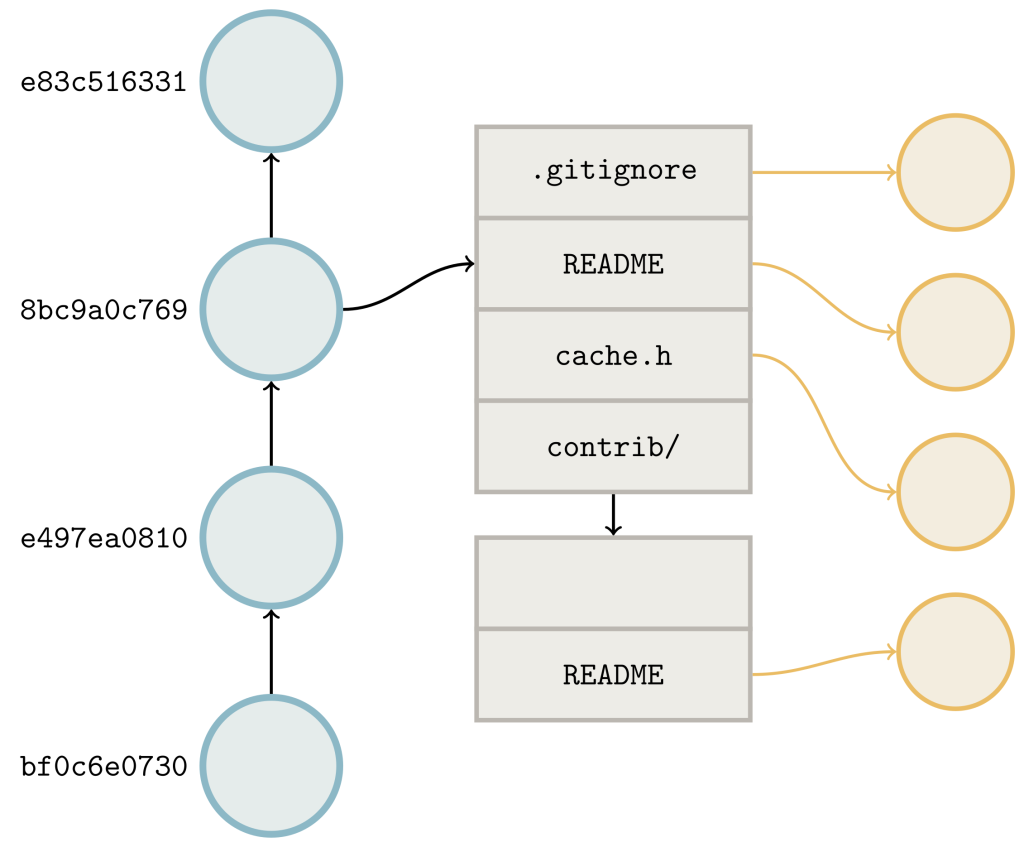
Эти связи помогают системе Git выяснять, какие объекты необходимо переместить, чтобы выполнить запрос на получение изменений или клонирование. Когда вы осуществляете получение изменений из репозитория в GitHub, система Git выполняет согласование, выясняя, изменения для каких объектов необходимо отправить. Сервер объявляет объекты, на которые указывают ссылки (обычно это концы веток и тэги). Клиент выполняет то же самое, параллельно выясняется набор ссылок, которые ему требуются от сервера. Затем сервер обходит связи между запрошенными объектами и объектами, уже имеющимися у клиента, выясняя, что нужно отправить.

Выше показан граф объектов. Клиент объявляет объекты на концах своих ссылок (коммиты, показанные тёмно-синим цветом). Объявляемые сервером ссылки окрашены тёмно-красным цветом. Затенённая голубым область соответствует результатам обхода границ для определения ограничений достижимости объектов, имеющихся у клиента. Затенённая красным область показывает такое же ограничение со стороны сервера, исключая те объекты, которые уже имеются у клиента. Объекты в этой области — это именно те объекты, которые нужно отправить клиенту.
В процессе получения изменений система Git должна отправить не только промежуточные коммиты, которые уже есть у клиента и которые ему нужны, но и все объекты, достижимые из этих коммитов. Поскольку в список всех достижимых объектов в Git не сохраняется, эта операция может быть ресурсоёмкой, особенно в случае с клонированием. При клонировании на клиенте нет никаких объектов, поэтому сервера запрашиваются все объекты, достижимые из любой ссылки.
В предыдущем посте в этом блоге мы обсуждали, как использовать битмапы достижимости в целях ускорения этого согласования. Если вы не читали эту публикацию, ниже приведён краткий пример.
Битмапы достижимости
Как же в системе Git обрабатываются те особые случаи, когда у клиента ничего нет, а ему нужно всё? Прежде всего серверу необходимо определить ограничения достижимости для всех концов ссылок. Иначе говоря, требуется список всех объектов на концах ссылок, а также всех предшественников этих объектов, чтобы на другом конце можно было собрать полную копию данного репозитория.
К сожалению для нас, чем больше репозиторий, тем дольше времени уходит у системы Git на вычисление этого списка объектов для отправки. Это становится непосильной задачей даже для репозиториев среднего размера. В нашем случае система Git могла бы решить проблему особым образом, просто отправив все имеющиеся объекты, но это может также привести к отправке множества нежелательных объектов. (Например, в GitHub в особых ссылках хранятся результаты «тестовых слияний», которые обычно не отправляются при получениях изменений, но объекты для которых, тем не менее, хранятся в том же каталоге объектов.)
Вместо этого система Git сохраняет набор битмапов достижимости, соответствующих определённым коммитам в файле пакета. Идея тут довольно проста: расположить объекты в пакете в определённом порядке (о том, какой конкретно используется порядок, мы вскоре обсудим более подробно). Затем бит из битмапа в позиции i, соответствующий коммиту C, получает значение 1, если из C можно достичь объект с номером i, или значение 0, если это сделать нельзя.
Такое однозначное соответствие между объектами и позициями битов имеет пару весьма привлекательных свойств: объединение нескольких достижимых объектов между коммитами выполнить настолько же просто, как применить логический оператор OR для их битмапов, а определение разницы между ними легко выполняется сочетанием операторов AND и NOT. Таким образом, при наличии битмапа система Git может значительно ускорить фазу согласования объектов.
Во-первых, соединим оператором OR все битмапы, соответствующие концам ссылок, требуемых клиенту. Назовём этот новый битмап W.
Затем проделаем ту же операцию с битмапами, соответствующими концам ссылок, которые клиент уже объявил как имеющиеся у него. Назовём этот битмап H.
Наконец, вычислим результат логической операции W AND NOT H, чтобы получить набор объектов, которые требуются клиенту (другими словами, определим то, что ему нужно и что у него пока отсутствует). Затем отправим эти объекты.
Поскольку вся информация о достижимости уже закодирована непосредственно в битмапах, система Git экономит время, так как нам больше не требуется открывать и анализировать сами объекты. Это позволяет получить нужный результат за малую часть того времени, которое требовалось раньше.
Сама эта идея использовалась ещё с 1970-х, чтобы ускорять запросы в реляционных базах данных. В системе Git битовые карты достижимости обеспечивают значительное ускорение при обходе объектов, находящихся в одном и том же пакете: например, обход всех объектов в репозитории ядра Linux занимал больше 33 секунд без битовых карт, а с их помощью эта операция происходит всего за 1,57 секунды.
Порядок объектов
Как же система Git преобразует набор объектов в последовательность битовых позиций? Несложно предположить, что один из способов сделать это — назначать позиции битов в лексикографическом порядке. Первый бит соответствует 000023961a, второй — 0000d6543f, второй — 000182eacf, и так далее в алфавитном порядке.
Почему бы так не сделать? Вспомним, что ID каждого объекта определяется хэш-функцией SHA-1 от его содержимого, что означает, что достижимость любого объекта при таком порядке возможна только для ближайших объектов, случайным образом. А достижимость ближайших объектов имеет значение: система Git сжимает битмапы, используя формат EWAH, при котором предполагается масштабное использование одинаковых битов. Если в результате упорядочивания объектов достижимость их от бита к биту приобретает случайный характер, система Git не сможет эффективно сжимать такие битмапы.
Порядок упаковки, т. е. физическое расположение объектов в файле пакета, создаёт последовательность позиций битов, при которой взаимодостижимые объекты располагаются друг возле друга. При этом складывается ситуация, аналогичная масштабному использованию одинаковых битов, в результате чего формат компрессии EWAH отлично работает.
Проблема
Но всё это создаёт нам проблему: если порядок позиций битов определяется расположением в пакете, то в этом случае битмапы тесно связаны концептуально и способом своей реализации с существованием одного файла в пакете. Таким образом, все объекты, накапливаемые за пределами пакета с битмапами, не получат такого же преимущества с ускорением обработки.
Для разрешения этой ситуации мы периодически выполняем переупаковку всего содержимого репозитория, объединяя его в один пакет, а затем создаём новый битмап достижимости. Это ускоряет выполнение запросов достижимости для самых свежих хронологических частей репозитория.
Но создание нового пакета приводит к увеличению затрат времени, и на самом деле это увеличение квадратичное. Чем больше репозиторий, тем больше времени требуется на переупаковку, при этом скорость увеличения репозитория также растёт, и это значит, что необходимо чаще проводить процедуры обслуживания. Этот кумулятивный эффект иногда приводит к тому, что некоторым репозиториям постоянно требуется обслуживание: к моменту завершения одного задания обслуживания в очереди уже находится другое, ожидающее своего запуска.
Но если главным ограничителем при обслуживании является сжатие всего содержимого репозитория в один файл пакета, то сколько же времени потребуется, чтобы переупаковать содержимое в несколько файлов пакета?
Мультипакетные индексы
Чтобы упорядочить набор объектов в нескольких пакетах, мы использовали недавно добавленную в Git функцию — мультипакетные индексы.
Когда системе Git требуется обнаружить объект по имени в отдельном пакете, она использует имеющийся в этом пакете файл индекса (.idx), который обеспечивает список объектов с возможностью двоичного поиска местоположений. Мультипакетные индексы работают сходно с файлами .idx, но местоположение, на которое они указывают, представляет собой пару, содержащую как сам объект, так и то, где в этом пакете можно найти данный объект.
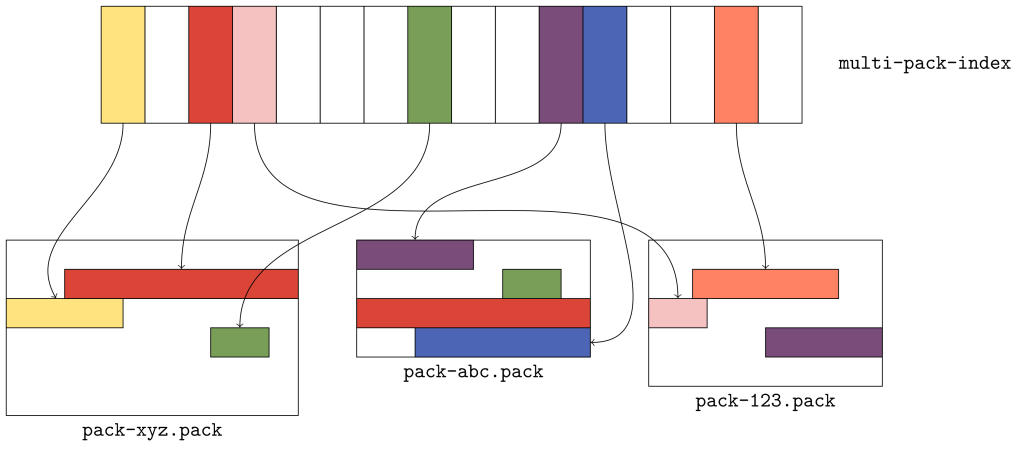
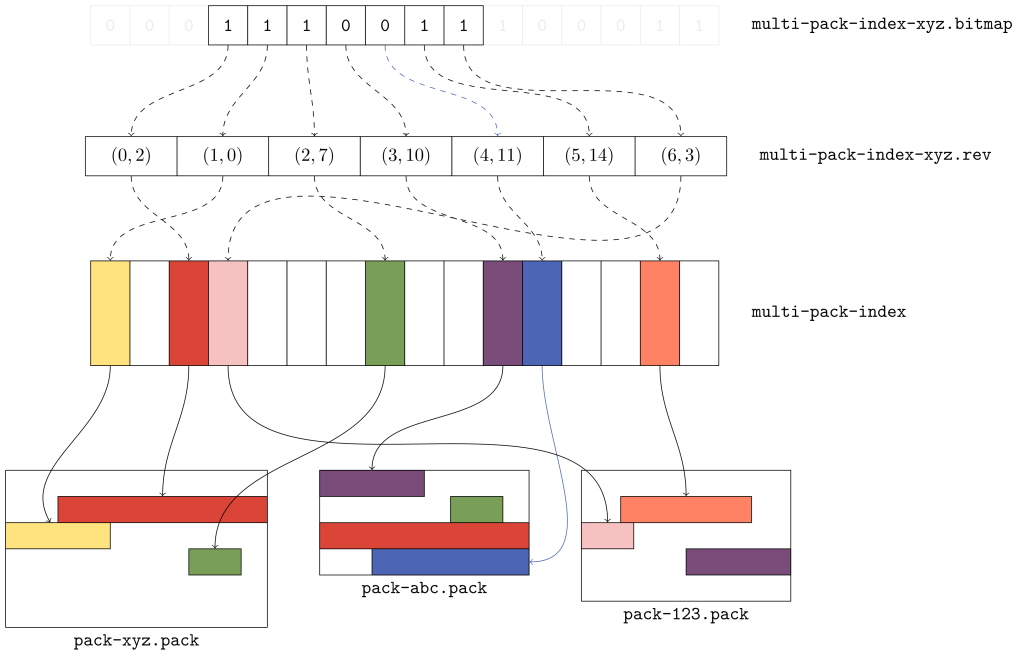
На приведённом выше рисунке показано, какие конкретно данные организованы в мультипакетном индексе. Здесь имеется три пакета, в каждом из которых находится по несколько объектов. В мультипакетном индексе хранится местоположение каждого уникального объекта в наборе пакетов. Если существует несколько копий объекта (например, зелёные или красные объекты в пакетах xyz и abc), то связи разрываются в пользу копии в пакете с самым ранним временем изменения.
Порядок объектов в мультипакетном индексе отличается от порядка в каждом отдельном пакете. Поскольку объекты в пакете могут храниться в любом порядке, в мультипакетном индексе объекты хранятся в лексикографическом порядке, чтобы каждый объект можно было быстро найти по его имени с помощью двоичного поиска.
Упорядочивание объектов
Каким же образом мы должны упорядочить объекты в пакетах, содержащихся в мультипакетном индексе? Как мы уже обсуждали ранее, упорядочивание объектов в лексикографическом порядке снижает качество сжатия. Мы также обращали внимание, что объекты в пакетах упорядочиваются топологически, и для наших целей это может означать, что отдельные объекты будут размещаться рядом с другими объектами, достижимыми из них при таком упорядочивании.
Таким образом, при любом упорядочивание объектов в мультипакетном индексе должно собираться как можно больше информации об этих двух свойствах. Учитывая это, мы решили применять следующий порядок:
Первоначально объекты группируются с учётом того, в каком файле они находятся, а пакеты упорядочиваются с учётом мультипакетного индекса.
Объекты в пределах одного пакета должны упорядочиваться с учётом их местоположения в этом пакете.
При этом происходит эффективное соединение порядков упаковки нескольких пакетов с учётом прочих особенностей упорядочивания в самих этих пакетах. Чтобы увидеть, как это происходит, давайте рассмотрим часть битмапа, охватывающую объекты из нашего предыдущего примера.
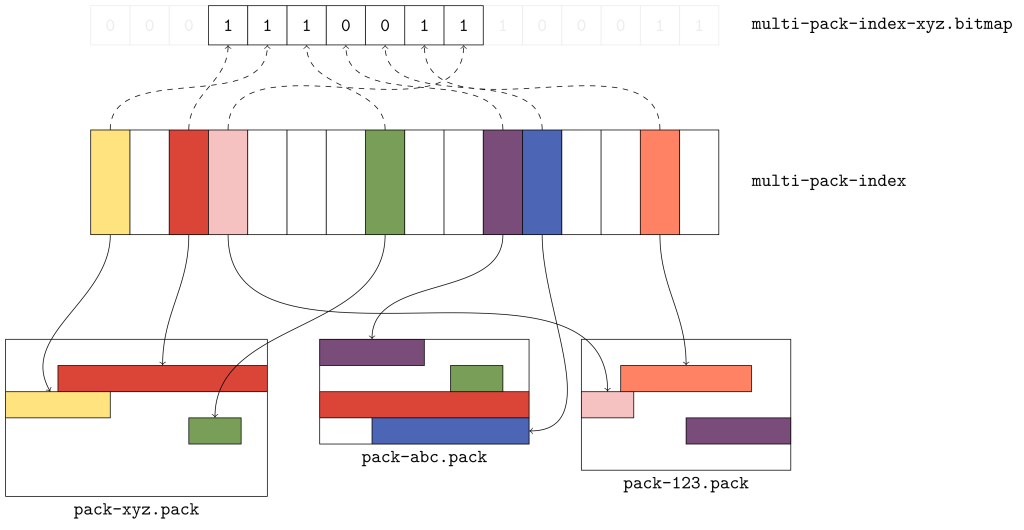
Первые три бита соответствуют красному, жёлтому и зелёному объектам соответственно. Каждый из этих объектов берётся из пакета xyz, и это означает, что пакет xyz имеет самую раннюю дату изменения из всех трёх. При сканировании этого битмапа слева направо данные объекты появляются в том порядке, в котором они упакованы, т. е. байтовое смещение красного объекта меньше байтовых смещений жёлтого и зелёного объектов, которые следуют за ним.
Фиолетовый и голубой объекты идут следом, поскольку они находятся в идущем следом пакете. Но обратите внимание, что копии красного и зелёного объектов в пакете abc не соответствуют никаким выделенным битам. Почему? Потому, что в мультипакетный индекс отобраны копии этих объектов из предыдущего пакета.
Наконец, также появляются оранжевый и розовый объекты, и они тоже отображаются в порядке их появления в пакетах. И, как мы и ожидали, копия фиолетового объекта, отображаемая в пакете 123, не включена в битмап, поскольку это уже сделано для его копии в пакете abc.
Такой вариант упорядочивания обеспечивает великолепную привязку к местоположению, но нам ещё нужно решить, как определять обратное соответствие между битовыми позициями и объектами, которые они представляют. Например, давайте рассмотрим бит в пятой позиции, который, как мы знаем, указывает на голубой объект: каким образом система Git определяет этот факт?
Разумно предположить, что информации о том, сколько объектов находится в каждом из пакетов, должно быть достаточно для выяснения того, какому из объектов соответствует каждый бит в индексе. Но в действительности этой информации недостаточно: мы ведь не знаем, как много уникальных объектов, выбранных в мультипакетный индекс, отображается в каждом из пакетов, а также мы ничего не знаем об отсутствующих в индексе неуникальных объектах. Поэтому не очень практичной выглядит технология, когда нужно вести отсчёт после трёх битов, соответствующих объектам в пакете xyz, а затем отсчитывать ещё два дополнительных бита до пятой позиции, поскольку именно она будет указывать на копию зелёного объекта в пакете abc.
Инвертированные индексы
Чтобы решить эту проблему, мы воспользовались инвертированными индексами. Таким же образом как индекс пакета обеспечивает соответствие между именем объекта и его местоположением, инвертированный индекс выполняет обратное сопоставление местоположения объекта и его имени.
Сама идея чрезвычайно проста: в дополнение к содержимому пакета (хранимому в файле .pack) и индексу (хранимому в файле .idx) записывается массив цифр (который составляет инвертированный индекс и хранится в файле нового формата .rev). Эти цифровые данные обеспечивают преобразование положения объекта в порядке упаковки в его положение в лексикографическом порядке. Чтобы лучше понять это, давайте рассмотрим пример с одним пакетом.
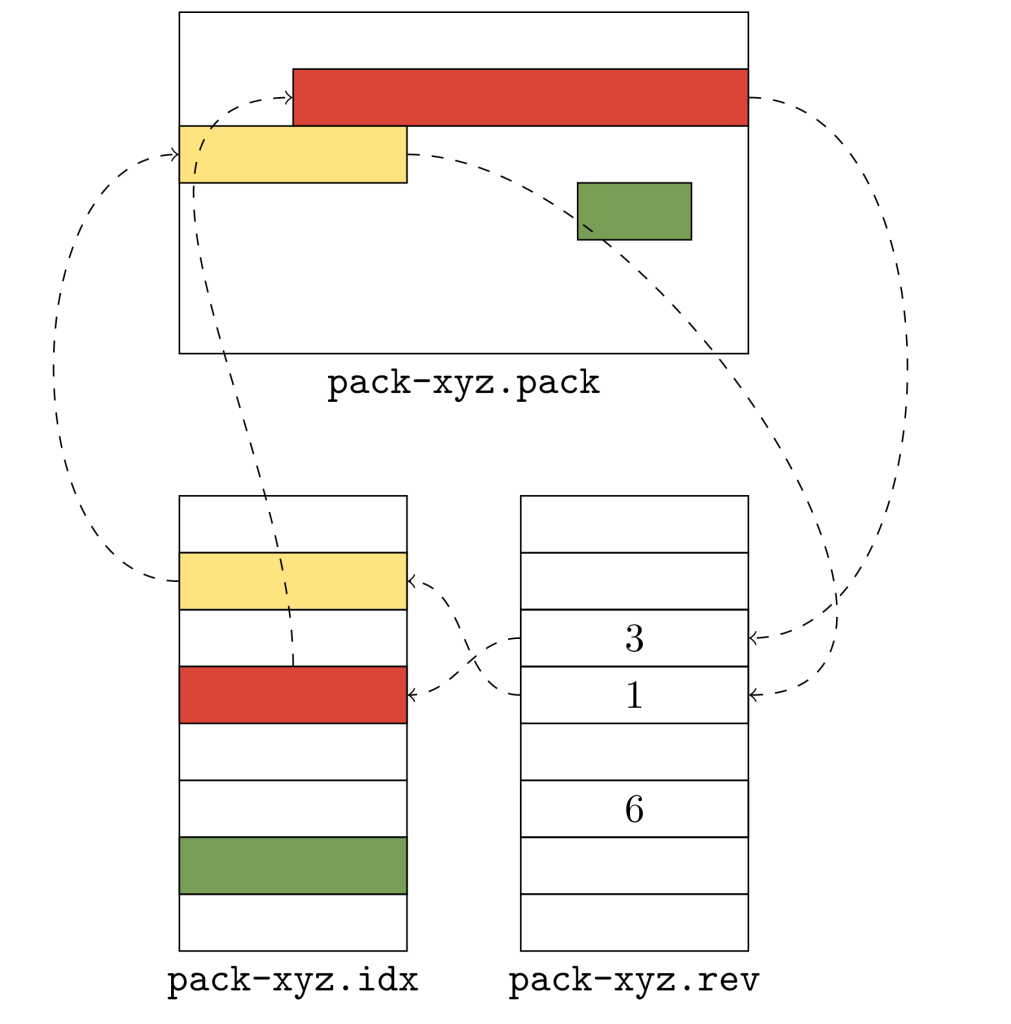
Файл .idx (показан внизу слева) содержит список объектов в лексикографическом порядке: жёлтый объект идет перед красным, а красный — перед зелёным. Но реальный порядок их упаковки другой: именно красный объект идёт раньше жёлтого, а не наоборот. Инвертированный индекс помогает нам разобраться с обоими объектами: он сообщает нам, что красный объект находится в позиции 3 в лексикографическом порядке, а жёлтый объект — в позиции 1.
Инвертированный индекс позволяет нам быстро преобразовывать смещение в файле пакета в позиции соответствующего объекта. Таким образом, появляется возможность быстро определить размер упакованного объекта. Например, предположим, вам требуется выяснить размер красного объекта. Поскольку система Git не хранит эту информацию в явном виде, есть две возможности выяснить её: либо выполнить линейное сканирование данных пакета (разворачивая их содержимое, пока вы не найдёте конец потока) или найти по имени прилегающие объект (в данном случае жёлтый) и измерить разность их смещений.
Без использования инвертированного индекса нет возможности выяснить, откуда начинается прилегающий объект. Но с инвертированным индексом выяснить информацию о красном объекте достаточно просто: нужно лишь прочитать соседнюю запись в инвертированном индексе, чтобы найти требуемое смещение. В нашем примере это значение равно 1, что указывает на запись в файле .idx, которая, в свою очередь, указывает на местоположение в пакете.
Ранее, до того как начать использовать инвертированный индекс на диске, система Git «на лету» производила расчёт соответствующей таблицы и хранила результаты в массиве оперативной памяти. У этого способа была пара серьёзных недостатков. Чтобы построить инвертированный индекс в процессе работы, системе Git требовалось установить пару связанных значений: смещения в пакете и позиции в индексе. Для этого требовалась оперативная память и время на выполнение, потребность в которых увеличивалась пропорционально размерам пакета. Несмотря на то что в этом процессе использовалась поразрядная сортировка, подобная работа с инвертированным индексом заметно медленнее, если она выполняется для каждого процесса.
В ходе нескольких предварительных тестирований таких инвертированных индексов выяснилось, что они могут обеспечивать весьма значительное ускорение при получении изменений из реальных репозиториев. Чтобы проверить наши первоначальные результаты, мы последовательно развернули инвертированные индексы в нескольких репозиториях.
На следующем рисунке показан 50-й процентиль процессорного времени для получения изменений из Homebrew/homebrew-core на нашем тестовом узле до и после этого изменения.

В нашем случае время выполнения всех получений изменений из репозитория сократилось примерно на 80 %. Здесь приведён ещё один график, построенный примерно в то же время, на котором показан размер выделенных процессу и находящихся в данный момент в ОЗУ страниц памяти, которая используется для получения изменений из реплик этого же репозитория.
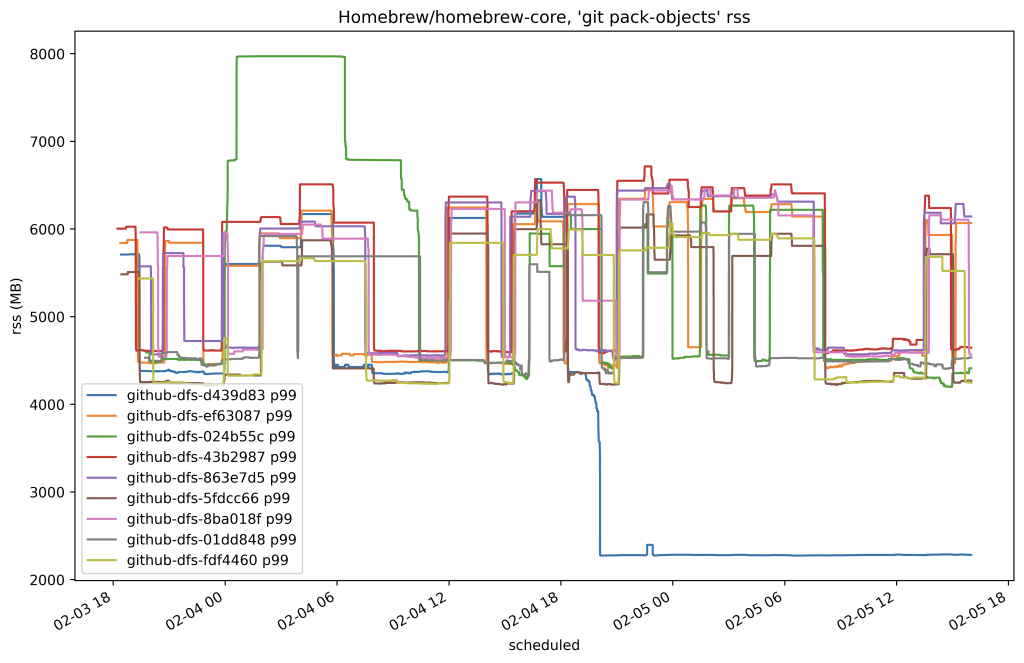
Воодушевлённые нашим первым результатом в промышленной системе, мы продолжили аккуратное развёртывание размещаемых на диске инвертированных индексов для всех других реплик. Как только мы завершили это развертывание, мы выждали пару дней, чтобы дать репликам достаточно времени для построения инвертированных индексов. Затем мы сделали замеры общего процессорного времени, потребляемого на получение изменений по всем репозиториям и увидели именно то снижение нагрузки, на которое рассчитывали.

На приведённом выше графике показаны три суточных цикла. В первый из показанных дней файлы .rev еще не были развёрнуты, а следующие два пика — это два следующих дня. Дневные пики потребления уменьшились примерно с 10,8 до 7 секунд, что совокупно обеспечило экономию в 35 % для всех репозиториев.
Мультипакетные битмапы
Теперь, когда у нас есть формат для файлов .rev, мы можем использовать их как недостающее звено, необходимое при построении мультипакетных битмапов. Вместо того чтобы записывать позиции относительно индексного файла .idx для пакета, мультипакетный инвертированный индекс записывает позиции, которые соотносятся с мультипакетным индексным файлом.
При этом мы получаем именно ту информацию, которая необходима для выяснения соответствия между битовыми позициями и объектами, на которые они ссылаются в мультипакетном индексе. Чтобы понять, почему так происходит, давайте рассмотрим следующий пример.
Чтобы выяснить, что 5-й бит соответствует голубому объекту на вышеприведённом графике, мы считываем пятую запись в мультипакетном инвертированном индексе и получаем информацию, что 5-й бит соответствует 11-му объекту в мультипакетном индексе. И достаточно очевидно, что этот 11-й объект указывает на голубой объект, который мы искали в пакете abc.
Всё вместе это даёт нам битмап, который может ссылаться на объекты в нескольких пакетах. По имени файла каждый битмап может определить, относится ли он к пакету (и если да, то к какому) или к мультипакетному индексу. И, учитывая эту информацию, битовая карта может преобразовывать поисковые запросы для своих объектов, связывая их с файлом пакета или с мультипакетным индексом с помощью инвертированного индекса.
Поскольку мы тщательно подбирали схему упорядочивания, такие мультипакетные битмапы сжимаются так же хорошо, как и битмапы для репозиториев с одним пакетом. Таким образом, использование битмапов больше не привязано к необходимости работы с отдельными пакетами. Поэтому у репозитория может по-прежнему быть всего один битмап, но уже соответствующий нескольким пакетам.
Геометрическая переупаковка
Теперь, когда мы можем включать несколько пакетов в один битмап, каким будет самый оптимальный способ переупаковки этого репозитория при обслуживании?
В битовых картах с одним пакетом единственным вариантом была совместная упаковка всего в один огромный пакет. Но теперь, когда это ограничение снято, необходимо выяснить способ, которым лучше переупаковать эти объекты. Рассуждая о новой стратегии переупаковки, мы хотели соблюсти баланс между двумя следующими свойствами:
обычно в репозитории содержится относительно небольшое число пакетов;
обычно мы создаём пакет, куда попадают объекты, изменения для которых отправлялись с момента последнего запуска обслуживания.
Мы решили соблюсти инвариантность, обеспечив формирование геометрической прогрессии пакетов в репозитории от размера объектов. В частности, если отсортировать пакеты по числу объектов, когда в первом пакете содержится максимальное, а в последнем — их минимальное количество, то в каждом пакете будет содержаться как минимум в два раза больше объектов, чем в последующем.
Мы научили команду git repack выполняться в новом режиме --geometric=, при котором как раз и создавалась такая геометрическая прогрессия. Вскоре (а на момент написания данной статьи эти исправления ещё подавались и проверялись) у вас будет возможность самим проверить это на собственном репозитории, выполнив следующий код:
$ packsizes() {
find .git/objects/pack -type f -name '*.pack' |
while read pack; do
printf "%7d %s\n" "$(git show-index < ${pack%.pack}.idx | wc -l)" "$pack"
done | sort -rn
}
$ packsizes # before
$ git repack --write-midx --write-bitmap-index -d --geometric=2
$ packsizes # afterКак работает эта команда? Мы отобрали набор пакетов и объединили их объекты в один новый пакет, заменивший собой этот набор. Но подобрать такой набор оптимально весьма сложно с точки зрения недетерминированного полиномиального времени, поэтому мы должны аппроксимировать его.
Чтобы увидеть, как выполняется такая аппроксимация, давайте рассмотрим пример. Первым шагом мы выясняем, как много пакетов уже формируют геометрическую прогрессию. Для этого представьте, что пакеты упорядочены по числу содержащихся в них объектов. Затем рассмотрите каждую пару прилегающих пакетов от самых крупных, до самых маленьких. В каждом из случаев проверяйте, является ли больший по размерам пакет хотя бы в два раза больше, чем меньший? Если да, то каждый из пакетов этой пары уже образует геометрическую прогрессию.

В рассматриваемом примере второй и третий пакеты (каждый содержит по одному объекту) нарушают прогрессию. В этот момент мы знаем, что второй пакет и все предыдущие пакеты должны быть переупакованы вместе, чтобы восстановить прогрессию.
Но мы не можем просто взять и переупаковать первые два пакета вместе, поскольку объединённый пакет всё ещё будет слишком большим (ведь он будет содержать два объекта, а третий — только один). Поэтому мы увеличивали набор пакетов для объединения до тех пор, пока инвариантность не восстановилась:
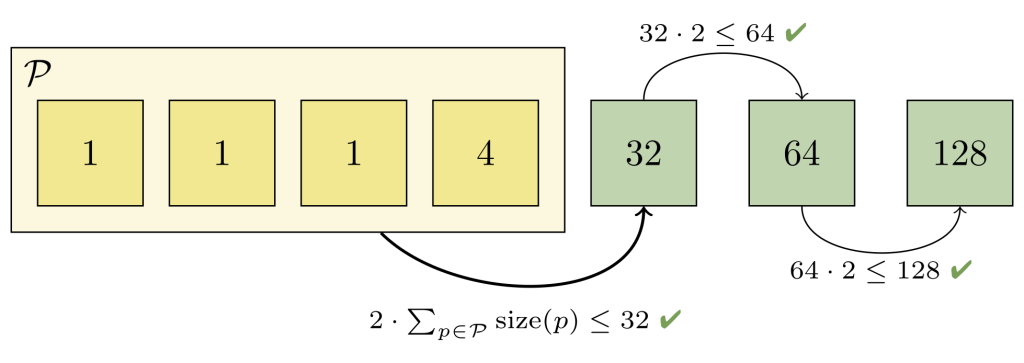
Здесь нам пришлось объединить первые четыре пакета, чтобы восстановить геометрическую прогрессию. Совместно в этих пакетах 7 объектов, и это меньше чем вдвое, чем в следующем по размеру пакете (в котором содержится 32 объекта). И мы не сможем объединить большее число пакетов, поскольку выполнение этого нарушит оставшуюся часть прогрессии.
В этот момент мы можем записать новый пакет, содержащий только объекты из набора пакетов, которые мы объединили в предыдущем шаге. После удаления лишних пакетов оставшиеся снова образуют геометрическую прогрессию:
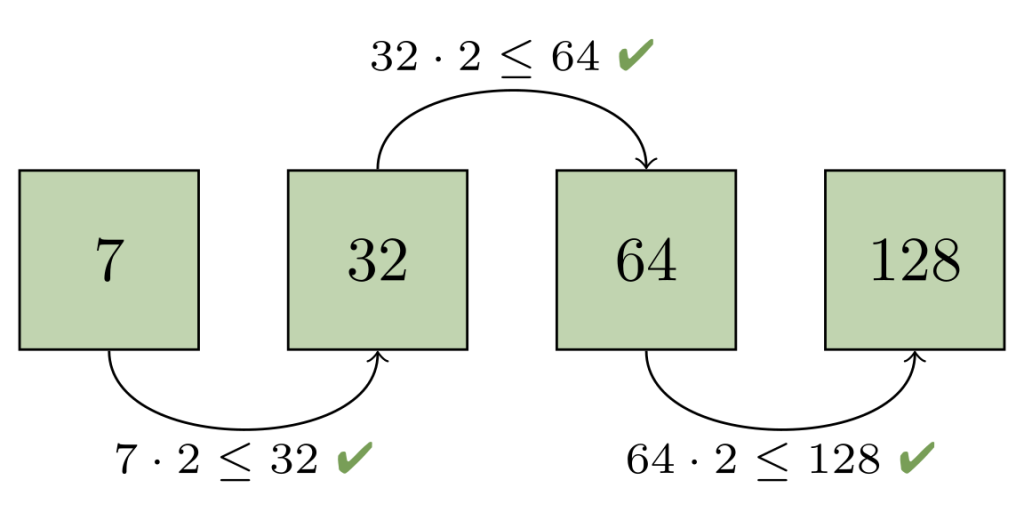
Это означает, что число пакетов растёт логарифмически с течением времени, поэтому в репозитории никогда не будет слишком большого числа пакетов. У этого метода также есть ещё одно привлекательное свойство: обычно для старых объектов изменения отправляются в более крупные пакеты, а это значит, что они реже переупаковываются с течением времени. Важным следствием этого является то, что каждая операция переупаковки имеет тенденцию сосредотачиваться на объектах с последними отправленными изменениями. Другими словами, эта стратегия нацелена на то, чтобы переупаковка занимала время, пропорциональное числу новых объектов, а не совокупному числу объектов в пакете.
Чтобы обеспечить хорошую работу репозитория после множества геометрических переупаковок, мы практикуем одну переупаковку «всего в один пакет» через каждые 8 геометрических переупаковок.
И что немаловажно, это означает, что, хотя классические операции переупаковки всё ещё выполняются медленно, нам не нужно запускать их каждый раз, когда требуется переупаковать репозиторий.
Развёртывание в производственной среде
Теперь, когда у нас есть способ записывать битмапы, охватывающие все объекты в мультипакетном репозитории, есть метод, позволяющий быстро установить связь между битовой позицией и объектами, на которые она ссылается в мультипакетном индексе, а также стратегия переупаковки, предполагающая изменения только для последних добавлений к репозиторию, мы готовы к тому, чтобы соединить все эти технологии вместе.
Прежде чем выполнять развертывание таких масштабных изменений, как это, мы провели локальное тестирование, убедившись, что записывание битмапов работает правильно, а наша новая стратегия переупаковки не приводит к скрытым повреждениям репозиториев. Но это всё, что мы могли протестировать локально: при получении изменений и выполнении операций клонирования количество возможных тупиковых ситуаций и проблем в принципе не ограничено, поэтому настоящие испытания возможны только после обкатки этих новых технологий с реальным трафиком, под реальной рабочей нагрузкой. Наша задача состояла в том, чтобы спроектировать такую стратегию развёртывания, при которой, с одной стороны, бы рассматривалось достаточно много различных ситуаций, а с другой — была бы гарантия, что любые потенциальные повреждения никогда не смогут вывести из строя большую часть реплик репозиториев.
Нашими первыми демонстрационными примерами были внутренние репозитории системы. Мы разделили наши исходные тесты на две фазы. В первой фазе мы создавали «мультипакетные битмапы», в действительности содержавшие только один пакет. Это позволило нам изучить наиболее простой случай использования мультипакетных битмапов (с одним пакетом), не выполняя нашего нового кода переупаковки. Убедившись в надёжности работы этого метода, мы расширили тестирование, чередуя операции геометрической и полной переупаковок.
После того как в течение двух недель никаких проблем не возникало, у нас появилась уверенность в наших изменениях, позволившая нам начать тестирование новых технологий с другими, внешними, репозиториями GitHub. Сначала мы выбрали первый отдельный узел, а затем целую стойку узлов, на которых стали чередоваться операции геометрических и полных переупаковок. Результаты на этом этапе были очень обнадёживающими: среднее время на переупаковку значительно сократилось, так же как и общее время, затрачиваемое системой на операции переупаковки.
Этот этап продолжался несколько недель и только в одном из трёх наших центров обработки данных. Поскольку мы никогда не помещаем большинство реплик репозиториев в какой-либо один центр обработки данных, такая конфигурация защищала большую часть копий репозиториев от возможных необратимых повреждений в результате наших изменений, но в то же время они (эти изменения) были задействованы для большого объёма трафика, т. е. оказались под реальной нагрузкой.
Поработав с такой конфигурацией в течение недели, мы стали применять мультипакетные битмапы к репликам репозиториев, размещённых в других центрах обработки данных, пока, наконец, во всех репозиториях не начала использоваться новая технология мультипакетных битмапов достижимости.

После того как мы развернули нашу новую стратегию переупаковки с мультипакетными битмапами, полученная в среднем экономия составила 5,67 процессорных дней за каждый час по сравнению со старой стратегией.
Сходным образом значительно сократилось среднее время на выполнение переупаковки всех отдельных репозиториев. Ниже на графике показана разбивка по сайтам, и можно увидеть, когда мы начали тестирование на отдельных сайтах, а также тот момент, когда мы охватили развёртыванием все сайты.
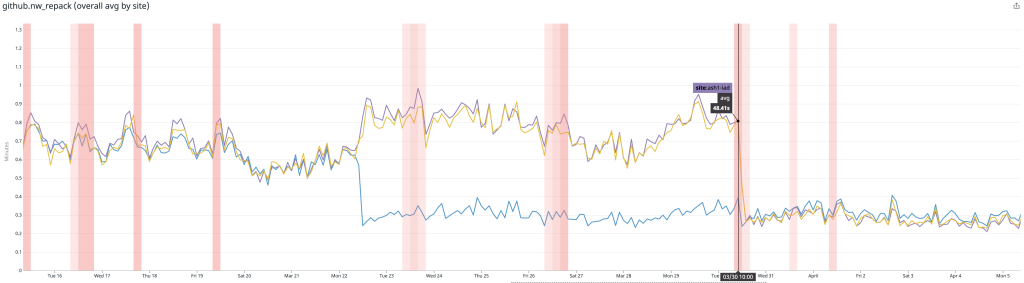
Здесь видно, что среднее время выполнения переупаковки репозитория сократилось с 1 минуты
.
Направления будущего развития
Думая о дальнейших улучшениях производительности, мы рассматриваем две основные области, где есть возможность такой оптимизации.
Одной из таких областей оптимизации является сама процедура вычисления битмапов. Код, создающий битмапы в системе Git, может повторно использовать существующие битмапы, переупорядочивая их биты, но эта операция может занимать время, которое пропорционально размеру репозитория. Одним из способов решения этой проблемы могла бы стать инкрементальная запись битмапов, при которой выполнялся бы обход только новых объектов, добавленных после выполнения последней записи битмапа. Но проблема эта в действительности очень непростая, поскольку не только требуется возможность инкрементальной записи файла битмапа, но и необходима стабильность порядка объектов, т. е. добавление новых битмапов не должно делать существующие бессмысленными.
Другой областью оптимизации является структура пакета. Создание пакетов, образующих геометрическую прогрессию, является многообещающим шагом вперёд, позволяющим находить разумное равновесие между выполнением полных и частичных переупаковок. Но некоторые репозитории настолько огромны, что переупаковка всего репозитория практически невозможна, а значит, её вообще лучше бы не затевать. Разработка стратегии, которая позволит «заморозить» пакеты, содержащие старые версии объектов для какого-то момента в истории репозитория, даст нам возможность роста и работы с ещё большими репозиториями в будущем.
Высокая производительность программного обеспечения и его тонкие оптимизации по-прежнему стоят во главе угла по-настоящему больших и сложных проектов, и если вы хотите погрузиться в разработку до уровня железа, писать современные и эффективные программы, то вы можете обратить внимание на курс о разработке на С++, который используется везде: от приложений и сложных банковских продуктов до программирования роботов и нейронных сетей.

Узнайте, как прокачаться и в других специальностях или освоить их с нуля:
Другие профессии и курсы
ПРОФЕССИИ
КУРСЫ