
Привет! Меня зовут Александра Елисеева, я студентка Computer Science Center. В рамках практики в осеннем семестре 2020 года я участвовала в проекте BERT for Source Code под руководством Тимофея Брыксина и Ярослава Соколова из JetBrains Research. Я исследовала решение задачи автоматической генерации сообщений к коммитам с помощью языковой модели BERT. Что получилось, а над чем еще предстоит поработать, расскажу в этом посте.

В области обработки языков программирования есть много интересных задач, автоматическое решение которых может пригодиться для создания удобных инструментов для разработчиков.
Исходный код программ во многом отличается от текстов на естественном языке, но его тоже можно воспринимать как последовательность токенов и использовать аналогичные методы. Например, в области обработки естественного языка активно применяется языковая модель BERT. Процесс её обучения предполагает две стадии: предобучение на большом наборе неразмеченных данных и дообучение под конкретные задачи на более маленьких размеченных датасетах. Такой подход позволяет многие задачи решать с очень хорошим качеством.
Недавние работы (1, 2, 3) показали, что если обучить модель BERT на большом датасете программного кода, то она и в этой области неплохо справляется с несколькими задачами (среди них, например, локализация и устранение неправильно использованных переменных и генерация комментариев к методам).
Проект направлен на исследование применения BERT для других задач, связанных с исходным кодом. В частности, мы сосредоточились на задаче автоматической генерации сообщений к коммитам.
Почему мы выбрали эту задачу?
Во-первых, системы контроля версий используются при разработке многих проектов, поэтому инструмент для автоматического решения этой задачи может быть актуален для широкого круга разработчиков.
Во-вторых, мы предположили, что применение BERT для этой задачи может привести к хорошим результатам. Это обусловлено несколькими причинами:
За семестр мне нужно было сделать следующее:
Существует несколько открытых датасетов для этой задачи, я выбрала наиболее отфильтрованный из них (5).
Датасет собирался из топ-1000 открытых GitHub репозиториев на языке Java. После фильтрации из исходных миллионов примеров осталось около 30 тысяч.
Сами примеры представляют собой пары из вывода команды git diff и соответствующего короткого сообщения на английском языке. Выглядит это как-то так:
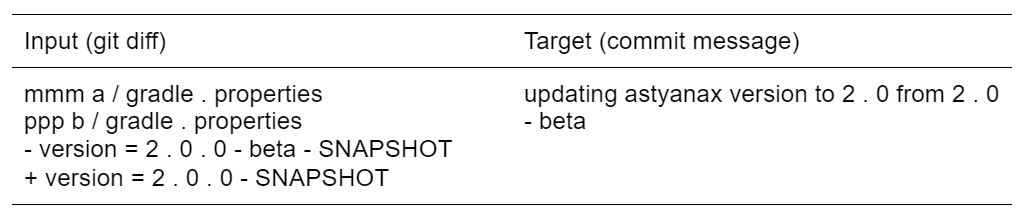
И изменения, и сообщения в датасете короткие — не более 100 и 30 токенов соответственно.
В большинстве существующих работ, исследующих задачу автоматической генерации сообщений к коммитам, на вход моделям подается последовательность токенов из git diff.
Встречается и другая идея: явно выделить две последовательности, до изменений и после, и выровнять их с помощью классического алгоритма для подсчета редакционного расстояния. Таким образом измененные токены всегда находятся на одинаковых позициях.
В идеале нам хотелось попробовать несколько подходов и понять, насколько они влияют на качество решения этой задачи. На начальном этапе я использовала достаточно простой: на вход модели подавались две последовательности, до изменений и после, но без какого-либо выравнивания.
И входные, и выходные данные для задачи автоматической генерации сообщений к коммитам представляют собой последовательности, длина которых может отличаться.
Для решения подобных задач обычно используют архитектуру энкодер-декодер, состоящую из двух компонент:
Модель BERT основана на энкодере из архитектуры Transformer и сама по себе для такой задачи не подходит. Возможно несколько вариантов, чтобы получить полноценную sequence-to-sequence модель, самый простой -— использовать с ней какой-либо декодер. Такой подход с декодером из архитектуры Transformer хорошо себя показал, например, для задачи нейронного машинного перевода (7).
Для проведения экспериментов необходим был код для обучения и оценки качества подобной sequence-to-sequence модели.
Для работы с моделью BERT я использовала библиотеку HuggingFace’s Transformers, а для реализации в целом — фреймворк PyTorch.
Так как в начале у меня было мало опыта с PyTorch, я во многом опиралась на существующие примеры для sequence-to-sequence моделей других архитектур, постепенно адаптируя под специфику моей задачи. С таким подходом, к сожалению, получилось большое количество кода плохого качества.
В какой-то момент было решено заняться рефакторингом, практически переписав пайплайн. Структурировать код помогла библиотека PyTorch Lightning, позволяющая собрать всю основную логику модели в одном модуле и во многом автоматизировать её.
В ходе экспериментов нам хотелось понять, позволяет ли использование предобученной на программном коде модели BERT улучшить state-of-the-art результат в этой области.
Среди обученных на коде моделей BERT нам подошла только CodeBERT (1), так как только у неё в примерах для обучения присутствовал язык программирования Java. Сначала, используя CodeBERT в качестве энкодера, я попробовала декодеры разных архитектур:
На дальнейшие эксперименты времени в осеннем семестре не хватило, я продолжила их уже зимой. Мы рассмотрели несколько других способов представления входных данных: попробовали выравнивать последовательности до изменений и после, а еще просто подавать git diff.
Основные результаты экспериментов выглядят следующим образом:


В целом предположение о пользе применения CodeBERT к данной задаче не подтвердилось, во всех случаях обучаемая с нуля модель Transformer показала качество выше. Лучшим методом в этой области остаётся модель CoreGen6: это тоже Transformer, но дополнительно предобученный с использованием предложенной авторами целевой функции.
Для решения этой задачи можно рассмотреть еще много идей: например, попробовать представление данных на основе абстрактных синтаксических деревьев, которое часто применяется при работе с программным кодом (10, 11), попробовать другие предобученные модели или провести какое-нибудь специфичное для этой области предобучение, если есть необходимые ресурсы. Мы же в весеннем семестре сосредоточились на более практическом применении полученных результатов и занимались автодополнением сообщений к коммитам. Об этом расскажу во второй части :)
В заключение хочу сказать, что участвовать в проекте было действительно интересно, я погрузилась в новую для себя предметную область и многому научилась за это время. Работа над проектом была очень здорово организована, за что большое спасибо моим руководителям.
Спасибо за внимание!
О проекте
В области обработки языков программирования есть много интересных задач, автоматическое решение которых может пригодиться для создания удобных инструментов для разработчиков.
Исходный код программ во многом отличается от текстов на естественном языке, но его тоже можно воспринимать как последовательность токенов и использовать аналогичные методы. Например, в области обработки естественного языка активно применяется языковая модель BERT. Процесс её обучения предполагает две стадии: предобучение на большом наборе неразмеченных данных и дообучение под конкретные задачи на более маленьких размеченных датасетах. Такой подход позволяет многие задачи решать с очень хорошим качеством.
Недавние работы (1, 2, 3) показали, что если обучить модель BERT на большом датасете программного кода, то она и в этой области неплохо справляется с несколькими задачами (среди них, например, локализация и устранение неправильно использованных переменных и генерация комментариев к методам).
Проект направлен на исследование применения BERT для других задач, связанных с исходным кодом. В частности, мы сосредоточились на задаче автоматической генерации сообщений к коммитам.
О задаче
Почему мы выбрали эту задачу?
Во-первых, системы контроля версий используются при разработке многих проектов, поэтому инструмент для автоматического решения этой задачи может быть актуален для широкого круга разработчиков.
Во-вторых, мы предположили, что применение BERT для этой задачи может привести к хорошим результатам. Это обусловлено несколькими причинами:
- в существующих работах (4, 5, 6) данные собираются из открытых источников и требуют серьёзной фильтрации, поэтому примеров для обучения остаётся немного. Здесь может пригодиться способность BERT дообучаться на небольших датасетах;
- state-of-the-art результат на момент работы над проектом был у модели архитектуры Transformer, которая достаточно специфичным способом предобучена на небольшом датасете (6). Нам интересно было сравнить его с моделью на основе BERT, которая предобучена по-другому, но на гораздо большем количестве данных.
За семестр мне нужно было сделать следующее:
- изучить предметную область;
- найти датасет и выбрать представление входных данных;
- разработать пайплайн для обучения и оценки качества;
- провести эксперименты.
Данные
Существует несколько открытых датасетов для этой задачи, я выбрала наиболее отфильтрованный из них (5).
Датасет собирался из топ-1000 открытых GitHub репозиториев на языке Java. После фильтрации из исходных миллионов примеров осталось около 30 тысяч.
Сами примеры представляют собой пары из вывода команды git diff и соответствующего короткого сообщения на английском языке. Выглядит это как-то так:
И изменения, и сообщения в датасете короткие — не более 100 и 30 токенов соответственно.
В большинстве существующих работ, исследующих задачу автоматической генерации сообщений к коммитам, на вход моделям подается последовательность токенов из git diff.
Встречается и другая идея: явно выделить две последовательности, до изменений и после, и выровнять их с помощью классического алгоритма для подсчета редакционного расстояния. Таким образом измененные токены всегда находятся на одинаковых позициях.
В идеале нам хотелось попробовать несколько подходов и понять, насколько они влияют на качество решения этой задачи. На начальном этапе я использовала достаточно простой: на вход модели подавались две последовательности, до изменений и после, но без какого-либо выравнивания.
BERT для sequence-to-sequence задач
И входные, и выходные данные для задачи автоматической генерации сообщений к коммитам представляют собой последовательности, длина которых может отличаться.
Для решения подобных задач обычно используют архитектуру энкодер-декодер, состоящую из двух компонент:
- модель-энкодер на основе входной последовательности строит векторное представление,
- модель-декодер на основе векторного представления генерирует выходную последовательность.
Модель BERT основана на энкодере из архитектуры Transformer и сама по себе для такой задачи не подходит. Возможно несколько вариантов, чтобы получить полноценную sequence-to-sequence модель, самый простой -— использовать с ней какой-либо декодер. Такой подход с декодером из архитектуры Transformer хорошо себя показал, например, для задачи нейронного машинного перевода (7).
Пайплайн
Для проведения экспериментов необходим был код для обучения и оценки качества подобной sequence-to-sequence модели.
Для работы с моделью BERT я использовала библиотеку HuggingFace’s Transformers, а для реализации в целом — фреймворк PyTorch.
Так как в начале у меня было мало опыта с PyTorch, я во многом опиралась на существующие примеры для sequence-to-sequence моделей других архитектур, постепенно адаптируя под специфику моей задачи. С таким подходом, к сожалению, получилось большое количество кода плохого качества.
В какой-то момент было решено заняться рефакторингом, практически переписав пайплайн. Структурировать код помогла библиотека PyTorch Lightning, позволяющая собрать всю основную логику модели в одном модуле и во многом автоматизировать её.
Эксперименты
В ходе экспериментов нам хотелось понять, позволяет ли использование предобученной на программном коде модели BERT улучшить state-of-the-art результат в этой области.
Среди обученных на коде моделей BERT нам подошла только CodeBERT (1), так как только у неё в примерах для обучения присутствовал язык программирования Java. Сначала, используя CodeBERT в качестве энкодера, я попробовала декодеры разных архитектур:
- Рекуррентная нейронная сеть GRU.
Я предполагала, что с этим вариантом удастся быстро получить какой-нибудь базовый результат. GRU не так часто используют с архитектурой Transformer, поэтому было не до конца понятно, чего ожидать.
В итоге какого-либо разумного качества получить не удалось даже после подбора нескольких влияющих на процесс обучения гиперпараметров. - Декодер из архитектуры Transformer.
Можно как обучать декодер полностью с нуля, так и инициализировать почти все его слои весами предобученной модели — для некоторых задач таким образом можно добиться более высокого качества.
Я попробовала второй вариант, используя для этого предобученную на английском языке GPT-2 (8) — модель на основе декодера из архитектуры Transformer, часто применяемую для задач генерации, а также её более маленькую версию — distilGPT-2 (9).
На дальнейшие эксперименты времени в осеннем семестре не хватило, я продолжила их уже зимой. Мы рассмотрели несколько других способов представления входных данных: попробовали выравнивать последовательности до изменений и после, а еще просто подавать git diff.
Основные результаты экспериментов выглядят следующим образом:
Подводя итоги
В целом предположение о пользе применения CodeBERT к данной задаче не подтвердилось, во всех случаях обучаемая с нуля модель Transformer показала качество выше. Лучшим методом в этой области остаётся модель CoreGen6: это тоже Transformer, но дополнительно предобученный с использованием предложенной авторами целевой функции.
Для решения этой задачи можно рассмотреть еще много идей: например, попробовать представление данных на основе абстрактных синтаксических деревьев, которое часто применяется при работе с программным кодом (10, 11), попробовать другие предобученные модели или провести какое-нибудь специфичное для этой области предобучение, если есть необходимые ресурсы. Мы же в весеннем семестре сосредоточились на более практическом применении полученных результатов и занимались автодополнением сообщений к коммитам. Об этом расскажу во второй части :)
В заключение хочу сказать, что участвовать в проекте было действительно интересно, я погрузилась в новую для себя предметную область и многому научилась за это время. Работа над проектом была очень здорово организована, за что большое спасибо моим руководителям.
Спасибо за внимание!
Источники
- Feng, Zhangyin, et al. «Codebert: A pre-trained model for programming and natural languages.» 2020
- Buratti, Luca, et al. «Exploring Software Naturalness through Neural Language Models.» 2020
- Kanade, Aditya, et al. «Learning and Evaluating Contextual Embedding of Source Code.» 2020
- Jiang, Siyuan, Ameer Armaly, and Collin McMillan. «Automatically generating commit messages from diffs using neural machine translation.» 2017
- Liu, Zhongxin, et al. «Neural-machine-translation-based commit message generation: how far are we?.» 2018
- Nie, Lun Yiu, et al. «CoreGen: Contextualized Code Representation Learning for Commit Message Generation.» 2021
- Rothe, Sascha, Shashi Narayan, and Aliaksei Severyn. «Leveraging pre-trained checkpoints for sequence generation tasks.» 2020
- Radford, Alec, et al. «Language models are unsupervised multitask learners.» 2019
- Sanh, Victor, et al. «DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.» 2019
- Yin, Pengcheng, et al. «Learning to represent edits.» 2018
- Kim, Seohyun, et al. «Code prediction by feeding trees to transformers.» 2021


ShashkovS
А можно примеры автоматически сгенерированных комментариев? По BLEU не особо-то оценишь, получилось ли что-то осмысленное. Комменты к коммитам — только в мире розовых пони — лучший образец «перевода» изменений на человеческий язык.
saridormi
Согласна, примеров в посте не хватает. Можно посмотреть примеры лучшей из наших моделей для всей тестовой выборки в табличке в проекте Weights & Biases. Хотела привести конкретные хорошие и плохие примеры, но тут может быть немного субъективно :) В целом качества недостаточно, чтобы использовать такой метод на практике для генерации полноценных сообщений.
Извиняюсь за долгий ответ!