

Зачем всё это?
Все больше растет популярность голосовых интерфейсов. Многие технологические компании-гиганты стремятся сделать своего голосового помощника. Но речевые технологии доступны и обычным пользователям. Каждый может использовать их в своих проектах и делать голосовые интерфейсы еще удобнее и популярнее .
Голосовой дневник - лишь один из примеров того, как можно встроить функции голосового интерфейса в повседневные действия.
Постановка задачи
У голосового дневника есть 4 основные задачи:
распознать входящее аудиосообщение
сохранить данные в базу
вернуть или удалить данные из базы
иметь удобный интерфейс взаимодействия

Будем использовать mongo db для сохранения нашего очень важного текста, docker для разворачивания базы данных, telegram в качестве интерфейса и голосовую модель vosk для распознавания голоса.
Разберемся подробнее с составными частями нашего дневника.
Голосовой движок
Для распознавания голоса нужна языковая модель (online или offline), которая будет за разумное время переводить аудио в текст. Среди прочих существующих моделей мне понравился open source проект vosk. Он работает offline и достаточно точно распознает голосовые сообщения. К тому же, в нем для русского языка есть как очень легкие (43 mb) так и очень тяжелые (2.5 gb) модели, а выбор - это всегда хорошо. Полный список доступных моделей можно найти на официальном сайте. Помимо русского, там есть украинский, английский, немецкий и многие другие.
Ниже представлен код, использующий русскоязычную модель распознавания речи. Из особенностей: на вход должен подаваться файл формата wav.
import wave
import json
import vosk
from vosk import KaldiRecognizer
def recognize_phrase(model: vosk.Model, phrase_wav_path: str) -> str:
"""
Recognize Russian voice in wav
"""
wave_audio_file = wave.open(phrase_wav_path, "rb")
offline_recognizer = KaldiRecognizer(model, 24000)
data = wave_audio_file.readframes(wave_audio_file.getnframes())
offline_recognizer.AcceptWaveform(data)
recognized_data = json.loads(offline_recognizer.Result())["text"]
return recognized_dataХотя offline модели распознавания не такие точные, как их online аналоги, все-таки независимость от интернет-соединения развязывает руки во многих проектах.
Из минусов распознавания:
Не может распознать слова на другом языке
Плохо распознает заимствованные и терминологические слова
База данных
Для хранения текстовых данных будем использовать mongo db. Среди явных преимуществ такого решения следующее:
Удобное хранение объемных текстовых данных
Легкость расширения хранимых полей
Простота обращения с индексом
Полный код команд добавления, удаления и поиска по базе mongo db можно найти в репозитории проекта, здесь же, для примера, разберем функцию добавления наших текстовых данных.
import datetime
from pymongo.errors import DuplicateKeyError
from pymongo.collection import Collection
def add_value(database: Collection, value: str):
"""
Добавить одну запись в базу данных
"""
database_index = int(datetime.datetime.now().timestamp())
try:
database.insert_one({'_id': database_index, 'text': value})
return True
except DuplicateKeyError:
return False
Индексом для хранилища выбран timestamp по нескольким причинам:
Быстрый поиск / удаление для интервалов дат (одна из функций дневника)
Наличие всего одного юзера (не будет проблем с дублированием индекса)
Не нужно заморачиваться и выдумывать что-то сложнее
FFmpeg
FFmpeg — набор свободных библиотек с открытым исходным кодом, которые позволяют записывать, конвертировать и передавать цифровые аудио- и видеозаписи в различных форматах.
Зачем нам ffmpeg ? Формат файла, в котором сохраняются аудио-сообщения из telegram - это ogg. Но vosk работает с форматом wav. Поэтому будем использовать ffmpeg для трансформации ogg в wav.
Многие существующие библиотеки обработки аудио на python требуют наличие установленного ffmpeg. Но если у нас установлен ffmpeg, зачем использовать библиотеку, если можно использовать встроенные команды?
# команда для конвертации ogg в wav
ffmpeg -i ./my_phrase.ogg
-ar 16000 -ac 2 -ab 192K -f wav ./my_phrase_to_translite.wavразбор параметров команды
-i ./my_phrase.ogg - текущий источник данных (исходная фраза для конвертации)
-ar 16000- частота дискретизации звука конечного файла. (Гц)-ac 2 -количество аудиоканалов-ab 192K -битрейт-f wav -формат конечного файла
Docker
Нужен для того, чтобы запустить внутри контейнера базу данных. В перспективе приложение с интерфейсом бота так же будет разворачиваться внутри отдельного контейнера.
Сам скрипт запуска достаточно простой, но есть один важный момент: нам не нужно разворачивать базу данных, если ее контейнер уже существует. Мы же не хотим однажды потерять все наши накопленные записи. Делается это очень просто: поиском имени запускаемого контейнера в пространстве имен уже запущенных ранее.
Команда для проверки:
if docker inspect --format '{{json .State.Running}}' mongo_database
then
echo "container is already running"
exit
fiTelegram bot API
В качестве интерфейса дневника будем использовать всеми любимый telegram, а именно бота по API ключу. Преимущества такого решения следующие:
Удобное API
Реализованная функция отправки голосового сообщения
Работа дневника в интерфейсном режиме чата
Пример работы

Далее идем в базу данных за нашими сообщениями, но уже в формате текста.
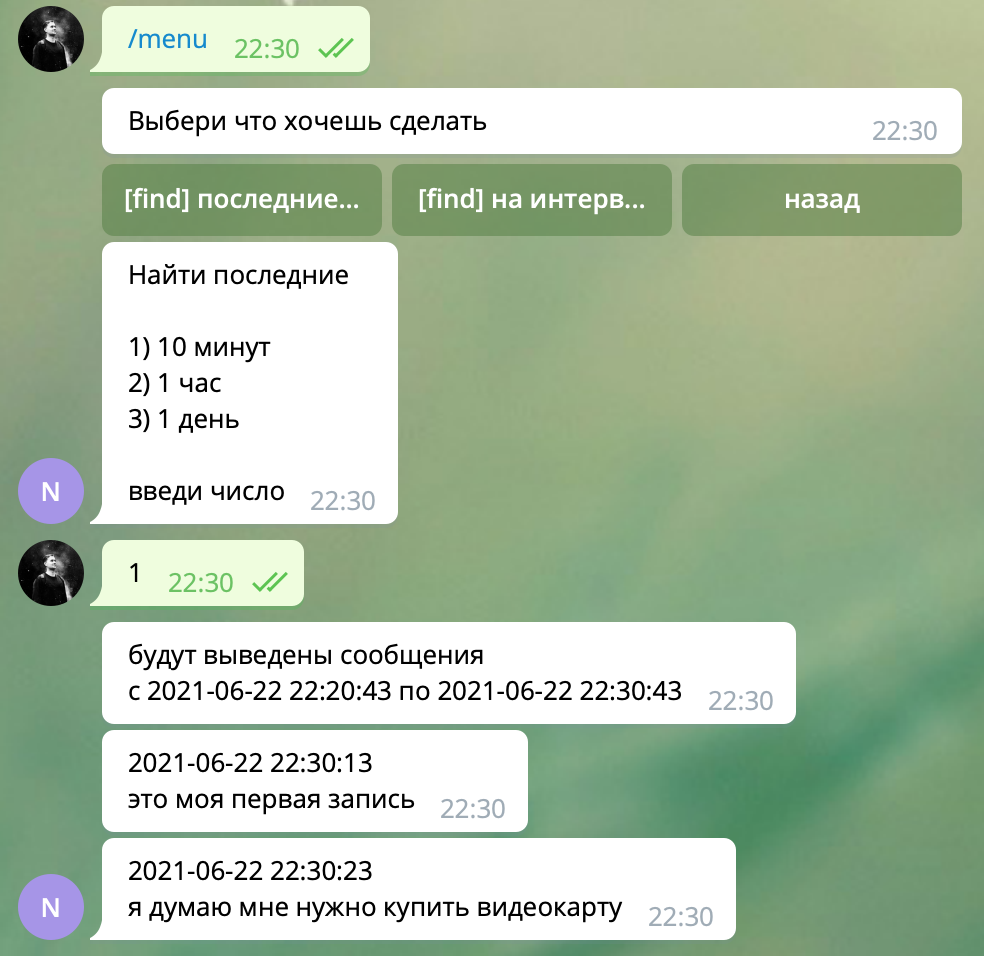
Как видим, текст распознался корректно и пользователю вернулись все записи, которые он сделал за последние 10 минут.
А что дальше?
Своим проектом я хотел показать простоту использования базовых голосовых функций в 2021 году. При желании можно прикрутить эвристическое / machine learning распознавание фраз или ключевых слов и сделать на основе этого проекта голосовое управление какой-нибудь системой.
Весь код проекта можно найти здесь: проект на GitHub



stepuncius
Не совсем понял, зачем явно проверять работу контейнера?
Чтобы не потерять данные - достаточно подмонтировать volume, в котором mongo хранит свои данные.
Если у контейнера фиксирован порт - тогда первый запущенный экземпляр сразу процент экземпляр данные, если они уже есть, а второй - всё равно не запустится, т.к. порт будет занят.
Да и вообще mongo для хранения "ключ:строка" - какой-то оверкилл, хватит и SQLite.
Также не раскрыта тема бекапов...
MaximML Автор
docker — не моя сильная сторона… не отрицаю, что есть способы сделать деплой оптимальнее. Про бэкапы — интересный вопрос, возможно, я копну глубже в эту сторону в следующих публикациях :)