
Введение
Русский язык велик и могуч, и компьютерные лингвисты уже много лет пытаются алгоритмизировать это богатство. Ещё в 1970-х Мельчук предложил концепцию "Смысл-текст", где ультимативная языковая модель способна превратить любой текст в его смысловое представление, и наоборот, получить из этого представления все возможные тексты, обладающие таким смыслом. 50 лет спустя мы не только не создали подобную модель, но даже не очень хорошо умеем просто автоматически перефразировать тексты. Впрочем, последнюю задачу решить мы пытаемся. В 2015 году Екатерина Проноза собрала корпус парафраз из новостных заголовков, на основе которого два года спустя была организована дорожка по детекции парафраз. В 2020 году появился аналогичный огромный корпус парафраз-заголовков и был предложен парафразер, основанный на заменах и перестановках слов. Совсем недавно Тамара Жордания из НИУ ВШЭ собрала несколько корпусов и моделей c парафразами в своей дипломной работе, а Алёна Феногенова из Сбера опубликовала статью про обучение нейросетей GPT и T5 для перефразирования русских предложений и выложила результаты в открытый доступ.
Я, собственно, предлагаю некоторое расширение Алёниной работы: новый (и более качественный) русский корпус парафраз, новую модель для перефразирования на основе нейросети T5, и новый набор автоматических метрик для оценки качества корпуса и модели. Модель можно использовать для рерайтинга текстов, для аугментации текстовых данных, для переноса стилей текстов (при разумном контроле на стиль), и как затравку для обучения новых text-to-text моделей.

Целевые показатели
Перефразировать - значит, переписать текст так, чтобы новый текст отличался от старого по написанию, но был похож по смыслу. А ещё новый текст должен выглядеть естественно.
Разницу в написании можно измерять по количеству совпадающих подстрок. Например, так устроена метрика BLEU - доля словных n-грамм, совпавших с оригиналом. BLEU - метрика несимметричная, так что я буду вычислять её в обоих направлениях и усреднять. Кроме BLEU, я использую коэффициент Жакара для символьных n-грамм (n от 3 до 6), чтобы учесть слова в переписанном тексте, которые частично совпадают со словами из исходного. Обе эти метрики я буду иногда называть текстовой или поверхностной близостью.
Сходство по смыслу измерить сложнее. К счастью, есть несколько моделей, специально обученных переводить текст в вектор так, чтобы векторы текстов, близких по смыслу, были геометрически близки друг к другу. Одна из таких моделей - LaBSE, которую обучали приближать друг к другу эмбеддинги текстов с одинаковыми смыслами на разных языках. Почему именно эта модель? Потому что на большинстве задач по кодированию русских предложений без дообучения она работает лучше аналогов. Так что сходство смысла пар текстов я буду мерять как косинусную близость их эмбеддингов LaBSE.
Наконец, естественность текстов. Традиционно её измеряют перплексией языковых моделей, и я пойду по тому же пути: буду вычислять естественность текста как перплексию модели rugpt3small от Сбера на нём. Начало и конец текста я обозначу переносом строки. Перплексию множества предложений буду измерять как среднюю перплексию каждого, взвешенную по числу токенов.
import numpy as np
from transformers import AutoModelForCausalLM
mname = 'sberbank-ai/rugpt3small_based_on_gpt2'
gpt_tokenizer = AutoTokenizer.from_pretrained(mname)
gpt_model = AutoModelForCausalLM.from_pretrained(mname)
gpt_model.cuda();
def get_gpt2_ppl_corpus2(test_sentences, aggregate=True, sep='\n'):
""" Calculate average perplexity per token and number of tokens in each text."""
lls = []
weights = []
for text in tqdm(test_sentences):
encodings = gpt_tokenizer(f'{sep}{text}{sep}', return_tensors='pt')
input_ids = encodings.input_ids.to(gpt_model.device)
target_ids = input_ids.clone()
w = max(0, len(input_ids[0]) - 1)
if w > 0:
with torch.no_grad():
outputs = gpt_model(input_ids, labels=target_ids)
log_likelihood = outputs[0]
ll = log_likelihood.item()
else:
ll = 0
lls.append(ll)
weights.append(w)
likelihoods, weights = np.array(lls), np.array(weights)
if aggregate:
return sum(likelihoods * weights) / sum(weights)
return likelihoods, weights
Код всех этих метрик можно взять из этого файла и использовать в своих проектах.
Перефразирование переводчиком, или туда и обратно
Как я уже упоминал в контексте LaBSE, корпуса и модели для перевода между языками обладают мощным парафразным потенциалом, ибо перевод в каком-то смысле является перефразированием на стероидах: форма текста изменяется полностью, а смысл сохраняется максимально близок к оригиналу. Поэтому в качестве парафразера можно использовать пару моделей: первая переводит с русского на промежуточный язык (у меня это английский), вторая - обратно.
Чтобы полученные таким образом парафразы были нетривиальными, нужно как-то обеспечить непохожесть их на оригинальный текст. В пакете transformers от Huggingface есть подходящий инструмент: аргумент bad_word_ids, который запрещает использовать определённые последовательности токенов при генерации. Этим аргументом мы можем запретить нашему переводчику копировать слишком длинные куски исходного текста. Чтобы это не слишком портило качество текстов, нужно использовать beam search с шириной луча, превосходящей размер запрещаемых n-грамм. Поэтому гиперпараметры парафразера такие: чем меньше gram, тем более непохожими на оригинал получаются тексты, но потенциально и более нелепыми. А чем больше num_beams, тем более естественными получаются тексты, но тем дольше длится генерация.
import torch
from transformers import FSMTModel, FSMTTokenizer, FSMTForConditionalGeneration
tokenizer = FSMTTokenizer.from_pretrained("facebook/wmt19-en-ru")
model = FSMTForConditionalGeneration.from_pretrained("facebook/wmt19-en-ru")
inverse_tokenizer = FSMTTokenizer.from_pretrained("facebook/wmt19-ru-en")
inverse_model = FSMTForConditionalGeneration.from_pretrained("facebook/wmt19-ru-en")
model.cuda();
inverse_model.cuda();
def paraphrase(text, gram=4, num_beams=5, **kwargs):
""" Generate a paraphrase using back translation.
Parameter `gram` denotes size of token n-grams of the original sentence that cannot appear in the paraphrase.
"""
input_ids = inverse_tokenizer.encode(text, return_tensors="pt")
with torch.no_grad():
outputs = inverse_model.generate(input_ids.to(inverse_model.device), num_beams=num_beams, **kwargs)
other_lang = inverse_tokenizer.decode(outputs[0], skip_special_tokens=True)
# print(other_lang)
input_ids = input_ids[0, :-1].tolist()
bad_word_ids = [input_ids[i:(i+gram)] for i in range(len(input_ids)-gram)]
input_ids = tokenizer.encode(other_lang, return_tensors="pt")
with torch.no_grad():
outputs = model.generate(input_ids.to(model.device), num_beams=num_beams, bad_words_ids=bad_word_ids, **kwargs)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
return decoded
Попробуем перефразировать предложение и засечём время:
%%time
text = 'Женщина-дайвер исчезла в Черном море во время научных работ на побережье Анапы.'
print(paraphrase(text, gram=3, do_sample=False))
# Женщина-водолаз пропала в акватории Черного моря, когда выполняла исследовательские работы у берегов Анапы.
# Wall time: 699 ms
Кажется, получилось и близко по смыслу к оригиналу, и непохоже по словам, и не то чтобы прям супер медленно. Но, конечно, таки медленно. Поэтому следующим шагом мы попробуем обучить модель, которая бы перефразировала текст в один проход, а не в два. Но сначала надо понять, на каких данных её тренировать.
Новый корпус парафраз
Раз уж у меня есть крутой автоматический инструмент перефразирования, можно использовать его для генерации нового корпуса парафраз из любого источника. Я решил взять Лейпцигский веб-корпус русского языка за 2019 год. Он содержит миллион предложений, взятых из разных источников в Интернете, и, в отличие от некоторых других веб-корпусов, неплохо очищенных от всякого мусора. Весь этот корпус я прогнал через описанную выше функцию paraphrase с параметрами gram=3, num_beams=5, repetition_penalty=3.14, no_repeat_ngram_size=6, и заняло это порядка недели вычислительного времени (за счёт использования батчей можно было бы ускорить процесс, но я никуда не торопился).
В результате у меня получился файл paranmt_ru_leipzig.tsv на миллион строк. Каждая строка выглядит примерно так:
idx 920024
original Хм… то есть с жж лучше вообще не выкладывать?
en Hmm... is it better not to post with LJ at all?
ru Хм.... не лучше ли вообще не писать в ЖЖ?Большая часть получившихся парафраз невооружённым взглядом кажутся довольно качественными. В некоторых из них, однако, допущены переводческие ляпы, например, "полустанок" модель перевела как "полумашина", а "были по колено в грязи" как "лежали на коленях в иле". Другая проблема заключается в том, что за счёт bad_word_ids модели пришлось перефразировать имена собственные, и иногда она делала это плохо - например, превратила "Оймякон" в "Оймянск", а "Верхоянск" вообще заменила на "Тольятти". Но в целом, как мы увидим дальше, качество корпуса относительно высокое.
Скачать корпус можно из моего Яндекс.Облака. Называть его я рекомендую ParaNMT-Ru-Leipzig, по аналогии с англоязычным корпусом ParaNMT.
Сравнение корпусов
Мой корпус русскоязычных парафраз далеко не первый. Кроме него в публичном доступе есть как минимум следующие:
Opusparcus - многомиллионный корпус, автоматически извлечённый из субтитров для 6 европейских языков, включая русский. В этом корпусе есть автоматическая оценка качества парафраз на основе mutual information;
opus_good- подмножество Opusparcus, отфильтрованное по условию PMI>15 (1.8 миллиона из 22), и содержащее более похожие друг на друга пары.
русская часть Tapaco - корпуса парафраз, извлечённого из мультиязычного параллельного корпуа;
Три корпуса Тамары rysshe Жордании:
backed: обратный перевод англо-русского параллельного корпуса Яндекса;
news: отфильтрованные по сходству пары новостных заголовков, описывающих одну и ту же новость;
subtitles: отфильтрованные по сходству пары субтитров, отобранные аналогично Opusparcus;
Paraphraser 2016 - относительно небольшой корпус пар новостных заголовков, вручную размеченный по семантической близости. Я брал из него только пары, отмеченные как синонимичные;
ParaPhraserPlus: огромный корпус наборов заголовков об одних и тех же новостях, собранный автоматически и профильтрованный по сходству эмбеддингов RuBERT в этой статье .
Из каждого корпуса я случайно (равномерно) выбрал по 10К пар предложений.
Для каждого из корпусов я оценил следующие метрики:
sim- косинусную близость пар. Чем она выше, тем парафразы ближе по смыслу друг к другу;sim_random- косинусную близость случайным образом перемешанных пар. Чем она выше, тем корпус однообразнее;bleu- BLEU пары парафраз, усреднённое по обоим направлениям;char_ngram_overlap- доля общих символьных n-грамм;perp- средняя перплексия всех предложений в корпусе.
После всех вычислений результат вышел такой:
corpus | sim | sim_random | bleu | char_ngram_overlap | perp |
|---|---|---|---|---|---|
tapaco | 0.9177 | 0.3426 | 0.5845 | 0.4331 | 3.7707 |
leipzig | 0.9027 | 0.3040 | 0.5185 | 0.3154 | 3.8428 |
paraphraser | 0.8979 | 0.3062 | 0.6404 | 0.5155 | 3.5635 |
backed | 0.8627 | 0.3284 | 0.5345 | 0.3609 | 4.0627 |
subtitles | 0.8141 | 0.4316 | 0.4499 | 0.3134 | 4.3803 |
ppp | 0.7465 | 0.2647 | 0.4200 | 0.3037 | 3.9351 |
opus_good | 0.7238 | 0.3278 | 0.4071 | 0.2488 | 4.7208 |
news | 0.6709 | 0.2735 | 0.3833 | 0.2352 | 3.7960 |
opus | 0.5473 | 0.3204 | 0.3319 | 0.1222 | 4.7753 |
Наиболее близкими по смыслу пары оказались в корпусах tapaco (там часто просто заменяется грамматический род) и leipzig, наименее близкими - в news и нефильтрованном opus (и там, и там данные довольно грязные). Корпуса news и leipzig оказались самыми разнообразными по содержанию, а subtitles - самым однообразным. Корпуса paraphraser и tapaco демонстрируют самое высокое поверхностное сходство текстов, а opus и news - самое низкое.
Большинство корпусов - симметричные, и перплексия обоих текстов примерно одинаковая. Но у корпусов, полученных обратным переводом, перплексия оригинального текста заметно меньше, чем у переведённого: 3.82 против 3.91 у leipzig и 3.87 против 4.44 у backed.

Если изобразить смысловую близость (по LaBSE) и поверхностную близость (по общим n-граммам), мы увидим, что зависимость почти прямая и даже почти линейная. Это логично, ибо требования высокой смысловой близости и низкого поверхностного сходства друг с другом конкурируют: чем больше в паре текстов общих подстрок, тем больше шанс, что и по смыслу они близки. В этом отношении корпус ParaNMT-Ru-Leipzig выгодно отличается от остальных, выбиваясь из общей прямой: у него больше смысловая близость, чем у корпусов с аналогичной текстовой близостью. Именно это я имел в виду, когда называл выше новый корпус относительно качественным.

Ещё одна пара метрик, которые, возможно, в каком-то смысле тоже конкурируют друг с другом - это смысловая близость и однородность корпуса: чем более корпус разнородный, тем сложнее ко всем предложениям подобрать адекватную пару. С этой точки зрения ParaNMT-Ru-Leipzig тоже оптимален: более высокая близость в парах только у корпуса Tapaco (который сильно более однороден), а более низкая однородность - только у news и ppp (где большие проблемы с близостью).
Обучение своего парафразера
Следуя образцу Алёны Феногеновой и здравому смыслу, за основу парафразера я взял предобученную модель для генерации русских текстов. Из T5 (encoder+decoder) и GPT (decoder only) я выбрал T5, как более способную к сохранению смысла. За базу я взял дообученную на русском языке модель rut5-base-multitask. Рассказ о её создании заслуживает отдельного поста, но, если вкратце, я взял за основу модель mT5 и вырезал из неё нерусские и неанглийские эмбеддинги по этому рецепту, получив rut5-base. Потом я пофайнтюнил её на 10 разных русских (и отчасти английских) задач, требующих способности как понимать, так и генерировать тексты, и получил rut5-base-multitask. И вот эту нейронку я теперь дообучил уже чисто на перефразирование.
Датасеты для обучения я решил сэмлировать в таком соотношении: 40% ParaNMT-Ru-Leipzig (наиболее качественный корпус), 20% opus_good (самый большой и разнообразный из адекватных корпусов), и по 10% news, subtitles, backed и tapaco. При дообучении я использовал батч размера 10, накапливал градиент 32 шага, а шаг делал длины 1e-5 градиента. Где-то 1% батчей забивали память CUDA и падали с ошибкой; их я просто игнорировал. Длилось обучение на Colab около 5 суток (я каждый день перезапускал блокнот). Код для обучения выглядит (в упрощённом виде) как-то так:
import torch
from transformers import T5ForConditionalGeneration, T5Tokenizer
# use here a backbone model of your choice, e.g. google/mt5-base
backbone_model = 'cointegrated/rut5-base-multitask'
model = T5ForConditionalGeneration.from_pretrained(backbone_model)
tokenizer = T5Tokenizer.from_pretrained(backbone_model)
model.cuda();
optimizer = torch.optim.Adam(params=[p for p in model.parameters() if p.requires_grad], lr=1e-5)
# todo: load the paraphrasing corpus and define the get_batch function
for i in range(100500):
xx, yy = get_batch(mult=mult)
x = tokenizer(xx, return_tensors='pt', padding=True).to(model.device)
y = tokenizer(yy, return_tensors='pt', padding=True).to(model.device)
# do not force the model to predict pad tokens
y.input_ids[y.input_ids==0] = -100
loss = model(
input_ids=x.input_ids,
attention_mask=x.attention_mask,
labels=y.input_ids,
decoder_attention_mask=y.attention_mask,
return_dict=True
).loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
model.save_pretrained('my_paraphraser')
tokenizer.save_pretrained('my_paraphraser')
Готовую модель я выложил под названием rut5-base-paraphraser, и использовать её можно как любую другую модель из Huggingface, то есть просто:
from transformers import T5ForConditionalGeneration, T5Tokenizer
MODEL_NAME = 'cointegrated/rut5-base-paraphraser'
model = T5ForConditionalGeneration.from_pretrained(MODEL_NAME)
tokenizer = T5Tokenizer.from_pretrained(MODEL_NAME)
model.cuda();
model.eval();
def paraphrase(text, beams=5, grams=4):
x = tokenizer(text, return_tensors='pt', padding=True).to(model.device)
max_size = int(x.input_ids.shape[1] * 1.5 + 10)
out = model.generate(**x, encoder_no_repeat_ngram_size=grams, num_beams=beams, max_length=max_size)
return tokenizer.decode(out[0], skip_special_tokens=True)
print(paraphrase('Каждый охотник желает знать, где сидит фазан.'))
# Все охотники хотят знать где фазан сидит.
Сравнение парафразеров
Чтобы понять, насколько парафразер хорош, логичнее всего сравнить его с аналогами. К сожалению, аналогов у нас не очень много:
t5_new: моя новая модель;translation: алгоритм перефразирования, основанный на переводе - см. выше;word-based: мой прошлогодний dependency-paraphraser, основанный на двух эвристиках:Сделать синтаксический разбор предложения Наташей и переставить слова правдоподобным образом,
Для случайно выбранных слов поискать соседей по fastText эмбеддингам (из маленькой модели) и заменить, если соседи нашлись достаточно близкие.
sber_t5: алгоритм из russian_paraphrasers на основе mt5-base;sber_gpt: алгоритм из russian_paraphrasers на основе rugpt2-large.
У каждого из алгоритмов я варьировал параметры: для t5_new и translation я менял число токенных n-грамм, запрещённых к повторению, для sber_t5 и sber_gpt - число кандидатов, из которых выбирается наилучший (кандидаты там ранжируются по сходству предложений, рассчитанному моделью XLM). Методы t5_new и translation используют только одного кандидата, зато генерируют его лучом ширины 5. Для чистоты сравнения я взял сберовскую t5-base и прогнал с ней инференс в том же режиме, как и для t5_new, получив запись sber_t5_new. Для word-based я взял четыре комбинации гиперпараметров, соответствующие разной степени агрессивности.
В качестве тестовой выборки я взял случайно выбранные 100 заголовков из тестовой выборки paraphraser.ru. В качестве метрик - всё те же показатели, которые я считал для корпусов. В первую очередь нам интересно, как каждая модель балансирует текстовое сходство со смысловым:
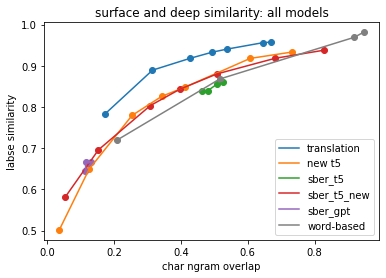
Результат меня удивил: модель translate показала наилучший баланс, то есть самое высокое смысловое сходство при заданном поверхностном сходстве. Моя собственная модель, несмотря на долго обучение, дала менее оптимальный результат, равно как и модели от Сбербанка. Параметр n (число кандидатов), как оказалось, не сильно влияет на результат работы Сберовских моделей. А вот если их запустить в моём режиме (beam search и запрет на повторение n-грамм), то результат получается у двух версий T5, обученных независимо и на частично разных данных, очень близким.
При сравнении парафразеров важно учитывать не только сходство текстов, но и их естественность, которую я измеряю перплексией языковой модели. У всех нейросетевых моделей перплексия оказалась примерно одинаковой; чуть лучше - у модели translate в некоторых настройках; чуть хуже почему-то у GPT. У модели, основанной на эвристиках, перплексия вышла на порядок больше, чем у нейросетевых, так что для генерации правдоподобных текстов я её не советую.

Итоги
Как это часто бывает, внятная постановка задачи сразу породила сильный бейзлайн. Нам нужно переписать текст, сохранив смысл? Что ж, возьмём модель для перевода, которая ровно этому и обучена. Нужно, чтобы переписанный текст отличался от исходного, ну так запретим модели повторять длинные подстроки. Построенный таким образом алгоритм оказался сильнее, чем нейросети, специально обученные на задачу перефразирования. Заодно мы научились оценивать свойства, которые мы от парафразеров ожидаем: близость смыслов, различие в написании, и естественность текстов.
В поиске хорошего парафразера я собрал корпус из миллиона качественных пар предложений и обучил на нём собственную модель, но её качество оказалось не выше, чем у моделей, обученных на других корпусах. Возможно, для обучения парафразера важен не только корпус, но и применяемая функция потерь, в которую в явном виде можно зашить предъявляемые нами требования. Поэтому в каком-то обозримом будущем я попробую применить RL для оптимизации свойств парафразера непосредственно в ходе обучения. Ну а пока что пользуйтесь той моделью, что есть, новым корпусом, метриками, и, конечно же, алгоритмом перефразирования с помощью переводчика. Мир вам!

iAMDiver
Спасибо, очень круто, больше бы таких статей
cointegrated Автор
А про что ещё хочется?)
MaxKozlov
Интересно восстановление целых слов из сокращений. Мало где видел
предл. сокр. зам. нач. отдела и т.д.
многозначность по контексту угадывать - как раз для машинного обучения, мне кажется