

Lombok — это отличный инструмент, с которым Java-код становится чище и лаконичнее. Однако есть несколько нюансов, которые надо учитывать при его использовании с JPA. В этой статье мы выясним, как неправильное применение Lombok может повлиять на производительность приложений или даже привести к ошибкам. Разберемся, как этого избежать не теряя преимуществ Lombok.
Мы разрабатываем JPA Buddy — плагин для IntelliJ IDEA, который упрощает работу с JPA. Прежде чем приступить к разработке, мы проанализировали сотни проектов на GitHub, чтобы понять, как именно программисты взаимодействуют с JPA. Оказалось, что многие из них используют Lombok.
Использовать Lombok в проектах с JPA вполне можно, но нужно учитывать его некоторые особенности. Анализируя проекты, мы увидели, что разработчики снова и снова наступают на те же грабли. Именно поэтому мы добавили в JPA Buddy целый ряд инспекций кода для Lombok. Давайте рассмотрим наиболее распространенные проблемы, с которыми вы можете столкнуться при использовании Lombok с JPA.
Некорректно работающий HashSet (и HashMap)
Анализируя проекты, мы часто видели сущности, помеченные @EqualsAndHashCode или @Data. В документации по аннотации @EqualsAndHashCode сказано следующее:
По умолчанию реализации методов будут использовать все нестатические и не транзиентные поля. Однако вы можете явно указать используемые поля, пометив их с помощью аннотаций
@EqualsAndHashCode.Includeили@EqualsAndHashCode.Exclude.
Как правильно реализовать equals()/hashCode() для JPA-сущностей — вопрос не тривиальный. Сущности мутабельны по своей природе. Даже ID зачастую генерируется базой данных, то есть изменяется после первого сохранения сущности. Получается, не существует полей, на основе которых можно было бы консистентно вычислить hashCode.
Докажем это на практике. Создадим тестовую сущность:
@Entity
@EqualsAndHashCode
public class TestEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(nullable = false)
private Long id;
}И выполним следующий код:
TestEntity testEntity = new TestEntity();
Set<TestEntity> set = new HashSet<>();
set.add(testEntity);
testEntityRepository.save(testEntity);
Assert.isTrue(set.contains(testEntity), "Entity not found in the set");Assert в последней строчке упадет с ошибкой, хотя сущность добавлена в set всего несколькими строками выше. Если использовать Delombok на этой сущности, мы увидим, что @EqualsAndHashCode под капотом реализует следующий код:
public int hashCode() {
final int PRIME = 59;
int result = 1;
final Object $id = this.getId();
result = result * PRIME + ($id == null ? 43 : $id.hashCode());
return result;
}При первом сохранении сущности ID изменяется. Соответственно, меняется и hashCode. Именно поэтому HashSet и не может найти объект, который мы только что создали, так как он ищет его в другом бакете. Проблем бы не было, если бы ID был установлен во время создания объекта сущности (например, в качестве ID использовался бы UUID, генерируемый приложением), но чаще всего за генерацию идентификаторов отвечает именно база данных.
Непреднамеренная загрузка lazy полей
Как было отмечено выше, @EqualsAndHashCode по умолчанию использует все поля сущности. Такой же подход используется и для @ToString:
Любой класс может быть помечен аннотацией
@ToString, чтобы Lombok сгенерировал реализацию методаtoString(). По умолчанию сгенерированный методtoString()возвращает строку, содержащую имя класса и значения всех полей через запятую.
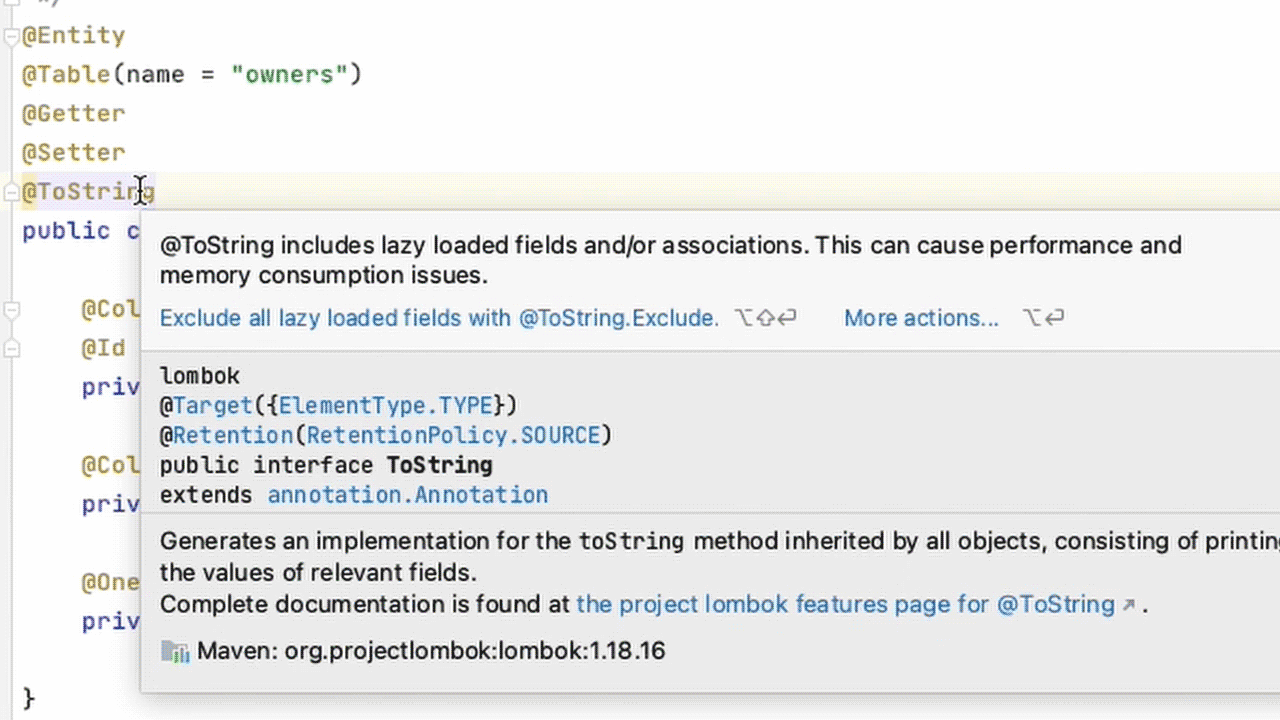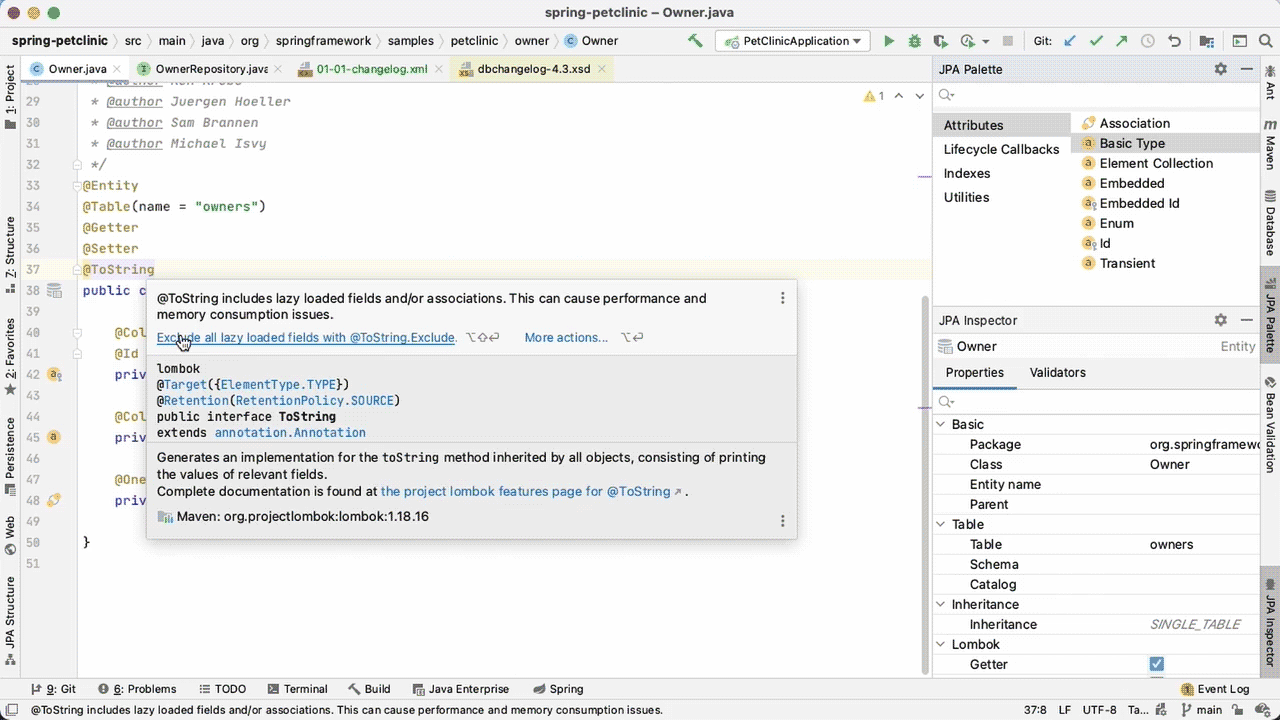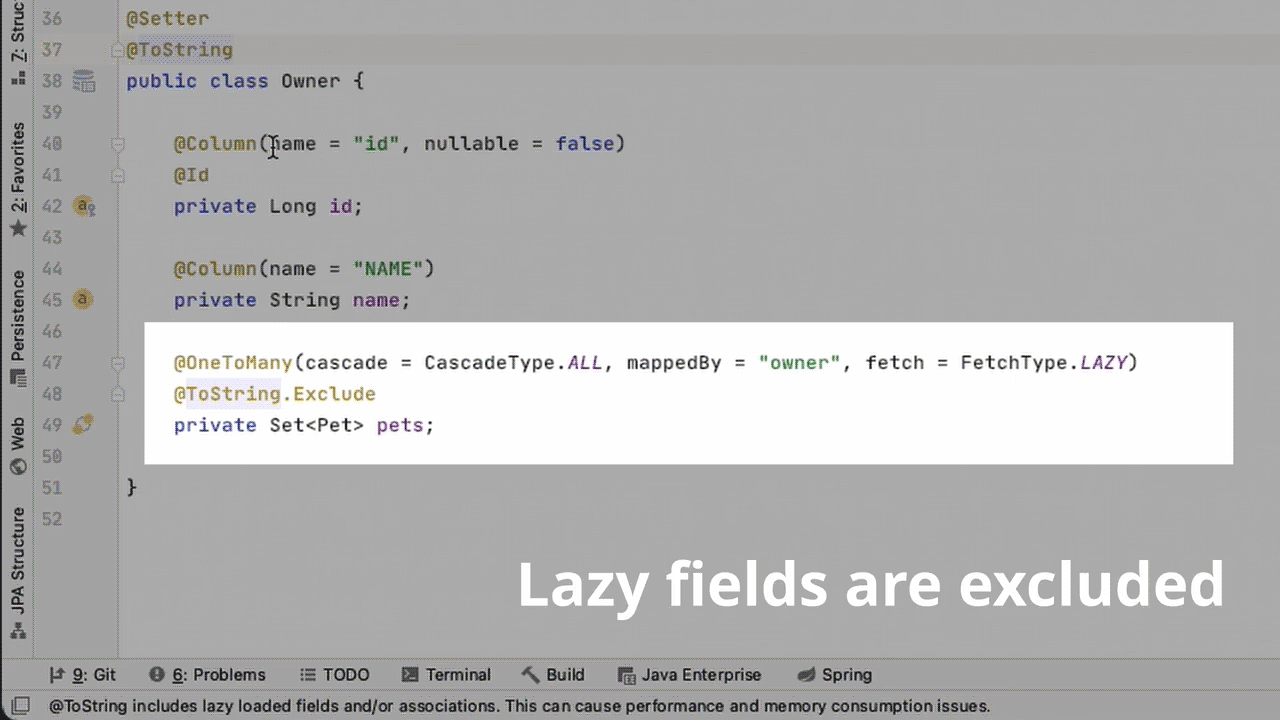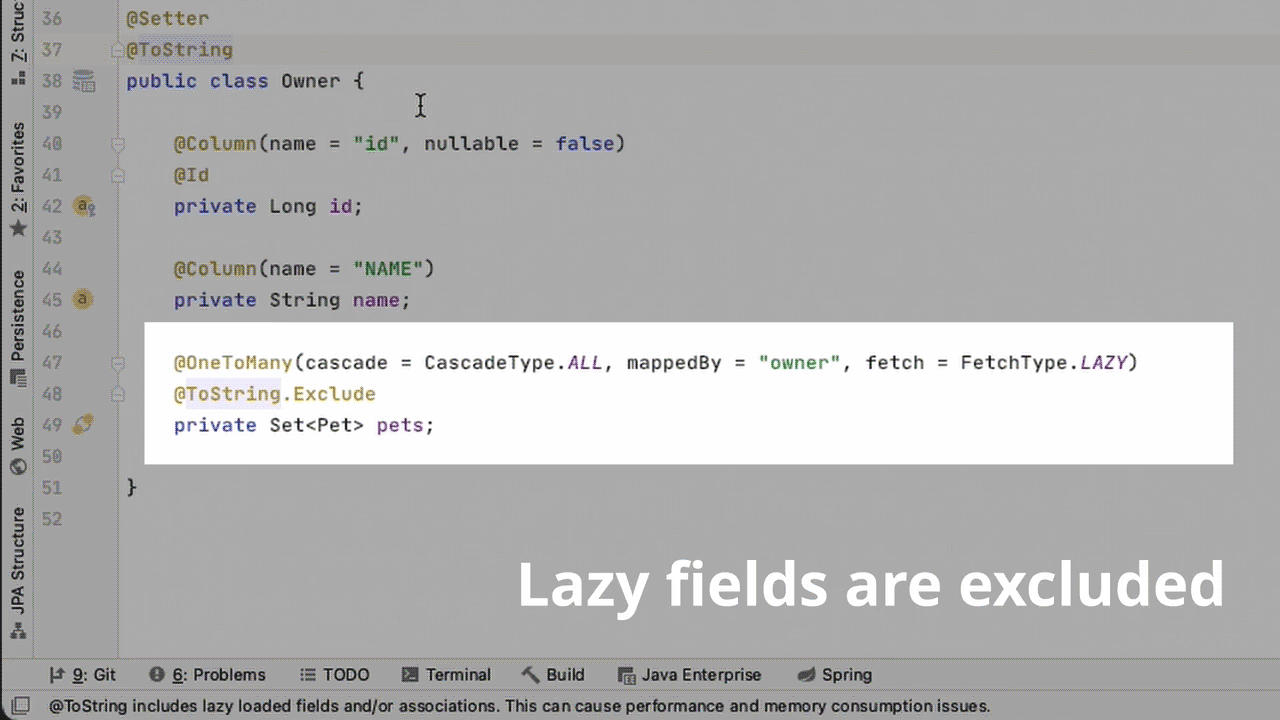
Получается, эти методы вызывают equals()/hashCode()/toString() на каждом поле сущности, включая lazy поля. Это может привести к их непреднамеренной загрузке.
Например, вызов hashCode() на lazy ассоциации @OneToMany может спровоцировать подгрузку всех связанных сущностей. Это может серьезно сказаться на производительности приложения или вызвать LazyInitializationException, если вызов произойдет вне транзакции.
Мы считаем, что вообще не стоит использовать @EqualsAndHashCode и @Data на сущностях, в JPA Buddy есть для этого инспекция:

Аннотацию @ToString можно использовать, если исключить все lazy поля. Для этого надо пометить lazy поля аннотацией @ToString.Exclude или использовать @ToString(onlyExplicitlyIncluded=true) на классе и @ToString.Include на не-lazy полях. В JPA Buddy есть для этого квик-фикс:
Конструктор без аргументов
Согласно спецификации JPA, все сущности должны иметь public или protected конструктор без аргументов. Очевидно, что при использовании @AllArgsConstructor компилятор не генерирует конструктор по умолчанию, это также касается и @Builder:
Применение
@Builderк целому классу равноценно применению@AllArgsConstructor (access = AccessLevel.PACKAGE)на классе и@Builderна конструкторе с параметрами.
Поэтому обязательно используйте их с аннотацией @NoArgsConstructor или с конструктором без параметров:

Заключение
С Lombok ваш код выглядит чище, но, как и в случае с любым другим магическим инструментом, важно понимать, как именно он работает и когда его использовать. В противном случае производительность вашего приложения может снизиться, либо оно вовсе может перестать работать корректно. Как вариант, можно положиться на инструменты разработки, которые будут предупреждать вас о потенциальных проблемах.
При работе с JPA и Lombok помните следующие правила:
Избегайте использования аннотаций
@EqualsAndHashCodeи@Dataс JPA сущностями;Исключайте ленивые поля при использовании аннотации
@ToString;Не забывайте добавлять аннотацию
@NoArgsConstructorк сущностям помеченным аннотациями@Builderили@AllArgsConstructor.
Есть еще один вариант: переложите ответственность за соблюдение этих правил на JPA Buddy, его инспекции кода всегда к вашим услугам.
maxzh83
В случае с equals()/hashCode() из статьи понятно как делать не надо, но не понятно как надо. Особенно когда нет явного естественного ключа.
andreyoganesyan Автор
Да, это вопрос на отдельную статью :) Вот хорошая: thorben-janssen.com/ultimate-guide-to-implementing-equals-and-hashcode-with-hibernate
TL;DR:
1. Если объекты будут всегда сравниваться в пределах одной сессии Хибернейта, можно equals и hashCode вообще не переопределять
2. Если есть natural id или id выставляется самим приложением, используем только его в equals и hashCode
3. Если id генерирует база, используем его в equals и возвращаем из hashCode некоторую константу. Да, это ухудшит производительность коллекций на хешах, но серьезно это начнет влиять с такого количества объектов, что узким местом скорее станет сам факт вытаскивания их из БД. Такова идея, конечно, в реальном мире все зависит от того, как часто к этим коллекциям обращаться
mayorovp
Никогда не возвращайте из hashCode константу. Это бессмысленно, поскольку не просто ухудшает производительность хеш-таблиц, но сводит их к массиву. Но если вам достаточно массива, почему бы не использовать ArrayList вместо хеш-таблицы?
andreyoganesyan Автор
Если нам нужна коллекция уникальных элементов, заменив HashSet на ArrayList мы переложим ответственность за поддержание уникальности на себя. Придётся каждый раз вызывать contains и все в этом духе, то есть писать лишний код. А в сете это все уже за нас написано, пусть по производительности он будет сведён к массиву в случае константного hashCode. Да и что делать с Map?
Проблема в том, что иногда hashCode просто не от чего считать, вот и приходится выбирать между плохим решением и решением ещё хуже. Сущность, где все поля мутабельны — как раз такой случай
BugM
И все равно так не делайте. Это выстрелит через непонятное время.
Ваши хешмапы превратились в тримапы. logn это не очень много, но все равно легко можно написать код который думая что там o(1) внезапно начнет тормозить на пустом месте. Особенно на активном добавлении-удалении элементов.
И естесвенно это произойдет на проде в НГ или черную пятницу. Когда минута простоя стоит несколько миллионов. Хорошо если рублей.
poxvuibr
Вот если написать в hashCode не константу, то да, выстрелит. Не сразу, но обязательно будут плавающие баги.
Для этого не надо использовать энтити как ключи в хешмапе. А когда используешь коллекции типа HashSet, надо помнить, что нельзя класть туда много элементов. Но вообще надо просто помнить, что надо делать связи OneToMany в которых много элементов
BugM
Вы прячете в деталь реализации неожиданное усложнение .get из мапы до o(n).
Пишем типовой поиск всех элементов из соседней коллекции в этой и вот он квадрат.
И уже не надо много. Уже тысячах на 10 элементов тормоза будут. Которые не ловятся ни тестами ни ручными тестировщикам ни даже нагрузочным тестированием.
А вот на проде они замечательно выстрелят. В момент максимальной нагрузки. И потратят максимально возможное количество денег бизнеса.
Не надо так софт проектировать. Это гарантирует проблемы. Надо подумать и сделать хорошо. Именно за это деньги платят.
poxvuibr
Поэтому не надо делать энтити ключами мапы
По перечисленным выше причинам, так делать не надо.
Во-первых, по перечисленным выше причинам на надо делать Set из десяти тысяч энтити. Потому что это приведёт к проблемам.
Во-вторых, десять тысяч элементов на связи OneToMany это много независимо от коллекции, которая используется для их хранения. В таких случаях лучше делать только связь ManyToOne потом выбирать элементы отдельным запросом.
Я тоже говорю об этом.
Не надо использовать энтити в качестве ключей хешмепа. Не надо использовать что-то кроме id в equals и hashCode. hashCode должен возвращать константу. equals должен вернуть false если хотя бы один id равен null. Это актуально для энтити в которых нет естественного ключа, а суррогатный ключ не известен сразу после вызова конструктора объекта.
Не надо делать OneToMany с большим количеством участников. Это актуально для всех энтити.
Правил ещё много, но эти относятся к теме напрямую.
mayorovp
Уточнение — чтобы получился TreeMap, нужен способ сравнения записей. А его нет, так что там никакой не логарифм выйдет, а линия.
BugM
Согласен. Если даже hashCode константа, то рассчитывать на реализацию сравнения глупо.
LaRN
А разве нельзя в таком случае создать статичные суррогатное поле, которое будет при создании объекта заполняться некоторым предопределенным значением, хоть GUID - например, и его использовать как базу для расчёта hashcode? Вроде генерация GUID не очень затратна по времени и почти исключает дубликаты.
mayorovp
Проще не создавать никакого поля и использовать equals и hashCode по умолчанию.
poxvuibr
Такая позиция существует, но тогда получается, что будут проблемы с пониманием, что две энтити у которых равен id относятся к одной и той же строке в БД
mayorovp
А она так и так будет если программист не следит какие сущности он получает и из каких источников.
poxvuibr
Если переопределить equals, то проблем с определением быть не должно, даже если одна из сущностей ещё не находится в контексте.
mayorovp
Ну а если обе сущности находятся в контексте, и программист не знает какая из них верная — то проблемы будут независимо от того как вы определили equals.
poxvuibr
По хорошему движок JPA не должен поместить в контекст две разных энтити, указывающих на одну и ту же строку. Вся штука в том, что нужно держать в одной коллекции несколько энтити, которые есть в контексте, которых ещё в нём нет и не забыть про энтити, которые пока не попали даже в БД.
mayorovp
В данном случае, "контекст" означал не "контекст JPA", а более общее понятие.
В случае с контекстом JPA как раз всё понятно: движок за всем проследит независимо от реализации equals.
poxvuibr
За исключением случая, когда речь идёт о hashCode в классе, помечнном аннотацией Entity.
В случае с Entity это крайне осмысленно, потому что equals должен быть завязан на Id и Entity у которых Id == null должны быть не равны друг другу, чтобы можно было сложить их в Set
Не к массиву, а к дереву, но да, сводит. Поэтому Entity не надо делать ключами в HashMap. Что касается коллекций типа Set — когда речь идёт об Entity, там в любом случае нельзя держать много элементов, так что ничего страшного не случится.
Обычно так и делают. Но даже в этом случае надо сделать так, чтобы arrayList.contains работал корректно, когда ему отдают Entity с id равным null
mayorovp
Зачем?
poxvuibr
Чтобы когда кладёшь в Set энтити и там уже есть энтити с таким id, новая энтити вытеснила старую.
Ну и иногда удобно делать arrayList.contains
mayorovp
В таком случае вы завязываетесь на недокументированное поведение.
А ведь можно вместо
Set<EntityType>использоватьMap<KeyType, EntityType>и ни на какое недокументированное поведение не завязываться. И бонусом тут будет ускорение работы.poxvuibr
Мне кажется нет такого. Какое поведение из того на что я ссылаюсь не документировано?
mayorovp
Вот это и недокументировано. Это просто особенность реализации HashSet и TreeSet. Более того, это ещё и на баг похоже, потому что в документации на интерфейс написано следующее:
poxvuibr
Контракт на интерфейс Set гарантирует, что если сделать сначала remove, а потом add, то в коллекции окажется новый объект. Наверное надо было сразу написать про все операции целиком.
mayorovp
Ну, если remove делать — то да, но вы же изначально без remove предлагали
poxvuibr
Прошу прощения за недостаточную детализацию. Если серьёзно писать на эту тему — комментария не хватит. И вот эту важную деталь, как и многие другие, я не упомянул. Использование коллекций с JPA вообще нетривиальная штука. Мало того, что в некторых случаях надо делать remove а потом add одного и того же объекта, так ещё и надо делать много странных движений для маппинга, если хочешь убрать дополнительные запросы. Плюс надо помнить, что в Hibernate зачастую используется на ArrayList или что-то в этому духе, а какая-нибудь другая структура. Когда я пытаюсь вкратце рассказать, постоянно что-то упускаю.
KivApple
Как вариант, можно договориться никогда не пихать в HashMap несохранённые хоть раз сущности. Это звучит гораздо разумнее, чем превращать HashMap в ArrayList.
poxvuibr
HashMap невозможно превратить в ArrayList. В лучшем случае будет дерево.
mayorovp
Чтобы получилось дерево — записи должны быть сравнимыми (Comparable). А без этого сравнивать можно только хеши, которые одинаковы. Так что дерево выродится в LinkedList.
poxvuibr
Ну вот я и говорю, что дерево будет в лучшем случае ))
mayorovp
Правильно — вообще не трогать эти методы.
Вариантов-то всего три: сравнивать по ссылке, сравнивать по id, сравнивать по всем атрибутам. Почему плох третий — автор написал, теперь сравним первые два варианта.
Если у двух сущностей совпадают id — это вовсе не означает что они равны, это означает что их нельзя использовать совместно, поскольку они представляют несогласованное знание об одном и том же предмете. А если сущности с одним id никогда не встречаются — то равенство id и равенство ссылок эквивалентны, но равенство ссылок проще и лишено некоторых недостатков (таких как поведение при незаполненном id). Следовательно, id можно при сравнении не проверять.
a1ex322
Есть ещё четвёртый вариант - самому генерировать ключ для мапки в зависимости от требуемой бизнес логикой уникальности: FirstName + LastName, email и т.п. А если уникальность не требуется то и мапка не нужна
mayorovp
Да, такой вариант есть. Но он ничем не отличается от варианта с id.
a1ex322
id можно использовать как ключ мапки чтобы, например, убедиться, что в бд не уйдет апдейт двух рекордов с одинаковым id. А свой ключ когда требуется какая-нибудь особая уникальность для новых и/или существующих entity (id пустой в первом случае)
mayorovp
Но ведь для этого не нужно же перегружать equals и hashCode...
a1ex322
Да. Честно говоря не ясен их смысл у мутабельных объектов. Добавили в сет, потом поменяли?
poxvuibr
Конкретно в энтити — есть необходимость безопасно добавлять и в Set.
Да, добавили в сет пока id == null, потом записали в БД и id сгенерировались и при этом сет должен работать корректно.
a1ex322
Непонятно. Вы поменяли поле/поля, изменился хеш и объект теперь не в своем бакете.
poxvuibr
Именно для того, чтобы объект не менял бакет, hashCode должен возвращать константу
a1ex322
я бы предпочел, чтобы вот такое вообще не компилировалось (так как сам на эти грабли наступал):
Set<EntityType>иMap<EntityType,...>poxvuibr
Правильно сравнивать по Id, но добавить условие, что если id ==null, то equals выдаст false. Ну и плюс вернуть константу в hashCode конечно