
Эмуляторы это очаровательная область разработки софта: возможность вдохнуть жизнь в 30-летний игровой автомат на современном компьютере это невероятно приятное достижение. Увы, меня всё больше расстраивает отсутствие амбиций в сообществе эмуляторщиков. В том время как остальной мир движется в облака, к массивным распределённым архитектурам, эмуляторы крепко застряли в XX веке с его С++ в один поток.
Этот проект родился из желания привнести лучшее из современного дизайна систем обратно в будущее древней истории компьютеров.

Так что же лучшее из современной архитектуры может дать эмуляторам?
Горячая замена кода, чтобы позволить отладку игр
Разные языки для разных компонентов
Безопасность по умолчанию (mTLS для всех вызовов функций)
Масштабируемость
Отказоустойчивость
Родной для облаков подход (cloud native design)
Кульминацией этого проекта стала реализация процессора 8080 с использованием современной, контейнеризованной, микросервисной архитектуры запущенной на Кубернетесе с фронтэндами для тестов CP/M и полной версии оригинального автомата Space Invaders.
Целиком проект можно найти в гитхаб-организации, которая содержит 60 отдельных репозиториев, каждая из которых реализует микросервис или предоставляет инфраструктуру. Эта статья описывает подробности технической архитектуры и проблемы с которыми я столкнулся на этом проекте.
Ключевые вещи для начала:
Основанный на реакте дизассемблер 8080, запущенный на github pages
Тестовая обвязка CP/M, использованная для валидации процессора (просто используйте
docker-compose up --buildдля запуска приложения).Space Invaders UI (запускайте локально с помощью
docker-compose up --buildили используйте проект из следующего пункта чтобы задеплоить в кубер).Конфигурация и деплой в Кубернетес
Обратите внимание, что эта репа предполагает, что у вас есть доступ к кластеру, который может выдержать ~200 новых подов.
И наконец, скриншот эмулятора в действии:

Обзор архитектуры
Картинка ниже описывает полную архитектурную модель в применении к автомату Space Invaders, ключевые компоненты затем обрисованы в дальнейших секциях.
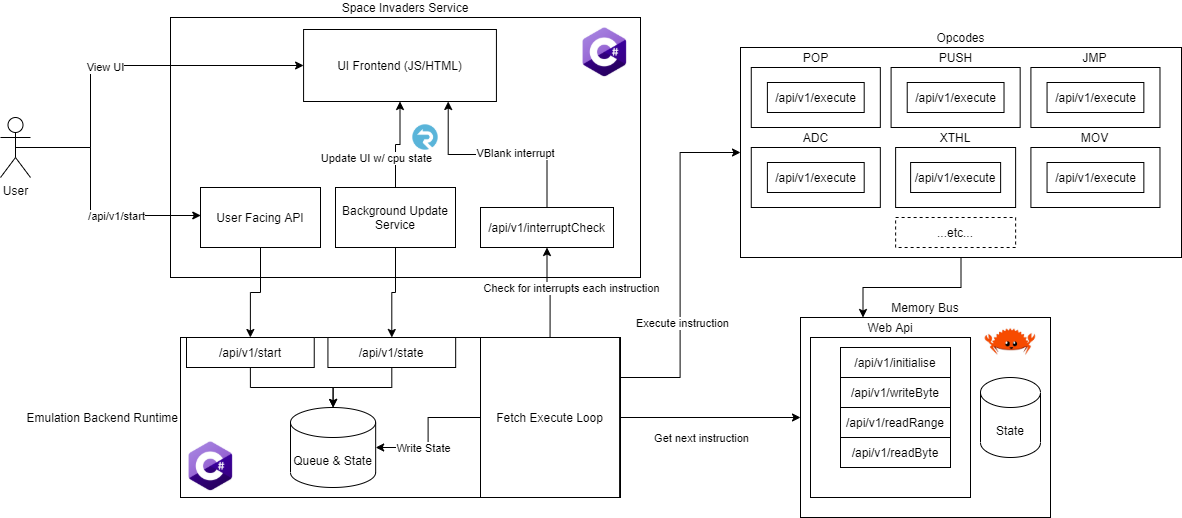
Основной цикл Fetch Execute
Все эмуляторы старой школы делятся на два лагеря: или они выполняют инструкции ЦПУ по одной и затем обновляют остальные компоненты или они обновляют все компоненты (включая ЦПУ) каждый такт. 8080 как он использован в автомате space invaders не нуждается в точной эмуляции по тактам, поэтому этот эмулятор использует первый вариант. Сервис Fetch Execute Loop (цикл Получить Выполнить) -- это сервис, который выполняет этот главный цикл и в целом выглядит следующим образом:
while true:
Call microservice to check if interrupts should occur
If so then run RST x instruction
Get next instruction from memory bus microservice
Call corresponding opcode microserviceЭто всё. Чтобы реально использовать этот микросервис мы ещё предоставляем команды `/api/v1/start` и `/api/v1/state`, которые запускают новый экземпляр процессора и получают статус текущего ЦПУ соответственно.
Микросервисы опкодов
Каждый опкод соответствует микросервису, который должен иметь POST апи `/api/v1/execute`, принимающий JSON такого формата:
{
"id": "uuid",
"opcode": 123, // Текущий опкод, чтобы разделять вызовы к разным командам, например, MOV (MOV B,C or MOV B,D)
"state": {
"a": 0,
"b": 0,
"c": 0,
"d": 0,
"e": 0,
"h": 0,
"l": 0,
"flags": {
"sign": false,
"zero": false,
"auxCarry": false,
"parity": false,
"carry": false,
},
"programCounter": 100,
"stackPointer": 1000,
"cyclesTaken": 2000,
"interruptsEnabled": false,
}
}Шина памяти
Шина памяти нужна, чтобы предоставлять постоянное хранилище для сервисов и должна иметь 4 роута для других сервисов:
/api/v1/readByte?id=${cpuId}&address=${u16}- прочитать один байт по переданному адресу/api/v1/writeByte?id=${cpuId}&address=${u16}&value=${u8}- записать один байт по переданному адресу/api/v1/readRange?id=${cpuId}&address=${u16}&length=${u16}- прочитать максимумlengthбайта начиная с адреса (то есть, к примеру, 3 байта которые соответствуют инструкции)/api/v1/initialise?id=${cpuId}- POST принимает base64 строку и использует её для инициализации памяти переданного ЦПУ
Тут простая и быстрая реализация, написанная на Rust с использованием высокотехнологичной in-memory базы данных. Альтернативные реализации с использованием постоянного хранилища оставлены как упражнение читателю. Самым лучшим вариантом скорее всего было бы использовать решение на базе блокчейна.
Сервис прерываний
Запуская сервис fetch execute loop вы можете по желанию указать (через переменную окружения) адрес сервиса проверки прерываний, который будет вызываться перед выполнением каждой инструкции. Этот API обязан принимать такой же JSON как сервисы опкодов и будет возвращать опциональное значение, которое показывает какую RST инструкцию нужно выполнить (или none, если прерываний не было).
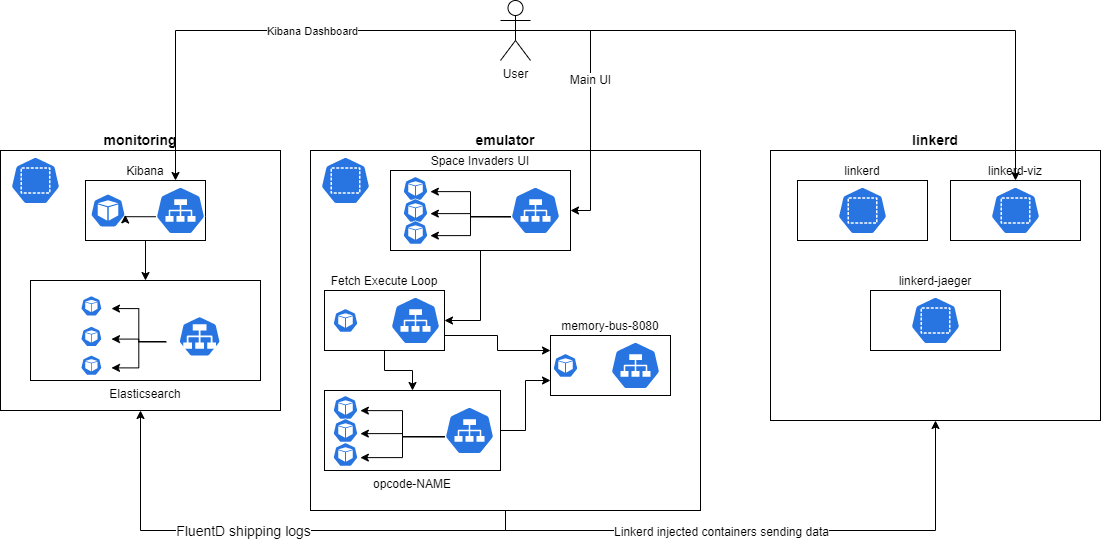
Архитектура развёртывания
Хотя приложение и можно запустить локально с помощью docker-compose, ни один уважающий себя архитектор облачных решений не будет довольствоваться этим из-за рисков связанных с использованием всего одной машины. Следовательно, этот проект также предоставляет чарт helm, который можно найти тут.
Имея этот репозиторий и достаточно большой кластер кубера (прим: мы настоятельно рекомендуем выбрать для этого топового облачного провайдера, такого как IBM), все компоненты можно установить просто запустив ./install.sh.
Архитектура кубернетеса описана в https://github.com/21st-century-emulation/space-invaders-kubernetes-infrastructure/blob/main/README.md, но для краткости ниже диаграмма:
Производительность
В современном дизайне систем всегда необходимо придерживаться модели "сначала заставить работать, затем сделать быстрее" и это то, что этот проект принимает близко к сердцу. В 1974 году, когда 8080 был выпущен, он достигал невероятных 8МГц. Наш новый, современный, контейнеризованный, облачный проект немного не дотягивает до этого с первой попытки. Как видно из скриншота выше, Space Invaders запущенная на кластере AKS работает со скоростью ~1КГц, что даёт нам кучу времени для отладки, но делает реальную игру слегка затруднительной.
Однако, теперь, когда приложение работает, мы можем посмотреть на оптимизацию и вот очевидные будущие пути для этого:
Переписать все на Расте. Как видно из картинки ниже, значительную часть времени занимают инструкции
LXIиPOP. Это понятно, ведьLXIнаписана на Java/Sping, аPOPна Scala/Play. Оба сервиса очевидно на порядок медленнее, чем все остальные языки.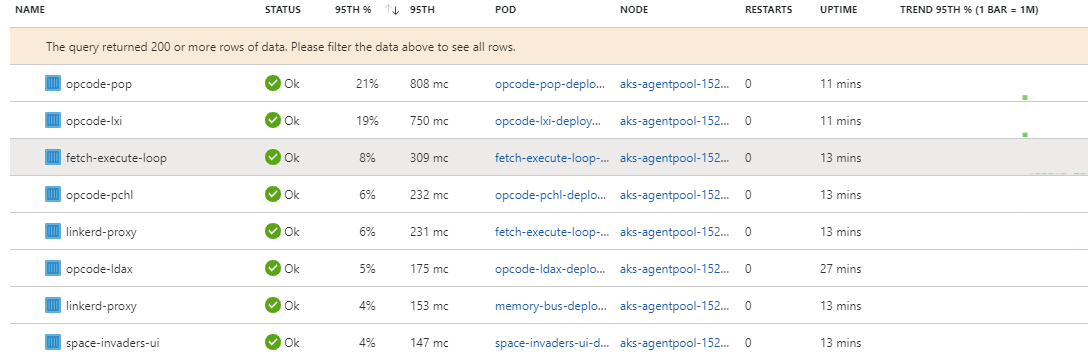
JSON -> Avro/Protobuf. Все знают, что сериализация/десериализация JSON слишком медленная для современных приложений, и использование более клёвого, бинарного и упакованного формата очевидно увеличит производительность.
Конвейеризация и спекулятивное выполнение
Небольшой буст можно получить если просто запускать до N следующий инструкций и сбрасывать конвейер на любой инструкции, которая изменяет счетчик инструкций. Это особенно шикарно, потому что приносит технологию из современных процессоров в древний 8080!
Так как внутри все операции асинхронные и ждут ввода-вывода, то мы может элементарно выполнять несколько инструкций в параллель, и дальнейшее улучшение будет следовательно спекулятивно выполнять инструкции и откатывать, если выполнение предыдущей повлияло бы на результат.
Кеши
Каждый раз ходить в шину памяти очень медленно, отметив какие инструкции могут изменять память, мы может действовать как современная виртуальная машина и кешировать память до момента записи, когда мы инвалидируем кеш и продолжаем. См. картинку ниже демонстрирующую количество запросов к
/api/v1/readRangeот цикла fetch execute (который использует этот API чтобы получить следующую инструкцию)

Подробности реализации
Одна из многих прекрасных вещей в микросервисной архитектуре -- благодаря тому, что вызовы функций это теперь HTTP поверх TCP, мы больше не ограничены одним языком в нашем окружении. Это позволяет нам реально воспользоваться лучшим, что современный http api подход предоставляет.
Следующая таблица показывает выбор языка для каждого опкода, как вы можете видеть, это позволяет получить преимущества безопасных операций с целыми числами в Rust, в то же время используя надёжность Deno для таких важных операций как CALL и RET.
Опкод | Язык | Описание | Размер образа | Производительность (средняя задержка) |
|---|---|---|---|---|
Swift | Moves data from one register to another | 257MB | 4.68ms | |
Javascript | Puts 8 bits into register, or memory | 118MB | 3.43ms | |
VB | Puts 8 bits at location Addr into A Register | 206MB | 4.56ms | |
C# | Stores 8 bits at location Addr | 206MB | 4.61ms | |
Typescript | Loads A register with 8 bits from location in BC or DE | 365MB | 6.22ms | |
Python | Stores A register at location in BC or DE | 59MB | 5.24ms | |
Ruby | Loads HL register with 16 bits found at Addr and Addr+1 | 898MB! | 13.63ms | |
Perl | Stores HL register contents at Addr and Addr+1 | 930MB! | 12.68ms | |
Java + Spring | Loads 16 bits into B,D,H, or SP | 415MB | 6.84ms | |
Lua | Puts 16 bits of BP onto stack SP=SP-2 | 385MB | 4.42ms | |
Scala + Play | Takes top of stack, puts it in RP SP=SP+2 | 761MB | 13.99ms | |
D | Exchanges HL with top of stack | 156MB | 26.54ms | |
F# | Puts contents of HL into SP (stack pointer) | 114MB | 3.25ms | |
Kotlin | Puts contents of HL into PC (program counter) [=JMP (HL)] | 445MB | 7.61ms | |
C++ | Exchanges HL and DE | 514MB | 2.16ms | |
Rust | Add accumulator and register/(HL) | 123MB | 1.95ms | |
Rust | Add accumulator and register/(HL) (with carry) | 123MB | 2.00ms | |
Rust | Add accumulator and immediate | 123MB | 2.16ms | |
Rust | Add accumulator and immediate (with carry) | 123MB | 2.22ms | |
Rust | Sub accumulator and register/(HL) | 123MB | 1.95ms | |
Rust | Sub accumulator and register/(HL) (with borrow) | 123MB | 1.70ms | |
Rust | Sub accumulator and immediate | 123MB | 2.15ms | |
Rust | Sub accumulator and immediate (with carry) | 123MB | 1.91ms | |
Rust | And accumulator and register/(HL) | 123MB | 2.68ms | |
Rust | And accumulator and immediate | 123MB | 1.93ms | |
Rust | Xor accumulator and register/(HL) | 123MB | 1.70ms | |
Rust | Xor accumulator and immediate | 123MB | 1.57ms | |
| Or accumulator and register/(HL) | 74MB | 11.36ms | |
Rust | Or accumulator and immediate | 123MB | 1.40ms | |
Rust | Decimal adjust accumulator | 123MB | 2.26ms | |
Rust | Compare accumulator and register/(HL) | 123MB | 1.70ms | |
Rust | Compare accumulator and immediate | 123MB | 1.90ms | |
PHP | Adds contents of register RP to contents of HL register | 430MB | 17.2 ms | |
Crystal | Increments register | 23MB | 1.98ms | |
Crystal | Decrements register | 23MB | 2.06ms | |
Crystal | Increments register pair | 23MB | 2.01ms | |
Crystal | Decrements register pair | 23MB | 1.99ms | |
Powershell | Unconditional Jump to location Addr | 294MB | 6.51ms | |
Deno | Unconditional Subroutine call to location Addr | 154MB | 6.04ms | |
Deno | Unconditional return from subroutine | 154MB | 6.43ms | |
Go | Rotate left carry | 6MB | 2.28ms | |
Go | Rotate right carry | 6MB | 2.19ms | |
Go | Rotate left accumulator | 6MB | 2.39ms | |
Go | Rotate right accumulator | 6MB | 2.29ms | |
IN | Data from Port placed in A register | |||
OUT | Data from A register placed in Port | |||
Haskell | Complement Carry Flag | 90MB | 2.50ms | |
Haskell | Complement A register | 90MB | 2.54ms | |
Haskell | Set Carry Flag = 1 | 90MB | 2.52ms | |
HLT | Halt CPU and wait for interrupt | |||
C | No operation | 70MB | 1.89ms | |
Dart | Disable Interrupts | 79MB | 2.37ms | |
Dart | Enable Interrupts | 79MB | 2.21ms | |
Deno | Call interrupt vector | 154MB | 7.34ms |
Nim немного припозднился на вечеринку, так что получил только один опкод, да и всё равно оказался медленным.
Подробности о коде
-------------------------------------------------------------------------------
Язык Файлов Строк Пустых Комментариев Сложность кода
-------------------------------------------------------------------------------
YAML 144 6873 859 396 5618 0
Dockerfile 112 2007 505 353 1149 248
JSON 106 15383 240 0 15143 0
Shell 64 2448 369 195 1884 257
Plain Text 59 404 171 0 233 0
Docker ignore 56 295 0 0 295 0
Markdown 56 545 165 0 380 0
gitignore 56 847 129 178 540 0
C# 35 1803 198 10 1595 51
TypeScript 22 1335 116 30 1189 275
Rust 18 1825 241 7 1577 79
TOML 18 245 20 0 225 0
Java 7 306 66 0 240 1
Haskell 6 207 24 0 183 0
Visual Basic 6 119 24 0 95 0
MSBuild 5 53 13 0 40 0
Crystal 4 330 68 4 258 5
Go 4 255 33 0 222 6
JavaScript 4 147 8 1 138 5
License 4 84 16 0 68 0
PHP 4 147 21 43 83 2
Swift 4 283 15 4 264 1
C++ 3 32 4 0 28 0
Emacs Lisp 3 12 0 0 12 0
Scala 3 112 15 0 97 6
XML 3 97 13 1 83 0
C Header 2 24 2 0 22 0
CSS 2 44 6 0 38 0
Dart 2 58 6 0 52 18
HTML 2 361 1 0 360 0
Lua 2 65 8 0 57 15
Properties File 2 2 1 0 1 0
C 1 63 8 0 55 18
CMake 1 68 10 15 43 4
D 1 71 6 2 63 14
F# 1 88 11 3 74 0
Gemfile 1 9 4 0 5 0
Gradle 1 32 4 0 28 0
Kotlin 1 40 9 0 31 0
Makefile 1 16 4 0 12 0
Nim 1 82 9 0 73 2
Perl 1 49 6 3 40 4
Powershell 1 78 9 0 69 10
Python 1 37 6 0 31 1
Ruby 1 28 6 0 22 0
SVG 1 3 0 0 3 0
TypeScript Typings 1 1 0 1 0 0
-------------------------------------------------------------------------------
Всего 833 37413 3449 1246 32718 1022
-------------------------------------------------------------------------------
Оценочная стоимость разработки $1,052,256
Оценочное время разработки 14.022330 месяцев
Оценочное количество людей 6.666796
-------------------------------------------------------------------------------
Обработано 1473797 байт, 1.474 мегабайт (SI)
-------------------------------------------------------------------------------Проблемы
Естественно, я столкнулся с множеством новых проблем с этим подходом. Я перечислил некоторые ниже, чтобы дать представление о типах проблем с этой архитектурой
Github Actions
Случайные таймауты логина в ghcr.io, случайные таймауты заливки образов. В целом просто всякие разные спонтанные ошибки. Это реально продемонстрировало как весело управлять системой разработки для микросервисной архитектуры.
Образа компилятора Haskell
Ох, блин. Haskell получает награду как мое самое нелюбимое окружение для разработки только за образ SDK размером абсурдные 3.5 гигабайта! Это достаточно много, чтобы было невозможно собирать сервисы на базе хаскеля в CI без тюнинга образа до 3.4 гигов (лимит github actions).
Случайные периодические ошибки сети в AKS
Хотя AKS и показал надёжность в четыре девятки для всех микросервисов, но там были спонтанные 504-ки между микросервисами.
С хороший стороны, так как мы использовали linkerd как сервис меш, чтобы получить безопасные подключения по TCP между микросервисами, это также позволило использовать его автоматические повторы и забыть об этой проблеме! Прямо как и положено в современной архитектуре!
Кеширование DNS (или нет)
Из всех языков, только у node.js были проблемы, когда она будет долбать DNS сервер натурально при каждом запросе, пока тот не сказал идинах и следующий запрос отвалился #justnodethings
Логи на большом масштабе
Сначала я поставил Loki как бэкенд для логов, потому что он новый и значит хороший, но потом обнаружил, что библиотеки C# для него периодически отправляют запросы не по порядку и в конце концов Loki сдается и просто перестаёт принимать логи. К счастью, fluentd всё ещё канает по духу проекта и по-настоящему привязывает проект к кубернетесу, так что это очевидно изначально было лучшим решением.
Оркестрация изменений между сервисами
Странно, но управлять ~50 репозиториями было лишь едва сложнее, чем одним. Изменять что-то, чтобы (скажем) добавить флаг
interruptsEnabledв ЦПУ нужно было одновременно по всем микросервисам. К счастью, я хорош в написании отвратительных скриптов на баше как и любой уважающий себя девопс инженер.
Неужели это на самом деле возможно?
Ок, если вы дочитали до сюда, то наверное уже догадались, что весь проект что-то типа шутки. Однако, это ещё и интересное умственное упражнение, чтобы оценить реально ли добиться >=2МГц с этой архитектурой.
Стартовая точка для достижения 2МГц: мы должны исполнять одну инструкцию за 2 микросекунды.
2MHz = 2,000,000 тактов в секунду
Каждая инструкция 4-17 тактов, так что нам нужно в худшем случае выполнять 2,000,000 / 4 = 500,000 инструкций в секунду.
Это даёт 1/500,000 seconds = ~2?s на операциюТо как реализовано сейчас даёт 3 вызова HTTP на инструкцию, один для получения инструкции, один для выполнения и один для проверки прерываний.
Предположим ради аргумента, что мы сделали такие оптимизации:
Уберём проверку прерываний с горячего пути
Кешируем весь ROM в сервисе fetch execute loop и предположим, что приложение исполняется из ROM (для Space Invaders так и было)
Это приводит нас к ~1 инструкции на операцию
Заменим JSON с кодировкой UTF8 на отправку массива байт для состояния ЦПУ
Это уменьшает размер запроса до ~256 байт и устраняет всю сериализацию/десериализацию (просто держим указатель на структуру указывающую на массив)
Тогда мы придём к хорошей начальной позиции с одним запросом для каждого опкода. Какая же минимальная стоимость запроса по сети?
Этот ответ из 2015 бенчмаркает локалхост и получает ~2 микросекунды с размером запроса <= 256 байт.
Предполагая, что тот чувак знает о чём говорит, то ответ конкретное нет. Мы никогда не получим требуемую задержку по сети (особенно учитывая так себе сети в облачных датасентрах).
Но давайте не будем сдавать. Мы уже совсем недалеко от требуемой скорости, так что можем постараться выжать нужные 2х.
Несколько мыслей по методам, как добиться этих последних 2х ускорения:
Запись в память по методу "выстрелил и забыл"
Записанное в память практически никогда не читается немедленно, так что пихаем команду в шину и не паримся с блокировкой пока она пишется. Может быть часть записей потеряется? Это нормально. Будь как Mongo. fsync для скучных сишников и современные разработчики не обязаны разбираться со всякими стрёмными сложными штуками типа CAP теоремы, в конце концов. Скорее всего кубер с этим разберётся за нас.
Мы можем выполнять множество операций в параллель и валидировать правильной результатов потом
Это очевидно ускорит операции, такие как
memsetкоторые делаются простыми алгоритмами типа `MVI (HL) d8 -> DCX HL -> JNZ` и каждая группа может выполняться параллельно.
Если бы каждый опкод знал следующую инструкцию то мы могли бы избежать второй половины каждого раундтрипа и не возвращаться к сервису `fetch execute loop`, пока поток инструкций не закончится.
Это практически гарантированное ускорение в 2 раза.
Выводы? Я думаю, это может быть возможно в каких-то идеальных условиях, предполагая почти нулевую задержку по сети, но я не собираюсь больше думать об этом!



HardWrMan
Забавно, но именно в i8080 команды RLC/RRC циклически сдвигают аккумулятор, а флаг C копирует старший/младший бит. А вот RAL/RAR циклически сдвигают аккумулятор через флаг C. А по названию мнемоники можно подумать, что это не так.