

Все мы знаем, что С++ — мощный язык, у которого много сторонников. Но чем могут быть недовольны даже сторонники? Где сталкиваешься с неудобствами и чем они вызваны? Почему в примитивном приложении могут вылезти неожиданные сложности и чего не хватает в стандартной библиотеке? А главное, что можно сделать для улучшения ситуации?
Антон Полухин (antoshkka), состоящий в комитете по стандартизации C++ и работающий в «Яндекс.Такси», рассказал обо всём этом в докладе «C++ на практике». Сам доклад появился ещё в 2019-м, и с выходом C++20 что-то изменилось, но главные тезисы и вывод остались актуальны. Поэтому теперь, готовя новую конференцию C++ Russia 2021, мы решили сделать для Хабра пост на основе этого доклада. Под катом — и текст, и видеозапись. Далее повествование идёт от лица Антона.
Вступление
Меня зовут Антон Полухин, я сотрудник компании «Яндекс.Такси». В свободное и рабочее время я занимаюсь развитием C++: разрабатываю Boost-библиотеки, провожу мастер-классы и читаю лекции о своём любимом языке программирования.
Сегодня мы поговорим о том, насколько приятно пользоваться C++ в повседневной жизни: рассмотрим два совершенно разных приложения и увидим всю боль, ужасы и приятности «плюсов».
В «Википедии» умные люди пишут, что C++ — это «компилируемый, статически типизированный язык программирования общего назначения». А это значит, что на нём можно писать практически всё, что угодно: и консольные вспомогательные утилиты, и игры, и Android-приложения, и поисковые движки! По крайней мере, так говорят. Давайте проверим.
Пример «Ёлочка»
Под Новый год знакомый скинул мне программу на Bash, которая выводила на экран ёлочку в ASCII-графике с красиво мигающими лампочками:
Насколько сложно написать то же самое на «плюсах»? У меня это заняло день. Но написание на Perl, Python или Bash отняло бы столько же времени и было бы чуть неприятнее.
Что собой представляет это мини-приложение? Ёлочка мигает, а при нажатии на клавишу меняется режим «гирлянды»: все лампочки становятся одного цвета.

Суперсерьёзная программа! Она занимает примерно 100 строчек кода, но даже тут есть некрасивости. Например, что происходит в этом блоке?
std::thread t([&lamp]() {
char c;
while (std::cin >> c) {
lamp.change_mode();
}
});Блок отвечает за управление лампочками, но это приходится делать в отдельном потоке, так как в C++ нельзя одновременно мигать лампочками и смотреть, нажал ли пользователь клавишу. Чтение из потока — блокирующее. Как только мы дошли до std::cin >> c, лампочки перестают мигать, поток останавливается, а мы ждём, когда пользователь нажмёт клавишу.
И чтобы обойти это, приходится создавать отдельный поток и там смотреть, когда же пользователь нажмёт кнопку. А еще внутри придётся воспользоваться атомиками.
Нам всего лишь хотелось нарисовать ёлочку в терминале, а тут внезапно вылезла многопоточность! Не очень приятно.
А вот и вторая неприятность:
std::ifstream ifs{ filename.c_str() };
std::string tree;
std::getline(ifs, tree, '\0');Есть файл с ASCII-графикой, и мы его никак не меняем — из него нужны только байты. Но в С++ нельзя работать с файлом как с массивом байт: придётся открыть поток, считать информацию из потока в контейнер (string или vector) и только тогда работать с этим контейнером.
Почему всё так криво?
Казалось бы, программа простая, почему же возникают такие сложности?
Круг задач, которые можно решать с помощью C++, очень широк. И за то, чтобы эти задачи можно было решать, отвечают вот эти люди:

Знакомьтесь — комитет по стандартизации языка C++. Они эксперты в своих областях: одни в машинном обучении, другие в компиляторах, третьи великолепно знают алгоритмы. Но есть маленькая проблема: все члены комитета находятся в круге задач, отвечающих за высокую производительность.
Если обозначить экспертов зелёными точками, область задач с высокой производительностью — чёрным кругом, а область всех задач, которые можно решать на C++ — жёлтым, ситуация выглядит так:

Так сложилось исторически.
Например, есть стартап, где мало денег и где код пишут как придётся. Со временем стартап ширится, развивается и через 20 лет вырастает в огромный монолит и конгломерат. И тогда компания задумывается о том, что хорошо бы влиять на тот язык программирования, на котором у них всё написано. Поэтому нужен человек, который хорошо разбирается в языке и преследует интересы компании — его-то и отправляют в комитет по стандартизации C++.
Так уж получается, что самые хардкорные C++ программисты занимаются самыми суровыми вещами — они редко читают вывод с клавиатуры или из файлика, а занимаются только тем местом, которое критично для всего приложения. Если программа на C++, значит, нужна высокая производительность. Поэтому человек из комитета и отвечает за высокую производительность.
Около двадцати лет назад в комитете было 20 человек, а теперь уже ближе к двумстам. И по-прежнему это люди, которые решают задачи, связанные с высокой производительностью.
А наша задача с ёлочкой помечена на картинке звёздочкой, и очень далека от целей комитета.

На примере этой программы мы видим, что несмотря на шероховатости, всё работает. А какие будут проблемы в приложении, требующем высокой производительности?
«Ява не тормозит»
В основе «Яндекс.Такси» лежит микросервисная архитектура. Если взять какой-то один сильно нагруженный сервис в отдельном дата-центре, то он будет обрабатывать где-то 20 000 сообщений в секунду. Что-то приходит в виде запроса, что-то он считывает, ищет на графе, обращается к базе и выдает ответ. Каждое такое событие нужно логировать, то есть записать информацию в файл. Один микросервис в отдельном дата-центре порождает 30 гигабайт логов в час, а в сумме все микросервисы генерируют в час больше терабайта логов и миллиарда событий.
Терабайты данных собираются со всех машин и отправляются в удалённое хранилище, где удаляются. Но перед удалением на них смотрят разработчики и менеджеры: находят интересные стратегии улучшения, какие-то несоответствия и то, на чём можно строить дальнейший бизнес.
Раньше для отправки таких сообщений мы использовали Logstash — популярное, бесплатное и открытое приложение, написанное на Java, которым пользуется огромное количество компаний.
Казалось бы, что может пойти не так?
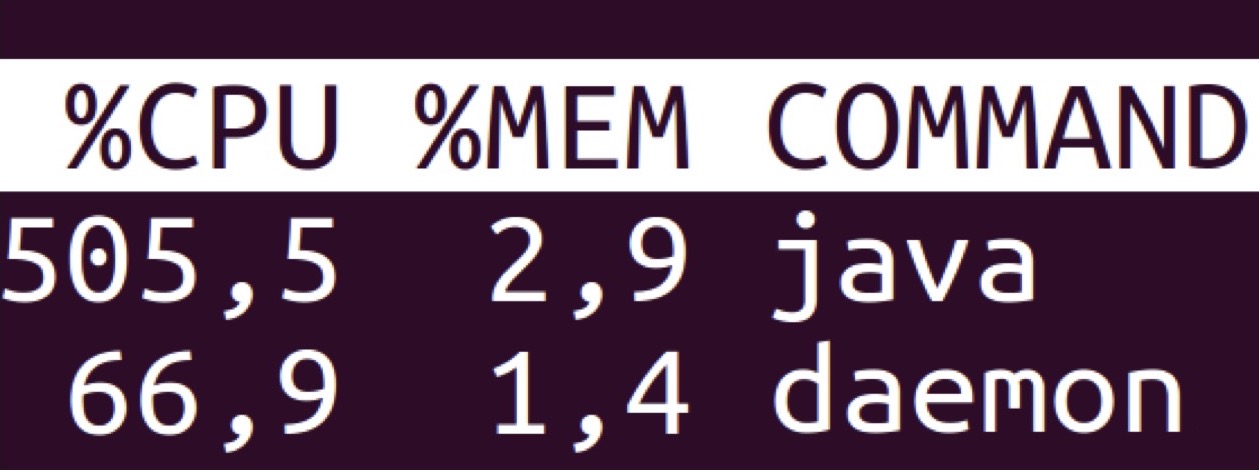
Демон — это то, что принимает запрос, обрабатывает его, обращается к удалённому хранилищу, получает ответ, что-то считает на графе, производит криптографические операции, пишет лог и отдаёт ответ. А Java — это Logstash, который просто отправляет этот лог в удалённое хранилище. При этом потребляет Logstash в два раза больше оперативной памяти и в девять раз больше ресурсов процессора.
Что тут происходит под капотом? Logstash делает следующее:
- Считывает данные с диска.
- Разбивает запись на ключ—значение.
- Применяет простые правила трансформации ключей и значений (например, меняет формат времени).
- Формирует запись в конечном формате.
- Отправляет запись в удалённое хранилище.
Вооружимся perf и натравим его на Java. Что мы видим? Logstash постоянно что-то сует в какие-то конкурентные ассоциативные контейнеры, в которых тратится огромное количество времени.
Для чего здесь вообще эти контейнеры? У нас ведь обычный пайплайн и простые правила по преобразованию логов, где по ключу и значению можно сразу понять, что там произошло и как это трансформировать. Нет никаких сложных правил, например, по разной обработке в зависимости от того, встретился ли до этого один ключ или другой.
Давайте сделаем свой Logstash без излишеств — шустрый, модный и современный. Для этого воспользуемся всеми доступными фишками C++17.
«Пилорама»
Представляю вашему вниманию «Пилораму». Почему такое название? Говоря по-английски, пилорама — это «factory in which logs are sawed». То есть что-то, что «пилит логи»! Вот и наша «Пилорама» пилит их и отправляет куда-то дальше.
Учтём ошибки Logstash и вместо трёх стадий с обменом контейнерами между ними (разделение на ключ—значение, применение правил, формирование записи) сделаем одну. Есть кусок данных, мы знаем, как преобразовать его в конечный формат, и никаких сложных промежуточных шагов не нужно.
Как мы это делаем? Данные приходят в виде std::string_view, то есть в виде указателя на кусок данных, над которыми нужно работать, и size_t — количества этих данных. Со string_view мы делаем следующее:
do {
const std::string key = GetKey();
if (state_ == State::kIncompleteRecord) {
// Stop parsing to let the producer write more data and finish the record.
return 0;
}
const utils::string_view value = GetValue();
if (state_ == State::kIncompleteRecord) {
return 0;
}
WriteWithFilters(writer, key, value);
} while (state_ == State::kParsing);Берём ключ, проверяем, нормальный ли он. Затем достаём значение и проверяем, пришло ли оно целиком. Записываем всё в выходной формат, применяя какие-то правила. Повторяем до тех пор, пока есть что разбирать.
Но для чего тут нужны две проверки?
«Пилорама» и основной демон работают в разных процессах. Основной демон может захотеть записать четыре с лишним килобайта логов, но успеет записать всего два, когда вклинится «Пилорама» и начнёт эти логи читать. В какой-то момент она заметит, что запись не готова целиком. Для таких случаев и нужны проверки.
С этой функцией конвертации получается более 360 тысяч записей в секунду, а это более 75 мегабайт данных в секунду. Итого больше 270 гигабайт логов в час. Таким образом можно держать 10 самых загруженных микросервисов на одном ядре «Пилорамы» или вообще все логи «Яндекс.Такси» на четырёх ядрах.
Честно говоря, когда я только написал этот конвертер и впервые запустил его, то был недоволен результатом: всего в 30 раз быстрее Java. Но потом я выспался и понял, что собирал всё в режиме отладки. Поэтому сейчас мы примерно в 100 раз быстрее Java, что более-менее приемлемо, но все равно недостаточно.
Почему так медленно? Вот вам немного нашей боли. В приложении есть конвертация данных и преобразование времён, а в C++17 для этого ничего нет. Поэтому приходится пользоваться сторонними библиотеками, например cctz. А эта «редиска» в цикле динамически аллоцирует память.
// Formats a std::tm using strftime(3).
void FormatTM(std::string* out, const std::string& fmt, const std::tm& tm)
{
for (int = 2; i !=32; i*=2) {
size_t buf_size = fmt.size() * i;
std::vector<char> buf(buf_size);
if (size_t len = strftime(&buf[0], buf_size, fmt.c_str(), &tm)) {
out->append(&buf[0], len);
return;
}
}
}Если это безобразие убрать и заменить на работу с датой/временем из C++20, то скорость конвертации увеличится практически в два раза.
С++ на практике
Теперь попробуем считать данные с диска. Стандартный подход в C++ — использовать стримы. Есть файл, с которым нужно что-то сделать. Мы открываем ifstream и даём ему команду читать из конкретного файла в определённый контейнер. Тот, в свою очередь, говорит операционной системе отдать какой-то файл. ОС не умеет работать напрямую с диском и записывать байты прямо с него в пользовательские буферы. Сначала ОС подтягивает большой кусок файла в оперативную память и уже оттуда копирует байты в нужный контейнер.
Такой способ работы с файлами — стандартный, но большинство современных ОС могут работать лучше. Операционная система сразу даст доступ к этому фрагменту памяти и работать с ним можно будет без всякого копирования.
Именно это делает boost::interprocess::mapped_region. Вы называете файл, с которым будете работать, оффсет и примерный требуемый размер. И boost::interprocess::mapped_region возвращает указатель на начало этих данных и размер, что отлично сочетается со string_view. Мы получаем указатель и размер, создаем от них string_view и отправляем на конвертацию. В итоге без всяких динамических аллокаций и промежуточных контейнеров получаем пайплайн, начиная с чтения файла до получения итогового формата. Осталось самое сложное — отправить данные в удалённое хранилище. Выглядит это так:
std::string result;
do {
AppendNewData(result);
if (result.size() < treshold) {
engine::SleepFor(1s);
continue;
}
SendToRemote(result);
result.clear();
} while (true);Здесь есть какой-то result и функция, которая читает данные с диска, конвертирует и добавляет их в result. Затем мы проверяем, что данных для отправки достаточно, и если их недостаточно, то засыпаем на секунду, а если достаточно, то отправляем их в удаленное хранилище.
Вы можете спросить: «Sleep в коде? Это точно высокопроизводительный сервис?» Если есть 100 файлов, значит, нужно 100 потоков, и все эти потоки иногда спят. Изредка им нужно резко пробудиться, что-то сделать и снова уснуть. ОС будет переключаться между этими потоками и пытаться угадать, какие и когда нужно разбудить. Если файлов 10 тысяч, то и потоков будет 10 тысяч, и тогда все станет ещё хуже: оперативная память будет съедаться, а операционная система — зашиваться. Выглядит не очень производительно.
Но устроено здесь всё хитро и функции engine::SleepFor() и SendToRemote()на самом деле асинхронные методы из нашего асинхронного фреймворка userver. Перепишем их с использованием Coroutines TS, и тогда к методам добавится co_await. В результате получим co_await engine::SleepFor() и co_await SendToRemote(result).
При вызове SleepFor происходит следующее. Есть поток, где выполняется этот код. Вызывается SleepFor, с потока снимается вся задача, весь стек откладывается в сторону. И в операционную систему передается обратный вызов, говорящий, что через секунду его можно перенести в очередь готовых задач. С потока сняли задачу, и он берет новую задачу из пула готовых. Таким образом, на одном потоке мы можем держать сотни и тысячи файлов, а код при этом будет выглядеть синхронным и линейным.
От пользователя полностью скрыто, что происходит под капотом. Можно просить программистов писать код максимально просто, а под капотом будет эффективная работа, о которой он даже не задумывался.
Аналогичным способом данные отправляются в удаленное хранилище, через асинхронный метод co_await SendToRemote().
Отправлять их по сетке может быть очень долго, поэтому мы говорим операционной системе: «Отправь эти сто тысяч мегабайт данных туда-то, а когда сделаешь это, вызови вот эту функцию». Тогда текущая задача снимается с выполнения, откладывается в сторону, а вызываемая функция помечает эту задачу как готовую к выполнению и переносит ее в очередь готовых к выполнению задач. Поток остался без задачи, и поэтому подхватывает ту, что готова к выполнению. И выполняет другую задачу.
Чего не хватает в C++
Некоторые вещи, которые хотелось бы использовать для этой задачи, появятся в C++20. Например, появятся таймзоны, тогда можно будет выкинуть cctz. Появится в С++23 flat_map — это как std::map, но намного эффективнее для небольших наборов данных. Там, где всего 10-20 элементов и количество данных расти не будет, отлично впишется flat_map. А еще в С++20 появится замечательная вещь — тип char8_t.
Казалось бы, две одинаковые функции, но вся разница в том, что в одном случае у нас unsigned char*, а в другом char8_t*:
void do_something(unsigned char* data, int& result)
{
result += data[0] - u8’0’;
result += data[1] - u8’0’;
}
void do_something(char8_t* data, int& result)
{
result += data[0] - u8’0’;
result += data[1] - u8’0’;
}Более того, размеры у них одинаковые и кажется, что компилятор должен превратить обе функции в идентичный ассемблерный код. Но нет:
Функция, принимающая char8_t* на треть короче. Почему?
Когда вы работаете с unsigned char*, char* или byte*, компилятор думает, что char* может указывать на все, что угодно: на integer, string или пользовательскую структуру. И когда компилятор видит, что на вход передается char* и что-то извне посылки, то думает, что любая модификация этой переменной может поменять те данные, на которые указывает char*. Это работает и в обратную сторону. Поэтому компилятор генерирует такой код, который лишний раз выгружает это из регистра в оперативную память (ну, если быть полностью корректным, в кеш процессора) и из неё подтягивает в регистр. В результате мы имеем лишние инструкции. В char8_t* можно такое убрать.
Но и в C++20 будет не всё. В С++ по-прежнему не хватает memory map: он нужен и для простых приложений, вроде нашей «Ёлочки», и для высоконагруженных. Предложение по mmap есть в комитете по стандартизации, и оно может быть принято в C++23.
Не хватает стандартной библиотеки побольше. У нас удалённое хранилище, но оно не неоптимальное: написано на Java и работает с JSON. А в С++, к сожалению, из коробки нет возможности работать с JSON. Также хочется Protobuf.
Ну и не хватает правильной работы с вводом/выводом. Есть networking TS, где под капотом используется библиотека Asio, и возможно, её добавят в C++23. Есть Boost.Beast, который работает с HTTP асинхронно — им сложно пользоваться, но код в итоге получается красивым. И есть библиотека AFIO, которая позволяет асинхронно работать с файловой системой и может сказать ОС: «Когда в этой директории появится новый файлик, вызови эту функцию». А там просыпается какая-то корутина и начинает делать с файликом что-то полезное. К несчастью, AFIO — это прототип, работающий, но не быстро.
Что можете сделать лично вы?
Мы рассмотрели два приложения, в каждом из которых есть шероховатости. В случае второго приложения большинство этих недочетов исправят в C++20, но «осадочек остался». Ведь, наверное, с подобными проблемами встречаюсь в разработке не только я. И скорее всего, у разных людей «шероховатости» разные. Что в связи с этим делать?
В комитете по стандартизации хотелось бы видеть больше людей. Причём из разных областей, не обязательно из области высокой производительности. Нужны люди из стартапов, которые будут говорить, где им становится неудобно в начале работы над приложением. Нужны люди из академического мира. В комитете есть преподающие профессора, которые могут рассказать, где студенты стреляют себе в ноги. И с задних рядов слышен голос: «Да-да, я эксперт, и я тоже себе в этом месте ногу отстрелил».
Также требуются люди из тех областей, где C++ не популярен или вообще не используется. Хорошо, если в комитете будет сидеть матерый разработчик embedded-железок, слушать о том, как механизм исключений уместили в 200 байт, и говорить: «А у нас всего 128 байт (нет, не килобайт), думайте дальше».
Если вам что-то не нравится в C++ и вы хотите это улучшить или донести свою боль до комитета по стандартизации, начните с сайта stdcpp.ru. Там люди обмениваются мыслями, желаниями и проблемами, связанными с развитием языка C++. Идеи обсуждаются, обрабатываются и некоторые из них становятся официальными предложениями для международного комитета. При этом рук не хватает, поэтому особенно ценная помощь — когда человек готов не только генерировать идеи, но и браться за написание предложений к ним (хотя бы черновиков).
Драматичным шёпотом: и таким человеком может стать каждый из вас!
Если оптимизация программ на С++ для вас не пустой звук, обратите внимание на C++ Russia 2021, где будет много всего интересного. Конференция пройдёт с 15 по 18 ноября 2021, информация и билеты на сайте.
Комментарии (168)

agalakhov
15.07.2021 13:49+9Главная проблема C++ в том, что людей, умеющих на нем писать, очень мало. Чаще всего приходится видеть такой код, что прямо кровь из глаз.

PyerK
15.07.2021 16:05-2Для поиска специалистов, Вам стоит обратить внимание на Киев.
В Киеве, на зарплату чистыми 5-6к usd воронка кандидатов умеющих писать на с++ превышает пропускную способность собеседующего.Вакансии закрываются быстро. Тоже самое и с вакансиями на с++, их тут очень много, работу можно найти практически в любой сфере, которая нравится.
agalakhov
15.07.2021 19:25+2Дело не в наших специалистах, а в коде, написанном третьими лицами, сторонних библиотеках. Что не STL и не за авторством FAANG, то чаще всего кошмарно.

iroln
16.07.2021 14:06+4Почти любой код на C++ вызывает кровь из глаз. Разве не так? :)
Что не STL и не за авторством FAANG
Как будто на код из STL или, например, Boost не больно смотреть. Любое метапрограммирование вызывает кровь из глаз. Лучше уж на "C с классами писать". :)
У Google неплохой Code Style Guide, многое запрещает. Но в любом случае, этому языку уже ничего не поможет, а стандарт от редакции к редакции будет пухнуть, пухнуть и пухнуть. А вместе со стандартом будут пухнуть головы разработчиков, а тех, кто умеет писать будет всё меньше и меньше.

Door
15.07.2021 14:17-2std::thread t([&lamp]() { char c; while (std::cin >> c) { lamp.change_mode(); } });Хммм, мне кажется здесь дата рейс ? std::cin связан с std::cout. Нужно делать что-то типа cin.tie(nullptr), наверное.

mayorovp
15.07.2021 15:01Э-э-э, а как он связан?
Door
15.07.2021 15:17+1Я так понимаю std::cin вызывает flush для std::cout - https://en.cppreference.com/w/cpp/io/basic_ios/tie
that is, flush() is called on the tied stream before any input/output operation on *this

antoshkka
15.07.2021 17:34Data race не возникнет, гарантируется стандартом: http://eel.is/c++draft/iostream.objects#overview-7
Door
15.07.2021 17:42Охх, т.е., sync_with_stdio(true) делает больше чем "синхронизирует standard C streams". Спасибо.

alecv
15.07.2021 18:36В случае с терминалом проблема глубже. Абрстракция 'потока' плюсов не очень хорошо совместима с абстракцией 'терминала' Unix. Да, абстракции немного пересекаются (и это позволяет с натяжкой считать std::cin потоком), но терминал - это не просто поток, он может делать намного больше, см. termio/termios/tty_ioctl (на этом построен, например, job control в юниксовых CLI и т.д.). По идее, вам надо использовать неблокирующий non-canonic input режим терминала. Но насколько помню, у плюсов такого функционала нету, придется использовать POSIX-совместимые вызовы.

SpiderEkb
15.07.2021 20:43+1Ну естественно у плюсов такого нету… Тут надо глубже смотреть. Помнится в досе в сишной библиотеке была волшебная функция kbhit() которая проверяла есть ли что-то в буфере клавиатуры. И там все было просто —
if (kbhit()) ch = getch();
Т.е. если в буфере клавиатуры что-то есть — читаем оттуда. Нет — идем дальше.
Уверен, что для никсового терминала можно аналогичное найти.
Но это же не по плюсовому…mayorovp
26.07.2021 00:24Тут есть ещё одна проблема — проверка
kbhit()в цикле лишь съест процессорное время. Поток не должен гонять цикл, поток должен ждать — вот только ждать придётся, в большинстве программ, появления символа в консоли ИЛИ другого события. В итоге всё опять сводится к абстракции над epoll/IOCP, которой в языке нету.Ждём Networking TS, может после её принятия и появится нормальный консольный ввод через какое-то время…

alexxisr
30.08.2021 14:56Но в елочке мы же все равно гоняем цикл, чтобы обновлять лампочки. В конце каждого цикла проверить клавиатуру — если кнопка нажималась за последний кадр, то в следующем кадре рисуем поновому.

kovserg
15.07.2021 19:25-9Главная проблема в C++ что в него постоянно запихивают грабли
int fn() { int x; return x || !x; }
Например почему clang с чистой совестью возвращает из fn 0. Почему стандарт ему позволяет такое делать?kovserg
15.07.2021 21:07-5И чего молча минусуем clang 5-12. Что сказать нечего?

KanuTaH
15.07.2021 21:17+8А что здесь нужно сказать? Чтение значения из неинициализированной переменной - UB. Clang может возвращать и 0, и 42, и 322, он в своём праве. Неудивительно, что вас минусуют.
kovserg
15.07.2021 21:32-4А вас ничего не смущает. Не инициализированная переменная может иметь одно из 2^32 (если int 32bit) значений при любом возможном значении результат работы функции 1. Но clang выбирает наименее часто встречающийся (а именно 0 раз) вариант и бодро возвращает 0, не 42 и не 322 которые тоже 0 раз встречаются во всех возможных исходах. Правила формальной логики можно смело выкидывать — устарели видимо. Так?
KanuTaH
15.07.2021 22:19+6Нет, не смущает. Например, нет никаких гарантий, что при последовательных чтениях из неинициализированной переменной будет возвращаться одинаковый результат. Это же UB, может происходить все, что угодно.
kovserg
15.07.2021 22:28-3«Нет не смущает это же UB» — так сказал Хэнк, а правила логики лесом

movl
15.07.2021 23:48-4Зачем вы пытаетесь обосновать какую-то необходимость некоторого свойства современных языков программирования и автоматов, какими-то правилами, записанными еще древними? Это же и есть проявление истинного прескриптивизма, в котором вы хотите уличить оппонента. Современную алгебру уже достаточно давно не так сильно интересует сама форма отношений, сколько форма отношений выраженных во времени. И в такой постановке, нам никто не завещал, что третьего не дано.
kovserg
16.07.2021 00:02-3Зачем вы пытаетесь обосновать, бардак и не согласованность? И зачем эти магические модели и ритуалы оторванные от реального железа? Вы правда не видите к каким это может привести последствиям на практике?
Если у вас что-то меняется со временем то это следует указывать явно. например есть модификатор volatile. Но тут явное нарушение всех правил. При это всегда находятся люди которые как сектанты с пеной у рта будут доказывать что это правильно, «потому чтотак сказал Хэнкэто UB» илуна из зеленого сыракомпилятор должен сгенерировать максимальноеб@#&тыйне логичный код.Ведь Хэнк всегда правСмотрите стандарт.
mayorovp
16.07.2021 00:46+3Вот как раз правила логики и позволяют программе так вести себя. Утверждение "произошло UB" всегда ложно, это аксиома. А из лжи следует что угодно.
movl
16.07.2021 10:23-2А в чем здесь аксиома?
То есть конечно мы можем формально высказать какое-то абстрактное, если для undefined(x) существует definition(x), то undefined(x) устраняется. При этом под definition(x) тут формально подходит любая отсылка к undefined(x), что выполняется априорно в момент описания undefind(x) в спецификации. Но без индукции, выходящей за пределы классической логики - это не аксиома логики, это определение абсурда.
Думаю, тут все сильно проще можно попробовать объяснить: спецификация сообщает о том как обеспечить совместимость, и где воспользоваться свободным пространством для внедрения произвольного кода. Про цель предоставить свободу компиляторам, есть в спецификации. Компиляторы сосредоточиваются на оптимизациях, плюс дают низкоуровневые интерфейсы программистам. Программисты пишут эффективный код под железо. Статья как раз о цене, за все это. А тред о том, что маленькая формальность, не может является значимой в сложившейся ситуации. И это ни разу не является утверждением привлекательности C++.mayorovp
16.07.2021 12:47+3Это одно из определений UB — UB никогда не присутствует в корректной программе (а поведение некорректной программы нас не интересует). Поэтому утверждение "произошло UB" всегда ложно.
movl
16.07.2021 14:58Так-то да, вполне логично. Я что-то совсем не в ту степь пошел, и пытался примерить тезис к тому как доказать, что программа корректно скомпилируется. И соответственно "произошло UB" принял за подстановку требуемых конструкций в итоговый файл, а не за их выполнение. В таком случае корректность компиляции, видимо должна доказываться, ее успешным завершением, но что-то мне кажется, что там не все так просто.
Спасибо за разъяснение. Захотелось теперь попробовать написать компилятор, как раз можно будет приспособить к ассемблеру, который где-то у меня валяется.

PkXwmpgN
16.07.2021 13:33Хм, интересно, кажется clang ничего не выбирает вообще и не анализирует как используется переменная (правила формальной логики), анализатор говорит что это просто:
Branch condition evaluates to a garbage value
и дальше с этим ничего не делается, а просто считается false (имеет право, потому что UB). Судя по всему в версия 4.0.1 и еще в 5.0.0 с этим были баги
https://godbolt.org/z/EPd37cjfW
<source>:4:38: warning: Branch condition evaluates to a garbage value int check_compiler() { int i; return i || !i; } ^ <source>:5:39: warning: Branch condition evaluates to a garbage value int check_compiler1() { int i; return !i || i; } ^~ <source>:10:7: warning: Branch condition evaluates to a garbage value if (x) // expected-warning{{Branch condition evaluates to a garbage value}} ^ <source>:17:10: warning: Branch condition evaluates to a garbage value return x ? 1 : 0; // expected-warning{{Branch condition evaluates to a garbage value}} ^ 4 warnings generated.
movl
15.07.2021 21:33+2Так он может и 1 вернуть. Позволяет, потому что подразумевается, что программа работает не с лексикой языка, а с ячейками памяти, или вообще с реле какими-нибудь. С таким же успехом грабли про "быть или не быть" можно и у Шекспира поискать.
kovserg
15.07.2021 21:44-3Так почему не возвращает? И главное почему такое поведение поощряет стандарт?
movl
15.07.2021 21:51+3В стандарте ясно сказано, что поведение таких переменных не определенно. Компилятор что хочет, то делает с ними. Чтобы ее инициализировать, необходимо присваивание. Причины, очевидно, в оптимизациях.
kovserg
15.07.2021 22:20-2Значение функции не зависит от переменной. Оно при любых допустимых значениях равно 1.
x or not x = 1 всегда независимо от x
Или вы можете привести контрпример? Так притензии именно к стандарту что именно он порождает такой бардак, который ставит под сомнение применение «С++ на практике».movl
15.07.2021 22:41Неопределенным поведением не решалась проблема лексики. Этим решались проблемы чтения/записи, ввода/вывода, срабатывание на прерывания, перепайки проводов на стендах и все прочего, что не относится к формальной логике.
http://www.open-std.org/jtc1/sc22/wg14/www/docs/n1570.pdf
В стандарте есть примерно 100500 уточнений, что неопределенное поведение, это значит неопределенное поведение.

DerRotBaron
15.07.2021 22:44Проблема а том, что ваш код не на корректном c++. А в неопределённом расширении c++, код на котором вы привели, это вполне возможно т.к. там логические операции могут быть определены с исключениями
kovserg
15.07.2021 22:57+1Тогда почему он возвращается 0, а не исключение? Исключение не разрушает логику, в то время как 0 разрушает.
DerRotBaron
16.07.2021 00:03Потому, что выкидывать исключения из кода, который вам настолько не важен, что вы его решили написать не на плюсах, вообще говоря безумие.
А 0 скорее всего вывелся как результат `undefined && !undefined = undefined` с преобразованием у нулю в конце. Вполне корректная конструкция для работы с некорректным кодом, ведь так любую цепочку вычислений можно свести до бесплатной в рантайме константы. И для ннпривязанного никуда int это будет 0.
kovserg
16.07.2021 00:28-2А ничего что вы, на ровном месте, порождаете сущность не предстваимую данным типом данных. Вас это не смущает? Почему не double(3.14) не комплексную единицу или вообще контекст потока? Почему undefined -> int не равно throw exception? Почему выбрали undefined -> 0 — это явное нарушение логики.
Тут такая же ущербная логика?unsigned inc(unsigned x) { unsigned u; return 1u+x+u-u; }
ps: «вы его решили написать не на плюсах» — почему на этапе компиляции компилятор не сообщил что это не C++, а «вообще говоря безумие».DerRotBaron
16.07.2021 00:38+2Почему undefined -> int не равно throw exception?
Потому, что это сломается в большем количестве мест, чем вы ожидаете
Почему выбрали undefined -> 0 — это явное нарушение логики.
Вы ожидаете, что undefined подчиняется правилам арифметики целых чисел? Но же бессмысленно, если речь идёт о потенциально некорректном коде.
И вообще радуйтесь, что у вас 0, а не `rm -rf /`
kovserg
16.07.2021 11:09-3Еще раз. Тут логическая ошибка в компиляторе. Он успользует не верные предпосылки, на основе которых делает абсолютне не верные выводы. И это стандарт считает нормальным. — Вы слепые?
x=undefined
y=undefined
Так вот во первых эти undefined разные, во вторых они могут быть разных типов и в третьих для них справедливы математические операции которые используют эти типы, не смотря на то что они undefined
int x=undefined
x*0=0
0*x=0
x-x=0
x||!x=1
x==x
int y=undefined
x и y это разные undefined
Тут же просто всё упростили в ввели обычный «undefined» которые ни типа ни операций не имеет.
Даже банально засунуть несколько случайных чисел и провести расчет, то можно получить более вменяемый результат.
Те кто пишет стандарты, вы какие наркотики используете, что бы это не замечать? Какой может быть практика использования C++ если у вас нет комилятор использует не консистентую математику. И нет иструмента который может сказать что программа будет испорчена компилятором, потому где-то в недрах был UB. И после этого это язык программирования?
И самое главное все ошибки компилятора списываютсяпод ковёрна UB.
ibrin
16.07.2021 12:56-3Погодите, а чего это ваш рандомный целочисленный undefined какого-то разного неопределенного типа? Этож 4х-байтовый целочисленный undefined! Просто память под переменную выделяется без очистки. Считайте, что там просто целочисленный рандом.

Chaos_Optima
16.07.2021 13:48+1Это всё по вашей логике которую вы хотели бы видеть, но в чужой монастырь так сказать.
Вы хотитеint x=undefined
x*0=0
0*x=0
x-x=0
x||!x=1
x==x
а по факту (что я считаю имеет смысл)int x=undefined
x*0=undefined
0*x=undefined
x-x=undefined
x||!x=undefined
x==x = undefined
Любое взаимодействие с undefined должно приводить результат к undefined
undefined != random numberkovserg
16.07.2021 21:08-4По факту это детская ошибка. Сделанная гуманитарием, слабо понимающий математику. И вообще не понимающего последствий сделанного.
Вот что происходит. Всё банально до ужаса.
int x;
Значение x определяется как специальное значение undefined.
Дальше веселей для undefined введён ряд операций
например: godbolt.org/z/YMqz3hxzd
undefined&0=0
undefined|x=-1 (если x!=0)
undefined*0=0
0*undefined=0
undefined -> int -> no_value или 0 как повезет
value + undefined = undefined
undefined==undefined — false
undefined!=undefined — false
undefined<=undefined — false
undefined>=undefined — false
undefined+undefined = undefined
undefined-undefined = undefined
undefined*x = undefined — где x!=0
и еще куча несуразицы.
И компилятор имея эту мякоть взятую с потолка не проверенную и не согласованную (ничего общего не имеющей со здравым смыслом, математикой и тем что происходит в железе). Выполняет преобразования по этим правилам. Результат предсказуем получается лютая хрень, в зависимости от порядка действий. Но исправлятьленьне хочется, поэтому договорились этот(у)багфичу списывать на UB и все кто в это не верит — еретики и нечего не понимают.
Так что не надо говорить о высоких материях, что это не коректная программа на C++. Это банально баг компилятора и ошибка в логике преобразований.
ps: Смотрю тут как-то мало истенно верующих в стандарт. Хэнк негодует. Как-то вяло минусуете. Еще раз такой стандарт который оправдывает такие тупые и примитивные ошибки (которые столько времени в поде) нахрен не нужен, более того он вреден, тем более платный. Выза#6&тесьустаните отлавливать подобные хитро спрятанные UB в большой кодовой базе.

Antervis
17.07.2021 08:43+2Так вот во первых эти undefined разные, во вторых они могут быть разных типов и в третьих для них справедливы математические операции которые используют эти типы, не смотря на то что они undefined
Те кто пишет стандарты, вы какие наркотики используете, что бы это не замечать? Какой может быть практика использования C++ если у вас нет комилятор использует не консистентую математику.
ознакомьтесь например с арифметикой над NaN по IEEE754, оно полностью попадает под ваше определение
Imobile
17.07.2021 15:41+1Это все-равно что сунуть вилку в розетку, а потом спорить что должно случиться, сгореть проводка, выбить предохранители или ударить током :) Для меня было бы ошибкой более медленная работа на валидацию и прочее в рантайм...

Racheengel
15.07.2021 22:37Неинициализированная переменная получит значение в рантайме, а не при компиляции. Просто это значение может быть произвольным, т.к. во время компиляции компилятору ничего не известно о содержимом стека или регистров. Следуя формальной логике и правилам языка С, результат выражения x || !x вообще не зависит от х и должен быть всегда равен true. В этом случае компилятор может оптимизировать локальную переменную, убрав её полностью. И заменить результат выражения константой времени компиляции. Поэтому функция должна вернуть значение, отличное от 0 (пусть и не обязательно 1).
movl
15.07.2021 22:51+1Чтение из неинициализированной переменной приведет к неопределенному поведению, это ясно сказано в стандарте. Да и с чего вы вообще решили, что все реализации компилятора обязаны что либо знать о стеке или регистрах?
ibrin
16.07.2021 13:04-5Кстати, а UB же не значит, что вообще всё что угодно может произойти. UB для неинициализированной переменной не приведет к неопределенному изменению потока выполнения, а всего лишь к неопределенному значению переменной при первом обращении.
mayorovp
16.07.2021 13:27+4Именно это UB и означает, что произойти может что угодно.
ibrin
16.07.2021 13:35-4Я отказываюсь в это верить. Куда машинный код катится...
mayorovp
16.07.2021 13:38+2К сожалению, корректность программы не является вопросом веры.
ibrin
16.07.2021 15:03-4Практика ISO C++ 14 Std, MSVS2019 (v142)!
int main() { int i; i++; printf("%d\n", i); }
Дизассемблер:
int i; i++;012D2125 mov eax,dword ptr [i]
012D2128 add eax,1
012D212B mov dword ptr [i],eax
printf("%d\n", i);Результат: -858993459
int main() { int i=666; i++; printf("%d\n", i); }
Дизассемблер:int i=666;
003A2125 mov dword ptr [i],29Ah
i++;
003A212C mov eax,dword ptr [i]
003A212F add eax,1
003A2132 mov dword ptr [i],eax
printf("%d\n", i);Результат: 667
Я же говорю, всё нормально будет!
ibrin
16.07.2021 15:16-4К тому, что UB для неинициализированной переменной не приведет к неопределенному изменению потока выполнения, а всего лишь к неопределенному значению переменной при первом обращении.
mayorovp
16.07.2021 15:19+6Но вы этого не доказали. Вы просто продемонстрировали что иногда неопределённое поведение совпадает с вашими ожиданиями.
ibrin
16.07.2021 15:34-2Ну на самом деле, если программист хочет посмотреть, что в памяти до инициализации, он должен иметь вариант не инициализировать переменные!
ibrin
16.07.2021 15:58+1Мы можем быть не очень счастливы от такого поведения компилятора, поскольку его предположения на счёт вывода реального значения указателя на функцию оказались ошибочными. Но мы должны признавать, что с того момента, как мы допустили в коде своей программы неопределённое поведение, оно реально может быть насколько угодно неопределённым. https://m.habr.com/en/company/infopulse/blog/338812/
Фигово, чо...
ibrin
16.07.2021 15:49-1Плохо, что clang все соптимизировал к xor eax,eax.
Мой вариант такой...
00F61EA5 cmp dword ptr [x],0
00F61EA9 jne __$EncStackInitStart+31h (0F61EBDh)
00F61EAB cmp dword ptr [x],0
00F61EAF je __$EncStackInitStart+31h (0F61EBDh)
00F61EB1 mov dword ptr [ebp-0D0h],0
00F61EBB jmp __$EncStackInitStart+3Bh (0F61EC7h)
00F61EBD mov dword ptr [ebp-0D0h],1
00F61EC7 mov eax,dword ptr [ebp-0D0h]
Результат: 1
DerRotBaron
16.07.2021 00:10+1Следуя формальной логике компилятор может оптимизировать UB. В данном случае проще всего вывести неопределенный результат операции как 0, вероятно, как int по умолчанию. В каком-то другом случае оптимальным может быть что-то иное
Racheengel
16.07.2021 11:06-2В приведенном по ссылке примере как раз показано некорректное поведение конкретного компилятора, который заменил явную инструкцию (перейти по адресу 0) неявной, вместо того, чтобы выдать предупреждение и остановить компиляцию.
В примере из комментария примерно такое же неверное поведение компилятора. результат выражения x || !x для параметра типа int по правилам языка от х не зависит вообще. Поэтому корректно будет либо выдать ошибку, либо выполнить оптимизацию в виде return int(true), что для int вернёт число, отличное от 0. Локальная переменная в этом случае смысла вообще не имеет и может быть редуцирована.
mayorovp
16.07.2021 13:37+5Компилятор действовал в соответствии со стандартом языка.
Если стандарт языка не совпадает с вашими "хотелками" — это не означает что компилятор плохой, это означает что плохой язык (для вас). Просто пишите на другом языке если не желаете подобных "сюрпризов".
Racheengel
16.07.2021 14:08-3Думаю, вы не понимаете разницы между неопределенным и некорректным поведением. Вызов по адресу 0 - это UB, которое приведёт, как правило, к падению программы. Вызов вместо этого произвольной функции не по адресу 0 - это именно вольное трактование стандарта, что не допустимо. Это поведение некорректно. Как минимум должно быть выдано сообщение об ошибке, чего данный компилятор не сделал.
mayorovp
16.07.2021 14:13+4Нет, это вы не понимаете что такое неопределённое поведение. Оно и в самом деле никак не определено, произойти (согласно стандарту) может что угодно.
Не бывает корректного и некорректного неопределённого поведения.
ibrin
19.07.2021 04:55Но, блин, этож неинициализированная переменная, а не какой нибудь класс без инстанса! Переменную объявили, память на стеке под неё выделили, но никаким определенным значением не инициализировали! У неё даже адрес есть! Почему бы не работать с ней, выражение не посчитать до конца? Вот зачем в стандарте под неё специально было логику ломать через UB? А если пойти дальше, учитывая стандарт, то неопределенная оптимизация с неинициализированной переменной не имеет смысла, т.к. ломает логику, лучше уж сразу сегфолт кидать.
mayorovp
19.07.2021 11:14А с чего вы взяли, что у ней адрес есть? Нет такого правила, которое бы заставило компилятор резервировать память под каждую переменную.
ibrin
19.07.2021 12:42-1Первое же обращение и должно триггерить резервирование памяти, независимо от того, чтение это или запись. Но нет. Я понимаю, UB требуется для целей оптимизации, чтобы можно было оптимизировать хоть до NOP. Ну и ладно.
mayorovp
19.07.2021 15:59+2С чего бы обращение к переменной должно что-то там триггерить?
Возьмём вот такую программу:
int foo(int x, int y) { int z = x+y; return z; }Переменная
zтут локальная? Да. Обращение к ней есть? Есть. Память под неё выделять нужно? Нет, не нужно.
ibrin
20.07.2021 10:24-2В примере память под z не пригодилась и её можно не выделять, а в примере с UB память пригодилась - читать-то надо откуда-то!
ibrin
20.07.2021 15:07-2Но у нас же оптимизирующий компилятор, если читаем и выходим, то даже не пишем и, тем более, не храним, сразу результат на foo и на выход. А с UB, переменную нужно выделить, т.к. читать приходится полюбому и пользоваться содержимым в дальнейших вычислениях.
ibrin
21.07.2021 15:18-1Ну, конечно! Это всего лишь моё переосмысление UB. Я же не настоящий программист - промавтоматика :D
Racheengel
23.07.2021 00:58-1То есть вы согласны, что если вы допустите опечатку в коде, не инициализировав явно какую либо переменную, то компилятор имеет право вызвать Format c:/ на вашей машине, со всеми вытекающими? Это тоже будет соответствовать стандарту? UB ж, что хочу, то и вызываю, так?

dvserg
16.07.2021 14:32А если посмотреть очень строго, то применение логических операций к арифметическим типам напрямую невозможно. Всегда следует скрытое преобразование типа, в данном случае (int) в (bool).
Для сравнения можно попробовать исходный пример с булевым типом.

Playa
15.07.2021 22:38-1auto buf = std::unique_ptr<uint8_t>(new uint8_t[10 * 1024 * 1024]);Тоже предлагаете нулями инициализировать?
kovserg
15.07.2021 22:51+1Да, всё инициализировать нулями пока не сказано обратное.
Вот nullptr ввели, что мешает ввести noinit.auto buf = std::unique_ptr<uint8_t>(new<std::noinit> uint8_t[10 * 1024 * 1024]);
ps: И главное. Антон вот на этом моменте www.youtube.com/watch?v=g2iyNH2Gh1k&t=1257s говорит очень интересную вещь, при этом, он даже не поморщился. «Казалось бы — но нет». Нет надо вхардкоидить оптимизации для конкретных типов char и int8_t. Где логика? А точно, меморимапа не хватает же.
Вот что мешает ввести явные модификаторы работы с целыми числами помимо restrict, short и longmodular int
saturated int
overflow_check int
И убрать эти UB
knstqq
16.07.2021 11:05-1Никто не будет писать просто так без причин «overflow_check int» вместо каждого «int» как здесь и в тысяче других мест: `for (overflow_check int i = 0; i < n; ++i)`. А где будет осознанно написано — так человек уже понимает чем это может быть плохо.
а если никто не будет писать специально, значит ничего не изменится. Если поменять молча «int» на «overflow_check int», то производительность внезапно может где деградировать. Куда не плюнь — будут отрицательные side-effects.kovserg
16.07.2021 11:17+3Вы не поверите, но люди пишут template<typename T>…
или даже так typedef overflow_check int int_s;
не говоря уже о том, что в цикле надо использовать не int, а что-то типа std::ssize_t так как sizeof(int)<sizeof(ssize_t) на нынешних платформах.
Не по умолчанию надо сделать модульную арифметику. Тем кому понадобиться математика с насыщением или проверкой переполнения, вот они пусть явно это указывают. Тоже самое и для инициализации 0 — тем кому не важно что в переменной будет мусор, пусть пишут это явно. Зато по умолчанию так будет 0 и куча UB и ошибок уйдет само собой, даже кода меньше придётся писать.ksergey01
16.07.2021 11:36-3Тоже самое и для инициализации 0 — тем кому не важно что в переменной будет мусор, пусть пишут это явно.
Тем кому важно, что в переменной будет мусор, пусть явно инициализируют 0.
Зато по умолчанию так будет 0 и куча UB и ошибок уйдет само собой, даже кода меньше придётся писать.
По умолчанию я не хочу платить перфомансом и больше писать кода.
kovserg
16.07.2021 12:15И сколько вы заплатили за последний месяц?
Наоборот это приводит к большим потерям, кучи UB и потерям человекочасов на поиск ошибок.
Вам либо лень думать, либовы каждую неделю целуете жопу Хэнкапросто не способны это понять. Нет ничего бесплатного.ksergey01
16.07.2021 12:40И сколько вы заплатили за последний месяц?
Нисколько.
Наоборот это приводит к большим потерям, кучи UB и потерям человекочасов на поиск ошибок.
Это ваш личный опыт. Я точно так же мог бы сказать, что неявная инициализация тривиальных типов приводит к потерям человекачасов на поиск проблемы.
Вам либо лень думать, либо
вы каждую неделю целуете жопу Хэнкапросто не способны это понять. Нет ничего бесплатного.Симметрично: вам лень думать, либо вы не способны это понять
Можно сказать, что вы выбрали для себя не тот ЯП, на котором вам было бы комфортно работать.
C++ was designed with an orientation toward system programming and embedded, resource-constrained software and large systems, with performance, efficiency, and flexibility of use as its design highlights.
kovserg
16.07.2021 13:00+1C++ was designed
Вот именно был, а превратили в то на что противно смотреть.
Какие нафиг large systems если в тривиальных преобразованиях он делает недопустимые ошибки.
Если есть утверждение которое вы считаете верным. То любой контр пример убивает это утверждение. Тут же контрпримеров вагон и маленькая тележка. А вы продолжаете бить себя в грудь и говорить что только так и надо. А кто против тот неспособен это понять.ksergey01
16.07.2021 13:05-1Если хотите, что бы стандарт учитывал ваши хотелки, пишите proposal.
Ну или по заветам Бендера
kovserg
16.07.2021 13:26-1Причем тут хотелки. Это очевидная критическая ошибка. Я на неё указываю, и внимание, посмотрите на результат. Сколько больных на голову минусуют, только из религиозных соображений. Вы действительно считаете, что если написать такой пропозал, то "вот эти люди" будут способны договориться? Судя по тому что они выпускают, Я вот сильно сомневаюсь.
ps: Есть еще вариант использовать не сломанные компиляторы.
ksergey01
16.07.2021 13:59+2Причем тут хотелки. Это очевидная критическая ошибка. Я на неё указываю, и внимание, посмотрите на результат. Сколько больных на голову минусуют, только из религиозных соображений.
Вы выдаете желаемое за действительное. Тут нет никакой критической ошибки и вы упорно отрицаете стандарт.
Вы действительно считаете, что если написать такой пропозал, то "вот эти люди" будут способны договориться? Судя по тому что они выпускают, Я вот сильно сомневаюсь.
Ваши хотелки, это только ваши хотелки. И я уверен, что комитет их не примет, т.к. профит неочевиден.
ps: Есть еще вариант использовать не сломанные компиляторы.
А еще можно форкнуть компилятор (и стандарт за одно). xD

AlexeyK77
16.07.2021 14:02+2но прогресс все же движется в сторону того, что по-умолчанию отдается предпочтение безопасности, а не производительности. Например RUST, мутабельность надо прописать явно, по молчанию - не мутабельна и т.д. Да и смещение фокуса в джаву и другие платформы от С++ тоже говорят и приоритете безопасности ипредсказуемости.
Но это все философия конечно же, полагаю, что философия С++ в сторону производительности уже не поменяется.
ibrin
16.07.2021 13:09вот раньше можно было о переполнении судить по флагам OF, CF процессора. Сейчас уже не прокатит?
Rexarrior
16.07.2021 14:02-1В Вас говорить перфекционист. Задайте один простой вопрос — кто за это заплатит? За ту работу, которая требуется, чтобы корректно выпилить UB? И кто будет платить за то падение производительности кода, которое возникнет в результате, хотя бы на первых порах? И ради чего? Чтобы кто-то меньше задумывался, когда пишет на с++? Ну, если хочется меньше думать над кодом, можно выбрать другой язык программирования.
Касательно же формальной логики и того, что компилятор должен оптимизировать по ее правилам и отказаться от UB… ну, а условное f(x) = f(x) || !f(x) Вы тоже предложите свернуть по правилу исключения третьего? Как бы ни было удивительно, но даже в насквозь дискретном, сиречь цифровом, программировании возможен парадокс Рассела.

eptr
16.07.2021 14:02+3Потому что чтение из неинициализированной переменной есть Undefined Behavior.
А UB подразумевает под собой любое поведение скомпилированного, в результате, кода.
Поскольку компилятор обычно стремится максимально соптимизировать код, в данном случае он соптимизировал его до простого возврата 0. Результирующее поведение кода после такой оптимизации вписывается в рамки UB, поскольку UB -- это любое поведение.

ksbes
16.07.2021 17:15-1Извините, что лезу с джавошный рылом во ваш сиплюплюшный ряд, но во это UB — это поведение чего? Получившейся программы или компилятора?
Если компилятора — то да, всё нормально — он «пошёл в разнос», имеет право. Но в этом сильно сомневаюсь, т.к. этак и вставку трояна в любое место UB можно оправдать (а это, если сделано сознательно автором компилятора — уголовная статья в кодексах всех развитых стран).
А вот если это UB получившейся программы — то это всё же косяк и переоптимизация компилятора. Т.к. задача компилятора трансляция кода с одного языка на другой, то как и всякий переводчик он ответственности за смысл не несёт: его задача чтобы «реальная процессорная» машина, делала в точности тоже, что идеальная «С++ машина» (т.е. непосредственно исполняющая С++ код).
Оптимизации допустимы в тех местах, где компилятор знает как оптимизировать. А если не знает — он ничего оптимизировать права не имеет. Это простой здравый смысл!
Очевидно, что UB относится к последнему случаю. Т.е. нормальный компилятор при виде UB должен либо прекращать компиляцию (программа ведь некорректна! Нахрена её компилировать?), либо переходить к буквальной компиляции. Но никак не делать ничего третьего.
Нет, я конечно понимаю, реальность посложнее подобной логики и приходится идти на компромиссы ради сохранения простоты и надёжности того же компилятора. Но тогда нужно просто признавать что в определённых граничных случаях программа ведёт себя не совсем корректно, а не пытаться это оправдывать «священными текстами».
P.S. сам пишу в том числе и транслитераторы (с «мёртвого языка» на «полумёртвый»), знаком с подобными проблемами не по наслышке.KanuTaH
16.07.2021 18:32+4Т.е. нормальный компилятор при виде UB
Уже здесь у вас ошибка в рассуждениях. UB - это ошибка, которую компилятор в общем случае не может обнаружить (только в некоторых частных и то не всегда), поэтому он вправе выполнять все оптимизации в расчёте на то, что таких ошибок программист не допускает. Грубо говоря, недопущение подобных ошибок ложится на программиста, а не на компилятор. Если брать пример с неинициализированной переменной, то в общем случае UB обнаружить нельзя, потому что переменная может быть передана по ссылке в функцию из другого модуля, где и инициализирована (или не инициализирована - компилятор этого не знает и знать не может потому, что этот модуль может, например, поставляться уже в бинарном виде).
kovserg
17.07.2021 00:03-4Уже здесь у вас ошибка в рассуждениях. UB — это ошибка, которую компилятор в общем случае не может обнаружить (только в некоторых частных и то не всегда), поэтому он вправе выполнять все оптимизации в расчёте на то, что таких ошибок программист не допускает.
WTF? Прикольно делать выводы на не доказанных утверждениях. Более того ложных утверждениях.
1. программист не допускает ошибок — поржал, это вообще фичА стандарта.
2. выполнять все оптимизации в расчёте на UB которую которую компилятор не может обнаружить. Но если обнаружил то молчит и делает максимально через ж#пу или на оте%&сь.Грубо говоря, недопущение подобных ошибок ложится на программиста, а не на компилятор.
Ахренеть, это еще хорошо если программистов меньше десятка, а что делать если некоторых уже нет и новые приходят?
Вообще, мягко говоря это очень плохая практика сваливать ответственность с компилятора на самых безответственных людей — программистов. Это еще можно было понять для низкоуровневого C, но C++ позиционирует себя как высокоуровневый язык.Если брать пример с неинициализированной переменной, то в общем случае UB обнаружить нельзя,
Ложь и лицемерие. Он тупо использует элемент который не принадлежит множеству значений переменной, и использует правила которые ни имеют никакого отношения к типу переменной.
Более того никакого выигрыша в производительности не получает. Вернуть правильный ответ или не правильный по скорости не отличается. Вот если бы он выкинул всю программу, то да — идеальная оптимизация. Но пока это слишком. Может быть позже.потому что переменная может быть передана по ссылке в функцию из другого модуля, где и инициализирована (или не инициализирована — компилятор этого не знает и знать не может потому, что этот модуль может, например, поставляться уже в бинарном виде).
О да, в данном примере, он не вкурсе что переменная локальная и её время жизни ему не известно и он явно видит как её передают куда-то на сторону по ссылке.
Я смотрю Вы всегда говорите правду, даже если для этого приходится врать.Antervis
17.07.2021 08:51+3WTF? Прикольно делать выводы на не доказанных утверждениях. Более того ложных утверждениях.
это не "не доказанные утверждения", это аксиомы, исходя из которых проектируется компилятор.
программист не допускает ошибок — поржал, это вообще фичА стандарта.
Вообще, мягко говоря это очень плохая практика сваливать ответственность с компилятора на самых безответственных людей — программистовесли вы способны написать ЯП и компилятор к нему так, чтобы на любую несуразицу написанную программистом компилятор догадался, чего там автор хотел от него добиться, и это сделал, то валяйте, сделайте как надо. Если нет, то не надо ныть какой плохой компилятор что не правит ваши UB
Более того никакого выигрыша в производительности не получает. Вернуть правильный ответ или не правильный по скорости не отличается. Вот если бы он выкинул всю программу, то да — идеальная оптимизация. Но пока это слишком. Может быть позже.
тут нет "правильного" ответа.
kovserg
17.07.2021 15:59-2это не «не доказанные утверждения», это аксиомы, исходя из которых проектируется компилятор.
Почему в списке аксиом по которым проектируется компилятор нет аксиомы не противоречивости аксиоматики?DerRotBaron
17.07.2021 17:46+3А в каком месте она противоречива? Она контринтуитивна и из-за этого плохо совместима с реальными программистами, но при этом противоречит она только вашему нежеланию понимать, что если компилятор может оптимизировать чушь произвольным образом, он будет это делать.
И хуже того, вы выбрали очень плохой пример для иллюстрации проблем с UB в C/C++, и поэтому ваше поведение выглядит как война с ветрянными мельницами
kovserg
17.07.2021 20:21-1А в каком месте она противоречива?
Из всех возможных исходов он молча выбирает исход которого нет.Она контринтуитивна
это не важно, важно что она противоречива.выбрали очень плохой пример для иллюстрации проблем с UB
этот самый простой.
Основная притензия в том что смотря на кусок программы вы не можете сказать что она делает. Вообще. Вам надо вкапываться во все детали, а лучше сразу смотреть ассемблерный код. Например вы видите цикл, в нём условие. Но его компилятор может выкинуть, если внутри цикла вызывается функция которая может быть заинлайнена, при этом в функции окажется UB с переполнением int. Еще веселей если это еще закопано в многоэтажных шаблонах. Просто нечаенная опечатка или вызов логирования, способны развалить рабочий код. Это просто достойно всяческих похвал.Antervis
17.07.2021 21:04+3Просто нечаенная опечатка
или вызов логирования(логгирование без ошибок не сломает код), способны развалить рабочий код. Это просто достойно всяческих похвал.ошибки программистов ломают код (ваш кэп), UB это класс ошибок программиста, отличающийся лишь тем, что ломает код не гарантированно или не определенным образом. Оно блин в честь этого и названо undefined behavior. Ждать от UB гарантированного поведения глупо по определению.
Да, я в целом согласен, что на не инициализированную переменную можно было бы и ошибку компиляции выдавать, но, такого поведения можно добиться от любого с++ компилятора (например -Werror -Wuninitialized в clang/gcc).
DerRotBaron
19.07.2021 21:31Вот именно примеры неочевидного UB, от которого код на первые десятки взглядов необъяснимо разваливается, и надо приводить. В случае неинициализированной переменной же UB очевидно, и код будет вполне очевидно некорректным, если только какие-то "добрые" преподаватели в вузе или коллеги на первой работе не внушили вам, что там будет не UB, а вполне себе однозначный "мусор".
Ну а еще это UB ловится любыми компиляторами и линтерами, так что конкретно его опасность сильно вами преувеличена
ibrin
18.07.2021 15:14-1Учитывая уровни оптимизации, можно выдвинуть предложение, что градус UB повышается с ростом сложности оптимизации. Без оптимизации, обращение к неинициализированной переменной не будет UB, а на каком нибудь -O3 компилятор имеет право наколбасить любую дичь. UB по уровням оптимизации, красота же.
Racheengel
24.07.2021 00:38-1Чтение из неинициализированной переменной подразумевает Undefined Behavior по отношению к возвращаемым данным (Data arbitrary), но не Control flow violation.
То есть грубо говоря, код типа
int f () { unsigned char x; return x * 10; }
должен вернуть целое число в диапазоне от 0 до 2550. Потому что значение х не определено, Но явно определён его диапазон и операции над ним. И в целях оптимизации компилятор имеет право всегда возвращать, скажем, 0 или 1000. Но никогда -1. Это будет некорректным поведением априори.
eptr
24.07.2021 01:47Чтение из неинициализированной переменной подразумевает Undefined Behavior по отношению к возвращаемым данным (Data arbitrary), но не Control flow violation.
В стандарте понятие UB трактуется значительно шире, при этом UB не делится на подвиды. Там нет таких понятий как "UB по отношению к возвращаемым данным" или "Control flow violation".
С UB, приводящем к "Control flow violation", я сталкивался лично, правда, на C.
должен вернуть целое число в диапазоне от 0 до 2550. Потому что значение х не определено, Но явно определён его диапазон и операции над ним. И в целях оптимизации компилятор имеет право всегда возвращать, скажем, 0 или 1000. Но никогда -1. Это будет некорректным поведением априори.
Это больше похоже на Unspecified Behavior. В случае же UB результирующая программа, если скомпилировалась, имеет в месте возникновения UB поистине безграничные полномочия: может не только вернуть любое значение
 , но даже не вернуть никакое, например, завершившись.
, но даже не вернуть никакое, например, завершившись.Racheengel
24.07.2021 10:30-1Вы слишком вольно трактуете понятие UB. В данном примере UB относится только к значению переменной. Весь остальной код полностью валиден согласно стандарта и должен исполняться соответственно.
Что касается control flow violation, это уже указывает, как правило, на серьёзные ошибки в компиляторе. (Компиляторами заниматься приходилось, так что я знаю, о чём говорю)
Antervis
24.07.2021 10:38+1В данном примере UB относится только к значению переменной. Весь остальной код полностью валиден согласно стандарта и должен исполняться соответственно.
тогда в стандарте было бы написано "yields unspecified value" а не "undefined behavior". Я еще раз приведу пример с санитайзером: при чтении значения из не инициализированной памяти программа падает, и это полностью соответствует стандарту. А то, о чем вы говорите - то, как компилятор пытается обрабатывать такое чтение по умолчанию.
kovserg
24.07.2021 11:51-1Так почему компилятор из возможных вариантов поведения (в том числе останова и исключения) выбирает вариант который отсутствует в возможных конечных состояниях? И это считается «стандартным» поведением (оправдывается стандартом — это не мы это стандарт, всё по стандарту). Принцип наименьшего удивления видимо еще не
изобрелиподвезли.Antervis
24.07.2021 12:18вам комментариев 100 уже написали почему это так, и почему в возможных конечных состояниях UB может присутствовать что угодно вам тоже писали, а принцип наименьшего удивления отлично работает, просто вам абсолютно любой вариант реализации кажется каким-то невероятно удивительным.
kovserg
24.07.2021 15:17-1Ни один из комментаторов не привел ни единого убедительного аргумента почему так должно быть.
eptr
24.07.2021 16:56+2Вы слишком вольно трактуете понятие UB.
Ну, что ж, придётся обратиться к последнему прибежищу интеллектуала, то есть, к первоисточнику (draft стандарта C++17):
3.27
[defns.undefined]
undefined behavior
behavior for which this document imposes no requirements"Поведение, к которому данный документ не предъявляет вообще никаких требований" (форма отрицания с частицей "no" -- более жёсткая, чем просто отрицательная форма; в русском варианте она соответствует фразе, в которую добавлено слово "вообще" или "абсолютно").
Если к поведению не предъявлено вообще никаких требований, то такое поведение может быть абсолютно любым (это же верное логическое следование?).
По этой причине я принципиально не могу трактовать понятие UB "слишком вольно", потому что не существует ещё более вольной трактовки по сравнению с "не предъявляет вообще никаких требований". То есть, возможность трактовать понятие UB слишком вольно у меня отсутствует даже теоретически, не говоря уже о практике.
В данном примере UB относится только к значению переменной. Весь остальной код полностью валиден согласно стандарта и должен исполняться соответственно.
С момента возникновения UB не имеет никакого значения степень валидности остального кода.
Вы пытаетесь предъявить требования к коду на поведение при UB, когда утверждаете, что "... остальной код полностью валиден согласно стандарта и должен исполняться соответственно". "Код должен" -- это прямое требование к некоторому определённому поведению кода при данном UB.
Однако в
библиистандарте прямо указано, что "данный документ не предъявляет вообще никаких требований" на поведение кода при UB. Поэтому требование "код должен" как минимум "нестандартно" и, поэтому, "необязательно к исполнению" компилятором при генерации кода (подразумевается, что мы обсуждаем "стандартные" компиляторы, то есть, те, которые "действуют" в соответствии со стандартом).Что касается control flow violation, это уже указывает, как правило, на серьёзные ошибки в компиляторе.
Характерно, что как только UB в том моём случае был устранён, так control flow violation сразу же исчез совершенно чудесным и непостижимым образом.
Кстати, control flow violation "укладывается" в допустимое поведение при UB, поэтому, выходит, что компилятор в том случае был абсолютно прав.
Racheengel
25.07.2021 09:17-1Но тогда получается, если трактовать UB именно так, как считаете вы, то по сути, любая ответственность по обработке UB, в том числе юридическая, перекладывается на производителя компилятора.
То есть клиент, получивший ущерб из за того, что компилятор некорректно обработал UB, теоретически вполне вправе требовать от производителя возмещения, ссылаясь на тот же стандарт. Ибо некорректное поведение компилятора в этом случае - проблема производителя.
Соответственно, изменение Control flow это проблема конкретного компилятора. Получается так.
mayorovp
25.07.2021 11:27Вы как-то странно понимаете отсутствие требований. Отсутствие требований к компилятору означает, что любая проблема из-за наличия UB в программе — вина программиста.
Racheengel
25.07.2021 12:16-1А кто должен программисту сообщить о потенциальном UB, как не компилятор? Если он этого не сделал, то это вина производителя - это раз.
Во вторых, программист никак не может влиять на сгенерированный компилятором код. А значит, все сайд-эффекты от выполнения сгенерированого компилятором кода - тоже ответственность производителя.
Так что подход "что не запрещено, то разрешено" очевидно не верен.
Лично я отношусь к тому множеству людей, которые выступают за ликвидацию понятия UB как такового и упрощение базовых правил с++. Прописав UB в стандарте, его разработчики внесли больше неоднозначности и переложили проблемы языка на производителей компиляторов.
mayorovp
25.07.2021 12:21+2Так для тех UB, которые очевидны — компилятор обычно сообщает.
Проблема в том, что в языке С++ есть много мест, где потенциальное UB может быть в каждой строчке кода.
Racheengel
25.07.2021 17:24-2Если подумать, то на самом деле "неопределенного поведения" в принципе не существует. Каждый раз компилятор выполняет вполне определенный код: для неинициализированной переменной при чтении из неё вернётся мусор, при делении на ноль произойдёт исключение, при выходе за пределы массива - ошибка доступа к памяти и пр. Эти случаи достаточно однозначны. Всё, что выходит за типичное поведение в подобных ситуациях, должно являться (и по сути, является) некорректным поведением.

tyomitch
25.07.2021 18:16при делении на ноль произойдёт исключение, при выходе за пределы массива — ошибка доступа к памяти и пр.
Вот вам наглядный пример: на большом числе целевых платформ таких вещей, как «исключение» и «ошибка доступа к памяти», не существует в принципе. Если дописать в стандарт ваши требования, то компиляторы для этих платформ не смогут существовать, либо им придётся к любому компилируемому коду прицеплять довеском мини-ОС.
Racheengel
25.07.2021 18:53Не вижу противоречий. Платформенно-зависимые вещи должны стандартизироваться соответственно особенностям платформы. Как например размерность int.
mayorovp
25.07.2021 19:37Нет, в языках Си и С++ эти случаи не являются однозначными. За однозначностью лучше идти в управляемые языки или в Rust.
Antervis
25.07.2021 20:43За однозначностью лучше идти в управляемые языки или в Rust.
Понятие UB есть и в расте, и оно ничуть не более определенное. И причины возникновения примерно те же что и в плюсах. Разница только в том, что места где UB может возникнуть в расте огорожены, а в с++ нет
tyomitch
25.07.2021 14:53Если поведение, которое сейчас не определено, доопределить, то стандарт не станет проще, а наоборот, сложнее и толще.
Antervis
25.07.2021 20:31+1... компилятор некорректно обработал UB, ...
вы можете чутка поднатужить мозг и понять наконец что значит слово undefined в термине undefined behavior?
Racheengel
25.07.2021 22:05-1Я думаю, что ваш уровень некомпетентности в вопросах с++ не даёт вам права кому-либо что-либо советовать в данной теме. Уровень вашего хамства впрочем тоже.
Antervis
26.07.2021 04:56+1Итак, давайте еще раз пройдемся по тезисам. Undefined behavior является "неопределенным" по определению этого термина, приведенному в стандарте языка с++. С точки зрения стандарта языка с++ программа, содержащая UB, является некорректной, это факт. Компиляторы имеют право доопределять некоторые виды UB, однако в большинстве случаев вместо этого оптимизируют исходя из аксиомы о том, что программа корректна, то есть программист не допустил ошибку. Если ошибка есть, значит компилятор исходит из неправильного предположения и результат оптимизаций является непредсказуемым. Что, опять же, полностью удовлетворяет отсутствующим требованиям к UB.
Вы в одном лишь этом треде успели поспорить и с фактами, и с аксиомами, и с "по определению". Вы не осилили понять аргументацию как меня, так и других комментаторов. Обвинять кого-либо в некомпетентности с такой позиции равносильно росписи под диагнозом Даннинга-Крюгера. А то что я хам даже соглашусь. Опять же, я не обязан быть вежливым с людьми, исчерпавшими кредит моего уважения.
eptr
26.07.2021 00:53+1Но тогда получается, если трактовать UB именно так, как считаете вы, то по сути, любая ответственность по обработке UB, в том числе юридическая, перекладывается на производителя компилятора.
Почему "как считаю я"?
Разве в стандарте неоднозначно написано?В стандарте -- ни слова об ответственности, тем более, юридической.
Если же говорить об "ответственности", то "ответственность" с компилятора в месте возникновения UB как раз снимается, причём абсолютно и полностью, чем современные компиляторы вовсю и пользуются.Если уж говорить о чьей-то "ответственности", то имеет смысл говорить об "ответственности" программиста, ведь это он написал код с UB, к чему компилятор уж точно не имел ни малейшего отношения.
То есть клиент, получивший ущерб из за того, что компилятор некорректно обработал UB, теоретически вполне вправе требовать от производителя возмещения, ссылаясь на тот же стандарт. Ибо некорректное поведение компилятора в этом случае - проблема производителя.
Компилятор не имеет даже теоретической возможности неверно "обработать UB", ибо любая теоретически возможная "обработка" соответствует стандарту и поэтому является верной.
Неверная изначальная посылка о том, чья это ответственность, может далеко завести... но как правило не туда. Более того, вплетать вопросы юриспруденции в IT-шную сферу -- занятие неблагодарное, тем более, что в стандарте нигде нет ни намека на чью бы то ни было ответственность.
Насколько мне известно, сейчас лицензионные соглашения пишутся в стиле "компания <такая-то> никогда ни при каких условиях ни за что не будет отвечать". Поэтому мне странно видеть выводы о возможности требовать возмещения. Но это -- опять же, юриспруденция, к вопросу отношения не имеет.
Соответственно, изменение Control flow это проблема конкретного компилятора. Получается так.
Нет, получается не так.
Это проблема программиста, а не компилятора.
Компилятор в случае UB приобретает "абсолютные права" на всё, что угодно и что неугодно, в том числе, на нарушение Control flow, и никто не может ограничить его в этом "праве": для компилятора нет никого и ничего выше стандарта.
Кстати, компилятор не обязан "пользоваться" своими "абсолютными правами" на всё, что угодно и неугодно, и поэтому может создаться иллюзия, что компилятор, который ими в каком-то конкретном случае UB не воспользовался, "правильнее".
Нет, он -- не "правильнее", он просто -- "другее". Один ничем не лучше и не хуже другого, если пытаться сравнивать их по этому показателю.
UB допускает или не допускает программист без какого-либо участия в этом компилятора.
Компилятор в случае отсутствия UB теряет те самые "абсолютные права" на всё, что угодно и неугодно, в том числе, и "право" на нарушение Control flow.
Вот, как получается.
Racheengel
25.07.2021 11:05-1Если к поведению не предъявлено вообще никаких требований, то такое поведение может быть абсолютно любым (это же верное логическое следование?).
Ну строго говоря, не совсем. Это только означает, что данный конкретный документ не предъявляет никаких требований. Но это не значит, что они поэтому могут быть вообще любыми. Это примерно, как в трудовом кодексе не написано явно, что нельзя убивать коллег в офисе. Но это не означает автоматически, что это делать можно.
mayorovp
25.07.2021 11:28+1Извините, а какие ещё документы предъявляют требования к компиляторам С++?
kovserg
25.07.2021 11:45Заодно какие документы предъявляют требования к программистам использующим C++?
Racheengel
25.07.2021 14:45-1Как минимум, правила языка и техническая спецификация компилятора, например?
mayorovp
25.07.2021 15:35+1"Правила языка" — это и есть стандарт, который цитировался выше.
А техническая спецификация компилятора лишь описывает поведение компилятора, и если оно отличается — переписывать будут спецификацию, а не компилятор.
eptr
26.07.2021 01:10Ну строго говоря, не совсем. Это только означает, что данный конкретный документ не предъявляет никаких требований.
Коллеги уже высказались по этому поводу, добавить нечего.
Но это не значит, что они поэтому могут быть вообще любыми.
Откуда это следует?
Это примерно, как в трудовом кодексе не написано явно, что нельзя убивать коллег в офисе. Но это не означает автоматически, что это делать можно.
По трудовому кодексу -- означает. По трудовому кодексу -- можно. Нельзя -- по другому кодексу.
Если и проводить аналогии с юриспруденцией, то стандарт соответствует совокупности всех кодексов.
Однако, проводя аналогии с юриспруденцией, можно сильно ошибиться.
Куда логичнее проводить аналогии с ближайшими науками, например с математикой.
Antervis
16.07.2021 20:37Почему стандарт ему позволяет такое делать?
Если вам интересно почему там UB, то это потому, что реализация, которая будет крашить программу при обращении к не иницализированной памяти, соответствует стандарту. Это нужно для того же memory sanitizer'а.
Если вам интересно почему компилятор обрабатывает UB как ему вздумается - это помешает компилятору оптимизировать код.

VioletGiraffe
17.07.2021 01:21+3Garbage in — garbage out. clang видит, что вы написали глупость и этот код не может выполнять никакую полезную функцию, а вернуть что-то из функции всё равно нужно. Поэтому он смело возвращает первую попавшуюся констатнту типа int. Логично, что на эту роль выбран 0. А стандарт это разрешает с очень важной целью — это открывает простор для оптимизаций. Не конкретно в этом примере, а в корректных программах на С++, конечно. К которым ваш пример не относится.
kovserg
17.07.2021 01:33-5Вот именно. Стандарт позволяет делать garbage практически на ровных местах. Более того культивирует такую практику. Нельзя допускать введения ничем не обоснованных правил, взятых с потолка. Они всегда будут приводить к противоречиям и костылям.
Продемонстрируйте пример где это приводит к увеличению производительности с сохранением логики работы программы.
ps: И главное если компилятор явно видит garbage in то зачем делать garbage out? Для чего выходить за множество значений типа к объектам другого множества без единого обоснования корректности данной операции. Потом приходится переубеждать толпы идиотов, которые с горящими глазами говорят что это по стандарту и ведёт к охренительному ускорению кода и бесплатно. И главное доказательств им не требуется, только вера в непогрешимость стандарта.
rg_software
17.07.2021 02:57+3Ускорение достигается за счёт в том числе обрезания того кода, который "не может" выполняться. Вот, например, статья, где показано, как компилятор вырезает целые куски с UB. Вам может не нравиться эта философия языка, но с тем же успехом можно не любить философию Java, Smalltalk или Forth. Непонятно зачем кого бы то ни было переубеждать - просто пользуйтесь другими языками, благо, их тысячи.
VioletGiraffe
17.07.2021 10:27Т. е. ваша версия — стандарт С++ писали идиоты, и программисты на С++ тоже идиоты?
kovserg
17.07.2021 12:29-2Нет — У семи нянек детё без глаза.
ps: Любые неявные предположения — мать всех ошибок.

oleg1977
20.07.2021 10:31чтобы возвращать не 0 компилятор должен уметь символьные вычисления: слишком сильное требование
dvserg
20.07.2021 10:42Можете пояснить? Не понял каким образом это должно работать?
oleg1977
24.07.2021 03:06логика ub такова, что в с точки зрения компилятора никогда не выполняется ub код. с точки зрения c++ _любое_ выражение с неинициализированной переменной (пусть она называется uninit) - это ub. математически некоторые выражения с uninit определены, например, uninit || !uninit равно 1, а uninit*0 равно 0. поэтому, чтобы гарантировать, что ub код не выполняется, компилятор должен уметь различать выражения:
uninit || !uninit
uninit*0
uninit*2
в случаях 1 и 2 компилятор должен знать, что там гарантированно нет ub и поэтому код может выполняться, как он записан в исходнике. в случае 3 есть ub, поэтому (учитывая что ub код не выполняется) он не достижим и просто выбрасывается. если код нельзя выбросить, например, потому что он является аргументом return, то его выбрасывание - это замена на 0.
проблема в том, что компиляторы не настолько умны, чтобы различать случаи 1,2 и 3 и вынуждены следовать логике: если я не могу доказать, что нет ub, значит это ub. поэтому любое выражение с uninit - это ub. если бы компиляторы умели делать символические вычисления, то они могли бы доказать, что в 1 и 2 нет ub и выполнять их как есть.
pascha40otdel
16.07.2021 14:02Есть файл с ASCII-графикой, и мы его никак не меняем — из него нужны только байты. Но в С++ нельзя работать с файлом как с массивом байт: придётся открыть поток, считать информацию из потока в контейнер (string или vector) и только тогда работать с этим контейнером.
А почему нельзя сделать матрицу и массив лампочек (ссылки на элементы матрицы), менять только массив, зачем из файла читать, если только первый раз.

{kind=link}

nehaev
16.07.2021 14:25Поэтому сейчас мы примерно в 100 раз быстрее Java, что более-менее приемлемо, но все равно недостаточно.
А можете пояснить для людей, не очень умеющих в плюсы, за счет чего получился такой прирост?
Antervis
16.07.2021 20:44потому что:
Logstash постоянно что-то сует в какие-то конкурентные ассоциативные контейнеры, в которых тратится огромное количество времени.
nehaev
16.07.2021 20:55+1Мне было непонятно, является ли это какой-то принципиальной проблемой джавы, или это просто особенность реализации в Logstash?
Antervis
18.07.2021 10:00тут надо апологетов джавы спрашивать. Я могу лишь предположить что конкурентные контейнеры там нужны для распараллеливания, которое нужно потому что в один поток приложуха не справляется
iemelyanov
16.07.2021 17:57Антон, вы не рассматривали github.com/timberio/vector как очень шуструю альтернативу logstash?

dllmain
20.07.2021 18:39Блок отвечает за управление лампочками, но это приходится делать в отдельном потоке, так как в C++ нельзя одновременно мигать лампочками и смотреть, нажал ли пользователь клавишу. Чтение из потока — блокирующее.
Неясно, что мешало использовать неблокирующие методы, тот же readsome(&c, 1).
Но в С++ нельзя работать с файлом как с массивом байт: придётся открыть поток, считать информацию из потока в контейнер (string или vector) и только тогда работать с этим контейнером.
Тут совсем претензии непонятны: простейшая обёртка пишется в несколько строк. Количество строк на небольших программках показателем не является, особенно в C++ - это не язык для написания скриптов на несколько десятков строк(хотя он даже с этим справляется).
Ну и сравнение некорректно - сравнивать куда более ограниченную модель bash/perl/etc и обобщённую модель C++ нельзя - здесь не учитывается количество возможностей, предоставляемых языком. Как минимум, пример нужно брать другой, какая-нибудь простенькая СУБД, например.
antoshkka
21.07.2021 17:30+1Неясно, что мешало использовать неблокирующие методы, тот же readsome(&c, 1).
Его поведение не переносимо, на многих платформах не работает, https://en.cppreference.com/w/cpp/io/basic_istream/readsome :
"Likewise, a call to std::cin.readsome() may return all pending unprocessed console input, or may always return zero and extract no characters."
Тут совсем претензии непонятны: простейшая обёртка пишется в несколько строк.
Или берётся Boost и используется mmaped file. Только вот хочется готовое стандартное решение, а не самому писать его заново в каждом проекте или в каждый проект тянуть Boost.

emusic
13.09.2021 10:40-1Функция, принимающая
char8_t*на треть короче.Какие компиляторы делают лишний код [unsigned] char?
Когда вы работаете с
unsigned char*,char*илиbyte*, компилятор думает, чтоchar*может указывать на все, что угодно: наinteger,stringили пользовательскую структуру.Это худо-бедно смотрелось бы в первом выпуске K&R, но при чем здесь современный C++? Еще в ANSI C для "чего угодно" использовался void *. А компилятор здесь вообще не должен ни о чем думать, а должен работать с указанным типом, как положено по стандарту.
И когда компилятор видит, что на вход передается
char*и что-то извне посылки, то думает, что любая модификация этой переменной может поменять те данные, на которые указываетchar*И правильно думает - здесь прежде всего нужен const. А сам по себе char8_t не предполагает никакой подобной магии.
mayorovp
13.09.2021 12:44Это худо-бедно смотрелось бы в первом выпуске K&R, но при чем здесь современный C++? Еще в ANSI C для "чего угодно" использовался void *. А компилятор здесь вообще не должен ни о чем думать, а должен работать с указанным типом, как положено по стандарту.
Ну так именно что стандарт и разрешает char* указывать на что угодно.
И правильно думает — здесь прежде всего нужен const. А сам по себе char8_t не предполагает никакой подобной магии.
А как тут const поможет?
emusic
13.09.2021 14:37стандарт и разрешает char* указывать на что угодно
Где он это разрешает? И, даже если б и разрешал, это может позволить компилятору лишь проглотить конструкцию без ошибки, но никак не менять режим генерации кода.
как тут const поможет?
Чтобы компилятор не думал лишнего. Впрочем, фраза с "что-то извне посылки" составлена настолько коряво, что ее можно интерпретировать несколькими разными способами.
mayorovp
13.09.2021 15:20Разрешает стандарт это в пункте 7.2.1 (11):
If a program attempts to access (3.1) the stored value of an object through a glvalue whose type is not similar (7.3.6) to one of the following types the behavior is undefined
(11.1) — the dynamic type of the object,
(11.2) — a type that is the signed or unsigned type corresponding to the dynamic type of the object, or
(11.3) — a char, unsigned char, or std::byte type.И да, "чтобы компилятор не думал лишнего" поможет только restrict, но никак не const.
emusic
13.09.2021 21:52-1Здесь стандарт не "разрешает", а определяет, что будет, если насильно обращаться к объектам через указатель/ссылку на чужой тип. Понятно, что гарантированно (и совместимо) работать будет только байтовый доступ. И поведение тут "undefined" только в рамках абстрактной программы в вакууме, а фактически оно platform-dependent, поскольку такое совершенно нормально для низкоуровневого кода. Никакого запрета здесь нет, есть лишь ограничение переносимости.
С какими компиляторами, и в каких режимах можно наблюдать, как компилятор "думает" и "выгружает", если в функцию передан указатель на char? Я такого не видел нигде и никогда.
Насчет const я говорил в том смысле, как мне удалось понять ту кривую фразу про "что-то извне посылки". Если она расшифровывается иначе - возможно, const там действительно не нужен.
mayorovp
14.09.2021 12:35-1Это именно что разрешение. Согласно стандарту, через указатель типа
char*можно обращаться к любым объектам не вызывая UB — а следовательно, компилятор обязан учитывать тот случай, когда указательdataуказывает наresult. Именно это и "удлиняет" машинный код функцииdo_somethingиз примера в статье.С какими компиляторами, и в каких режимах можно наблюдать, как компилятор "думает" и "выгружает", если в функцию передан указатель на char? Я такого не видел нигде и никогда.
С любыми достаточно современными. GCC, Clang, MSVC. Тут на Хабре уже много раз приводили примеры, так что приводить их ещё раз как-то лень.
Насчет const я говорил в том смысле, как мне удалось понять ту кривую фразу про "что-то извне посылки". Если она расшифровывается иначе — возможно, const там действительно не нужен.
Вы не можете через const запретить указателю data указывать на result — а потому модификатор const тут совершенно бесполезен.
И поведение тут "undefined" только в рамках абстрактной программы в вакууме, а фактически оно platform-dependent
emusic
14.09.2021 17:23-1компилятор обязан учитывать тот случай, когда указатель
dataуказывает наresult. Именно это и "удлиняет" машинный кодКод удлиняет не соблюдение конкретно этой особенности стандарта, а гораздо более общее предположение о возможном наложении, независимо от типов. И это правильно, поскольку закладывать генерацию кода на столь тонкую особенность стандарта нет смысла - здесь гораздо надежнее ориентироваться на явно заданные режимы и квалификаторы.
С любыми достаточно современными. GCC, Clang, MSVC
Вот я посмотрел, что делают GCC 11.2.0 с -Ofast, и VC 19.29 с /O2. Как и 10, 20 или 30 лет назад, логика кода в режиме рабочей (максимальной) оптимизации никак не зависит от типа указателя, поскольку возможность наложения подразумевается для всего. Но VC как сохраняет промежуточные значения result, так и загружает значения из data в правильном порядке, а вот GCC почему-то соблюдает это для char и int, но не соблюдает для char8_t, short и long.
Так что я до сих пор не понимаю, почему в статье сделан упор именно на char8_t, а не режимы контроля наложения.
Вы не можете через const запретить указателю data указывать на result
Спасибо, я уже на прошлой итерации догадался, о чем хотел сказать автор. :) Если бы он формулировал мысль более внятно, было бы проще.
mayorovp
14.09.2021 17:36-1Возможность наложения как раз от типов зависит. В случае char8_t стандарт говорит о UB в случае наложения с int, что равносильно запрету наложения.
emusic
14.09.2021 17:57-1Если следовать стандарту, то любой тип, отличный от [unsigned] char, равносилен запрету наложения. Но компиляторы, слава богу, пока не делают добуквенное соблюдение стандарта своей главной целью, а ориентируются на практические задачи, поскольку компилятор - средство решения задач, а не проверки соблюдения стандарта. Именно поэтому они чаще всего оставляют без внимания обсуждаемую особенность.
В итоге, скорее всего, в компиляторах будет реализован специальный, явно задаваемый режим "соблюдать все требования стандарта до мелочей". Но использоваться он будет главным образом для тестирования совместимости. А практические задачи будут продолжать решаться с использованием более очевидных конструкций, вроде того же restrict, __declspec (noalias) и подобных.
mayorovp
14.09.2021 18:00Э-э-э, в каком мире вы живёте? Компиляторы давно уже в целях оптимизации "осваивают" разные UB, и strict aliasing rule было "освоено" одним из первых.
emusic
14.09.2021 18:32-1Я как раз живу в реальном, где неявное (требующее предположений от компилятора) наложение встречается очень редко. И меня весьма удручает, что компиляторы "осваивают" подобные оптимизации недостаточно активно. По уму, следовало изначально исходить из того, что наложения нет, если оно не указано явно (квалификаторами, разносом адреса объекта по разным указателям и т.п.).
mayorovp
14.09.2021 20:07-1Ещё более активная оптимизация сломает обратную совместимость, а это для языка смерть.
И да, разрешённое наложение char с любым другим типом — одна из проблем языка, из-за которой и пришлось вводить char8_t.
emusic
15.09.2021 13:55-1Сдуру можно много чего сломать. А если по уму, то обещанная "максимальная оптимизация, невзирая на возможность наложения" так и должна работать - невзирая, а для случаев, где наложение возможно, должна быть возможность явно это указать. Но почему-то сложилось так, что явно можно указать лишь отсутствие наложение, поэтому оптимизаторы вынуждены осторожничать.
Разрешенное для char наложение является проблемой только для тех, кто под программированием понимает исключительно запись конструкций языка согласно спецификации. Огромное количество программ работает с наложением, используя указатели на что угодно, кроме char. Если вдруг оптимизаторы перестанут предполагать наложение в этих программах лишь на основании стандарта, они все поломаются.
Поэтому добавление chat8_t может принести пользу исключительно "программисту нового типа", который записывает конструкции языка, весьма смутно представляя, что происходит под капотом. C++ таки не для этого, и эта тенденция к выхолащиванию очень удручает.
Gorthauer87
Тащить все в стандартную библиотеку? А потом все будет как в Go, где все более хорошие альтернативы так и так пользуют. Лучше менеджер зависимостей сделать стандартный.
И ещё интересно, а ведь можно и на джаве намного код ускорить если поменять алгоритм. А то сравнивается какой то универсальный код на джаве с либой строго под задачу.
Symphel
В прикрепленном видео оба эти вопроса задавали. И ответы Антона меня удивили.
Стандартный менеджер пакетов. Ответ примерно такой: вот есть уже 10 разных пакетных менеджеров под разные наборы платформ, поэтому (?) мы лучше затащим все в стандартную библиотеку. А если кто не может на своей платформе STL, то мы сделаем для нее подмножество, которое точно можно реализовать.
Переписать logstash на Java. Кто-то когда-то пробовал, получилось медленнее.
Последние 3 пишу только на Го. Решил посмотреть, чем живет современный C++, может стоит вкатиться на C++20. Что могу сказать, проблемы в общем-то все те же: попытка угодить всем сразу и при этом сохранить легаси, отказ от инфраструктурных компонент, которые нужны всем (пакетный менеджер), зато стремление поддержать ОЧЕНЬ узкую категорию платформ, на которых всего 120байт памяти или нет оперативки. Что могу сказать, я рад, что больше в этом не варюсь.
Antervis
скорее стремление поддерживать в первую очередь самые востребованные для плюсов платформы. Так то с с++ и в веб можно, но кому это надо? А ембедщикам кроме си и плюсов то и сунуться некуда, не учитывать их мнение значит ударить по целому классу устройств.
Symphel
Насколько я понимаю, в Яндексе весь веб бэкэнд на C++. И программистов там больше, чем во всем ембеде в России. И что, ембедщикам пакетный менеджер не нужен?
Antervis
Пакетный менеджер всем нужен, просто не хочется ситуации с пятнадцатым стандартом, а значит, куча народу, в т.ч. мейнтейнеры существующих решений, должны прийти к консенсусу.
Говоря про веб я конечно же имел в виду фронтенд, а за яндекс не переживайте - монорепа с in-house системой сборки не шибко нуждается в пакетном менеджере.
KanuTaH
Проблема в том что пакетных менеджеров уже есть некоторое количество (навскидку могу вспомнить conan, vcpkg, cget, nuget - это только навскидку, так их еще больше). Ну будет yet another package manager ¯ \ _ (ツ) _ / ¯