

Код пока недоступен.

Это еще одна статья о сочетании сверточных нейронных сетей (CNN) и внимания (attention) для решения задач компьютерного зрения. Авторы (из Google Research) объединяют depthwise свертки с self-attention, вертикально накладывая друг на друга слои внимания и свертки. Полученные CoAtNet сети хорошо работают как в условиях низкого, так и большого количества данных. Они достигают 86,0% top-1 точности ImageNet без использования дополнительных данных; используя данные JFT, эти архитектуры способны достигать 89,77%.
О свертках и внимании


CNN и архитектуры на основе трансформаторов имеют разные преимущества. Уже были попытки совместить их — авторы систематически анализируют различные подходы к этому и предлагают свой. Основные идеи следующие:
Относительное внимание (relative attention) — это особый вариант внимания. Здесь есть две основные категории: зависимые от ввода (input-dependent) и независимые от ввода (input-independent) версии. Независимые от ввода довольно быстрые и требует меньше памяти;
Сверточные слои сходятся быстрее и лучше обобщают благодаря сильному индуктивному смещению;
Слои внимания обладают большей пропускной способностью, что позволяет им обучаться на больших наборах данных;
MBConv сочетается с относительным вниманием; идея состоит в том, чтобы суммировать глобальное ядро статической свертки с матрицей адаптивного внимания либо после, либо до Softmax нормализации (они выбрали пре-нормализацию);
Вертикальная компоновка
Первая задача, которую необходимо решить, заключается в том, что применение относительного внимания к исходному входному изображению будет затратным с точки зрения вычислений. Авторы пробуют два подхода:
сверточный stem-блок 16x16 (как в ViT), а затем блоки L трансформеров с относительным вниманием
многоступенчатую (5) сеть с постепенным пулингом. Авторы пробуют четыре варианта: C-C-C-C, C-C-C-T, C-C-T-T и C-T-T-T, где C и T обозначают свертку и трансформер соответственно.
Эти подходы оцениваются на основе двух критериев:
обобщение (генерализация): минимальный разрыв между баллами по обучению и валидации. Чистый трансформер работает хуже всего; чем больше сверточных слоев, тем лучше;
емкость: лучшая производительность за такое же количество эпох. Чистый трансформер работает нормально, но лучше один или два сверточных блока;
Был проведен дополнительный тест: C-C-T-T и C-T-T-T были предварительно обучены на JFT и тонко настроены на ImageNet-1K за 30 эпох, C-C-T-T оказался лучше.

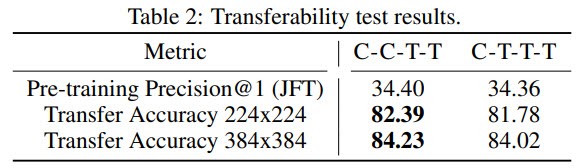
Модель и обучение

В семействе CoAtNet есть несколько моделей большого размера;
Модели предварительно обучены на ImageNet-1K (1,28M изображений), ImageNet-21K (12,7M изображений) и JFT (300M изображений) с разрешением 224x224 за 300, 90 и 14 эпох соответственно. Затем они тонко настраиваются на ImageNet-1K на 30 эпох на необходимое разрешение;
RandAugment, Mixup, стохастическая глубина, сглаживание меток, уменьшение веса;
Интересное наблюдение: если определенная аугментация отключена во время предварительной тренировки, то ее использование во время точной настройки может снизить производительность, а не наоборот улучшить ее. Лучше использовать эти аугментации с очень небольшой степенью, а не отключать их: это может снизить показатели до обучения, но может привести к повышению производительности при выполнении последующих задач;

Результаты


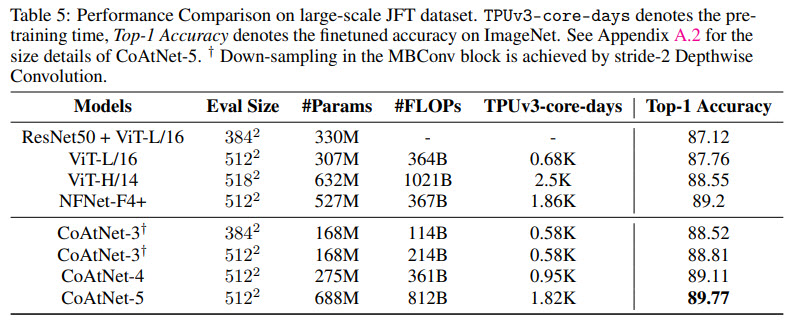
Когда CoAtNet предварительно обучена только на ImageNet-1K, она где-то на уровне EfficientNet-V2 и NFNets и превосходит ViT;
Когда ImageNet-21K используется для предварительного обучения, CoAtNet становится еще лучше;
Исследования абляции

Относительное внимание обеспечивает лучшее обобщение;
Мы должны добавлять блоки трансформеров для получения большей пропускной способности, но только до тех пор, пока количество блоков MBConv не станет слишком маленьким для правильного обобщения;
BatchNorm и LayerNorm дают схожую производительность, но BatchNorm быстрее;
В приложениях представлена дополнительная интересная информация, например, подробные значения гиперпараметров.

Материал подготовлен в рамках курса «Deep Learning. Basic». Если вам интересно узнать подробнее о формате обучения и программе, познакомиться с преподавателем курса — приглашаем на день открытых дверей онлайн. Регистрация здесь.