

В октябре прошлого года я опубликовал статью «О талантах, деньгах и алгоритмах сжатия данных», где с юмором описал, как «изобретают» новые алгоритмы сжатия люди, не имеющие достаточно навыков для реализации своих идей. А заодно рассказал про существующие конкурсы по новым алгоритмам, в том числе двигавшийся тогда к завершению конкурс алгоритмов сжатия с призовым фондом 50 тысяч евро.
Пост набрал 206 «плюсов», вышел на 2 место топа недели и вызвал оживленную дискуссию, в которой мне больше всего понравился комментарий: «Коммерческого интереса эффективность по сжатию алгоритмов сжатия без потерь сегодня не представляет, в силу отсутствия принципиально более эффективных алгоритмов. Деньги сегодня — в сжатии аудио-видео. И там и алгоритмы другие. Тема сжатия без потерь удобна именно лёгкостью верификации алгоритма, и не слегка устарела. Лет на 20.»
Поскольку я сам уже 20 лет в области сжатия видео, с ее бурным развитием мне спорить сложно. А вот что сжатие без потерь развиваться перестало… Хотя логика тут понятна каждому. Я до сих пор пользуюсь ZIP, все мои друзья пользуются ZIP с 1989 года — значит, ничего нового не появляется. Так ведь? Похоже рассуждают сторонники плоской земли. ))) Я не видел, знакомые не видели, и даже некоторые авторитеты утверждают, значит, это так!
О том, как Intel просили меня не прекращать читать курс по сжатию, ибо людей нет новые алгоритмы делать, я в прошлый раз писал. Но тут и Huawei в ту же дуду дует! Вместо того, чтобы раздать призы
Развивались ли алгоритмы сжатия без потерь в последние 20 лет? Чем закончился прошлый конкурс и на сколько опередили baseline? Сколько денег получили русские таланты, а сколько зарубежные? И есть ли вообще жизнь
Кому интересно — добро пожаловать под кат!
Про развитие алгоритмов сжатия
Арифметик
Давайте посмотрим, что произошло за последние 20 лет. Для начала — истек срок действия 5 патентов на арифметическое сжатие от IBM (которая их никому не лицензировала), и его теперь можно легально использовать повсеместно. Объясняю на пальцах, почему это важно. Большинство представляет сжатие без потерь как-то так:

Наиболее частые символы кодируем короткими цепочками, наиболее редкие — длинными. Примитивная магия префиксного кодирования позволяет разобраться, где в потоке бит начинаются и заканчиваются символы. Profit!
Когда я говорю студентам, что арифметическое сжатие позволяет сжать символ, например, в 3.5 бита, или в 1.273 бита, или даже, страшно сказать, в 0.0001 бита, у них происходит разрыв шаблона, ведь в рамках их

Источник: ветхие лекции 20-летней давности начинающего седеть автора
На реальных примерах смена Хаффмана на арифметик дает примерно +15% к сжатию при том же качестве, что позволило использовать его в JPEG-2000 и сказалось на популярности H.264 (2003) по сравнению с MPEG-4 (1998), да и в целом он удачно получился (о новых кодеках, надеюсь, сделаю отдельный большой пост, там тоже много нового интересного прямо сейчас происходит, о чем газеты не пишут).

Источник: Market share of top online video codecs and containers
А примерно 10 лет назад ([1], [2]) появились методы Asymmetric numeral systems (ANS), позволившие достичь степени сжатия арифметика при скорости и вычислительных затратах быстрого алгоритма Хаффмана, что с 2013 года привело к маленькой революции в быстрых практичных алгоритмах. Заметим, потребовалось 30 лет для создания быстрой версии эффективного алгоритма. Сейчас ANS используется в библиотеках Facebook Zstandard, Google Draco, JPEG XL и многих других свежих разработках. Замечу, что автор ANS Ярек Дуда входит в состав экспертного совета нового конкурса по сжатию, о котором будет ниже.
Контекстное моделирование
Но дальше интереснее. Чистый арифметик с безусловными вероятностями по сути никто не использует, популярны варианты так называемого контекстного моделирования (Context Modeling или CM), которое использовалось с Хаффманом, а с арифметическим сжатием заиграло новыми красками.
Основная идея CM — в ПРЕДСКАЗАНИИ следующего символа. Чем более точное предсказание дает наша модель для следующего символа (чем больше его вероятность, т.е. мы чаще его угадываем), тем сильнее сжатие (тем правее мы находимся на графике оптимального сжатия выше). Context Modeling уже в полный рост использует межсимвольные зависимости в потоке, и на довольно простом коде хорошо видно, как модель недообучается и переобучается (плавно увеличивается-уменьшается размер файла, сжатого без потерь, в зависимости от объема статистики модели).
«Стоимость», или вычислительная сложность моделирования, для сравнительно медленных, но хорошо сжимающих компрессоров минимум на порядок выше стоимости собственного сжатия (так называемого энтропийного кодирования). А для топовых по степени сжатия компрессоров — на несколько порядков, что сильно влияет на практичность алгоритмов, и позднее мы на этом еще отдельно остановимся.
Интересно, что долгое время, примерно 4–5 лет c 2009 по 2013, в топе известного рейтинга архиваторов Large Text Compression Benchmark Мэтта Махони был архиватор с прекрасным названием durilca kingsize, не без юмора названный так нашим замечательным соотечественником Дмитрием Шкариным. У него и до сих пор 8-е место в топе (для сравнения: у pkzip — 150-е место, у gzip — 148, у знакомого линуксоидам bzip2 — 118, у 7-Zip Игоря Павлова — 46). Алгоритм Дурилки основан на разновидности контекстного моделирования — PPM (Prediction by Partial Matching) — явном предсказании следующего символа по строке (контексту) ограниченной длины.
LSTM
Дальше — еще интереснее, на 6-й строчке рейтинга видим tensorflow-compress v3 с указанным методом сжатия LSTM. «Да это же рекуррентная нейросеть!» — воскликнет догадливый читатель. «Прям в точку!» — скажу я. Этот компрессор в открытых исходниках появился летом 2020 года
LSTM хорошо показали себя в предсказании следующего символа, и интересно, что идущий на пару строчек выше в рейтинге CMIX (4 место) — и тоже, кстати, доступный в исходниках — также использует внутри LSTM. Заметим, что его более быстрая и удачная модификация cmix-hp (2 место) была выпущена 10 июня этого года, всего 1.5 месяца назад!
Трансформеры
Ну и наконец, самое интересное. Как известно, трансформеры были разработаны в Google AI и сначала раскатали всех в переводе текстов, потом в обработке текстов (их производные: BERT в 2018 и нашумевшая GPT-3 в 2020), также хорошие результаты были получены для распознавания образов (тоже 2020). В январе 2021
В целом расклад по топ-30 выглядит так (даже до 7-Zip, простите, не дошел, чтобы названия лучше на графике читались):
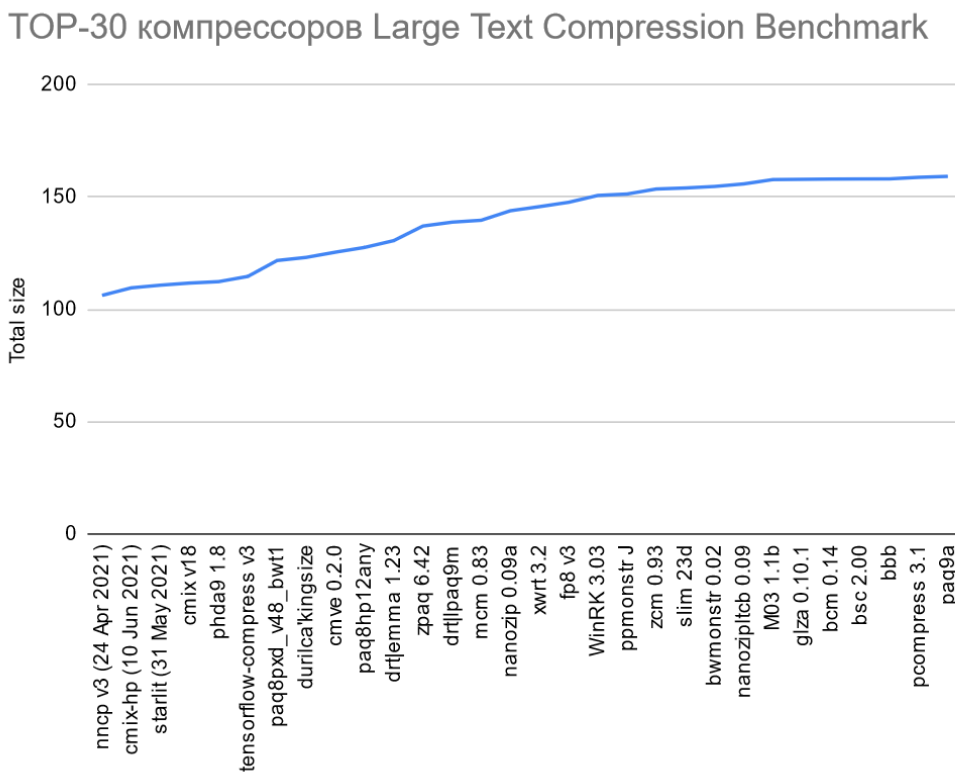 По оси ординат — сжатый размер 1 Гб файла данных английской Википедии (enwik9) с учетом размера декодера, в мегабайтах. У лидера преимущество по сравнению с 7-Zip — в 1.62 раза (!), по сравнению с pkzip — в 2.92 раза (архив почти в 3 раза меньше), причем в топе хорошая ступенька идет как раз с tensorflow-compress (привет, LSTM!), три первых места — свежак 2021 года, а рывок с трансформерами вполне себе убедительный (около 3% — это очень много в сжатии без потерь). И развитие на этом не остановится, очевидно. По ощущениям, развлечение с участием трансформеров и других нейросетевых архитектур в области сжатия только начинается.
По оси ординат — сжатый размер 1 Гб файла данных английской Википедии (enwik9) с учетом размера декодера, в мегабайтах. У лидера преимущество по сравнению с 7-Zip — в 1.62 раза (!), по сравнению с pkzip — в 2.92 раза (архив почти в 3 раза меньше), причем в топе хорошая ступенька идет как раз с tensorflow-compress (привет, LSTM!), три первых места — свежак 2021 года, а рывок с трансформерами вполне себе убедительный (около 3% — это очень много в сжатии без потерь). И развитие на этом не остановится, очевидно. По ощущениям, развлечение с участием трансформеров и других нейросетевых архитектур в области сжатия только начинается. Кстати, обделенный выше вниманием starlit (3 место, тоже LSTM) — это свежая (май 2021) опенсорсная разработка выпускника Физтеха Артемия Маргаритова, который закончил аспирантуру и работает в университете Эдинбурга в Шотландии.
По всем законам жанра где-то в этот момент должен нарисоваться злобный скептик и громко крикнуть: «Вы только посмотрите, сколько времени оно все работает!!!» Мой опыт учит относиться к таким аргументам с терпеливым юмором. Помнится, JPEG при его появлении требовал порядка 5 минут, чтобы распаковать файл, а для MP3 специально сделали облегченные версии (помимо Layer 3 — Layer 2 и Layer 1), поскольку даже на топовых компьютерах того времени слушать музыку в нем было невозможно — не хватало скорости. И кто сейчас об этом помнит? Правильно. Специалисты. Потому что эта история повторялась уже много раз. Последний раз, кстати, с появлением AV1 совсем недавно — буквально пару лет назад, когда даже просто погонять его на сжатии было большой проблемой. Спрос на ускорение трансформеров в ближайшие годы очень велик. Люди массово хотят классный real time переводчик на свой смартфон и чтобы при наборе текста подсказка продолжения работала еще лучше, поэтому работы над аппаратными ускорителями идут фантастическими темпами (кстати, новый пост про это — будет). А то, что сжатие данных на тот же ускоритель ляжет параллельно с улучшением сегментации фотографий — будет мелким приятным бонусом.
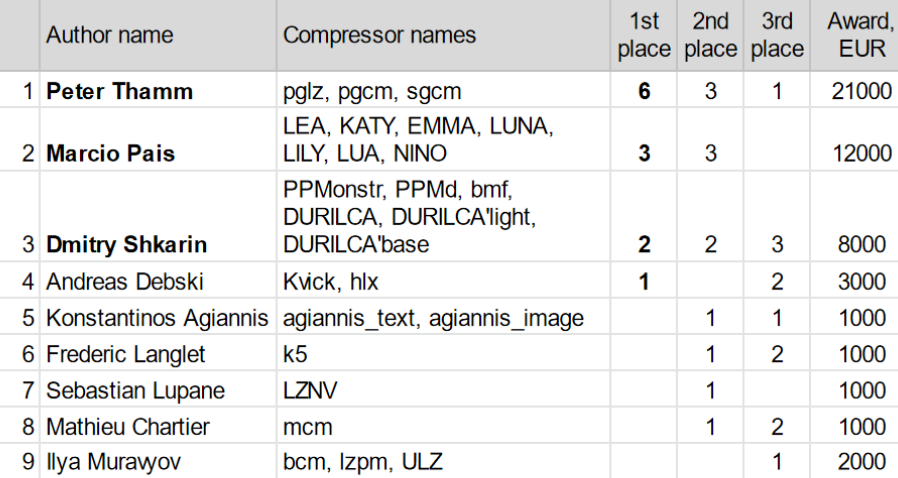
Стоит упомянуть о количестве исследователей, работающих сейчас в области сжатия без потерь. На запрос "lossless compression" с 2020 года (1.5 года) Google Scholar дает 4,2 тысяч статей, на "image compression" — 12,6 тысяч, а на "video compression" — 5,5 тысяч. Прикидка очень грубая, в частности, в топе выборки попалась статья «Lossless compression of deep neural networks», где речь идет об удалении слоев из глубокой сети, т.е. выборка заметно зашумлена. Более того, видно, что большинство статей по сжатию без потерь — это сжатие всевозможных специфичных видов данных, где действительно зачастую можно получить преимущество в несколько раз по сравнению с универсальными алгоритмами. И, кстати, работ по картинкам больше, поскольку с ними банально проще работать (отдельная интересная тема, как техническая сложность влияет на научную популярность области). Но в целом можно говорить о том, что чисто в области сжатия без потерь работает существенно меньше специалистов, чем в других областях. Примерно ту же картину можно наблюдать и в трудах наиболее известной и авторитетной в области Data Compression Conference, тем не менее свежих статей даже по энтропийному сжатию (еще более узкая область, чем просто сжатие без потерь!) довольно много.
При этом в лучших традициях современного информационного средневековья (когда в паре кликов — ответ на любой вопрос, но информационный шум забил каналы) существует параллельная вселенная массового сознания, в которой на вопрос о том, какой алгоритм лучше всего жмет, старший заслуженный инженер с 20-летним стажем в единственном (!) ответе Quora дает ссылку на примитивный алгоритм середины прошлого века (популярный в Windows 3.x, кстати!):
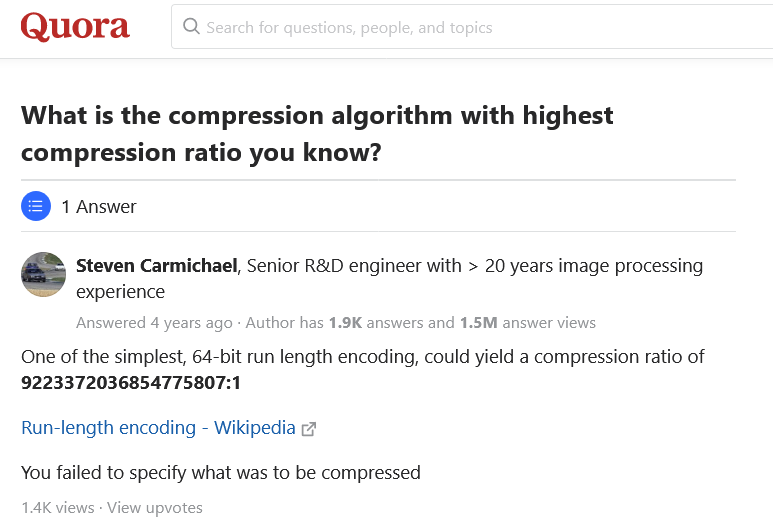
Источник: What is the compression algorithm with highest compression ratio you know?
Этот ответ достоин лучших финансовых консультантов — абсолютно точный и абсолютно бесполезный (поскольку верен только для огромных файлов жестко определенного размера, состоящих из одинаковых байт, например, нулей). С другой стороны, он прав в том плане, что характер данных не был указан. Хотел привести еще несколько сравнений вида «Best compression tool in 2020», которые «технические журналисты» и блоггеры делают на основе пресс-релизов продавцов архиваторов, даже не попытавшись включить мозг, но не стал. Всё с ними понятно… Так люди и не находят
Пара слов про сравнение алгоритмов сжатия без потерь
Качественное сравнение от массового отличает как минимум анализ времени работы. Большинство серьезных алгоритмов имеют ручку скорости, которая иногда может варьироваться в весьма значительных пределах (изменение степени сжатия в 2 раза при изменении скорости работы почти в 1000 раз):
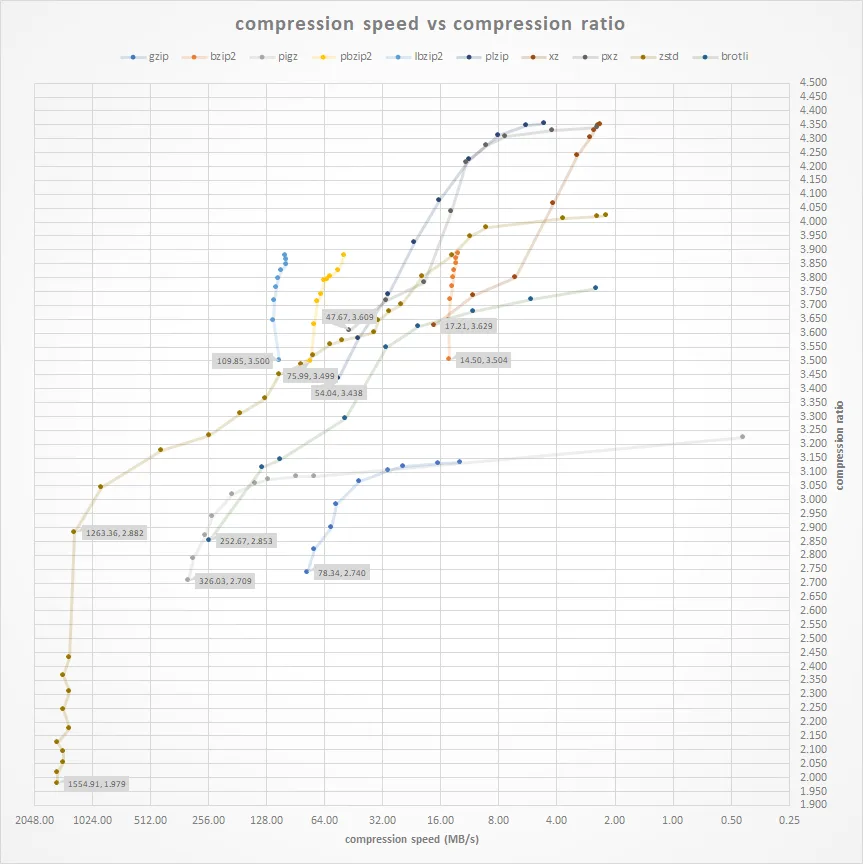
Источник: Compression Comparison Benchmarks: zstd vs brotli vs pigz vs bzip2 vs xz etc
Как правило, на графике степень сжатия/скорость получаются полукруглые кривые (часто зависимость близка к логарифмической), но на графике выше по горизонтали идет логарифмическая шкала, поэтому кривые вытягиваются почти в прямые и становится очень хорошо видно, как неравномерно они идут. При интерпретации таких графиков надо хорошо понимать, что результаты зависят от методов оптимизации конкретных реализаций алгоритмов, скорости памяти тестовой машины, размера памяти, размера кэша, характера данных и т.д. (то есть на разных компьютерах график будет разным!) У некоторых алгоритмов есть многопоточные реализации, и результат начинает зависеть от количества ядер. Чтобы жизнь медом не казалась, у современных алгоритмов появляется зависимость от наличия и мощности GPU, далее можно прогнозировать появление зависимости от TPU и т.д. В общем, чем дальше, тем такие бенчмарки становятся все сложнее в корректной интерпретации и интереснее.
На практике эти соображения приводят к нескольким важным следствиям:
- Во-первых, имеющиеся бенчмарки по сути используются как референс. Люди ищут там, кого в принципе имеет смысл гонять на своей задаче, и дальше, исходя из своих требований к скорости (в том числе отдельно скорости упаковки и скорости распаковки) и результатов на своих данных, выбирают алгоритм.
- Во-вторых, доведенные до ума промышленные библиотечные версии алгоритмов серьезно отличаются от исследовательских авторских — в них реализовано много алгоритмов оптимизации, дающих лучшее сжатие (с расходом времени) или лучшую скорость (с просадкой качества) с большим количеством градаций, которые сбалансированы между собой и управление ими выведено в единую ручку скорости. Именно поэтому кривые выше идут столь неравномерно — под капотом работают разные алгоритмы. При этом большое количество положений ручки скорости дает, например, возможность в случае перегрузки CPU серверов понизить условно на 10% сжатие на трафике, но при этом сбалансировать перегрузку. Или наоборот, докупить серверов, закрутить ручку и получить экономию по трафику в зависимости от того, что важнее для компании сегодня.
Специально для очень суровых инженеров серьезных систем. Хорошая «промышленная» реализация и оптимизация нового алгоритма сжатия (с поддержкой работы в потоке и всеми видами оптимизации) иногда требует пары лет квалифицированной работы. В этом плане очень радует, что коммерческие компании (и в первую очередь Google) в последние 10 лет начали регулярно выкладывать годные реализации библиотек сжатия без потерь в open source (см. гугловые Snappy — 2011, Zopfli — 2013, brotli — 2013, PIK — 2017, Draco — 2017 и т.д.).
По факту алгоритм проходит через следующие стадии:
- Исследовательская версия: в ней течет память, ужасный код, и т.д. Его задача — не упасть на датасете бенчмарка, обогнав при этом всех. Под капот лицам с тонкой нервной организацией лучше не заглядывать, ибо чревато!
- Standalone архиватор: падает на 2-3 порядка реже, распакованный файл за редчайшим исключением совпадает с паковавшимся (ура!), сделаны какие-то оптимизации по скорости и вообще можно пользоваться, пусть не слишком удобно.
- Промышленная библиотека: отличный отдокументированный код, портированный под несколько архитектур, сжимает в потоке и командной строке, OpenMP и OpenCL реализации, много разных оптимизаций, удобные параметры, работает, как часы.
Многие суровые инженеры говорят — пока код не будет промышленного уровня, даже смотреть в его сторону не будем. А зря! Очень часто по более ранним версиям можно прикинуть экономический эффект (для кого-то он становится заметен с 20% экономии трафика или хранилища, а для кого-то и с 3%) и для крупных компаний — как минимум появляется о чем говорить с вендорами технологических решений (должен же их кто-то образовывать). Так что смотрите бенчмарки, измеряйте, пробуйте!
В качестве стартовых точек можно посмотреть:
-
Squash Compression Benchmark — отличный бенчмарк с 46 участниками на 28 датасетах. Увы, не обновляется, но представление о ситуации трехлетней давности дает очень хорошее.
-
Sequence Compression Benchmark — великолепно организованный специализированный бенчмарк сжатия ДНК данных. Сравнивает 19 универсальных и 31 специализированный компрессор на 27 наборах данных. Фактически этот бенчмарк породил отдельное направление исследований и позволил в разы сильнее сжать специфические данные геномов.
-
Large Text Compression Benchmark — самый долго обновляемый и большой бенчмарк по сжатию без потерь (в мае ему стукнуло 15 лет!), он содержит 201 участника (!) и дает хорошее представление о лучших алгоритмах, ориентированных на сжатие англоязычных текстов. На нем интереснее всего смотреть тренды и появление новых направлений исследований (много решений в open source).
Также имеет смысл смотреть участников конкурсов, особенно с большими денежными призами:
- Это, например, Global Data Compression Competition — наш недавний конкурс на сжатие текстов, картинок, смешанных данных и блоков по 32 Кб c призовым фондом в 50 тысяч евро, о чем будет ниже.
-
Hutter Prize — сжатие англоязычной википедии, в котором, кстати, в конце мая 9000 евро получил упоминавшийся выше бывший физтеховец Артемий Маргаритов, а до этого 4 раза подряд выигрывал наш коллега и соавтор Александр Ратушняк.
-
Sequence Squeeze Compression Competition — конкурс на сжатие ДНК данных с призовым фондом 15 тысяч долларов
- и свежий конкурс Global Data Compression Competition 2021 с призовым фондом 200 тысяч евро, результаты которого будут к концу года.
Легко заметить корреляцию между денежными конкурсами и популярными бенчмарками, они идут по сути на одних данных, для которых есть спрос. Специально для талантливых ребят замечу, что, судя по запросам компаний, спрос на сжатие специфичных данных есть заметный, но обычно компании не хотят заморачиваться новыми конкурсами, а просто стараются нанять победителей прошлых конкурсов (именно поэтому авторы топовых алгоритмов часто работают в Google, Facebook, Apple, Huawei и других интересных компаниях). Так что пробуйте и достигайте!
Итоги Global Data Compression Competition 2020
Что можно сказать про прошлогодний конкурс. Во-первых, он
Итак, поехали! Test 1 — сжатие большого массива текстовых данных. Ниже приведены избранные графики, результаты в категории Rapid, т.е. самые быстрые решения (жирным обозначены участники, обычным — baseline):

По оси абсцисс — общее время кодирования и декодирования в секундах (чем меньше, тем лучше), по оси ординат — коэффициент сжатия, вычислявшийся как отношение суммы размеров сжатых данных и декомпрессора к размеру исходных данных (чем меньше, тем лучше).
Чтобы было понятнее, кто является соперниками: Zstd — это упоминавшаяся выше библиотека Facebook Zstandard, которая появилась в 2015 году, имеет очень неплохие характеристики (во многом благодаря появлению ANS) и в исходниках выложена на GitHub. А brotli — это библиотека сжатия в открытых исходниках, развиваемая с 2013 Google, и через 8 лет развития он поддерживается в браузерах у 95% пользователей интернета. Если кто-то еще жмет gzip-ом (данные или трафик), вот вам мотивационный график, вы можете наиграть 20–30%, просто сменив архиватор на что-то свежее

И, вы знаете, в нашем бенчмарке получилось обогнать и Facebook, и Google, и имеющиеся популярные решения! Получилось настолько хорошо, что было неожиданно даже для нас, организаторов. Когда pglz (автор Peter Thamm) жмет на 20-30% сильнее Brotli при вчетверо лучшей скорости работы — это серьезнейший повод для новой промышленной библиотеки.
В категории изображений интересно посмотреть результаты на распаковке в средней скоростной категории (Balanced). Видно, как неплохо новые компрессоры обошли и JPEG-LS (2003), и, что особенно интересно, JPEG XL (2020), серьезную конкуренцию составил только PIK (2018), продвигаемый Google-ом (последние два — это ещё аргументы в копилку к вопросу об остановке развития):

В категории смешанных данных (Mixed data) борьба была очень ожесточенной и неплохо себя на Balanced показал даже старичок bzip2. Кстати, рекомендую полные графики посмотреть в лидерборде сайта (там в Mixed data тесте быстрые baseline решения были сильны, но в медленной категории High compression ratio удалось очень хорошо улучшить результат). Итак, результаты борьбы на Balanced:

И наконец, в четвертой номинации (независимое сжатие блоков данных по 32 Кб) из-за малого количества участников (новые таланты, это предельно прозрачный намек!) на парето-оптимальную кривую попал даже старичок zlib, но если есть вычислительные ресурсы, то новые подходы позволяют сильно уменьшить размер вашей базы данных или файловой системы:

Надо понимать, что многое зависит от задачи. Например, для случая резервного копирования может быть важно время упаковки и совсем не важно время распаковки, а для задачи распространения дистрибутивов, наоборот, не важно, как долго мы сжимаем, а важно, сколько ресурсов (время, память, GPU) тратится при распаковке. По графикам на сайте можно посмотреть соответствующие варианты, и лидеры на парето-оптимальной кривой могут существенно меняться.
Также важно учесть, как обстоят дела, если использовать разные параметры по скорости и качеству для наиболее популярных сегодня промышленных zstd и brotli. А вдруг, если им параметры покрутить, они будут сильно лучше? Ниже результаты лидеров для «Test 1, Rapid, 1 GB», хорошо видно, что они поддержали свое высокое реноме, уверенно обогнав топовые библиотеки от Google и Facebook:
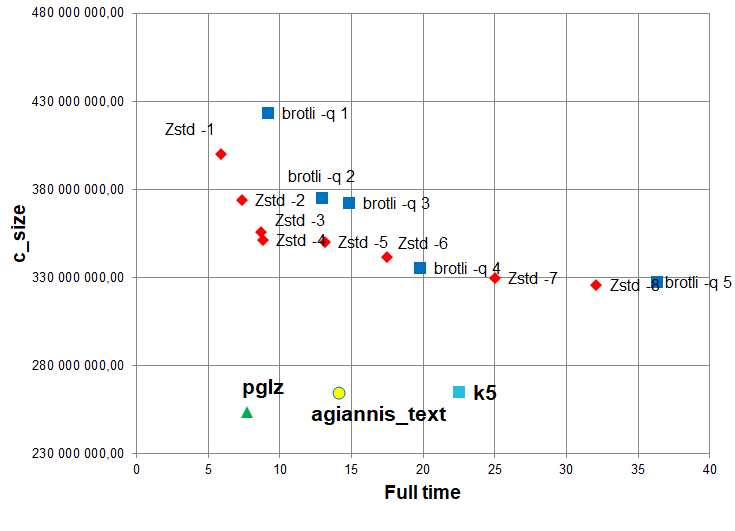
Источник: материалы автора
Ну, и самое интересное! Кому сколько денег досталось? В каждой номинации (текст, картинки, смешанный текст и блочное сжатие (базы данных), разные категории скорости) подводились свои результаты, всего 12 списков. Например, вот списки лидеров для картинок (Test 2):
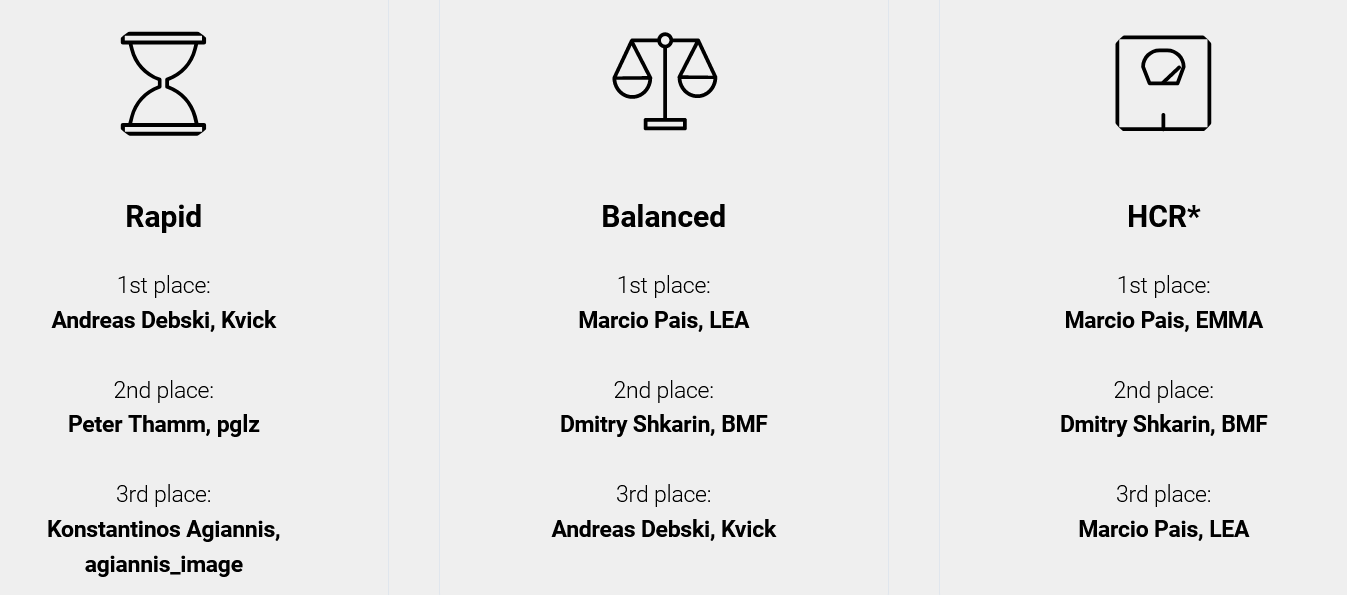
За 1 место было 3000 EUR, за второе 1000 EUR, за третье —
Источник: сайт конкурса, расчеты автора
Максимально один участник выставлял до 7 разных компрессоров (!). В сумме 3 автора за 16 топовых компрессоров получили 41 тысячу евро, в т.ч. Дмитрий Шкарин — 8 тысяч. Также специальный приз судей 2 тысячи
Про новый контест
По итогам прошлого проекта Marcio Pais (2 место «по медалям») писал: «It's been fun trying out some ideas that I kept postponing and seeing what worked and what didn't… If you are planning on continuing this project, I just hope that the format can be changed a bit to make things more interesting» (12 тысяч евро понравились, если будете продолжать, можно доработать правила, чтобы было интереснее). Yann Collet, автор lz4 и zstd, работает в Facebook, прислал очень теплые слова о конкурсе: «I applaud the existence as well as your leading of this Data Compression Competition, which I believe is very valuable for the field in general» («Я аплодирую появлению и проведению Data Compression Competition, который я полагаю очень ценным для этой области в целом»). Christian Martelock, автор референсных ccm, rzm, работает в Apple, писал: «I like your initiative and I hope that you will be successful in breathing some new life into the compression community» («Мне нравится ваша инициатива, и я надеюсь, что вам удастся вдохнуть новую жизнь в сообщество авторов алгоритмов сжатия»). Было много других положительных отзывов.
Естественно, при создании правил конкурса 2021 года постарались отзывы учесть, особенно замечания Marcio Pais. Суть там заключается в том, что, если заметная часть датасета открыта для участников и входит в финальный датасет, на котором производится сравнение, появляются не самые спортивные тонкие способы (толсто было нельзя — размер декомпрессора складывался с архивом) увеличить степень сжатия за счет того, что ты уже «знаешь» часть данных абсолютно точно. В условиях, когда не требуются исходники (да-да, в этом году ваши исходники снова не нужны), это становится особенно важно. В итоге в новом конкурсе все данные закрыты, есть только сэмплы (данные такого же типа), при этом можно участвовать в промежуточных прогонах и видеть свое место.
Интересно, что в прошлом году были письма типа «А если я не писал компрессоров, у меня есть шанс?» В прошлом году шансов по сути не было, а в этом введена специальная номинация для новичков, которая заключается в настройке имеющихся компрессоров:

Более подробно задача описана тут. По опыту, конкуренция со студентами из Юго-Восточной Азии простой не будет, но это не повод не попытаться!
Также в целом данные стали сложнее. Например, в тексте появились иероглифы, а изображения — это теперь не привычные RGB по байту на компоненту, а многоканальные 16 битные HDR и даже 32-битные floating point, хорошо известные профессионалам и очень специфичные по контенту (не фото, примеры скачать можно). К слову — как там сжимать в целом понятно, а область, в отличие от сжатия текстов, почти целина, что, на мой взгляд, заметно повышает шансы талантливых грамотных новичков.
Да, еще в этом году есть гран-при за быстрый блочный алгоритм и в каждой категории отдельно будет поощряться первое место, у которого будет заметный отрыв от второго (т.е. поощрение прорывных результатов). В целом все выглядит так:

Вместо заключения
Надеюсь, мне удалось показать, как интересно развиваются алгоритмы сжатия без потерь в последние 20 лет. После общения с компаниями понимаешь, что сегодня основная проблема области — количество нерешенных задач заметно превышает количество людей, которые хорошо разбираются в современных алгоритмах. Ровно за это сейчас Huawei платит деньги, причем подсвечивая таких людей не только для себя. Для компаний разница между «старыми» и «новыми» подходами легко может означать от 10% до 50% (а в узких случаях до 300%) «лишних» расходов на трафик или дисковое пространство и это часто кардинально бОльшие деньги, чем призовой фонд.
Как писали в свое время любимые Стругацкие: «Я вернулся на свой пост в приёмную директора, свалил бесполезные ключи в ящик и прочёл несколько страниц из классического труда Я.П. Невструева «Уравнения математической магии». Эта книга читалась как приключенческий роман, потому что была битком набита поставленными и нерешёнными проблемами. Мне жгуче захотелось работать...»
(с) АБС «Понедельник начинается в субботу»
В общем — основной аудитории этой статьи я искренне желаю успевать за прогрессом, мастерски владеть актуальными профессиональными знаниями и жгуче хотеть решать нерешенные проблемы!
А тем, кто чувствует в себе силы попробовать себя в алгоритмах сжатия, настоятельно желаю быть настойчивыми, глубоко копать и не сдаваться!
Дерзайте! И почаще занимайте первое место!
Читайте также:
-
О талантах, деньгах и алгоритмах сжатия данных — подробный текст о зарабатывании денег на алгоритмах сжатия вообще и конкурсе прошлого года в частности.
-
Уличная магия сравнения кодеков. Раскрываем секреты — как мы много лет свежие видеокодеки сравниваем и какие прикольные моменты там были (про одно из интересных направлений развития видеокодеков свежий прикольный материал лежит, надеюсь хватит времени пост сделать).
Благодарности
Хотелось бы сердечно поблагодарить:
- родную Лабораторию Компьютерной Графики и Мультимедиа ВМК МГУ им. М.В. Ломоносова за вклад в развитие сжатия медиа в России и не только,
- моих замечательных соавторов по книге «Методы сжатия данных», Максима Смирнова, Александра Ратушняка и примкнувшего к ним Евгения Шелвина, благодаря которым этот проект вообще стал возможным и нанес непоправимую пользу людям,
- компанию Huawei за смелость финансировать самый крупный в мире конкурс по алгоритмам сжатия без потерь,
- и, наконец, огромное спасибо Дмитрию Коновальчуку, Кириллу Малышеву, Ивану Молодецких, Егору Склярову, Анастасии Кирилловой, Андрею Москаленко, Евгению Зимину, Никите Алутису, Егору Чистову, Александру Яковенко, Екатерине Шумицкой и Дмитрию Клепикову за большое количество дельных замечаний и правок, сделавших этот текст намного лучше!
Комментарии (125)

sergeyns
02.08.2021 11:02+7Эээ, дело идет к тому чтобы обучать нейросеть (парочку трансформеров) под каждый архив?? Типа будем не видео кодировать, а выдавать сценарий и учить нейросеть по нему генерить кино «на лету» )))

3Dvideo Автор
02.08.2021 11:19+8Не секрет, что во многих массовых архиваторах (в том же RAR) была предобработка под разные типы данных (картинки, бинарники), которые благодаря ей получалось лучше сжать. Сейчас скорее в декодере будет несколько сеток лежать под разные типы данных.
С кино и видео - отдельная тема, но рендеринг без движка рендеринга на нейросетях очень прикольно и быстро развивается )
Aquahawk
02.08.2021 12:02рендеринг без движка рендеринга на нейросетях очень прикольно и быстро развивается
А можете накидать ключевых слов / ссылок, как на это глянуть?

cruzo
02.08.2021 14:07немного не в тему, но про рендринг игры без движка рендринга можно почитать про GTA GAN https://www.eurogamer.net/articles/2021-06-23-gan-theft-auto-is-a-snippet-of-gta-5-made-by-ai

cepera_ang
14.11.2021 13:49+1
masai
15.11.2021 14:01Технически там всё же есть рендерер, сетка отвечает только за представление сцены. Но штука интересная, и похоже, что хайп всё больше и больше набирает обороты.
cepera_ang
15.11.2021 15:06+1Ну да, совсем без рендерера — это GAN/diffusion models, но я там не помню, чтобы были прям "рендеры", скорее "рисование" по мотивам.


edo1h
02.08.2021 11:04+2а в сжатии коротких сообщений (сотня байт, например) прогресс есть?
я пробовал zlib/lz4/zstd/xz/bzip2, из-за коротких заголовков только zlib нормально себя показал
n0isy
02.08.2021 11:15+1А зачем их жать? Думаю, что задача пожать массив таких сообщений? Тогда и жать их надо порциями с балансом размер порции / ратио

tbl
02.08.2021 17:09В telegram bot api есть Inline Keyboard, и размер поля callback_data (отправляемый в бота при нажатии той или иной кнопки пользователем) не более 64 байт. При разных вариациях кнопок бота отдельную таблицу для декодирования айдишников запросов в команду на стороне сервера городить не хочется (тут начинают вылезать проблемы с тем, где хранить, очисткой старых данных, и т.п.), а в 64 байта уместить команду очень надо. Я структурированную команду паковал в protobuf+голый DEFLATE (без заголовков). Для небольших ботов с функционалом поиска (типа поиска билетов, или справочник для онлайн-игр) этого хватало с лихвой. Но думаю, что специализированные компрессоры должны себя лучше показать.
n0isy
02.08.2021 17:17+1Это тот случай, кода можно всё упаковать ID СУБД
tbl
02.08.2021 20:53+2Когда у тебя stateless-сервис, ради кнопочек тащить СУБД в проект - ну такое...

PrinceKorwin
02.08.2021 21:42Я в подобном проекте сделал временное key:value хранилище в памяти с TTL для записей. А в callback_data отправлял key. Тоже не хотелось тащить полноценный persistence. Но у меня и не скалировался этот сервис правда.
tbl
03.08.2021 03:29+2Если пакуешь в callback_data данные, то защищен от рестарта сервиса, т.к. персистентное хранение перекладывается на плечи телеги. Плюс горизонтальное сканирование забесплатно. Надо только не забывать подписывать данные (генерить MAC), хотя бы с транком до одного байта, чтобы уберечь себя от перебора значений в этом поле. Хотя последнее актуально и для ID, если они генерятся секвентально.
PrinceKorwin
03.08.2021 11:59Вы совершенно правы, но, блин, 64 байта - это чертовски мало :)

SGordon123
03.08.2021 13:42Что за команды такие, раньше в твитторе 140 символов все сообщение было ;-))
tbl
03.08.2021 13:52у меня были листалки поисковой выдачи вправо-влево, в команду паковались параметры поиска и номер следующей требуемой страницы
tbl
03.08.2021 14:03на самом деле там немножко меньше: 48, т.к. можно пользоваться только символами из UTF-8 диапазона, поэтому паковал еще в Base64

amarkevich
06.08.2021 12:30тоже используем protobuf, известный набор данных кодируется в enum'ы, на стороне сервиса свитчами разворачивается. да, код громоздкий, зато данные компактные
edo1h
04.08.2021 00:37А зачем их жать? Думаю, что задача пожать массив таких сообщений? Тогда и жать их надо порциями с балансом размер порции / ратио
https://habr.com/ru/post/479044/
задача сразу сохранить сообщение, а не накапливать «пачку», удобную для сжатия
3Dvideo Автор
02.08.2021 11:28+7Конечно. Еще со словарными методами там можно было заметно наиграть.
Вот, например, на гитхабе старый специализированный компрессор:
https://github.com/antirez/smaz SMAZ - compression for very small strings
Вот поновее:
https://github.com/unixba/b64pack - B64pack compresses short text messages
https://ed-von-schleck.github.io/shoco/ - shoco: a fast compressor for short strings
Ну и если сколар посмотреть - работы вполне есть, в том числе свежие.edo1h
02.08.2021 12:37это текстовые сообщения, а мне бы бинарные.

demoth
02.08.2021 16:41+2Несколько лет назад переписал алгоритм сжатия одной старой игры. В ней как раз маленькие udp-пакеты сжимались. Если интересно, можно потыкать:
go get github.com/koteyur/eimaster/cmd/lzevil(название алгоритма неофициальное).
Вот, например:$ head -c 100 /usr/bin/gzip | ~/go/bin/lzevil | wc -c 54 $ head -c 100 /usr/bin/gzip | gzip -9 | wc -c 68 $ tail -c 100 /usr/bin/gzip | ~/go/bin/lzevil | wc -c 30 $ tail -c 100 /usr/bin/gzip | gzip -9 | wc -c 47edo1h
03.08.2021 21:19немного поигрался, разница больше из-за заголовков gzip (которых 18 байт), в которые завёрнут поток deflate.
а так сам алгоритм очень похож на deflate, на моих данных deflate ведёт себя чуть лучше.

Alert1234
02.08.2021 11:42+2zstd умеет делать словарь по большому набору различных коротких сообщений.
Потом имея этот словарь, использовать его для сжатия/расжатия.
Получается достаточно эффективно. Я использовал такое чтобы базу из многих коротких строк сжимать.

aamonster
02.08.2021 19:18+3Тупой ленивый метод (так делать не надо, но для понимания возможностей сойдёт): берёте 100500 ваших сообщений (тренировочный набор), как образец. Сжимаете любым типовым методом.
Приписываете к тренировочному набору сообщение, которое надо передать, сжимаете. У вас получится новый архив, в котором добавилось сколько-то байт в конце. Только их и передаёте.
(на самом деле, конечно, не упаковываете/распаковываете каждый раз с начала большого файла, а просто откатываете упаковщик/распаковщик к состоянию после упаковки/распаковки тестового набора. Но оценить, насколько на самом деле сожмётся ваше сообщение, вы можете и так)
Ну, на самом деле есть методы попроще (не модифицировать состояние упаковщика в процессе упаковки/распаковки – для ppm-методов это довольно просто и ускоряет их работу).
Но гарантий, что ваше сообщение уложится в 64 байта, никаких. Так что сжатие сжатием, а делать отправку большого буфера несколькими сообщениями вам всё равно придётся.


IkaR49
02.08.2021 11:40+1У меня прям вот мечта ещё со старших классов школы создать свой крутейший алгоритм сжатия. Но, знаний и квалификации до сих пор не хватает, как-то в другую степь развиваюсь...
PrinceKorwin
02.08.2021 12:06+5Я таки нашёл время и будучи аспирантом сделал свой архиватор. Сжимал zip файлы ещё на 15% (максимум), но оказалось, что все запатентовано до нас.
И эта собака на сене и сама не выпускает архиватор и другим не даёт. Так и потерял интерес к этой теме.
Но у вас, возможно, всё получится.

edo1h
02.08.2021 11:45+1И наконец, в четвертой номинации (независимое сжатие блоков данных по 32 Кб) из-за малого количества участников (новые таланты, это предельно прозрачный намек!) на парето-оптимальную кривую попал даже старичок zlib
что-то странно, что zstd тут заметно медленнее zlib, ЕМНИП именно быстрым сжатием (при степени сжатия на уровне zlib) zstd и прославился.или тут какая-то мега-степень сжатия, а нормальная плохо себя показала (и не попала на приведённую часть графка) из-за малых размеров блоков данных?всё, сходил на страницу с результатами, разобрался.
ещё вопрос, бинарники не сжимали? или третий тест это оно и есть?и это нашёл )))
и раз были zlib/bzip2/zstd, почему не было lzma2 (7z/xz)?
3Dvideo Автор
02.08.2021 12:03Это совершенно нормально. У zlib разбор проще. У zstd в зависимости от уровня сжатия (параметр) сложные стратегии разбора. Кроме того, если речь про этот год и реф данные этого года, у zlib, помнится, словарь вроде 32к (надо проверять), а в этом году в референсе по 64к блоки, т.е. картина скорее всего несколько поменяется.
dijapif
02.08.2021 12:13-17-zip - архиватор, а не алгоритм. Зачем вы трижды упоминаете архиватор, сравнивая его с алгоритмами? Это совсем разные вещи. Уточните, о каких конкретно алгоритмах идёт речь. LZMA/LZMA2?

titbit
02.08.2021 13:12+4Зачем же мешать в кучу алгоритмы сжатия с очень разными свойствами?
По определению, любой условный файл (или группу) можно всегда сжать до условного 1 байта. Значит, надо соревноваться надо не только по коэффициенту сжатия и скорости, но и по объему данных (модели) для разжатия, например. И тогда монстроподобные нейросети уже будут смотреться на равных с каким-нибудь lzss, которому вообще не нужна память для распаковки.
Или вот еще пример из практики, мне нужен был несимметричный алгоритм сжатия для экономии траффика и ресурса флэш: сжатие на хилом контроллере (мало памяти и времени), разжатие на мощном ПК (ресурсов на порядки больше). Много вы знаете подобных алгоритмов? 90% описанных тут не годятся для этой задачи вообще.
Так что даже для алгоритмов сжатия произвольных данных без потерь надо рассматривать несколько категорий (в каждой будут свои победители).
1. Условно неограниченный по ресурсам упаковщик и распаковщик (память + время + размер данных/модели для сжатия и разжатия).
2. Неограниченный упаковщик (время + память) и жестко лимитированный распаковщик (нет памяти + нет объема для модели).
3. Жестко лимитированный упаковщик и неограниченный распаковщик (редкий случай)
4. Оба компонента жестко лимитированы, в идеале вообще не используют память.
И в каждой категории могут быть свои подкатегории, условно говоря когда, скажем, скорость важнее памяти или наоборот.
Вот такую табличку было бы интересно увидеть.
И тогда может быть выяснится, что в отдельных категориях прогресса нет те самые 20 лет?..masai
02.08.2021 13:57+3По определению, любой условный файл (или группу) можно всегда сжать до условного 1 байта.
По какому именно определению?
Если мы говорим про конкретный алгоритм сжатия, то он, возможно, какой-то файл и сожмёт до одного байта или даже бита, но за счёт того, что другой файл окажется больше, чем он был в оригинале.
Задача алгоритмов как раз в том, чтобы более вероятные данные оказывались короче, а менее вероятные нам уже не так интересны.
n0isy
02.08.2021 15:00Имеется ввиду, что если для разжатия требуется запустить нейросеть, весом 305 гигабайт, на компьютере с топовым GPU, то надо как-то оценить эти затраты. Допустим добавить эти 305 гигабайт к архиву.

TheDaemon
02.08.2021 17:55+2А я вот согласен с @titbit, что во многих случаях требования к распаковщику и упаковщику могут быть "весьма специфичными" и многие случаи заслуживают отдельных конкурсов :)
Например:
Любые асимметричные применения: инсталятор может упаковываться долго и при этом жрать все ресурсы билд-сервера/фермы билд-серверов, так как упаковывают его один раз. Распаковывать его будут тысячи клиентов, поэтому хорошо бы ему делать это быстро и с минимальными ресурсами. Сюда же IoT (сервер и микроконтроллеры), g-code для станков и т.д.
тонкие каналы и мощные вычислители: неважно сколько ресурсов требует упаковщик и распаковщик снимков с марсохода (спутниковый интернет на северном полюсе, связь с подводными лодками и т.д.). Канал связи с ним довольно узкий, а вычислительных ресурсов у NASA более чем достаточно. Учитывать при этом объем распаковщика будет не очень логично;
потоковое сжатие на магистральных каналах связи: ресурсы упаковщика/распаковщика условно-безграничные, но должно работать с минимальным latency и максимально параллелиться;
можно рассмотреть эволюцию стоимости вычислительных ресурсов: стоимость 305 гигабайт на SSD примерно 1000р. Как быстро окупится постоянное хранение 305 гигабайт, если это позволит сэкономить 10% интернет трафика (поднять скорость на 10%), при стоимости интернета 500р/мес? А если считать в рамках крупной организации? Можно учесть, что производительность процессоров, количество ядер, объем/скорость оперативки, объем/скорость дисков и т.д. дешевеют не очень равномерно. Например, раньше быстро расла производительность ядра, а теперь растет их количество, т.е. теперь для алгоритмов важнее возможность распараллеливания.
можно также рассмотреть: архивное хранение "холодных" данных; большие объемы сырых, но хорошо структурированных и повторяющихся данных в научных исследованиях; сжатие коротких пакетов/сообщений; гомоморфное сжатие (возможность проводить операции, не распаковывая); сжатие в условиях возможных потерь/искажений кусков данных (учет возможностей и особенностей алгоритмов, обеспечивающих избыточность); интеграцию сжатия с алгоритмами шифрования (сейчас жмут потом шифруют, но есть мнение, что сжатие может рассматриваться как кусок алгоритма шифрования, так как на выходе хорошего компрессора данные статистически приближены к "случайным") и т.д. на сколько хватит фантазии :)

encyclopedist
02.08.2021 18:34+1В этом конкурсе и так 12 категорий, которые отличаюся в том числе приведенными вами критериями.
3Dvideo Автор
02.08.2021 19:03во многих случаях требования к распаковщику и упаковщику могут быть "весьма специфичными" и многие случаи заслуживают отдельных конкурсов :)
Однозначно так!)
Вообще, если дальше пойдет такими же темпами (в первую очередь ускорение нейросетевых методов), то стоимость конкурсов по алгоритмам сжатия можно будет проводить просто Kaggle (что резко снизит себестоимость организации конкурса для компаний и повысит их популярность).
3Dvideo Автор
02.08.2021 17:54+2Зачем же мешать в кучу алгоритмы сжатия с очень разными свойствами?
А кто мешает? ) Выше в тексте вот прям специально для вас сказано, что есть много разных случаев и бенчмарки обычно на практике используются, как страртовая точка для своих экспериментов. Плюс приведены примеры бенчмарков, где больше параметров можно использовать для более детального сравнения.
Текущие 12 категорий были взяты чтобы с одной стороны покрыть основные интересные компаниям кейсы, с другое - не сделать сравнение слишком узким, чтобы был смысл в нем участвовать (и так приз получился не слишком большим в каждой категории).
И тогда может быть выяснится, что в отдельных категориях прогресса нет те самые 20 лет?..
Т.е. 12 категорий GDCC 2020 никак не коррелируют с ответом на этот вопрос? ))))
titbit
04.08.2021 12:06Если я правильно понял статью, то подавляющее большинство алгоритмов можно отнести к пункту 1 моей классификации, что конечно здорово, но интересен прогресс и в других пунктах. Я не смог увидеть никаких улучшений по пунктам 3 и 4. Поправьте меня, если я что-то упустил.
3Dvideo Автор
04.08.2021 18:53Поправляю) Статью вы поняли правильно, но в ней речь идет о конкурсе, а не о бенчмарке. Главное отличие между ними в том, что в конкурсе платятся деньги. Прямое следствие - во-первых, попытки читерить разной степени продвинутости (про это было в предыдущей статье и такие попытки были) и на это уходит много усилий. Во-вторых, в конкурсе важно приз за номинацию побольше, иначе он станет неинтересен.
В прошлый раз "размазали" 50 тысяч по 12 номинациям (по 4 тысячи в каждой + 2 в резерве) и это в принципе немного. Понятно, что можно было подавать любое количество программ (что является нагрузкой на организаторов), за счет чего победители и получили заметные суммы, но членам жюри известны конкретные люди, которые могли бы дать хороший результат, но не стали напрягаться, в силу не слишком большой суммы. Именно поэтому в конкурсе этого года не стали увеличивать количество номинаций - те же 12 + студенческая, но уже на 200 тысяч (хотя нам тоже интересен прогресс в других областях). Но "разбудить" еще участников интереснее.
Можно предложить заинтересованным лицам сделать специализированный конкурс или бенчмарк, это было бы классно!
encyclopedist
02.08.2021 18:22+3Размер декомпрессора включается в размер сжатых данных.
titbit
04.08.2021 12:13По хорошему надо еще размер используемой памяти включать. Очевидно, что при одинаковых размерах распаковщика и объема сжатых данных, алгоритм не требующий память намного круче алгоритма требующего гигабайты (это условный пример), и это надо учитывать. Потому что есть хилые железки, контроллеры (я вот писал сжатие для контроллера с 128 байтами (!) памяти всего — msp430f1132 кажется), и там 99.9% приведенных алгоритмов вообще не работоспособны.


iskatel
02.08.2021 16:07+4"... поблагодарить: компанию Huawei за смелость финансировать самый крупный в мире конкурс по алгоритмам сжатия без потерь,"
а кроме Хуавея у остальных не нашлось даже таких, очень скромных сумм .
При том, что и они, и другие имеют с этого хоть и косвенные, но немалые бонусы.
Молодцы, что тут скажешь.
Teplo_Kota
02.08.2021 17:20+1Кроме алгоритма, есть ещё то, как ты им пользуешься. Precomp использует тот же LZMA2, что и 7zip, но сжимает докуметны в 2-3 раза сильнее.
3Dvideo Автор
02.08.2021 19:07Есть очень большая тема препроцессинга, который может в некоторых случаях очень много дать (и в Precomp активно используется).

hedgeg
02.08.2021 17:44А что, скажем, с упрощением самого языка и, например, сокращением алфавита (хотя не за пределы 16 < символов < 32), т.е., получается, некоторой подгонкой исходных данных.
Должен же быть выигрыш в разнице за счет более простого языка и его конструкций (я подразумеваю эсперанто), особенно для предсказания следующих символов.
Окажется ли достаточным 5, тире 8 битов для кодирования всех символов и знаков?
Все резко захотели стать (воодушевились) пионерами в благом деле)TheDaemon
02.08.2021 18:07+2мощность алфавита и сложность языка просто снижают/повышают первоначальную эффективность кодирования информации данным языком :) Количество информации (энтропии) при этом не меняется. Оптимизация алгоритмов сжатия просто приближает объем выходного файла к объему содержащейся в нем информации.

graphican
02.08.2021 18:48+1Разработчику ПО была бы очень полезна сводка по:
лицензия под которой код доступен
Поддерживаемые платформы (esp32? etc.) и сложность интеграции
Размер компрессора / декомпрессора в скомпилированном варианте
Всё это, так же важно, как и стандартные параметры: скорость сжатия/распаковки, потребление памяти, коэффициент сжатия для разных типов данных и разного размера данных, многопоточность.

BugM
03.08.2021 00:32+2Там в статье было же.
Это не промышленный код. Это соревновательные примеры. О платформах и лицензиях рано еще говорить.
3Dvideo Автор
03.08.2021 07:19+1Ровно так. Это не бенчмарк, это конкурс. Основная проблема конкурсов - за счет появления приза в нем появляется заметное количество махинаторов разной степени хитросделанности и основная задача (и трудозатраты) - их фильтрация. Про это подробнее в прошлом посте было. В этом конкурсе они тоже были, но поскольку стартован новый конкурс я не стал облегчать им задачу и про это рассазывать ))), тем более что в этом году их явно будет больше ) (надеюсь, что не в 4 раза).
Бенчмарки мы тоже делаем, например, многолетний - сравнение кодеков (кстати - из-за опыта в нем нам доверили этот международный конкурс), матирования, видеозаполнения, супер-резолюшена, смен сцены, деинтерлейсеров. И еще пару новых бенчмарков собираемся опубликовать в этом году (в т.ч. очень прикольные). Если бы каждая университетская лаборатория программистских факультетов в России делала столько бенчмарков, бенчмарки с русскими корнями встречались бы на три порядка чаще. )))
Увы, покрыть все темы наших возможностей физеологически не хватает. Помогайте! )graphican
03.08.2021 10:25Вот бы конкурс не "архиваторов", но библиотек компрессоров: 7zip архиватор не так интересен, как LZMA, входящий в состав SDK. А то получается, что zlib - всё наше.
Кстати, есть множество узких ниш, где могли бы пригодиться, например, BMF или bCdr, но не как исполняемые файлы, а как исходники под MIT, скажем. Дмитрий Шкарин исходники не опубликовал к этим алгоритмам?
3Dvideo Автор
04.08.2021 10:17Конкурс - это условно "хакатон" - в нем главное - показать работоспособность идеи. А библиотека - это промышленное программирование и удел либо компаний, либо open source (либо и того, и того)). От компаний скорее можно ожидать спонсирования библиотеки под своим брендом.
На конкурс исходники принципиально не требовались - все вопросы к лауреатам (которых сейчас на части рвут компании))).

toxicdream
02.08.2021 19:16+2Не нашел в рейтингах древний КГБ-архивер.
Помню решил проверить легенду: специально нашел таки запакованный им в 1,44 Мб дистрибутив MS Office 2003, дождался распаковки, установил на чистую систему и проверил работоспособность.
Был сильно впечатлён. Дважды. Второй раз - временем распаковки - что-то около 4 часов.

alex_shpak
02.08.2021 19:52+3Википедия пишет, там используется алгоритм PAQ, который в 2007 году сжимал википедию до 133 Мб. На третьем графике в данной статье (где про Large Text Compression Benchmark) он был бы на 9~10 месте, что, я так понимаю, достойно для over-10-летнего алгоритма.
TakashiNord
02.08.2021 20:07-1лет 15 назад помню в универе, мы тоже придумывали - разные архиваторы, стремясь перехватить славу zip и rar. А потом, мы вышли в жизнь....
Может быть, подобные алгоритмы хороши для передачи фото Илона Маска в марсоход. На Марс.
Но, представьте, обычную организацию - несчастные промсервера G5\G6\G7 у них - задача хранить бухгалтерию, какую-нибудь базу эдак гигов на 500-600. все это сжимать, бакапить за приемлемое время , при этом, сохранять отклик... И алгоритм, должен был общеизвестен. Могу представить, в какой осадок выпадет весь Ит-отдел, если мы ему подсунем Durilka. :)
edo1h
02.08.2021 20:19+4И алгоритм, должен был общеизвестен
ну пример zstd, brotli показывает, что ничего нереального в появлении нового стандартного алгоритма нет — несколько лет назад их не было, а сейчас они на каждой кофеварке.
ладно, за этими двумя стояли мега-корпорации, но xz тоже не так давно набрал популярность.TakashiNord
03.08.2021 04:08а я и не отрицаю.
может быть пройдет еще 20 лет, и на смену нынешним алг без потерь (словарных), или для видео - придет, что нибудь.
alex_shpak
03.08.2021 10:45+1Ну так очевидно же, для тех кто ведет двойную бухгалтерию:
архиватором KGB (о котором вспомнили веткой выше) жмем "белую"
архиватором Durilka жмем "черную"
И тогда IT-отдел их точно никогда не перепутает!

sterr
02.08.2021 20:23-8Я не понимаю зачем это. Ну то есть это наверное круто — жать сильнее, чем ZIP. Но дело в том, что сейчас везде почти несжимаемые данные — видео, фото. Да и производители винтов и ssd вроде идут вперед семимильными шагами. Оперативка дешевеет. Сетки везде гигабитные и выше. 5G, 6G, WiFi6. Я понимаю, когда ходили друг к другу с пачками дискет. Вот тогда это было ой как критично. Искали самый лучший архиватор. И он по моему (не помню уже) был .ha. Жал лучше всех. Потом появился RAR, но он уже сильно долго жал на максимальной компрессии. Опять же, мало сжать. А если данные повредятся? Есть возможность восстановления?

Ivan22
02.08.2021 21:23+3фото и видео - это не сжимаемые данные???? "а, мужики-то не знают" (с)
sterr
02.08.2021 21:39Ну я лет 20 назад пробовал сжимать МП3, чёт не впечатлило. Ну попробуйте сжать H265, может быть вам повезет.
dijapif
02.08.2021 23:11+11MP3, как и H265 - это и есть уже сжатые данные. И сжаты они как раз алгоритмами, которые появляются благодаря таким вот людям, которые занимаются разработкой новых алгоритмов. Вы и правда не понимаете, о чём говорите. Так что лучше воздержаться от обесценивающих высказываний и разобраться в теме, прежде чем высказываться по ней.
sterr
02.08.2021 23:43Так и я о том же. Большинство данных уже сжато. Но в данной статье идёт речь о сжатии без потерь, что об МП3 и остальных не скажешь.
alex_shpak
03.08.2021 00:14пнг?

g5p4m7
04.08.2021 20:03Пф, Ничем не отличается от BMP, сжатого на NTFS-разделе…
Изредка и GIF может меньше PNG весить, но вот многие «здоровенные» монохромные PNG жмутся всё-таки лучше!
Раз уж упомянули аудио, то вот. Меня удивило "парадоксальное" сжатие 96kHz в такие форматы, как .ogg, .aac и .m4a… А вынуждают сохранять записи в mp3 какие-нибудь у района "колоночки" или "муз.центры"… Странно: мой Symbian отказывается воспроизводить .OGG .MP2, но отлично воспроизводит 96-килогерцовые .m4a и .aac!
А вот с древнейшими "форматами без потерь" есть даже такое сравнение: https://www.firstpr.com.au/audiocomp/lossless/
(зачёркнутым привожу то, что не воспроизводит "на лету"):WaveZip (MUSICompress)| Shorten |Pegasus SPSjpg|SONARC|WavArc| LPAC | WavPack |AudioZip| Monkey's | RKAU | недотестированные FLAC с OptimFROG, ещё сказано про DAKX, а на 3/3 страницы идёт объяснение алгоритма Райса!
3Dvideo Автор
03.08.2021 10:11+4Но в данной статье идёт речь о сжатии без потерь, что об МП3 и остальных не скажешь.
Не поверите, но в прошлой статье как раз я рассказываю, как мы 17 лет назад делали компрессор MP3 (рабочее название проекта было MP3ZIP, коммерческое - SoundSlimmer) и достигли сжатия в 1.2 раза на большой коллекции файлов. Это была перепаковка, но без потерь. Если поискать, в сети даже программу можно найти, а в прошлой статье были ссылки на патенты с описанием метода))) Это кстати, непросто было, 6 человек 2 года работали. Основная головная боль была - работа с битыми MP3, которых довольно много к сожалению. AAC тоже тогда сжали, кстати, но слабее.
Я люблю про этот проект рассказывать, когда кто-то про несжимаемость медиафайлов говорит. И даже под настроение могу рассказать, как именно это можно сделать и за счет чего ;)))

Balling
02.08.2021 21:32+1Это ключевая часть HTTP 2, например. Специальный алгоритм сжатия… и .zstd файлы очень классно сжаты.
О, и еще там же есть сжатие exe пакерами. Это заставляет быстрее грузануть в ОЗУ, а там раскпаковка дешевле.
lamerAlex
03.08.2021 11:39Это заставляет быстрее грузануть в ОЗУ, а там раскпаковка дешевле.
И подложить свинью системе управления памятью, ага.
tbl
02.08.2021 21:36Опыт кликхауса показывает, что даже в случаях с использованием SSD сжатие не стоит отключать из-за просадки по производительности (не говоря уже про экономию места). Там, по-моему, по дефолту lz4 используется


inetstar
02.08.2021 22:31+1Да, лучше такой конкурс, чем никакой. Но, если учесть, что за многолетний труд программист получит 10-20к евро, то это просто хедхантинг талантливых аутистов корпорациями.
3Dvideo Автор
02.08.2021 22:55Про это подробно было тут: https://habr.com/ru/post/525664/ )
inetstar
02.08.2021 23:18Ну зачем давать эту ссылку? Суть всё-равно такая же. На конкурсах/патентах денег не заработать.

SADKO
03.08.2021 00:16Если хочется денег, нужно начинать с осознания их природы и смысла. Тогда элементарные начала статистики и анализа, дадут вам больше, чем решение каких-то фундаментальных проблем.
В атомарном обществе, скрипач не нужен. Сейчас корона подогрела интерес к некоторым областям, и что же, есть боянистый метод, есть современные публикации, но зачем решать проблему на корню, если итеративно тянуть резину гораздо выгоднее :-)
Aquahawk
03.08.2021 08:16+3Конкурсы, конференции и прочие активности это в первую очередь дешёвая и очень таргетированная реклама. Для этого у вас должен быть продукт, о котором вы можете рассказать на конкурсе. И это невероятно важно и полезно.
DmitrySpb79
02.08.2021 23:09К ответу автора на вопрос «вы еще пользуетесь zip?» ответ простой - у меня уже лет 10 диск больше чем на 50% свободен :) Понятно что для пром.задач оно актуально, для дома же я последний раз игрался с ключами rar и 7zip наверно когда студентом был и на новый винт денег не хватало.
BugM
03.08.2021 00:37+1Вы в контексте ваша фирма. Где вы пишите софт или админите сервера.
И дисков там сотни или тысячи и за траффик платить надо. -10% размера всего, при той же загрузке ЦПУ, это солидный минус к расходам фирмы.

third112
03.08.2021 01:11-6Спасибо за интересный обзор. (Сожалею, что не могу за него голосовать).
Одного не понял: как юмор заголовка " развитие алгоритмов сжатия остановилось 20 лет назад" сочетается с итоговой фразой в конце?:Надеюсь, мне удалось показать, как интересно развиваются алгоритмы сжатия без потерь в последние 20 лет.
Развиваются или развитие остановилось??

phenik
03.08.2021 10:28+4По ощущениям, развлечение с участием трансформеров и других нейросетевых архитектур в области сжатия только начинается.
Несколько не в тему, но возможное интересное развитие темы сжатия с помощью нейросетей, для моделирования ментальных явлений, включая сознание. Лет десять назад группа авторов выдвинула идею, что компрессия лежит в основе функционирования сознания, см. одну из их публикаций Compressionism: A Theory of Mind Based on Data Compression, наряду с другими многочисленными объяснениями этого феномена. Они назвали свой подход компрессионизмом. Показалась эта идеи интересной с точки зрения когнитивных исследований. Почему? Потому как по мере обработки информации поступающей от органов чувств в вышележащие области мозга происходит ее пространственно-временное нелинейное сжатие. На эту тему существует масса исследований, см. напр., это. В ней авторы иллюстрируют идею этого сжатия такой схемой.Схема компрессииС помощью моделирования сверточными сетями можно объяснить такое поведение, благодаря суммативным способностям нейронов и их моделей, напр, для вентрального тракта зрительной системы. Однако в более высоких областях происходит обобщение (абстрагирование) этой информации, кот. также можно рассматривать как сжатие, и создание того, что можно назвать статистической моделью мира. Хотя в этом случае компрессия происходит с потерями. Возможно это как-то поможет объяснить так называемый разрыв в объяснении сознания, также называемой тяжелой проблемой объяснения сознания. Однако десять лет назад применение нейросетей и глубокого обучения только начинало раскручиваться, и авторы не могли привлечь подобное моделирование для проверки своих идей. Поэтому особого развития эта тема не получила. Сейчас нейросетевое моделирование весьма успешно применяется для решения различных когнитивных задач. Как например, оценка численности объектов, успешно моделирующая поведение биологического аналога, см. эту работу. Возможно работы по компрессии с помощью нейросетей вдохнут жизнь в компрессиониский подход к объяснению ментальных явлений. Вот тут автор развивает идеи в этом направлении.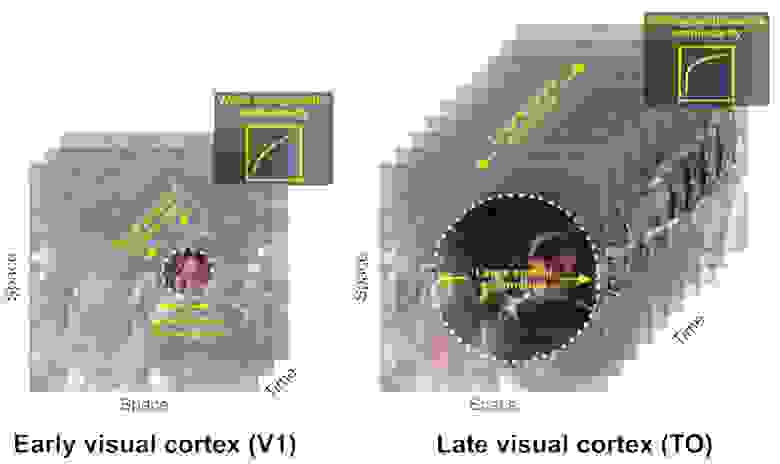
Спасибо автору за статью, весьма информативно.3Dvideo Автор
03.08.2021 10:39+2Спасибо за самый интересный комментарий к статье! )
Да, семантическое сжатие информации (в т.ч. аудиовизуальной) - это безумно интересная тема, которая очевидно будет активно развиваться, причем стартует лет через 5-10 (сейчас не хватает ни мощности датасетов, ни мощности акселераторов, чтобы развернуться в полный рост). Прикладная польза там будет в кардинальном улучшении поиска по картинкам, фрагментам видео, фрагментам песен и т.д. Революция будет (и уже начинается) в видеонаблюдении и т.д. Прикольная тема - автоматическое создание трейлеров и роликов (например, из видео, заснятых в путешествии) - тоже сжатие))) Мы последним даже побаловались, но пока отложили (многие блоки из которых надо собирать пока слишком слабы).


v1000
03.08.2021 11:25+2Иногда интересно сравнить старые файлы с новыми, и удивиться, как в одинаковом размере файла раньше умещался только звук не самого лучшего качества, а сейчас и звук и видео.

vitalif
03.08.2021 11:58+1А исходники pglz есть в природе?
3Dvideo Автор
03.08.2021 17:55+1Мы принципиально не собирали исходники в конкурсе. В природе они конечно есть)
vitalif
03.08.2021 21:27Ну просто их и в инете нигде нет, вроде алгоритм неплохой, но юзать без исходников никто ж его не будет :-)
Ну, хорошо, что наконец-то в ЛабКГММ занимаются алгоритмами сжатия. А не видеофильтрами для самсунга, бгг ))). // когда в 2005 выбирал кафедру — не пошёл на АСВК, потому что мне сообщили, что учиться мы не будем, а будем видеофильтры типа «мультфильм» для самсунга писать)3Dvideo Автор
03.08.2021 23:26+1Сейчас от автора зависит, как решит. Хантить его уже начали, причем походу в несколько мест)
По поводу того, что не будете учиться - вас грязно обманули)

Fahrain
03.08.2021 15:19А вот давно хотел спросить у разбирающихся…
Существуют ли архиваторы с "внешним" словарем? Ну т.е. если грубо, в старых архиваторах при упаковке создавался словарь, который и использовался для сжатия (а там уже вопрос в алгоритмах, как именно словарь делаем/используем).
Так вот, вопрос в том, не пробовал ли кто-то сделать архиватор, который таскает со своим исполняемым файлом большой словарь и при сжатии по факту ссылается на него, а не в данные файла полученного архива. В принципе, можно же иметь такой "внешний" словарь довольно большого размера с разбивкой под разные типы данных и в итоге получить большое сжатие?tbl
03.08.2021 16:04+1zstandard позволяет вести тренировки на данных и потом переиспользовать этот словарь для упаковки/распаковки новых данных


Nnnnoooo
03.08.2021 23:17Я понимаю что времени никогда не бывает много, но такой вопрос, а когда можно ожидать следующую статью?
3Dvideo Автор
03.08.2021 23:20+1))) В высокой степени готовности 2 статьи. До конца сентября хотел бы их выкатить (в тексте даже анонсы были), точнее я бы не обещал, ибо в августе будут разъезды.
cepera_ang
14.11.2021 14:03Хотя бы до конца года стоит ждать? :)
3Dvideo Автор
15.11.2021 07:44+2Со временем совсем плохо, но постараюсь)
Спасибо за мягкую мотивацию)
Wingtiger
04.08.2021 04:45Ты все еще пользуешься gzip (1992), старина?зипом и гзипом, потому что нужно упаковать на сотнях и тысячах машин с одним корявым "русским" линуксом, распаковать на винде, упаковать и затем распаковать на линуксе. И чтобы везде всё работало. И допсофт ставить на все эти линуксы это для извращенцев и мазохистов.
3Dvideo Автор
04.08.2021 09:47+5Понятно, что консерватизм - наше все и использовать софт дедов наших - святое дело. И понятно, что когда человек высылает архив в xz коллегам - это пижонство (даже если коллеги занимают сжатием))).
Но вообще я наблюдаю в России очень низкую профессиональную культуру сжатия данных. Возможно, это связано с тем, что в Кремниевой долине все смотрели сериал "Кремниевая долина" (где главный герой изобрел новый алгоритм сжатия и для них новые алгоритмы - это нормально), а наши айтишники смотрели сериалы первого канала (и просто не в курсе, что нового есть), не знаю.
Можно интересный тест сделать - распарсить, какие российские сайты отдают brotli (о котором я пишу в предыдущем предложении перед вашей цитатой). Его ведь 95% броузеров поддерживают (все, кроме странных встроенных броузеров планшетов, и отдать каждому его поток не проблема). И какие западные сайты его отдают. И даже можно пережать отдачу и посмотреть, где какой наигрыш (он от данных зависит сильно). И тут (внезапно!) откроются тайны великие, почему сайт условного Тинькова работает шустрее сайта условного Альфа-банка, даже когда сложные скриптовые графики отдает. А если с людьми поговорить, будут те же выводы, которые нам западные компании озвучивают (жестко не хватает специалистов).edo1h
04.08.2021 16:20Можно интересный тест сделать — распарсить, какие российские сайты отдают brotli
это легко объяснить.
почти весь рунет отдаётся nginx'ом; сейчас проверил, собранные пакеты nginx как в debian, так и на nginx.org не включают поддержку brotli, а общее правило админа такое: если ты не уверен, что тебе это нужно и «из коробки» оно не включено — не включай )3Dvideo Автор
04.08.2021 18:39Тем интереснее сравнить) Инициатива в подобных вопросах идет не от админов, а от архитекторов или (в небольших компаниях) CTO, т.е. напрямую зависит от их уровня подкованности.

Godless
04.08.2021 09:07+1Спасибо за статью.
Есть книженция некоторой давности. Но, думаю, для стартового погружения, может быть кому-то полезна: "Ватолин Д., Ратушняк А., Смирнов М., Юкин В. Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео. - М.: ДИАЛОГ-МИФИ, 2002. - 384 с. ". Читал ее еще в универе, весьма подробно описаны алгоритмы сжатия, вспомогательного преобразования и кодирования.
3Dvideo Автор
04.08.2021 10:00+3Я первый автор, а в жюри описанного выше конкурса первые трое ;)))
Полностью согласен с вами в оценке книжки ;)))))))))))) (сейчас уже много нового, но для старта - вполне)Godless
04.08.2021 10:37хехе) а я стеснялся спросить имеете ли вы к ней отношение))
Раза 3 перечитывал книгу. С первого раза не удалось уложить все в голову.
Впечатления от книги сугубо положительные. Спасибо за труд.

Vvvyg
04.08.2021 22:36Спасибо за статью. Представление о современных трендах в сжатии имею по форуму на encode.su, но здесь всё наглядно и понятно, со сравнением алгоритмов.

YuryB
08.08.2021 23:28+1очень интересно, а я думал, что в этой области движухи особо нет, конечно в новостях на хабре иногда мелькают сообщения о новых библиотеках, но потом это всё куда-то исчезает. Сжатие картинок у которых 16 бит на канал, кстати, востребовано фотографами, RAW файлы с камеры весят от 20 до 100 МБ за штуку и сжатие тоже хотелось бы иметь без потерь (ну или со специфическими малозначимыми), ведь иначе теряется весь смысл в RAW файле.
Overseer_Y
Отличная познавательная статья! Спасибо автору за труд.
3Dvideo Автор
Спасибо) В черновиках разной степени готовности еще 6 статей, но где время взять вечный вопрос)
Yoskaldyr
В последнее время все реже и реже статьи такого качества появляются на хабре!
Благодаря таким статьям остается надежда на то, что хабр все еще торт :)
Спасибо!
3Dvideo Автор
Буду стараться время найти, спасибо!)