
Как показывает опыт последних лет, самые интересные результаты в deep learning получаются при использовании больших нейросетей, обученных на массивах неразмеченных данных. Правда, для создания этих моделей нужен суперкомпьютер с десятками или сотнями мощных видеокарт, а также быстрым соединением между серверами. Но что делать, если таких ресурсов нет, а в открытом доступе хорошей модели под вашу задачу не нашлось?
Сегодня я расскажу про технологию, которая позволяет учить нейросети, объединяя через интернет вычислительные мощности энтузиастов из любой точки мира. В её основе лежит совместная научная работа Yandex Research, Hugging Face, студентов ШАД, ВШЭ и МФТИ, а также профессора Университета Торонто. Технология уже получила боевое крещение в ходе реального эксперимента, подробно описанного ниже. В конце статьи вы узнаете, как поставить такой эксперимент самостоятельно — модель и код доступны всем желающим.
Претрейн для всех, и пусть никто не уйдёт обиженным
За последние несколько лет во многих областях deep learning (например, в обработке естественного языка) стала популярной идея self-supervised learning. Оказалось, что для получения полезных в целевой задаче представлений не нужна большая размеченная выборка. Достаточно обучить модель на какой-то простой сигнал, построенный из неразмеченных данных, которых чаще всего в достатке. В частности, известные многим архитектуры BERT, GPT и языковая модель YaLM обучаются именно так.
На такие модели, однако, приходится тратить много ресурсов: обучение даже оригинального BERT-large занимало несколько дней на 64 TPU, а новые модификации и более крупные модели часто требуют ещё больше вычислений. Обучение BERT оценивается в 7 тысяч долларов, а в случае с моделями вроде GPT-3 сумма может достигать 12 миллионов долларов — терпимо для больших корпораций, но совершенно неподъёмно для энтузиастов и многих исследователей. При этом не для всех задач существуют качественные предобученные модели: например, из-за разнообразия мировых языков и доменов в NLP существует много областей, где специализированные нейросети по-прежнему работают лучше.
На помощь приходит парадигма добровольных вычислений (volunteer computing). Объединив мощности с другими энтузиастами, можно создать распределённую сеть, узлы которой будут совместно решать одну задачу. Такой подход давно и успешно используется в ряде научных областей, например, в моделировании свёртывания белка (Folding@home) или поиске внеземных цивилизаций (SETI@home), но стандартные методы распределённого обучения нейросетей здесь плохо применимы. Нужны технологии, которые умеют работать с нестабильным участием каждого компьютера, разнородным «железом» и варьирующейся скоростью интернет-соединения.
Специально для решения этих проблем мы разработали метод децентрализованного обучения Distributed Deep Learning in Open Collaborations (или DeDLOC), подробно описанный в препринте на ArXiv. Вместе с энтузиастами мы смогли обучить близкую к state-of-the-art модель для бенгальского языка (шестого в мире по числу носителей) на дешёвых и даже бесплатных ресурсах, не прибегая к использованию GPU-кластера. Модель и библиотека для децентрализованного обучения нейросетей находятся в открытом доступе (ссылки — в конце поста), поэтому можете применить этот подход к интересным вам задачам уже сейчас.
Коллаборативное глубокое обучение: что это и с чем его едят
Для начала вспомним, как устроено стандартное распределённое обучение нейросетей. Для простоты будем считать, что модель помещается на одну видеокарту. Самый распространённый подход называется data-parallel training: при обучении стохастическим градиентным спуском можно легко распараллелить по разным устройствам этап подсчёта градиентов по разным примерам в батче. Подсчитав их независимо друг от друга, участники процедуры затем должны усреднить градиенты и сделать шаг оптимизатора, сдвинувшись на одинаковый вектор.
Фактически применение такого алгоритма означает, что рост числа GPU кратно увеличивает размер батча на каждом шаге обучения. Если взглянуть на процесс с другой стороны и вспомнить, что на практике градиенты часто аккумулируют с нескольких шагов, можно прийти ещё к одному выводу: чем больше GPU, тем быстрее накопится батч нужного размера. Если учесть, что большие трансформеры и так обучаются на огромных батчах, нельзя ли сделать процесс накопления примеров постепенным?
Наш метод опирается на эту очень простую идею для обеспечения fault tolerance: каждый участник может в меру возможностей накапливать подсчитанные примеры и участвовать в формировании большого батча по всей коллаборации. Как только нужное число примеров достигнуто, все участники усредняют свои градиенты посредством Butterfly All-Reduce — эффективного протокола обмена данными, который позволяет получить среднее со всех узлов без роста трафика с числом компьютеров в сети.
Если какой-то участник отключится, это приведёт не к ошибке обучения, а лишь к незначительному откату в рамках одной итерации: остальные компьютеры возместят прогресс спустя некоторое время. Ещё одно полезное следствие: благодаря своей простоте метод математически совпадает с обычным распределённым обучением на больших батчах — менять саму процедуру оптимизации не требуется.

Пример двух итераций обучения с DeDLOC
Адаптивная стратегия усреднения
Сам по себе описанный алгоритм не решает проблему гетерогенности вычислительной сети: в кластере все узлы работают с одинаковой скоростью, каждый домашний компьютер тормозит по-своему. Попытавшись запустить стандартный Butterfly All-Reduce на компьютерах, соединённых по интернету, вы столкнётесь со множеством проблем и неравной загруженностью участников. Скорее всего, ваш метод будет передавать данные со скоростью самого медленного узла.
Чтобы учесть разнородный характер устройств участников, мы предложили адаптивный алгоритм усреднения градиентов, который явным образом учитывает информацию о производительности. Например, какие-то компьютеры могут обладать медленным соединением, но мощными видеокартами, кто-то может иметь быструю связь только с подмножеством узлов сети, а чей-то компьютер и вовсе может быть не в состоянии принимать входящие соединения.
Оказывается, можно динамически подбирать оптимальную стратегию усреднения на каждой итерации, пользуясь этими входными данными. Если не вдаваться в подробности, то идея алгоритма заключается в том, что усредняемый вектор разбивается не на равные части для каждого узла, а на пропорциональные их сетевой скорости: чем быстрее соединение сервера, тем большую часть данных можно на нем агрегировать. Если какие-то компьютеры не могут принимать входящие соединения, то они ничего не агрегируют и просто отправляют свой градиент другим участникам.
Любопытное следствие адаптивности заключается в том, что наш алгоритм в каком-то смысле обобщает существующие стратегии распределённого обучения, такие как All-Reduce или Parameter Server. Более того, в ситуациях, когда конфигурация сети оптимальна для этих методов, алгоритм сводится к ним же.
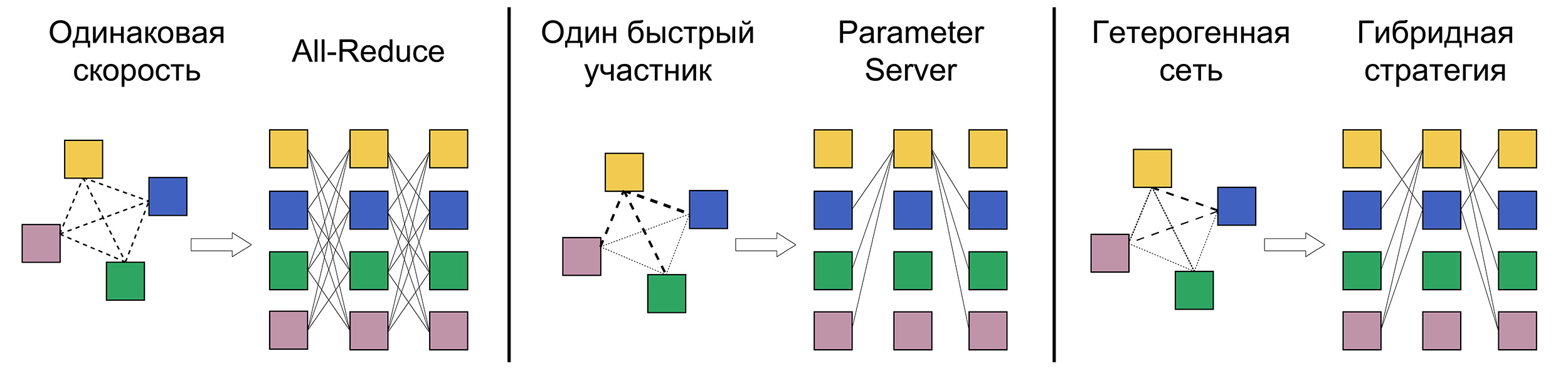
Примеры конфигураций участников с соответствующими оптимальными стратегиями усреднения
Обход NAT подручными средствами
Последняя интересная проблема, которую предстояло решить, связана со способностью компьютеров участников принимать входящие соединения. Если вы пользовались peer-to-peer передачей файлов или хостили игровые серверы, то наверняка сталкивались с проблемами закрытых портов, «серых» IP-адресов и прочими радостями домашнего интернета. Эти проблемы возникают из-за использования провайдерами Network Address Translation (сокращенно NAT) — метода, который сопоставляет нескольким IP-адресам локальных компьютеров один публичный IP-адрес и решает таким образом вопрос нехватки адресного пространства.
К счастью, есть технологии, которые позволяют обходить NAT разными способами: например, UDP hole punching или STUN. Их подробное описание можно прочитать в приложении к нашей статье на ArXiv. Здесь же отмечу, что для своих экспериментов мы выбрали сетевой стек проекта libp2p (поддерживаются языки Go и JavaScript), где есть ряд реализаций методов NAT traversal, успешно работающих в большинстве случаев.
В видео от Lucile Saulnier (оригинал — в блоге Hugging Face) представлена иллюстрация работы DeDLOC на нескольких примерах:
Все ключевые элементы децентрализованного обучения реализованы в открытой библиотеке Hivemind, созданной и разрабатываемой с участием исследователей Yandex Research. Она позволяет довольно легко адаптировать код обучения вашей сети на PyTorch под коллаборативный сценарий. Подробнее о применении библиотеки можно прочитать в документации или примерах.
sahajBERT: «народная» Transformer-модель для бенгальского
Даже самый элегантный алгоритм не всегда проходит проверку реальностью, особенно в случае deep learning. Чтобы протестировать работоспособность метода на практике, мы объединили усилия с Hugging Face — авторами известной библиотеки Transformers и хаба с предобученными моделями. Эта компания активно организует мероприятия с участием NLP-энтузиастов, и с их помощью мы связались с Neuropark — сообществом, заинтересованном в обучении BERT-like модели для бенгальского языка. Хотя этот язык занимает шестое место по числу носителей, для него есть не так много качественных предобученных энкодеров.
В качестве архитектуры мы взяли ALBERT, чьё главное отличие от BERT заключается в переиспользовании одних и тех же параметров на разных слоях. Это заметно снижает потребление GPU-памяти при обучении и трафика при усреднении. Для обучения использовалось бенгальское подмножество мультиязычного корпуса OSCAR. Мы общались с участниками эксперимента в Discord, чтобы оперативно отвечать на вопросы и рассказывать про текущий статус обучения с интерактивными графиками.
В эксперименте приняли участие 40 человек. Ни один суперкомпьютер в ходе обучения не пострадал: люди зачастую подключались к обучению буквально из Google Colab, используя подготовленные нами ноутбуки с инструкциями.
Само обучение продлилось девять дней, а каждая сессия участника продолжалась в среднем четыре часа. Полученная модель под названием sahajBERT выложена на Model Hub, так что её сразу можно загрузить в Transformers и протестировать. Там же можно увидеть, что на downstream-задачах она работает сравнимо или даже лучше как других моделей для бенгальского языка, так и многоязычной XLM-R от Facebook, где в 20 раз больше параметров, а для обучения использовалось 500 видеокарт Tesla V100.
| Модель | Распознавание сущностей |
Классификация новостей |
| sahajBERT | 95,45 ± 0,53 | 91,97 ± 0,47 |
| XLM-R | 96,48 ± 0,22 | 90,05 ± 0,38 |
| IndicBERT | 92,52 ± 0,45 | 74,46 ± 1,91 |
| bnRoBERTa | 82,32 ± 0,67 | 80,94 ± 0,45 |
Заключение
В этой статье я рассказал про метод DeDLOC, позволяющий совместно обучать очень требовательные к ресурсам нейросети, которые раньше нельзя было получить за разумное время без кластера под рукой. Несмотря на то, что у метода есть большой простор для улучшений (над которыми мы уже работаем) и он будет полезен не во всех сценариях, надеюсь, вам было интересно узнать о такой технологии. Будем рады пообщаться, если вам захочется узнать больше или запустить подобный эксперимент с друзьями. Код экспериментов из статьи опубликован на GitHub.
Что ещё можно почитать:
- Статья про DeDLOC на ArXiv
- Пост в блоге Hugging Face
- Hivemind — библиотека для децентрализованного обучения на PyTorch
- Discord-канал про коллаборативное обучение
- Сайт Yandex Research
- Твиттер-аккаунт с новостями Yandex Research и других команд
- Модель sahajBERT
Комментарии (4)

ANIDEANI
26.08.2021 14:00-1Люди не хотят что либо скачивать это выглядит подозрительно.
Проблемой ИИ на BOINC занимается MLC@HOMEЧто следует сделать яндексу. Если вам не всё равно на тему распределённых вычислений ИИ
Нужно.
1) что бы все вычисления производились в браузере
2) эти вычисления должны быть микро вычислениями до 1 минуты или до 5 минут3) виртуальное облако должно видеть всех участников через DHT или браузерную торрент сеть
4) за вычисления должны быть очки, и вознаграждение и планка сколько % отдать процессорау FOLDING HOME были вычисления в браузере, но они закрыли эту функцию. А было удобно. зайти на сайт, и вычислять пару часов и уйти.

iShrimp
26.08.2021 20:05Остался один шаг — сделать из всего этого криптовалюту.
И сразу решатся все проблемы, и воцарится мир и порядок: пользователи зарабатывают монетки, компьютеры заняты полезной работой (а не тупо греют воздух), вычислительная мощность сети неуклонно растёт...Кажется, что-то подобное уже было. Действительно, члены проекта BOINC восемь лет назад запустили собственную криптовалюту Gridcoin, которая один раз даже подскочила в цене до 1/5 доллара в начале 2018 года. Но кто вспомнит про неё сейчас, когда она стоит меньше цента. Вычислительных задач мало, потенциал для роста и расширения сообщества невелик, мануалы для новичков давно никто не обновлял. А главный недостаток такой модели - возможность злоупотребления вознаграждением, отсюда низкое доверие к результатам вычислений (одну и ту же задачу необходимо поручить минимум двум узлам и убедиться, что результаты одинаковые) и необходимость многоступенчатого контроля.
Arseny_Info
Очень интересный фреймворк, спасибо!
Вопрос: насколько сейчас такой метод обучения устойчив к adversarial атакам? Кажется, что малое количество злонамеренных участников может сильно повлиять на итоговые веса.
mryab Автор
Хороший вопрос! Проблема действительно важная: даже один участник может отправлять неправильные градиенты и дестабилизировать обучение, если не предпринимать никаких мер противодействия этому. Здесь в экспериментах мы использовали механизм аутентификации для допуска только доверенных участников, однако есть и более продвинутые методы.
В целом область науки, занимающаяся этой проблемой, называется byzantine-tolerant training, и существует не так мало методов для обеспечения устойчивости. В частности, в ещё одной нашей недавней статье мы предлагаем масштабируемый метод для защиты децентрализованного обучения: он опирается на устойчивую к выбросам агрегацию CenteredClip и идеи из secure multi-party computation для проверки случайного подмножества участников. Уже работаем над его встраиванием в hivemind, stay tuned!