
Недавно здесь, на Хабре, появилось несколько статей о достоинствах/недостатках VLIW архитектуры по сравнению с CISC и RISC. Но ведь и те и другие далеко не идеальны! Суперскалярные процессоры вынуждены тратить ресурсы на попытки распараллеливания последовательных команд и предугадывание возможных переходов, что не только ведет к перерасходу вычислительных ресурсов, но и просто небезопасно (вспоминаем Spectre и Meltdown).
VLIW предполагает выполнение длинных командных слов внутри которых может предполагаться выполнение до 23 (Эльбрус) параллельных инструкций. Однако и эта структура не лишена недостатков : длительность выполнения командного слова определяется самой медленной инструкцией (например деления или обращения к памяти); приходится для каждого ядра держать большой резерв вычислительной мощности в расчете на необходимость параллельного выполнения максимального числа инструкций; очень ограниченные возможности по распараллеливанию инструкций обращения к памяти; ограниченность параллелизма только шагом в одну инструкцию; необходимость предсказания перехода (как и в суперскалярных процессорах); и невозможность динамически разносить инструкции на параллельные потоки (количество одновременно исполняемых инструкций жестко прописано на этапе компиляции программы и не может быть изменено для процессоров с разными возможностями).
В этой статье я представлю свои мысли по альтернативной архитектуре процессора, которая должна объединить в себе достоинства RISC, CISC и VLIW архитектур.
Итак, представляю вашему вниманию процеонную архитектуру процессора :
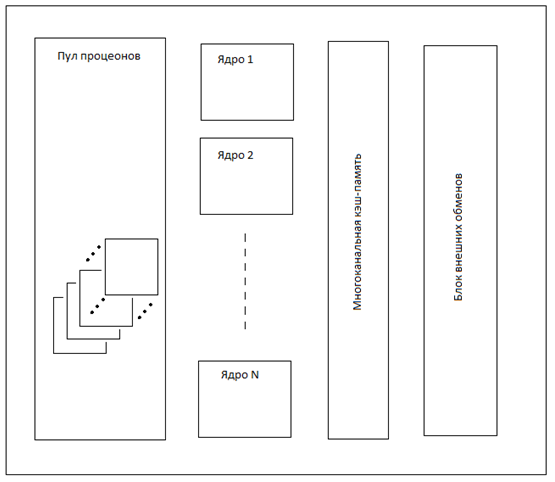
Пул процеонов (от Processor и Nucleon (протон или нейтрон)) – это набор SuperRISC процессоров, находящихся в ожидании или в выполнении линейки команд. Ядро – это управляющий процессор для выполнения потоков команд и управления обращениями к внешним данным. Многоканальная кэш-память обеспечивает быстрый доступ к наиболее часто необходимым данным. Блок внешних обменов транслирует запросы к внешней (относительно микропроцессора) памяти, внешним устройствам и обеспечивает приём внешних прерываний.
Ниже приводятся принципы для новой архитектуры (процеонная структура).
Процессор многоядерный.
Ядро не выполняет команды, а только управляет потоком команд и обращениями к памяти.
Команды выполняют процеоны – это SuperRISC процессорные ядра с ограниченным набором команд (ограничение прежде всего управлением исполнения программы).
Ядро обрабатывает целый блок команд – параграф (в дальнейшем под этим понимается замкнутый набор команд, после выполнения которых изменяется состояние программы. Можно сказать что параграф для ядра процессора – это команда), который содержит отдельно данные и отдельно одну или более линеек команд.
Параграф начинается префиксом и заканчивается окончанием. Префикс и окончание обрабатываются ядром.
Префикс определяет сколько линеек в параграфе, какой они длины и типа. Самая первая линейка – это данные для команд находящихся в рабочих линейках. Благодаря этому можно отделить команды от данных и сделать фиксированную длину каждой команды.
Окончание определяет какие результаты помещаются в регистры по окончанию работы всех команд параграфа. А так же какой параграф выполняется следующим.
Линейки команд выполняются параллельно (по возможности, если есть свободные процеоны). А команды в линейке – последовательно.
Процеоны (а значит и линейки команд !) могут быть разными (например процеон для целочисленных 32-битных операций, для работы с числами с плавающей запятой, для работы со строковыми данными, для работы с двойными словами и т.д.). Однако формат команд для всех процеонов един.
Система команд процеонов не содержит команд перехода, за исключением команды выполнить/пропустить следующую команду по условию и команд завершить линейку, завершить параграф. Флаги выполнения в процеонах не используются (за исключением переноса в целочисленных операциях для учета в следующей команде).
Процеоны не жестко закреплены за ядром, а выделяются для выполнения конкретного параграфа команд по мере необходимости. Если процеонов оказывается меньше, чем линеек в параграфе, то часть линеек выполняются последовательно.
Прерывание параграфа возможно только при неустранимой ошибке вызывающей аварийное завершение. В остальных случаях прерывание откладывается до окончания параграфа. Так например деление на 0 не вызывает немедленного прерывания параграфа, а только завершение одной линейки, в которой произошла ошибка.
Регистры процессора делятся на 4 группы : Регистры Общего Назначения (РОН (R0-R15) – 16 регистров по 64 бит, копии передаются в процеоны при старте линеек, по окончании линеек их комбинация копируется в ядро), локальные (временные / temporary) регистры процеонов (RT – 16 регистров разрядностью в зависимости от типа процеона, по окончании линейки значения теряются, при начале линейки инициализируются значениями от 0 до 14, последний получает значение -1), регистры данных (RD – доступны только для чтения, инициализируются данными 0-ой линейки или командами отложенной загрузки. Регистры не получившие данные – обнуляются), управляющие регистры (RF – 16 регистров: регистр состояния программы, счетчик команд, регистр следующего параграфа, управления кэш-памятью, регистры копирования, регистр блока коротких обращений к памяти и проч.).
Процеон может обращаться к памяти напрямую только в границах сегмента указанного в регистре блока коротких обращений к памяти (не более 4 ГБ – пространство адресуемое 32 битами, конкретный размер определяется в регистре флагов). Обращения за пределами этого сегмента возможны только в виде команд отложенного обращения к памяти (их выполнение откладывается до момента окончания параграфа).
Для уменьшения обращений в память есть 3 регистра копирования (в блоке управляющих регистров): стартовый адрес, конечный адрес и количество байт для копирования.
Все обращения к памяти и трансляцию адресов выполняет ядро. Процеон не имеет кэша и не преобразует виртуальные адреса в реальные физические.
Рассмотрим структуру параграфа :
Наименование |
Структура |
Префикс |
<Код префикса><Длина Данных (K) ><Количество линеек (N)> <Тип линейки 1> <Длина линейки 1 (L1)>…. <Тип линейки N> <Длина линейки N(Ln)> |
Данные |
<Слово 1> ….. <Слово K> |
Линейка 1 |
<Команда 1>…..<Команда L1> |
....... |
........ |
Линейка N |
<Команда 1>…..<Команда Ln> |
Окончание |
<Код окончания> |
Код префикса (4 бита + 3 бита резерв ) – код определяющий начало параграфа и его тип
Длина Данных (5 бит) – количество 64-разрядных данных для регистров данных (K – от 0 до 16, часть регистров данных может быть инициализирован через отложенную команду чтения или остаться 0)
Количество линеек (4 бита) – количество линеек в блоке команд (N – от 1 до 16)
Тип линейки (4 бита) – какой нужен тип процеона для выполнения данной линейки
Длина линейки (4 бита) – количество команд в соответствующей линейке команд (L от 1 до 16)
Код окончания (8 бит) – код определяющий как будет завершен параграф и как будут объединены регистры из процеонов в ядре.
Как происходит отработка ядром параграфа по типу 1 (базовому) при достаточном количестве процеонов:
Ядро выбирает префикс содержащий Код префикса, Длину Данных, Количество линеек (итого 16 бит)
Выбирает байты с длиной и типом линеек (в соответствии с Количеством линеек)
Считывает Данные в блок регистров данных (или заполняет данными из команд отложенного чтения)
Запрашивает нужные процеоны из общего пула процеонов
Инициализирует блок общих регистров каждого процеона копией РОН ядра, а Регистр Следующего Параграфа адресом следующим за Окончанием. Блок временных регистров каждого процеона инициализируется от 0 до 14 (RT0 - RT14) и -1 (RT15).
Передает каждому процеону его линейку команд
Ждет окончания всех линеек (в это время ядро может переключиться на выполнение другого потока – по аналогии с hyper-threading technology в процессорах x86)
Собирает данные со всех линеек по условию (код окончания определяет процедуру сбора РОН, управляющие регистры заполняются строго последними поступившими данными)
Передает управление по адресу из Регистра Следующего Параграфа
Как происходит отработка ядром параграфа по типу 2 (параллельный цикл). В этом случае в параграфе содержится только одна линейка команд, но которая будет выполняться параллельно на нескольких процеонах, причем количество процеонов может быть меньше количества итераций выполнения линейки. Рассмотрим как это должно происходить.
Ядро выбирает префикс параграфа типа 2, в котором вместо количества линеек указан РОН в котором содержится количество итераций (из-за ограничения на выполнение прерывания внутри параграфа число итераций ограничено 256).
Считывает Данные в блок регистров данных
Запрашивает процеоны из пула в количестве равным количеству итераций.
В зависимости от реально полученного числа процеонов, выделяет каждому процеону выполнение своего количества итераций (например, количество итераций 16, а выделено 4 процеона, значит 1-й выполняет итерации с 16 по 13, 2-й - с 12 по 9, 3-й - с 8 по 5, 4-й - с 4 по 1)
При каждом входе каждый процеон инициализирует свои регистры, регистр содержащий количество итераций, инициализируется номером итерации
Каждый процеон выполняет отведенные ему итерации
Ядро дожидается окончания выполнения всех итераций и решает какие данные поместить в РОН (в зависимости от кода окончания происходит либо выбор регистров определенного процеона, либо арифметическое/логическое действие над регистрами, либо их комбинация. Подробнее механизм заполнения РОН результатами рассматривается ниже)
По окончании передается управление по адресу из Регистра следующего Параграфа (данные в него могут быть занесены командой процеона)
Все команды (инструкции) всех процеонов имеют одинаковую длину и формат. Формат инструкций следующий : одна команда - 24 бита, 7 бит КОП, 5 бит - приемник, 6+6 бит - источник1 и источник2. Исключение – команда сравнения. В ней вместо приемника – условие выполнения следующей команды. В случае операций записи в память вместо регистра-приемника указывается регистр-источник данных, а 2 регистра-источника суммируются в адрес памяти.
Структура памяти и обращений к ней.
Все операции к памяти процеоны выполняют через обращение к ядру. Операции записи ядро выполняет через кэш с обратной записью (т.е. программа не ждет выполнения записи). Результат операций чтения так же является отложенным – данные попадают в регистры к моменту начала следующего параграфа, благодаря чему процеоны не простаивают в ожидании данных. Исключение – обращение к памяти в ограниченном сегменте, адрес которого указан в регистре быстрых обращений к памяти (РБОП), а в регистре флагов находится длина маски изменяемых бит адресов (в пределах которых процеоны могут обращаться напрямую к памяти и дожидаться данных). Это позволяет заранее загрузить в кэш блок данных на который указывает РБОП и размером определяемым в регистре флагов. Если в кэше такой блок не помещается, то он должен быть размещен в основной памяти, но ни в коем случае не в виртуальной, чтобы при обращении к нему не произошло прерывания из-за отсутствия данных в ОЗУ.
Так же для разгрузки вычислительных мощностей процеонов специально для копирования данных в ядро добавлена логика копирования – 3 управляющих регистра: Регистр Начального Адреса (РНА), Регистр Конечного Адреса (РКА) и Регистр Длины Копирования (РДК). При инициализации РДК, ядро начинает операцию копирования из адреса РНА+РДК на адрес РКА+РДК, затем уменьшает РДК на количество скопированных байт и повторяет операцию копирования, пока РДК не станет равен 0. Такая операция копирования может выполняться параллельно с основной программой, не привязываясь к началу или окончанию параграфа. Признаком окончания такой операции является 0 в РДК.
Важное замечание : знаковый бит в адресе определяет идет ли обращение к ОЗУ или к внешним устройствам. Таким образом все адресное пространство разделено пополам на ОЗУ (адреса 0-0x7FFFFFFFFFFFFFFF) и порты ввода-вывода (адреса 0x8000000000000000-0xFFFFFFFFFFFFFFFF). Это сделано для облегчения перехода на 128-битные процессоры: 128-битный адрес получается расширением знакового бита из 64-разрядного адреса.
Механизм заполнения РОН результатами выполнения параграфа
По окончании выполнения параграфа в ядре оказываются копии РОН каждой выполненной линейки (или итерации) команд. Ядро должно выбрать те данные которые следует поместить в РОН (замечание по Управляющим Регистрам – в них попадают данные строго по тому, в какой очередности были выполнены команды, поэтому ответственность за заполнение Управляющих Регистров лежит на программисте ! Исключение – сумматор, о нем речь ниже), для этого используется код окончания блока команд.
Рассмотрим подробнее как происходит заполнение РОН при окончании параграфа. Если данный регистр был изменен только из одной линейки, то он будет заполнен результатом переданным из этой линейки. Если для одного регистра приходят данные из двух или более линеек, то выбор результата для заполнения осуществляется в зависимости от кода окончания: а) данные берутся из линейки с самым большим номером (принцип последние данные замещают более ранние); б) самый младший регистр (R0) считается селектором – то есть «побеждают» данные из той линейки, которая записала в селектор самое большое (или самое маленькое) число (примечание – все РОН можно разделить на 2 группы по 8 регистров, в каждой из которых будет свой селектор); в) данные комбинируются через битовые операции (AND, OR, XOR). Наиболее интересным представляется вариант Б – выбор данных на основании селектора. В этом случае программа может параллельно решить несколько вариантов и по окончании параграфа выбрать правильный вариант, отбросив ненужные. Для удобства, можно разделить все РОН на 2 группы, в каждой из которых можно применить свои правила заполнения при окончании параграфа (например среди первых 8 регистров выбор результата происходит по варианту В, а для регистров R8-R15 – по варианту Б (селектором в этом случае выступает R8)).
Особое место среди Управляющих Регистров занимает Сумматор. При окончании параграфа данные занесенные в регистр младшего слова сумматора, суммируются и результат заносится в регистры старшего и младшего слов сумматора.
Преимущества данной схемы:
Распараллеливанием команд занимается компилятор, а не процессор, что позволяет делать это более оптимально
Распараллеливание происходит на уровне элементарных RISC команд (аналог микрокоманд в x86 процессорах), причем не на уровне отдельных команд, а в виде линеек последовательно выполняющихся команд, что позволяет параллельно выполнять команды с разным временем выполнения (например в одной линейке выполняется команда деления, а в другой за это время может быть выполнено несколько простых арифметических команд)
Есть возможность динамически изменять количество одновременно выполняемых линеек команд (в зависимости от свободных ресурсов выполнять линейки либо последовательно, либо параллельно)
Вычислительные мощности (процеоны) могут быть использованы любым ядром (динамическое перераспределение вычислительной мощности между задачами)
Экономия энергии (возможность временно отключать неиспользуемые процеоны)
Благодаря отсутствию команды условного перехода (на уровне ядра) отпадает потребность в блоке предсказания переходов. Адрес следующего параграфа может быть получен заранее, до окончания выполнения текущего параграфа
Удобное масштабирование и специализация процессоров – достаточно увеличить или уменьшить число процеонов соответствующего типа
Упрощается одновременное выполнение ядром нескольких задач (на время выполнения процеонами одной задачи ядро может запускать на выполнение другую задачу)
Оптимизируется доступ к памяти – процеонам требуется для чтения блок в памяти ограниченного размера. Операции чтения из других адресов (оказавшихся в виртуальной памяти) могут быть отложены и не приводят к немедленному прерыванию задачи
Благодаря разделению процессора на сравнительно одинаковые блоки, упрощается проектирование микропроцессоров.
Заключение
В этой краткой статье сделана попытка описания альтернативной структуры (в рамках классического «фон-Неймановского» процессора) центрального процессора общего назначения с упором на внедрение параллельного исполнения команд на уровне приближенном к микрокомандам. Конечно данный подход не является единственно возможным, но принципы изложенные выше (вынесение из ядра процессора вычислительных модулей, возможность динамически перераспределять ресурсы между ядрами, параллельное выполнение целых линеек команд (а не отдельных команд), динамическое выделение ресурсов для параллельных вычислений, отсутствие потребности в блоке прогнозирования ветвлений и введение команд отложенного чтения из памяти) заслуживают рассмотрения.
Комментарии (67)

SlFed Автор
07.09.2021 21:59А если это не что-то, что вы собираетесь реально реализовывать, а заготовка для главы в Научно-Фантастической книжке — то об этом нужно было сразу сказать, в таком разрезе это — ноборот, весьма глубокая и хорошо продуманная работа.
Так я в самом начале статьи написал, что представляю свои мысли по альтернативной архитектуре процессора.
Смешно даже думать что сейчас на основании этих идей побегу куда-нибудь с просьбой сделать процессор !

VaalKIA
07.09.2021 22:56+7Нет никаких проблем сделать софтовый эмулятор и попробовать написать программу, что бы оценить эффективность выполнения стандартных алгоритмов. Но то что автор такого чуда, это будет делать «смешно даже думать».
Параграфы и миниядра-клетки, есть в архитектуре Мультиклет. Её можно пощупать в железе.SlFed Автор
08.09.2021 11:35-1К сожалению я уже не программирую лет 20. Навыки растерял. Если кто возьмется помочь, это было бы здорово !
Про Мультиклет - читал я их документацию, но они упирают что у них не-фон-Неймановская идеология (а по сути - программа тупо ждет пока ей данные передадут). Хотя название "параграф" я у них подсмотрел.

ECRV
07.09.2021 22:24+9Статья была интересна в контексте ситуации, но уровень идеи, как заметили выше, больше подходит развлекательным ресурсам.
Здоровый интерес к теме архитектуры можно только поддержать и вы молодец. Посмотрите как можно реально пощупать архитектуру RISC-V(Syntacore на ChipEXPO даже очно учить будут). Можете освоить ее, после попробовать симулировать свой рабочий процессор внутри ПЛИС-ины и сравнить!
И уже к этому сравнению статья была бы вообще самый сок
Удачи!

Akon32
07.09.2021 22:46+2Похоже на некий "транспонированный" VLIW, где инструкции длинные не в ширину, а в длину. Полагаю, архитектура наследует недостатки VLIW, касающиеся плохой на практике компиляторной оптимизации.
SlFed Автор
07.09.2021 23:12Браво! Вы уловили самую главную идею - я сначала думал именно о замене команд внутри vliw на небольшие последовательности микроопераций.
Позже пришла идея "варианта Б" - когда одна линейка команд выполняется параллельно на разных процеонах (этакий SIMD в ЦП).

Armmaster
08.09.2021 00:54+4Собственно, первый комментарий достаточно точно оценил уровень данного предложения.
От себя лишь замечу, что если выбросить все технические детали, а сконцентрироваться на идее попытки распараллеливания микро-потоков, то я знаю о нескольких попытках реализовать такого рода идею в железе (в достаточно серьёзных компаниях). Все они на текущий момент ничем не закончились ( в том смысле, что до реальных пользователей не дошли).
Но за попытку плюс.

le2
08.09.2021 02:18Есть легенда, что в Гугле запрещено улучшать что-то на 20%. Улучшение должно быть значительное, например на 80% и более.
Нет смысла пытаться изобрести велосипед. В этом нет заинтересантов. Заранее понятно, что улучшение если и будет то незначительное.
Нужно значительное улучшение в решении каких-то задач. Например, вычислитель на мемристорах.
Квантовый компьютер. Или какая-то биологическая форма в виде кактуса в горшке.
Если привычный кремний, то покажите где будет гешефт.
pankraty
08.09.2021 07:50+6Есть также легенда, что в том же гугле (вот совпадение-то!) борются за доли процентов быстродействия поиска, т. к. на их объемах это огромные величины суммарно.
Но что-то мне подсказывает, что истина где-то посередине.

funny_falcon
08.09.2021 10:14Про Гугл не знаю, но в авиастроении есть правило «менять не более 10% за раз»: новая конструкция должна отличаться от предыдущей не более чем на 10%.

byman
08.09.2021 08:00+1Слишком много деталей. Лучше бы если бы процеоны это просто какой-то мозг, способный очень быстро выполнять сложные вещи. Упрощенно - суперFPGA с реконфигурацией на лету. А все ядра, как рецепторы, могут делать только примитив, но снабжают мозг трудными задачами. И все эти ядра пережевывают уже давно написанные бинарники, любых архитектур. Это мой вклад в новую утреннюю архитектуру :)

iShrimp
08.09.2021 19:31+2Уже есть множество гибридных чипов, сочетающих обычное процессорное ядро и FPGA, но они не умеют быстро перепрограммировать свою FPGA-часть на лету. Она прошивается заранее под конкретную задачу. Для процессоров общего назначения это не вариант, т.к. задача меняется с каждым квантом времени ОС. Нужен чип, умеющий перепрограммироваться за то время, пока переключается контекст.
byman
09.09.2021 08:50я думаю, что реально новая архитектура не может сразу иметь готовых решений. Должно быть что-то такое, что кто-то сразу скажет:"а вот это-то невозможно", опираясь на текущие знания. Но пройдет пару лет ,или найдется светлая голова, и вопрос будет снят. Должны быть серьезные проблемы у реально новой архитектуры с точки зрения сегодняшнего дня.

MainBelia
09.09.2021 06:34+1А не систолический ли массив описываете?
byman
09.09.2021 09:04у вас получился интересный взгляд на мой утренний порыв создать новую архитектуру :) Ваша подсказка тоже подходит под описанный мной вариант. Но моя мысль базировалась на одной работе , которую я пытался сделать лет 12 назад. Я активно занимался Н264. Сначала пытался допилить скачанный иоткуда-то аппаратный вариант, но очень быстро устал. Решил сделать вариант на многих ядрах ARM v6.Получилась у меня система вроде из 5-ти армов, сеть каждый с каждым, и каждый решал свою задачу в общем потоке. Но очень быстро обнаружилось, что простую обработку ядра делают хорошо, а вот всякую интерполяцию, интраполяцию, DCT, фильтрацию, YUV-RGB очень медленно. И я добавил в систему узел который все эти задачи решал очень быстро по запросам от ядер. Вся система была в FPGA. И это более-менее работало. Потом я взял арм с НЕОН , открытую библиотеку OpenMAX и этот вариант обогнал мой многоядерный :) Но вот сам многоядерный подход с перепрограммируемым под задачи супервычислителем мне понравился.
SlFed Автор
09.09.2021 21:12У меня описан немного другой подход - процеон это минимальный вычислительный блок для самых простых операций, но которые могут объединяться в ядре для выполнения сложной команды-параграфа.
А насчет суперFPGA я не совсем понял. Можно пояснить ?
byman
10.09.2021 08:46точнее было бы написать "придумать", а не пояснить :)
Если в вашем случае задача ядер максимально озадачить работой процеоны, то в моем случае ядра не озадачивают процеон по мелочам, а обращаются к нему с более сложной вычислительной задачей. За счет своей аппаратнореконфигурируемой сути, процеон может максимально быстро эту задачу решить. Процеон может иметь заранее ограниченный набор вычислителей (как было у меня в примере выше), а может быть чистым листом , готовым переконфигурироваться под задачу которую ему выдает ядро :).

Zeiram
08.09.2021 09:33-3Intel тоже пыталась изобрести что-то новенькое, отличное от RISC и x86 - получился Itanium (VLIW, кстати). Мучали этот процессор на рынке аж 20 лет. Вот только несмотря на миллиарды потраченных долларов, эта новая "замечательная" архитектура так и не зашла потребителю - ни частникам, ни бизнесу. Производство Itanium закрыто. Процессор признан крупнейшим фейлом Intel за всю историю их существования (пытались скрестить ежа с ужом).
У вас есть больше денег, чем "Intel-овские миллиарды"?
У вас есть 10 лет на разработку и 20+ лет на продвижение?
Вопросы риторические ;-)SlFed Автор
08.09.2021 10:10Действительно, зачем люди что-то изобретают ? Зачем Райт делал какой-то аэроплан, когда и на лошадях можно доехать ?
И конечно если у интел что-то не получилось, то это всё... приговор на веки вечные что ни у кого не получится.
А если серьёзно, то это статья - изложение моих мыслей о том какие идеи могли бы быть применены в альтернативной архитектуре ЦП. Если кто-то захочет их усовершенствовать - Welcome !

khim
14.09.2021 19:23+1Зачем Райт делал какой-то аэроплан, когда и на лошадях можно доехать ?
Главный-то вопрос не зачем, но как. Вот ключевой отрывок из книжки:
Было решено изучить всю имеющуюся на тот момент литературу о воздухоплавании и познакомиться с опытом американских и зарубежных инженеров. Уилбор и Орвилл решили, что пока они полностью не разберутся в устройстве планеров и законах воздухоплавания, они не станут совершать рискованные испытательные полеты, дабы не повторить судьбу Лилиенталя. Вскоре братья пришли к выводу, что все предыдущие полеты планеров, разработанных американскими и зарубежными инженерами, были неудачными, потому что до сих пор не удалось решить проблему управления и сохранения равновесия. Следовательно, нужно было разработать новую систему управления и решить проблему с сохранением равновесия.
Братья соорудили свою “этажерку”, так как чётко знали что за проблемы они и решают и понимали, что “узкое место” — именно там. Проведя сотни опытов и набрав статистику.
Вы же пытаетесь что-то такое “творить” особо не разобравшись в том что ж вы такое творите, зачем, и, главное, не выяснив что является проблемой, а что — нет.

TSForst
08.09.2021 14:09+2У интел были и risc архитектуры и нет их, значит они хуже x86?
Zeiram
08.09.2021 15:26Ага, именно так. Intel поняла, что на x86/x64 может сделать сильно больше денег и отказалась от RISC - "ничего личного, только бизнес". Потом эпический фейл с VLIW (Itanium-ом). Думали сделать процик по-принципу "и швец, и жнец, и на дуде игрец", но получилось "пятое колесо телеги".
Кстати, я не имею ничего против RISC. Архитектура, как архитектура - ест мало электричества и встроить её можно во всякое.

Guul
08.09.2021 09:330) примеры в студию. Не хочется учить верилог/вхдл/нмиген/писать эмуль, сделай хотя бы набросок асм программы с комментами что как на каком ядре/процеоне считается. Чтобы мы посмотрели и поняли - это решение проблем о которых мы не думали и х86/risv-v/арм не справятся
1) 4гб фактически доступного пространства в параграфе это мало. Причём зачем это ограничение сделано - не ясно. Простоц Arr(i) += arr(arr(i)) уже в один параграф не влезет при sizeof arr > 4gb. Или если arr - указатель и у компилятора нет информации о размере и потому придётся обезопаситься.
2) регистров меньше чем в x64(rax-r15+куча xmm+системная мелочь типа gs), не говоря arm и risc-v
3) sufficiently smart compiler требовался итаниуму. Учитывая его яркое пршлое, зачем недостаток писать в достоинство непонятно.
4) "Адрес следующего параграфа может быть получен заранее, до окончания выполнения текущего параграфа" не понял этот момент. это как в случае "Jmp rand()==42? Rand() :fread()" и зачем если ему результат прошлого потребуется(что приводит нас к branch prediction от которого ушли) ? Или более реалистичный пример - jmp (r9 + r10 * 8), который разруливает switch/case'ы. Как без r10 узнать результат?
5) в процессорах деление/доступ к памяти и так не выполняются за 1 цикл. То есть разницы в этом плане нет между процеонами и существующими цпу.
6) Толку от процеонов немгого, если ядро будет вечно селекторов ждать прежде чем дальше двигаться. С таким же успехом можно считать на самом ядре.
7) "Благодаря разделению процессора на сравнительно одинаковые блоки" наоборот. Одинаковые блоки - ядра у современных процов(уродцев big.LITTLE не считаем). Здесь они разные по дизайну: "Процеоны (а значит и линейки команд !) могут быть разными"
8) "Операции чтения из других адресов (оказавшихся в виртуальной памяти) могут быть отложены" это я тоже не понял. зачем их читать если они не нужны? Если нужны, то они не могут быть отложены.
Tldr. Есть ощущение что уходим от старого чтобы к нему же вернуться, но на костылях.

Tiriet
08.09.2021 09:46Почему все так зациклились на производительности процессоров? Есть ведь еще такая штука, как "пропускная способность памяти"- 12 ядер Ryzen 3950х сложно нагрузить под завязку обработкой 16GB данных. Эти ядра жрут по 10-12GB/s флоатов каждое, а память позволяет прокачать только ~60GB/s, шесть ядер забивают всю полосу памяти, остальным просто не достается данных. нужны ли мне в таком случае большие толпы процеонов?

Tarakanator
08.09.2021 11:10ИМХО все зациклились не на производительности процессоров, она-то достаточная обычно.
А производительность однопоточного кода и энергоэффективность.

creker
02.10.2021 15:19Райзен это проц для домашнего сектора. Берите лучше серверные решения, где и каналов 8, и память не только DDR обычная может быть.
SlFed Автор
08.09.2021 11:09Спасибо что прочитали всю статью ! Но наверно я все-таки не достаточно популярно объяснил в ней идею процеонов.
Попробую на примере:
Есть код :
a=a/15+58;
if (r>0) {....}Он выполняется одним параграфом, но двумя процеонами параллельно в виде 2 линеек команд. Примерно так :
{
DATA: RD0=15;RD1=58;RD2=&a;RD3=&r; RD4=&label1 // линейка данных
INT64: MOW RT2, [RD3]; IF (RT2<=RT0) MOW NextCommand,RD4; //Вторая строка кода (Линейка1)
INT64: MOW R1,[RD2]; DIV R1,RD0; ADD R1,RD1; store [RD2],R1 // Первая строка кода (Линейка2)
}Поясняю :
Линейка1 по результатам сравнения помещает в Регистр Следующей команды адрес метки перехода, а параллельно выполняется Линейка2 (причем команда store не ждет пока данные запишутся, главное чтобы они оказались в памяти к началу следующего параграфа).
Ядро получает адрес в Регистр Следующей команды ДО окончания Линейки2 (команда DIV выполняется несколько тактов) и может уже загружать следующий параграф.

funny_falcon
08.09.2021 10:29+2В итоге всё равно суперскаляр с OoO победит, т.к. имеет все преимущества «процеонов» и менее требователен к компилятору.
maxman85
08.09.2021 11:12+1Папка John Hennessy уже три года назад рассказал куда все это катиться ( https://www.youtube.com/watch?v=Azt8Nc-mtKM&t=1802s ). А катиться оно (инновации в процессора строении) к доменным архитектурам, для каждой задачи свое спецовое ядро. Например, в новом проце Intel Mount Evans за сетевую подсистему отвечает отдельное ядро, которое, кстати, программируется на языке P4.
creker
02.10.2021 15:15Не только за сетевую. Тренд сейчас это вынести задачи с хостового проца на DPU. Тонны компаний их сейчас клепают, в их числе интел и нвидия. Выносят тут и сеть, и криптографию, и безопасность, и хранилище. Все, что получится.
gwg605
08.09.2021 12:27Это здорово, что кто-то пытается изобретать :) Но я бы пошел с другой стороны. Тоже люблю изобретать :) С анализа тех проблем которые сейчас есть.
Начало отсчета это код и данные. Сначала определяются задачи решаемые процессором. Из этих задач получаем код и данные. После этого делаем архитектуру.
Идеальный случай - линейный код и широкие/параллельные данные (GPU/SIMD) больше разрядности процессора. Худший случай - иф на ифе и ифом погоняет и узкие данные меньше разрядности процессора (universal CPU). Посередине куча специфиных кейсов (различные Accelerators/DSP). Приходим к тому, что эффективный процессор это набор различных вычислительных ядер под конкретную работу объедененных одной шиной и неким блоком управления.
Ну и естественно нужен язык программирования на котором можно было бы все это внятно писать :)
naishin
08.09.2021 13:35Это называется SoC и уже существует. big.LITTLE CPU, GPU, DSP, MCU в одной упаковке.
naishin
08.09.2021 13:20+2Вам не кажется, что ваше "ядро" выполняет функции конвейера?
SlFed Автор
08.09.2021 15:35И не только конвейера, еще коммутатора обращений к памяти ( MMU ), управлением задачами и распределением нагрузки.
naishin
08.09.2021 16:04Я к тому, что может оно уже так примерно и работает в современных процессорах, просто называется конвеером, контроллером DMA, и ещё как-то. Не знаю, кто и как заполняет, например, кэши L1 и L2, но вряд ли это делает основное ядро, верно?

RarogCmex
08.09.2021 15:50+1Отмечу разрабатываемую архитектуру ForwardCom: https://forwardcom.info/
Я не специалист, так что вот мой кривой перевод основных фич:
Не RISC и не CISC
Масштабируемость
Автоматическое высчитывание циклов на уровне ассемблера
Без TLB
Без dll/so. Единый формат библиотеки и executable.
Там ещё куча всего интересного.

qw1
10.09.2021 10:40Что VLIW, что эта идея основаны на том, что в программе мало ветвлений, большие куски кода выполняются линейно и в момент компиляции можно построить план выполнения линейного куска и раскидать его по вычислительным модулям.
Это верно для «числодробительных» задач, где обсчитываются трёхэтажные формулы. Но такие задачи хорошо ложаться на SIMD, GPU, и думать как их оптимизировать в CPU нет практического смысла, разве что для разминки мозгов.
Для типичных enterprise-задач (где фасад проложен над мостом и обмазан интерфейсами, а всё выпуливается из фабрик), поток исполнения прыгает между всеми этими классами, и больших линейных кусков в принципе нет.
Для типичных computer-science задач (списки, сортировки, деревья/графы, парсеры, компиляторы, оптимизаторы) тоже нет больших линейных кусков. Плюс там большая зависимость по памяти от только что прочитанных данных, т.е. нет ресурса для автоматического распараллеливания компилятором/процессором, только переписывание на параллельные алгоритмы (что вне компетенции процессоростроителей).
Возможность ускорения таких задач я вижу в улучшении спекулятивного выполнения в симбиозе с динамическим предсказанием ветвлений. То есть то, куда идут менйстримные процессоростроители.SlFed Автор
10.09.2021 16:05Спекулятивное выполнение можно запланировать на уровне компилятора. Предположим есть код:
if (3*a > 255) b=b/10+1; else b++;
Компилятор это разбивает на 3 линейки вычисляющиеся параллельно, а в конце просто выбирается нужный результат.qw1
10.09.2021 19:39Ваш пример и есть «числодробительный» код.
Если брать компиляторы/парсеры, там на горячих местах будет что-то типаif (node->kind == NodeType::BIN_EXPR) { result_node = new Node(node->left, node->right); } else if (node->kind == NodeType::UN_EXPR) { result_node = new Node(node->body);
причём все new — это вызовы malloc/HeapAlloc из runtime/OS и поэтому никак не заинлайнятся. Удачи проспекулировать это средствами компилятора
OpenA
30.09.2021 12:56+1Спекулятивное/внеочередное исполнение не обладает возможностями ментального вызова функций с неизвестными аргументами для выделения памяти и мгновенным обращением к свежесозданному объекту в следующей итерации
Но оно может заранее попытаться подгрузить
node->left, node->right, node->bodyпрямо до проверкиnode->kind, от типа которого в том числе может зависеть и есть ли вообще эти поля как таковые. В том числе проделать это сразу для нескольких итераций путем раскрутки цикла в коде или компиляторе.qw1
30.09.2021 14:40Спекулятивное исполнение может начать уже выполнять пролог ф-ции malloc, не загрузив ещё kind, left, right.
Про раскрутку циклов в этом примере вообще не стоило говорить.
Нет такой глубины спекулятивного исполнения, чтобы полностью накрыть внутренности этого if, да ешё уйти на вторую итерацию.OpenA
01.10.2021 14:53А может и не начать
Компания Google сообщила о внедрении патчей KPTI и retpoline для блокирования атак Meltdown и Spectre на своих Linux-серверах, в том числе обслуживающих поисковую систему, Gmail, YouTube и Google Cloud Platform. Несмотря на то, что теоретически данные патчи приводят к возникновению дополнительных накладных расходов при выполнении системных вызовов, влияние на производительность обоих патчей при реальной нагрузке Google при выполнении большинства задач оценивается как незначительное. Напомним, что в синтетических тестах наблюдалось проседание производительности до 30% и даже до 60%.
В то же самое время есть пример эльбруса в котором malloc можно подгрузить в дополнительный конвеер сильно заранее и вызвать за один такт когда понадобиться. Может это немного и не то по скорости, все таки пока не переключишься, никакие загрузки оттуда вперед не запустятся, но уж всяко быстрей заплаток безопасности и в статике прекрасно планируется. Хотя реализация на эльбрусе не позволяет например два вызова подготовить и поочередно их запустить, можно только подготовить один, вызвать и только после этого можно начать готовить второй.
Про раскрутку я говорил что "в коде или компиляторе" не во время исполнения естественно.qw1
02.10.2021 14:59В то же самое время есть пример эльбруса в котором malloc можно подгрузить в дополнительный конвеер сильно заранее и вызвать за один такт когда понадобиться
Эм, я не понял эту фразу. Имеется ввиду, что код заранее загрузить в кеши, чтобы к моменту выполнения не ждать чтений? Это немного не то, можно считать, что весь горячий код уже в кешах.Про раскрутку я говорил что «в коде или компиляторе» не во время исполнения естественно.
Естественно, я про компилятор. Я говорил о том, что распараллелить какой-то цикл его раскруткой можно только если он короткий, несколько инструкций. А если цикл хотя бы 50 инструкций, то «следующая итерация» начнётся на +50 от текущей инструкции. Слабо представляю, как одновременно может исполняться 50+ инструкций, чтобы говорить, что 2 итерации цикла выполняются параллельно за счёт раскрутки.OpenA
02.10.2021 19:30Нет, не в кэши, а в конвеер. Устроено это примерно вот так:
0 5 8 pipe2 | | | | | X pipe1 | | | | | X pipe0 | | | | | | | | | pipe3 | | | | | XОсновной конвеер на девять (или больше) стадий, но в дополнение к нему есть еще 3 обрубка на 6 стадий. Обрубка в том смысле что в них код не исполняется никак, а лишь заполняется кодом функции или бранча на 6 (широких) команд и останавливается. Подготовка конвеера запускается командой
disp, %ctpr1, mallocпосле чего в любом удобном месте процедуры можно вызвать
call %ctpr1нижние стадии основного конвеера перецепляются к pipe1 после чего он становится основным, а предыдущий отрезается от исполнения и таким образом ждет возврата. Аргументы передаются путем наложения окна вызываемой процедуры на крайние регистры текущей, может это чуть менее эффективно чем наслоение процедур в интеле, но зато с точки зрения безопасности не подкопаешься.
если цикл хотя бы 50 инструкций, то «следующая итерация» начнётся на +50 от текущей инструкции
Ну даже так может оказаться полезно вынести загрузку данных первой итерации из цикла, а в теле цикла разместить обработку этих данных вместе с загрузкой данных для следующей, как бы "открутив" от него.
qw1
02.10.2021 21:21Интересно, а если в начале malloc тоже есть какой-то call, то компилятор при создании бинарника основной программы, ничего не зная про вызываемые внешние функции, тут уже ничем не сможет помочь (если оставаться в парадигме классического c/c++, а не прибегать к jit. да и с jit предвижу большой пласт проблем в переходах между генерируемым кодом и внешним библиотечным). Интеловский же подход это всё прожуёт и не подавится.
SlFed Автор
01.10.2021 15:47Короткие циклы можно раскрутить на процеонах, как я описывал в статье.
Предположим есть код:
char k=64;
................ //возможно здесь k изменился
for (i=0;i<k;i++) sum+=a[i]*b[i];В этом случае компилятор создает параграф типа-2, в котором будет только ОДНА линейка команд, но параллельно выполняющаяся на нескольких процеонах. А результат просуммируется в конце.
qw1
02.10.2021 15:06Скалярное произведение — это и есть «числодробительная» задача, которую сейчас неплохо решает SIMD.
SlFed Автор
03.10.2021 13:23Тогда любой цикл без вызова внешних функций - "числодробилка".
qw1
03.10.2021 15:24Нет, не любой. К не числодробилкам я отнесу всякие xml/json/css-парсеры. Или игровую логику, где программа поведения юнитов имеет очень запутанную сеть ветвлений и чтений памяти по косвенным индексам. То есть всё то, что не имеет линейных кусков по 20-30 инструкций, которые можно отдать процеонам.
SlFed Автор
04.10.2021 10:56Хорошо, вот пример на ветвления. Пусть будет обычный CASE на десяток вариантов (или многоуровневый IF-ELSE). В CISC,RISC и VLIW это выльется в десяток последовательных сравнений с переходами. Причем спекулятивное исполнение им не сильно поможет, параллельно можно запустить 2-4 варианта, не больше. Процеоны же позволяют параллельно запустить сравнения по всем вариантам и выдать правильный адрес перехода.
qw1
04.10.2021 12:01В том виде, как они у вас описаны — не могут.
Каждый процеон выставит на выходе какое-то значение в регистре данных, и не более того. Как ядро будет все эти значения агрегировать в один адрес перехода, тот ещё вопрос.SlFed Автор
04.10.2021 12:35Вы плохо читали статью. Попробую поподробнее.
Есть CASEswitch (a){ case 25: {.....} case 44: {.....} case 49: {.....} case 55: {.....} case 70: {.....} case 72: {.....} case 90: {.....} }Как это выглядит в коде параграфа для процеонов (предполагаем что а уже в R1):
{ DATA: RD0=25;RD1=44;RD2=49;RD3=55;RD4=70;RD5=72;RD6=90; RD7=&label1 ; RD8=&label2; RD9=&label3; RD10=&label4; RD11=&label5; RD12=&label6; RD13=&label7 INT64: IF (R1==RD0) MOW NextCommand,RD7; INT64: IF (R1==RD1) MOW NextCommand,RD8; INT64: IF (R1==RD2) MOW NextCommand,RD9; INT64: IF (R1==RD3) MOW NextCommand,RD10; INT64: IF (R1==RD4) MOW NextCommand,RD11; INT64: IF (R1==RD5) MOW NextCommand,RD12; INT64: IF (R1==RD6) MOW NextCommand,RD13; }В NextCommand попадет только результат одной линейки. Или вообще ничего.
qw1
04.10.2021 16:10Плохой пример. Это надо же столько электричества сжечь и столько кода потратить из-за такой мелочи. Настройка регистров, линеек, запуск, ожидание синхронизации. Когда в x64 это просто
mov rax, QWORD PTR jmptab[rax*8] jmp raxSlFed Автор
04.10.2021 16:47А если в rax окажется 2**32 ?
qw1
04.10.2021 17:45Понятно, что тут нужна ещё одна проверка, но на суть примера мало влияет.
В идеале, было бы круто взять какой-то реальный код, например из PCRE и посмотреть, ляжет ли на процеоны хоть что-нибудь оттуда.SlFed Автор
04.10.2021 21:57А вот и попробуйте что-нибудь подобрать, попробуем вместе придумать как это можно закодить для процеонов.
qw1
05.10.2021 13:19Бесполезно, это такая лапша из if-ов, никак не ложащаяся на vliw и процеоны
github.com/luvit/pcre2/blob/master/src/pcre2_compile.c
creker
02.10.2021 15:42+1Прочитал по диагонали до самого главного — память и кэши. И тут мне кажется все остальные умозаключения теряют смысл. Процеоны не имеют своих кэшей, ходят постоянно в ядра. Т.е. мало того, что все обращения к памяти будут проходить через шину между процеонами и ядрами, так еще здесь же будет постоянно гулять трафик для поддержания когерентности кэшей. Как кэши вообще эти устроены? Один общий пул для всех ядер? Несколько уровней? Вся производительность в этом месте и умрет. Сначала дизайн начал напоминать Cell, где точно так же разделены управляющие и вычислительные ядра. С той лишь разницей, что там все вычислительные ядра имеют свою память и сидят на кольцевой шине, что разгружает управляющие ядра от необходимости еще обслуживать между ними взаимодействие. Все это в итоге выглядит как VLIW — без компилятора, который идеально разложит все обращения к памяти, это все работать не будет.
SlFed Автор
02.10.2021 22:33Процеоны не имеют своих кэшей, ходят постоянно в ядра. Т.е. мало того, что все обращения к памяти будут проходить через шину между процеонами и ядрами, так еще здесь же будет постоянно гулять трафик для поддержания когерентности кэшей.
Не так. Все обращения по записи в память откладываются до завершения параграфа, поэтому проблемы когерентности кэшей не будет (если разные процеоны пытаются писать в одну ячейку, более ранние данные сразу заменяются пришедшими позже).
Как кэши вообще эти устроены? Один общий пул для всех ядер? Несколько уровней? Вся производительность в этом месте и умрет.
Кэши двухуровневые. L1 - на ядро, L2 - на процессор. Задачи должны как можно реже мигрировать между ядрами, тогда в кэше L1 будут нужные данные.
Именно для разгрузки обращений в память сделаны отложенные операции чтения/записи. А непосредственное чтение возможно только из заранее зарезервированной области.Все это в итоге выглядит как VLIW — без компилятора, который идеально разложит все обращения к памяти, это все работать не будет.
И да и нет. Это не VLIW - процеонная схема гораздо гибче (в теории) и позволяет выделять переменное количество ресурсов в зависимости от нагрузки. Но увы, компилятор действительно нужен более сложный.
creker
03.10.2021 13:52+2Не так. Все обращения по записи в память откладываются до завершения параграфа, поэтому проблемы когерентности кэшей не будет (если разные процеоны пытаются писать в одну ячейку, более ранние данные сразу заменяются пришедшими позже).
Проблема будет, но будет решаться на стороне L1 и L2. Тогда это все начинает напоминать недавнюю статью habr.com/ru/post/581222 Ваша архитектура походит на попытку всунуть OoO во VLIW. Может проще уже признать, что RISC/CISC лучше и приложить свой гений там? Все эти трюки там уже и так реализованы, в том или ином виде, хоть в x86, хоть в arm.Именно для разгрузки обращений в память сделаны отложенные операции чтения/записи. А непосредственное чтение возможно только из заранее зарезервированной области.
Разгрузка эта будет достигнута ценой постоянных конфликтов параграфов между собой, их перестановкой и, в конечном итоге, pipeline stalls. Я вижу здесь туже самую проблему VLIW — невозможность достичь высокой загрузки блоков реальной работой. У вас явно идеализированное представление о том, как реальный код будет себя вести. В реальном коде полно зависимостей по памяти, ветвлений и, наконец, атомарных операций. И компилятор с этим ничем не поможет. Как вы вот предполагаете атомарные операции откладывать? Это нарушит их сериализуемость. А атомарные операции нынче повсюду.SlFed Автор
04.10.2021 11:14Ваша архитектура походит на попытку всунуть OoO во VLIW.
Не так. Я размышлял о том как переложить OoO на плечи компилятора. Процессор в момент выполнения жестко ограничен ресурсами, в отличии от компилятора, который имеет больше свободного времени для разбора кода.
Разгрузка эта будет достигнута ценой постоянных конфликтов параграфов между собой, их перестановкой и, в конечном итоге, pipeline stalls.
Параграфы должны выполняться строго последовательно, а вот линейки команд процеонов могут выполняться как параллельно, так и последовательно в зависимости от свободных ресурсов, именно поэтому я пришел к отложенным операциям записи, когда ядро сначала аккумулирует все записываемые данные от префикса, затем разрешает конфликты и только после этого производит запись.
Как вы вот предполагаете атомарные операции откладывать? Это нарушит их сериализуемость. А атомарные операции нынче повсюду.
Атомарность записи обеспечивается только внутри параграфа.
qw1
04.10.2021 12:08А атомарные операции нынче повсюду.
Автор скажет «мало ли что повсюду принято, а у нас так не делают. Переписывайте без атомиков». Атомик будет очень дорогой операцией, с ценой одного параграфа (ведь только они последовательны).
khim
Вот с этим вот, конечно, невозможно не согласиться. Только надо понимать, что всё остальное содержание статьи имеет такое же отношение к конструированию процессоров, как вот этот вот рисунок имеет отношение к космическим полётам.
То есть да, некоторое количество здравых идей имеется, но они густо перемешаны с вещами, которые ну настолько просто дикие, что дальше ехать просто некуда. Ну вот как какой-нибудь “химический отсек” в этой самой Знайкиной ракете: к чему он там? Вот и предложение поделить адресное пространство пополам на ОЗУ и порты ввода-вывода — это из той же оперы.
P.S. А если это не что-то, что вы собираетесь реально реализовывать, а заготовка для главы в Научно-Фантастической книжке — то об этом нужно было сразу сказать, в таком разрезе это — ноборот, весьма глубокая и хорошо продуманная работа.
byman
думаю, что это удобрения. ведь Знайка везет семена. все логично :)