
Здравствуйте, меня зовут Дмитрий Карловский и у меня… посттравматическое стрессовое расстройство после генерации сорсмапов. И сегодня, с вашей помощью, мы будем это лечить путём максимально глубокого погружения в травмирующие события.

Это — текстовая расшифровка выступления на HolyJS'21. Вы можете посмотреть видео запись, прочитать как статью, либо открыть в интерфейсе проведения презентаций.
Как я до этого докатился?
Сперва история болезни:
Однажды я разработал простой формат Tree для представления абстрактных синтаксических деревьев в наиболее наглядной форме. На базе этого формата я реализовал уже несколько языков. Один из них — язык view.tree — предназначен для декларативного описания компонент и композиции их друг с другом. И именно на этом языке описаны все стандартные визуальные компоненты фреймворка $mol. Это позволяет писать короткий и наглядный код, делающий при этом много чего полезного.
Зачем DSL? Бойлерплейт!
Сейчас вы видите законченное приложение на $mol:
$my_app $my_page
title @ \Are you ready for SPAM?
body /
<= Agree $my_checkbox
checked?val <=> agree?val trueОно состоит из панельки, внутри которой расположен чекбокс. И вместе они связаны двусторонней связью по заданным свойствам. В этих 5 строчках кода есть даже поддержка локализации. Эквивалентный код на JavaScript занимает в 5 раз больше места:
class $my_app extends $my_page {
title() {
return this.$.$my_text( '$my_app_title' )
}
body() {
return [ this.Agree() ]
}
Agree() {
const obj = new this.$.$my_checkbox()
obj.checked = val => this.agree( val )
return obj
}
agree( val = true ) {
return val
}
}
$my_mem( $my_app.prototype, "agree" )
$my_mem( $my_app.prototype, "Agree" )Этот код, хоть и на более привычном многим языке, куда более сложный в понимании. Кроме того, он совсем потерял иерархию, чтобы добиться того же уровня гибкости. Плоский класс хорош тем, что от него можно отнаследоваться и переопределить любой аспект поведения компонента.
Таким образом, одна из основных причин использования DSL — это возможность писать простой и лаконичный код, который легко изучить, в котором сложно накосячить, и который легко поддерживать.
Зачем DSL? Пользовательские скрипты!
Другая причина внедрения DSL — это потребность давать самим пользователям расширять логику вашего приложения, используя скрипты. Например, возьмём простой скрипт автоматизации работы со списком задач, написанный обычным пользователем:
@assignee = $me
@component = \Frontend
@estimate ?= 1D
@deadline = $prev.@deadline + @estimateТут он говорит: назначь меня ответственным на все задачи; укажи, что они все относятся к фронтенду; если эстимейт не задан, то пропиши 1 день; и выстрой их дедлайны по очереди с учётом получившихся эстимейтов.
JS в песочнице? Это законно?!7
И тут вы, возможно, спросите: почему бы просто не дать пользователю в руки JS? И тогда я с вами, внезапно, соглашусь. У меня даже есть песочница для безопасного исполнения пользовательского JS. И онлайн-песочница для песочницы:
Можете попробовать выбраться из неё. Мой любимый пример: Function is not a function — в очень духе JS.
JS в песочнице? Не, это не для средних умов..
Однако, для обычного пользователя JS — слишком сложен.

Ему было бы куда проще освоить какой-то простой язык, ориентированный на его бизнес-область, а не язык общего назначения типа JS.
Зачем DSL? Разные таргеты!
Ещё одна причина создавать свой DSL — это возможность написать код один раз, а исполнять его в самых разных рантаймах:
- JS
- WASM
- GPU
- JVM
- CIL
А разные таргеты зачем? Одна модель, чтобы править всеми!
В качестве иллюстрации, приведу пример из одного стартапа, который я разрабатывал. За пол года разработки мы сделали довольно много. И всё благодаря тому, что у нас был универсальный изоморфный API, который конфигурировался простеньким DSL, где описывалось, какие у нас есть сущности, какие у них есть атрибуты, какие у них типы, как связаны с другими сущностями, какие на них есть индексы и всё такое. Всего несколько десятков сущностей и под сотню связей. Простой пример — модель задачи..
Task
title String
estimate DurationИз этого декларативного описания, которое занимает несколько килобайт, генерируется уже код, работающий как на сервере, так и на клиенте, и, конечно, схема базы данных тоже автоматически обновляется.
class Task extends Model {
title() {
return this.json().title
}
estimate() {
return new Duration( this.json().estimate )
}
}
$my_mem( Task.prototype, "estimate" )
CREATE CLASS Task extends Model;
CREATE PROPERTY title string;
CREATE PROPERTY estimate string;Таким образом, разработка (и особенно рефакторинг) существенно ускоряется. Достаточно поменять строчку в конфиге, и через несколько секунд мы уже можем дёргать на клиенте за новую сущность.
Зачем DSL? Фатальный недостаток же!
Ну и, конечно, какой же программист не любит быстрой езды на велосипеде?

Зачем всё это? Транспиляция и проверки!
Так у нас появилось множество разных полезных инструментов:
- Babel и прочие транспайлеры.
- Uglify и прочие минификаторы.
- TypeScript, AssemblyScript и прочие языки программирования.
- TypeScript, FlowJS, Hegel и прочие тайпчекеры.
- SCSS, Less, Stylus PostCSS и прочие CSS генераторы.
- SVGO, CSSO и прочие оптимизаторы.
- JSX, Pug, Handlebars и прочие шаблонизаторы.
- MD, TeX и прочие языки разметки.
- ESLint и прочие линтеры.
- Pretier и прочие форматтеры.
Разрабатывать их — задача не простая. Да даже чтобы плагин к любому из них написать — придётся попариться. Так что давайте порассуждаем, как всё это можно было бы упростить. Но сперва разберём проблемы, которые нас подстерегают на пути..
Так какие проблемы? Это не то, что я написал!
Допустим, пользователь написал такой вот простенький маркдаун-шаблон..
Hello, **World**!А мы сгенерировали развесистый код, который собирает DOM через JS..
function make_dom( parent ) {
{
const child = document.createTextNode( "Hello, " )
parent.appendChild( child )
}
{
const child = document.createElement( "strong" )
void ( parent => {
const child = document.createTextNode( "World" )
parent.appendChild( child )
} )( child )
parent.appendChild( child )
}
{
const child = document.createTextNode( "!" )
parent.appendChild( child )
}
}Если пользователь столкнётся с ним, например, при дебаге, то ему потребуется много времени, чтобы понять, что это за лапшекод, и что он вообще делает.
Так какие проблемы? Да тут чёрт ногу сломит!
Совсем печально, когда код не просто раздутый, но и минифицированный с однобуквенными именами переменных и функций..
Hello, **World**!function make_dom(e){{const t=document.createTextNode("Hello, ");
e.appendChild(t)}{const t=document.createElement("strong");
(e=>{const t=document.createTextNode("World");e.appendChild(t)})(t),
e.appendChild(t)}{const t=document.createTextNode("!");e.appendChild(t)}}Чем помогут сорсмапы? Исходники и отладка!
Но тут нам на помощь приходят сорсмапы. Они позволяют вместо сгенерированного кода показывать программисту тот код, что он написал.

Более того, с сорсмапами будут работать инструменты отладки: можно будет исполнять его по шагам, ставить брейкпоинты внутри строки и всё такое. Почти нативненько.
Чем помогут сорсмапы? Стек-трейсы!
Кроме того, сорсмапы используются для отображения стек-трейсов.

Браузер сперва показывает ссылки на сгенерированный код, в фоне загружая сорсмапы, после чего на лету подменяет ссылки на исходный код.
Чем помогут сорсмапы? Значения переменных!
Третья ипостась сорсмапов — отображение значения переменных.

В примере исходника используется имя next, но в рантайме такой переменной нет, ибо в сгенерированном коде переменная называется pipe. Однако, при наведении на next, браузер делает обратный мапинг и выводит уже значение именно переменной pipe.
Спецификация? Не, не слышал..
Интуитивно ожидается, что у сорсмапов должна быть обстоятельная спецификация, которую можно заимплементить и всё, мы в шоколаде. Этой штуке ведь уже 10 лет. Однако, всё не так радужно..
- V1 — Internal Closure Inspector format
- Proposal V2 2010 +JSON -20%
- Proposal V3 2013 — 50%
Спека насчитывает 3 версии. Первую я не нашёл, а остальные — это просто заметки в Google Docs.
Вся история сорсмапов — это история о том, как программист, делающий инструменты разработчика, героически боролся за уменьшение их размеров. Суммарно они уменьшились в итоге примерно на 60%. Это мало того, что довольно смешная цифра сама по себе, так ещё борьба за размер сорсмапов — довольно бессмысленное занятие, ведь скачиваются они лишь на машине разработчика и то лишь тогда, когда он занимается отладкой.
То есть мы получаем классическую беду многих программистов: оптимизация не того, что важно, а того, что интересно или проще оптимизировать. Никогда так не делайте!
Как всё же разобраться в сорсмапах?
Если вы решитесь связаться с сорсмапами, то вам могут пригодиться следующие статьи:
Далее же я расскажу вам про подводные грабли, которые обильно рассыпаны тут и там во имя уменьшения размера..
Как сорсмапы подключаются?
Подключать сорсмапы можно двумя способами. Можно через HTTP заголовок..
SourceMap: <url>Но это довольно бестолковый вариант, так как требует специальной настройки веб-сервера. Далеко не каждый статический хостинг вообще такое позволяет.
Предпочтительнее использовать другой способ — размещение ссылки в конце сгенерированного кода..
//# sourceMappingURL=<url.js.map>
/*# sourceMappingURL=<url.css.map> */Как видите, у нас тут отдельный синтаксис для JS и отдельный для CSS. При этом второй вариант синтаксически корректен и для JS, но нет, так не заработает. Из-за этого мы не можем обойтись одной универсальной функцией для генерации кода с сорсмапами. Нам обязательно нужно отдельная функция для генерации JS кода и отдельная для CSS. Вот такое вот усложнение на ровном месте.
Как сорсмапы устроены?
Давайте посмотрим, что там у них внутри..
{
"version": 3,
"sources": [ "url1", "url2", ... ],
"sourcesContent": [ "src1", "src2", ... ],
"names": [ "va1", "var2", ... ],
"mappings": "AAAA,ACCO;AAAA,ADJH,WFCIG;ADJI;..."
}Поле sources содержит ссылки на исходники. Там могут быть любые строки, но обычно это относительные ссылки, по которым браузер будет выкачивать исходники. Но я рекомендую всегда класть эти исходники в sourcesContent — это убережёт вас от проблем с тем, что мапинги в какой-то момент у вас будут одной версии, а исходники другой, или вообще не скачаются. И тогда — счастливой отладки. Да, сорсмапы раздуваются в размере, зато это гораздо более надёжное решение, что важно во время отладки и без того глючащего кода. Получаем, что вся та борьба за размер сорсмапов была бессмысленна, так как добрая половина сорсмапа — это исходные коды.
В поле names хранятся имена переменных в рантайме. Этот костыль уже не нужен, так как сейчас браузеры умеют как прямой, так и обратный мапинг. То есть они сами вытягивают имена переменных из сгенерированного кода.
Ну а в поле mappings уже находятся, собственно, мапинги для сгенерированного кода.
Как расшифровать мапинги?
Представим мапинги для наглядности в несколько строк, чтобы понять их структуру..
AAAA,ACCO;
AAAA,ADJH,WFCIG;
ADJI;
...Для каждой строки сгенерированного файла задаётся несколько спанов, разделённых запятыми. А в конце — точка с запятой для разделения строк. Тут у нас 3 точки с запятой, поэтому в сгенерированном файле минимум 3 строки.
Важно подчеркнуть, что хотя точка с запятой и может быть висящей, а вот запятые висящими быть не могут. Ну, точнее, ФФ их скушает и не подавится, а вот Хром просто проигнорирует такие сорсмапы без какого-либо сообщения об ошибке.
Это что за спаны такие?
Спан — это некоторый набор чисел в количестве 1, 4 или 5 штук. Спан указывает на конкретное место в конкретном исходнике.
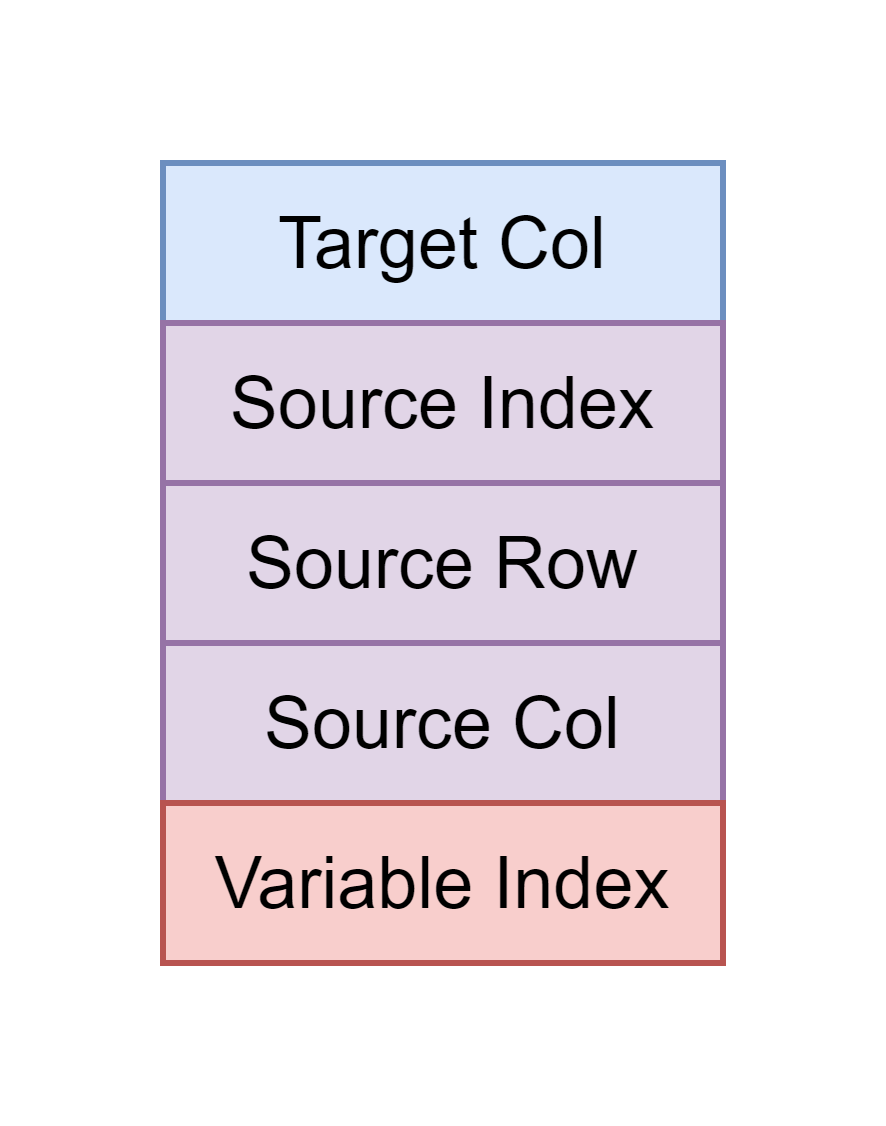
Пятое число — это номер имени переменной в списке names, который (как мы уже выяснили), не нужен, поэтому это число просто не указываем.
Так что в этих числах-то?
Остальные 4 числа — это номер колонки в соответствующей строке генерированного файле, номер исходника, номер строки исходника и номер колонки в этой строке.

Имейте в виду, что номера начинаются с 0. Три последних числа можно опустить, тогда у нас будет лишь указатель на колонку в сгенерированном файле, который никуда в исходниках не мапится. Чуть позже я расскажу, зачем это надо. А пока разберём, как числа кодируются..
И это всё в 5 байтах? Дифференциальное кодирование!
Наивно было бы сериализовать спаны как-нибудь так (каждая строка — один спан)..
| TC | SI | SR | SC |
|---|---|---|---|
| 0 | 1 | 40 | 30 |
| 3 | 3 | 900 | 10 |
| 6 | 3 | 910 | 20 |
Но в сорсмапах применяется дифференциальное кодирование. То есть значения полей представлены как есть лишь для первого спана. Для остальных же сохраняется уже не абсолютное значение, а относительное — разница между текущим и предыдущим спаном..
| TC | SI | SR | SC |
|---|---|---|---|
| 0 | 1 | 40 | 30 |
| +3 | +2 | +860 | -20 |
| +3 | 0 | +10 | +10 |
Обратите внимание, что если к 40 от первого спана прибавить 860, то получится 900 для второго спана, а если добавить ещё 10, то 910 для третьего спана.
Информации в таком представлении сохраняется столько же, но размерность чисел несколько уменьшается — они становятся ближе к 0.
И это всё в 5 байтах? VLQ кодирование!
Далее применяется VLQ кодирование, или кодирование с переменной длиной. Чем ближе число к 0, тем меньше оно требует байт для представления..
| Values | Bits Count | Bytes Count |
|---|---|---|
| -15… +15 | 5 | 1 |
| -511… +511 | 10 | 2 |
| -16383… +16383 | 15 | 3 |
Как видите, каждые 5 значимых бит информации требуют по 1 дополнительному байту. Это не самый эффективный способ кодирования. Например, в WebAssembly применяется LEB128, где по байту тратится уже на каждые 7 значимых бит. Но это уже бинарный формат. А у нас тут мапинги зачем-то сделаны в формате JSON, который текстовый.
В общем, формат переусложнили, а в размере не особо-то и выиграли. Ну да ладно, это ещё цветочки..
Как же сорсмапы хороши! Был бы исходник..
Сорсмапы мапят не диапазон байт в одном файле на диапазон в другом, как мог бы подумать наивный программист. Они мапят лишь точки. И всё, что попадёт между замапленной точкой и следующей в одном файле — оно как бы оказывается замапленным на всё, что после соответствующей точки до следующей в другом файле.
И это, конечно, приводит к разным проблемам. Например, если мы добавим какой-то контент, которого нет в исходниках, и, соответственно, никуда не замапим, то он просто приклеится к предыдущему указателю..

В примере мы добавили Bar. И если не пропишем для него никакой мапинг (а мапить-то его некуда), то он приклеится к Foo. Получится, что Foo мапится на FooBar, и, например, отображение значений переменных при наведении перестаёт работать.
Чтобы этого не происходило, нужно Bar замапить в никуда. Для этого как раз и нужен вариант спана с одним числом. В данном случае это будет число 3, так как Bar начинается с третьей колонки. Таким образом, мы говорим, что после данного указателя до следующего (или конца строки) контент никуда не замаплен, а Foo мапится только лишь на Foo.
Как же сорсмапы хороши! Был бы результат..
Есть и обратная ситуация, когда в исходнике контент есть, а в результат он не идёт. И тут тоже может быть проблема с прилипанием..

Получается, надо вырезанный контент куда-нибудь всё же замапить. Но куда? Единственное место — это куда-нибудь в конец результирующего файла. Это вполне себе рабочее решение. И всё бы хорошо, но если пайплайн наш на этом не заканчивается, и продолжается обработка, то могут быть проблемы.
Например, если мы далее склеиваем несколько сгенерированных файлов вместе, то нам нужно объединить их мапинги. Устроены они таким образом, что их можно просто сконкатенировать. Однако при этом конец одного файла станет началом следующего. И всё благополучно сломается.
А если надо склеить сорсмапы?
Можно было бы делать хитрый ремапинг при конкатенации, но тут нам на помощь приходит ещё один формат сорсмапов. Вот это твист! Их на самом деле два. Композитные сорсмапы выглядят уже следующим образом..
{
version: 3,
sections: [
{
offset: {
line: 0,
column: 0
},
url: "url_for_part1.map"
},
{
offset: {
line: 100,
column: 10
},
map: { ... }
}
],
}Тут сгенерированный файл разбивается на секции. Для каждой секции задаётся начальная позиция и либо ссылка на обычный сорсмап, либо само содержимое сорсмапа для этой секции.
Причём обратите внимание на то, что задаётся начало секции в формате "строка-колонка", что крайне не удобно. Ведь для того, чтобы отмерить секцию, необходимо пересчитать все переводы строк в предыдущих секциях. Особенно весело такие приколы смотрелись бы при генерации бинарных файлов. Благо сорсмапы by design их не поддерживают.
А макросы? Мапим на их внутрянку..
Ещё один крайний случай — макросы в том или ином виде. То есть кодогенерация на прикладном уровне. Возьмём для примера макрос log, который принимает некоторое выражение и оборачивает его в условное логирование...
template log( value ) {
if( logLevel > Info ) { // A
console.log( value ) // B
}
}
log!stat1()
log!stat2()
log!stat3()Таким образом мы не вычисляем потенциально тяжёлое выражение, если логирование выключено, но при этом не пишем кучу однотипного кода.
Внимание, вопрос: куда мапить сгенерированный макросом код?
if( logLevel > Info ) { // A
console.log( stat1() ) // B
}
if( logLevel > Info ) { // A
console.log( stat2() ) // B
}
if( logLevel > Info ) { // A
console.log( stat3() ) // B
}Если мы замапим его на содержимое макроса, то получится, что, при исполнении кода по шагам, мы будем ходить внутри макроса: A-B-A-B-A-B. А в точке его применения так и не остановимся. То есть разработчик не сможет увидеть, откуда он попал в макрос, и что ему передавалось.
А макросы? Мапим на их применение..
Тогда может быть лучше мапить весь сгенерированный код на место применения макроса?
template log( value ) {
if( logLevel > Info ) {
console.log( value )
}
}
log!stat1() // 1
log!stat2() // 2
log!stat3() // 3if( logLevel > Info ) { // 1
console.log( stat1() ) // 1
}
if( logLevel > Info ) { // 2
console.log( stat2() ) // 2
}
if( logLevel > Info ) { // 3
console.log( stat3() ) // 3
}Но тут получается иная беда: мы остановились на строке 1, потом снова на строке 1, потом опять… Так продолжаться может утомительно долго, смотря сколько инструкций окажется внутри макроса. Короче, теперь отладчик уже будет по несколько раз останавливаться на одном и том же месте, так и не зайдя в код макроса. Это и так-то неудобно, плюс отлаживать сами макросы таким образом просто не реально.
А макросы? Мапим и на применение, и на внутрянку!
С макросами лучше совмещать оба подхода. Сначала добавить инструкцию, которая ничего полезного не делает, но мапится на место применения макроса, а сгенерированный макросом код уже мапить на код макроса..
template log( value ) {
if( logLevel > Info ) { // A
console.log( value ) // B
}
}
log!stat1() // 1
log!stat2() // 2
log!stat3() // 3void 0 // 1
if( logLevel > Info ) { // A
console.log( stat1() ) // B
}
void 0 // 2
if( logLevel > Info ) { // A
console.log( stat2() ) // B
}
void 0 // 3
if( logLevel > Info ) { // A
console.log( stat3() ) // B
}Таким образом, при отладке по шагам мы сначала остановимся на месте применения макроса, потом зайдём в него и пройдёмся по его коду, потом выйдем и пойдём дальше. Почти как с нативными функциями, только без возможности их перепрыгнуть, ибо рантайм ничего про наши макросы не знает.
Хорошо бы в 4 версии сорсмапов добавили поддержку макросов. Эх, мечты, мечты..
Как же сорсмапы хороши! Если бы не имена переменных..
Ну и касательно переменных, тут всё тоже довольно дубово. Если вы думаете, что можно выделить произвольное выражение в исходнике, и ожидать, что браузер глянет, во что оно мапится, и попробует это исполнить, то как бы не так!
- Только имена переменных, никаких выражений.
- Только полное совпадение.
Как же сорсмапы хороши! Если бы не evil..
И ещё один дьявол в деталях реализации. Если вы генерируете код не на сервере, а на клиенте, то, чтобы его исполнить, вам потребуется та или иная форма вызова интерпретатора. Если вы воспользуетесь для этого eval, то с мапингами будет хорошо, но работать будет медленно. Гораздо быстрее сделать функцию и её уже исполнять много раз..
new Function( '', 'debugger' )Но браузер под капотом делает что-то типа:
eval(`
(function anonymous(
) {
debugger
})
`)То есть добавляет в ваш код сверху две строки, отчего все мапинги сворачивают не туда. Чтобы это побороть, надо сорсмапы сдвинуть вниз, например, добавив пару точек с запятой в начало мапинга. Тогда new Function будет хорошо мапиться. Но съедет теперь уже в eval.
То есть, когда вы генерируете мапинги, вы должны чётко понимать, как вы этот код будете запускать, иначе мапинги будут показывать не туда.
Как же сорсмапы хороши! Но что-то пошло не так..
Ну и самая главная беда сорсмапов: если вы где-то накосячите, то в большинстве случаев браузер вам ничего не скажет, а просто проигнорирует. И тогда придётся лишь гадать..
- Карты Таро
- Натальные карты
- Гугл Карты
И даже Гугл тут мало чем помогает, ибо там в основном ответы на вопросы в духе "как настроить WebPack?". А там есть всего один разумный вариант настройки. Зачем пользователям раздали столько гранат — не понятно.
Пофантазируем? Сорсмапы здорового человека!
Ладно, с сорсмапами сейчас всё довольно печально. Давайте попробуем спроектировать их сейчас с нуля. Я бы сделал для этого бинарный формат, где мапились бы не указатели, а конкретные диапазоны байт. На спан выделим константные 8 байт, то есть машинное слово. Работать с ним просто, быстро и, главное, его достаточно для наших нужд. Состоять спан будет из 3 чисел: смещение диапазона в кумулятивном исходнике (конкатенация всех исходников), длина этого диапазона, и длина диапазона в результате.
| Field | Bytes Count |
|---|---|
| source_offset | 3 |
| source_length | 3 |
| target_length | 2 |
Эта информация необходима и достаточна, чтобы однозначно смапить исходники на результат. Даже если результатом будет бинарник, а не текст. А даже если нам потребуется где-то что-то заремапить, то делается это простой и эффективной функцией.
Но, к сожалению, приходится работать с тем, что есть сейчас..
Стоит ли связываться с сорсмапами?
Надеюсь, мне удалось показать, что сорсмапы — это то ещё болото, в которое лучше не лезть. В процессе трансформаций за ними нужно аккуратно следить, чтобы они не потерялись и не съехали. В сообщения об ошибках надо указывать на исходник, а в случае макросов нужно выводить трейс по исходникам. Итого:
- Сложно само по себе.
- Проносить через трансформации.
- Проносить в сообщения об ошибках.
- Плюс трейс по шаблонам.
Я бы не хотел с ними связываться, но мне пришлось. Но давайте подумаем, как их всё же избежать..
Сложно? Возьмём Бабель!
Возьмём популярный инструмент, например Babel. Наверняка же там все проблемы уже решены и можно садиться да ехать!
Возьмём первый попавшийся плагин..
import { declare } from "@babel/helper-plugin-utils";
import type NodePath from "@babel/traverse";
export default declare((api, options) => {
const { spec } = options;
return {
name: "transform-arrow-functions",
visitor: {
ArrowFunctionExpression(
path: NodePath<BabelNodeArrowFunctionExpression>,
) {
if (!path.isArrowFunctionExpression()) return
path.arrowFunctionToExpression({ // Babel Helper
allowInsertArrow: false,
specCompliant: !!spec,
})
},
},
}
})Он трансформирует стрелочную функцию в обычную. Задача вроде бы простая, да и кода не так уж много! Однако, если присмотреться, то всё, что эта портянка делает, — это вызывает стандартный бабелевский хелпер и всё. Как-то многовато кода для такой простой задачи!
Бабель, зачем столько бойлерплейта?
Ладно, давайте заглянем в этот хелпер..
import "@babel/types";
import nameFunction from "@babel/helper-function-name";
// ...
this.replaceWith(
callExpression( // mapped to this
memberExpression( // mapped to this
nameFunction(this, true) || this.node, // mapped to this
identifier("bind"), // mapped to this
),
[checkBinding ? identifier(checkBinding.name) : thisExpression()],
),
);Ага, тут генерируются новые узлы AST, используя глобальные функции-фабрики. Но беда в том, что вы не контролируете, куда они будут замаплены. А чуть ранее я показывал, как важно точно контролировать, что куда мапится. Тут же этой информации нет, поэтому Бабелю ничего не остаётся, как мапить новые узлы на тот единственный узел, на который сматчился плагин (this), что далеко не всегда даёт адекватный результат.
Займёмся отладкой? AST курильщика..
Следующая проблема — отладка трансформаций. Тут нам важно иметь возможность смотреть, какое AST было до трансформации, а какое стало после. Возьмём простенький JS код:
Вы только гляньте, как выглядит типичное абстрактное синтаксического дерево (AST) для него..
{
"type": "Program",
"sourceType": "script",
"body": [
{
"type": "VariableDeclaration",
"kind": "const",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "foo"
},
"init": {
"type": "ObjectExpression",
"properties": [
...И это лишь его половина. И это даже не бабелевское AST, а какой-то ноунейм — я просто взял самое компактное из тех, что есть на ASTExplorer. Собственно, поэтому этот инструмент вообще и появился, ибо без него смотреть на эти JSON-чики — боль и страдания.
Займёмся отладкой? AST здорового человека!
И тут нам на помощь приходит формат Tree, который я когда-то разработал специально для целей наглядного представления AST..
{;}
const
foo
{,}
:
\bar
123Как видите, js.tree представление уже гораздо нагляднее. И не требует никаких ASTExplorer. Хотя я и сделал для него патч для поддержки tree, который уже второй год игнорируется мейнтейнером. Это — open-source, детка!
И как с этим работать? Всё, что нужно и ничего ненужного!
В моей реализации API для Tree ($mol_tree2) у каждого узла есть лишь 4 свойства: это имя типа, сырое значение, список дочерних узлов и спан (указатель на диапазон в исходнике)..
interface $mol_tree2 {
readonly type: string
readonly value: string
readonly kids: $mol_tree2[]
readonly span: $mol_span
}Каждый спан содержит ссылку на исходник, само содержимое исходника, номера строки и столбца начала диапазона и длину этого диапазона..
interface $mol_span {
readonly uri: string
readonly source: string
readonly row: number
readonly col: number
readonly length: number
}Как видите, тут есть всё, что нужно для представления и обработки любого языка, и ничего ненужного.
И как с этим работать? Локальные фабрики!
Генерация новых узлов происходит не глобальными функциями-фабриками, а наоборот, локальными методами-фабриками..
interface $mol_tree2 {
struct( type , kids ): $mol_tree2
data( value , kids ): $mol_tree2
list( kids ): $mol_tree2
clone( kids ): $mol_tree2
}Каждая такая фабрика создаёт новый узел, но наследует спан от существующего узла.
Почему это работает?
Таким образом, мы можем точно контролировать, на какую часть исходника будет мапиться каждый узел, даже после применения множества трансформаций AST..
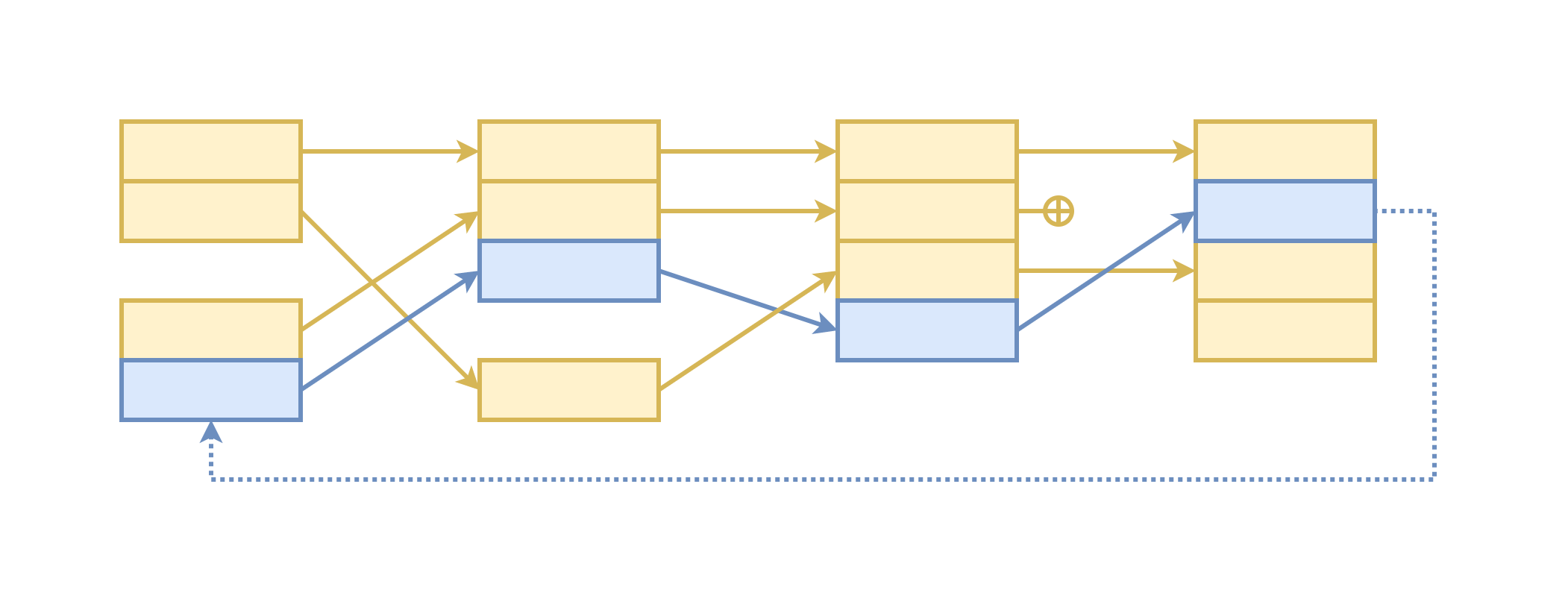
На диаграмме вы видите, как мы из 2 файлов сгенерировали 1 путём 3 трансформаций, которые что-то вырезали, что-то добавили, а что-то перемешали. Но привязка к исходным кодам никуда не потерялась.
И как с этим работать? Обобщённые трансформации!
Для написания трансформаций есть 4 обобщённых метода..
interface $mol_tree2 {
select( ... path ): $mol_tree2
filter( ... path, value ): $mol_tree2
insert( ... path, value ): $mol_tree2
hack( belt, context ): $mol_tree2[]
}Каждый из них создаёт новое AST, никак не меняя существующее, что очень удобно при отладке. Они позволяют делать глубокие выборки, фильтрацию по глубокой выборке, глубокие вставки и применять хаки.
Это что за хаки такие? Шаблонный пример..
Хаки — самая мощная штука, позволяющая пройтись по дереву, заменяя узлы разных типов на результат исполнения разных обработчиков. Проще всего их работу продемонстрировать на примере реализации тривиального шаблонизатора для AST. Допустим, у нас есть шаблон конфига для нашего сервера..
rest-api
login @username
password @password
db-root
user @username
secret @passwordРаспарсив его в AST, мы можем похачить наш конфиг всего в несколько строчек кода..
consfig.list(
config.hack({
'@username': n => [ n.data( 'jin' ) ],
'@password': p => [ p.data( 'пороль' ) ],
})
)В результате получится, что все плейсхолдеры заменены на нужные нам значения..
rest-api
login \jin
password \пороль
db-root
user \jin
secret \порольА если что-то более сложное? Скрипт автоматизации..
Рассмотрим пример посложнее — скрипт автоматизации..
click \$my_app.Root(0).Task(0)
click \$my_app.Root(0).Details().TrackTime()Тут у нас есть команда click. Ей передаётся идентификатор элемента, по которому должно быть произведено нажатие.
Что ж, похачим этот скрипт так, чтобы на выходе получился AST яваскрипта..
script.hack({
click: ( click, belt )=> {
const id = click.kids[0]
return [
click.struct( '()', [
id.struct( 'document' ),
id.struct( '[]', [
id.data( 'getElementById' ),
] ),
id.struct( '(,)', [ id ] ),
click.struct( '[]', [
click.data( 'click' ),
] ),
click.struct( '(,)' ),
] ),
]
},
})Обратите внимание, что часть узлов создаются из имени команды (click), а часть из идентификатора элемента (id). То есть отладчик будет останавливаться и там, и там. А стек-трейсы ошибок будут указывать на правильные места исходника.
А можно ещё проще? jack.tree — макро-язык для трансформаций!
Но можно погрузиться ещё глубже и сделать DSL для обработки DSL. Например, трансформацию скрипта автоматизации можно описать следующим образом на языке jack.tree..
hack script {;} from
hack click ()
document
[] \getElementById
(,) data from
[] \click
(,)
script jack
click \$my_app.Root(0).Task(0)
click \$my_app.Root(0).Details().TrackTime()Каждый hack — это макрос, который матчится на заданный тип узла, и заменяющий его на что-то иное. Это пока ещё прототип, но он уже много чего умеет.
А если разные таргеты? Трансформируем в JS, вырезая локализацию..
Хаки позволяют не просто дословно транслировать один язык в другой. С их помощью, можно экстрактировать из кода интересующую нас информацию. Например, у нас есть скрипт на некотором простом DSL, который что-то там выводит на английском языке..
+js
print @ begin \Hello, World!
when onunload print @ end \Bye, World!И мы можем преобразовать его в JS так, чтобы вместо английских текстов дёргалась функция localize с нужным ключом, просто завернув его в макрос +js..
{
console.log( localize("begin") )
function onunload() {
console.log( localize("end") )
}
}А если разные таргеты? Вычленяем переводы, игнорируя логику..
Но мы можем применить к нему другой макрос — +loc..
+loc
print @ begin \Hello, World!
when onunload print @ end \Bye, World!И тогда, наоборот, вся логика будет проигнорирована, а мы получим JSON со всеми ключами и соответствующими им текстами..
{
"begin": "Hello, World!",
"end": "Bye, World!"
}А если разные таргеты? Меняем трансформации как перчатки..
На jack.tree эти макросы описываются сравнительно не сложным кодом..
hack +js
hack print ()
console
[] \log
(,) from
hack @ ()
localize
(,) type from
hack when function
struct type from
(,)
{;} kids from
{;} fromhack +loc
hack print from
hack when kids from
hack @ :
type from
kids from
{,} fromКак видите, внутри макроса можно объявлять другие макросы. То есть язык легко можно расширять средствами самого этого языка. Таким образом, можно генерировать разный код. Можно учитывать контекст, в котором находятся узлы, и матчиться только в этом контексте. Короче, техника очень простая, но мощная и при этом шустрая, так как нам не приходится ходить по дереву туда-сюда — мы только спускаемся по нему.
Что-то пошло не так? Трейс трансформаций!
Большая сила требует и большой ответственности. Если что-то пойдёт не так и возникнет исключение, а у нас макрос на макросе и макросом погоняет, то крайне важно выводить трейс, который поможет разобраться, кто где на что матчился по пути к месту ошибки..

Тут мы видим, что исключение возникло в точке (1), но ошибка человеком была допущена в точке (2), в которую мы пришли из точки (3).
Ну зачем ещё один велосипед?
И тут вы, скорее всего, задаётесь вопросом: "Дима, зачем ещё один велосипед? Горшочек, не вари! Хватит уже велосипедов!". Я бы и рад, но давайте вкратце сравним его с альтернативами..
| Babel | TypeScript | tree | |
|---|---|---|---|
| Сложность API | ~300 | ∞ | ~10 |
| Абстракция от языка | ❌ | ❌ | ✅ |
| Иммутабельность API | ❌ | ❌ | ✅ |
| Удобная сериализация | ❌ | ❌ | ✅ |
| Самодостаточность | ❌ | ✅ | ✅ |
У Бабеля порядка 300 функций, методов и свойств. У TS там вообще какое-то запредельное complexity, ещё и почти без документации.
Все они гвоздями прибиты к JS, что осложняет их использование для кастомных языков. У них мутабельное API без лаконичной сериализации AST, что существенно осложняет отладку.
Наконец, AST Бабеля не является самодостаточным, то есть мы не можем из него напрямую сгенерировать и результирующий скрипт, и сорсмапы к нему — для этого надо окольными путями протягивать исходники. С сообщениями об ошибках — та же беда. У TS с этим получше, но тут уже другая крайность — он вместе с бананом даёт вам и обезьяну, и джунгли, и даже свою солнечную систему в нескольких ипостасях.
Типичный пайплайн… что-то тут не так..
Давайте глянем как выглядит типичный фронтенд-пайплайн..
- TS: распарсил, транспилировал, сериализовал.
- Webpack: распарсил, пошатал деревья, собрал, сериализовал.
- Terser: распарсил, минифицировал, сериализовал.
- ESLint: распарсил, всё проверил, сериализовал.
Что-то тут не так… Всем этим инструментам не хватает единого языка для общения, то есть некоторого представления AST, которое было бы, с одной стороны максимально простым и абстрактным, а с другой — позволяло бы выразить всё необходимое каждому инструменту, но не завязывалось бы на него.
И, на мой взгляд, формат Tree подходит для этого как нельзя лучше. Поэтому в перспективе было бы классно протолкнуть им идею перейти на этот формат. Но я для этого, к сожалению, недостаточно инфлюенсер. Так что не будем сильно раскатывать губу, но немного помечтаем..
А как бы выглядел пайплайн здорового человека?
- Распарсили в AST.
- Всё протрансформировали и прочекали.
- Сериализовали в скрипты/стили и сорсмапы.
Таким образом, основная работа проходит на уровне AST без промежуточных сериализаций. А даже если нам и потребуется временно сериализовать AST чтобы, например, передать его в другой процесс, то компактный Tree может быть сериализован и распаршен куда быстрее развесистого JSON.
Как избежать разъезда результата и сорсмапа? text.tree!
Ок, мы потрансформировали AST, осталось его сериализовать. Если это делать для каждого языка отдельно, то это будет слишком сложно, ведь иной язык может насчитывать десятки, а то и сотни типов узлов. И каждый нужно не только правильно сериализовать, но и правильно сформировать для него спан в мапинге.
Чтобы упростить эту задачу, мы со Стефаном разработали язык text.tree, где есть всего 3 типа узлов: строки, отступы и сырой текст. Простой пример..
line \{
indent
line
\foo
\:
\123
line \ }{
foo: 123
}
//# sourceMappingURL=data:application/json,
%7B%22version%22%3A3%2C%22sources%22%3A%5B%22
unknown%22%5D%2C%22sourcesContent%22%3A%5B%22
line%20%5C%5C%7B%5Cnindent%5Cn%5Ctline%5Cn%5C
t%5Ct%5C%5Cfoo%5Cn%5Ct%5Ct%5C%5C%3A%20%5Cn%5C
t%5Ct%5C%5C123%5Cnline%20%5C%5C%7D%5Cn%22%5D
%2C%22mappings%22%3A%22%3B%3BAAAA%2CAAAK%3BAACL
%2CAACC%2CCACC%2CGACA%2CEACA%3BAACF%2CAAAK%3B%22%7DЛюбой другой язык может быть сравнительно несложно трансформирован в text.tree без плясок вокруг спанов. А дальнейшая сериализация с формированием сорсмапов — это просто применение стандартных, уже написанных функций.
А если нужен WebAssembly? wasm.tree -> bin.tree
Ну а в дополнение к текстовой сериализации, у нас есть и сериализация бинарная. Тут всё то же самое: трансформируем любой язык в bin.tree, после чего стандартной функцией получаем из него бинарник. Например, возьмём не хитрый код на языке wasm.tree..
custom xxx
type xxx
=> i32
=> i64
=> f32
<= f64
import foo.bar func xxx\00
\61
\73
\6D
\01
\00
\00
\00Можно писать код как сразу на wasm.tree, так и на каком-либо своём DSL, который уже трансформировать в wasm.tree. Таким образом, вы легко можете писать под WebAssembly, не погружаясь в дебри его байт-кода. Ну… когда я этот компилятор таки допилю, конечно. Если кто-то готов помочь — присоединяйтесь.
Даже WASM с сорсмапингом?!
И, конечно, из bin.tree мы автоматически получаем и сорсмапы. Только вот работать они не будут. Для WASM нужно генерировать уже более взрослый формат мапинга, который используется для компилируемых языков программирования..
DWARF

Но в эти дебри мне пока страшно лезть..
Ничего не забыли?
Пока что мы говорили лишь про генерацию кода из нашего DSL. Но для комфортной работы с ним требуется ещё много вещей..
- Подсветка синтаксиса
- Подсказки
- Проверки
- Рефакторинги
Единое расширение, чтобы править всеми… Да ладно?!
У меня есть дикая идея — для каждой IDE сделать по одному универсальному плагину, который сможет читать декларативное описание синтаксиса языка и по нему обеспечивать базовую интеграцию с IDE: подсветку, подсказки, валидацию. Я пока что так реализовал подсветку.
На $mol-канале есть трёхминутное видео процесса описания нового языка для своего проекта..
Вам не нужно ничего перезапускать, ставить девелоперские сборки среды разработки или специальные расширения к ним. Вы просто пишете код, и он в реальном времени перекрашивает ваш DSL.
Справа вы видите код на языке view.tree, а слева описание этого языка. Плагин при этом ничего не знает про этот язык, но благодаря описанию знает, как его раскрашивать.
Что нужно для автоматической подсветки?
Работает это просто: встретив незнакомый язык (определяемый по расширению файла), плагин сканирует воркспейс на предмет существования схемы для этого языка. Если найдёт несколько схем, то соединяет их.
Есть требование и к самому языку — семантика его узлов должна задаваться синтаксически. Например, "начинается с доллара" или "имеет имя null". То есть не должно быть синтаксически неразличимых узлов, имеющих разную семантику. Это, впрочем, полезно не только для подсветки, но и для упрощения понимания языка самим пользователем.
Итого, что нужно:
- Декларативное описание языка.
- Синтаксическая привязка к семантике.
- Без установки для каждого языка.
- Дефолтная эвристика.
Да, описание языка вовсе не обязательно, ведь порой хватает и дефолтной эвристики для раскраски любых tree-based языков.
Куда-куда пойти?
На этом моё повествование подходит к концу. Надеюсь, мне удалось вас заинтересовать своими изысканиями. И если так, вам могут пригодиться следующие ссылки..
- nin-jin.github.io/slides/sourcemap — эти слайды
- tree.hyoo.ru — песочница для трансформаций tree
- lang_idioms — чат о разработке языков
-
_jin_nin_— твиты о JS
Спасибо, что выслушали. Мне полегчало.
Свидетельские показания
- ❌ Вначале было немного сложно сфокусироваться на проблематике.
- ❌ Сложновато и не видно, где это применять.
- ❌ Я так и не понял, зачем этот доклад нужен на этой конференции тему вроде раскрыл, но дезайн DSL несколько странный, практическая применимость = 0.
- ❌ Название не соответствует заявленному (даже минимально), информация о sourcemap идет с 5 минуты по 35-ю, в остальное время автор вещает про свой фреймворк, который не имеет никакого отношения к теме. Зря потратил время, лучше бы посмотрел другого автора.
- ✅ Прикольная тема и Дима даже почти отвязался от профдеформации с $mol.
- ✅ Интересный доклад. Дмитрий очень хорошо рассказал предметную область, осветил возможные проблемы и подумал об удобстве использования для пользователя. Очень круто!

Комментарии (28)

amakhrov
21.09.2021 00:42+2В качестве предупреждения: если хотите маппить стек трейс ошибок (например, из логов приложения) на исходники - забудьте по Safari как про страшный сон. Ну или помните - и игнорируйте.
Ибо Safari генерит трейсы как бог на душу положит, и после применения сорс мапов в лучшем случае что-то просто не смаппится, а в худшем - смаппится не туда, и долго разбираешься, что же пошло не так.
amakhrov
21.09.2021 02:37+1Насчет js.tree. А как его расширять доп метаданными?
К примеру, для генерации сорсмапов нам для каждого узла AST надо знать позицию в исходном файле. Babel это записывает в поле
rangeкаждого узла. Как это будет выглядеть в js.tree?
nin-jin Автор
21.09.2021 12:41Все tree-ноды имеют поле span, через которое можно получить координаты. Чтобы их увидеть в AST можно их заимпринтить, как тут. Это полезно при передаче между процессами, чтобы при сериализации не терялись ссылки на исходники и сами исходники.
В общем же случае, в любой узел можно подкладывать кастомный узел с метаданными. Например, добавим аннотации типов:
const foo @ [,] any [,] @ [,] | number string 123 @ number bar @ stringПросто нужно не забыть эти узлы вырезать перед трансляцией в JS.

bjornd
21.09.2021 13:04Как вводная часть статьи выглядит для ничего не подозревающего человека:
Сейчас вы видите законченное приложение на $shmol:
$my_appОно состоит из панельки, внутри которой расположен чекбокс. И вместе они связаны двусторонней связью по заданным свойствам. В этой 1 строчке кода есть даже поддержка локализации. Эквивалентный код на JavaScript занимает в 25 раз больше места.

SnakeSolid
22.09.2021 22:04+1@nin-jin, у вас есть подробное описание того, как работает hack()? Из примеров и ссылок на tree.hyoo.ru не совсем понятно как интерпретируются наборы скобочек со знаками препинания и как происходит поиск и подмена узлов в исходном дереве. Можно ли описать трансформацию нескольких узлов в дереве по шаблону, например поменять местами узлы сохраняя все их листья как есть.
nin-jin Автор
23.09.2021 09:48+1Проще, наверно, просто код глянуть. Хак проходится по всем дочерним узлам, смотря на их типы. Если для типа задан хендлер, то заменяет узел на тот список узлов, что что он вернёт. Дефолтный хендлер возвращает клон узла, применяя хак к каждому ребёнку. Таким образом, если не задать никаких хендлеров, то хак просто склонирует всё дерево. Ну а в кастомном хендлере можно делать что хочешь. Можно вернуть поддерево как есть без какого-либо процессинга, создавать новые деревья, хачить сторонние деревья и тд.
Поиска по шаблону пока что нет. У меня есть реализация сверки шаблонов, но она специфична для конкретного языка. В общем же случае, нужно проработать язык шаблонов и сделать их компилятор, чтобы выбирать шаблон, на который сматчиться, за один проход, а не в цикле по шаблонам.
pecheny
Спасибо за подробный и полезный материал! Имею возражение только по списку сравнения из раздела про «велосипед».
Есть такой язык – Haxe. И там практически все это есть из коробки. И макро апи для работы с AST, и Printer который прямо в консольку напечатает кусок AST в виде уже готового кода. И таргетов намного больше. И сурсмапы из коробки работают.
Вот так, например, выглядит макрос, который в любой, отмеченный метой, класс
– докинет интовое поле
– если есть метод main(), то докинет в него вывод приветствия
– выведет все поля класса в виде кода в консоль во время компиляции.
Поиграться можно здесь. Код макроса на вкладке Source 2, вывод полей – Compiler output.
nin-jin Автор
Haxe, конечно, классный язык, но в качестве DSL он слабо подходит. Для обычного пользователя он слишком сложен. Для анализируемых конфигураций он слишком привязан к Haxe. А возможности AST ограничены лишь моделью Haxe.
pecheny
Ну, если пользователю не показывать всякие макросы, то на уровне прикладного кода он довольно прост. Если DSL ориентированы вообще для не-программистов, то преимуществ у Haxe, конечно, будет меньше. Тем не менее, если даже написать свой макро, который парсит произвольный язык и строит Haxe-AST, то мы сразу получаем возможность выгонять его на кучу таргетов – это все равно хорошее подспорье, я считаю. Поскольку в языке представлено достаточно много концепций, то выразить в терминах его AST можно очень многое, хоть оно и не «абстрактное».
По крайней мере, под определение «пайплайна здорового человека» он подходит больше, чем все конкуренты из статьи, поэтому быть упомянутым в качестве альтернатив он достоин.
forthuse
Что то мало решённых задач с ресурса rosettacode.org на Haxe (всего 52-а решения)


Если нужен «экстремально» простой и гибкий язык программирования, то даже в качестве DSL — Domain Specific Language применяют Forth (Форт).
При программировании микроконтроллеров и зачастую как основной инструментарий.
Была и статья на Хабр Универсальный DSL. Возможно ли это?
где Форт рассматривался в качестве DSL языка C# проекта.
Вот и ещё пример — EFrt проект полной реализации Форт на C#
P.S. Конечно же, «поверх» JavaScript JeForth.3we — Форт тоже делают
И на Github достаточно ещё проектов по связке Форт и JS
Mako.JS — Демо игры проекта запускаемые в браузере, с Форт в качестве DSL
Mako on Github
nin-jin Автор
Forth имеет постфиксную нотацию, что для людей крайне не удобно. Но её легко превратить в префиксную, которую воспринимать уже гораздо легче.
Например, возьмём эту программу на форте:
И напишем эквивалентную в префиксной нотации:
forthuse
Да, это и другие возможности доступны и при использовании Форт, но если бы только специфичность Форт была только в постфиксе, то это был бы не Форт, а что то близкое к калькуляторному языку MK-61 и вряд ли Форт, на протяжении 50-ти лет своего существования смог бы войти тогда в современный топ 50-ти языков программирования по версии IEEE Spectrum
P.S. Кстати, страшилки по поводу неудобства «формата» записи Форт программ немного преувеличена в отношении к нему и эта «страшилка Forth» не на первом месте по степени грамотного понимания и использования Форт языка, есть и другие, но серое вещество мозга достаточно гибкая система при её «переформатировании». Форт, как «искуственный» компьютерный язык, гораздо проще в освоении чем, например, иностранный естественный язык по поводу которого нет «предвзятых» взглядов.
В России Форт начался и так же быстро сощёл со сцены в мутные 90-е годы безвременья.
Баранов С.Н. «Язык Форт в СССР и России»
nin-jin Автор
Да, надо ещё очень внимательно следить за содержимым стека. Ибо одно неверное движение, и программа ведёт себя непредсказуемым образом. С этим людям ещё сложнее управляться. Поэтому для тог же WASM кроме постфиксной нотации с ручным управлением стеком, есть и префиксная, где стеком управляет компилятор, а программист управляет лишь виртуальными регистрами.
forthuse
Если следить за стэком становится следить сложно в Форт программе, то что то не правильно делается по его использованию. :)
Обычно происходят мелкие перестановки 2-3 элементов стэка и они не сложно понимаемы. Для других — «особо тяжёлых случаев» никак не ложащихся в алгоритм в Форт реализации можно использовать, например, локальные переменные появившееся в Форт стандарте 94года.
И, конечно, Форт, как язык нацеленный на использование метапрограмирования и DSL наиболее значимо себя проявляет именно при использовании таких техник его использования неплохо описанных во 2-й книге за авторством Броуди «Мышление Форт».
P.S. И, локально оттестировать поведение слова не сложно в Форт.
nin-jin Автор
А стат типизация там есть, чтобы гарантировать, что к моменту применения слова на стеке уже лежит всё необходимое, а после применения не лежит ничего лишнего? В васме, например, ошибки со стеком приводят к падению в рантайме.
forthuse
А, она в нём в целом не нужна т.к. на стеке лежат числа в размере 1-й ячейки хранения принятой в том или ином Форте 16/32/64 а возможность по типизации их предоставляется программисту по применению слов с разными именами ( +, D+ ...) оперирующими сколько, как и в каком размере оперировать ими на стэке.
Если, программист, по определению не даун, то это им легко должно легко пониматься, а если что пошло не так, то последствия его действий не заставят себя ждать (Форт упадёт и/или выведет информацию об эксепшене)
Для чисел плавающей арифметики есть отдельный стэк со словами подобными F+, F-…
P.S. Конечно, в более серьёзном Форт инструментарии может в процессе трансляции программы выводится и проверяться соответствие типов данных и операций применённых к ним, но обычно на это все использующие Форт обычно кладут «болт» и особо не парятся :)
Хотя есть варианты Форт -типа StrongForth где разработчики его стали контролировать типизацию в их Форт.
Если интересен более продвинутый «Форт», то есть например Factor — язык программирования. где на стэк помещаются уже более комплексные сущности чем числа.
pecheny
А вы не могли бы продолжить мысль? Это по каким-то критериям должно влиять на принятие решения о выборе инструмента?
Применять-то применяют совершенно разное. И выбирают по совершенно разным критериям, в зависимости от ситуации. Я бы предположил, что если бы была возможность оценить количество всего, что можно посчитать DSL, то в «наколенных» условиях, коих большинство, победили бы JSON/XML, так как для них вообще не надо задумываться о лексерах-парсерах-синтаксических деревьях, все инструменты для разбора доступны с любого языка/платфомы.
Посыл автора я не совсем понял. Особенно вот эту сентенцию
Я не понимаю, как ограничение доступных средств может обеспечить возможность более короткой записи логики. На самом деле, здесь происходит подмена понятий, а «выразительность» достигается комплектными командами. При предоставлении такого же апи, запись этой логики на «родительском» языке вряд ли будет сильно длиннее.
Кроме того, предлагается самостоятельно велосипедить с нуля интерпретатор. Это может оказаться хорошим решением в некоторых ситуациях, но вряд ли во всех. На месте пользователя DSL из той статьи я бы предпочел что-то на основе XML или хотя бы JSON.
Вообще, когда речь заходит про «запилить по-быстрому язык для своей системы с ноля», то в первую очередь в голову придет лисп из-за простоты и надежности. Хотя он далеко не самый юзер-фрэндли для пользователя.
В других ситуациях хорошим решением будет встроить в систему каую-нибудь lua, выствив для нее нужный апи. Это уже и не совсем DSL, но области применимости могут пересекаться.
forthuse
Например для типовых примеров уже готовых решений в рамках использования нового языка в чём разница Hexe с другими языками на «типовом» примере задачи.
Сентенция с Форт, в общем понимании его как языка программирования приводит к возможности записи каких то «макросов» близко по форме к естественным языкам.
Для кого то это хорошо, а кто то без явно синтаксическо-семантических ограничений присутствующих в современных языках даже не сможет понять для использования Форт.
т.е., наши привычки и освоенные взгляды — наши же «оковы» из «недоступности» понимания, что пути решения задач этим не ограничивается.
Форт ещё проще т.к. в нём нет скобок в Лисп понимании и он прямолинеен по последовательности выполнения слов при трансляции кода программы в исполнение.
На уровне трансляции Форт программ в базисе Форт нет даже понятия синтаксиса языка, кроме того, что мы имеем дело со словами — самодостаточными сущностями во взаимодействии с другими словами и создающими свой контекст при их использовании для других слов.
Уф… :)
pecheny
А сколько «типовых примеров» в штуках вам надо, чтобы сравнивать языки? 50 мало, я понял.
Если серьезно, то не вижу, какая разница 10 или 20 сортировок написано на языке для примера, они используют одни и те же конструкции. Гораздо эффективнее заглянуть на сайт языка, часто на главной странице есть выразительный пример. У Haxe кроме документации есть еще и весьма интересный кукбук.
forthuse
Чем больше, тем лучше и желательно с их описанием
и если есть кукбук, то не должно (или должно) возникнуть сложностей с их размещением и в рамках этого ресурса и возможно со ссылками и в самой «Книге рецепов для IT повара на Hexe»
pecheny
Не думаю, что кто-то будет возражать, если вы перенесете примеры из кукбука на розетту или куда-либо еще.
forthuse
Как ни «странно», но на Хабр есть Хаб по Haxe («эпизодически» пополняемый статьями одним пользователем, в последнее время, и количеством подпичиков — 759)
P.S. Не являясь пользователем Haxe мне сложно перенести примеры из кукбоок на ресурс rosettacode.org.
forthuse
Дополню предыдущее сообщение.
pecheny
Спасибо за ссылки по Haxe. Поправлю ссылку на хаб, у вас лишняя кавычка затесалась, и поэтому она не работает. Этого видео не встречал раньше. Оно довольно интересное, но ему 8 лет, и оно очень сильно отстало от реалий. Neko VM сейчас deprecated, на ее место пришли HashLink и режим интерпретатора. Но для сервера нет смысла тащить отдельную ВМ, так как сейчас haxe транспилируется и в php, и в питон, и в JVM-байткод (а также в js, cpp, c#, lua), так что haxe-код можно выполнять в рамках существующих серверов в совершенно разных стеках.
forthuse
А, есть примеры транспиляциии в Haxe из других языков?
Или это «сложно/нецелесобразно»?
pecheny
Такие примеры есть, но не очень много. В первую очередь, это транспиляция из ActionScript3 – это позволяет относительно «дешево» переносить проекты с умершего флэша на актуальные платформы. Насколько я знаю, у компании достаточно обширная кодовая база на AS3, которую они продолжают развивать. Haxe используется как промежуточный шаг при компиляции веб-клиета. Было несколько попыток для тайпскрипта, например, а также для go. Об их функциональности и работоспособность я ничего не знаю.
nin-jin Автор
А как у него с, собственно, сорсмаппингом при трансляции в другие языки?
pecheny
Сорсмапы в чистом виде поддерживаются для двух таргетов: Js и PHP. Но сорсмапы имеют смысл, когда они поддерживаются инструментарием целевого языка. Помощь в отладке в том или ином виде есть на всех таргетах, то есть стектрейс по haxe-исходникам получить можно. Для Hashlink и Cpp, насколько я помню, дебаггер работает нормально и позволяет в VSCode перемещатсья по исходникам из стектрейса, смотреть переменные, ставить брейкпоинты. HashLink позволяет транслировать в С. В плюсовом коде маппинги вписываются непосредственно в транслированный код, выглядит это как-то так:
Если речь идет об отладке прикладного кода, то великолепно работает связка flash+idea. Быстрая компиляция и очень удобный дебаггер от JetBrains. Когда я работал над юнити проектами, то стектрейсы из редактора тоже нормально мапились (там c#).