
В этой статье мы познакомимся с подходом к разработке конвейеров потоковой обработки данных (от англ. Streaming Data Pipelines) с помощью фреймворка Lightbend Cloudflow:
рассмотрим фреймворк с точки зрения общей концепции и разработки;
обратимся к архитектуре demo-проекта и его имплементации на языке Scala.
Технологический стек:
Что такое Cloudflow?
Cloudflow – это open-source фреймворк от компании Lightbend, объединяющий в себе набор инструментов для разработки программного обеспечения и набор расширений Kubernetes.
Первый набор – это software development kit, который позволяет ускорить разработку распределенных потоковых приложений. Нам открывается доступ к популярным движкам для потоковой обработки данных, таких как: Akka, Flink и Spark, а в качестве транспорта сообщений между приложениями – Kafka.
Второй набор – волшебная палочка для оркестрации распределенными потоковыми приложениями с помощью Kubernetes. Более подробно о нем мы попросим написать наших коллег из Ops в отдельной статье.
Заявленный профит
Disclaimer. Информация описанная в данном разделе является вольным переводом автора с главной страницы официального сайта Lightbend Cloudflow.
Значительное ускорение разработки потоковых приложений в результате сокращения времени на их создание, упаковку и развертывание с нескольких недель до нескольких часов. И вот за счет чего:
Разработка. Возможность сосредоточиться на бизнес-логике и избавиться от бойлерплейта;
Сборка. Богатый набор средств разработки для перехода от бизнес-логики к развертываемому приложению;
Развертывание. Набор расширений Kubernetes для кластера и клиента, которые дают возможность развертывания распределенной системы с помощью одной команды.
Основные понятия
Schema-first подход
Для построения pipeline’ов фреймворком предусмотрен подход, основанный на схеме данных. Суть подхода состоит в преобразовании данных доменной модели, для которой требуется построить поток обработки, в схемы данных.
В качестве системы сериализации данных используется Apache Avro или Google Protobuf. Обе системы поддерживаются Kafka, а для генерации Avro-схем в Scala-классы фреймворк имеет специальные модули, подключаемые в систему сборки. Что немаловажно, Avro-схемы имеют механизм обратной совместимости.
Attention! Использование в качестве системы сериализации Google Protobuf на момент написания статьи – экспериментальная возможность фреймворка.
Streamlet
Streamlet -– основная модель компонентов Cloudflow. В привычной системе координат, за исключением нижеперечисленных особенностей, к streamlet’у можно относиться как к микросервису.
Строго типизированные входы и выходы
Streamlet’ы имеют inlet’ы и outlet’ы, иными словами – входы и выходы. В коде они представляют собой типизированные классы, параметризированные заранее созданной Avro-схемой.
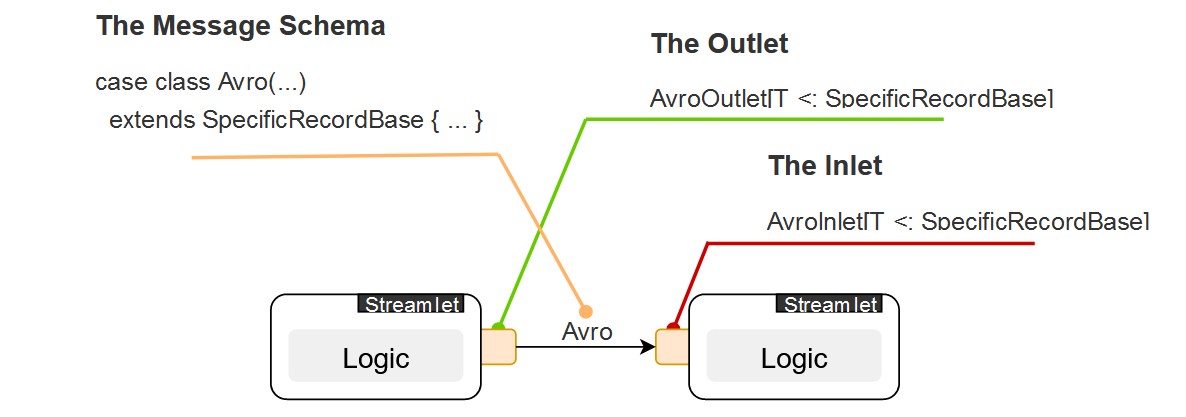
Строгая типизация в данном контексте позволяет своевременно и эффективно контролировать соблюдение контракта взаимодействия streamlet’ов внутри pipeline. Чуть более наглядно об этом - при рассмотрении компонента под названием Blueprint.
Формы и взаимодействие
Форма streamlet’а напрямую зависит от количества его входов и выходов, а коммуникация между streamlet’ами осуществляется через Kafka.
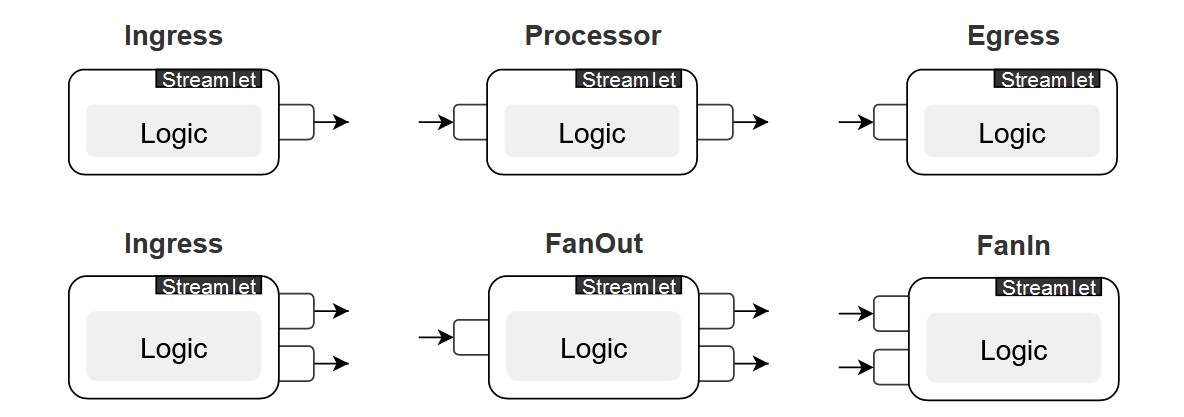
Из этого следует, что producer’ы и consumer’ы в streamlet’ах представлены уже знакомыми нам inlet’ами и outlet’ами. В коде у них есть соответствующие методы для настройки таких параметров, как: name, uniqueGroupId, partitioner, errorHandler.

Интерфейсы
При создании streamlet’а, в зависимости от поставленной задачи, мы можем выбрать одну из трех потоковых сред обработки. Для этого у Cloudflow под капотом есть базовые абстракции: AkkaStreamlet, FlinkStreamlet и SparkStreamlet со всей необходимой обвязкой. Данные классы позволяют приступить к разработке логики приложения, избежав значительного количества бойлерплейта.
/*The Synthetic Streamlet Example*/
class MyFlinkProcessor extends FlinkStreamlet {
val in = AvroInlet[Data]("in")
val out = AvroOutlet[Simple]("out", _.name)
val shape = StreamletShape(in, out)
override def createLogic() = new FlinkStreamletLogic {
override def executeStreamingQueries = {
// do logic
}
}
}Blueprint
Blueprint - это чертеж, описанный на языке HOCON, в котором мы отображаем целевую картину взаимодействия streamlet’ов внутри pipeline. Графически его можно представить так:

А так выглядит содержимое файла blueprint.conf:
blueprint {
streamlets {
transiever = dope.nathan.movement.data.transceiver.Transceiver
converter = dope.nathan.movement.data.converter.Converter
collector = dope.nathan.movement.data.collector.Collector
}
topics {
transiever_sensor-data-got {
producers = [transiever.sensor-data-got-out]
consumers = [converter.sensor-data-got-in]
}
converter_track-made {
producers = [converter.track-made-out]
consumers = [collector.track-made-in]
}
}
}С помощью sbt-команды verifyBlueprint плагина Cloudflow запускается проверка соблюдения контракта взаимодействия streamlet'ов внутри pipeline. Другими словами - проверка соответствия написанного кода заявленному чертежу. Данный подход можно рассматривать, как дополнение к интеграционным тестам.
Note. Команда
verifyBlueprintможет запускаться как по требованию, так и в автоматическом режиме, например, в рамках выполнения командыrunLocal(см. раздел Тестирование).
Разработка
Анализ
Бизнес требование
Представим, что к нам обратился Плейстоценовый парк. Ученые в борьбе с таянием вечной мерзлоты задумали восстановить экосистемы ледникового периода на территории республики Саха (Якутия) в России. Они завезли бизонов из Дании на территорию парка, и теперь для исследовательских целей им необходимо отследить миграцию популяции с использованием GPS-датчиков.
Техническое задание
Разработать MVP конвейера, который будет получать на вход данные с GPS-датчиков, преобразовывать их и собирать.
Note. С полным кодом demo-проекта можно ознакомиться на GitHub.
Архитектура пайплайна
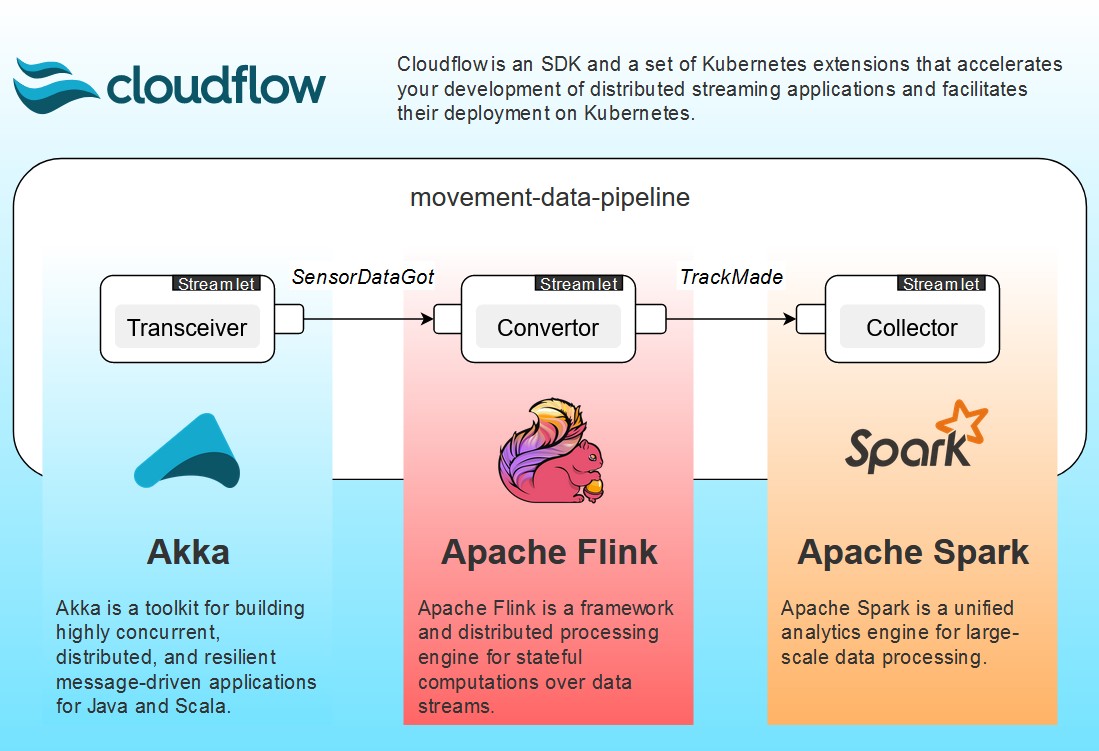
Реализация
Конфигурация
build.properties
sbt.version = 1.5.4cloudflow-plugins.sbt
Фундаментом при создании pipeline с помощью Cloudflow является набор плагинов Sbt, которые могут упаковывать наше приложение в развертываемые модули. Базовым плагином является “sbt-cloudflow”. Так что файл cloudflow-plugins.sbt наряду с build.properties – это первое, о чем стоит позаботиться при создании проекта Cloudflow.
addSbtPlugin("com.lightbend.cloudflow" % "sbt-cloudflow" % "2.1.0")build.sbt
Файл, на основании которого будет строиться структура директорий и создаваться модули проекта в IDE:
// (1) - Enabling The Cloudflow Plugins
lazy val root = (project in file("."))
.settings(
name := ProjectName,
version := ProjectVersion,
publish / skip := true,
CustomSettings.commons
)
.withId(ProjectName)
.aggregate(
pipeline,
datamodel,
transceiver,
converter,
collector
)
lazy val pipeline = appModule(postfix)
.enablePlugins(CloudflowApplicationPlugin) // (1)
.settings(
blueprint := Some("blueprint.conf"),
runLocalConfigFile := Some(s"$ProjectResources/sandbox/local.conf"),
runLocalLog4jConfigFile := Some(s"$ProjectResources/sandbox/log4j.properties")
)
.dependsOn(datamodel, transceiver, converter, collector)
/* The auxiliary things are here */
lazy val common = appModule("common")
.settings(
libraryDependencies += Logback,
Test / parallelExecution := false
)
/* The Avro-schemas are here */
lazy val datamodel = appModule("datamodel")
.enablePlugins(CloudflowLibraryPlugin) // (1)
/* The Akka Streamlet Module */
lazy val transceiver = appModule("transceiver")
.enablePlugins(CloudflowAkkaPlugin) // (1)
.settings(
libraryDependencies ++= commons,
Test / parallelExecution := false
)
.dependsOn(datamodel)
/* The Flink Streamlet Module */
lazy val converter = appModule("converter")
.enablePlugins(CloudflowFlinkPlugin) // (1)
.settings(
libraryDependencies ++= commons ++ flinkTestKit,
Test / parallelExecution := false
)
.dependsOn(datamodel, common)
/* The Spark Streamlet Module */
lazy val collector = appModule("collector")
.enablePlugins(CloudflowSparkPlugin) // (1)
.settings(
libraryDependencies ++= (commons :+ AkkaSlf4j),
Test / parallelExecution := false
)
.dependsOn(datamodel, common)
def appModule(moduleID: String): Project = {
Project(id = moduleID, base = file(moduleID))
.settings(
name := moduleID,
idePackagePrefix := Some(s"$Company.$namePart1.$namePart2.$moduleID"),
CustomSettings.commons
)
.withId(moduleID)
}
blueprint.conf
Говоря, что blueprint - это просто чертеж, мы конечно упрощали. При необходимости, в нем можно кастомизировать настройки Kafka:
common-kafka-config = {
producer-config {
linger.ms = 5
batch.size = 131072
max.request.size = 3145728
}
consumer-config {
max.partition.fetch.bytes = 3145728
fetch.max.bytes = 3145728
}
}
blueprint {
streamlets {
transiever = dope.nathan.movement.data.transceiver.Transceiver
converter = dope.nathan.movement.data.converter.Converter
collector = dope.nathan.movement.data.collector.Collector
}
topics {
transiever_sensor-data-got = ${common-kafka-config}{
producers = [transiever.sensor-data-got-out]
consumers = [converter.sensor-data-got-in]
}
converter_track-made = ${common-kafka-config}{
producers = [converter.track-made-out]
consumers = [collector.track-made-in]
}
}
}
local.conf
Для тестирования работы pipeline потребуется еще один файл с расширением .conf. Он будет использоваться при локальном запуске pipeline в песочнице:
cloudflow.streamlets {
converter.config-parameters {
auto-watermark-interval = 200ms
track-window-duration = 60s
max-time-delay-of-track-points = 5s
track-window-release-timeout = 30s
}
}На текущем этапе в нашем pipeline специфические параметры конфигурации понадобились только для одного streamlet’а, остальные - без параметров.
log4j.properties
Для наглядности работы pipeline в режиме песочницы, логирование точечно переведено на debug-уровень.
# Root logger option
log4j.rootLogger=INFO, stdout
# Direct log messages to stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.EnhancedPatternLayout
log4j.appender.stdout.layout.ConversionPattern=[%p] [%d{HH:mm:ss.SSS}] %c{2.}:%L %m%n
log4j.logger.cloudflow=INFO
log4j.logger.dope.nathan=DEBUG
log4j.logger.localRunner=DEBUG
# Noisy Exclusions
log4j.logger.org.apache.spark=ERROR
log4j.logger.org.spark_project=ERROR
log4j.logger.kafka=ERROR
log4j.logger.org.apache.flink=ERROR
*.avsc
Файлы с данным типом расширения представляют собой Avro-схемы и находятся в модуле под названием "datamodel". Данный модуль проекта отвечает за хранение моделей данных как в виде Avro-схем, так и в виде сгенерированных Scala-классов (в папке "target"). Благодаря плагину CloudflowLibraryPlugin Avro-схемы распознаются Sbt и являются основанием для генерации Scala-классов при сборке проекта.
Note. Директория, содержащая сгенерированные Scala-классы (например, datamodel/target/scala2.12/scala_avro), должна быть помечена в IDE как Generated Sources Root.
Пример Avro-схемы:
{
"namespace": "dope.nathan.movement.data.model",
"type": "record",
"name": "Track",
"fields":[
{ "name": "id", "type": "string" },
{ "name": "carrier", "type": "string"},
{ "name": "metrics",
"type": "dope.nathan.movement.data.model.track.Metrics"
}
]
}Пример класса, сгенерированного на основе Avro-схемы:
import dope.nathan.movement.data.model.track.Metrics
case class Track(var id: String, var carrier: String, var metrics: Metrics)
extends org.apache.avro.specific.SpecificRecordBase {
// the SpecificRecordBase implementation
}
object Track {
// the companion object logic
}Streamlets
Transceiver (Akka Server) Streamlet
/*
* (1) - the String parameter is a part of the producer name
* (2) - the logic is here
* */
trait TransceiverOpenings {
val sensorDataGotOut: AvroOutlet[SensorDataGot] =
AvroOutlet("sensor-data-got-out") // (1)
}
trait TransceiverBase extends AkkaServerStreamlet with TransceiverOpenings {
import json.SensorDataGotJsonProtocol.SensorDataGotJsonFormat
final override def shape: StreamletShape =
StreamletShape.withOutlets(sensorDataGotOut)
final override def createLogic: AkkaStreamletLogic =
HttpServerLogic.default(this, sensorDataGotOut) // (2)
}
object Transceiver extends TransceiverBaseTransceiver отвечает за получение данных по http и передачу их Converter’у в виде сформированного события SensorDataGot.scala. При локальном запуске пайплайна http-сервер будет принимать POST запросы по адресу http://localhost:3000.
Тело запроса выглядит следующим образом:
{
"sensor": {
"id": "ID-1",
"carrier": "Bob",
"metrics": {
"timestamp": 1630701100,
"geoposition": {
"coordinates": {
"lat": 1.0,
"lon": 1.0
},
"direction": "N"
}
}
},
"eventTime": 1630706100
}Converter (Flink) Streamlet
/*
* (1) - the parameter is part of the consumer\producer name
* (2) - the logic is here
**/
trait ConverterOpenings {
@transient val sensorDataGotIn: AvroInlet[SensorDataGot] =
AvroInlet("sensor-data-got-in") // (1)
@transient val trackMadeOut: AvroOutlet[TrackMade] =
AvroOutlet("track-made-out") // (1)
}
trait ConverterBase extends FlinkStreamlet with ConverterOpenings {
override def shape(): StreamletShape =
StreamletShape
.withInlets(sensorDataGotIn)
.withOutlets(trackMadeOut)
override def configParameters: Vector[ConfigParameter] =
FlinkConfig.allParameters
override protected def createLogic(): FlinkStreamletLogic =
new ConverterLogic(FlinkConfig.apply) // (2)
}
object Converter extends ConverterBaseConverter подписан на событие SensorDataGot.scala, исходящее от Transceiver’а, как было описано выше. В результате обработки данных, полученных из события, в Converter’е формируется трек и создается событие TrackMade.scala, на которое подписан Collector. (см. ConverterLogic.scala)
Collector (Spark) Streamlet
/*
* (1) - the parameter is a part of the consumer name
* (2) - the logic is here
* */
trait CollectorOpenings {
val trackMadeIn: AvroInlet[TrackMade] =
AvroInlet("track-made-in") // (1)
}
trait CollectorBase extends SparkStreamlet with CollectorOpenings {
override def shape(): StreamletShape =
StreamletShape.withInlets(trackMadeIn)
override protected def createLogic(): SparkStreamletLogic =
new CollectorLogic // (2)
}
object Collector extends CollectorBase {
// to run in the sandbox
System.setProperty(
"hadoop.home.dir",
"C:\\Spark\\spark-2.4.5-bin-hadoop2.7"
)
}Collector принимает событие TrackMade.scala от Converter’а, достает из него сформированный трек и выводит данные в лог. (см. CollectorLogic.scala)
Тестирование
Перед локальным запуском pipeline позаботьтесь, чтобы у вас на машине был запущен Docker. После этого достаточно передать Sbt команду runLocal.
Note. Для локального запуска Spark Streamlet’ов операционной системе нужно указать путь к домашней директории Hadoop (см. objetc Collector). Архивные версии Hadoop ищите тут. Для Windows в директорию hadoop/bin потребуется положить файл winutils.exe (не забудьте после скачивания архива проверить контрольную сумму по SHA-256).
Чтобы получить записи в логах streamlet’ов, сделайте несколько POST запросов к http://localhost:3000 после того, как pipeline запустится. Данные можно взять тут.
Вместо заключения
Мы рассмотрели фреймворк Lightbend Cloudflow и реализованную на его базе систему потоковой обработки данных, состоящую из трех микросервисов, каждый из которых обладает:
слабой связностью внутри системы;
высоким уровнем соблюдения контракта взаимодействия между собой;
настраиваемыми механизмами отказоустойчивости;
открытыми API для создания систем метрик;
возможностью эволюционировать до приложения near-real time обработки данных.
Важно: благодаря набору расширений Kubernetes от Cloudflow данная система микросервисов “разворачивается” как единая платформа.
Резюмируя: в терминах Lightbend мы рассмотрели фреймворк по созданию Fast Data систем. Подробнее о том, что подразумевается под этим термином читайте в Readme.md Cloudflow.
А теперь, давайте, пофантазируем. Представьте, что у вас:
десятки микросервисов потоковой обработки с различными API (возможно, без механизма обратной совместимости);
всего несколько рук в команде ИТ-обслуживания;
десяток-другой разработчиков, которые непрестанно рефакторят код;
воинственно настроенные тестировщики, без конца требующие редеплоя во имя проверки качества.
Кажется, что при таких условиях Cloudflow – действительно хорошее решение для поставленной задачи.
Но очень интересно узнать, не появились ли у вас доводы против? Или, возможно, вы научились эффективно решать такие задачи с помощью других технологий?
Пишите комментарии, - мы открыты к обсуждению. Спасибо!