

Подобных инструментов довольно много. В топиках на Хабре масса обзоров сервисов для анализа сайтов и результатов поиска.
Например, здесь описано 30+ решений, а в двух других топиках (https://habr.com/ru/company/globalsign/blog/466911/ и
habr.com/ru/post/340302) описаны правовые аспекты этой темы.
Сравнение и выбор оставляю за читателями, в статье публикую только примеры использования конкретного инструмента на своем опыте.
Возможности и интеграции
Какие возможности предоставляет XMLRiver:
- анализ поисковой выдачи (в том числе, конкурентов, товарной выдачи, картинок, новостей Google);
- проверки позиций;
- кластеризации семантики;
- проверки индексации страниц.
С каким софтом «дружит» сервис:
- XMLRiver.Parser (собственное простое приложение сервиса для сбора данных поисковой выдачи и проверки индексации);
- Key Collector;
- KeyAssort (кластеризация семантики);
- TopSite (проверка позиций);
- SerpParser (проверка позиций);
- PositionMeter (бесплатная проверка позиций).
Просто, быстро и без головной боли
В свое время я отказался от аренды прокси для работы с проверкой позиций, анализа выдачи и прочим, т.к. «живые» сервисы находить все сложнее, а платить ежемесячно и еще капчу вводить − такое себе развлечение. Сейчас пользуюсь, в основном, облачными сервисами или софтом с API.
В плане многопоточной работы описанный выше «головняк» берет на себя XMLRiver.
Работа ведется в 10 потоков, что обеспечивает скорость сбора примерно 15 тысяч запросов в час.
Для начала потребуется выбрать параметры, скопировать ссылку и добавить ее в настройки вашего софта:

Документация по использованию сервиса написана простым языком с примерами, поэтому трудностей не возникнет даже у новичка. Она полезна как разработчикам, так и простым пользователям, чтобы понимать, какие возможности предоставляет сервис.
Кроме того, на страницах параметров есть краткая справка:

В настройках масса параметров (в т.ч. съем «нулевой позиции» и «подсветок»), поэтому можно проводить довольно глубокую аналитику и для конкурентного анализа:

Что еще понравилось: высокая точность. Я пробовал достаточно много вариантов, тот же Мегаиндекс, и сравнивал вручную выдачу с тем, что отдается сервисами. XMLRiver дает более 90% совпадений.
Пример того, как выглядит файл xml, если задать запрос в браузере:

Результаты выдачи:

Использование XMLRiver.Parser и языка поисковых запросов
Например, можно получить результаты выдачи с документами в формате pdf.
Импортируем текстовый файл с запросами:

Получаем на выходе 1000+ документов по аудиту сайтов для изучения конкурентов в считанные секунды:

Анализ выдачи Google в XML
В большинстве десктопных приложений, ориентированных на seo отрасль, интегрирован сервис XMLRiver. Но даже там, где нет, обходится это довольно просто, т.к. формат взаимодействия повторяет очень популярный ЯндексXML. Покажу на примере Key Collector 3 (не смотря на то, что уже вышла 4я версия программы, многие по привычке продолжают пользоваться 3й).
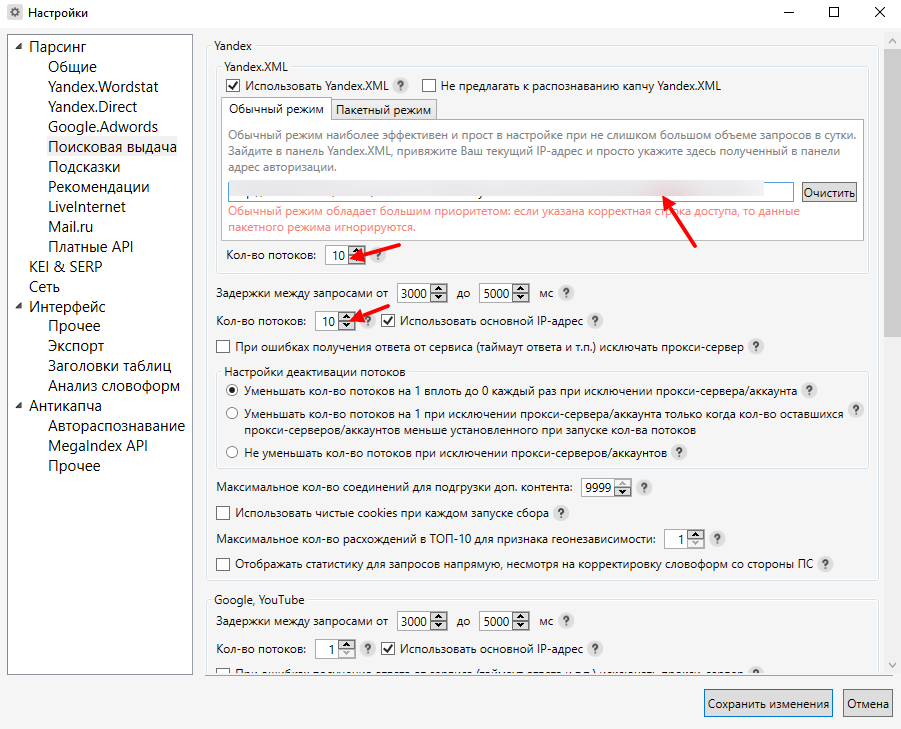
В настройках парсинга поисковой выдачи нужно вставить свой ключ от Гугла:

И указать нужное количество потоков:
После чего получить нужные данные в KK (информация появится в колонках Яндекса, но по факту это анализ выдачи Google):
Разработчики охотно идут навстречу пожеланиям пользователей, поэтому если чего-то не хватает — можно смело писать в поддержку.
Итоги
Сервис удобен для работы как в связке с другими инструментами (я пользуюсь Key Collector), так и в качестве самостоятельного «бойца». При такой скорости и стоимости обработки 20 рублей за 1 000 запросов для Google и 10 − для Яндекса − без аренды и решения проблем “на лету”, хорошая альтернатива существующим онлайн-решениям.
Поделитесь, какими сервисами для анализа поисковой выдачи вы пользуетесь, и почему?
Комментарии (6)


Hungry_Hunter
31.10.2021 11:24На сколько я помню, первопроходцами в теме парсинга Google и Яндекса в разных форматах ( XML, JSON, HTML) были XMLstock. Могу ошибаться, но пользуюсь ими почти с самого открытия до сих пор, все более чем устраивает.
Вижу тема развивается, и появляются новые сервисы. Конкуренция это хорошо, посмотрим что за новый сервис.

wilelf Автор
01.11.2021 16:52Насколько мне известно, xmlstock частично скопировал XMLRiver, и появился почти на год позже (если мы говорим о прямой выдаче Google).
alexprey
Забавно и может быть очень полезно. А как с гугл капчами боролись? Есть проблемы со скоростью обработки запросов (задержки, rps), интересует как быстро я смогу выкачать весь гугл?)
Hidadmin
Алексей, тебе ли не знать как ))
wilelf Автор
Задержек не заметил. Про капчи забыть можно.