
До того как заняться реверс-инжинирингом, исполняемые файлы казались мне черной магией. Я всегда интересовался, как все работает под капотом, как двоичный код представлен внутри .exe файлов, и насколько сложно модифицировать “исполняемый код” без доступа к исходникам.
Но одним из главных препятствий был язык ассемблера, отпугивающий большинство людей от изучения этой области.
Это главная причина, по которой я задумался о написании этой статьи, содержащей только самые важные вещи, с которыми чаще всего сталкиваются в реверс-инжиниринге, хотя она и упускает некоторые детали для краткости, предполагая, что у читателя имеются навыки поиска определений и ответов в Интернете и, что более важно, придумывания примеров / идей / проектов для практики.
Цель состоит в том, чтобы направить начинающего реверс-инженера и вдохновить на изучение этого, казалось бы, труднопостижимого увлечения.
Примечание: предполагается, что читатель обладает элементарными знаниями о шестнадцатеричной системе счисления, а также о языке программирования С. В качестве примера используется 32-разрядный исполняемый файл Windows — результаты могут отличаться на других ОС/архитектурах.
Вступление
Компиляция
Код, написанный на компилируемом языке, компилируется (еще бы) в выходной двоичный файл (например, exe. файл).

Это действие выполняют сложные программы, компиляторы. Они проверяют корректность синтаксиса вашего кода, прежде чем компилировать и оптимизировать получившийся машинный код путем минимизации его размера и повышения производительности, когда это применимо.
Двоичный код
Как мы уже говорили, результирующий выходной файл содержит двоичный код, понятный для CPU. По сути, это последовательность инструкций различной длины, которые должны выполняться по порядку — вот так выглядят некоторые из них:

Преимущественно, это арифметические инструкции. Они манипулируют регистрами/флагами CPU, а также энергозависимой памятью по мере выполнения.
Регистры процессора
Регистр CPU чем-то похож на временную целочисленную переменную — они имеются в небольшом фиксированном количестве. В отличие от переменных на основе памяти, к ним можно быстро получить доступ. Регистры помогают CPU отслеживать данные (результаты, операнды, счетчики и т. д.) во время исполнения.
Важно отметить наличие специального регистра, называемого FLAGS (EFLAGS в 32-битном формате), в котором находится набор флагов (логических индикаторов), содержащих информацию о состоянии процессора, включая сведения о последней арифметической операции (ноль: ZF; переполнение: OF; четность: PF; знак: SF и т. д.).

Некоторые из этих регистров представлены во фрагменте, приведенном выше, а именно: EAX, ESP (указатель стека), EBP (базовый указатель).
Доступ к памяти
Когда CPU что-то выполняет, ему необходимо обращаться к памяти и взаимодействовать с ней. Вот тут-то и вступают в игру стек и куча.
Стек
Более простая и быстрая из двух сущностей — это линейная непрерывная структура данных LIFO (последний вошел = первый вышел) с механизмом push/pop. Служит для хранения локальных переменных, аргументов функций и отслеживания вызовов (слышали когда-либо о трассировке стека?)
Куча
Куча довольно не упорядочена и предназначена для более сложных структур данных. Обычно используется для динамического выделения памяти, когда размер буфера изначально неизвестен, и/или если он слишком большой, и/или объем должен быть изменен в будущем.
Инструкции ассемблера
Как я упоминал ранее, ассемблерные инструкции имеют разный «размер в байтах» и различное количество операндов.
Операндами могут быть либо непосредственные значения (значение указывается прямо в команде), либо регистры, в зависимости от инструкции:
55 push ebp ; size: 1 byte, argument: register
6A 01 push 1 ; size: 2 bytes, argument: immediateДавайте быстро пробежимся по очень небольшому набору некоторых из наиболее употребляемых команд — не стесняйтесь самостоятельно изучать для получения более подробной информации:
Стековые операции
push
value; помещает значение в стек (ESPуменьшается на 4, размер одной «единицы» стека).pop
register; помещает значение в регистр (ESPувеличивается на 4).
Передача данных
mov
destination,source; копирует значение из/в регистр.mov
destination, [expression]; копирует значение из памяти по адресу, получаемому из ‘регистрового выражения’ (одиночный регистр или арифметическое выражение, содержащее один или больше регистров) в регистр.
Поток выполнения
jmp
destination; переходит к команде по адресу (устанавливаетEIP(указатель инструкций)).jz/je
destination; переходит к команде по адресу, если установленZF(нулевой флаг).jnz/jne
destination; переходит к команде по адресу, еслиZFне установлен.
Операции
сmp
operand1,operand2; сравнивает 2 операнда и устанавливаетZF, если они равны.add
operand1,operand2; операнд1 += операнд2.sub
operand1,operand2; операнд1 -= операнд2.
Переходы функций
call
function; вызывает функцию (помещает текущее значениеEIPв стек, затем переходит в функцию).retn; возврат в вызываемую функцию (извлекает из стека предыдущее значение
EIP).
Примечание: вы могли заметить, что слова «равно» и «ноль» взаимозаменяемы в терминологии x86 — это из-за того, что инструкции сравнения внутренне выполняют вычитание, которое означает, что, если два операнда равны, то устанавливает ZF.
Шаблоны в ассемблере
Теперь, когда у нас есть приблизительное представление об основных элементах, используемых во время выполнения программы, давайте познакомимся с шаблонами инструкций, с которыми можно столкнуться при реверс-инжиниринге обычного 32-битного двоичного файла PE.
Пролог функции
Пролог функции — это некоторый код, внедренный в начало большинства функций и служащий для установки нового стекового кадра указанной функции.
Обычно он выглядит так (X — число):
55 push ebp ; preserve caller function's base pointer in stack
8B EC mov ebp, esp ; caller function's stack pointer becomes base pointer (new stack frame)
83 EC XX sub esp, X ; adjust the stack pointer by X bytes to reserve space for local variablesЭпилог функции
Эпилог — это просто противоположность пролога. Он отменяет его шаги для восстановления стека вызывающей функции, прежде чем вернуться к ней:
8B E5 mov esp, ebp ; restore caller function's stack pointer (current base pointer)
5D pop ebp ; restore base pointer from the stack
C3 retn ; return to caller functionТеперь может возникнуть вопрос — как функции взаимодействуют друг с другом? Как именно вы отправляете/обращаетесь к аргументам при вызове функций, и как вы получаете возвращаемое значение? Именно для этого существуют соглашения о вызовах.
Соглашения о вызовах: __cdecl
Соглашение о вызове — это протокол для взаимодействия функций, есть разные варианты, но все они используют общий принцип.
Мы рассмотрим соглашение __cdecl (от C declaration), которое является стандартным при компиляции кода С.
В __cdecl (32-bit) аргументы функции передаются в стек (помещаются в обратном порядке), а возвращаемое значение передается через EAX регистр (при условии, что это не число с плавающей точкой).
Это означает, что при вызове func(1, 2, 3) будет сгенерировано следующее:
6A 03 push 3
6A 02 push 2
6A 01 push 1
E8 XX XX XX XX call funcСобираем все вместе
Предположим, что func() просто складывает аргументы и возвращает результат. Вероятно, это будет выглядеть так:
int __cdecl func(int, int, int):
prologue:
55 push ebp ; save base pointer
8B EC mov ebp, esp ; new stack frame
body:
8B 45 08 mov eax, [ebp+8] ; load first argument to EAX (return value)
03 45 0C add eax, [ebp+0Ch] ; add 2nd argument
03 45 10 add eax, [ebp+10h] ; add 3rd argument
epilogue:
5D pop ebp ; restore base pointer
C3 retn ; return to callerТеперь, если вы внимательно за всем следили и все еще в замешательстве, можете задать себе один из двух вопросов:
-
Почему мы должны сместить
EBPна 8, чтобы получить первый аргумент?Если вы проверите определение инструкции
call, упоминаемой ранее, то поймете, что внутренне она помещает значениеEIPв стек. И если вы проверите определение командыpush, то обнаружите, что она уменьшает значениеESP(которое скопировано вEBPв прологе) на 4 байта. К тому же, первая инструкция пролога — это такжеpush, поэтому получаем 2 декремента по 4, следовательно, необходимо добавить 8. -
Что случилось с прологом и эпилогом, почему они кажутся «усеченными»?
Это просто потому, что мы не использовали стек во время выполнения нашей функции — если вы заметили,
ESPвообще не изменялся, а это значит, что нам не нужно его восстанавливать.
Условный оператор
Чтобы продемонстрировать ассемблерные инструкции управления потоком выполнения, я бы хотел добавить еще один пример, иллюстрирующий, во что скомпилируется оператор if в ассемблере.
Предположим, у нас есть следующая функция:
void print_equal(int a, int b) {
if (a == b) {
printf("equal");
}
else {
printf("nah");
}
}После ее компиляции вот дизассемблированный вид, который я получил с помощью IDA:
void __cdecl print_equal(int, int):
10000000 55 push ebp
10000001 8B EC mov ebp, esp
10000003 8B 45 08 mov eax, [ebp+8] ; load 1st argument
10000006 3B 45 0C cmp eax, [ebp+0Ch] ; compare it with 2nd
┌┅ 10000009 75 0F jnz short loc_1000001A ; jump if not equal
┊ 1000000B 68 94 67 00 10 push offset aEqual ; "equal"
┊ 10000010 E8 DB F8 FF FF call _printf
┊ 10000015 83 C4 04 add esp, 4
┌─┊─ 10000018 EB 0D jmp short loc_10000027
│ ┊
│ └ loc_1000001A:
│ 1000001A 68 9C 67 00 10 push offset aNah ; "nah"
│ 1000001F E8 CC F8 FF FF call _printf
│ 10000024 83 C4 04 add esp, 4
│
└── loc_10000027:
10000027 5D pop ebp
10000028 C3 retnДайте себе минутку и попытайтесь разобраться в этом дизассемблированном коде (для простоты, я изменил реальные адреса и сделал начало функции с 10000000).
В случае, если вам интересно, зачем нужна команда add esp, 4, то это просто приведение ESP к исходному значению (такой же эффект, что и у pop, только без изменения какого-либо регистра), поскольку у нас есть push строкового аргумента для printf.
Базовые структуры данных
Давайте двигаться дальше. Поговорим о том, как хранятся данные (особенно целые числа и строки).
Endianness
Endianness — это порядок байтов, представляющих значение в памяти компьютера.
Есть 2 типа: big-endian и little-endian

Для справки, процессоры семейства x86 (которые есть практически на любом компьютере) всегда используют little-endian.
Чтобы привести живой пример этой концепции, я скомпилировал консольное приложение на С++ в Visual Studio, в котором объявил переменную int со значением 1337, а затем вывел адрес переменной, используя функцию printf().
После я запустил программу с отладчиком, чтобы проверить напечатанный адрес переменной в шестнадцатеричном представлении памяти, и вот результат, который я получил:
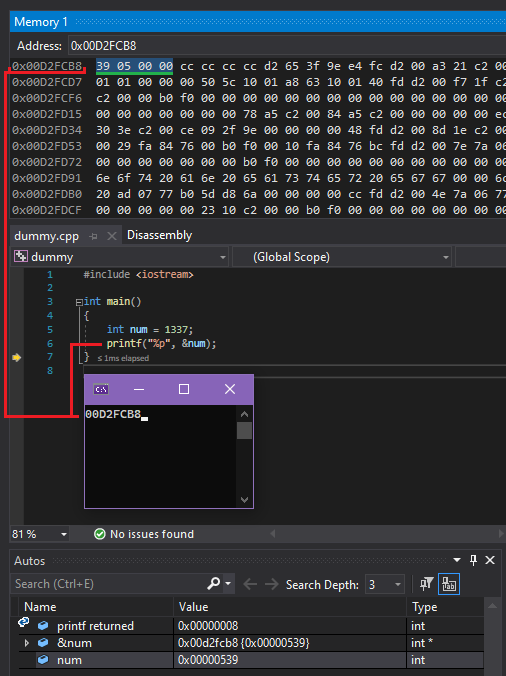
Уточним этот момент — переменная int имеет длину 4 байта (32 бита) (на случай, если вы не знали), поэтому это означает, что если переменная начинается с адреса D2FCB8, то она заканчивается прямо перед D2FCBC (+4).
Чтобы перейти от значения, удобочитаемого человеком, к байтам памяти, выполните следующие действия:
Десятичное: 1337 -> шестнадцатеричное: 539 -> 00 00 05 39 -> little-endian: 39 05 00 00
Знаковые целые числа
Это часть интересна, но относительно проста. Здесь вы должны знать, что представление знака у целых чисел (положительных/отрицательных) обычно выполняется на компьютерах с помощью концепции, называемой дополнением до двух.
Суть в том, что наименьшая/первая половина целых чисел зарезервирована для положительных чисел, а наибольшая/вторая половина предназначена для отрицательных, вот как это выглядит в шестнадцатеричном формате для 32-битного знакового int (выделено = шестнадцатеричный формат, в скобках = десятичный):
Положительные (1/2): 00000000 (0) -> 7FFFFFFF (2 147 483 647 или INT_MAX)
Отрицательные (2/2): 80000000 (-2 137 483 648 или INT_MIN) -> FFFFFFFF (-1)
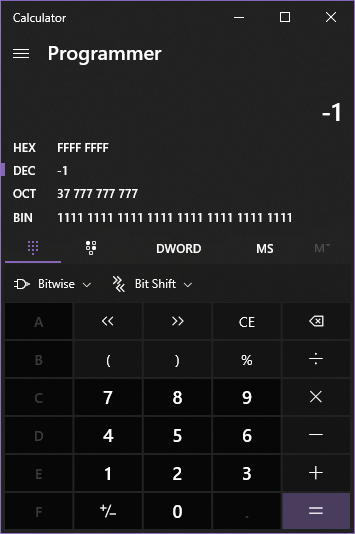
Если вы заметили, значения у нас всегда возрастают. Независимо от того, поднимемся ли мы в шестнадцатеричном или десятичном формате. И это ключевой момент этой концепции — арифметические операции не должны делать ничего особенного для обработки знака, они могут просто работать со всеми значениями как с беззнаковыми/положительными, и результат все равно будет интерпретироваться правильно (если мы будем в пределах INT_MAX и INT_MIN). Так происходит потому, что целые числа будут ‘переворачиваться’ при переполнении по принципу, схожему с аналоговым одометром.

Совет: калькулятор Windows — очень полезный инструмент. Вы можете войти в режим программиста и установить размер в DWORD (4 байта), затем ввести отрицательные десятичные значения и визуализировать их в шестнадцатеричном и двоичном формате, получая удовольствие от выполнения операций с ними.
Строки
В C строки хранятся в виде массивов char, поэтому здесь нет ничего особенного, кроме того, что называется null termination.
Если вы когда-нибудь задумывались, как strlen() узнает размер строки, то все очень просто — строки имеют символ, обозначающий их конец, и это нулевой байт/символ — 00 или ‘\0’.
Если вы объявите строковую константу в C и наведете на нее курсор, например, в Visual Studio, то покажется размер сгенерированного массива, и, как можете видеть, в нем на один элемент больше, чем в видимом размере строки.
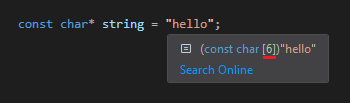
Примечание: концепция порядка байтов не применима к массивам, только к одиночным переменным. Следовательно, порядок символов в памяти здесь будет нормальным.
Смысл call и jmp инструкций
Теперь, когда вы знаете все это, то, вероятно, уже можете начать разбираться в каком-то машинном коде и в некоторой степени, так сказать, имитировать центральный процессор своим мозгом.
Возьмем пример с print_equal(), но на этот раз сосредоточимся только на инструкциях call printf().
void print_equal(int, int):
...
10000010 E8 DB F8 FF FF call _printf
...
1000001F E8 CC F8 FF FF call _printfВы можете спросить себя — подождите секунду, если это одни и те же инструкции, то почему их байты разные?
Это потому, что инструкции call (и jmp) (обычно) принимают в качестве операнда смещение (относительный адрес), а не абсолютный адрес.
Смещение — это в основном разница между текущим местоположением в памяти и пунктом назначения. Это также означает, что оно может быть как отрицательным, так и положительным.
Как вы можете видеть, опкод инструкции call, содержащей 32-битное смещение, — это E8. После него следует само смещение — полная инструкция имеет вид: E8 XX XX XX XX.
Вытащите свой калькулятор (почему вы закрыли его так рано?!) и вычислите разницу между смещением обеих инструкций (не забывайте о порядке байтов).
Вы заметите, что это разница такая же, как разница между адресами инструкций (10000001F — 10000010 = F):

Еще одна небольшая деталь, о которой нужно упомянуть — процессор выполняет инструкцию только после ее полного «чтения». Это означает, что к тому времени, когда CPU начинает «выполнение», EIP (указатель инструкций) уже указывает на следующую команду.
Смещения учитывают такое поведение, а это означает, что для получения реального адреса целевой функции мы также должны добавить размер инструкции call: 5.
Теперь применим все это, чтобы узнать адрес printf() из первой инструкции в примере:
10000010 E8 DB F8 FF FF call _printfИзвлеките смещение из инструкции
E8 (DB F8 FF FF)->FFFFF8D8(-1829)Сложите его с адресом инструкции:
100000010+FFFFF8D8=0FFFF8EBИ наконец, прибавьте размер инструкции:
0FFFF8EB+5=OFFFF8F0(&printf)
Точно такой же принцип применяется к инструкции jmp:
...
┌─── 10000018 EB 0D jmp short loc_10000027
...
└── loc_10000027:
10000027 5D pop ebp
...Единственное отличие в этом примере состоит в том, что EB XX — это короткая версия jmp. Это означает, что в ней используется только 8-битное (1 байт) смещение.
Следовательно: 10000018 + 0D + 2 = 10000027
Вывод
Вот и все! Теперь у вас должно быть достаточно информации (и, надеюсь, мотивации), чтобы начать свое путешествие в реверс-инжиниринге исполняемых файлов.
Начните с написания игрушечного кода на С, его компиляции и пошаговой отладки (Visual Studio, кстати, позволяет это сделать).
Compiler Explorer также является чрезвычайно полезным веб-сайтом, который компилирует код C в ассемблер в реальном времени с использованием нескольких компиляторов (выберите компилятор x86 msvc для 32-разрядной версии Windows).
После этого вы можете попытать счастья с собственным двоичными файлами с закрытым исходным кодом с помощью дизассемблеров, таких как Ghidra и IDA, и отладчиков, таких как x64dbg.
Дата-центр ITSOFT — размещение и аренда серверов и стоек в двух дата-центрах в Москве. UPTIME 100%. Размещение GPU-ферм и ASIC-майнеров, аренда GPU-серверов, лицензии связи, SSL-сертификаты, администрирование серверов и поддержка сайтов.
Комментарии (10)


oleshii
13.11.2021 15:23Прежде, чем давать читателю что-то о дизассемблировании, он (читатель) должен понимать, что есть asm, и как с ним работать, какова структура CPU на логическом уровне, смысл инструкций, и т.д. Без этого как ни дизассемблируй - всё равно ничего не поймёшь. Знаю по себе. В начале 90-х начинал с Borland Tasm, и работал с ним профессионально больше 4 лет. И потом тоже не забыл. Когда потребовалось выяснить, почему перестал работать драйвер под OS X, дизассемблирвал xnu и две недели не вылезал из этого дампа. Выяснилось, что apple developers перенесли одну табличку из секции .data в const data

perfect_genius
17.11.2021 23:47Прежде, чем давать читателю что-то о дизассемблировании, он (читатель) должен понимать,
зачем нужна очередная статья и чем она лучше других таких же на Хабре.

Godless
18.11.2021 16:53Почти слезу пустил. =)
По сути. Забыли упомянуть про УК РФ и тп при реверсе приложений.и оффтоп: а проект OllyDbg еще жив ?

Emelian
Интересно, а может быть есть смысл перепечатать статьи о дизассемблировании бинарного кода из erfaren.narod.ru на Хабр? Особенно, если учесть, что ассемблерный код можно представить в виде Си-кода, с помощью соответствующего плагина IdaPro.
raven19
Ну дали Вы ссылку, отлично! Зачем дублировать-то? Тем более, что те статьи хоть и «серьёзны» по содержанию, по своему подходу и реализации, в настоящее время они не более, чем «забавны». Использование, например, Visual FoxPro в процессе решения задачи декомпиляции может (мне кажется) даже ввести в глубокий транс начинающих!.. Хотя, не буду ни в коем разе принижать уровень решений, описанных в тех статьях.
Но так сейчас уже точно не стоит делать, да и тогда-то этот подход был весьма и весьма спорным. Но это отдельный и достаточно длинный разговор (если что).
И ещё: Ильфак никогда не говорил, что результатом плагина (Hex-Rays Decompiler plugin) является «Си-код» (по Вашему выражению выше). Результатом работы плагина является псевдокод. И это отнюдь не одно и то же. Не советую питать иллюзии по поводу результатов плагина, хотя для «Hello, World» будет «вполне» Сишный результат!
Emelian
Если причесать псевдокод, то получим код, как я это делал на упомянутом сайте, для дизассемблерного листинга, переводя его в ассемблер (см. мою последнюю статью там).
Ну, а что именно говорил Ильфак Гильфанов, в 2003 году, в интервью: fcenter.ru/online/hardarticles/interview/6704-IDA_Pro_samyj_moschnyj_dizassembler_v_mire:
так это можно понимать по-разному.
Я встречал в Интернете упоминания, что полученный, с помощью плагина HexRays «псевдокод» Си, вполне успешно переводился в реальный Си-код. Вы думаете, это сложнее, чем дизассемблерный листинг превратить в ассемблерный код?
raven19
Вы уверены, что с 2003 года, когда декомпилятора у Ильфака не было, и он только «мечтал» об этом, что с тех пор ничего не поменялось?!
Это известный факт, более того, могу подтвердить, что среди таких проектов были достаточно серьёзные. Но подобная процедура — это далеко не тривиальная задача, а людей, способных на подобные подвиги, можно на пальцах пересчитывать. И речь идёт об серьёзных проектах, а не тех, где Си-шные исходники всего-то на сотню другую строк.Эти вещи он утверждал ещё до «нашей эры». В принципе, он вроде и тогда уже был знаком с трудами Кристины Г., но тогда он ещё мог говорить что угодно, ведь декомпилятора-то у него ещё не было. А при реальной разработке реального декомпилятора… Как говорят у нас на Руси: «Весна покажет, кто где с...», ну или на вполне литературном: «Не говори „гоп“, пока не перепрыгнул»… Могло и его мировоззрение поменяться!
Так что ссылки на 2003 год — извините, это уже абсолютно не актуально. Много воды с тех пор утекло и многое поменялось!..
А всё потому, что выхлопом Hex-Rays Decompiler plugin является Си подобный псевдокод, а не Си-шный код. А получить нормальный Си-шный код из псевдокода очень часто отнюдь не тривиальная задача (специально повторился)!!!
И да, это должно быть значительно проще, чем получать ассемблерный код (компилируемый) из выхлопа Иды.
Честно говоря, мне не хотелось бы поднимать эту тему и тем более давать оценку самой процедуре получения ассемблерного кода после Иды для процедуры его компиляции ассемблером. Это абсолютно «несерьёзное» занятие для серьёзных проектов!..
Хотя никто не запрещает заниматься подобными вещами ради интереса или ещё зачем либо, но всерьёз воспринимать откомпилированный результат и тем более его использовать в реальной жизни… Я даже обсуждать это не буду...!!!