
Эпопея с автодокументацией началась у нас неспроста: 300 разработчиков, 500 репозиториев и 400 сервисов — все живет на 600 хостах и использует 600 баз данных. Изменения происходят настолько часто, что ручной поиск данных в наших масштабах — та еще морока. При этом раньше никакого общего хранилища с актуальной информацией о владельцах проектов, о конфигурациях хостов и связанных с проектами сервисах не было. Расскажу, как мы вконец устали от квестов, перешли на сторону автодоки и почему выбрали в помощь Insight.

Меня зовут Юля, я руковожу командой SRE. Помимо стабильности сервисов, моя команда занимается поддержкой инструмента, который нам позволяет за этими сервисами следить. Это отдельное приложение, генерирующее документацию по всей нашей инфраструктуре.
В 2018 году, когда я только пришла в компанию в роли девопса, мне дали для погружения в процессы простую задачу: допилить скрипт локального разворачивания проектов, чтобы он корректно работал под macOS. То есть скрипт уже был, он успешно работал для Linux-окружения. Его нужно было просто адаптировать, подправить пару регулярок, настроить сеть, дописать инструкцию — совсем не сложно. Я довольно быстро сделала правку в самом инструменте, и казалось, что нет никаких проблем. Но дальше 15-минутная на первый взгляд задача растянулась на 3 месяца.
После того, как я внесла правки в скрипт раскатки, нужно было добавить мелкие изменения во все проекты, которые он поддерживал: поменять директорию монтирования, поправить сеть. Однотипные простые правки, примерно пять строк. Но в каждом проекте. Я их сделала, сформировала пулл-реквесты и застряла. Потому что изменения надо было с кем-то согласовать. Нельзя же совать людям в мастер коммиты без предупреждения. Особенно если работаешь в компании первую неделю. Так что возник вопрос: где и как искать владельца сервиса?
Найти владельцев проектов: старт квеста
Первое, что пришло в голову — README-файлы. Я уже видела к тому моменту, что ими принято пользоваться в Skyeng, поэтому там и попыталась найти нужную инфу. И в большинстве случаев это получилось, но еще выяснилось, что у значительной части проектов README-файлов просто нет, а у некоторых не заполнен владелец или он уже изменился, а файл не актуализировали.
Дальше я пошла за советом к коллегам, ведь девопсы настраивают всем деплои, следят за тестингами и наверняка в курсе всего. С какими-то проектами они мне помогли, но со многими были в таком же тупике, что и я.
После этого начались извращённые методы: я заглянула в GitHub actions. В некоторых местах можно было найти каналы для алертинга, где-то были указаны имена. Несколько человек нашла таким способом.
Потом решила спросить последнего и основного контрибьютора репозиториев — тоже не сильно помогло. Порой эти люди уже и не работали в компании.
Совсем отчаявшись, я пришла к QA, ведь они тестят все фичи и должны знать главных по проектам. Они скинули мне статью в Confluence, где были собраны все интересующие меня проекты с владельцами. Его составляли для тестирования примерно такой же задачи, как моя, буквально за пару месяцев до этого. Сначала я очень обрадовалась, что решение проблемы найдено. Но вскоре оказалось — процентов на 30 эта статья уже не актуальна. Компания быстро растет и многое изменилось за эти два месяца.
В общем, я сделала все, что могла. Познакомилась чуть ли не со всей компанией, но глобально вопрос так и не решила. Мерж и раскатка этих коротких правок заняли три месяца только потому, что не удавалось в адекватное время найти ответственных.
Уже тогда стало понятно — процесс надо менять
В принципе, проблема с поиском владельцев решилась бы, будь у нас четкий регламент по README-файлам.
Но есть ещё пул вопросов, которые возникали у других участников нашей команды:
Как найти сервис по серверу. Например, мы собираемся выкатить обновление на сервер, которое приведет к даунтайму. Надо предупредить владельцев о работах, согласовать тестирование после работ или выяснить безопасное время для обновления.
Как найти зависимые сервисы. Проводим работы на каком-то сервисе и хотим знать, что потенциально может пострадать от наших действий, чтобы предупредить или проверить работоспособность.
Как найти сервисы с доступом к базе. Решили перевезти базу на другой хост, но как узнать, какие сервисы к ней обращаются, чтобы поправить в них url для обращения или логины / пароли.
Как найти сервис по IP, если в логах видно, что сервис неправильно себя ведет.
Как отследить прогресс по большим задачам. У нас недавно был большой проект по «докеризации» всех сервисов. Как понять, насколько продвинулись по задаче, сколько времени еще нужно на проект? Или нужно раскатить новую фичу на все проекты. Как проверить, кто уже раскатил, а кому нужно напомнить о задаче?
Почти все вопросы упираются в первый и ключевой: как найти владельца?
Составленные вручную документы устаревают раньше, чем их успевают прочитать? Нужна автодокументация
Автодокументация — это скрипт плюс источники данных, из которых скрипт сможет сгенерить документацию. И источники данных первичны. Информаци о релизах не получится, если деплой делается путем git pull на хосте. Не будет документации по пользователям и их учеткам в разных системах, если эти учетки заводятся стихийно вручную и нигде не учитываются. Поэтому прежде, чем садиться писать код, нужно найти эти самые источники данных.
Для Skyeng основными источниками данных стали:
README-файлы, где мы договорились делать краткое описание проектов и указывать их владельцев.
Репозиторий Ansible, где указаны все конфигурации серверов.
-
Репозиторий с пайплайнами, где про каждый проект записано: какой репозиторий, куда выкатывается, по каким правилам, какие переменные мы ему передаем.
Из этой информации мы сформировали автодокументацию по первым трем сущностям:
сервисы
хосты
базы данных
Далее мы расширили и список источников данных, и список сущностей в автодокументации. Например, стали парсить факты Ansible, дашборды в Grafana, ресурсы в Qrator, информацию по доменам и еще много всего. Но в этой статье я хочу рассказать о самом начале нашего пути, так что обо всем по порядку.
Дальше иногда я буду называть автодокументацию техкартой — внутри мы зовем ее именно так.
Сначала наводим порядок в README-файлах
Самое главное, что мы сделали — ввели регламент по заполнению README-файлов на всю компанию. Это был большой проект с поддержкой CTO и с огромной помощью административных ассистентов. Каждая команда получила задачи на заведение в своих проектах README-файлов с определенной структурой: название сервиса, краткое описание и ответственные.

Изначально это был ручной процесс. Мы провели несколько итераций, приходили с задачами дозаполнить README, для контроля формировали списки проектов, которые никто себе так и не забрал. И даже несколько заархивировали, обнаружив, что они уже по факту мертвы.
Важно сказать, что делать скрипты для формирования автодокументации, которые работали бы с этим форматом файлов, мы начали немного раньше общей деятельности по заполнению README. Это позволило командам сразу видеть ценность от того, что они выполняют эти задачи: их проекты появлялись в техкарте, у них было корректное описание. Мы прямо по техкарте проверяли статус выполнения задач по заполнению README.
По мере развития автодокументации мы стали генерировать обязательные блоки скриптом. Еще сделали скрипты, которые автоматически обновляют содержимое README при смене владельцев сервисов, и скрипты, которые сообщают, что данные потеряли актуальность. Под именем сотрудника в README теперь лежит ссылка на профиль человека в Slack и ему можно сразу написать в личку.
Чем больше людей узнавали о том, что у нас есть техкарта, тем чаще коллеги сами напоминали ответственным обновить README. Так что со временем эта система стала самобалансирующейся и уже не требует пристального внимания.
В репозитории Ansible и в репозитории с пайплайнами у нас изначально был порядок, никаких мер отдельно предпринимать не пришлось. Просто договорились, что формат описания не меняем без предупреждения.
Теперь можно писать скрипты для сбора информации
В нашем случае скрипт сбора автодоки состоит из трех ключевых групп классов:
парсеры
обработчики
пушеры
Парсер — основная часть скрипта. Это класс, который знает всего две вещи: где взять инфу и как ее распарсить в самый простой вид типа «поле => значения».
public function getClustersList()
{
$dummyHosts = yaml_parse_file($this->ansibleDir . '/inventories/_clusters.yml');
$hosts = $dummyHosts['all']['children']['clusters']['children'] ?? [];
return array_keys($hosts);
}Например, парсер знает, что в файле inventories/_clusters.yml лежит инфа по кластерам, и в каком она формате. Он достает ее и передает дальше.
Такой парсер есть под каждый источник информации и он занимается только «своим» источником. Некоторые парсеры ходят в API, например, в Grafana или Amazon, какие-то в базу, какие-то — парсят репозитории.
Все, что отдают парсеры, складывается в общую «коробочку» — это по сути массив слабоструктурированной информации, который потом передается дальше.
Затем наступает очередь обработчиков.
Техкарта состоит из сущностей и связей между ними, а сущности состоят из полей. Поле — это любая характеристика сущности. Так, на первом этапе сущностями были хосты, базы, сервисы. У сервисов могут быть поля: название, описание, владелец, репозиторий, тип деплоя и так далее.
Обработчик пишется отдельно для каждого поля техкарты. Это тоже короткий скрипт, который знает только две вещи: какого типа данные он должен отдать и как их собрать из слабо структурированных данных, которые лежат в «коробочке» с прошлого этапа.
Вот так это выглядит:
class UseBalancer implements HandlerInterface
{
public const NAME = 'use_balancer';
public function getFieldType(): int
{
return Field::TYPE_BOOL;
}
public function getFieldName(): string
{
return self::NAME;
}
public function getFieldTitle(): string
{
return 'Использует балансировщик';
}
public function getValue(\App\Autodoc\Entity\Project $project)
{
if (is_null($project->getPipeline())) {
return false;
}
return (bool)$project->getPipeline()->isUseBalancer();
}
}У этого скрипта есть тип (в данном случае это булево поле), название для внутренних нужд и заголовок — для визуализации.
Как видно, скрипт-обработчик очень короткий: достает из слабоструктурированной информации (это $project) поле, в которое сложено то, что мы получили на предыдущем шаге, и приводит к правильному типу. Здесь может быть и некая логика по интерпретации полученных данных, но не получение информации. Далее всё, что вернут обработчики, складывается в другую «коробочку», уже со структурированной информацией. Эта коробочка передается дальше — в скрипты-пушеры.
Они в свою очередь доставят информацию в место назначения.
Где хранить структурированную информацию?
Мы попробовали несколько вариантов — аппетиты росли по мере внедрения фич. Благодаря описанной выше структуре кода мы получили достаточно гибкое решение, которое может без проблем «запушить» автодокументацию в разные места в зависимости от потребностей.
Вариант 1. GitHub
На первом этапе задачи (мы же делали по факту пилот и надо было еще проверить, выстрелит ли идея) нам нужно было что-то простое и с минимальными затратами времени и сил. Мы немного подумали и решили, что GitHub — идеальное место для «быстро и дешево».

Загрузить все в GitHub было легко: в .md файлы выгрузили то, что у нас есть, в виде таблицы. Настроили крон, который делал это раз в час, чтобы инфа всегда была актуальной. Так появилась табличка по серверам: теперь искать сервер по IP стало просто.
Точно так же выгрузили информацию по сервисам: какие базы используют, кто владелец, куда писать по проблемам. Между хостами и сервисами настроены ссылки.
Это был настоящий прорыв после полного хаоса, это было (не побоюсь этого слова) счастьем. Многие рутинные процессы по поиску и сопоставлению информации сразу же упростились в разы.
У подхода с репозиторием есть очевидные минусы: таблицу нельзя фильтровать, из-за ограничений гитхаба таблицы достаточно узкие и мы получаем либо мало инфы, либо огромный скролл, поиск на странице возможен только по Ctrl+F.
Проблемы обострились, когда мы решили добавить больше полей: люди начали пользоваться автодокументацией и постоянно приходили запросы на добавление новых полей. Какие-то команды заинтересованы в одних данных, какие-то — в других. В конце концов у нас получилась очень длинная таблица с горизонтальной прокруткой, причем закрепить первый столбец нельзя и ты никогда не можешь быть уверен — ту ли строку ты сейчас читаешь, которую собирался?
Плюсы и минусы GitHub
Плюсы |
Минусы |
|
Быстро и дешево Строится само Актуальнее ручной автодокументации Внутренние ссылки Табличное отображение У всех есть доступ |
Узкие таблицы Нет фильтров Поиск только по Ctrl+F |
Мы начали думать, как сделать лучше.
На первое время мы добавили возможность выгрузки этой информации в CSV и пользователи стали экспортировать этот документ в Google Таблицы для дальнейшего анализа. Так мы и пришли к нашему следующему варианту для расположения документации
Вариант 2. Google Таблицы
Посмотрев, что делают наши пользователи, мы решили: раз данные из автодокументации для анализа выгружаются в Google Таблицы, то мы можем это делать автоматически и регулярно.
У Google Spreadsheets довольно простое API: отправляешь информацию в виде двумерного массива и она превращается в красивенькую таблицу.
В таблицах есть очевидные плюсы по сравнению с репозиторием: можно закрепить нужное поле, добавить сколько угодно полей, можно фильтровать данные. А главное, по такой таблице можно собрать статистику и построить графики.
Мы, например, на лету считали проценты докеризации и проценты раскатки больших межкомандных задач по данным техкарты на отдельных вкладках, которые не перетирались при обновлении и всегда показывали нужную статистику.
В общем было удобно, но вскоре полей снова стало слишком много, потому что разным людям нужны разные поля для работы. И даже несмотря на возможность закрепить первую колонку, в какой-то момент скроллить начинаешь слишком много и теряешь фокус.
Еще мы столкнулись с тем, что кто-то постоянно настраивает себе глобальные фильтры для анализа или скрывает мешающие колонки, переставляет колонки местами. В итоге у остальных пропадает нужная информация.
Плюсы и минусы Таблиц
Плюсы |
Минусы |
|
Быстро, дешево Строится само Актуальнее ручной документации Внутренние ссылки Табличное отображение У всех есть доступ Можно закреплять строки и столбцы Фильтры Поиск с регулярками Удобно собирать статистику |
Неудобный поиск Сущность = строка Фильтры действуют на всех пользователей |
В этот момент мы уже понимали, что идея взлетела и ее надо развивать. Мы стали искать, какие есть более технологичные варианты, ведь теперь надо было не «быстро» или «дешево» и уж тем более не «хоть как-нибудь». Теперь нам надо было «удобно».
Вариант 3. Jira Insight
Стали смотреть в сторону инструментов именно для документации по инфраструктуре. Эти системы называются CMDB — Configuration management database. Оказалось, что в Jira есть плагин, который реализует такой подход. Поскольку мы и так пользуемся продуктами Atlassian и в частности JIRA — решили пробовать.
Этот вариант дорогой, реализовывать его значительно сложнее, чем выгрузку в таблицу или репозиторий, но он значительно гибче.
Выглядит так:

Сущностей у нас уже очень много: мы выгрузили и провайдеров, и датацентры, и команды, и домены.
Insight поддерживает фильтрацию с ипользованием iql (insight query language), очень удобную:

Кроме того, Insight позволяет выбрать колонки, которые нужно отображать. И этот выбор никак не влияет на остальных людей.

Как это работает
Каждая сущность Insight обладает набором параметров, поля типизированы.

Как видно, у каждого поля есть Id, обновление данных в полях производится именно по Id. К полям можно добавить комментарии, чтобы пользователям было понятнее, что там записано. Типы полей есть разные — как простые (строки, числа, bool), так и сложные. Например, связи между объектами. Так в поле «Code owner» можно добавить только сущности типа «It specialist». Причем связь позволяет фильтровать допустимые значения. К примеру, только пользователи с активной учетной записью могут быть привязаны к сервисам. Можно выбирать максимальное и минимальное число объектов в связях. Настройка довольно тонкая.
Но с большей гибкостью приходят и сложности при сохранении. В GitHub мы выгружали информацию в виде строк через pipe и это генерило таблицу, не нужно было ничего приводить к определенному типу. Только ссылки требовали минимального оформления. Почти тоже самое было с таблицами — в Google Spreadsheet Api просто грузишь массив строк. С Insight нужно следить за типом значений.
Если указана ссылка, то в это поле нужно всегда отправлять ссылку. Если накосячить с типами данных, объект просто не сохранится. Нам пришлось пилить целый набор классов, в которых мы записываем соответствие Id полей в Insight, их названий и типов, чтобы передать данные в правильном формате. Причем из-за того, что тестовая Jira может «разъехаться» с основной, для стейджей мы еще и держим второй комплект этих соответствий.
class S3BucketType extends AbstractType
{
private const TYPE_ID_DEV = 81;
private const TYPE_ID_PROD = 82;
public const KEY = 'KEY';
public const NAME = 'NAME';
public const LOCATION = 'LOCATION';
public const CREATION_DATE = 'CREATION_DATE';
public const CREATED = 'CREATED';
public const UPDATED = 'UPDATED';
protected function getMappingDev(): array
{
return [
self::KEY => 935,
self::NAME => 936,
self::CREATED => 937,
self::UPDATED => 938,
self::LOCATION => 944,
self::CREATION_DATE => 943,
];
}
protected function getMappingProd(): array
{
return [
self::KEY => 945,
self::NAME => 946,
self::CREATED => 947,
self::UPDATED => 948,
self::LOCATION => 949,
self::CREATION_DATE => 950,
];
}
protected function getTypeIdDev(): int
{
return self::TYPE_ID_DEV;
}
protected function getTypeIdProd(): int
{
return self::TYPE_ID_PROD;
}
}Помимо типа для каждой сущности написан еще и сервис, который сопоставляет данные. Примерно так:
public function execute()
{
$insightBuckets = $this->jiraInsight->getAllByType(S3BucketType::class);
$bucketIds = $this->entityType->getAttributeMapping();
$buckets = $this->bucketService->getAll();
foreach ($buckets as $bucket) {
$id = $insightBuckets[$bucket->getName()]['objectKey'] ?? null;
$this->update($id, [
$bucketIds[S3BucketType::NAME] => $bucket->getName(),
$bucketIds[S3BucketType::LOCATION] => $bucket->getLocation(),
$bucketIds[S3BucketType::CREATION_DATE] => $bucket->getCreatedAt()->format('c'),
]);
}
}Естественно, чем больше полей, тем этот код длиннее. Здесь приведен самый короткий пример.
Второй нюанс, который требует проработки: удаление и обновление данных.
Если информацию в таблице можно перезаписывать при каждой синхронизации, то в случае с Insight сущности остаются. Нам нужно обновленную информацию загрузить в старые сущности, а не наплодить новых. Поэтому необходимо сопоставить старые сущности с новыми и деактивировать то, чего уже нет. А то, что есть — обновить. Как видно из предыдущего куска кода, нам приходится сначала выгрузить все сущности нужного типа, потом поискать, есть ли там уже та, которую мы собираемся записать, и только потом обновить информацию.
При этом удобства Jira Insight сильно перевешивают минусы, поэтому вся наша автодокументация переехала сюда.
Например, если нужно поделиться с коллегой выборкой, с которой работаешь, — можно пойти в раздел поиска, туда вставить свой запрос, а получившийся в адресной строке url просто скопировать и отправить. Никто никому не мешает.
Есть и предустановленные фильтры, которые мы готовим для всех команд и регулярно пополняем. Например, список «боевых» хостов или сервисов, в которых нужно обновить какую-то библиотеку.

Благодаря возможности создавать связи между сущностями в виде полей, этой техкартой удобно пользоваться: вся деятельность происходит в одном окне. Проект прилинкован к команде, команда к людям. Можно из проекта перейти в карточку команды и из нее в карточку сотрудника этой команды, где сразу найдешь ссылку на Slask и свяжешься с этим человеком.
Причем ссылки эти необязательно делать в обе стороны — в каждой сущности есть отдельный блок для входящих ссылок, а в них всегда можно увидеть связанные сущности.
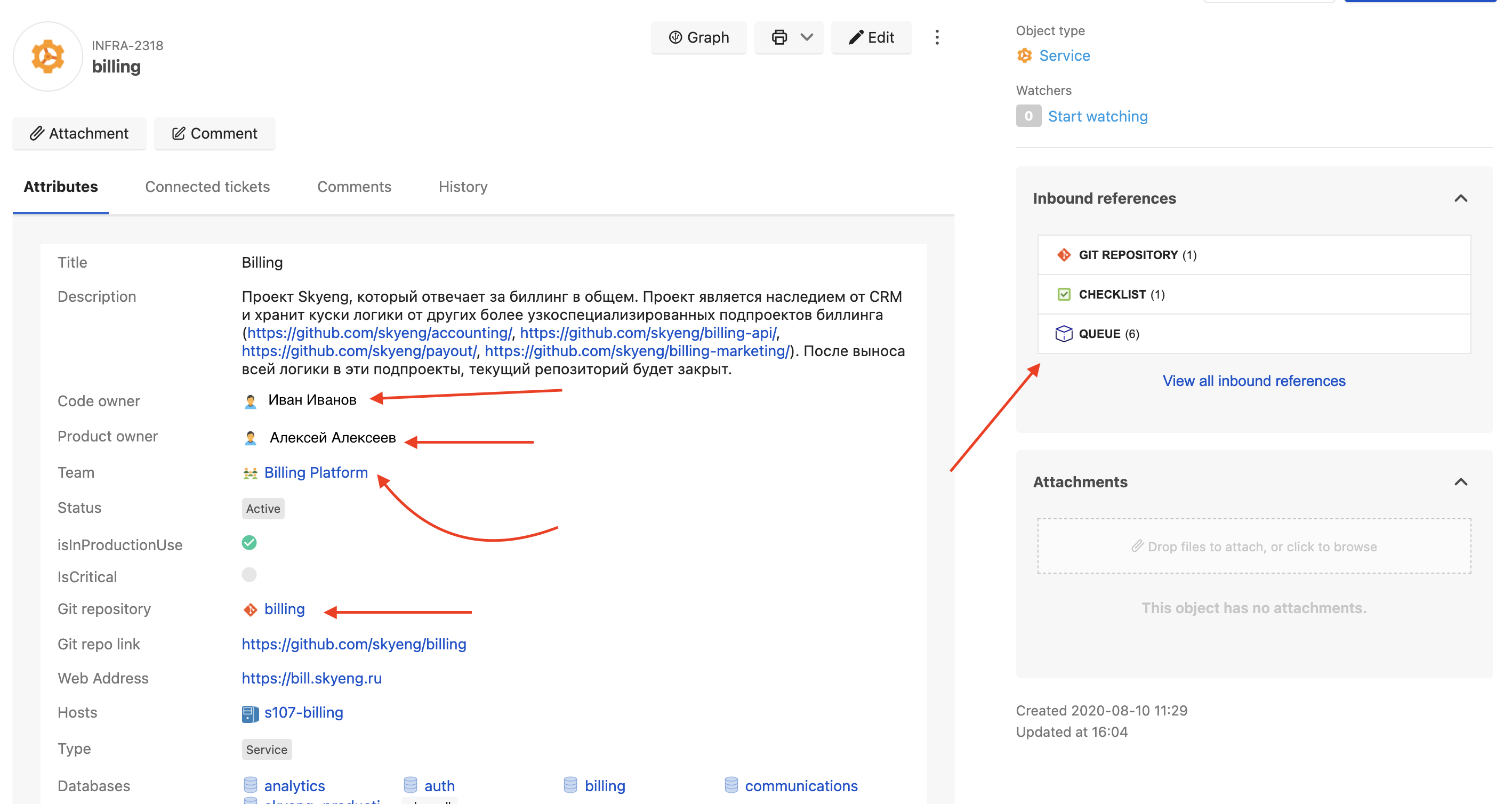
У нас настроена и обратная синхронизация из Insight в README: если у проекта меняется владелец, мы изменяем поле в Insight, после чего автоматически делается MR с этими исправлениями в README и автоматически мержится. Благодаря этому данные всегда синхронны.
Кроме того, Insight можно связывать с тикетами из Jira.
У нас есть проект DSTR — про инциденты в продакшне. И мы связываем задачи из этого проекта с сущностями Insight. Благодаря этому можно ввести статистику: какой проект больше падает, в каком чаще всего возникают проблемы определенного типа.
Есть минус: неудобно собирать сложную статистику, если она нужна в формате «сколько процентов сервисов имеют такие-то свойства у связанных сущностей».
Например, «Сколько процентов хостов расположены в цодах определенного провайдера данных». Для таких случаев мы добавили скрипт, генерирующий view в БД JIRA для всех сущностей из Insight. Поэтому для более-менее сложного анализа приходится либо выгружать данные в Google Таблицу, либо делать SQL-запросы к этим view.
Плюсы (и немного минусов) Jira Insight
Плюсы |
Минусы |
|
Строится само Актуально Внутренние ссылки Табличное отображение У всех есть доступ Поиск с JQL Карточки сущностей Типизация полей Фильтры для себя и с возможностью поделиться Интеграции с ServiceDesk, боты, Jira |
Дорого Неудобно собирать статистику |
В чём еще помогает Jira Insight
Автоматически согласовывать доступы к базам и хостам. Для снижения операционки у нас настроена автоматизация: при получении заявки на выдачу доступа куда-либо скрипт находит нужную сущность в инсайте, достает оттуда владельцев и отправляет им уведомление с запросом разрешения выдать доступ. Владелец просто ставит галку — можно или нет. Далее скрипт автоматически выдает новый доступ или пишет человеку, что разрешения нет.
Строить автоматические дашборды. Каждый новый сервис «из коробки» получает автоматически сгенерированный дашборд в Grafana, на основании всего того, что указано в карточке проекта. А ссылка на этот дашборд, в свою очередь, публикуется в карточке сервиса.

Можно мониторить проект сразу же, как только он был запущен в прод. Ничего не надо отдельно руками настраивать.
Проверять соблюдение стандартов качества. У нас есть внутренний фреймворк стабильности, который описывает характеристики сервисов, необходимые, чтобы гарантировать их надежность. Мы отслеживаем соответствие этим показателям тоже с помощью Insight. У нас отдельный класс скриптов настроен на проверку пунктов этого фреймворка. Нужные поля заполняются автоматически и составляется рейтинг команд по соответствию стандартам.
Что в итоге
Процесс внедрения автодокументации занял у нас примерно полгода. Доработки идут до сих пор и, кажется, никогда не прекратятся — всегда есть еще что-то классное, что хочется добавить. Для себя мы решили, что остаемся с Jira Insight до тех пор, пока будем пользоваться Jira.
P.S.: Инструкцию к техкарте мы выдаем в первые дни адаптации новичков. Так что никто больше не будет вынужден долго и мучительно искать ответственного за сервис :)
slutsker
Молодцы! Единый источник правды с автоматическим сбором данных - крайне полезный инструмент при таком количестве разных сущностей и людей.