
Распространенная в пандемию ситуация: общаетесь с друзьями или коллегами по Zoom, несколько человек начинают говорить одновременно и… разобрать хоть что-то не представляется возможным. Эта проблема натолкнула нас на идею написать свое приложение для аудиозвонков, где громкость регулируется весьма необычным образом. У каждого пользователя есть свой аватар — кружок на плоскости, который управляется перетаскиванием. Чем ближе аватары пользователей на экране, тем громче они друг друга слышат. Работает ли это? В целом да. Рассказываем, что у нас получилось.
Краткое содержание:
О нас
Привет! Мы второкурсники программы «Прикладная математика и информатика» в Питерской Вышке — Фёдор Громов, Никита Денисов и Алексей Поздняков. Приложение мы делали в рамках семестрового проекта по C++ на первом курсе университета. Мы еще со школы увлекаемся программированием и математикой, но PosiPhone — наш первый серьезный командный проект.
Идея проекта
Идею для проекта нам дал ментор — Всеволод Опарин. Он выпускник СПбАУ, сейчас занимается машинным обучением при небольшом стартапе из Кремниевой Долины. Во время карантина Всеволод много общался с друзьями с помощью разных приложений, но столкнулся с проблемой: если во время звонка говорят сразу несколько человек, трудно разобрать хоть что-нибудь. Поэтому возникла простая идея: сгруппировать людей в кучки, как в реальной жизни, и сделать так, чтобы они могли кочевать от группы к группе, слушая несколько разговоров одновременно.
Так и появился PosiPhone — десктопное клиент-серверное приложение для общения голосом. Его особенность в необычной регулировке звука: пользователь слышит других людей громче или тише в зависимости от их удаленности на экране.
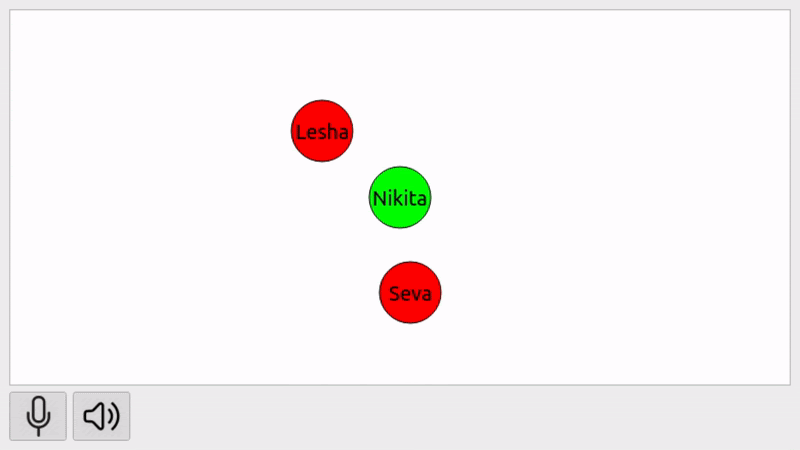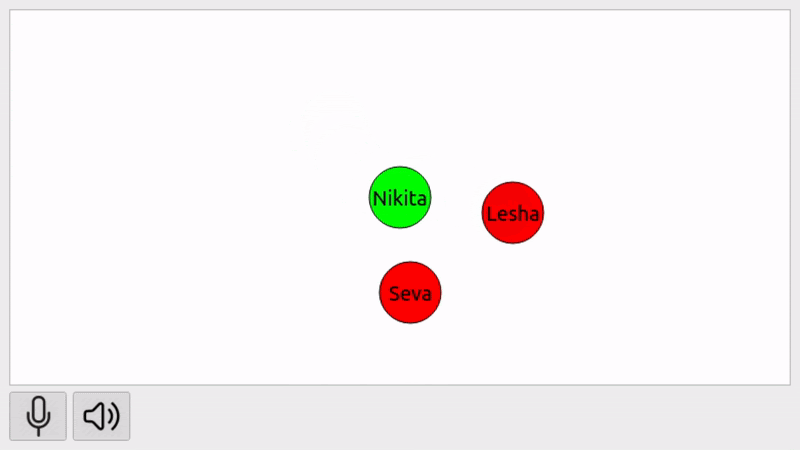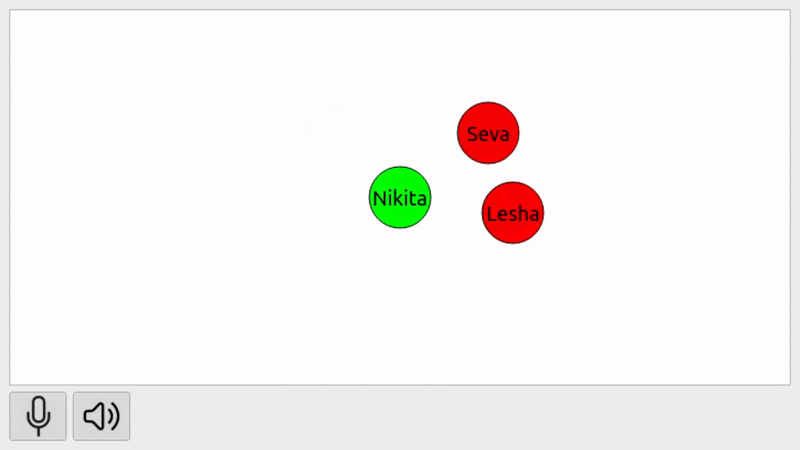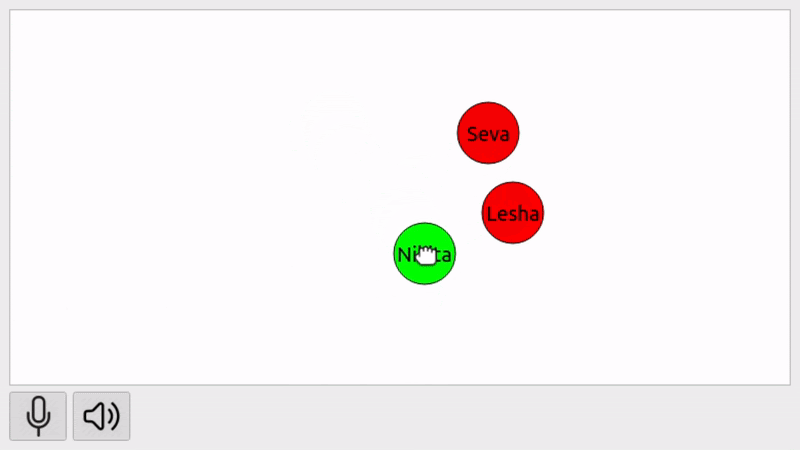
Как это выглядит? Пользователь запускает приложение, видит на экране свой аватар — зеленый кружок — и аватары других участников — красные кружки. Пользователь может перемещать свой аватар, включать/выключать звук, чтобы слышать других участников, а также включать/выключать микрофон, чтобы другие участники слышали его. Как мы уже сказали, громкость звука зависит от расстояния аватаров на экране. Соответственно, если пользователи слишком далеко, они вообще не услышат друг друга.

Целью нашего проекта было выяснить, насколько удобна такая необычная регулировка громкости. А заодно изучить стек технологий, необходимых для реализации проекта.
Структура приложения
Клиент
Начнем описание приложения с клиентской части. Она состоит из трех модулей: графического интерфейса, аудиомодуля и сетевого модуля.
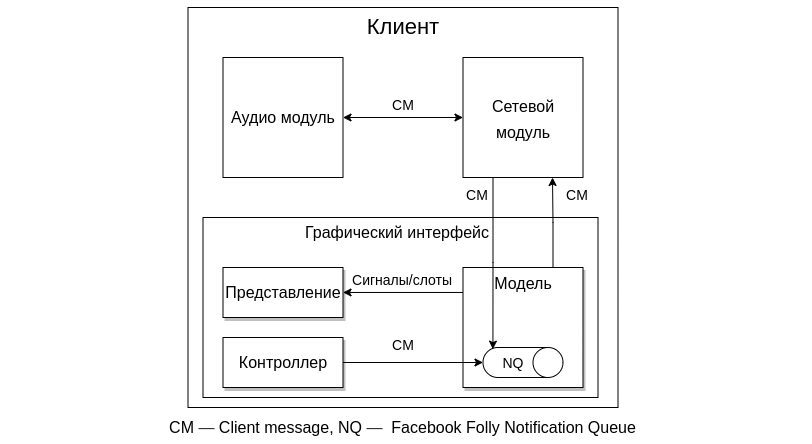
Графический интерфейс. Реализован с помощью паттерна проектирования MVC (Model-View-Controller, Модель-Представление-Контроллер). Когда пользователь передвигает мышкой свой кружок, контроллер фиксирует это событие и передает его в модель. Она поддерживает информацию о пользователях и задает логику графического интерфейса. Изменения модели передаются на представление с помощью механизма сигналов и слотов библиотеки Qt. Главное их преимущество — они потокобезопасны, то есть объекты из разных потоков не будут мешать друг другу во время работы с общими данными.
Сетевой модуль позволяет пользователям обмениваться данными друг с другом.
Аудиомодуль записывает и проигрывает звук.
Подробнее об этих модулях расскажем позже.
Многопоточность
Понятно, что графический интерфейс и аудиомодуль не могут работать одновременно в одном потоке. Поэтому нам потребовалась многопоточность.
Для удобной работы с несколькими потоками ментор посоветовал использовать структуру данных Notification Queue (далее NQ) из библиотеки Facebook Folly. Это асинхронная потокобезопасная очередь, в которую объекты из других потоков могут складывать свои сообщения, где, например, могут лежать новые координаты для кружка или записанный аудиофрагмент. Когда в очередь поступает новое сообщение, она вызывает специальную callback-функцию, в которой это сообщение можно обработать асинхронно. Это значительно упрощает реализацию.
Для обмена информацией между модулями на клиенте была реализована структура Message (на схеме обозначена как CM — Client Message). Когда модуль хочет передать, например, новые координаты кружка или аудиофрагмент модулю из другого потока, он кладет эти данные в структуру Message, и передает это сообщение в соответствующую NQ.
Добавляем сеть
Для передачи данных по сети у нас есть два сетевых модуля: один расположен на клиенте, второй — на сервере. Модули общаются друг с другом через интернет с помощью библиотеки ZMQ. Сериализацию сообщений мы делали с помощью библиотеки boost. При ожидании ответа сервера сетевой модуль ZMQ на клиенте может зависнуть на неопределенное время, например, из-за проблем с соединением. Чтобы это предотвратить, мы также поместили этот модуль в отдельный поток. Поэтому модель и аудиомодуль соединены с сетевым модулем клиента посредством очереди NQ.
Сервер

Сетевой модуль ZMQ на сервере. Хранит в себе актуальную информацию о всех активных клиентах. Также он обменивается данными с микшером. В дополнение к базовой функциональности, сетевой модуль ZMQ на сервере оснащен модулем детектирования пользователей. Он отвечает за обнаружение тех пользователей, которые испытывают проблемы с подключением к интернету. Если сетевой модуль клиента, который отвечает за конкретного пользователя, не отвечает модулю детектирования в течении нескольких секунд, то сервер считает, что пользователь вышел из приложения и обрывает с ним связь.
Микшер. Это модуль, который из аудиофрагментов от разных пользователей генерирует аудиозаписи с громкостями, измененными в зависимости от расстояния. Опять же по причинам, связанным с сетью, мы вынесли его в отдельный поток. Данные для микширования он получает из сетевого модуля ZMQ на сервере. Это взаимодействие реализовано через NQ, но с использованием новых сообщений — Server Message (SM). Мы решили сделать две разные структуры для сообщений на клиенте и на сервере, потому что микшер не использует дополнительную информацию, которая хранится в CM.
Добавляем аудио
Подробнее о микшировании звуков

На этой схеме более подробно показано взаимодействие сетевого модуля на сервере и микшера. Сетевой модуль складывает в NQ сообщения, полученные от клиентов. Там модуль микшера выбрасывает те сообщения, которые пришли слишком поздно из-за задержек сети. Остальные сообщения сортируются по очередям в зависимости от клиента, от которого они пришли. Микшер каждые 50 миллисекунд берет по одному сообщению из каждой очереди и смешивает их в несколько аудиодорожек: каждому пользователю своя в зависимости от расстояния до других пользователей. Смешанные фрагменты обратно отправляются в сетевой модуль.
Подробнее об аудиомодуле на клиенте
Теперь поговорим про аудиомодуль на клиенте. Записывание аудиосообщений тривиально: в буфер постоянно добавляются новые аудиофрагменты и раз в 50 миллисекунд из свежих данных генерируется сообщение, которое отправляется на сетевой модуль клиента.

С проигрыванием история интереснее. Сетевой модуль перенаправляет на аудиомодуль аудиосообщения от других участников. Сообщения перед проигрыванием выравниваются по времени. Это нужно в ситуации, когда есть задержки сети. В этом случае клиенту приходит сразу несколько аудиосообщений. Тогда логично проиграть их не все сразу, а последовательно в том порядке, в котором они записывались. Для этого мы использовали структуру данных Producer Consumer Queue из библиотеки Facebook Folly. Её мы выбрали, потому что она потокобезопасна, но работает как обычная очередь. Для выравнивания мы достаем аудиосообщения каждые 50 миллисекунд из очереди и проигрываем их.
Общая структура приложения

Давайте рассмотрим на примере, какой путь проходят аудиосообщения. Сначала аудиомодуль записывает голос на каждом из клиентов, из которого конструируются сообщения Client Messages (CM). Эти сообщения передаются в сетевой модуль клиента, откуда информация по сети идет на сервер. Сетевой модуль сервера конструирует Server Messages (SM) на основе полученной информации и передаёт их в микшер. Микшер отдает обратно смешанные звуковые SM. Сетевой модуль сервера пересылает результаты работы микшера на каждый из клиентов. На сетевом модуле конструируются CM и передаются в аудиомодуль, где сообщения и проигрываются.
Работа над приложением
Мы разделили проект на три части: Никита отвечал за сетевую часть, Лёша взялся за GUI и запись/воспроизведение звука на клиенте, а Федя писал микшер звука на сервере.
Сначала перед нами стояла задача написать приложение с базовым функционалом: на экране двигаются свой и чужие кружки, звука нет.
Сеть
Чтобы лучше ознакомиться с темой, Никита прошел курс от Google по сетям на Coursera. После подготовки пришло время определиться с технологией. Мы встали перед выбором: Socket.IO, boost или ZMQ? С помощью первой библиотеки достаточно просто написать клиент-серверное приложение, но у нас были опасения, что скорости может не хватить, так как она была разработана в основном под JS. Второй библиотекой пользовались многие наши одногруппники в своих проектах, но там надо было работать почти с голыми сокетами. В то время как в библиотеке ZMQ уже реализованы многие удобные паттерны обмена сообщений. Как вы, наверное, догадались, мы остановились на третьем варианте. Чтобы понять на простом примере особенности обмена сообщениями по сети, Никита написал простой чат с помощью ZMQ, как ему посоветовал ментор.
Для работы над проектом нам понадобился сервер с публичным IP-адресом, где мы могли бы запустить общедоступный сервер. Спасибо нашему преподавателю по C++ Егору Суворову за то, что он предоставил такой сервер.
Графический интерфейс
Для GUI мы выбрали Qt. Причин несколько Во-первых, эта библиотека написана на C++, который мы изучали, к тому же у нас проводилось несколько семинаров именно по Qt. Также это удобная библиотека для разработки интерфейса пользователя с подробной документацией и большим сообществом разработчиков. Изначально у нашего ментора была задумка реализовать этот проект в вебе. Но в таком случае пришлось бы в спешном порядке изучать JavaScript/TypeScript и несколько других фреймворков, из-за чего мы могли бы не успеть к защите.
Так как проект разрабатывался параллельно, во время написания графической части сетевая часть еще была не готова. Поэтому мы заменили ее на mock-объект.
Для записи звука выбрали модуль Qt Multimedia, а именно классы QAudioInput и QAudioOutput. Они позволяют сохранять записанное аудио в буфер и проигрывать звук из него, что удобно для передачи аудио по сети.
Микшер
Фёдор реализовал базовые функции этого модуля. Перед добавлением в проект микшер был протестирован локально на аудиозаписях, скачанных из интернета. Для упрощения работы с аудиофайлами воспользовались библиотекой AudioFile: она декодирует .wav файл на диске в его структурное представление в программе. После успешного тестирования на нескольких файлах начали добавление модуля в проект.
И как мы все это объединяли
Сеть и GUI. Сначала мы решили объединить сеть с GUI. С интерфейсом пересекается клиентская часть приложения, поэтому Никита реализовал функционал, который диктовал GUI. Примерно через неделю попыток у нас получилось добиться, чтобы можно было подключить несколько человек к одной сессии, и передвижение кружка на одном компьютере отображалось на других.
Проблемы серверного модуля. При работе с удаленным сервером возникли проблемы с запуском серверного модуля. Сначала мы пробовали скомпилировать файлы прямо на выделенном сервере. Но для этого надо было поставить библиотеку Facebook Folly, которая либо собирается из исходников, что сделать весьма нетривиально, либо ставится на всю систему специальным скриптом — чего Егор Суворов сказал нам не делать. Зато можно было загружать любые пакеты на выделенный сервер. Поэтому мы применили статическую линковку, загрузили получившийся файл на выделенный сервер, поставили необходимые пакеты для библиотеки Facebook Folly, и уже после этого получилось запустить исполняемый файл серверного модуля на сервере. Позднее мы обернули серверную часть в docker, как нам посоветовал ментор. Теперь серверная часть собирается гораздо удобнее, чем раньше.
Микширование. Далее настало время добавлять микширование звуков. Эта часть должна запускаться на сервере как отдельный модуль. Собственно, проблем с микшированием почти не было, объединение прошло гладко. Но когда мы запустили наше приложение, были ощутимые задержки голоса при передаче его по сети, а некоторые звуки вообще пропадали и не проигрывались. Мы это исправили при поддержке ментора, и в итоге нам удалось добиться приемлемой задержки проигрывания сообщений.
Что же мы поменяли? Сначала мы стали решать проблему со звуками, которые пропадают: она возникала из-за того, что аудиофрагменты, которые пришли на микшер слишком поздно, выкидывались. Поэтому мы попытались вообще не выкидывать сообщения на микшере, а проигрывать все, что было отправлено и обработано микшером. В этом случае при запуске приложения задержки были не слишком большие, но по прошествии времени они увеличивались.

Стало понятно, что буфер аудиофрагментов, который пересылается между частями клиента, увеличивается с течением времени. То есть аудиомодуль записывал голос пользователя, далее складывал полученные аудиофрагменты в буфер, потом создавал сообщение с этим буфером и посылал его на сетевой модуль. Однако, буфер забывали чистить, поэтому его размер становился больше. Как следствие, время на пересылку сообщений увеличивалось. Мы исправили это, удаляя из буфера те сообщения, которые уже были отправлены на сетевой модуль. Потестили — теперь задержка была примерно постоянной, но хотелось, чтобы было быстрее. Тогда мы уменьшили качество записи звука в голосовых сообщениях. В итоге получился приемлемый результат: мы смогли разговаривать друг с другом через наше приложение и понимать сказанное.
Что у нас получилось
В результате получилось приложение со всем базовым функционалом, которого мы хотели добиться. Вот видео с нашей защиты. Конечно, проект не идеален. Вот несколько пунктов, которые можно изменить в нашей работе:
оптимизировать сетевую часть для уменьшения времени задержки, например, использовать альтернативный паттерн обмена сообщениями;
некоторые константы захардкожены, следовало бы предоставить пользователю возможность выбирать качество звука;
добавить комнаты для параллельных звонков;
добавить видео участников чата.
Заключение
В итоге мы пришли к выводу, что такая регулировка звука весьма удобна: чтобы сделать звук громче или тише, достаточно всего лишь пододвинуть свой кружочек к говорящему или отодвинуть соответственно. Также в одной сессии на экране пользователи могут организоваться в несколько компаний, при этом общение происходит отдельно внутри каждой группы. Пользователи могут перейти из одной компании в другую просто перетащив кружок. Это альтернативный взгляд на комнаты в приложении Zoom.
Однако, в путешествии важен не только пункт назначения, но и путь к нему. Пока мы реализовывали проект, мы прошли через многое:
работали в команде;
проходили code-review;
практиковались в использовании git;
изучили стек новых технологий: Qt, ZMQ, многопоточность, асинхронность, и так далее.
Это был классный опыт разработки своего приложения в команде. Спасибо Вышке, организаторам, нашему ментору Всеволоду Опарину и всем причастным!
Репозиторий проекта на GitHub
Другие материалы из нашего блога о проектах студентов младших курсов:
Комментарии (24)

GryZin
22.11.2021 18:35Интересный проект, еще бы CI прикрутили там actions на коммиты было бы еще лучше. Что касается идея, то я думаю проблема многоголосия в чатах из-за того что звук если груба становиться двумерным - все говорят с разной громкостью но из одной точки 3х мерного пространства. Если говорить про переход между группами собеседников - то для этого и создают отдельные каналы в чатах.

Ritan
22.11.2021 19:14Так умел( и умеет ) ещё TeamSpeak, причём там ещё делалась попытка имитировать направление на источник звука.
В целом, точности современного "3D" аудио сильно не хватает, и когда людей больше 3-4, то угадать направление становится очень сложно

dempfi
22.11.2021 19:54+4Можно посмотреть на https://spatial.chat/ как на коммерческую реализацию вашей идеи в продукт.

AVL93
23.11.2021 02:01+3А можно и на эту идею посмотреть как на открытую и бесплатную альтернативу spatial.chat :)

Denisov22
24.11.2021 11:41Да, вы правы, в Spatial chat используется та же идея с динамическим звуком, что и в нашем проекте и еще много классных фич. К сожалению, мы не знали об этом приложении на старте.
Кстати, есть еще аналоги нашего проекта, например: gatherly и kinspray graffiti

p07a1330
23.11.2021 00:20-3В целом годно, но есть проблемы с подачей материала - слишком сильно торчат уши дипломной/курсовой работы, с формальным вступлением/заключением...

johnfound
23.11.2021 01:53И еще, перемещаться будет удобнее через WASD или стрелках. Так можно будет просто прогуляться по комнате.

kt97679
23.11.2021 03:59Может проще добавить возможность на клиенте индивидуально регулировать громкость каждого участника?

eigrad
23.11.2021 08:25+2Использовать ZMQ конечно оригинально, и в целом не лишено смысла, но почему не рассматривали вариант взять готовую библиотеку для передачи мультимедиа, которая умеет в какой-нибудь современный Opus, автоматическую подстройку задержки и обработку проблем соединения? И использовать какой-нибудь стандартный для передачи потока аудио протокол :-).
Безотносительно этого вопроса, ребята и ментор - молодцы, нормальная работа.
Denisov22
24.11.2021 11:48Решение взять готовые библиотеки и применить их несомненно хорошо. Но мы с ребятами были поставлены в жесткие рамки успеть написать готовое приложение до защит проектов. Поэтому было принято решение реализовать базовый функционал каким-нибудь не особо сложным способом, чтобы не закопаться в изучении/применении готовых библиотек и точно успеть.

tmin10
23.11.2021 12:22А почему не взяли за основу ru.wikipedia.org/wiki/Mumble? Вроде бы всё тоже самое, но уже готовое и опенсурсное.
Denisov22
24.11.2021 12:06Честно говоря мы не знали о таком приложении для позиционировании звука. Выглядит весьма интересно) Вообще есть множество приложений с похожей идеей динамического звука. Аналоги я привел в комментарии выше.
MikhailZankovich
23.11.2021 16:45Идея интересная.
Не понятно, почему решили микшировать на сервере? Есть предложение, что при масштабировании это станет очень узким местом.
Второй момент как согласуются маппинги пользователей? Т.е. тип А у себя настроил 100% слышимость типа В, а тот в свою очередь убрал А "в дальний угол". Пошла разобщённость и ноль диалога.
Имхо нужно виртуальное согласованное пространство с координатами каждого участников.
Сервер в этом случае должен определить какие звуковые потоки попали в "зону" слышимости конкретного пользователя и передать их на клиента.
Клиент уже смикшировать по установкам пользователя.
Да, клиент при этом станет более ресурсоемким, но в целом приложение стабильнее и функциональнее.
Denisov22
24.11.2021 13:22+1Смотрите, перемещение аватаров пользователей в нашем проекте уже синхронизировано между всеми клиентами. Поэтому не будет такой ситуации, что один пользователь слышит другого, а второй — нет. Возможно, стоило написать это в тексте статьи более явно.
У нас нет как таковых "зон" слышимости конкретного пользователя. Сервер передает микшеру вообще все аудиосообщения. Но если расстояния между пользователями достаточно большое, то они перестают слышать друг друга.
Сейчас объясню почему мы микшируем именно на сервере. Пусть подключено n клиентов. Микшеру нужно для каждого клиента выдать свою уникальную аудиодорожку.
Если микширование исполняется на сервере, то передач аудиосообщений по сети происходит всего O(n) штук. Каждый клиент передал одно свое аудисообщение и после микширования на сервере получил одну готовую аудиодорожку с голосами всех других пользователей. Стоит отметить, что сам микшер все же выполняет O(n^2) действий.
Если же микширование сделать на каждом из клиентов, то передач аудиосообщений по сети потребуется O(n^2) штук: каждому из n микшеров на клиентах нужно знать все (n - 1) аудисообщения от других пользователей. При этом суммарно все микшеры выполнят те же O(n^2) действий.
Получаем, что микшировать на сервере эффективнее с точки зрения количества аудиосообщений, передающихся по сети.
Не могли бы вы дополнительно пояснить почему микширование на сервере может стать узким местом при масштабировании?
MikhailZankovich
24.11.2021 14:32-1На небольших объемах - Вы правы.
Но если вы собираетесь провести он-лайн конференцию/митап с 1000+ участников?
В любом случае вы будете либо делить участников на группы (что снижает "реализм" платформы), либо ограничивать "зону слышимости" участников.В противном случае вам надо будет микшировать 1000^2 потоков в рантайме...
Второй момент: ваша платформа вырастает до 10м+ одновременных сессий. "Комнаты" - по 10 участников в среднем. Итого 1млн комнат, для каждой нужно "микшировать" 10*10 =100. Т.е. 100 млн "миксов" вам надо "готовить" на сервер сайде. Можете прикинуть мощности, которые вам потребуются для реализации? Сможете оставить платформу условно бесплатной (а-ля зум)?
Вы сыграли существенно в пользу снижения утилизации сетевого ресурса, но пожертвовали при этом ресурсами вычислительными. Тут надо оценить - что для вас "дороже" - масштабировать "канал" передачи данных практически линейно с ростом пользователей, или квадратично наращивать ресурсы сервера?
И позволю "замкнуть" обсуждение на первый тезис: "реалистичность". Представьте он-лайн митап, где участники свободно перемещаются по он-лайн пространству, в различных точках которого идут доклады / выступления / дискуссии и человек волен сам выбирать где ему "оказаться" в каждый момент времени - он может подобраться ближе "к площадке" выступающего с интересным докладом или находится между двух площадок одновременно, он может объединится с коллегами комментируя по ходу доклад, но не мешая при этом другим участникам. И все это позволяет сделать механизм "области слышимости".
И как раз этот механизм позволит "ограничить" рост передачи количества "дорожек" по сети и нагрузку на "один пользовательский канал".
Denisov22
24.11.2021 15:24Согласен, на сервер действительно выйдет много нагрузки при наличии множества комнат.
Давайте сравним оба подхода. Пусть у нас есть k комнат в каждой из которых по n участников. Когда микшер на сервере, то получаем передачу по сети O(kn) сообщений и микширование O(kn^2) сообщений на сервере.
Когда микшер на каждом из клиентов, то получаем передачу по сети O(k * n^2) сообщений и микширование O(n) сообщений на каждом из (n * k) микшеров, установленных на клиентах.
Получаем, что в первом случае нужно наращивать ресурсы сервера в (n * k) раз, а во втором масштабировать канал передачи данных в n раз. Действительно, при большом количестве комнат второй способ явно привлекательнее.
Отмечу еще, что в первом способе можно сделать систему из нескольких серверов, которая будет перекидывать участников между серверами, если нагрузка на каком-то сервере превысила определенный предел.
Также, про митап с 1000+ участников согласен. При масштабировании определенно стоит добавить зону слышимости. Она действительно должна ограничить количество сообщений, передающихся по сети.
MikhailZankovich
24.11.2021 15:58"масштабировать канал передачи данных в n раз"
а вот тут можно попробовать посмотреть в сторону P2P протоколов обмена между участниками, а сервер использовать исключительно как "координатор".
и минимизировать утилизацию ресурсов на серверном уровне.
В целом еще раз отмечу - идея интересная и перспективная. Я бы на вашем месте ее развивал именно в сторону массовых он-лайн мероприятий в "виртуальной реальности".
Сейчас КОВИД ограничения этому благотворствуют. Как минимум хайп на проведении "он-лайн корпоративов" обеспечен: собрать сотни сотрудников на одной он-лайн площадке, дать им возможность виртуального перемещения, встроить игровые механики, поставить "сцены" с выступлением приглашенных "групп" - имхо, потенциал огромен. Удачи!
Alex_ME
Постоянно о таком думал во время бесконечных созвонов. Жалко, что реально используемые средства (Zoom, Teams) не используют такой подход.
Вот только помимо громкости, стоило бы добавлять фазовый сдвиг, чтобы виртуально располагать собеседников в пространстве. Это, кажется, даже более важно для того, чтобы слышать всех разборчиво.
Tontu
Раз такое дело, дополню. Подобие стереопанорамы можно получить, добавив зависимость сдвига фазы между воспроизведением на левом и правом каналах от угла источника звука относительно направления взгляда. Сдвиг там совсем небольшой, порядка единиц миллисекунд, это всё легко считается через скорость звука и расстояние до левого и правого уха.
Но кроме этого, для более правдоподобной картины стоит рассмотреть ещё параметрическую эквализацию, ведь если мы берём первое приближение головы идеальной сферой, то мощность звука на ухо зависит от частоты этого сигнала и угла относительно уха. Если низкие частоты с длиной волны сильно больше диаметра сферы будут регистрироваться почти вне зависимости от направления звука, то средне- и высокочастотные уже не способны огибать такие препятствия и будут значительная разница между каналами. Это более правильная регулировка, нежели просто уровнем сигнала. Частоту среза не скажу, но что-то порядка единицы кГц, плюс минус. Ну это если не брать АЧХ реального уха и его зависимость от этих углов. В реальном ухе ещё и нелинейности ярко выраженные есть, зависящие от направления на источник, но там уже совсем мрак. Имхо в чатах и "округления" будет достаточно более чем.
Denisov22
Насколько я понимаю добавление фазового сдвига соответствует идее регулирования громкости звука всех пользователей у каждого участника независимо (будь то в реальном времени или уже в записи).
Это интересный подход, но я не думаю, что он пересекается с нашим: в проекте все перемещения кружков (а соответственно и громкости между каждой парой участников) синхронизированы между пользователями, чтобы было понятно какие конкретно пользователи образуют компании.
Как я вижу интегрирование вашей идеи: помимо основного интерфейса можно сделать дополнительный, в котором только сам пользователь может регулировать громкость всех участников конкретно для себя, например уже передвигая любые кружки. В принципе, это возможное развитие приложения. Спасибо за идею)
mayorovp
Неправильно вы понимаете, добавление фазового сдвига как раз и соответствует идее расположения участников в пространстве. И неважно, индивидуально они регулируются или одинаково для всех.
Denisov22
Хм, а можете подробнее объяснить идею с фазовым сдвигом? Пока что неясно как это соответствует расположению участников в пространстве.