
В процессе создания контейнеров ключевым компонентом является изоляция процессов. При этом одним из основных внутренних механизмов выступают пространства имен. В этой статье мы разберем, что они из себя представляют и как работают, чтобы научиться создавать собственный изолированный контейнер и лучше понять каждый его компонент.
Что такое пространства имен?
Пространства имен – это одна из особенностей ядра Linux, введенная в версии 2.6.24 в 2008 году. Они обеспечивают процессы собственным системным представлением, тем самым изолируя независимые процессы друг от друга. Другими словами, пространства имен определяют набор ресурсов, которые может использовать процесс (нельзя взаимодействовать с тем, что не видно). На высоком уровне они позволяют тонко разделять глобальные ресурсы операционной системы, такие как точки монтирования, сетевой стек и утилиты межпроцессного взаимодействия.
Сильная сторона пространств имен в том, что они ограничивают доступ к системным ресурсам без информирования об этом выполняющегося процесса. В Linux они обычно представлены как файлы в директории
/proc/<pid>/ns. cryptonite@cryptonite:~ $ echo $$
4622
cryptonite@cryptonite:~ $ ls /proc/$$/ns -al
total 0
dr-x--x--x 2 cryptonite cryptonite 0 Jun 29 15:00 .
dr-xr-xr-x 9 cryptonite cryptonite 0 Jun 29 13:13 ..
lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 ipc -> 'ipc:[4026531839]'
lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 mnt -> 'mnt:[4026531840]'
lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 net -> 'net:[4026532008]'
lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 pid -> 'pid:[4026531836]'
lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 pid_for_children -> 'pid:[4026531836]'
lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 time -> 'time:[4026531834]'
lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 time_for_children -> 'time:[4026531834]'
lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 user -> 'user:[4026531837]'
lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 uts -> 'uts:[4026531838]'При порождении нового процесса, он наследует все пространства имен от своего родителя.
# порождение
cryptonite@cryptonite:~ $ /bin/zsh
# верификация родительского PID
╭─cryptonite@cryptonite ~
╰─$ ps -efj | grep $$
crypton+ 13560 4622 13560 4622 1 15:07 pts/1 00:00:02 /bin/zsh
╭─cryptonite@cryptonite ~
╰─$ ls /proc/$$/ns -al
total 0
dr-x--x--x 2 cryptonite cryptonite 0 Jun 29 15:10 .
dr-xr-xr-x 9 cryptonite cryptonite 0 Jun 29 15:07 ..
lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 ipc -> 'ipc:[4026531839]'
lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 mnt -> 'mnt:[4026531840]'
lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 net -> 'net:[4026532008]'
lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 pid -> 'pid:[4026531836]'
lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 pid_for_children -> 'pid:[4026531836]'
lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 time -> 'time:[4026531834]'
lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 time_for_children -> 'time:[4026531834]'
lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 user -> 'user:[4026531837]'
lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 uts -> 'uts:[4026531838]'Пространства имен создаются с помощью системного вызова
clone, сопровождаемого одним из следующих аргументов:-
CLONE_NEWNS– новое пространство имен mount; -
CLONE_NEWUTS– новое пространство имен UTS; -
CLONE_NEWIPC– новое пространство имен IPC; -
CLONE_NEWPID– новое пространство имен PID; -
CLONE_NEWNET– новое пространство имен NET; -
CLONE_NEWUSER– новое пространство имен USR; -
CLONE_NEWCGROUP– новое пространство имен cgroup.
Пространства имен также можно создавать с помощью системного вызова
unshare. Разница между clone и unshare в том, что первый порождает новый процесс внутри нового набора пространств имен, а последний перемещает в новый набор пространств имен текущий процесс.Зачем использовать пространства имен?
Если представить, что пространства имен – это ящики для процессов, содержащие некоторые абстрагированные системные ресурсы, то удобной особенностью таких ящиков будет возможность добавлять и удалять их содержимое, не влияя на содержимое других ящиков. Либо, если изолированный процесс А вдруг обезумит и решит удалить всю файловую систему или сетевой стек в своем ящике (наборе пространств имен), то подобное действие не повлияет на абстракцию этих ресурсов, предоставленную для процесса В, находящегося в другом ящике.
Более того, пространства имен могут обеспечивать еще более тонкую изоляцию, позволяя процессам А и В разделять некоторые ресурсы (например, совместно использовать точку монтирования или сетевой стек). Зачастую пространства имен используются, когда на машине нужно выполнить недоверенный код, не подвергая рискам ее ОС.
Платформы соревновательного программирования, такие как Hackerrank, Codeforces и Rootme, используют среды, помещенные в пространства имен, для выполнения нескольких пользовательских служб (например, веб-серверов или баз данных) на одном оборудовании без возможности их коллизий.
Так что, пространства имен также могут оказаться полезны для эффективной реализации общего доступа к ресурсам. Другие облачные технологии вроде Docker или LXC тоже используют пространства имен для изоляции процессов. Эти платформы помещают процессы операционной системы в изолированные среды, называемые контейнерами. Выполнение процессов, к примеру, в контейнерах Docker, подобно их выполнению на виртуальных машинах.
Разница же между VM и контейнером в том, что контейнеры разделяют и используют непосредственно ядро ОС, что делает их существенно легче виртуальных машин ввиду отсутствия аппаратной эмуляции. Такое повышение общей производительности в основном обеспечено использованием пространств имен, интегрированных непосредственно в ядро Linux. Но при этом существует и ряд реализаций облегченных виртуальных машин.
Типы пространств имен
В текущей стабильной версии ядра 5.7 есть семь пространств имен:
- PID: изоляция дерева системных процессов;
- NET: изоляция сетевого стека хоста;
- MNT: изоляция точек монтирования файловой системы хоста;
- UTS: изоляция имени хоста;
- IPC: изоляция утилит межпроцессного взаимодействия (сегменты разделяемой памяти, семафоры);
- USER: изоляция ID пользователей системы;
- CGROUP: изоляция виртуальной файловой системы
cgroupхоста.
Каждый процесс может воспринимать только одно пространство имен, то есть в любой момент времени любой процесс P принадлежит только к одному его экземпляру. Например, когда определенный процесс хочет обновить таблицу маршрутов в системе, то ядро показывает ему копию этой таблицы для пространства имен, к которому он принадлежит в данный момент. Если процесс запросит свой ID в системе, то ядро сообщит ID в его текущем пространстве имен (в случае со вложенными пространствами).
Мы подробно разберем каждое пространство имен, чтобы понять стоящие за ними механизмы операционной системы. Это понимание, в свою очередь, поможет нам прояснить, что же скрывается под покровом современных технологий контейнеризации.
Пространство имен PID
Исторически ядро Linux поддерживает одно дерево процессов. Древовидная структура данных содержит ссылку на каждый активный процесс в виде иерархии от родителя к потомку. Она также нумерует все выполняющиеся в ОС процессы. Эта структура поддерживается в файловой системе
procfs, которая является свойством исключительно работающей ОС. Эта структура позволяет процессам с достаточными привилегиями прикрепляться к другим процессам, инспектировать эти процессы, обмениваться с ними информацией и/или завершать их. Она также содержит информацию о корневом каталоге процесса, его текущем рабочем каталоге, дескрипторах открытых файлов, адресах виртуальной памяти, доступных точках монтирования и т.д.
# пример структуры procfs
cryptonite@cryptonite:~ $ls /proc/1/
arch_status coredump_filter gid_map mounts pagemap setgroups task
attr cpu_resctrl_groups io mountstats patch_state smaps timens_offsets
cgroup environ map_files numa_maps root stat uid_map
clear_refs exe maps oom_adj sched statm
...
# пример структуры дерева процессов
cryptonite@cryptonite:~ $pstree | head -n 20
systemd-+-ModemManager---2*[{ModemManager}]
|-NetworkManager---2*[{NetworkManager}]
|-accounts-daemon---2*[{accounts-daemon}]
|-acpid
|-avahi-daemon---avahi-daemon
|-bluetoothd
|-boltd---2*[{boltd}]
|-colord---2*[{colord}]
|-containerd---17*[{containerd}]При загрузке системы в большинстве современных ОС Linux изначально запускается
systemd (системный демон), расположенный в корневом узле дерева. Его родителем выступает PID=0 – по сути, не существующий процесс ОС. После старта демон отвечает за запуск других служб/демонов, которые представлены в качестве его потомков и необходимы для нормального функционирования операционной системы. Эти процессы будут иметь PID > 1, при этом сами PID в структуре дерева являются уникальными.С введением пространства имен PID появилась возможность создавать вложенные деревья процессов. В результате не только
systemd (PID=1), но и другие процессы могут воспринимать себя как корневые, перемещаясь в вершину поддерева и получая в нем PID=1. Все процессы этого же поддерева тоже будут получать ID относительно данного пространства имен PID. Это также означает, что некоторые процессы могут в итоге иметь несколько ID в зависимости от количества пространств имен процессов, в которых они находятся. Тем не менее в каждом пространстве имен только один процесс может иметь конкретное значение PID (уникальное значение узла в дереве процессов становится свойством, относящимся к конкретному пространству имен).
Это вытекает из того факта, что отношения между процессами в пространстве имен корневого процесса сохраняются. Иначе говоря, процесс в новом пространстве имен PID по-прежнему остается прикреплен к своему родителю, таким образом являясь частью его пространства имен PID. Эти отношения между всеми процессами можно увидеть в пространстве имен корневого процесса, но не в пространстве вложенного процесса.
Из этого следует, что процесс в пространстве имен вложенного процесса не может взаимодействовать со своим родителем или любым другим процессом в пространстве имен вышестоящего процесса. Причина в том, что, находясь на вершине нового пространства имен PID, процесс воспринимает свой PID как 1, а до процесса с PID=1 других процессов нет.

В ядре Linux PID представлен как структура. Внутри нее мы также находим пространства имен, частью которых является процесс, в виде массива структуры
upid.struct upid {
int nr; /* значение pid */
struct pid_namespace *ns; /* пространство имен, в котором
* это значение видимо */
struct hlist_node pid_chain; /* цепочка хеширования для быстрого поиска PID в заданном пространстве имен */
};
struct pid {
atomic_t count; /* подсчет ссылок */
struct hlist_head tasks[PIDTYPE_MAX]; /* списки задач */
struct rcu_head rcu;
int level; // количество upid
struct upid numbers[0]; // массив пространств имен pid
};Для создания нового процесса в новом пространстве имен PID нужно вызвать
clone() с флагом CLONE_NEWPID. При том, что другие пространства имен, обсуждаемые далее, можно также создавать при помощи системного вызова unshare(), пространство имен PID создается только во время порождения нового процесса с помощью clone() или fork().Рассмотрим пример:
# Запустим процесс в новом пространстве имен pid;
cryptonite@cryptonite:~ $sudo unshare --pid /bin/bash
bash: fork: Cannot allocate memory [1]
root@cryptonite:/home/cryptonite# ls
bash: fork: Cannot allocate memory [1]Что произошло? Кажется, что оболочка застряла между двух пространств имен. Причина в том, что unshare не входит в новое пространство имен после выполнения (вызов
execve()). Это является желаемым поведением Linux. Текущий процесс “unshare” вызывает unshare, создавая новое пространство имен PID, но текущий процесс “unshare” не находится в этом пространстве. Процесс B создает новое пространство имен, но сам этот процесс в него помещен не будет, туда попадут только его дочерние процессы. После создания пространства имен программа unshare выполнит
/bin/bash. Затем /bin/bash ответвит несколько новых под-процессов для выполнения определенных задач. Эти под-процессы получат PID относительно нового пространства имен и по окончанию своей работы завершатся, оставив это пространство имен без PID=1. Ядро Linux не любит пространства имен PID, в которых нет процесса с PID=1. Поэтому, когда пространство остается пустым, оно отключает некоторые механизмы, связанные с размещением PID внутри этого пространства, что и ведет к ошибке. В интернете можно найти немало информации по этой теме.Вместо этого нужно проинструктировать программу
unshare на ответвление нового процесса после создания пространства имен. Тогда этот новый процесс получит PID=1 и выполнит нашу программу оболочки. В таком случае, когда под-процессы /bin/bash будут завершаться, пространство имен будет по-прежнему хранить процесс с PID=1.cryptonite@cryptonite:~ $sudo unshare --pid --fork /bin/bash
root@cryptonite:/home/cryptonite# echo $$
1
root@cryptonite:/home/cryptonite# ps
PID TTY TIME CMD
7239 pts/0 00:00:00 sudo
7240 pts/0 00:00:00 unshare
7241 pts/0 00:00:00 bash
7250 pts/0 00:00:00 psНо почему при использовании
ps у оболочки нет PID 1? И почему мы все еще видим процесс из корневого пространства имен? Программа ps для получения информации о текущих процессах в системе использует виртуальную файловую систему procfs. Эта файловая система монтируется в каталог /proc. Однако в новом пространстве имен эта точка монтирования описывает процессы из корневого пространства имен PID. Избежать этого можно двумя способами:
# создать новое пространство имен mount и смонтировать в него новую procfs
cryptonite@cryptonite:~ $sudo unshare --pid --fork --mount /bin/bash
root@cryptonite:/home/cryptonite# mount -t proc proc /proc
root@cryptonite:/home/cryptonite# ps
PID TTY TIME CMD
1 pts/2 00:00:00 bash
9 pts/2 00:00:00 ps
# Либо использовать обертку unshare с флагом --mount-proc,
# что даст аналогичный результат
cryptonite@cryptonite:~ $sudo unshare --fork --pid --mount-proc /bin/bash
root@cryptonite:/home/cryptonite# ps
PID TTY TIME CMD
1 pts/1 00:00:00 bash
8 pts/1 00:00:00 psКак уже говорилось, процесс может иметь несколько ID в зависимости от количества пространств имен, в которых он находится. Далее мы разберем эти разные PID оболочки, вложенные в два пространства имен.
╭cryptonite@cryptonite:~ $sudo unshare --fork --pid --mount-proc /bin/bash
# этот процесс имеет PID 4700 в корневом пространстве имен PID
root@cryptonite:/home/cryptonite# unshare --fork --pid --mount-proc /bin/bash
root@cryptonite:/home/cryptonite# ps
PID TTY TIME CMD
1 pts/1 00:00:00 bash
8 pts/1 00:00:00 ps
# Рассмотрим другие PID
cryptonite@cryptonite:~ $sudo nsenter --target 4700 --pid --mount
cryptonite# ps -aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 18476 4000 pts/0 S 21:11 0:00 /bin/bash
root 9 0.2 0.0 21152 5644 pts/1 S 21:15 0:00 -zsh # me
root 14 0.0 0.0 20972 4636 pts/0 S 21:15 0:00 sudo unshare
root 15 0.0 0.0 16720 520 pts/0 S 21:15 0:00 unshare -fp -
root 11 0.0 0.0 18476 3836 pts/0 S+ 21:15 0:00 /bin/bash # вложенная оболочка
root 24 0.0 0.0 20324 3520 pts/1 R+ 21:15 0:00 ps -aux
# PID, наблюдаемый из первого пространства имен PID, равен 11
# Взглянем на этот PID в корневом пространстве имен PID
cryptonite@cryptonite:~ $ps aux | grep /bin/bash
....
root 13512 0.0 0.0 18476 4036 pts/1 S+ 14:44 0:00 /bin/bash
# поверьте мне, это тот самый процесс ;)
# всю эту информацию можно найти в procfs
cryptonite@cryptonite:~ $cat /proc/13152/status | grep -i NSpid
NSpid: 13512 11 1
# PID в корневом namespace = 13512
# PID в первом вложенном namespace = 11
# pid во втором вложенном namespace = 1Хорошо, рассмотрев виртуализацию в виде идентификаторов, теперь посмотрим, есть ли реальная изоляция в плане взаимодействия с другими процессами ОС.
# процесс запускается с действующим UID=0 (корень) и обычно может kill любой другой процесс в ОС
root@cryptonite:/home/cryptonite# kill 3
# ничего не происходит, потому что в текущем пространстве имен отсутствует процесс 3Мы видим, что процесс не смог взаимодействовать с процессом вне его текущего пространства имен (нельзя взаимодействовать с тем, что не видно, помните?).
Подытожим тему пространств имен процессов:
- процессы внутри пространства имен видят и могут взаимодействовать только с процессами в том же пространстве имен PID (изоляция);
- каждое пространство имен PID имеет собственную нумерацию, начинающуюся с 1;
- эта нумерация уникальна для каждого пространства имен – если PID 1 исчезает, тогда все пространство имен удаляется;
- пространства имен могут вкладываться друг в друга;
- в случае вложения у процесса получается несколько PID;
- Все
ps-подобные команды для реализации своей функциональности используют монтирование виртуальной файловой системыprocfs.
Пространство имен NET
Сетевое пространство имен ограничивает видимость процесса внутри сети. Оно позволяет процессу располагать собственной частью сетевого стека хоста (набором сетевых интерфейсов, хуков Netfilter и правилами маршрутизации). Разберем на примере:
# корневое сетевое пространство имен
cryptonite@cryptonite:~ $ip link # сетевые интерфейсы
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp0s31f6: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN mode DEFAULT group default qlen 1000
link/ether 8c:16:45:54:8b:65 brd ff:ff:ff:ff:ff:ff
.....
cryptonite@cryptonite:~ $ip route # правила маршрутизации
default via 192.168.2.1 dev wlp3s0 proto dhcp metric 600
10.0.0.0/16 via 10.0.1.230 dev tun0 proto static metric 50
....
cryptonite@cryptonite:~ $sudo iptables --list-rules # правила файрвола
-P INPUT ACCEPT
-P FORWARD DROP
-P OUTPUT ACCEPT
-N DOCKER
.....А теперь создадим новое сетевое пространство имен и рассмотрим его сетевой стек.
cryptonite@cryptonite:~ $sudo unshare --net /bin/bash
root@cryptonite:/home/cryptonite# ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
root@cryptonite:/home/cryptonite# ip route
Error: ipv4: FIB table does not exist.
Dump terminated
root@cryptonite:/home/cryptonite# iptables --list-rules
-P INPUT ACCEPT
-P FORWARD ACCEPT
-P OUTPUT ACCEPTЗдесь мы видим, что весь стек процесса изменился. Есть только интерфейс
LOOPBACK, который также не работает. Говоря иначе, этот процесс через данную сеть недостижим. Но ведь это проблема, не так ли? Зачем нам виртуально изолированный сетевой стек, если мы не сможем через него взаимодействовать? Вот, как выглядит эта ситуация:
Поскольку обычно нам нужна возможность так или иначе поддерживать связь с неким процессом, то необходимо обеспечить способ связать разные сетевые пространства имен.
Связывание двух пространств имен
Для того, чтобы сделать процесс внутри нового сетевого пространства имен достижимым из другого аналогичного пространства, нам потребуется пара виртуальных интерфейсов. Эти интерфейсы связаны виртуальным кабелем – то, что поступает на один его конец, передается на другой (подобно конвейеру в Linux). Значит, если мы хотим связать одно пространство имен (назовем его
N1) с другим (назовем его N2), то нужно поместить один из виртуальных интерфейсов в сетевой стек N1, а другой в сетевой стек N2.
Далее мы построим функциональную сеть между разными сетевыми пространствами имен. Здесь важно отметить, что они бывают двух типов – именованные и анонимные, но эту тему мы подробно разбирать не станем. Сначала мы создадим сетевое пространство имен, а затем пару виртуальных интерфейсов:
# создаем сетевое пространство имен
cryptonite@cryptonite:~ $sudo ip netns add netnstest
# проверяем успешность создания
cryptonite@cryptonite:~ $ls /var/run/netns
netnstest
# проверяем, сохранилась ли прежняя конфигурация
cryptonite@cryptonite:~ $sudo nsenter --net=/var/run/netns/netnstest /bin/bash
root@cryptonite:/home/cryptonite# ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# создаем пару виртуальных интерфейсов поверх сетевого стека корневого
# пространства имен
cryptonite@cryptonite:~ $sudo ip link add veth0 type veth peer name ceth0
# проверяем успешность создания пары veth0-ceth0
cryptonite@cryptonite:~ $ip link | tail -n 4
8: ceth0@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether f6:1a:ee:9c:26:0c brd ff:ff:ff:ff:ff:ff
9: veth0@ceth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether ae:4d:95:44:ab:39 brd ff:ff:ff:ff:ff:ff
# помещаем один из интерфейсов в ранее созданное сетевое пространство имен
# а второй конец оставляем в корневом
cryptonite@cryptonite:~ $sudo ip link set ceth0 netns netnstest
cryptonite@cryptonite:~ $ip link
...
9: veth0@if8: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether ae:4d:95:44:ab:39 brd ff:ff:ff:ff:ff:ff link-netns netnstest
# один из интерфейсов исчез
# включаем этот интерфейс и присваиваем ему IP
cryptonite@cryptonite:~ $sudo ip link set veth0 up
cryptonite@cryptonite:~ $sudo ip addr add 172.12.0.11/24 dev veth0
cryptonite@cryptonite:~ $sudo nsenter --net=/var/run/netns/netnstest /bin/bash
root@cryptonite:/home/cryptonite# ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
8: ceth0@if9: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether f6:1a:ee:9c:26:0c brd ff:ff:ff:ff:ff:ff link-netnsid 0
root@cryptonite:/home/cryptonite# ip link set lo up
root@cryptonite:/home/cryptonite# ip link set ceth0 up
root@cryptonite:/home/cryptonite# ip addr add 172.12.0.12/24 dev ceth0
root@cryptonite:/home/cryptonite# ip addr | grep ceth
8: ceth0@if9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
inet 172.12.0.12/24 scope global ceth0Теперь нужно протестировать соединение наших виртуальных интерфейсов.
# внутри корневого пространства имен
cryptonite@cryptonite:~ $ping 172.12.0.12
PING 172.12.0.12 (172.12.0.12) 56(84) bytes of data.
64 bytes from 172.12.0.12: icmp_seq=1 ttl=64 time=0.125 ms
64 bytes from 172.12.0.12: icmp_seq=2 ttl=64 time=0.111 ms
...
# внутри нового сетевого пространства имен
root@cryptonite:/home/cryptonite# tcpdump
17:18:17.534459 IP 172.12.0.11 > 172.12.0.12: ICMP echo request, id 2, seq 1, length 64
17:18:17.534479 IP 172.12.0.12 > 172.12.0.11: ICMP echo reply, id 2, seq 1, length 64
17:18:18.540407 IP 172.12.0.11 > 172.12.0.12: ICMP echo request, id 2, seq 2, length 64
....
# пробуем в обратную сторону
root@cryptonite:/home/cryptonite# ping 172.12.0.11
PING 172.12.0.11 (172.12.0.11) 56(84) bytes of data.
64 bytes from 172.12.0.11: icmp_seq=1 ttl=64 time=0.108 ms
...
# возвращаемся в корневое пространство имен
cryptonite@cryptonite:~ $sudo tcpdump -i veth0
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on veth0, link-type EN10MB (Ethernet), capture size 262144 bytes
17:22:27.999342 IP 172-12-0-12.lightspeed.sgnwmi.sbcglobal.net > 172-12-0-11.lightspeed.sgnwmi.sbcglobal.net: ICMP echo request, id 18572, seq 1, length 64
17:22:27.999417 IP 172-12-0-11.lightspeed.sgnwmi.sbcglobal.net > 172-12-0-12.lightspeed.sgnwmi.sbcglobal.net: ICMP echo reply, id 18572, seq 1, length 64
17:22:29.004480 IP 172-12-0-12.lightspeed.sgnwmi.sbcglobal.net > 172-12-0-11.lightspeed.sgnwmi.sbcglobal.net: ICMP echo request, id 18572, seq 2, length 64Из фрагмента выше видно, как создается новое сетевое пространство имен и подключается к корневому пространству через соединение, подобное конвейеру. Родительское пространство имен один интерфейс оставило себе, а второй передало дочернему пространству имен. Теперь, по аналогии с реальным сетевым соединением, все, что входит в один интерфейс, передается в другой.

Вот мы и разобрались, как изолировать, виртуализировать и соединять сетевые стеки в Linux. Имея подобную возможность виртуализации, логичным следующим шагом будет создание виртуальной LAN между процессами.
Соединение нескольких пространств имен (создание LAN)
Для создания виртуальной LAN мы используем другую утилиту виртуализации – мост. Мост в Linux действует подобно реальному сетевому коммутатору второго уровня – перенаправляет пакеты между подключенными к нему интерфейсами, используя MAC-таблицу.
Перейдем к созданию нашей виртуальной LAN:
# все предыдущие конфигурации были удалены
# создаем пару пространств имен
cryptonite@cryptonite:~ $sudo ip netns add netns_0
cryptonite@cryptonite:~ $sudo ip netns add netns_1
cryptonite@cryptonite:~ $tree /var/run/netns/
/var/run/netns/
├── netns_0
└── netns_1
...
cryptonite@cryptonite:~ $sudo ip link add veth0 type veth peer name ceth0
cryptonite@cryptonite:~ $sudo ip link add veth1 type veth peer name ceth1
cryptonite@cryptonite:~ $sudo ip link set veth1 up
cryptonite@cryptonite:~ $sudo ip link set veth0 up
cryptonite@cryptonite:~ $sudo ip link set ceth0 netns netns_0
cryptonite@cryptonite:~ $sudo ip link set ceth1 netns netns_1
# настраиваем первый подключенный интерфейс -> net_namespace=netns_0
cryptonite@cryptonite:~ $sudo ip netns exec netns_0 ip link set lo up
cryptonite@cryptonite:~ $sudo ip netns exec netns_0 ip link set ceth0 up
cryptonite@cryptonite:~ $sudo ip netns exec netns_0 ip addr add 192.168.1.20/24 dev ceth0
# настраиваем второй подключенный интерфейс -> netns_1
cryptonite@cryptonite:~ $sudo ip netns exec netns_1 ip link set lo up
cryptonite@cryptonite:~ $sudo ip netns exec netns_1 ip link set ceth1 up
cryptonite@cryptonite:~ $sudo ip netns exec netns_1 ip addr add 192.168.1.21/24 dev ceth1
# создаем мост
cryptonite@cryptonite:~ $sudo ip link add name br0 type bridge
# устанавливаем ip для моста и включаем его, чтобы процессы могли связаться через него с LAN
cryptonite@cryptonite:~ $ip addr add 192.168.1.11/24 brd + dev br0
cryptonite@cryptonite:~ $sudo ip link set br0 up
# подключаем концы сетевых пространств имен в корневом пространстве имен к мосту
cryptonite@cryptonite:~ $sudo ip link set veth0 master br0
cryptonite@cryptonite:~ $sudo ip link set veth1 master br0
# проверяем, является ли мост мастером наших двух veth
cryptonite@cryptonite:~ $bridge link show br0
10: veth0@if9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2
12: veth1@if11: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2
# разрешаем перенаправление через мост в корневом сетевом пространстве имен,
# чтобы позволить интерфейсам делать перенаправление между пространствами имен.
# в зависимости от различий в политике iptables этот шаг можно пропустить
cryptonite@cryptonite:~ $iptables -A FORWARD -i br0 -j ACCEPT
# проверяем сетевое соединение netns_1 -> netns_0
cryptonite@cryptonite:~ $sudo ip netns exec netns_1 ping 192.168.1.20
PING 192.168.1.20 (192.168.1.20) 56(84) bytes of data.
64 bytes from 192.168.1.20: icmp_seq=1 ttl=64 time=0.046 ms
...
# проверка подключения root_namespace -> netns_0
cryptonite@cryptonite:~ $ip route
...
192.168.1.0/24 dev br0 proto kernel scope link src 192.168.1.11
...
cryptonite@cryptonite:~ $ping 192.168.1.20
PING 192.168.1.20 (192.168.1.20) 56(84) bytes of data.
64 bytes from 192.168.1.20: icmp_seq=1 ttl=64 time=0.150 ms
...
# проверяем сетевое подключение netns_0 -> netns_1
cryptonite@cryptonite:~ $sudo ip netns exec netns_0 ping 192.168.1.21
PING 192.168.1.21 (192.168.1.21) 56(84) bytes of data.
64 bytes from 192.168.1.21: icmp_seq=1 ttl=64 time=0.040 ms
...Все работает! Здесь важно то, что виртуальный интерфейс должен выдавать разрешения на перенаправление пакетов в текущем сетевом стеке. Для избежания заморочек с правилами
iptables можно повторить эту процедуру в отдельном сетевом пространстве имен, где таблица правил будет пуста по умолчанию. Теперь давайте подключим нашу LAN к интернету!Связь с внешним миром
Мы присвоили нашему мосту IP и теперь можем пинговать его из сетевых пространств имен.
# попытка связи с интернетом
cryptonite@cryptonite:~ $sudo ip netns exec netns_1 ping 8.8.8.8
ping: connect: Network is unreachable
cryptonite@cryptonite:~ $sudo ip netns exec netns_1 ip route
192.168.1.0/24 dev veth1 proto kernel scope link src 192.168.1.21
# маршрут для интерфейса хоста отсутствует -> мост находится на уровне 2 =>
# отсутствует разрешение ARP и межсетевое взаимодействие.
# Можно сделать этот мост предустановленным шлюзом для обоих пространств имен
# и позволить ему перенаправлять весь трафик в вышестоящее сетевое пространство имен
cryptonite@cryptonite:~ $sudo ip -all netns exec ip route add default via 192.168.1.11
# Все ли прошло гладко?
cryptonite@cryptonite:~ $sudo ip -all netns exec ip route
netns: netns_1
default via 192.168.1.11 dev ceth1
192.168.1.0/24 dev ceth1 proto kernel scope link src 192.168.1.21
netns: netns_0
default via 192.168.1.11 dev ceth0
192.168.1.0/24 dev ceth0 proto kernel scope link src 192.168.1.20
# Пробуем еще раз
cryptonite@cryptonite:~ $ip netns exec netns_0 ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
^C
--- 8.8.8.8 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, ...
# И последнее -> внешний мир не знает о нашей LAN, равно как и хост, поэтому нужно
# добавить еще одно правило
cryptonite@cryptonite:~ $iptables -t nat -A POSTROUTING -s 192.168.1.0/24 -j MASQUERADE
cryptonite@cryptonite:~ $sudo ip netns exec netns_0 ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=61 time=11.5 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=61 time=12.5 ms
...Обратите внимание, что правила
iptables хоста должны быть грамотно настроены, так как неудачная конфигурация может привести к проблемам. Кроме того, без маскарадинга пакеты будут покидать хост с его внутренним IP-адресом, который известен только самому хосту, шлюз его LAN не знает, как присоединиться к сетевому мосту. Подытожим о сетевых пространствах имен:
- Процессы внутри определенного сетевого пространства имен получают собственный закрытый сетевой стек, включая сетевые интерфейсы, таблицы маршрутов, правила
iptables, сокеты (ss,netstat); - Соединение между сетевыми пространствами имен можно реализовать с помощью двух виртуальных интерфейсов;
- Взаимодействие между изолированными сетевыми стеками в одном пространстве имен реализуется с помощью моста;
- Пространство имен NET можно использовать для симуляции «ящика» процессов Linux, когда только несколько из них смогут связываться с внешним миром (для этого нужно будет удалить предустановленный шлюз хоста из правил маршрутизации некоторых пространств имен NET).
Сделаем перерыв
В этой статье мы разобрали несколько типов пространств имен. С остальными же мы познакомимся во второй части:
- USER: служит для отображения UID/GID, позволяя иметь в текущем пространстве имен несколько корневых пользователей.
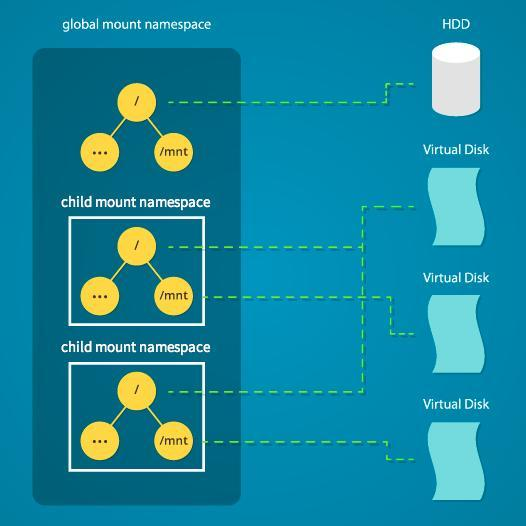
- MNT: используется для создания файловых систем под конкретные процессы.
- UTS: позволяет изолировать имя хоста системы.
- IPC: предоставляет возможность изоляции семафоров, очередей сообщений, разделяемой памяти и т.д.
- CGROUP: позволяет контролировать доступ к аппаратным ресурсам для каждого процесса.
В результате вы узнаете почти всю основную информацию о пространствах имен и сможете создавать собственные контейнеры или полностью изолированные среды для конкретных процессов.
Ссылки
- www.toptal.com/linux/separation-anxiety-isolating-your-system-with-linux-namespaces
- lwn.net/Articles/259217
- www.redhat.com/sysadmin/pid-namespace
- byteplumbing.net/2018/01/inspecting-docker-container-network-traffic
- opensource.com/article/19/10/namespaces-and-containers-linux
- iximiuz.com/en/posts/container-networking-is-simple
- ops.tips/blog/using-network-namespaces-and-bridge-to-isolate-servers
- www.cloudsavvyit.com/742/what-are-linux-namespaces-and-what-are-they-used-for
- lwn.net/Articles/532593
- lwn.net/Articles/689856
- www.redhat.com/sysadmin/7-linux-namespaces
- www.redhat.com/sysadmin/mount-namespaces
- ifeanyi.co/posts/linux-namespaces-part-3

Комментарии (3)

hogstaberg
30.11.2021 12:415.7 как бы и не свежее, но в реальном мире вполне околоактуальное для всяких шляпопроизводных дистрибутивов, поэтому причины писать про эту версию я представляю. А вот полное игнорирование time namespace с углубленным знакомством как-то не очень стыкуется. Причём в самой статье в примере содержимого /proc//ns есть time namespace, но эта строчка автора почему-то не заставила призадуматься.

XFNeo
02.12.2021 17:27+1Подскажите зачем создавать veth в рутовом NS, почему нельзя сразу соединить адаптер контейнера с бриджем?
amarao
5.7 такая свежая... А где time namespace?