
Привет, меня зовут Всеволод, я разработчик в Мир Plat.Form.
Хочу рассказать о том, как можно делать непрерывную поставку кода «снизу»: как это делали мы при разработке платежных сервисов, и какие ошибки при этом совершили.
Наша команда ведет несколько значимых ИТ-проектов: обеспечивает бесперебойность и доступность операций по картам всех международных платежных систем в России, а также платежной системы «Мир». А еще мы являемся технологическим «двигателем» для Системы быстрых платежей (СБП).
Оглавление
О команде и процессе разработки
Я работаю в одной из команд Мир Plat.Form, пишем на java и kotlin микросервисы для одной из наших систем.
Работаем по Large Scale Scrum (LeSS):
1 общий Бэклог Продукта
1 Владелец Продукта
4 мультифункциональные фиче-команды (на момент публикации уже 5 команд)
Также у нас есть команда сопровождения, которая осуществляет развёртывание, поддержку, мониторинг и решение инцидентов в продуктивной среде.
Процесс релиза
У нас более 50 микросервисов. Релиз может содержать изменения нескольких микросервисов.
В среднем задача (product backlog item) порождает 1 релиз. Так как у нас 4 фиче-команды, то у нас за один спринт готово до 4 релизов. В среднем за последние 3 месяца у нас 3.25 релиза в спринт (2 недели).
Релизы устанавливаются на прод независимо.
Работа над задачей выглядит приблизительно так:
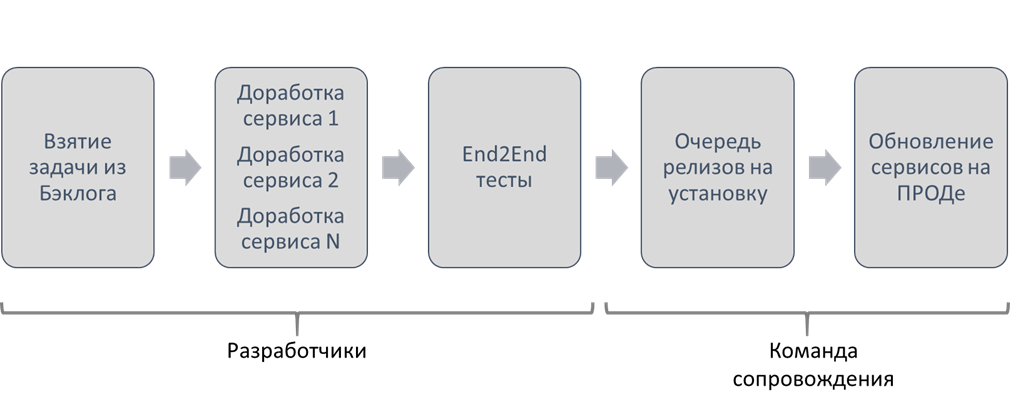
На планировании спринта фиче-команда берет из Бэклога задачу.
Разработчики изменяют код в одном или нескольких сервисах
Разработчики дорабатывают end2end тесты, запускают их
-
Команда сопровождения заводит заявку на обновление ПО(релиз), заранее определяя дату работ исходя из:
Размера очереди релизов, ожидающих установки
Загруженности команды сопровождения
Доступных для релиза временных окон(желательно не обновлять ПО во время больших инфраструктурных работ)
Команда сопровождения обновляет сервисы на проде
Отметим, что мы не считаем текущее состояние идеальным. Наша цель – автоматизированные безопасные релизы, которые устанавливаются на прод силами разработчиков с помощью «большой зеленой кнопки».
Проблема: долгий релизный цикл
И, возможно, всех бы устраивал процесс релиза, если бы не занимал в среднем 20 дней. При этом такая длительность не меняется уже в течение года.
Такой срок поставки кода не комфортен – если появился баг, который нужно срочно поправить, то не получится поправить его быстро.

Решение «в лоб»
Как ускорить поставку кода?
Это простой вопрос для каждого, но сложный вопрос для коллектива:
кто-то скажет, что нужно установить дженкинс
кто-то – переписать скрипты деплоя
кто-то – нужно считать метрики DORA
кто-то – нужно ускорить end2end тесты
Можно еще скопировать передовые практики в сфере DevOps. Например, прочесть книгу Continuous Delivery и применить все рекомендации.
При этом мы можем делать правильные вещи в неправильном порядке.
Пример:
В Стив Смит докладе "Continuous Delivery and the Theory of Constraints" описывает, как его коллектив поставил себе цель уменьшить время поставки новой строчки кода до прода с 30 дней до 14. В 2 раза, амбициозная цель!
Большой коллектив работал над улучшениями полгода, однако получилось ускорить всего лишь до 28 дней. Жалкие 6 %!
Стив Смит объясняет это тем, что они ускоряли неподходящий участок конвейера поставки кода: он и без улучшения был значительно быстрее другого участка.
Затем упоминает, что есть еще теории ограничений, которая может помочь. Рассмотрим ее детально.
Решение: теория ограничений
Область применения ТОС
Теория ограничений (theory of constraints, TOC) – набор практик, нацеленных на увеличение прибыльности производств, схожих с конвейером: продукт проходит несколько стадий обработки и лишь после этого готов к продаже покупателю.
Ранее мы описали процесс поставки кода у нас – он же крайне похож на конвейер! Какая удача! Рассмотрим этот инструмент подробнее.
Что такое TOC?
Упрощенно теория ограничений состоит из нескольких частей:
Пять фокусирующих шагов: алгоритм поиска и устранения «ограничений»
Мыслительные процессы: рекомендации по построению и проверке логических цепочек
Принятие управленческих решений на основе метрик потока, а не метрик материальных запасов
Пять фокусирующих шагов
Рассмотрим «Пять фокусирующих шагов» подробнее.
Техника «Пять фокусирующих шагов» отвечает на вопрос «как увеличить пропускную способность конвейера?».
Попробуем без подсказок ускорить работу вымышленного конвейера.

Предположим, что отдельные участки конвейера работают с разной скоростью. И есть участок, работающий с наименьшей скоростью.

Проведем мысленный эксперимент:
Ускорим участок конвейера «слева» от самого слабого – тогда перед самым слабым участком будет увеличиваться очередь незавершенной работы. Но общая пропускная способность не изменится.
Ускорим участок конвейера «справа» от самого слабого – увеличенная мощность участка будет простаивать, ведь самый слабый участок и раньше не мог загрузить участок «справа» на 100%. Опять общая пропускная способность не изменится.
Следствие: любые попытки ускорить конвейер не в самом узком месте – пустая трата ресурсов.
Вернемся к технике «Пять фокусирующих шагов».
Будем называть ранее упомянутый участок, работающий с наименьшей скоростью, ограничением.
Тогда алгоритм увеличения пропускной способности конвейера будет выглядеть так:

Найти ограничение
Оптимизировать ограничение – до того, как «покупать более производительные станки», стоит поискать способ более полного использования уже существующих. Придумать изменения, которые увеличат производительность «ограничения» без использования дополнительных ресурсов.
Подчинить ограничению работу всей системы – все остальные участки конвейера работают так, чтобы максимизировать не свою производительность, а производительность «ограничения».
Расширить ограничение – если предыдущие шаги не дали достаточного эффекта, то найти способ увеличения производительности уже с привлечением дополнительных ресурсов
Повторить цикл. После того как мы исправили существующее ограничение, уже другой участок ограничивает пропускную способность конвейера.
Применение TOC для процесса поставки кода
Начинаем поиск «ограничения» в конвейере доставки кода.

Сначала мы в экселе разметили старые релизы, чтобы понять, как выглядит стандартный релиз – есть ли изменения базы данных, какие из сервисов меняются…
Затем создали в джире новый набор статусов (dev -> e2e тесты -> ожидание установки на прод -> обновление сервисов на проде) и вручную меняли статус задачи при прохождении каждого этапа. Нашего терпения хватило на 4 релиза, но и этого оказалось достаточно, чтобы понять общую картину – самым долгим этапом является ожидание релиза в очереди на установку.

Мы долго пытались понять, почему же ожидание установки релиза такое долгое: несколько раз брали интервью у команды сопровождения , рисовали «дерево текущей реальности» (методика из "мыслительных процессов" теории ограничений). И, наконец, смогли найти ответ на вопрос.

Оказалось, что у нас три причины, действующие одновременно:
Очередь релизов в последний день спринта
Чаще всего все 4 команды подготавливают релиз в последний день спринта. Наверное, это связано с размером задач: если задача большая, то мы либо не успеваем ее сделать за спринт, либо заканчиваем в последний момент.20 из 26 релизов нужно устанавливать ночью
У нас есть один важный сервис, который «хрупкий»: его обновления устанавливают по ночам. И 20 из 26 релизов содержат изменения этого сервисаНе каждую ночь можно делать релиз
Очевидно, что не стоит делать релиз по пятницам, в праздники, предпраздники, выходные, во время инфраструктурных работ. Кроме того, о ночном выходе нужно уведомлять сотрудника заранее
Мы решили, что надо решать проблему «20 из 26 релизов нужно устанавливать ночью» – надо всего лишь адаптировать архитектуру «хрупкого» сервиса для безопасного деплоя. Заодно можно и код написать)

Но есть небольшой нюанс – сервис большой, сложный, важный и высоконагруженный, поэтому сходу такую задачу не решить. Нужно какое-то предварительное обсуждение.
Подходящим местом обсуждения является архитектурное сообщество (кружок) – каждые 2 недели мы коллективом обсуждаем идеи изменения архитектуры, которые затем превращаются в элементы беклога. Подробнее об этой практике координации - LeSS Сообщества.
Идея отправилась в архитектурное сообщество.
Провал
Идея отправилась в архитектурное сообщество (в середине мая), однако спустя полгода (декабрь) ее так и не обсудили. Хотя встречи проходят каждый спринт (2 недели).

Стоит отметить, что архитектурный кружок делает много важных вещей: решает, как реализовывать новый функционал, как решать проблемы нагрузки, как менять существующую архитектуру, чтобы решить завтрашние проблемы...
Однако, тот факт, что идея, которая может кратно увеличить скорость поставки кода, затерялась в списке будущих улучшений, вызывает бурю эмоций:
Бессилие, грусть, тоска
Никто не любит девопс, кроме меня!
Никто не читает книги по девопс!
Все неучи, а я Д’Артаньян!
Провал, это конечно, грустно, но как надо было делать?
На старте предполагалось, что самое сложное в подобном – показать Владельцу Продукта ценность от выполнения технической задачи, и понять, как будем мерить результат еще до старта работы по задаче. Однако оказалось, что убедить коллег в ценности подобного улучшения тоже важно.
Попробуем понять, почему у нас не получилось применить теорию ограничений.
Ошибка 1 – Не следовали алгоритму «5 фокусирующих шагов»
Если посмотреть на алгоритм улучшения (5 фокусирующих шагов), то можно заметить, что мы, возможно, пропустили шаг «подчинить систему ограничению» и сразу перешли к шагу расширения.

Кроме того, возможно, мы нашли не самое простое решение проблемы, а довольно трудоемкое – нужно заново обдумать архитектуру и написать какое-то количество кода. Вместо этого, например, можно было повлиять на «Очередь релизов в конце спринта» - уменьшить длину спринта
О шаге «подчинить систему ограничению» можно думать, как о проверке бизнес-гипотез – мы допускаем, что наше предположение о местонахождении ограничения может быть неверным, поэтому проводим небольшое изменение, не требующее ресурсов:
если пропускная способность конвейера увеличилась, то мы нашли ограничение.
если пропускная способность не изменилась, то мы ошиблись и ограничение находится в другом месте конвейера.
Соответственно, если результатов шага «подчинить систему ограничению» будет недостаточно, то шаг «расширение ограничения», требующий инвестиций, уже не будет «прыжком веры».
Ошибка 2 – Механистическое понимание ТОС
Мы применили «наивную теорию ограничений» - использовали только алгоритм улучшения (5 фокусирующих шагов) и «мыслительный процессы теории ограничений». Но, оказывается, в теории ограничений есть и кое-что ещё: в книге Theory of Constraints by Eliyahu Goldratt упоминается несколько сложностей при попытке начать организационные изменения: сопротивление изменениям, утверждения вроде «это не моя проблема».
И как один из основных способов справиться с этим Голдрат предлагает использовать «сократовский метод» убеждения – не говорить людям как решить проблему, а задавать вопросы, размышления над которыми, приведут к пониманию решения проблемы. Тем самым вы делаете собеседника соавтором идеи, а соавтор идеи вряд ли будет сопротивляться реализации своего творения.
Таким образом, диалоги Ионы и Алекса (героев книги «Цель») – это не только художественный прием, но и иллюстрация применения «сократовского метода».
Ошибка 3 – Выход из зоны применимости TOC
Возможно, мы вышли из зоны применимости ТОС.
С одной стороны, будучи руководителем, наверное, можно задавать вопросы, следуя «сократовскому методу», своим подчиненным (которые не могут убежать), но что делать простым программистам?
Планы
Мы живем в рамках плоской организационной структуры LeSS, поэтому работа выполняется с большой степенью прозрачности, что подсвечивает проблемы, которые в иерархичной структуре были бы незаметны.
Например, в иерархичной структуре некий техлид мог бы «протащить» решение проблемы «20 из 26 релизов нужно устанавливать ночью», не убеждая в пользе такой доработки. Но сколько было бы задач, улучшающих состояние всей системы, а не улучшающих выполнение KPI конкретного человека/отдела? Даже если и большая часть, то, как бы определялось в каком порядке делать такие технические улучшение? Ведь порядок выполнения задач тоже имеет значение – как отмечалось в начале статьи «мы можем делать правильные вещи в неправильном порядке».
Поэтому несмотря на неудачу, мы продолжаем искать пути ускорения поставки. Если у вас есть идеи – пишите в комментариях)
Выученные уроки
Теория ограничений – инструмент, позволяющий проводить ускорение поставки кода итеративным способом без больших трат ресурсов, благодаря акценту на мысленных и производственных экспериментах.
При применении можно легко ошибиться – неверно интерпретировать алгоритм «5 фокусирующих шагов».
Минусы теории ограничений – она ориентирована на формальное лидерство, так как из инструментов убеждения/доказательства необходимости изменений предлагает лишь «сократовский метод».
Ссылки
-
Теория ограничений
Про "мыслительные процессы" теории ограничений: Теория ограничений Голдратта. Системный подход к непрерывному совершенствованию
-
Теория ограничений в IT
Комментарии (9)

Sergey-Titkov
02.12.2021 18:15+2В ТОС есть три метрики: скорость генерации дохода, накладные расходы и связанный капитал. Все ваши действия должны влиять на них выгодным образом.
Смотрим на вашу проблему:Проблема: долгий релизный цикл
И, возможно, всех бы устраивал процесс релиза, если бы не занимал в среднем 20 дней. При этом такая длительность не меняется уже в течение года.
Такой срок поставки кода не комфортен – если появился баг, который нужно срочно поправить, то не получится поправить его быстро.
Как ваша проблема соотноситься с метриками ТОС? Окей, ваш релизный цикл стал 15 дней? Денег больше заработали? Да? А если нет, то и начинать не надо, это уже потери.
Не корректно искали узкое место, ТОС работает со всей цепочкой поставки ценности. А у вас только хвост: dev -> e2e тесты -> ожидание установки на прод -> обновление сервисовё1 на проде. Так, что то что вы делали может быть субоптимизацией.
На пошатать: 20 из 26 релизов содержат изменения этого сервиса. Вопрос, почему если в очереди несколько релизов одного и того же сервиса их нельзя схлопнуть в один.

wilyrussian
02.12.2021 20:12+1Спасибо, что делитесь применением ТОС! Особенно в IT).
Коллега @Sergey-Titkov верно подметил, что это может быть субоптимизация time-to-market.
Но если это оставить чуть в стороне, и сказать, что ваша идея в этой конкретной реализации корректна, то к проблеме ускорения протаскивания техдолга можно тоже подойти системно).
Внизу ссылка на статью, в которой техдолг упаковывают в бизнес ценность.
Как вариант - добить анализ потерь до начала цепочки, чтобы была полная карта потерь в time-to-market, упаковать в бизнес-ценность, посчитав на языке бизнеса value. Если это value нашли, идем дальше.
Список таких доработок (там может быть еще пара actionitem'ов) упаковываем уже вместе с бэклогом - ценность описана на языке бизнеса же - ускорение поставки ценности на ХХ% с ХХ дней до УУ дней - и будете вы не писать патч на хрустальный сервис, а добиваться ускорения (патч писать придется тоже, но вы не остановитесь на том, что выпустили патч и вы молодцы - команда, взявшая фичу будет должна убедиться в общем ускорении и это в разы важнее выкатки патча - потому что вы еще должны будете переделать правила выкатки релиза и тд).
Если вы используете ICE/RICE/WSJF и тд, то тут же взвешиваете и она сама всплывает где надо. Если сложно менять общие подходы и в бэклоге она будет внизу - то ОК - бизнес решил что это здесь и сейчас не важно. Еще один элемент - управление рисками - если такая штука есть, то можно добавить это как риск и оценить его степень.
Еще момент. Даже в рамках архит.комитета оказалось, что это не так и важно раз за полгода не дошли - следовательно, ценность для разработчиков этого не так велика, им скорее болит распил очередного монолита или как легаси конвейер переделать на кафку). Поэтому разработка не лоббировала снизу эту доработку), там, где у них реально болит - они обязательно будут вспоминать и проталкивать в бэклог.
Итого: две гипотезы почему застряли).
1) до бизнеса не донесли реальную ценность и оценку сложности реализации
2) боль для разработки от этого мала, как следствие задачу положили не в "тот" бэклог).
Можно: вернуться в начало и оценить реальную пользу для бизнеса и тащить, упаковав в бизнес-фичу. Тогда и архит. проработка включится в работу в обычном режиме - не надо будет ждать архит.комитета. архит.комитет (или просто команда) по идее и так уже разложил боль до некоего решения, которое и надо тащить в бэклог.
Техдолг. Все говорят: «невозможно», а я говорю, что буду
https://habr.com/ru/company/oleg-bunin/blog/480636/

dTex
02.12.2021 22:06У них там в ТОС ещё метод критической цепи есть для управления проектами, но как-то мало про это все это слышно, agile больше в моде.
Суть теории ограничений в том, чтобы найти где текущее узкое место системы с точки зрения ее Цели и оптимизировать остальную часть под это узкое место, чтобы использовать его максимально эффективно и по возможности компенсировать недостатки узкого звена за счет доступного запаса других звеньев. Узкое звено выдает себя по переизбытку чего-то перед ним - переизбыток сырья на складе, переизбыток заготовок, переизбыток товара и т.д. Этот переизбыток порождает целую серию негативных явлений, с которыми система вынуждена бороться, тратя ресурсы. У вас по всей видимости переизбыток релизов. Тут надо спросить - а на самом деле их нужно столько? Что запускает начало процесса, который заканчивается релизом и сколько стоит этот процесс? Зачем 4 команды выпускают релизы одновременно? Что включает понятие "ночь", ведь маловероятно, что вы можете обновляться только, когда не светит Солнце, правильная причина скорее всего звучит - обновление возможно, только когда нагрузка на соответствующий сервис минимальна, может там разные промежутки времени для разных сервисов.
Команда не оценила ваше предложение? Возможно система оценки их работы выстроена так, что они не могут не глушить систему релизами. Знаете - идет директор и видит что работник не пилит доски, и такой ах почему не работаешь, в итоге работник пилит доски на разные размеры, но не по заданию отдела сбыта, а на глазок, в итоге часть досок продается, а часть нет и уходит в запасы, которые не факт что продадутся.

mixsture
02.12.2021 23:28+1Имхо, ТОС рассчитана только на владельцев бизнеса. Исключительно. В книгах Голдрата то у них была угроза закрытия завода — это ж как раз требование владельца бизнеса. А вы пытаетесь идеи уровня целой фирмы предложить разработчикам.
А для них это не ценно. И не должно быть ценно. У них свои метрики — кстати говоря, похожие на объем производства каждого узла.
Вот почему проблемы уровня фирмы в книге голдратта стали проблемами каждого сотрудника? Да потому что завод закроют = всех на улицу выбросят. А без этого попытка представить идеи сотрудникам завершилась бы с таким же результатом, как у вас.
Поэтому работайте с владельцем бизнеса. Если ему это действительно не интересно — ок, займитесь чем-нибудь другим.

sbase
03.12.2021 10:47Оба-на, подскаст со мной! Рад что еще кто-то заинтересовался ТОС.
О шагах:
Если быть более точным, то второй шаг "РЕШИТЬ, как максимизировать работу ограничения" - "Decide how to EXPLOIT the system's constraint(s)." - в словаре TOCICO.
О внедрении:
Пять направляющих шагов простые, НО это это только кажется. Чтобы внедрить найденное решение необходимо пройти по всем слоям сопротивления. То есть как минимум:
1. Отсечь негативные ветви (см Дерево будущей реальности)
2. Выявить препятствия и найти промежуточные цели для преодоления препятствий (см. Дерево перехода aka "prerequisite tree")О границах применимости:
Из роли разработчика тоже можно менять систему. И для этого у вас есть Ретроспектива спринта. И я уверен, что есть даже кросс-командная Ретроспектива. Ретроспектива - Это основная точка изменений в компании. Это основная точка убеждения в том, что проблема существует. Если "клиент" не принял что "проблема существует", то любые изменения утонут.
О Методе критической цепи для ИТ-проектовЯ уже начинал цикл статей о Методе (читать отсюда https://habr.com/ru/post/462423/ )
Сейчас вышла книга "Управление проектным бизнесом" https://ridero.ru/books/upravlenie_proektnym_biznesom/ о том как скрестить Agile с Методом Критической Цепи так, чтобы это работало. В принципе Метод будет также хорошо работать и для LeSS команд и для управления конфигурацией, потому как планирование с применением "дерева предпосылок" обеспечивает выстраивание всей работы команд и зависимостей.
О метриках ТОС:
Для ИТ-компании связанный капитал и операционные затраты величины постоянные. На Проход внутри ИТ-отдела влияние небольшое, поэтому единственное что остается: "Скорость генерации единиц цели".
В 5 направляющих шагах есть еще 2:
-1 Шаг: Определить границы системы
0 Шаг: Определить цель системы.Если Цель системы - выкатывать больше изменений в единицу времени - то это хорошая тема для обсуждения. (Но так ли это?)
Sergey-Titkov
03.12.2021 20:56Для ИТ-компании связанный капитал и операционные затраты величины постоянные.
Для энтерпрайза это не так. Классический пример, у нас все было плохо, и что бы держать канарейку нам нужно 100 серверов. Мы пошли в инфраструктуру как код, и на выходе получили ту же канарейку но с быстрым развертыванием и уже 50 серверов.

GooG2e
03.12.2021 14:19Возможно я не до конца что-то понимаю в крутой enterprise разработке, но по тому что вы написали напрашивается как минимум одно решение, которое не затрагивает архитектуру вашего основного сервиса - пусть у фиче команд спринты будут заканчиваться в разные дни, тогда очередь не будет возникать или будет возникать, но в намного меньших объёмах. При этом на старте спринта вполне можно предположить будет ли затрагиваться это важный сервис.
filatovanton16
Автору респект!
Побольше бы таких статей:)