
Сделать хорошее аналитическое хранилище (DWH), когда в команде десяток-другой крутых специалистов и пара лет времени — не сложно. Проекты по созданию DWH, Data Lake и BI обычно очень ресурсоёмки и под силу только большим компаниям.
Мне интересно искать и применять практики, которые позволяют компаниям быстро создавать аналитические решения маленькой командой. Этими наработками хочу поделиться в данной статье.
Статья нацелена на:
- Небольшие команды в начале пути.
- Создание решений с быстрым возвратом инвестиций.
Коротко о моём DWH опыте (чтобы понимать ограничения моего мышления):
- Реализовывал три похожих не очень больших проекта по созданию DWH: 5-15 терабайт, 100+ сущностей, в команде 2-4 специалиста, в качестве источника — одна основная база продукта (сервиса) и несколько дополнительных.
- Участвовал в супер большом проекте DWH: 1+ Петабайт (прирост 1 терабайт в день), 2000+ сущностей, в команде 100+ специалистов. В этой компании жадно изучал Data Vault 2, исходники DWH движка, бизнес-процессы, которые масштабируются на сотни специалистов, правила описания DWH в вики и методы постановки задач.
- В продакшн работал только с batch процессами, со stream знаком только по обучающим курсам и книгам.
Ценность для бизнеса
Цепочка создания ценности в процессе работы с данными (источник):
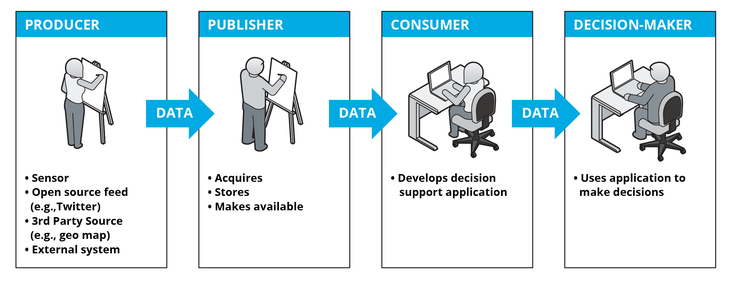
Ценность создается только на последнем шаге цепочки. Вы можете извлекать данные, обрабатывать их как угодно: чистить, обогащать, маршрутизировать по системам, накапливать в хранилищах, заливать в витрины и т.д. Все эти операции ценности никакой не приносят.
Ценность создается при принятии правильных решений. Поэтому, мне кажется, в начале пути нужно как можно быстрее научиться получать профит из данных и DWH, а затем постепенно улучшать модели данных и процессы разработки DWH.
Сейчас часто собирается всё что можно собрать в озеро, а на втором этапе начинается детальная проработка результирующих витрин. Считаю, что нужно мыслить от показателей к источникам данных, а не наоборот. Чем лучше вы проработаете показатели необходимые для анализа, разрезы в которых нужно анализировать показатели, тем меньше работы будет у дата инженеров (DE), а значит вы быстрее получите нужный результат.

Подробнее на эту тему: Six Things You Need to Know About Data Governance, также в этой статье есть хороший раздел “Продуктовый подход к DWH” о том, какие вопросы нужно задавать пользователям при создании витрин.
Сначала логика и архитектура, потом инструменты
Часто на презентациях я вижу картинки наподобие этой →
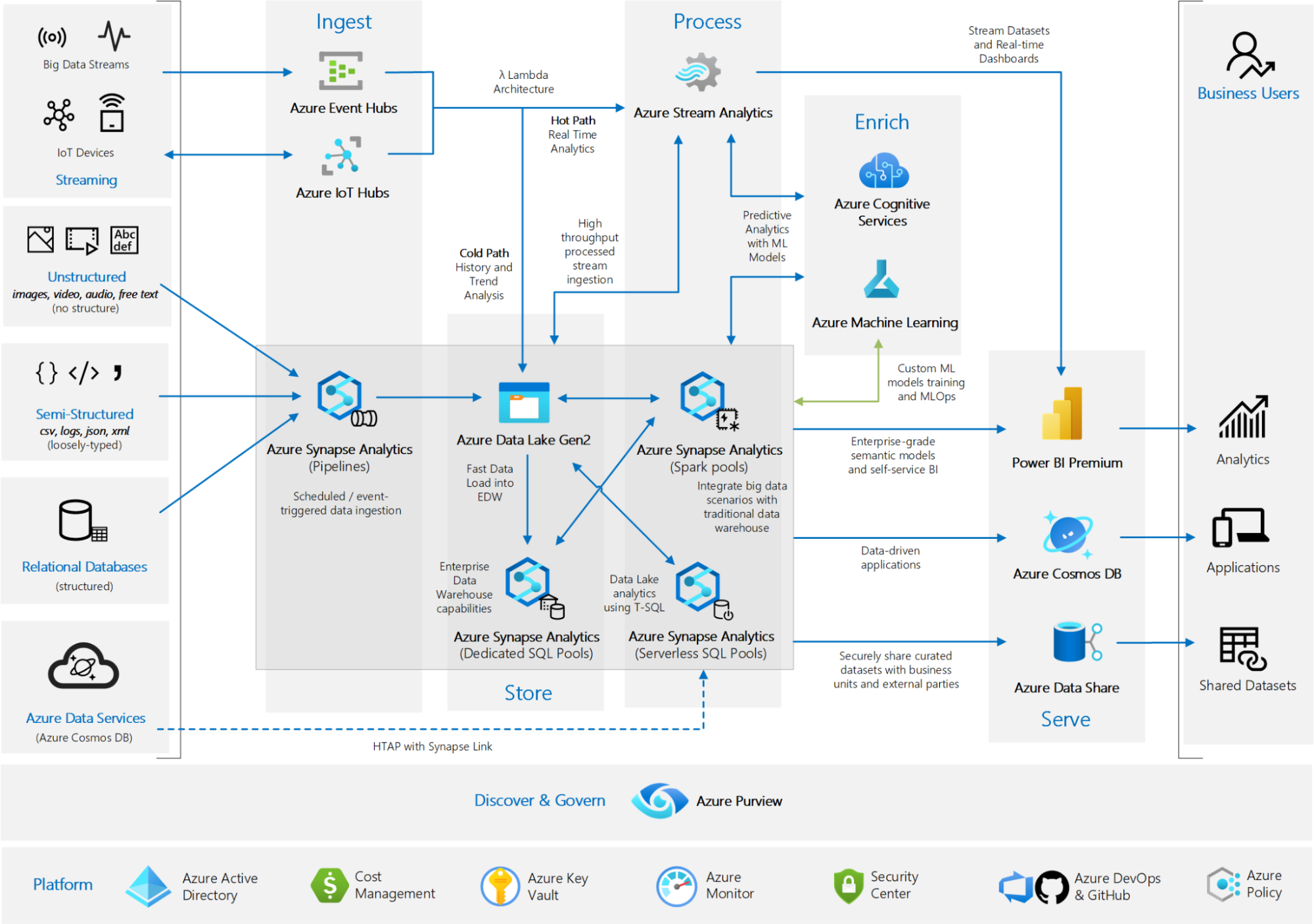
Важно помнить, что инструменты не дают методологии. Использование всего самого современного без проектирования увеличивает расходы и сложность системы.
Поэтому один из моих базовых принципов — сначала логика и архитектура, а потом инструменты. Именно логике построения DWH посвящена статья.
Основы логики и архитектуры DWH
Загрузить данные из источника А в результирующую таблицу (таргет) Б легко, но это нужно будет проделать для сотен таблиц: в стриминге и батче, инкрементами и полностью, с зависимостью одних таблиц от других, на тестовом и прод серверах и т.д. Таким образом, есть куча опций и если их не систематизировать, то скрипты загрузки DWH превратятся в страшный сон.
Поэтому, первая ключевая роль в создании DWH — архитектор, человек, который умеет думать и систематизировать. Через единообразие кода и правил нужно стремиться упростить жизнь DE. Большую часть времени DE должен тратить на создание продукта из данных.
Все типовые задачи должны быть автоматизированы:
- Подрезка (фильтрация) таблиц в источниках при получении инкремента.
- Типы загрузки таргета: append, upsert, full (snapshot), scd2, recreate.
- Типы таргетов: ods, mart, scd2, data vault сущности.
Важно:
- Четко определить, что такое Джоб.
- Иметь возможность отлаживать любую джобу/расчет локально.
- Если есть ресурсы хранить “сырые данные” и историю их изменений, это упрощает исторические перерасчеты.
Обязательно нужно разделить роли Бизнес-аналитика и DE. Аналитик понимает что хочет бизнес и где примерно находятся данные, а также описывает в вики какие данные должны быть в таргете. DE понимает как это сделать.
В начале Архитектором и DE может быть одно лицо, но аналитик совершенно точно должен быть другим человеком.
Джоба — основной кирпич системы. Джоба должна быть четко определена и проста.
Как лучше не делать джобы
Джобы изменяющие много таблиц DWH — это плохо:
- Большие джобы работают долго, а значит у вас меньше возможностей для маневров.
- При падении джобы её придется перезапускать полностью.
- Трудно дорабатывать джобу.
- Трудно развивать DWH.
Инструменты, которые заменяют SQL рисованием: SAS Data Integration Studio,
Informatica, Pentaho — почти всегда плохо:
- Частично или полностью недоступен Git: сравнение, слияние, версионность джобов и т.д.
- Ограничения на автогенерацию.
- Вендор-лок.
Первый принцип создания джоб (DAG’ов)
Одна джоба загружает один таргет (таблицу).
Преимущества:
- Простой перезапуск или пропуск упавших джобов.
- Разделяй и властвуй — зная входные таблицы и таргет, легко управлять порядком и параллельностью запуска джобов.
Этот принцип позволяет создавать действительно масштабируемые DWH, позволяя постепенно увеличивать число таблиц, слоев и DE.
Cколько джобов нужно для получения результата, полезного для бизнеса, зависит от числа слоев вашего DWH.
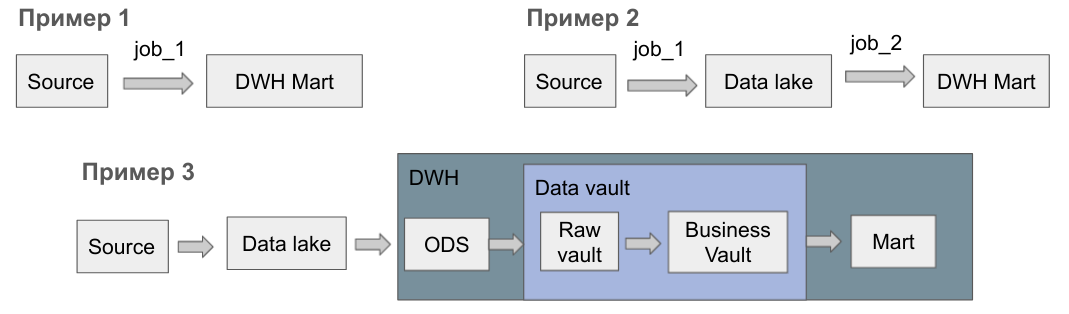
Пример 1. Данные из источника попадают сразу в витрину DWH, т.е. для одного таргета нужна одна джоба. Дополнительные слои не дают ценности бизнесу, поэтому для начала я рекомендую делать именно так. Разработка такой джобы займет не больше дня.
Пример 2. Данные из источников сначала складируются в озере данных. Такой подход лучше масштабируется по данным и разработчикам, однако разработка пары джоб в такой модели займет уже 2-3 дня.
Пример 3. Если делать всё правильно по популярной методологии Data Vault 2.0, то первого полезного результата можно ждать несколько недель. Мощь Data Vault 2.0 в том, что он позволяет прозрачно масштабировать DWH на любое число таблиц и DE.
С возрастанием числа источников, таблиц в DWH и DE нужно двигаться от примера 1 к 3.
Второй принцип создания джоб (DAG’ов)
Джоба — это не визуальная схема, а код (мини-проект), к которому применимы все типичные для кода манипуляции: Git, CI/CD, автотестирование и т.д.
Джоба — это папка, в которой хранятся скрипты и файл с инструкциями для исполнителя джобов. В случае смены сервера-источника или таргет-сервера в папке должно быть достаточно информации, чтоб перенакатить таблицы и запустить джоб.
Как сделано у нас:
В репозитории джоб называется по маске schema.table таргет таблицы
В каждой папке 3+ файла:
- job.py – инструкции исполнителю.
- getdata.sql – получение данных.
- recreate.sql – пересоздание таргета.
Аналитик или DE делают джобу и отлаживают локально, затем делают merge request, после проверки и одобрения другим спецом CI/CD отправляют джобу в прод.
Исполнитель джобы
Когда приходит очередь выполнить определенный джоб, запускается команда
launcher.run_job(job_name='marts.crm_bill', method='increment')
Исполнитель джобы читает файл job.py из папки marts.crm_bill. Получает объект класса JobDag, и дальше выполняет задачи из него. Поскольку одна джоба загружает один таргет, все джобы маленькие – от одного до пяти шагов.
Пример файла job.py с одной задачей:
from job_launcher_package import job_module
def get_job_dag() -> job_module.JobDag():
j = job_module.JobDag()
params = {
"connection": "dwh_main",
"get_data_sql": "get_data.sql",
"recreate_target_sql": "recreate_target.sql",
"target_table_name": "{JOB_NAME}",
"target_table_type": job_module.JobTargetTableType.MART,
"increment": { # при получении данных в where есть {CONDITION},
# движок его заменяет в зависимости настроек инкремент
"target_load_type": job_module.JobTargetTableLoadType.UPSERT_ROWS_BY_PK,
"target_pk_field": "crm_bill_id”,
"target_checkpoint_name": "crm_bill_dttm", # MAX значение этого поля сохранится в системную таблицу
"source_filtering_type": job_module.JobSourceFilteringType.MORE_THAN,
"source_filtering_field": "crm_bil_dttm",
"source_filtering_field_type": job_module.JobFieldType.TIMESTAMP}}
j.add_task(id=1,
order=1,# шаги выполняются по порядку, шаги с одинаковым step_order - параллельно
func='vertica_elt.load_data_vertica_to_vertica', # вызов функции исполнителя джобов
params=params) # параметры функции исполнителя джобов
return j
DE использует готовые функции движка, просто задавая параметры. Например: «target_load_type»: job_module.JobTargetTableLoadType.UPSERT_ROWS_BY_PK -тип загрузки данных в таргет.
Функция 'vertica_elt.load_data_vertica_to_vertica’ — обычная python функция, которая должна иметь следующие входные атрибуты:
@core.lakehouse_function
def load_data_vertica_to_vertica(
launcher: job_launcher.JobLauncher,# connection strings и общие методы исполнителя джобов
job_log: job_log_module.JobLog,# объект для логирования шагов
task: job_module.JobTask, # данные по таску из job.py
run_params, # параметры запуска, например method=’increment’
all_results): # результаты выполнения других шаговТаким образом, все ELT/ETL процессы у нас запускает один исполнитель джобов. В исполнителе есть несколько хорошо отлаженных, документированных функций, которые делают всю работу.
По сути DE создает джобу декларативно. Такой подход резко снижает барьер входа для создания джобов и в разы — вероятность возникновения ошибок.
Оркестрация джобов
От исполнителя одной джобы переходим к их оркестрации.
Вариант 1. Более правильный, но сложный в поддержке. Если на уровне метаданных для каждой джобы определить источники и таргет, то можно автоматически создавать граф. Допустим job_2 уже отработал, тогда если job_3 закончит работу быстрее, чем job_1, то оркестратор запустит job_5, иначе job_4.

Проблемы:
- Вариант 1 в идеальных условиях работает хорошо. Но бизнес может требовать много разных вещей типа “более приоритетных очередей”. Постоянное добавление логики в такую систему может сделать её очень непрозрачной.
- Одна джоба может сильно изменить граф.
Вариант 2. Разделяй и властвуй. Джобы объединяются в группы, у группы есть group_order. Внутри группы у джобы есть job_order. Оркестратор в порядке group_order выбирает группы, группы с одинаковым group_order запускаются параллельно. На уровне джобов и тасков такая же логика.

В обоих вариантах есть глобальный параметр — Параллельность — количество джобов/тасков, которые можно выполнять одновременно.
Второй вариант проще в реализации и контроле, он лучше подходит на старте DWH, но глобально вариант 1 лучше, когда быстро увеличивается число таблиц и DE.
Инструменты и технологии
Данная статье не про инструменты, поэтому скажу лишь пару мыслей.
Если у вас меньше 4 терабайт данных, то не переусложняйте. Достаточно на мощном компьютере поднять PostgreSQL или ClickHouse для DWH. Плюс BI решение: Superset, Metabase или PowerBI.
Если данных больше 4 терабайт, или объемы быстро растут, то необходимо заложить горизонтальное масштабирование. Лучше, чтобы объем данных и вычислительные ресурсы можно было масштабировать по отдельности.
Hadoop — очень сложно и дорого. Почти всегда дешевле и быстрее облачная MPP + S3-совместимый storage.
Облачная MPP/Lakehouse система — ядро аналитического решения. Посмотрите на Google BigQuery, Snowflake, Databricks.
Итоги
В начале проекта как можно быстрее нужно создать ценность для бизнеса.
Сделайте хорошие витрины.
Учитесь получать профит из данных.
К более профессиональному моделированию DWH лучше переходить, когда есть первые успехи.
Сначала логика, потом инструменты – решите задачу на псевдокоде. Поймите и отработайте основные сценарии, а затем уже начинайте выбирать оркестраторы и всё остальное.
Единообразие кода и правил — нужно стремиться упростить жизнь DE:
- Джоба — основной кирпич системы. Джоба должна быть четко определена и проста.
- Одна джоба загружает один таргет (таблицу).
- Джоба — это не визуальная схема, а код (мини-проект).
- job.py + унифицированный исполнитель джобов ускоряет разработку ELT/ETL процессов и снижает порог входа — инвестируйте в движок. Аналитики смогут делать джобы.
Приложение. Основные типы витрин.
Поскольку с витрин начинается DWH, и витрины это лицо DWH, которое видят бизнес-пользователи, хочу остановиться на главных типах витрин:
- Транзакционная витрина – данные в строках не меняются.
- Витрина снимков – все данные на определенную дату.
- Накопительная витрина – у каждой строки есть дата начала и конца действия.
- Витрина на основе запроса.
По моему опыту такие витрины покрывают 90% всех кейсов.
Транзакционная витрина – данные в строках не меняются
Самая простая и популярная витрина. Записи из источника попадают в неё один раз и не меняются.
Преимущества этой витрины — по ней автоматически строятся правильные графики и считаются суммы, например, продажи товаров.

Витрина снимков – все данные на определенную дату
Раз в месяц/квартал/год в такую витрину добавляются все данные из источника. Такая витрина позволяет анализировать данные которые меняются со временем, например, данные о клиентах.
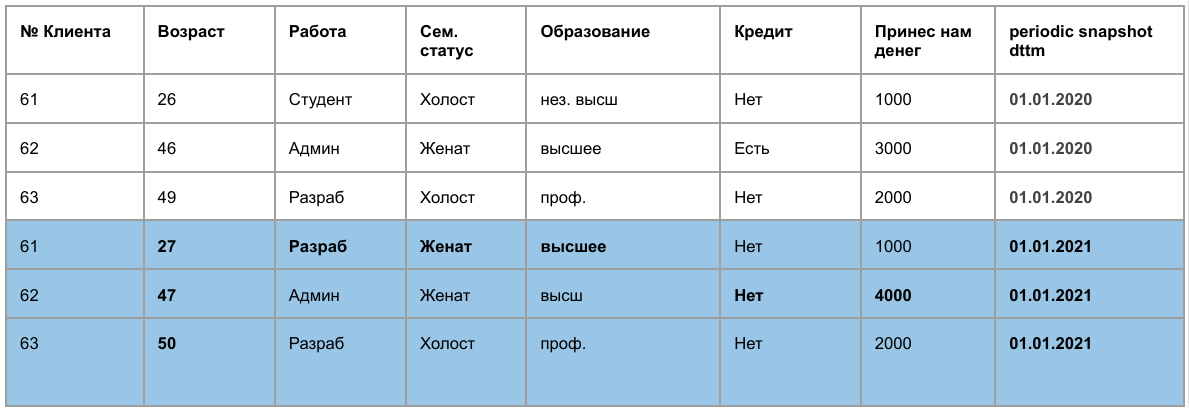
Накопительная витрина – у каждой записи есть интервал актуальности
У накопительной витрины есть 4 дополнительных поля:
- start_dttm, end_dttm – время актуальности записи.
- is_actual – признак актуальности записи.
- is deleted – признак удаления из источника.
Данные из источника забираются раз в час или в день. После загрузки в метаданные хранилища записывается максимально значение поля update_dttm, в котором хранится время обновления записи. В следующий раз данные забираются из источника с фильтром where source_table.update_dttm > MAX(target_table.update_dttm), т.е. берутся только изменившиеся и новые записи.
Пример: Постепенное дополнение заказа в интернет магазине.
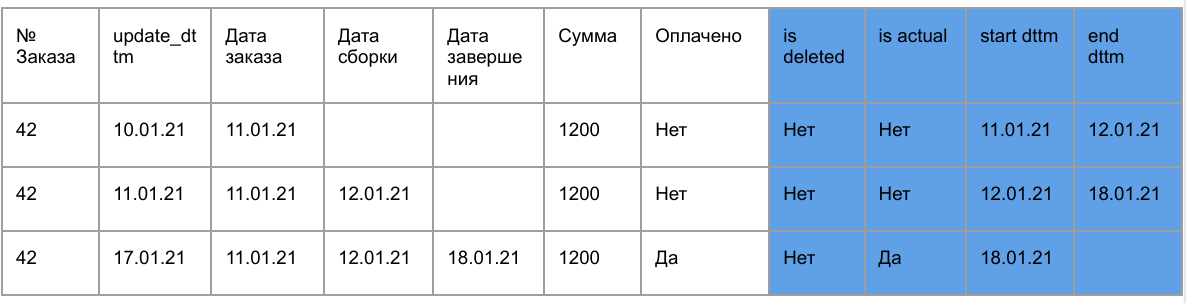
Если в новых данных из источника приходит запись, которая уже есть в таргет-таблице DWH, то у записи в DWH проставляется end_dttm = NOW(), is_actual = false и после добавляется новая актуальная запись.
Таким образом в DWH есть все изменения конкретной записи, что удобно для анализа.
Витрина на основе sql запроса к источнику
К источнику делается произвольный запрос с фильтром source_table.update_dttm > MAX(target_table.update_dttm)
Чтобы не было дублей, из таргет таблицы стираются строки с id, которые пришли из источника. Опционально также могут стираться записи, удаленные из источника. Затем делается вставка всех пришедших записей в таргет.
Итоги по витринам
Все запросы к источнику обычно делаются не к продакшен базе, а к её реплике.
На мой взгляд, на старте создания DWH, описанные 4 типа витрин закроют почти все нужды бизнеса.
По мере взросления DWH, лучше переходить сразу к Data Vault минуя 3NF. Для начала крутое видео.
P. S. Чтобы статья не стала бесконечной, я сознательно исключил ряд тем, таких как: управление метаданными, генерация суррогатных ключей.
Интересно мне сообщества:
Чем отличается ваш подход?
Какие вещи я раскрыл слабо?
Комментарии (8)

Cassiopeya
08.12.2021 08:35+3Действительно отличная вводная статья про dwh. Но от названия «создаем» все таки ожидается именно рассказ как создаем, а не набор пунктов «делайте как хорошо, не делайте как плохо».

tomleto Автор
08.12.2021 12:44+1Спасибо!
Я пытался описать принципы на основе которых мы создаем DWH.

lazutkinAN
08.12.2021 20:17+1Для систем -источников без человеческого фактора в информационных потоках может и взлетит.И главное не заменять прототипирование рабочим решением: переделка дорого будет стоить

Xneg
09.12.2021 09:52Спасибо за статью! Наша команда из трех-четырех DE за пару лет пришла к очень похожим принципам.
Есть вопрос про launcher/исполнитель джобов. Из статьи получается, что метод переливки находится не в коде джобы, а является параметром launcher'а.
launcher.run_job(job_name='marts.crm_bill', method='increment')Мы для себя решили, что метод тоже должен находиться в коде джобы для того, потому что запуски launcher'а не добавишь в Git и теряется информация для аудита, с тем ли методом была запущена джоба.
Вы как-то по-другому решаете эту проблему?
tomleto Автор
09.12.2021 10:29+1У нас расписание всегда запускается с method='increment'
А когда DE разрабатывает джобу ему доступны ещё "full" (полная перезагрузка) и "recreate" (пересоздание таргета).
А алгоритм загрузки определяется в теле джобы и зависит от основных двух параметров.
В примере:
"target_table_type": job_module.JobTargetTableType.MART,
"target_load_type": job_module.JobTargetTableLoadType.UPSERT_ROWS_BY_PK
Например при одном и том же алгоритме UPSERT_ROWS_BY_PK, аналитики для одних типов таблиц просят удалять данные удаленные из источника, а для других помечать как удаленные.
Т.е. как я предполагаю наши опции target_table_type и target_load_type играют ту же роль что у вас метод. И они также определяются в джобе.
Понятно ответил или я не очень понял вопрос?
Arkronus
По сути хорошая вводная статья, но глаз очень сильно режет слово "джобы" в каждом втором предложении ) Может всё таки назвать их задачами?
tomleto Автор
Спасибо!
Просто джобы состоят из тасков. И в кругах дата инженеров это самое популярное слова для обозначения законченного ETL/ELT процесса